■ LLM은 텍스트 요약 성능이 뛰어나며, 단순한 summary을 넘어 잘 구조화된 rationales을 생성할 수 있다. 이러한 rationales은 더 작은 모델(~1B)이 더 나은 summary를 생성하도록 유도하는 데 사용될 수 있다.
■ 그러나 70B 이상의 모델에서는 비용 문제로 제한된 환경에서는 이를 활용하기 어렵다. 게다가 이러한 structured rationales을 LLM에서 SLM으로 증류하는 것은 여전히 어려운 과제로 남아 있다.
■ 이를 해결하기 위해, 논문에서는 "LLM-based Structured Rationale-guided Multi-view Weak-gated Fusion framework (LSR-MWF)"를 제안한다.
1. Introduction

■ Fig 1에서 볼 수 있듯이, LLM은 document로부터 Essential Aspects (EA), Associated Sentences (AS), Triple Entity Relations (TER)로 구성된 high-quality structured rationales을 생성할 수 있다.
■ 이러한 rationales은 Chain-of-Thought (CoT)와 유사하게 작동하여 SLM이 더 나은 summary를 생성하도록 유도하는 데 사용될 수 있다.
■ 그러나 70B 이상의 파라미터를 가진 LLM의 비용 문제는 자원이 제한된 환경에서 사용하기 어렵다.
■ 그리고 rationale extraction, rationale selection 방법과 이것들을 어떻게 학습시킬지, 이러한 structured rationales을 LLM에서 SLM으로 효과적으로 증류하는 것은 어려운 문제로 남아 있다.
■ abstractive summarization은 긴 텍스트를 간결하고 정보가 풍부한 요약문으로 압축하는 task이다.
■ 기존 방법들은 주로 소스 문서의 전반적인 내용에만 초점을 맞추고, 문서가 지닌 계층적 구조 정보는 충분히 고려하지 못했다. 그 결과 요약문의 품질이 떨어지는 경우가 많았다.
■ 소스 문서의 계층적 특성을 인식하기 시작하면서 최근 연구들은 문서의 핵심 주제를 추출하여 structured rationales를 생성하는 데 있어 LLM이 큰 잠재력을 지니고 있음을 보여주고 있다.
■ LLM의 structured abstractive summarization capabilities을 SLM에 전수하여 성능과 해석 가능성을 동시에 향상시키기 위해, 논문에서는 LSR-MWF라는 새로운 프레임워크를 제안한다.
■ LSR-MWF의 전체 프로세스를 간략히 정리하면 (1) LLM을 통한 documents의 structured rationales 탐색 (2) best rationales 선별 (3) local small model training이다.
- (1)은 LLM-based Structured Rationale-guided (LSR) sub-framework를 기반으로 LLM이 document에서 EA, AS, TER을 발견하도록
- (2) high-quality structured rationales을 선별하기 위해 multi-step summary generation evaluation strategy를 사용하고
- (3) Multi-view Weak-gated Fusion (MWF) sub-framework를 사용하여 small model을 학습시킨다.
2. Related Work
LLMs for Abstractive Summarization
■ 수십억 개의 파라미터를 가지고 방대한 텍스트 코퍼스로 학습된 LLM들은 abstractive summarization tasks에서 뛰어난 성능을 보여준다. 특히, 이러한 LLM들의 성능은 step-by-step reasoning을 통해 가이드될 때 더욱 향상될 수 있다.
■ 그러나 이러한 인상적인 성능에도 불구하고, LLM 사용에 요구되는 비용이 제약으로 작용한다. 또한, LLM API를 사용할 때 개인정보 보호 문제도 있다.
■ 이러한 LLM의 비용 및 개인정보 보호 측면의 한계는 로컬 환경에서 실행되는 SLM의 필요성으로 이어진다.
■ abstractive summarization에서 LLM의 reasoning capabilities을 활용한 시도들은 헤드라인 생성을 위해 태그의 품질을 높이는 데 사용하거나, LLM이 생성한 aspect-triple rationales을 활용하여 SLM의 요약 품질을 개선시켰다.
■ 그러나 기존 방법들은 LLM의 능력을 온전히 가져온 것이 아니다. 여전히 LLM의 포괄적인 추출 및 생성 능력을 SLM으로 완전히 transfer시키는 데는 실패하고 있다.
Knowledge Distillation and Interpretability in Abstractive Summarization
■ knowledge distillation techniques은 larger model이 가지고 있는 specialized knowledge을 추출하여 smaller model을 특정 tasks에 맞게 조정하는 것을 목표로 한다.
■ abstractive summarization tasks에서 extractive summarization과 abstractive summarization에 초점을 맞추고 knowledge distillation을 활용해 summary generation의 품질을 향상시킨 연구들이 있다. 그러나 이들의 접근법은 해석 가능성(interpretability)가 부족했다.
■ 모델의 복잡성이 증가함에 따라 모델의 해석 가능성이 점점 더 중요해지고 있다.
■ 모델 해석 가능성을 높이기 위한 방법으로 rationales generation techniques이 등장하기 시작했으며, 최근에는 LLM이 생성한 structured rationales을 활용하여 small model의 성능과 투명성을 향상시키고 있다.
■ 그러나, abstractive summarization에서 LLM의 포괄적인 extraction 및 generation capabilities은 여전히 충분히 연구되지 않았다.
■ 이에 저자들은 LLM의 reasoning abilities을 더 깊이 파고들 수 있는 rationale generation method를 정교화하고, structured information을 보다 포괄적으로 활용하기 위한 방법으로 LSR-MWF를 제안한다.
3. Methodology
Overview

