■ CoT prompting은 LLM의 reasoning 능력을 향상시키며, 다양한 datasets에서 SOTA 결과를 달성했다. 그러나 이러한 추론 능력은 적어도 수백억 개의 파라미터를 가진 모델에서만 나타나는 emergent property로 여겨지고 있다.
■ 논문에서는 knowledge distillation을 통해 이러한 추론 능력을 더 작은 모델로 transfer하는 것이 가능한지 실험을 통해 확인한다.
[2212.08410] Teaching Small Language Models to Reason
Teaching Small Language Models to Reason
Chain of thought prompting successfully improves the reasoning capabilities of large language models, achieving state of the art results on a range of datasets. However, these reasoning capabilities only appear to emerge in models with a size of over 100 b
arxiv.org
1. Introduction
■ CoT prompting은 LM이 reasoning task를 일련의 intermediate steps로 분해하도록 유도한다.
■ Manual CoT paper에서는 이러한 CoT prompting이 commonsense, symbolic, mathematical reasoning datasets 전반에 걸쳐 LLM의 task accuracy를 상당히 증가시킨다는 것을 보여주었다.
■ 여기서 LLM은 PaLM 540B, GPT-3 175B, 또는 UL2 20B와 같이 적어도 수백억 개의 파라미터를 가진 모델을 의미한다.
■ 더 작은 LM의 reasoning capabilities은 CoT prompting으로 향상되지 않으며, 대부분 비논리적인 CoT를 생성한다. 주목할 점은, CoT prompting이 10B 미만의 파라미터를 가진 모델의 accuracy를 오히려 감소시킨다는 것이다.
■ Manual CoT에서는 이를 semantic understanding이나 symbolic mapping과 같은 abilities이 더 큰 scales에서만 나타나는 emerging한 현상이기 때문이라고 주장한다.
■ 이에 저자들은, 그렇다면 "LLM의 reasoning capabilities이 fine-tuning을 통해 더 작은 LM으로 transferred될 수 있는가"를 확인하고자 한다.
■ PaLM 540B와 GPT-3 175B로부터 각각 11B, 3B, 220M 파라미터를 가진 T5 XXL, XL, Base와 같은 다양한 크기의 smaller language model T5로의 "CoT knowledge distillation"을 수행한다.
■ 그 결과, CoT knowledge distillation이 teacher model과 관계없이 arithmetic, commonsense, symbolic reasoning dataset 전반에서 task performance를 향상시킨다는 것을 보여준다.
2. Related Work
■ Manual CoT에서는 input 앞에 2~8개의 CoT reasoning exemplars을 붙여 LM이 해당 예시와 동일한 방식을 따르도록 유도하여, GSM8K와 같은 datasets에서 SOTA 성능을 보여주었다.
■ self-consistency는 CoT prompting에서 majority voting을 통해 task accuracy를 더욱 향상시킬 수 있음을 보여주었다.
■ self-consistency는 모델의 decoder에서 CoT reasoning paths을 샘플링한 뒤 majority voting을 통해 가장 consistent한 path를 선택한다.
■ 그리고 논문처럼 몇몇 연구들은 CoT student–teacher knowledge distillation에 초점을 맞춘 방법들을 제안하고 있다.
■ 논문에서는 선행 연구들과 대조적으로, 더 많은 teacher models을 탐구하고 dataset size와 model size가 accuracy에 미치는 영향도 확인한다. 또한, GSM8K와 같은 datasets에서 선행 연구보다 더 높은 accuracy를 달성하였다.
