■ 언어 모델은 inference 과정에서 토큰을 한 개씩 left-to-right 방식으로 생성하기 때문에 몇 가지 한계를 가진다.
■ 여러 가능성을 시도해 봐야 하는 exploration이 필요한 경우나, 몇 단계 앞을 내다봐야 하는 strategic한 lookahead가 필요한 경우, 그리고 첫 방향을 잘 잡아야 하는, 즉 초기 선택이 매우 중요한 tasks에서는 inference time에서의 LM의 token-level, left-to-right decision-making processes 때문에 이러한 한계가 더욱 두드러질 수 있다.
■ 논문에서는 이러한 한계를 극복하기 위한 방법으로 CoT 접근법을 일반화한 Tree of Thoughts (ToT)을 제안한다.
■ off-the-shelf LM을 inference 단계에서 활용하는 방식인 ToT는 다양한 reasoning paths을 고려할 수 있고, 선택지를 스스로 평가하여 다음 행동 방향을 결정할 수 있다. 그리고 전략적인 선택을 내리기 위해, 필요할 때 looking ahead나 backtracking도 가능하다.
[2305.10601] Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inference. This means they can fall short in tasks that require
arxiv.org
1. Introduction
■ LM은 텍스트 생성을 위해 설계되었다. 그런데 GPT나 PaLM과 같이 scaled-up된 LM들이 등장하면서 이제는 단순한 텍스트 생성을 넘어 수학, 기호, 상식, 지식 기반 추론 같은 광범위한 tasks을 더 잘 풀고 있다.
■ 그러나 여전히 여전히 단어를 왼쪽에서 오른쪽으로 한 번에 하나씩 token-level에서 결정하는, 텍스트 생성을 위한 autoregressive 메커니즘이 자리 잡고 있다. 성능이 좋아졌는데도, 실제로 작동하는 추론 방식은 여전히 단순하다.
■ 이 점에 대해 저자들은 다음과 같은 질문을 던진다. 이렇게 단순한 생성 메커니즘으로 언어 모델을 general problem solver로 구축하기에 충분할까? 만약 그렇지 않다면, 이를 대체할 메커니즘은 무엇인가?
■ human cognition 연구의 dual process 모델에 대한 연구에 따르면, 사람들은 의사결정을 내릴 때 두 가지 모드가 있다고 주장한다. 하나는 빠르고 자동적이며 무의식적인 모드 (System 1)와 느리지만 신중하고 의식적인 모드 (System 2)이다. 예를 들어 단순한 문제를 푸는 것은 System 1에 가깝고, 복잡한 퍼즐을 여러 경우의 수를 따져가며 푸는 것은 System 2에 가깝다.
■ 저자들은 현재 LLM의 토큰 단위 생성이 System 1에 더 닮아 있다고 보고, 따라서 좀 더 신중한 System 2 planning process을 추가하면 큰 이점을 얻을 수 있을 것이라 판단했다.
■ System 2 planning process는 (1) 현재의 선택에 대해 단순히 하나만 고르는 대신 다양한 대안들을 유지하고 탐색하며, (2) 현재 상태를 평가하고 더 전역적인 결정을 내리기 위한 lookahead나 backtrack이 가능하다.
■ 이러한 planning process를 설계하기 위해 고전 연구로 돌아간다. 해당 연구에서는 problem solving을 combinatorial problem space 안에서의 탐색으로 보았다. 이때 탐색 공간은 tree 형태로 표현된다.
■ 저자들은 이 접근법에 영감을 받아, 일반적인 problem solving을 위한 Tree of Thoughts (ToT) 프레임워크를 제안한다. (Fig 1 (d))
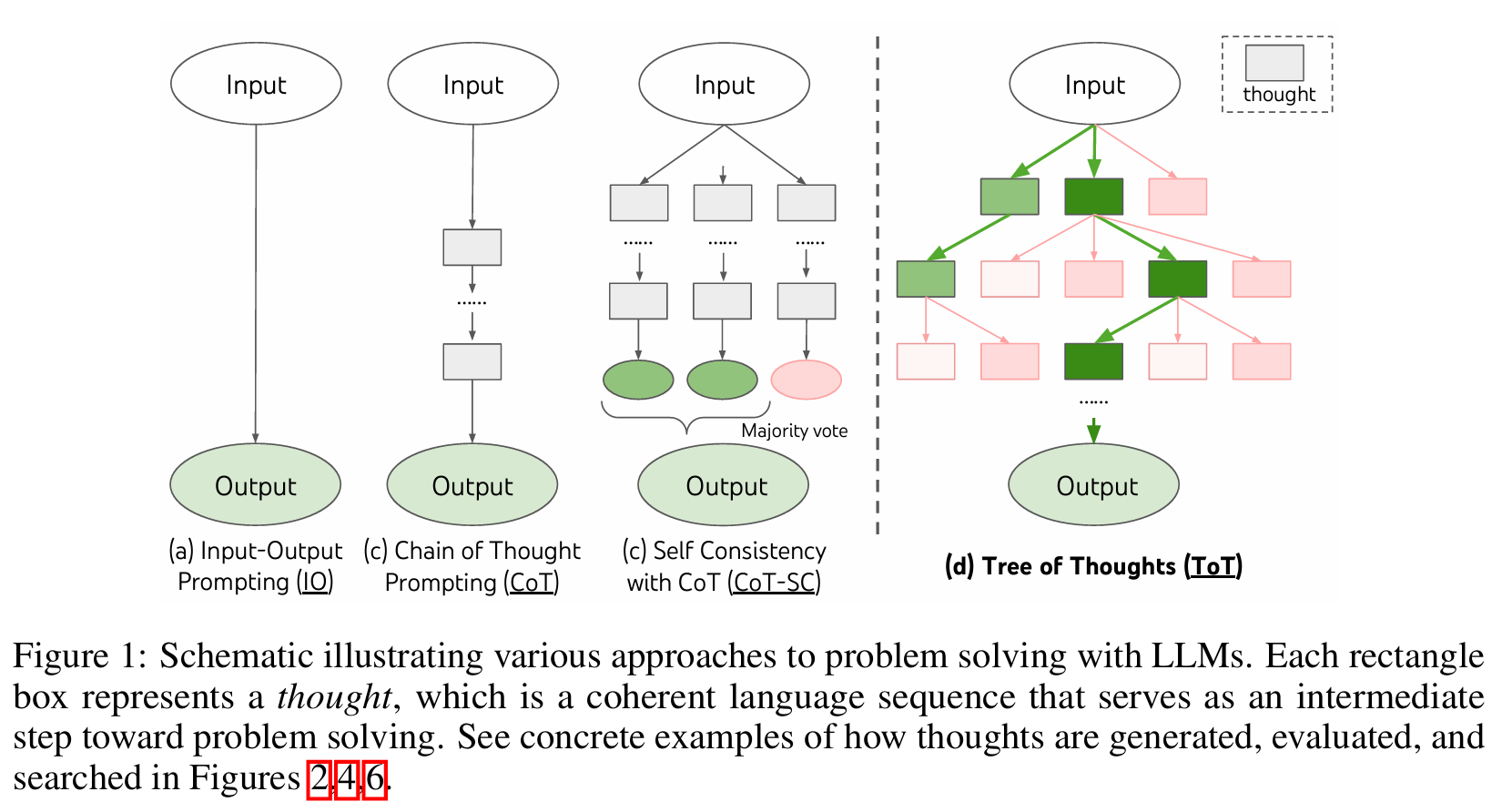
