■ CoT prompting은 LLM이 complex reasoning tasks을 step-by-step 방식으로 해결하도록 유도함으로써 reasoning abilities을 강화한다.
■ 그러나 이러한 능력은 수십억 개의 파라미터를 가진 모델에서만 나타나며, smaller model scale, 즉 SLM에서는 이런 능력이 부족하여 complex reasoning을 수행하지 못하는 문제가 있다.
■ 많은 기업들이 동일한 family의 더 적은 파라미터를 가진 LLM을 출시했지만, 이러한 모델들은 CoT reasoning을 포함하여 original models의 reasoning capabilities을 보존하지 못하는 경향이 있다.
■ 논문에서는 larger LM에서 smaller LM으로 reasoning abilities을 aligning하고 transferring하는 방법을 제안한다.
Aligning Large and Small Language Models via Chain-of-Thought Reasoning - ACL Anthology
Aligning Large and Small Language Models via Chain-of-Thought Reasoning
Leonardo Ranaldi, Andre Freitas. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2024.
aclanthology.org
1. Introduction
■ 예를 들어, Llama-2 family의 SLM인 Llama-2-7b/13b와 같은 SLM들은 다양한 tasks에서 높은 기능을 발휘하지만, 이러한 SLM들은 CoT 프레임워크 하에서 프롬프트될 때 비논리적인 answer를 생성한다.
■ 논문에서는 LLM이 제공하는 demonstrations을 통해 Instruction-tuning을 수행함으로써, SLM에서 CoT reasoning을 가능하게 하는 방법 "Instruction-tuning-CoT"를 제안한다. 또한, teacher-student Instruction-tuning을 위한 "in-family alignment" 개념을 도입한다.
■ 그리고 in-family와 out-family alignment 중 어떤 것이 더 효과적인지 검증한다.
- 즉, student를 같은 계열의 teacher로부터 alignment하는 것(in-family alignment)이 다른 계열의 teacher로부터 alignment하는 것(out-family alignment)보다 효과적인지
■ 논문에서 다루는 target research questions은 다음과 같다.
- (1) demonstrations을 통한 Instruction-tuning은 students models의 reasoning abilities에 어떤 영향을 미치는가
- (2) CoT reasoning process를 포함한 demonstrations이 더 효과적인가
- (3) in-family teacher가 생성한 demonstrations은 student models 성능에 얼마나 영향을 미치는가
■ 실험을 위해 students로 Llama-2-7b와 Llama-2-13b, 그리고 in-family 및 out-family teachers로 Llama-2-70b와 GPT-3.5를 사용하며, arithmetic reasoning 부터 commonsense tasks에서 평가를 수행한다.