3. Method
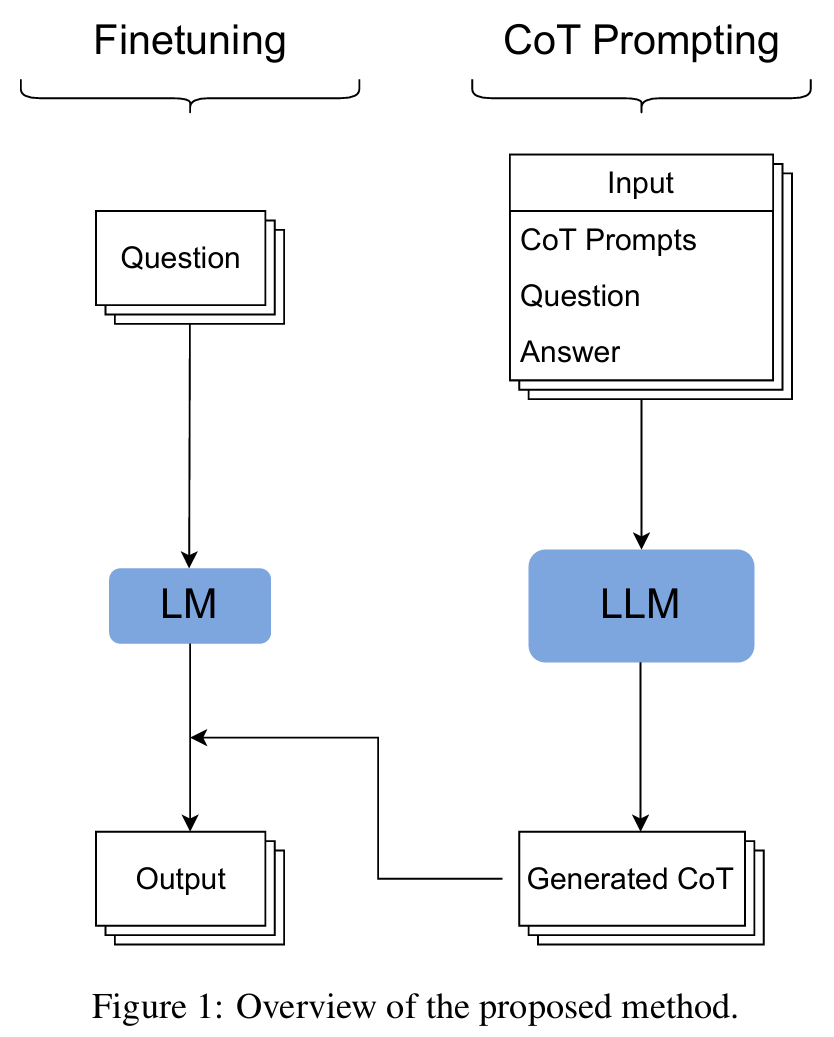
■ 논문에서는 CoT knowledge distillation을 위한 two-step pipeline을 제안한다. (Fig 1)
■ first step은 supervised dataset에 teacher model이 생성한 CoT reasoning을 생성한다.
■ 이때 high quality data를 생성하기 위해, CoT reasoning이 model scale에 따라 향상된다는 Manual CoT에 근거하여 PaLM 540B나 GPT-3 175B와 같은 LLM을 teacher로 사용한다.
■ 구체적으로, CoT를 생성하기 위해 teacher model에게 8개의 exemplars을 사용한 few-shot prompting을 수행한다.
■ 단, Manual CoT에서 제안한 prompts에 한 가지를 수정한다. model에게 question을 던진 후, CoT를 제공하기 전에 model에게 target을 제공하도록 유도하는 few-shot prompts을 사용한다.
■ 즉, 일반적인 방식(질문 -> 생각(CoT) -> 정답)과 다르게 "질문 -> 정답 -> CoT" 순서로 유도한다. 정답을 먼저 알려주고 풀이 과정을 쓰도록 하는 prompt를 model에게 보여주고, model이 이 guidance를 따라하도록 한 것이다.
■ 저자들은 이 setting을 사용한 이유로, 이러한 guidance를 LLM에게 제공했을 때 CoT 내의 사소한 mistakes이 correct되는 현상을 관찰했기 때문이라고 설명한다.