■ LLM의 문서 요약 능력을 SLM로 transfer하는 LSR-MWF의 전체 아키텍처는 Fig 2에서 볼 수 있듯이, 세 가지 구성 요소로 이루어져 있다: LLM-based Structured Rationale Digging, Best Rationale Selection, 그리고 Multi-view Weak-gated Fusion Small Model Training
Step 1: LLM-based Structured Rationale Digging
■ 먼저 LLM의 강력한 extraction 및 generation capabilities과 맞춤형 prompt templates을 활용하여 source document와 ground-truth summary 사이에 존재하는 잠재적인 추론 과정, 즉 "structured rationale"을 광범위하게 탐색한다.
■ 이 탐색 과정은 EA, AS, TER이라는 세 가지 서로 다른 관점의 발굴을 통해 진행되며, 이는 subsequent three tasks의 요구사항에 따라 유도된다.
- 논문에서는 EA, AS, TER을 보석(gem)에 빗대어 표현한다.
Gem 1: Essential Aspect (EA)
■ EA는 source document에서 추출된 topic words(단, summary sentence에 대응되는) \( a_{1 \sim n} \)으로 정의된다.
Gem 2: Associated Sentence (AS)
■ AS는 document 내에서 EA와 가장 관련성이 높은 sentences \( s_{1 \sim n} \)
Gem 3: Triples Entity Relation (TER)
■ TER은 AS에서 추출된 structured triple entity relations \( r^*_{1 \sim m} = \langle s|r|o \rangle_{1 \sim m}, (m \ge n) \)로 정의되며, 이는 subjects \(s_{1 \sim m} \), relations \( r_{1 \sim m} \), objects \( o_{1 \sim m} \)을 포함한다.
Task 1: EA Extraction
■ 먼저 document \( D \)와 \( D \)에 대응되는 ground-truth summary \( S^* \)에서 EA를 추출하여, set \( A = \{a_1, a_2, \dots, a_n\} \)을 얻는다.
■ \( |S^*| \)가 \( S^* \)의 문장 개수라고 할 때, 이에 대한 식은 다음과 같다.

- \( S^* \)의 각 문장(\( s^*_i \))마다 하나의 topic word(\( a_i \))를 추출한다.
- \( D \)와 현재 보고 있는 \( i \)번째 요악 문장 \( s^*_i \), 그리고 이전에 추출된 topic word들 \( a^{<i} \)이 주어졌을 때, 현재 문장의 topic word \( a_i \)가 무엇일지 계산한다. - 이렇게 각 \( a_i \)는 \( D \)와 \( s^*_i \), 그리고 이전에 추출된 \( a^{<i} \)에 조건부 확률로 모델링된다. 이는 문서와 ground-truth summary와 이전 EA의 맥락을 고려하는 것이다.
Task 2: AS Extraction
■ 추출된 EA가 주어졌을 때, \( D \)에서 AS를 추출하여 set \( S = \{s_1, s_2, \dots, s_n\} \)를 만든다.