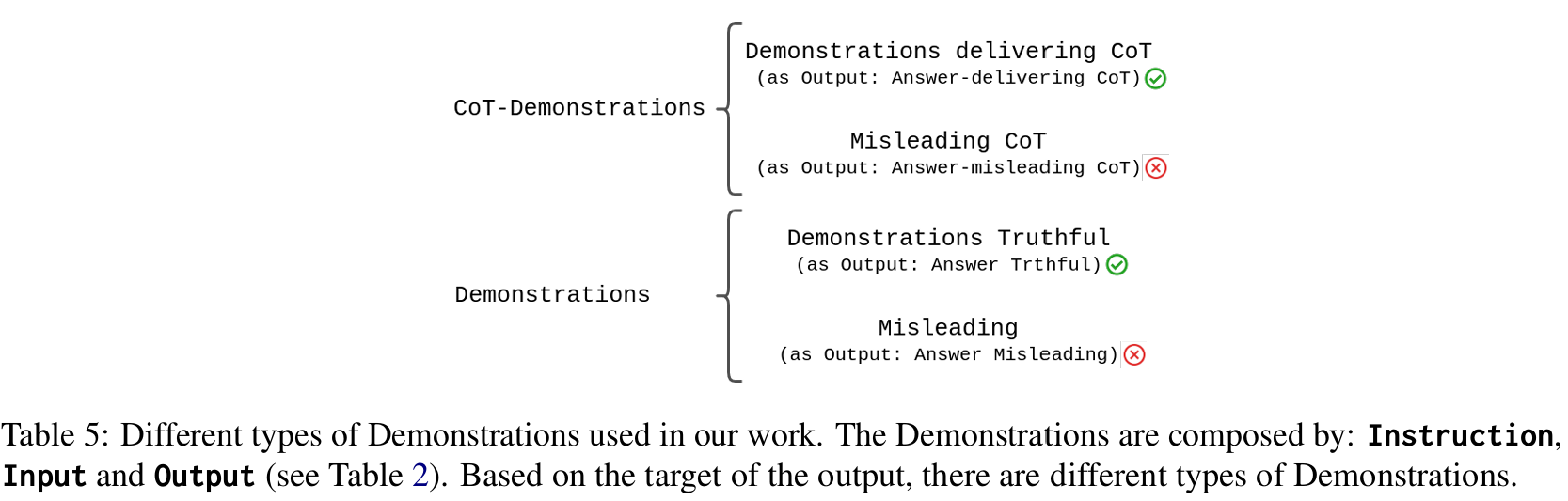
■ CoT-Demonstration을 "Answers-delivering CoT (올바른 CoT prediction)"에서 비롯된 "Demonstrations-delivering CoT"와 "Misleading CoT (wrong CoT predictions)"에서 비롯된 "Demonstrations-misleading CoT"로 구별한다. 그리고 비교를 위해, CoT prompting이 없는 base Demonstrations을 사용한다.
■ 실험을 통해 모든 벤치마크에서 저자들의 접근법이 baseline SLMs보다 일관되게 우수한 성능을 달성하며, in-family teacher가 제공한 Demonstrations-delivering CoT로 instructed된 student가 out-family에 의해 instructed된 student보다 더 뛰어난 성능을 달성한 것을 보여준다.
2. Method
■ 저자들은 two-phase alignment approach를 제안한다.
■ first phase는 automated "annotation phase"로, LLM이 체계적으로 프롬프트되어 outputs을 생성한다. (섹션 2.1)
■ second phase에서 이러한 Demonstration outputs은 smaller LM을 Instruction-tuning하는 데 사용된다. (섹션 2.2)
2.1 Teacher Model
■ teacher와 student를 모두 설정할 수 있는 Llama 2 family에서 in-family teacher로 Llama-2-70b를 선택했다. 그리고 실험을 위해 out-family teacher로 GPT-3.5를 선택했다.
■ zero-shot scenario에서 두 가지 다른 prompt types을 사용하는데, 첫 번째 input-prompt는 Table 1과 같이 question과 (multiple-choice tasks의 경우) 그 관련 선택지로 구성된 classic standard prompt이다.

■ 두 번째 prompt는 전형적인 CoT prompt component를 추가하는데, 여기에는 "Let’s think step by step"이라는 suffix가 붙는다.

■ LLM이 생성한 output은 Demonstrations의 annotated set을 구축하는 데 사용된다.
2.2 Student Model
■ in-family 실험을 위해 SLM으로 Llama-2-7b와 Llama-2-13b를 선택했으며, "chat" 버전을 사용한다. 논문에서는 이를 Llama-2-7 및 -13으로 지칭한다.

■ student models은 Instruction-tuning before and after로 평가된다.
■ Demonstration은 overall Instruction: 예를 들어 question answering tasks의 경우 "선택지 A, B, ... 중에서 question에 대한 answer만 선택하라", math word problem tasks의 경우 "mathematical question에 numerical solution으로 답하라", 그리고 question인 input과 teacher LLM이 생성한 output인 expected output으로 구성된다.