■ Fig 1에서 볼 수 있듯이, 기존 방법들은 problem solving을 위해 연속적인 시퀀스만 생성한다. 반면 ToT는 thoughts의 tree를 유지하면서 문제를 푼다.
■ 여기서 각각의 thought은 단순한 토큰 하나가 아니라, problem solving을 위한 중간 단계 역할을 하는 의미 있는 텍스트이다.
■ 이러한 high-level의 semantic unit은 언어 모델이 언어로 구체화된 추론 과정을 통해 서로 다른 중간 thoughts이 문제 해결을 위해 얼마나 진전을 보이고 있는지 self-evaluate할 수 있게 한다.
- 정리하면 ToT가 혁신적인 이유는, 기존 autoregressive 메커니즘의 경우 토큰 하나는 정보가 너무 적어 현재 시퀀스 생성 방향이 올바른지 평가하기 어렵지만, 'thought'처럼 어느 정도 의미 있는 단위는 평가가 가능하다는 점.
- 또한, LM이 직접 중간 단계(텍스트 형태의 thought)들이 가능성이 있는지를 언어적으로 판단한다는 점.
■ 마지막으로 저자들은 thought를 생성하고 평가하는 능력을 전통적인 탐색 알고리즘(예: BFS, DFS)과 결합한다. 이를 통해 lookahead나 backtracking으로 tree of thoughts을 체계적으로 탐색할 수 있다.
■ SOTA LM인 GPT-4를 사용해도 기존의 LM inference methods로는 해결하기 어려운 세 가지 문제로 자신들의 방법을 평가한다: Game of 24, Creative Writing, Crosswords (Table 1)

■ 이 tasks은 deductive, mathematical, commonsense, lexical reasoning abilities을 요구할 뿐만 아니라, 체계적인 planning이나 탐색을 통합하는 방법을 필요로 한다. 논문에서는 ToT가 서로 다른 문제의 본질에 적응하는 다양한 탐색 알고리즘과, thoughts을 생성하고 평가하는 다양한 방법, 그리고 다양한 수준의 thoughts을 지원할 만큼 충분히 범용적이고 유연하게 작동함으로써, 이 세 가지 tasks 모두에서 뛰어난 결과를 얻는다는 것을 보여준다.
2. Background
■ 파라미터 \( \theta \)를 가진 pre-trained LM을 \( p_{\theta} \), 소문자 \( x, y, z, s, \cdots \)을 language sequence라고 하자. \( x = (x[1], \cdots, x[n]) \)이라고 하면 여기서 각 \( x[i] \)는 하나의 token이다. 그러면 autoregressive LM \( p_\theta(x) = \prod_{i=1}^n p_\theta(x[i]|x[1...i-1]) \)가 성립한다. 대문자 \( S \)는 시퀀스들의 집합이라고 하자.
2.1 Input-output (IO) prompting
■ IO prompting은 roblem input \( x \)를 프롬프트로 감싼 뒤, 언어 모델이 그에 대한 output \( y \)를 생성하는 가장 일반적인 방법이다.
■ 수식으로는 \( y \sim p_{\theta}(y \mid \text{prompt}_{IO} (x)) \)로 나타낼 수 있으며, 여기서 \( \text{prompt}_{IO} (x) \)는 input \( x \)를 task instructions 및/또는 few-shot input-output examples로 감싼 형태이다.
- 즉, IO prompting은 input \( x \)가 있다면, 거기에 task instruction을 붙이거나 추가로/또는 몇 개의 few-shot examples을 붙인 프롬프트를 사용하여 모델이 정답 \( y \)를 생성하게 하는 방식이다.