- 각 AS \( s_i \)는 앞서 추출한 EA \( a_i \)와 \( D \), \( s^*_i \) 그리고 이전 AS \( s^{<i} \)에 조건부 확률로 정의된다. 즉, EA와 가장 관련성이 높은 원본 문장을 찾는 것이다.
Task 3: TER Extraction
■ 추출된 AS를 바탕으로, 각 \( s_i \)에서 그에 상응하는 TER을 추출하여 \( R = \{r^*_1, r^*_2, \dots, r^*_m\} \)을 얻는다.

- \( s_i \)를 활용하여, 그 안에 포함된 관계들을 삼중항(\( r_i \)) 형태로 변환한다.
Step 2: Best Rationale Selection
■ 각 training sample에 대해, 추출된 structured rationales의 유일성을 보장하기 위해 LLM의 temperature 파라미터 \( \tau \)를 0으로 설정한다.
■ multi-step summary generation evaluation strategy을 사용하여, multiple sub-summaries \( S^{mul} \)과 total summary \( S^{tol} \)을 생성한다.
Task 4: Multiple Sub-summaries Generation
■ document \( D \)가 주어졌을 때, LLM을 활용하여 각 structured rationale에 대한 summary를 생성한다. 이렇게 생성된 summary를 sub-summary라고 부른다. 최종적으로 multiple sub-summaries의 set \( S^{mul} \)을 얻는 것이 목표이다.
■ structured rationales \( R^* = \{(A_i, S_i, R_i)\}_{i=1}^n \)에 대해 LLM을 사용하여 sub-summary를 얻는 식은 다음과 같다.

- structured rationale \( r^*_i \)에 대해 LLM을 사용하여 sub-summary를 생성한다.
- 각 \( r^*_i \)는 \( D \)와 이전까지 생성된 sub-summary들 \( s^{mul, <i} \)와 결합되어 하나의 sub-summary \( s^{mul}_i \)를 생성한다. structured rationale별로 sub-summary를 생성하는 것이다.
Task 5: Total Summary Generation
■ 생성된 multiple sub-summaries \( S^{mul} \)을 바탕으로, LLM을 사용하여 이를 더 압축하여 더 total summary \( S^{tol} \)을 얻는다. 이에 대한 식은 다음과 같다.
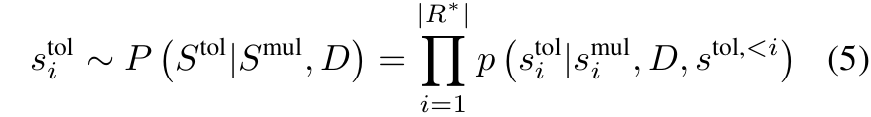
■ 그런 다음, \( S^{mul} \)과 \( S^{tol} \)에 대해 \( \text{ROUGE}_N \) scores를 계산한다.
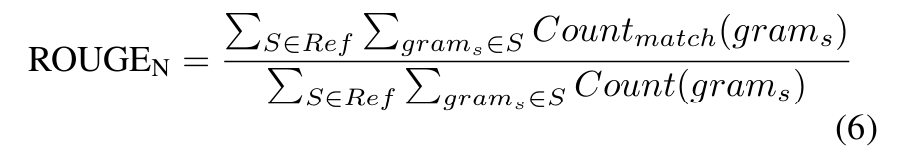
- 생성된 summary와 reference summary 간의 n-gram 기반 유사도를 측정하는 ROUGE 점수이다.
- reference summary에 있는 n-gram들이 생성된 summary에 얼마나 포함되어 있는지를 비율로 계산한다. 분모는 전체, 분자는 매칭된 개수이다.
■ abstractive model validation을 위해, 이전 연구들이 사용한 평가 방법을 따라 structured rationales의 quality scores를 계산하기 위해 CNNDM dataset에는 식 (7)을, XSum dataset에는 식 (8)을 각각 사용한다.