■ 마지막으로, student가 teacher로부터 bad examples을 배우는 것을 방지하기 위해, target answer를 기준으로 incorrect CoT를 모두 제거한다.
■ second step은 teacher forcing을 통해 student model을 finetuning하는 것이다. question이 input으로 사용되며, CoT와 answer이 target으로 사용된다.
■ 모델이 finetuning 중에 CoT를 생성하도록 학습되므로, 별도의 prompting이 필요하지 않다.
4. Experimental Setup
■ Manual CoT의 experimental setup을 따르며, arithmetic, commonsense, symbolic reasoning tasks에서 평가한다.
4.1 Benchmarks and Metrics
4.1.1 Arithmetic Reasoning
■ 사용한 math datasets은 GSM8K, MAWPS, ASDiv이다. GSM8K의 경우 official training 및 testing split을 사용하되, training data의 마지막 10%를 valid set으로 사용하며, MAWPS와 ASDiv의 경우 5-fold cross validation을 사용한다.
■ CoT 내의 target answer이 final answer과 일치하는지 확인하여 task accuracy를 측정한다. 추가로, CoT가 올바름에도 불구하고 모델이 산술적인 실수를 하는 경우를 고려하기 위해, 외부의 calculator가 주어졌을 때의 task accuracy도 측정한다.
■ external calculator는 생성된 output을 훑으며 방정식의 좌변을 재계산한다. 그런 다음, arithmetic mistakes이 계속 이어지는 것을 방지하기 위해 우변을 계산된 출력값으로 대체한다.
- 예를 들어, 모델이 '5 + 5 = 11. 11 * 2 = 22'라고 출력했다면, calculator는 먼저 '5+5'를 계산하여 '11'을 '10'으로 대체한다. 그리고 그 뒤의 subsequent 방정식에서도 '11'을 '10'으로 바꿔서 최종 결과 '20'을 계산한다.
4.1.2 Commonsense Reasoning
■ StrategyQA dataset을 사용하여 commonsense reasoning ability를 테스트한다. 단, 이 dataset은 official testing split가 없기 때문에, 처음 80%를 training data, 그다음 10%를 valid data, 마지막 10%를 test data로 사용한다.
- 저자들은 이 실험을 재현할 수 있도록 shuffle은 하지 않았다.
■ task accuracy는 앞서 언급한 방식과 동일하게 계산한다.
4.1.3 Symbolic Reasoning
■ last letter concatenation과 coinflip을 통해 symbolic reasoning ability를 테스트한다.
■ last letter concatenation에서는 문자열 내 각 단어의 마지막 글자를 연결하도록 모델에게 요청하고, coinflip은 던져진 동전의 상태를 tracking하도록 모델에게 요청한다. 그리고 동일한 방식으로 task accuracy를 측정한다.
■ out-of-distribution (OOD) examples에 대한 모델의 일반화 능력을 평가하기 위해, 길이가 2인 examples로 모델을 finetune하고, 길이가 3과 4인 시퀀스에 대해 평가한다.
4.2 Baselines and setup
■ teacher models로 PaLM 540B, GPT-3 175B를 사용한다. 이 teacher models은 섹션 3에서 설명한 대로 프롬프팅된다.
■ 다양한 크기의 T5 models을 student models로 사용한다. student models은 섹션 3에서 설명한대로 PaLM 540B 또는 GPT-3 175B가 생성한 CoT 데이터로 학습된다.
■ MAWPS와 ASDiv dataset에서는 5-fold cross validation으로 성능을 측정하고, 나머지 모든 datasets에 대해서는 training set의 10%를 valid set으로 사용하여 최적의 모델 체크포인트를 선택했다.
■ 아래의 Fig 2는 T5에 대한 input 예시이다.