3. Experimental Setup
3.1 Tasks & Datasets
Commonsense Task
■ commonsense reasoning을 평가하기 위해 두 가지 벤치마크를 채택했다: CommonSenseQA(CSQA)와 OpenBookQA(OBQA)는 two multi-choice commonsense question-answering tasks이다.
Physical & Social Interaction Task
■ 일상적인 상황 맥락에서의 reasoning ability를 평가하기 위해 물리적 상호작용에 대한 QA인 Interaction Question Answering (PIQA)과 사람들의 행동 및 사회적 의미에 대한 Social Interaction Question Answering (SIQA)를 사용한다.
Mathematical Task
■ mathematical reasoning을 평가하기 위해 두 개의 math word problem benchmarks을 사용한다: MultiArith는 multi-step arithmetic reasoning task을 다루며, GSM8k는 primary school-level의 mathematical problems을 다룬다.
Datasets
■ 모든 벤치마크에 test split이 지정되어 있지 않으므로, 다음과 같은 전략을 채택했다.
■ SIQA, PIQA, CSQA, OBQA의 경우 target classes이 균등하게 분포된 4,000개의 examples을 training data로 사용하고, 허깅페이스에 있는 validation versions을 test data로 사용한다.
■ GSM8K와 MultiArith의 경우 허깅페이스의 datasets을 사용한다.
■ Table 12는 각 벤치마크의 example, Table 13은 training 및 test data의 비율이다.

3.2 Teaching to Reason
■ teacher model인 Llama-2-70과 GPT-3.5는 Table 7에 나타난 바와 같이 zero-shot scenario에서 프롬프트된다.
■ student models로 Llama-2-7과 Llama-2-13을 선택했으며, 이들은 Stanford Alpaca(https://github.com/tatsu-lab/stanford_alpaca)에서 제안한 Instruction-tuning approach를 따라 fine-tune된다.
■ SLMs은 섹션 2.2에서 설명한 대로 teacher가 생성한 answers을 포함하고 있는 Demonstrations로 instructed된다. (Table 2는 CoT-Demonstration의 예시)
3.2.1 Models Setup
■ Instruction-tuning phase에서 QLoRA를 사용한다. 이를 통해 메모리 사용량을 줄이면서 instruction-tuning을 수행할 수 있다.
■ Alpaca에서 제안한 training approach를 따른다. 모델은 4 epochs 동안 학습되며, 학습률은 0.00002, weight decay는 0.001로 설정한다. warmup ratio가 0.03인 cosine learning rate scheduler를 사용한다.
3.3 Evaluation
■ question-answering tasks에서 가장 널리 사용되는 평가 방법은 가장 높은 확률을 가진 선택지를 선택하는 language-model probing과 모델에게 answer를 확정하도록 요청하는 multiple-choice probing이다.
■ 첫 번째 경우의 평가는 argmax를 취하는 함수로 수행되며, 두 번째 경우는 직접적인 string matching으로 수행된다.
■ 두 번째 방법(string matching)은 확률 값에 쉽게 접근할 수 없는 larger GPT family에도 적용할 수 있기 때문에, 첫 번째 방법보다는 더 널리 사용된다. 저자들도 비교 가능한 실험을 위해 후자를 선택했다.
■ 마지막으로, 생성된 outputs과 target choice 간의 string matching을 통해 정답 비율을 평가했다.
4. Results & Discussion
4.1 CoT-abilities of Small Language Models

■ CoT prompt가 항상 downstream performance improvement를 가져오는 것은 아니다. SLM은 CoT 메커니즘으로 프롬프트되었을 때 성능 향상을 보이지 않았다.
■ Table 3은 섹션 3.1에서 언급한 4가지 question-answering benchmarks에서 Llama-2-chat(7b-13b)을 사용하여 zero-shot scenario에서 classical prompt (Baseline)와 CoT prompt를 평가한 결과이다.