- 식 (7)은 CNNDM dataset에서 structured rationales의 품질을 평가하기 위해 설계된 점수이다.
- \( \text{ROUGE_1} \)과 \( \text{ROUGE_2} \)가 높을수록 분수 값이 커지므로, 이때의 \( Score_1 \)은 값이 작아진다.
- 식 (8)은 XSum dataset에서 사용되는 품질 점수로, \( \text{ROUGE_1} \), \( \text{ROUGE_2} \), \( \text{ROUGE_3} \)의 산술 평균을 1에서 뺀 값이다. 이 점수도 값이 낮을수록 품질이 좋음을 의미한다.
- 식 (8)에서는 \( \text{ROUGE_3} \)을 사용하여 더 긴 문맥을 고려한다.
■ 점수를 매긴 후, 점수가 낮은 training examples은 버린다. (실험에서 \( Score_1 \)과 \( Score_2 \)의 임곗값을 각각 85, 65로 사용한다)
■ step 1, 2를 통해 최종적으로 두 개의 새로운 datasets을 얻는다. (Table 1의 *로 표현된 datasets)

Step 3: Multi-view Weak-gated Fusion Small Model Training
■ step 3는 Multi-view weak-gated Fusion (MWF) sub-framework를 사용하여 SLM을 학습시키는 방법에 대한 내용이다.
■ 이 프레임워크는 LLM에서 추출한 structured rationales을 SLM이 효과적으로 학습할 수 있도록 modules을 추가하고 활용한다.
- 논문에서는 EA, AS, TER을 각각 \( \langle A \rangle \), \( \langle S \rangle \), \( \langle R \rangle \)
로 표기한다.
■ 그 후, weak-gated mechanism을 통해 modules에서 출력된 특징들을 original abstractive model과 통합한다.
Multi-view Hierarchical Aligning of Structured Rationales
■ structured rationales에 대한 세 가지 viewpoints에 대해 각각 모듈을 구축한다: essential aspects module, associated sentences module, triple entity relations module
■ 이 모듈들은 structured rationales을 학습하기 위해 추가된 모듈들이다.
■ 모든 모듈은 Transformer 아키텍처를 기반으로 하며, 모든 모듈에 대한 input은 동일한 소스 문서 \( D \)이다.
■ 각 모듈은 (Fig 2에서는 단순화를 위해 생략된)공유 임베딩 레이어를 통과한 후, 각각 자신만의 self-attention 레이어를 통해 input \( D \)를 처리하여 의미적 내용을 더 풍부하게 만든다.
■ 이 모듈들이 출력하는 semantic features인 \( A_{\text{out}} \), \( S_{\text{out}} \), \( R_{\text{out}} \)이 LLM이 추출한 \( \langle A \rangle \), \( \langle S \rangle \), \( \langle R \rangle \)과 밀접하게 정렬되도록 만드는 것이 목표이다.
■ 이 정렬을 위해, 사전에 abstractive model의 인코더를 사용하여 \( \langle A \rangle \), \( \langle S \rangle \), \( \langle R \rangle \)를 인코딩한다. 그리고 인코딩된 \( \langle A \rangle \), \( \langle S \rangle \), \( \langle R \rangle \)에 average pooling을 적용한다.
■ 그리고 각 모듈의 출력 \( A_{\text{out}} \), \( S_{\text{out}} \), \( R_{\text{out}} \)도 동일하게 average pooling을 적용한 다음,
■ 마지막으로, average pooling이 적용된 \( A_{\text{out}} \), \( S_{\text{out}} \), \( R_{\text{out}} \)과 \( \langle S \rangle \), \( \langle R \rangle \) 사이의 코사인 유사도를 계산한다.
- \( \text{Cosine loss} = sim \langle x, y \rangle = (xy) / (||x|| ||y||) \)이다. 예를 들어 \( \mathcal{L}_{\text{EA}} \)는 \( \mathcal{L}_{EA} = sim \langle A_{out}, \langle A \rangle \rangle \)와 같다.
- 이러한 정렬 과정의 목적은 SLM의 내부 표현이 LLM이 추출한 구조적 지식(EA, AS, TER)과 의미적으로 일치하도록 강제하는 것이다.
Features Fusion through Weak-gated Mechanism
■ 이 메커니즘은 각 디코딩 계층에서 다양한 관점(EA, AS, TER)에서 추출된 semantic features의 융합 정도를 동적으로 조절하기 위해 사용된다.
■ \( A_{\text{out}} \), \( S_{\text{out}} \), \( R_{\text{out}} \)이 각각의 weak-gated network에 입력된 후, \( L \)번 복제된다. 여기서 \( L \)은 abstractive model의 디코더의 레이어 수이다.
■ abstractive model의 인코더로부터 인코더의 출력 \( X^{en} \)이 주어지면, 디코딩 단계에서 각 디코더 레이어는 다음과 같은 연산을 수행한다.
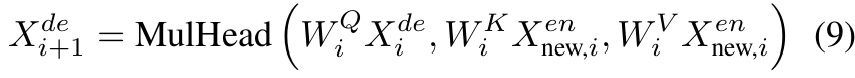
- 식 (9)는 cross-attention 과정을 나타낸 것이다.
■ 여기서 \( X^{en}_{\text{new}, i} \)는 abstractive model의 encoder output과 structured rationales 사이의 features fusion 결과이며, \( i \in L \)일 때 다음과 같다.