■ 수식의 단순화를 위해, \( p_\theta^{\text{prompt}}(\text{output} \mid \text{input}) = p_\theta(\text{output} \mid \text{prompt}(\text{input})) \)라고 표기하자. 그러면 IO prompting은 \( y \sim p_\theta^{IO}(y|x) \)로 간단하게 적을 수 있다.
2.2 Chain-of-thought (CoT) prompting
■ CoT prompting은 input \( x \)에서 output \( y \)로의 매핑이 까다로운 경우, 다시 말해 중간 사고 과정 없이 정답으로 한 번에 가기 어려운 경우를 다루기 위해 제안되었다. (예: \( x \)가 수학 문제이고 \( y \)가 최종 숫자 정답)
■ CoT의 핵심 아이디어는 \( x \)와 \( y \) 사이의 간극을 연결하기 위해 chain of thoughts \( z_1, \cdots, z_n \)을 도입한 것이다. 여기서 각 \( z_i \)는 language sequence로 problem solving을 향한 의미 있는 중간 단계이다. 예를 들어 수학 문제에서 \( z_i \)는 중간 계산 수식이 될 수 있다.
■ CoT를 사용하여 문제를 해결하기 위해, 각 thought \( z_i \sim p_\theta^{CoT}(z_i \mid x, z_{1\cdots i-1}) \)가 순차적으로 샘플링되고, 그다음 output \( y \sim p_\theta^{CoT}(y|x, z_{1\cdots n}) \)가 샘플링된다.
■ 실제로는 \( [z_{1\cdots n}, y] \sim p_\theta^{CoT}(z_{1\cdots n}, y|x) \)로, 하나의 연속된 텍스트 시퀀스로 생성된다. 이때 각 thought의 단위(즉, \( z_i \)하나)가 한 단어인지, 구인지, 문장인지, 아니면 단락인지가 분명하게 정해져 있지 않다.
■ 즉, CoT에서는 모델이 reasoning 과정을 연속적으로 써 내려가기 때문에, 어디서 한 thought가 끝나고 다음 thought가 시작되는지가 애매하다.
2.3 Self-consistency with CoT (CoT-SC)
■ CoT-SC는 서로 독립적이고 모두 동일한 확률분포를 따르는(i.i.d) \( k \)개의 chains of thought을 샘플링하는 ensemble approach이다. 즉, 같은 문제를 놓고 모델에게 여러 번 생각하게 하되, 매번 하나의 reasoning path를 선택한다.
■ \( [z_{1\cdots n}^{(i)}, y^{(i)}] \sim p_\theta^{CoT}(z_{1\cdots n}, y|x) \ (i = 1 \cdots k) \)를 샘플링한 다음, 빈도수가 가장 높은 output을 반환한다.
■ 동일한 문제에 대해 일반적으로 서로 다른 사고 과정이 존재할 수 있고(예: 동일한 정리를 증명하는 여러 가지 방법), 다수결 majority vote를 통해 더 높은 신뢰도를 가질 수 있기 때문에, CoT-SC는 단순 CoT보다 성능을 향상시킨다.
■ 그러나 각 chain 내부에서는 서로 다른 thought steps에 대한 exploration이 전혀 이루어지지 않으며, 가장 빈도수가 높은 답변을 고르는 휴리스틱은 출력 공간이 제한되어 있을 때(예: 객관식 문제)만 적용될 수 있다는 한계(예: 창의적인 글쓰기)가 있다.
3. Tree of Thoughts: Deliberate Problem Solving with LM
■ 인간의 problem solving에 관한 연구는 사람들이 combinatorial problem-space를 탐색한다고 주장한다. 이 공간은 nodes이 부분적인 solutions을 의미하고, branches은 그것들을 수정하는 연산자에 해당하는 트리구조이다.
■ 즉, 이 연구에서는 인간의 problem solving이 보통 트리 탐색처럼 이루어진다고 말한다. 사람은 하나의 생각만 끝까지 밀고 가지 않고, 지금 가능한 선택지들을 몇 개 떠올리고, 그중 유망한 것을 따져 보고, 안 되면 다른 길로 돌아가고, 때로는 몇 단계 앞을 내다본다.
■ 논문에서는 LM을 사용한 기존 접근법들이 이런 점이 부족하다고 본다. 구체적으로 두 가지이다.
- (1) 기존 방법들은 하나의 thought process 내에서 다른 continuation들(즉, 트리의 가지들)을 탐색하지 않는다.
- 예를 들어 CoT는 \( z_1 \rightarrow z_2 \rightarrow z_3 \)처럼 thought이 한 방향으로만 진행되지, \( z_2 \)에서 가능한 경로 \( A/B/C \)를 비교하는 식의 분기가 약하다.
- (2) 다양한 선택지들을 평가하는 데 도움이 될 어떠한 형태의 planning, lookahead, 또는 backtracking이 없다.
- 논문에서는 이것이 human problem-solving의 중요한 특징인데 기존 방법들에는 반영되지 않았다고 본다.
■ 이 한계를 해결하기 위한 방법으로 저자들은 Tree of Thoughts (ToT)를 제안한다. ToT에서는 모든 문제를 트리에 대한 탐색으로 본다.
■ 여기서 각 노드는 input \( x \)와 지금까지 생성한 thoughts의 sequence \( z_1, \dots, z_i \)를 결합하여 'partial solution'을 나타내는 state \( s = [x, z_{1 \cdots i}] \)로 정의된다.
■ 저자들은 ToT를 구현하려면 다음 네 가지를 정해야 한다고 말한다: (1) 중간 과정을 어떻게 thought steps로 분해할 것인가 (2) 각 state에서 어떻게 잠재적인 thoughts을 생성할 것인가 (3) states을 휴리스틱하게 어떻게 평가할 것인가 (4) 어떤 탐색 알고리즘을 사용할 것인가
3.1 Thought decomposition
■ CoT는 명시적인 분해 없이 thoughts을 샘플링하는 반면, ToT는 문제의 특성에 따라 thought steps을 설계하고 분해한다.