■ Manual CoT paper에서 주장했던, SLM에서는 관찰되지 않는 emergent CoT prompting abilities의 한계를 확인할 수 있다. SLM에 CoT prompting을 사용하는 것은 모델에게 혼란을 야기하며 downstream에서 성능 저하로 이어진다.
■ 특히, OpenBookQA (OBQA)와 CommonSenseQA (CSQA)에서 Llama-2-13의 절반에 해당하는 파라미터를 가진 Llama-2-7의 경우 CoT prompt 사용 시 성능 저하가 두드러지게 나타난다.
■ 단, PIQA와 SIQA에서는 OBQA 및 CSQA와 비슷한 결과가 관찰되지 않았는데, 이는 PIQA와 SIQA가 OBQA와 CSQA보다 선택지가 더 적어(Table 13)서 추론 복잡도가 낮아 모델이 덜 헷갈렸기 때문으로 볼 수 있다.
4.2 The Instruction-tuning Impact
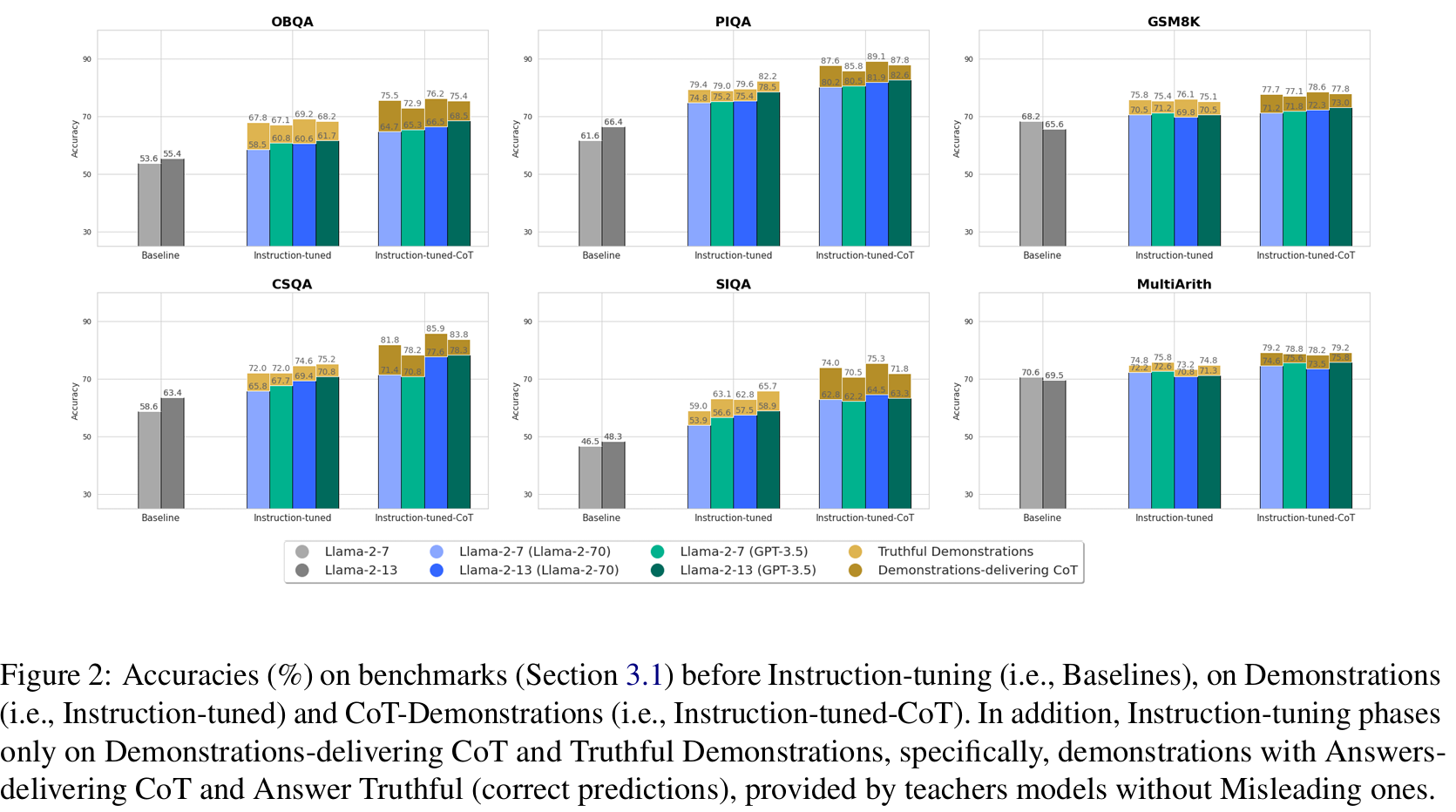
■ LLM(teacher model)을 통한 Instruction-tuning CoT는 SLM(student model)이 step-wise reasoning을 수행하도록 유도할 수 있다. (Fig 2)
■ teacher가 생성한 Demonstrations에 대해 Instruction-tuning을 수행한 student models은 benchmarks에서 baselines의 성능을 능가하며, CoT-Demonstrations으로 instructed된(즉, Instruction-tuned-CoT로 학습된) student models이 best accuracy를 달성했다.
■ Table 11에서 볼 수 있듯이, GPT-3.5 (17B)와 Llama-2-70 (70B)는 성능이 서로 다르다. CoT prompt의 경우 GPT-3.5의 성능이 더 뛰어난 것을 볼 수 있다.
■ 그러나 더 뛰어난 teacher라고 해서 반드시 student의 성능 향상으로 이어지는 것은 아니다.
■ GPT-3.5를 teacher로 사용한 Llama-2-7과 -13은 오직 OpenBookQA에서만 Llama-2-70을 teacher로 사용한 모델들을 능가한다. (Fig 2 OBQA 결과)
■ CSQA와 PIQA에서는 두 teacher의 students 성능이 비슷하지만, SIQA에서는 Llama-2-70에게 배운 student가 더 뛰어난 성능을 보인다.