- 모델 인코더의 output \( X^{en} \)에 \( A_{\text{out}} \), \( S_{\text{out}} \), \( R_{\text{out}} \)에 대한 벡터들을 더한 것이다.
- \( g^A_i \), \( g^S_i \), \( g^R_i \)는 [0, 1]의 스칼라 값으로 각 정보(EA, AS, TER)에 대한 가중치로 작동한다. 이 가중치는 학습 가능한 파라미터로, 이를 통해 모델이 \( i \)번째 레이어에서 EA, AS, TER 정보가 얼마나 필요한지를 스스로 결정한다.
■ \( g^A_i \)는 \( \langle A \rangle \)와 관련된 semantic feature를 통합하기 위해 설계된 \( i \)번째 레이어의 weak-gated unit이다. 그 값의 범위는 [0, 1]이다. 이는 학습 중에 적응적으로 업데이트될 수 있는 연속적인 값이다. \( g^S_i \)과 \( g^R_i \)의 역할도 \( g^A_i \)와 같다.
- semantic features이 각각의 weak-gated network에 입력된 후, \( L \)번 복제된다고 하였다. 이는 각 디코더 레이어마다 별도의 게이트 가중치를 적용할 수 있도록 구조화한 것으로 보인다.
- \( i \in L \)일 때, 가중치로 작동하는 \( g^A_i \), \( g^S_i \), \( g^R_i \)는 다른 층에서 다른 값으로 학습되어 모델이 디코딩 단계별 혹은 \( i \)번째 디코딩 레이어 레이어에서 중요한 feature에 의존하도록 만들 수 있다.
- \( g^A_i \), \( g^S_i \), \( g^R_i \)는 학습 가능한 파라미터로 [0, 1]의 값(sigmoid와 같은 함수를 사용해 이 범위를 유지할 수 있을 것이다)을 가지므로, EA 정보가 더 중요하다면 \( g^A_i \) 값이 높아지고, TER 정보가 더 중요하다면 \( g^R_i \) 값이 높아질 것이다.
■ 고정된(즉, 학습으로 업데이트되지 않는) ReLU activation function을 게이트로 사용한 이전 연구들과 달리, 저자들은 게이트를 adaptively하게 학습되는 가중치 네트워크 파라미터로 취급하며, 이를 "weak-gated unit"이라고 부른다.
■ 서로 다른 레이어에서 weak-gated unit의 값을 관찰함으로써, 각 디코딩 단계에서 모델이 특정 feature(\( A_{\text{out}} \), \( S_{\text{out}} \), \( R_{\text{out}} \) 중 어떤 것에 더 높은 가중치가 할당되었는지)에 얼마나 의존하는지(즉, model의 의사결정 과정)에 대해 확인할 수 있다.
Training Objective of Loss Function
■ abstractive model의 생성 능력을 보존하고 향상시키기 위해, sequence-level의 cosine loss \( \mathcal{L}_{\text{EA}} + \mathcal{L}_{\text{AS}} + \mathcal{L}_{\text{TER}} \)와 token-level의 cross-entropy loss \( \mathcal{L}_{cross-entropy} \)를 결합한 loss function을 사용한다.