■ Table 1에서 볼 수 있듯이 문제에 따라 thought의 단위는 몇 개의 단어(Crosswords), 한 줄의 수식(Game of 24), 또는 한 단락 전체(Creative Writing)가 될 수 있다.
■ 또한 저자들은 thought가 다음 두 조건을 동시에 만족해야 한다고 설명한다: (1) LLM이 다양한 샘플들을 생성할 수 있을 만큼 충분히 작아야 하지만, 동시에 (2) problem solving을 향한 가능성을 평가할 수 있을 만큼 충분히 커야 한다.
- 조건 (1)은 thought의 단위가 지나치게 커서는 안 된다는 뜻이다. 예를 들어 thought의 단위를 책 한 권 전체로 두면, 생성 자체가 어렵고 일관성을 유지하기에 너무 크다.
- 두 번째 조건은 thought의 단위가 지나치게 작아서도 안 된다는 뜻이다. 예를 들어 토큰 하나처럼 너무 작은 단위는 문제 해결에 대한 기여 가능성을 평가하기에 충분한 의미를 담지 못한다.
3.2 Thought generator \( G(p_{\theta}, s, k) \)
■ state \( s = [x, z_{1 \cdots i}] \)가 주어졌을 때, next thought step을 위한 \( k \)개의 candidates을 생성하는 두 가지 전략을 제시한다.
- (a) Sample i.i.d. thoughts from a CoT prompt (Creative Writing, Figure 4)
- \( z^{(j)} \sim p_\theta^{CoT}(z_{i+1}|s) = p_\theta^{CoT}(z_{i+1}|x, z_{1\cdots i}) \ (j = 1 \cdots k) \)
- 이 방식은 thought space가 풍부한 경우, 즉 현재 state에서 next thought로 가능한 후보들이 다양하고 넓게 많이 존재하는 경우에 더 좋다고 설명한다.
- 예를 들어 Creative Writing (Fig 4)의 경우, 각 thought를 하나의 단락 단위로 설정하면 여러 번 샘플링을 통해 다양한 아이디어를 얻을 수 있어 유리하다.
- (b) Propose thoughts sequentially using a "propose prompt" (Game of 24, Figure 2; Crosswords, Figure 6)
- \( [z^{(1)}, \cdots, z^{(k)}] \sim p_\theta^{propose}(z_{i+1}^{(1\cdots k)} \mid s) \)
- 이 방식은 thought space가 제한적일 때 좋다. 예를 들어 Game of 24 (Fig 2)에서 각 thought이 하나의 단어나 한 줄의 수식이라면, 같은 문맥에서 후보를 여러 개 제안하게 하는 편이 중복을 줄일 수 있다.
- Fig 2의 예시처럼 thought의 단위가 식 한 줄일 경우, 주어진 숫자가 정해진 상태에서는 가능한 연산 조합이 많지 않다. 즉, 후보 수가 어느 정도 제한된다.
3.3 State evaluator \( V(p_{\theta}, S) \)
■ 서로 다른 states이 주어지면, state evaluator는 각 state가 problem solving을 향해 얼마나 진전을 이뤘는지 평가한다. 그리고 탐색 알고리즘이 어떤 state들을 어떤 순서로 계속 탐색할지 결정하는 휴리스틱 역할을 수행한다.
■ 탐색 문제에서 사용된 기존 휴리스티근 보통 두 종류였다: (1) programmed rule: 사람이 직접 규칙을 짜놓음 (예: DeepBlue) (2) learned model: 별도 데이터로 학습시킴 (예: AlphaGo)
■ ToT에서는 세 번째 방식을 제안한다. LM이 state를 보고 추론해서 평가하게 하자는 것이다. 이렇게 하면 규칙을 사람이 작성할 필요도 없고, 별도의 evaluator를 학습시킬 필요도 없다.
■ 논문에서는 두 가지 전략을 고려한다: (1) state를 독립적으로 평가 (2) state들끼리 비교해서 하나를 고르는 방식
- (a) Value each state independently: \( V(p_\theta, S)(s) \sim p_\theta^{value}(v|s) \ \forall s \in S \)
- \( S \) 안의 각 state \( s \)를 하나씩 따로 보고, 그 state의 value \( v \)를 평가한다.
- 여기서 value prompt는 휴리스틱하게 숫자로 변화할 수 있는 scalar value \( v \)(예: 1-10점) 또는 classification(예: 확실함/가능성 있음/불가능함)을 생성하기 위해 state \( s \)에 대해 추론한다.
- 여기서 추론의 기준은 문제와 thought steps에 따라 달라질 수 있다. 논문에서는 few lookahead simulations과 commonsense를 평가의 근거로 사용한다.
- few lookahead simulations은 말 그대로, 조금 앞을 내다보는 시뮬레이션이다. 예를 들어 "5, 5, 14가 주어지면, 5+5+14=24가 가능하다", "hot_l에 e를 채우면 hotel이 될 수 있다"처럼 몇 수 앞을 짧게 확인하는 것이다.
- commonsense도 예를 들어 "1, 2, 3은 24를 만들기엔 너무 작은 숫자 조합이다", "tzxc로 시작하는 단어는 존재하지 않는다"처럼 commonsense를 판단한다는 것이다.
- 그래서 few lookahead simulations는 좋은 state를 밀어주고, commonsense는 나쁜 state를 제거하는 데 도움을 줄 수 있다.