5. Results
5.1 Arithmetic reasoning
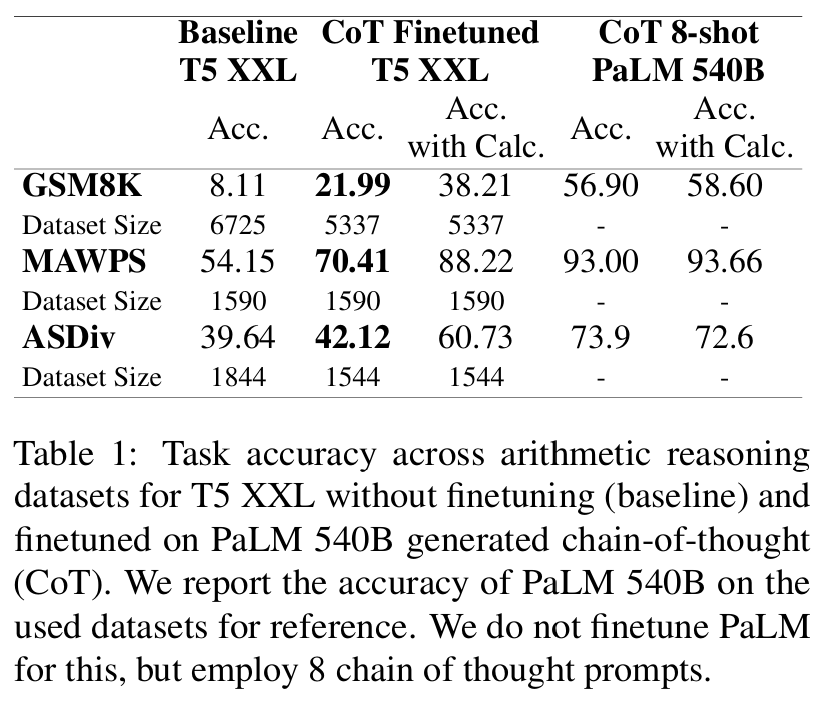
■ Table 1은 arithmetic reasoning benchmarks에서 external calculator가 있을 때와 없을 때의 task accuracy 결과이다. 저자들이 제안한 방법이 모든 datasets에 걸쳐 accuracy를 크게 향상시킨 것을 볼 수 있다.
■ 그리고 calculator가 주어졌을 때 달성한 accuracy는 8-shot PaLM 540B의 accuracy에 근접하며, 이는 수학적 연산 능력이 부족할 경우(예: 단순 small model), 성능 향상이 제한적임을 보여준다.
5.1.1 Ablation study on generating chain-of-thought data
■ CoT 생성 과정에서 LLM에게 target도 같이 제공하는 것이 유익한지(섹션 3) 확인하기 위해 ablation study를 수행했다.
■ GSM8K dataset에서 PaLM 540B가 target 없이 프롬프팅되었을 경우 accuracy는 59.98%였지만, 프롬프트에 target을 포함시켰을 때의 accuracy는 79.37% 였다고 한다.
■ 그러나 이러한 결과는 모델이 answer만 베낀 것일 수 있다.
■ 그래서 target 유무에 따라 생성된 CoT 간의 차이점에 대해 subset을 분석한 결과, target을 제공받은 모델은 풀이 과정 중간에 한 단계가 누락되었거나 틀렸던 CoT를 스스로 correcting했다고 한다.
5.2 Commonsense reasoning

■ StrategyQA의 경우, 1648 examples 중 1319개만을 사용하여 CoT finetuning을 수행했을 때 accuracy가 68.12%에서 71.98%로 향상된 것을 Table 3에서 볼 수 있다.
■ arithmetic reasoning datasets의 결과와 비교했을 때, 그 성능 향상 폭은 그리 크지 않다. 이는 StrategyQA dataset이 요구하는 factual knowledge가 모델에 부족하기 때문일 수 있다.