- abstractive model의 기본적인 생성 능력을 보존하기 위해 \( \mathcal{L}_{cross-entropy} \)를 사용하고, 세 가지 관점(EA, AS, TER)에 대한 정렬로 생성 능력을 향상시키기 위해 \( \mathcal{L}_{\text{EA}} + \mathcal{L}_{\text{AS}} + \mathcal{L}_{\text{TER}} \)를 사용하는 것이다.
- \( \gamma_1 \)과 \( \gamma_2 \)는 하이퍼파라미터이다.
■ 주목할 점은, sequence-level의 cosine loss와 token-level의 cross entropy loss가 상호 보완적으로 작용한다는 것이다.
■ cosine loss가 전체적인 structured rationales을 잘 포착했는지 평가하고, cross entropy loss는 일종의 정규화로 작용하여 모델이 전체 시퀀스에 걸쳐 균형 잡힌 확률 분포를 할당할 수 있도록 만들기 때문이다.
- cross entropy loss만 사용하면 생성된 요약문은 그럴싸하지만 핵심 주제나 논리 구조가 빈약할 수 있다.
- cosine loss만 사용하면, 주제는 파악하지만 문법적으로 말이 안 되는 문장을 만들 수 있다.
- 두 가지 loss를 같이 사용해서, 의미론적으로 구조화된 내용을 생성하는 능력(cosine loss를 통해)을 키울 때, 정확한 문장을 잘 생성(cross entropy loss를 통해)하도록 만들 수 있다.
4. Experiments
Datasets and Metrics
■ 널리 사용되는 두 가지 abstractive summarization datasets CNN/DailyMail (CNNDM)과 XSum을 사용하여 실험을 수행한다. 이 두 데이터셋은 텍스트 길이와 추상화 수준이 서로 다르므로, 저자들이 제안한 방법론의 일반화 능력을 평가할 수 있다.
■ original datasets에 대해 먼저 전처리를 수행하여 비어 있는 documents나 summaries을 제거한다.
■ 그 후 document-summary pairs은 두 단계의 처리 과정(식 (7)과 (8))을 거쳐 필터링된다. 저자들은 \( Score_1 \)과 \( Score_2 \)의 threshold 값을 각각 85와 65로 설정하였다.
- CNNDM과 XSum에 대한 처리 전후의 데이터셋 크기는 Table 1에서 볼 수 있다.
■ 결과 요약문의 품질을 측정하기 위해 ROUGE를 평가지표로 사용한다. 구체적으로 정답 요약문과 생성된 요약문 사이의 ROUGE-1 (R-1), ROUGE-2 (R-2), ROUGE-L (R-L)의 F1 scores을 사용한다.
■ 추가로, 생성된 요약문과 정답 요약문 사이의 의미적 유사도를 측정하기 위해 BERTScore (BS)를 사용한다.
Setup
■ LLM으로 Llama3-70B를 사용하고, origin abstractive model로 BART-large를 사용한다. LSR-MWF의 전체 파라미터 수는 439M이다.
■ learning rate scheduling과 Adam optimizer를 사용한다. 학습률은 \( 2 \times 10^{-3} \) min(\( \text{step}^{-0.5}, \text{step} \cdot \text{warmup}^{-.15} \))로 계산된다. 여기서 step은 업데이트 횟수를 의미하며, warmup은 10,000으로 설정했다.
- 초기에는 \( \text{step} \cdot \text{warmup}^{-.15} \) 값이 더 작지만, warmup 이후(10,000 스텝 이후)에는 \( \text{step}^{-0.5} \) 값이 더 작아진다. 그러므로 warmup 이후에 학습률은 스텝 수의 역제곱근에 비례하여 감소하게 된다.
■ CNNDM의 경우, initial weak-gated units 값은 모두 0.02로 설정하고 \( \gamma_1 = 0.6, \gamma_2 = 0.4 \)로 설정했다.
■ XSum은 initial weak-gated units 값은 모두 0.01, \( \gamma_1 = 0.7, \gamma_2 = 0.3 \)으로 설정했다.
- XSum은 CNNDM보다 훨씬 짧은 요약을 요구하며, 추상화 수준이 더 높다. XSum의 요약은 원문과 겹치는 n-gram이 훨씬 적다. 즉, 원문에 없는 어휘나 문장 구조를 사용하여 새로 쓰는 추상적 방식이 필요하다.
- XSum이 좀 더 창의적인 생성을 요구하므로, CNNDM보다 낮은 \( \gamma_2 \) 값을 설정해 구조적 제약을 조금 더 약하게 둔 것으로 보인다.
Results