- 중요한 포인트는, 이러한 value 평가는 완벽할 필요가 없고 decision making에 대략적으로 도움이 될 정도면 충분하다는 것이다. 왜냐하면 이건 정답 판별이 아닌 휴리스틱이기 때문이다.
- (b) Vote across states: \( V(p_\theta, S)(s) = \mathbf{1}[s = s^*] \)
- 두 번째 방식은 첫 번째 방식처럼 각 state를 따로 점수화하지 않고, 후보들을 서로 비교해서 가장 좋은 state \( s^* \)를 고르는 방식이다.
- \( s^* \)는 vote prompt 안에서 \( S \)에 속하는 여러 다른 state들을 비교한 결과를 바탕으로 투표를 통해 결정된다.
- 문제의 성공 여부를 점수로 평가하기 어려운 경우(예: 글의 응집성)에는 vote 방식은 유용하다. 여러 후보 중 가장 유망한 것 하나를 선택하는 방식이기 때문이다.
■ 두 전략 모두, LM에 여러 번 프롬프트를 제공하여 value나 vote results을 집계할 수 있다. value/vote를 여러 번 수행하기 때문에 시간, 자원 및 비용을 더 지불하지만 더 신뢰할 수 있고 견고한 휴리스틱을 얻을 수 있다.
3.4 Search algorithm
■ ToT에서는 하나의 state에서 next thought 후보가 여러 개 생성될 수 있으므로, 전체 추론 과정은 자연스럽게 트리 구조를 이룬다. 이에 따라 현재 state들 가운데 어떤 경로를 계속 탐색하고 어떤 가지를 버릴지 결정하는 탐색 알고리즘이 필요하다.
■ 논문에서는 가장 기본적인 두 가지, BFS와 DFS를 사용하지만 트리 구조에 따라 다양한 탐색 알고리즘을 사용할 수 있다고 말한다.
- (a) Breadth-first search (BFS) (Algorithm 1)

- \( x \)는 input problem, \( p_{\theta} \)는 LM, \( G \)는 thought generator, \( V \)는 state evaluator이며, \( T \)는 최대 step 수, \( k \)는 한 state에서 생성할 후보 thought 수, \( b \)는 각 step에서 남겨둘 state 개수
- \( S_0 \leftarrow \{ x \} \): 처음에는 아직 thought을 하나도 생성하지 않았으므로, 초기 상태 집합 \( S_0 \)에는 input \( x \) 하나만 들어 있다.
- \( \text{for} \; t = 1, \cdots, T \text{do} \): step 1부터 \( T \)까지 반복하겠다. 즉, thought를 최대 \( T \) step까지 확장한다.
- \( S'_t \leftarrow \{ [s, z] \mid s \in S_{t-1}, z_t \in G(p_{\theta}, s, k) \} \): 이전 step(\( t-1 \) step)에 존재하는 모든 state들 \( s \in S_{t-1} \)에 대해, 각 state마다 thought generator \( G \)가 next thought 후보를 최대 \( k \)개 생성한다. 그런 다음 생성된 thought을 붙여서 new state를 만든다.
- 예를 들어, 어떤 시점에 \( S_{t-1} \)에 state 3개가 있다고 하자. 각 state에서 후보 thought를 \( k = 2 \)개씩 생성하면, state 3개 각각에 새로운 state 2개가 생긴다. 즉, 총 6개의 new state가 생긴다. 이 전체를 담고 있는 집합이 \( S'_t \)이다. 즉, \( S'_t \)는 이번 step에서 새로 확장된 전체 state들이다.
- \( V_t \leftarrow V(p_{\theta}, S'_t) \): \( S'_t \)를 state evaluator \( V \)가 평가한다. 각 state가 답에 가까워 보이는지, 계속 탐색할 가치가 있는지를 스칼라 값 또는 vote로 판단한다. 즉, \( V_t \)는 이번 step에서의 평가 결과이다.
- \( S_t \leftarrow \arg\max_{S \subset S'_t, |S| = b} \sum_{s \in S} V_t(s) \): \( S'_t \) 중에서 정확히 \( b \)개만 고른다. 단, evaluator 점수의 합이 가장 커지도록 만드는 \( b \)개를 고른다. 즉, 점수가 높은 상위 \( b \)개의 state들만 남긴다.
- \( \text{end for} \): 이 과정을 \( t = 1 \)부터 \( T \)까지 반복한다. 즉, 매 step마다 생성, 평가, 상위 \( b \)개 유지를 반복한다.
- \( \text{return} \; G(p_{\theta}, \text{arg max}_{s \in S_T} V_T(s), 1) \): 마지막에는 최종 step까지 살아남은 state들 \( S_T \) 중에서 가장 점수가 높은 것 하나를 고르고, 최종 답을 생성한다.
- (b) Depth-first search (DFS) (Algorithm 2)

- 현재 state와 step을 \( s \)와 \( t \), \( v_{th} \)는 threshold이다.
- (b)는 (a)처럼 여러 state를 유지하기보다, 현재 가장 유망한 state 하나를 깊게 탐색하는 방식이다.
- \( \text{if} \; t > T \; \text{then record output} \; G(p_{\theta}, s, 1) \): final output에 도달하면(\( t > T \)), state evaluator \( G \)가 현재 state \( s \)에서 최종 output을 생성한다.
- \( \text{for} \; s' \in G(p_{\theta}, s, k) \; \text{do} \): \( s \)에서 다음 후보 state들 \( s' \)를 생성한다.
- \( \text{if} \; V(p_{\theta}, {s'})(s) > v_{thres} \; \text{then} \; \text{DFS}(s', t+1) \): 현재 후보 \( s' \)가 threshold보다 좋으면 그 아래로 계속 탐색한다.