■ StrategyQA는 factual knowledge에 기반한 reasoning에 중점을 두고 있지만, smaller LM은 larger model에 비해 memorisation capacity가 작기 때문에 factual knowledge를 소유하고 있지 않을 가능성이 있다.
5.3 Symbolic reasoning
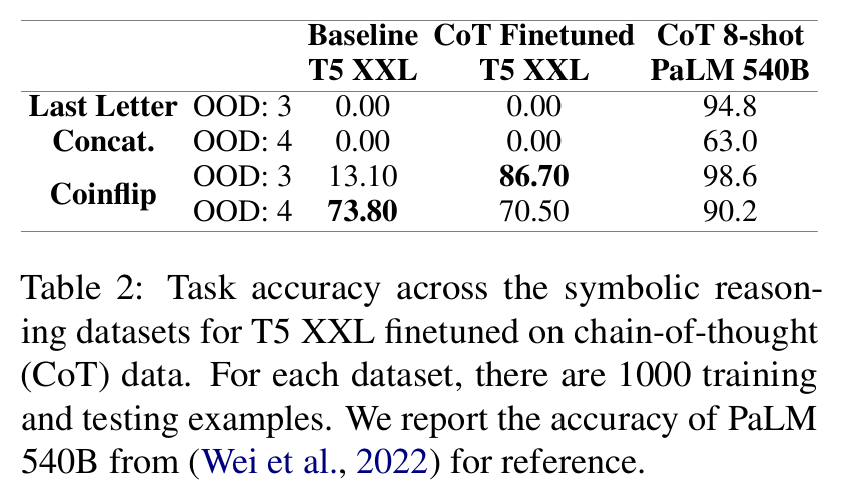
■ Table 2는 synthetic symbolic reasoning datasets에서 OOD generalization을 측정한 결과이다.
■ last letter concatenation은 traditional finetuning과 저자들이 제안한 method 모두 점수가 0이다. 즉, 더 긴 시퀀스 길이로 일반화하는 데 실패했다.
■ 단, coinflip에서는 일반화와 관련하여 정확도를 상당히 증가시켰다. (3회 던지기: 13.10 \( \rightarrow \) 86.70)
■ 그러나 4회 던지기에서는 오히려 베이스라인보다 성능이 저하된 것을 볼 수 있다. 저자들은 이러한 결과에 대해 small model이 긴 길이의 시퀀스를 제대로 파악하지 못했기 때문이라고 주장한다.
5.4 Replicating Results using different Teacher Models
■ GPT-3 175B라는 다른 teacher model을 사용했을 때, 저자들의 방법이 robust한지 실험하였다.
■ Table 3에서, GPT-3가 생성한 CoT 데이터로 T5 XXL을 finetune했을 때의 GSM8K와 StrategyQA에 대한 결과를 볼 수 있다. PaLM 540B뿐만 아니라 GPT-3 175B를 teacher로 사용해도 student의 성능이 향상된 것을 볼 수 있다.
■ 이는 저자들의 접근법이 특정 teacher model에 종속되지 않음을 보여주는 결과이다.
5.5 Ablation study on model size

■ Fig 3은 다양한 크기의 T5를 finetuning했을 때 달성된 performance gain을 나타낸 것이다.
■ T5 XXL보다 파라미터 수가 44배 적은 T5 Base가 CoT 데이터로 학습되었을 때, baseline T5 XXL의 성능에 필적하는 것을 볼 수 있다. 그리고 external calculator가 주어지면, baseline T5 XXL의 성능을 능가한다.
5.6 Ablation study on dataset size

■ Table 4는 무작위로 선택한 데이터의 단 4%와 20%만을 사용하여 T5 XXL을 finetuning했을 때 달성된 test accuracy 결과이다.
■ baseline의 accuracy (Table 3. 8.11%)와 비교했을 때, 단 20%의 examples만으로 11.22%의 accuracy를 달성하여 더 높은 데이터 효율성을 보임을 알 수 있다.