4.3 Demonstrations-delivering CoT vs Misleading CoT
■ consistent Demonstrations을 통한 Instruction-tuning은 misaligned answers을 포함한 Demonstrations보다 더 나은 성능을 발휘한다. 또한, Demonstrations-delivering CoT는 students의 reasoning abilities이 teacher Llama-2-70과 family-alignment되도록 만든다.
■ Fig 2에서 Truthful Demonstrations과 Demonstrations-delivering CoT로 instructed된 models은 overall Demonstrations과 overall CoT-Demonstrations으로 instructed된 models을 능가한다.
■ 그리고 in-family teacher가 생성한 Demonstrations-delivering CoT는 out-family teacher가 생성한 것보다 우수한 성능을 보인다.
■ Demonstrations-delivering CoTs과 Truthful Demonstrations로 Instuction-tuning한 결과, Truthful Demonstrations가 Misleading instances이 제거되었기 때문에 전체 Demonstrations의 수보다 작음에도 불구하고(결과적으로, student는 더 적은 수의 instances을 사용하게 된다) student model의 성능을 더욱 향상시킨다.
- 즉, 데이터 개수가 비교적 적더라도, 노이즈(오답, 잘못된 논리)를 제거한 고품질 데이터로 학습하는 것이 훨씬 효과적이다. 잘못된 CoT는 student model을 혼란스럽게 하여 성능을 떨어뜨릴 수 있음을 시사한다.
4.4 The Role of Demonstrations-delivering CoT

■ Fig 3에서 Demonstrations Truthful(막대 바로 표시됨)과 Demonstrations-delivering CoT(선으로 표시됨)로 instructed된 students이 overall Demonstrations으로 instructed된 students보다 우수한 성능을 보임을 확인할 수 있다.