■ structured rationales을 활용했을 때, LSR-MWF는 두 데이터셋 모두에서 거의 모든 베이스라인들을 능가하는 뛰어난 요약 능력을 보여준다. 즉, structured rationales을 사용하는 것이 더 높은 품질의 요약문을 생성하는 데 효과적이다.
■ 주목할 점은 LSR-MWF처럼 structured rationales을 활용하는 TriSum보다 더 나은 성능을 보였다는 것이다. 이는 저자들의 설계(EA, AS, TER 모듈, weak-gated fusion 등)가 더 효과적이었음을 시사한다.
Ablation Study

■ Table 3은 "gems"과 그에 해당하는 모듈을 제거했을 때 모델 성능에 미치는 영향을 확인한 결과이다.
■ CNNDM에서 TER에만 의존하는 것(w/o EA&AS)은 AS만 사용하는 것(w/o EA&TER)보다 좋은 성능을 내지 못한다는 것을 볼 수 있다.
■ 반대로 XSum에서는 TER만 사용하는 것이 AS만 사용하는 것보다 더 큰 이점을 보였는데, 이러한 결과에 대해 저자들은 XSum 요약문의 더 높은 추상화 수준에 기인한 것으로 추측한다.
- 저자들은 더 긴 요약문을 요구하는 CNNDM에서는 TER만으로는 부족하고, AS가 있어야 관계 정보를 제대로 활용할 수 있으며, XSum은 높은 추상화 수준을 요구하므로 AS보다는 TER만 사용해서 새로 조합하는 것이 유리하다고 주장한다.
■ 이러한 결과는 summarization task의 성격에 따라 필요한 구조적 정보의 종류가 다를 수 있음을 시사하며, 이 모든 요소들(EA, AS, TER)을 통합적으로 사용한(정확하게는 weak-gated 메커니즘으로 각 요소들의 중요도를 스스로 학습한) LSR-MWF가 최적의 성능을 냈음을 보여준다.
5. Analysis
Superiority of Weak-gated Mechanism

■ Table 4에서 볼 수 있듯이, weak-gated units의 가중치 초기화의 경우 지나치게 크거나 작은 값으로 설정하는 것은 바람직하지 않다.
■ Table 4에서 *로 표시된 0.020은 weak-gated units의 가중치를 고정된 값으로 설정하고 학습 중에 업데이트하지 않았을 때의 결과이다. 그렇지 않은 설정에 비해 모델 성능이 상당히 감소한 것을 볼 수 있다.
■ 이는 structured rationales을 abstractive model에 통합하는 과정에서, weak-gated units의 가중치를 adaptively and dynamically으로 변화하도록 학습시키는 것이 중요함을 보여준다. 즉, structured rationales은 항상 똑같은 비중으로 중요한 것이 아니라, 문맥에 따라 그 중요도가 달라짐을 시사한다.
Visualization of Weak-gated Mechanism