- 그래서 DFS는 구조상 현재 state에서 가장 유망한 자식으로 내려가고, 또 거기서 유망한 자식으로 내려가고, 계속 깊게 탐색하다가 유망하지 않으면 돌아오는 형태가 된다.
- 더 이상 내려갈 자식 state가 없거나 threshold를 넘는 자식 state가 없으면 부모 state로 되돌아가서 다른 후보를 탐색하게 된다.
■ 저자들은 ToT가 LM을 사용한 general problem-solving으로서 네 가지 장점을 갖는다고 언급한다.
- (1) Generality: 기존의 IO, CoT, CoT-SC 및 self-refinement 등은 모두 깊이와 너비가 제한된 ToT의 special cases이다. (Fig 1)
- (2) Modularity: ToT는 LM뿐만 아니라 다른 구성요소들(thought decomposition, thought 생성, 평가 및 탐색 방식)을 독립적으로 바꿀 수 있다.
- 이 구성요소들이 각각 모듈처럼 분리되어 있어서, 하나의 요소를 바꿔도 전체 틀은 유지된다.
- (3) Adaptability: 문제 특성, 모델의 연산 능력, 리소스 제약(API 비용, 시간 등)에 맞게 조절할 수 있다.
- 예를 들어 문제마다 thought 단위를 다르게 잡을 수 있고, 평가도 value/vote가 가능하다.
- (4) Convenience: 별도의 추가 학습이 전혀 필요 없으며, pre-trained LM만 있으면 된다.
- 별도 search model을 학습하거나 evaluator를 따로 훈련하지 않아도, 이미 있는 언어모델의 생성과 평가 능력을 활용해서 ToT를 구현할 수 있다.
4. Experiments
■ temperature 0.7로 설정한 chat completion mode의 GPT-4를 사용하여 일반적인 IO prompting이나 CoT prompting으로 해결하기 어려운 세 가지 tasks을 설계하여 ToT가 기존 방법들에 비해 어떻게 더 나은 결과를 도출하는지 비교한다.
4.1 Game of 24

■ Game of 24는 4개의 숫자와 기본 사칙연산(+-*/)을 사용하여 24를 만드는 것을 목표로 하는 mathematical reasoning challenge이다. 예를 들어, "4 9 10 13"이라는 input이 주어졌을 때, solution output은 "(10 - 4) * (13 - 9) = 24"가 될 수 있다.
Task Setup
■ 문제를 사람이 풀었을 때 걸리는 시간 기준으로 쉬운 것부터 어려운 것 순으로 정렬된 1,362개의 게임을 보유한 4nums.com에서 데이터를 수집하였다. 이 중에서 상대적으로 어려운 구간인 901번부터 1000번까지, 총 100개 문제를 테스트셋으로 사용한다.
■ 입력된 숫자를 각각 정확히 한 번씩 사용하여 24가 되는 유효한 수식을 출력하면 성공으로 간주한다. 테스트셋에 대한 성공률을 평가지표로 사용한다.
Baselines
■ input-output 형태의 in-context example 5개가 포함된 standard (IO) prompt를 사용한다.
■ CoT prompting의 경우, 각 input-output example에 중간 식 3개를 추가한다. 예를 들어, input "4 9 10 13"이 주어지면 thoughts은 "13 - 9 = 4 (남은 숫자: 4, 4, 10); 10 - 4 = 6 (남은 숫자: 4, 6); 4 * 6 = 24 (남은 숫자: 24)"처럼 구성된다. thought을 "남은 숫자를 갱신해 가는 죽안 식 한 줄"로 잡은 것이다. 이를 통해 thought의 적절한 단위를 자연스럽게 유도할 수 있다.
■ 각 게임에 대해 IO와 CoT prompting을 100번씩 샘플링하여 평균 성능(성공률)을 계산한다.
■ 추가로, 100개의 CoT 샘플에서 다수결 투표로 최종 답을 선택하는 CoT-SC 베이스라인과, IO 샘플에서 최대 10번 반복하는 iterative-refine 접근법도 고려한다. 각 반복마다 최종 답이 올바르지 않으면, LLM은 "실수를 성찰하고 개선된 답변을 생성하라"는 지시와 함께 이전 모든 기록을 입력받는다. 식이 맞는지 틀린지에 대한 ground-truth feedback을 사용한 것이다.
ToT Setup
■ 게임을 ToT 구조에 맞추기 위해, thoughts을 3 steps의 중간 수식으로 나눈다. 숫자 4개에서 시작하여 두 숫자를 연산하고 하나로 줄이는 과정을 3번 걸치면 마지막에 하나의 값이 남기 때문에 자연스럽다 (Baselines 예시 참고).
■ 각 노드는 현재까지의 연산 결과를 반영해 남아 있는 숫자들을 추출하고, 그 상태에서 가능한 다음 식 후보들을 생성한다. 즉, input이 "4 9 10 13"이면 다음 중간 수식 후보들을 만들고, 어떤 식을 선택하느냐에 따라 자식 노드들이 갈라진다.
■ 3개의 thought steps 모두에 동일한 propose prompt를 사용한다. 탐색 알고리즘으로 BFS를 사용하며 각 step에서 가장 좋은 후보 \( b = 5 \)개를 유지한다. 즉 매 step마다 후보를 넓게 만들어 보고, evaluator가 점수를 매긴 뒤, 상위 5개 상태만 다음 단계로 넘어간다.