■ 그리고 Demonstrations-delivering CoT는 Demonstrations Truthful를 일관되게 능가한다.
- 즉, Demonstrations-delivering CoT > Demonstrations Truthful > overall Demonstrations
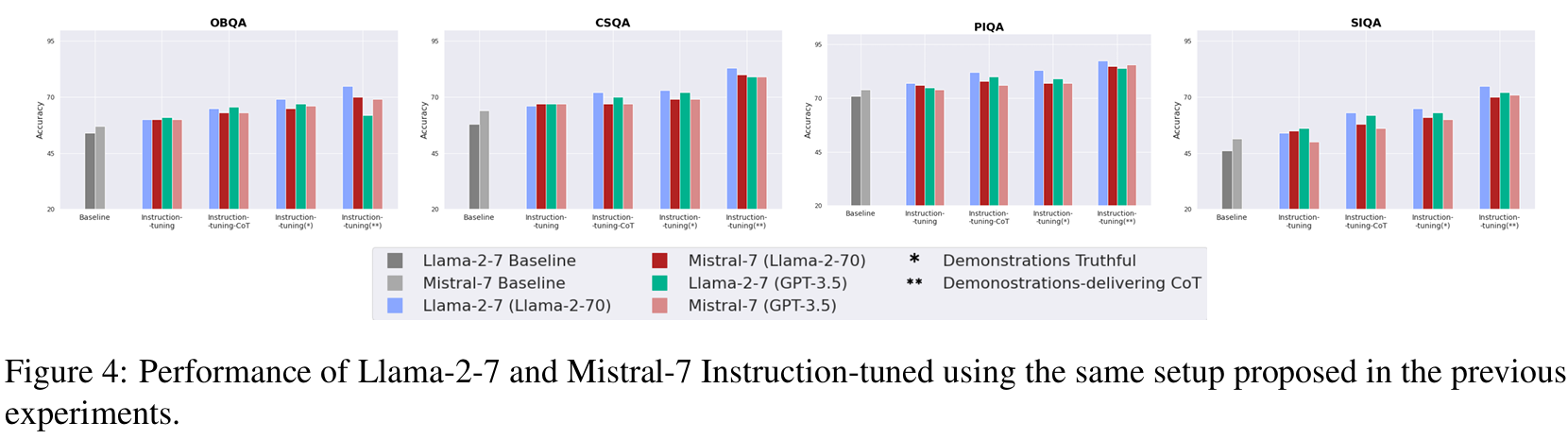
■ family-alignment를 검증하기 위해서 추가로 Mistral-7b를 사용했으며, Fig 4에서 Llama-2-70을 teacher로 사용했을 때, Llama-2-7이 대부분의 경우 Mistral-7b를 능가한 것을 볼 수 있다.
■ 이러한 결과는 in-family teacher로부터 파생된 Demonstrations을 사용하는 것이 student의 성능에 더 좋은 영향을 미칠 수 있음을 보여준다.