■ Fig 4는 세 가지 유형의 gems에 대해, LSR-MWF 학습 과정에서 weak-gated units의 가중치 변화를 나타낸 것이다.
■ CNNDM의 경우, 처음 6개 디코더 레이어에 해당하는 weak-gated units의 가중치 변동은 상대적으로 작으며 0.02에 가까운 값을 유지한다. 그러나 마지막 6개 레이어는 변동폭이 크다.
■ 그리고 TER의 weak-gated 가중치가 더 급격하게 변화하는 것을 볼 수 있다. 이에 대해 저자들은 TER이 높게 요구됨에 따라 가중치의 빠른 적응이 필요했기 때문이라고 추측한다.
■ XSum의 경우, 오직 마지막 4개 레이어의 weak-gated units만 변동을 보인다. 특히, 마지막 레이어의 weak-gated units은 EA, AS, TER 모두에서 급격한 변동을 보인다.
■ 이에 대해 저자들은 abstractive model의 마지막 디코더 레이어의 정보가 중요할 수 있으며, 이에 적응하기 위해 가중치가 빠르게 상승한 것으로 추측한다.
Study of Sequence-level and Token-level Loss
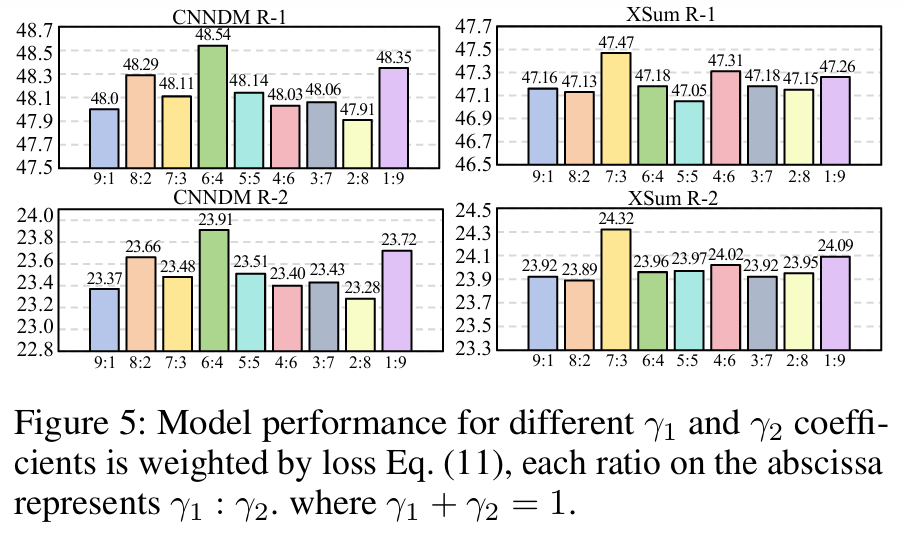
■ Fig 5는 CNNDM에 대한 \( \gamma_1 : \gamma_2 \)의 최적 비율이 6:4인 반면, XSum에 대한 최적 비율은 7:3임을 보여준다.
■ 이는 CNNDM이 sequence-level cosine loss가 더 적합하고, XSum은 token-level loss가 더 적합함을 시사한다. 이러한 차이는 XSum 요약문의 더 높은 추상화 수준에 기인한 것으로 보인다.
- XSum에서는 거의 새로운 문장을 생성해야 하므로, 구조적 제약보다는 자연스러운 문장 생성을 위한 토큰 단위 학습이 더 중요하다고 해석할 수 있다.
Case Study

■ Fig 3은 해리포터 대본 제작 예정 소식을 다룬 CNNDM의 예시이다.
■ 볼드체 처리된 Article은 BART가 기사를 요약한 것으로, 등장인물과 줄거리를 자세히 명시하고 있지만, 언제(ground truth summary의 2014)인지 그리고 어떤 맥락인지(공개 행사), 일부 핵심 정보를 누락했다.
■ 저자들의 방법론을 적용한 결과를 보면, EA에서 시작하여 AS로, 최종적으로 TER로 나아가는 모습을 볼 수 있다. (Structured Rationales)
- EA: "Harry Potter Play", "Play Development"라는 키워드를 먼저 잡은 다음,
- AS: AS는 문서에서 EA와 관련성이 높은 "The play, which will go into development in 2014"라는 문장을 근거로 삼은 것을 볼 수 있다
- TER: 그리고 <The play # will go into development # 2014>라는 확실한 관계식을 추출했다.
'자연어처리 > Reasoning' 카테고리의 다른 글
| [ToT] Tree of Thoughts: Deliberate Problem Solving with Large Language Models (0) | 2026.04.11 |
|---|---|
| Aligning Large and Small Language Models via Chain-of-Thought Reasoning (0) | 2026.01.28 |
| Orca 2: Teaching Small Language Models How to Reason (0) | 2026.01.26 |
| Teaching Small Language Models to Reason (0) | 2026.01.24 |
| ThinkSLM: Towards Reasoning Ability of Small Language Models (0) | 2026.01.22 |