■ deliberate한 BFS를 수행하기 위해, Fig 2 (b)에 나타난 바와 같이 LLM에게 "24"에 도달할 가능성과 관련하여 각 thought 후보를 "확실함(sure)/가능성 있음(maybe)/불가능함(impossible)"으로 평가하도록 프롬프트한다. 이 평가의 목적은 몇 번의 lookahead 시도 내에 판별될 수 있는 올바른 partial solutions은 촉진하고, "too big/small"과 같은 commonsense를 바탕으로 불가능한 partial solutions은 제거하며, 나머지는 "maybe"로 유지하는 것이다.
■ 즉, few lookahead와 commonsense를 이용해 ToT-BFS를 수행한다. 예를 들어 현재 남은 숫자가 "5, 5, 14"면 몇 번의 lookahead만으로도 5+5+14=24를 확인할 수 있다. 남은 숫자가 "1, 2, 3"처럼 너무 작은 숫자면 상식적으로 24에 도달하기 어렵다고 보고 "impossible"에 가깝다고 볼 수 있다. 이런 식의 few lookahead + commonsense를 이용하여 좋은 partial solution은 밀어주고, 불가능한 partial solution은 일찍 제거하는 것이 evaluator의 목표이다.
■ 그리고 저자들은 evaluator의 평가를 더 안정적으로 만들기 위해, 각 thought마다 value 평가를 3번 샘플링했다고 말한다.
Results

■ Table 2에서 볼 수 있듯이, IO, CoT, CoT-SC prompting의 성공률은 각각 7.3%, 4.0%, 9.0%로 매우 낮다. 즉, GPT-4와 같은 강한 모델을 사용해도, IO나 CoT 방식만으로는 이 문제를 거의 풀지 못한다는 것이다. 반면 ToT는 \( b = 1 \)일 때도 성공률이 45%였고, \( b = 5 \)일 때는 74%까지 성공률이 올라갔다.
■ 추가로 IO/CoT에 대해 best of \( k \; (1 \leq k \leq 100) \)의 결과를 사용하여 성공률을 계산했다. 그리고 IO/CoT best of \( k \)와 ToT의 공정한 비교를 위해, ToT가 방문한 노드의 수와 IO/CoT가 본 샘플 수를 어느 정도 일치시켜 성능을 비교한다. (Fig 3 (a))
■ 그 결과 CoT best of \( k \)는 IO best of \( k \)보다 더 좋은 결과를 달성했다. 그러나 best of 100 CoT도 성공률이 49%에 그쳐, 여전히 ToT의 \( b > 1 \) 설정보다 성능이 훨씬 낮다.
■ 이 결과들은 thoughts을 tree 형태로 평가 및 탐색하는 방법이 큰 차이를 만들 수 있음을 시사한다.
Error analysis

■ Fig 3 (b)는 CoT와 ToT가 어느 단계에서 실패한지 분석한 것이다. 여기서 실패란, CoT에서는 어떤 thought가 invalid하거나 24에 도달 불가능한 상태가 되는 것이고, ToT에서는 \( b \)개의 thought가 다 invalid하거나 impossible해지는 경우이다.
■ CoT의 경우 60%가 첫 번째 step에서 실패했음을 볼 수 있다. 이는 한 방향으로 직진만 하는 left-to-right decoding이 가진 치명적인 문제(예: 초기 선택 오류)를 보여준다.
4.2 Creative writing
■ creative writing은 input은 4개의 랜덤 문장이고, output은 해당 4개의 입력 문장으로 각각 끝나는 4개의 문단으로 이루어진 하나의 일관된 글이 되어야 하는 task이다. 이러한 task는 open-ended이고 exploratory이며, creative thinking뿐만 아니라 high-level planning 능력을 필요로 한다.
Task Setup
■ randomwordgenerator.com에서 랜덤하게 뽑아 100개의 inputs을 만들었으며, 각 input에 대한 groundtruth 정답 글이 없다.
■ 평가 기준은 글의 coherency이며, 두 가지 방식으로 평가를 수행한다: GPT-4 zero-shot prompt를 사용하여 1-10점의 스칼라 점수를 매기게 하거나, 서로 다른 방법에서 나온 출력 쌍을 사람이 판단하여 비교하는 것이다.
■ 전자의 경우 5개의 점수를 샘플링하여 평균을 내었으며, 이 5개의 점수는 outputs 전체에 걸쳐 평균 표준편차가 약 0.56으로 점수가 대체로 일관적이었다고 말한다. 후자의 경우 블리안드 테스트를 진행했으며, 100개의 입력에 대해 무작위로 CoT와 ToT가 생성한 글의 coherency을 비교하도록 했다.
Baselines
■ task의 특성이 '창의적'임을 고려해 IO와 CoT 모두 zero-shot으로 설정한다. 전자는 입력이 주어지면 LLM이 바로 coherent한 passage를 생성한다. 즉, plan 없이 곧바로 글을 작성한다. 반면, 후자는 LLM이 먼저 간단한 plan을 세운 다음 passage를 작성하도록 프롬프트한다. 이 plan이 intermediate thought step 역할을 한다.
■ IO와 CoT는 각각 문제당 10개 샘플을 생성한다.
■ 추가로, IO로 랜덤한 글 하나를 생성한 뒤, input constraints과 생성된 글을 조건으로 주고 그 글이 perfectly coherent한지 판단하고, 그렇지 않다면 개선된 글을 생성하도록 하는 iterative-refine도 베이스라인으로 사용한다.
ToT Setup

■ depth가 2인 ToT를 구성한다. intermediate thought step은 1개뿐이다. plan 생성 및 선택과 passage 생성 및 선택의 2단계 구조이며, 여기서 plan을 다루는 부분이 intermediate thought step이다.