4.5 In-Domain and Out-Domain
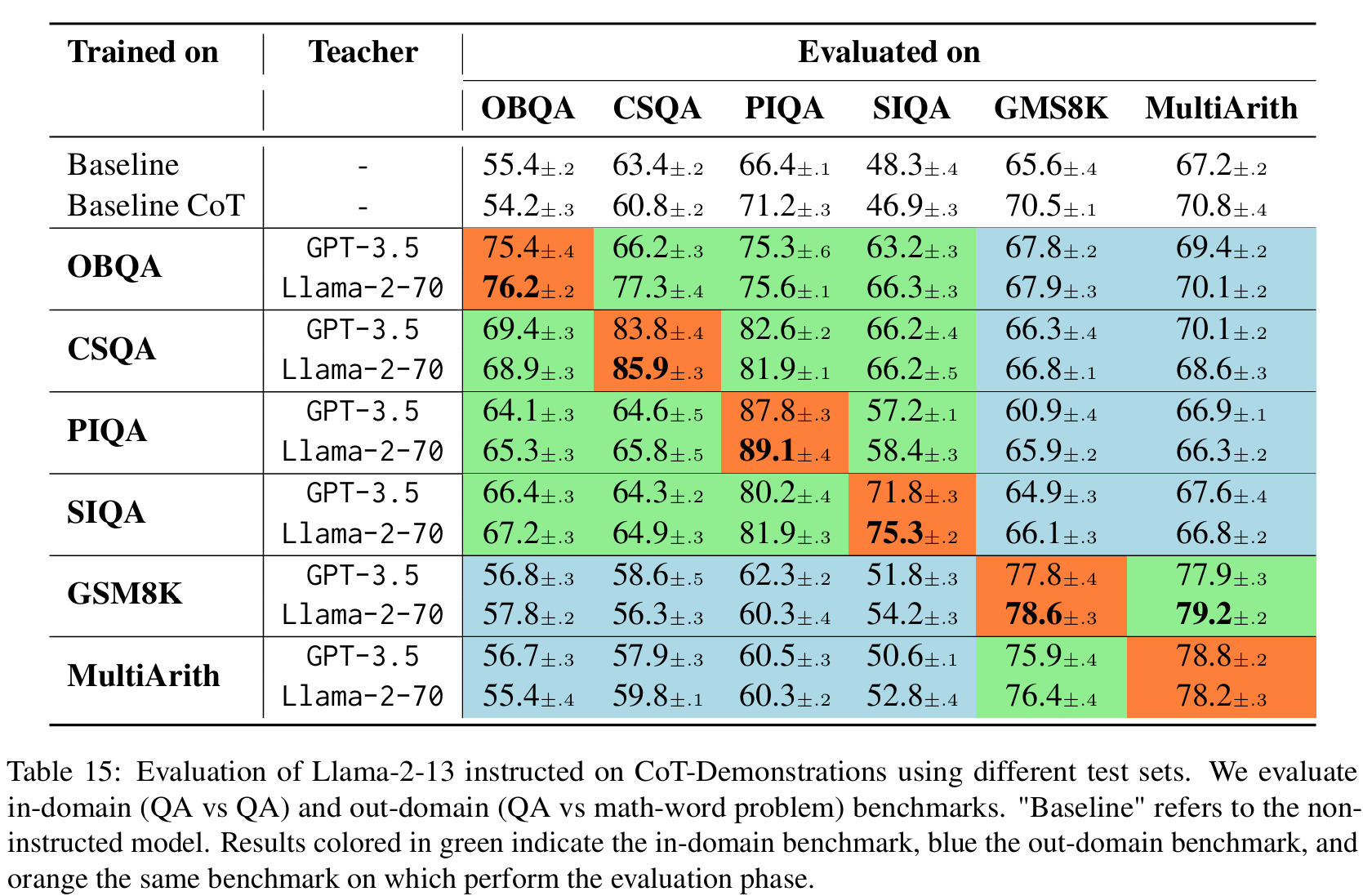
■ CoT-Demonstrations을 통한 Instruction-tuning은 student model이 in-domain과 out-domain tasks를 모두 커버할 수 있게 한다.
■ Fig 4는 student Llama-2-7, Fig 15는 Llama-2-13의 결과로, 두 경우 모두 instructed models이 baselines을 능가함을 볼 수 있다. 단, in-domain scenarios(예: QA tasks)에서 out-domain scenarios(예: mathematical problems)보다 훨씬 더 나은 결과를 달성한다.
■ 마지막으로 Table 16에서 볼 수 있듯이, instructed models이 baselines을 일관되게 능가한다.

■ 이러한 결과들은 (1) instruction-tuning 과정이 베이스라인 성능을 저하시키지 않으며 (2) instructed models은 학습하지 않은 tasks에서도 uninstructed models을 능가함으로써, instructed models이 generalization abilities을 학습했음을 시사한다.