■ LLM은 먼저 \( k = 5 \)개의 plans을 생성하고 가장 좋은 plan에 투표한 다음(Fig 4), 그 최고의 plan을 바탕으로 \( k = 5 \)개의 passages을 생성하고 가장 좋은 passag에 투표한다. 여기서 breadth limit \( b = 1 \)이다.
■ plan 생성 및 선택과 passage 생성 및 선택, 두 단계 모두에서 5번의 투표를 샘플링하기 위해 "analyze choices below, then conclude which is most promising for the instruction"라는 zero-shot vote prompt가 사용된다.
Results

■ Fig 5 (a)는 GPT-4의 평균 coherence score으로, ToT(7.56)가 IO(6.19) 및 CoT(6.93)보다 더 coherent한 passage를 생성하는 것으로 평가할 수 있다.
■ 이러한 자동 평가에는 노이즈가 있을 수 있지만, Fig 5 (b)는 인간이 100개의 지문 쌍 중 41개에서 CoT보다 ToT를 선호하는 반면, ToT보다 CoT를 선호한 경우는 단 21개라는 것을 보여줌으로써, ToT가 CoT보다 더 우수한 글을 생성한다는 Fig 5 (a)의 결과를 뒷받침한다.
■ 그리고 이 task에서는 iterative-refine 방식이 더 효과적이었다. IO coherence score를 6.19에서 7.67로, ToT coherence score를 7.56에서 7.91로 향상시켰다.
■ 저자들은 이를 ToT framework 안에서 thought generation의 제3의 방식으로 볼 수 있다고 언급한다. 즉, 기존 thought generation은 (1) i.i.d. sampling (2) sequential proposal 두 가지였는데, 여기에 더해 (3) 기존 thought를 iterative-refine하여 새 thought를 만드는 방식도 하나의 대안으로 볼 수 있다는 것이다.
4.3 Mini crosswords
■ Game of 24와 Creative Writing에서 ToT는 비교적 얕다. final output에 도달하는 데 최대 3번의 thought steps만 필요하다. 그래서 이번에는 mini crosswords라는 더 깊고 복잡한 탐색 문제에서 ToT를 평가한다.
■ LM 대신 대규모 retrieval를 활용하는 specialized NLP pipelines을 사용하면 crosswords을 쉽게 풀 수 있다. 다만 이 실험의 목적은 검색 전용 시스템이 아니라, LM이 스스로 thought를 생성하고 자체 평가를 바탕으로 탐색을 수행할 수 있는 general problem solver인지 검증하는 데 있다.
Task Setup
■ 5 x 5 mini crosswords 게임 156개가 포함된 GooBix에서 데이터를 수집했다. 인접한 게임끼리는 단서가 비슷한 경우가 많아서 테스트셋은 간격을 두고 뽑았다. 구체적으로 1, 6, ... 91, 96번 게임 20개를 테스트에 쓰고, 136, 141, 146, 151, 156번 게임을 프롬프트의 예시로 사용한다.
■ 각 task의 입력은 가로 단서 5개, 세로 단서 5개이고, output은 5 x 5 = 25글자의 보드 전체이다. 즉, 퍼즐 전체를 채워야 한다. 그리고 세 가지 수준의 성공률로 평가를 수행한다: 25개 글자 중 얼마나 맞았는지, 10개 단어 중 얼마나 맞았는지, 퍼즐 전체를 다 맞혔는지
Baselines
■ IO prompt에는 input-output pairs 예시 5개를 넣는다. CoT prompt에는 여기에 더해 가로 단어 5개, 세로 단어 5개를 차례로 채워가는 intermediate reasoning을 예시로 보여준다.
■ IO, CoT 모두 10번 샘플링해서 평균 성능을 계산한다.
ToT Setup
■ mini crosswords에서는 DFS(Algorithm 2)를 사용한다. 이유는 이 문제가 앞의 두 task보다 훨씬 더 깊은 탐색을 요구하기 때문이다. 현재 state에서 가장 유망해 보이는 다음 단어 단서를 계속 깊게 탐색하다가, 더 이상 유망하지 않다고 판단되면 부모 state로 backtrack해서 다른 thought를 시도한다.
■ 저자들은 탐색이 너무 커지는 것을 막기 위해, subsequent thoughts은 이미 채운 단어나 글자를 변경하지 못하도록 제한했다고 한다. 이렇게 하면 ToT의 intermediate step 수가 최대 5 + 5 = 10단계가 된다.
Results

■ 다른 단서들을 시도해보거나, 결정을 변경하거나, backtrack 메커니즘이 전혀 없는 IO와 CoT는 word-level success가 16% 미만으로 저조한 성능을 보이는 반면, ToT는 word-level success 60%를 달성하고 20개 게임 중 4개를 완벽히 해결했다.
5. Limitations
■ ToT는 LLM이 더 신중하게 의사결정하도록 만들 수 있지만, 기존의 IO, CoT보다 많은 비용이 필요하다. 왜냐하면 thought을 여러 개 생성하고, state 평가 수행, BFS/DFS로 여러 노드 탐색하며 때로는 backtracking까지 수행해야 하기 때문이다.
■ 즉, IO나 CoT처럼 한 방향으로 쭉 생성하는 방식보다 API 호출 수, 토큰 수, 시간, 비용이 더 많이 든다.
■ 다만, ToT는 모듈식 구조이기 때문에 성능과 비용 사이의 타협점을 조절할 수 있다. 예를 들어 breadth를 줄이거나, state evaluation 횟수를 줄이거나, shallow search만 하거나, 더 작은 LM을 쓰는 식으로 비용을 낮출 수 있다.
