■ LM에서 reasoning ability는 오랫동안 LLM의 emergent 속성으로 간주되어 왔다. 그러나 최근 연구들은 기존 통념과 달리, SLM 또한 경쟁력 있는 reasoning performance를 달성할 수 있음을 보여주고 있다.
■ 논문에서는 Llama, Qwen 등 6개 패밀리에서 나온 72개의 다양한 SLMs을 reasoning benchmarks에 걸쳐 평가한 결과를 제시한다. 핵심 발견은 다음과 같다.
- (1) SLM의 reasoning ability는 단순히 model scale보다는 training method와 data quality에 영향을 많이 받는다.
- (2) 양자화는 reasoning capability를 보존하는 반면, 가지치기는 이를 저해시킨다.
- (3) 더 큰 모델들이 adversarial perturbations이나 intermediate reasoning에 더 강하지만, 잘 학습된 특정 소규모 모델들은 대규모 모델의 성능과 거의 비슷하거나 이를 능가한다.
[2502.11569] Towards Reasoning Ability of Small Language Models
Towards Reasoning Ability of Small Language Models
Reasoning has long been viewed as an emergent property of large language models (LLMs). However, recent studies challenge this assumption, showing that small language models (SLMs) can also achieve competitive reasoning performance. This paper introduces T
arxiv.org
1. Introduction
■ 오랫동안 LM의 reasoning은 LLM의 emergent property로 간주되어 왔으며, 이는 특정 규모(약 100B 파라미터) 이상에서만 나타나는 것으로 여겨졌다.
■ 그러나 최근 연구들은 이러한 통념과 반대되는 결과들을 보여주고 있다. 예를 들어, 3.8B 파라미터의 Phi-3.5-mini는 GPT-3.5와 비슷한 성능을 보여주었다. 이는 SLM에서도 reasoning ability를 가질 수 있음을 시사한다.
■ DeepSeek-R1에서는, DeepSeek-R1이라는 large model (671B)의 reasoning abilities을 smaller models (1.5B–70B parameters, Qwen Family)에 distillation하는 방식으로 인상적인 reasoning ability를 보여주었다.
■ 이러한 연구들은 reasoning ability가 오직 scaling에서만 나온다는 기존 통념과 상충되는 결과이다. 이에 저자들은 SLM도 강력한 reasoning capabilities을 develop할 수 있는지 확인하고자 하였다.
■ SLM의 정의는 모델 크기, 효율성, 배포 제약 조건에 따라 매우 다양한데, 논문에서는 SLM을 SOTA LLMs보다 상당히 작으며, 수억 개에서 최대 약 30B 파라미터 범위를 가지거나, compression(예: quantization, pruning)을 통해 유사한 계산 효율성을 달성하는 모델로 정의한다.
■ SLM의 reasoning ability, 특히 compressed된 상태에서의 성능은 아직 충분히 연구되지 않았다.
- 예를 들어, 양자화된 LLaMA-70B가 8B variant보다 성능이 좋은지, SLM이 compression을 거친 후에도 reasoning ability을 유지할 수 있는지 그리고 그 정도는 얼마나 되는지 등
■ 이러한 질문에 답하기 위해 논문에서는 포괄적인 평가를 수행하는데, 먼저 reasoning performance를 평가하기 위한 신뢰할 수 있는 evaluation metric을 확립하고자 하였다.
■ reasoning은 generative task이기 때문에 객관적인 평가지표를 정의하기 쉽지 않다. 또한 서로 다른 지표들은 human evaluation과 상충되는 결과를 보이는 경우도 있어 모델의 실제 추론 능력을 평가하기 어렵게 만든다.
■ manual evaluation은 비현실적이며, rule-based evaluation은 모델이 특정 instructions을 따르는지 평가한다. 목표는 모델의 "instructions following" ability를 측정하는 것이 아닌 "reasoning" ability를 측정하는 것이기 때문에 rule-based evaluation은 적합하지 않다.
■ 저자들은 best evaluation framework를 찾기 위해 다양한 파싱 기반 방법들, LLM-as-a-Judge, 그리고 lm-eval-harness와 같이 널리 사용되는 벤치마크들을 자체적으로 진행한 human evaluation과 비교했고, 그 결과 GPT-4-Turbo와 GPT-4o가 human judgment와 가장 일치함(98% 일치)을 보여, LLM-as-a-Judge를 SLM reasoning을 벤치마킹하기 위한 main evaluation metric으로 사용한다.
■ 그리고 대표적인 8개의 reasoning benchmarks(GSM8K, MATH 등)과 6개의 sorting tasks에서, 6가지 families(Llama 및 Qwen 등)의 72개 SLM에 다양한 SLM strategies(예: 양자화, 증류)을 적용했을 때의 성능을 평가한다.
- sorting tasks을 통해 모델이 memorization이 아닌 추론 능력을 보여주는지 확인하고자 한 것이다.
■ 동일한 prompting strategies이라도 서로 다른 모델들이 다르게 반응하여, GSM8K에서 5가지 다른 prompting strategies (Direct I/O, COT, 5-Shot, COT 5-Shot, 8-Shot)을 사용하여 SLM의 프롬프트 민감도를 테스트한다.
■ 모든 실험은 3회 수행되었으며, 성능으로 그 평균과 표준편차를 reporting한다.
■ 마지막으로, 세 가지 specialized benchmarks: MR-Ben, MR-GSM8K, GSM-Plus에서 SLM reasoning의 robustness를 테스트한다.
- MR-Ben: reasoning steps에서 잠재적인 오류를 찾아내고 분석하는 능력을 평가
- MR-GSM8K: intermediate reasoning ability 평가
- GSM-Plus: adversarial perturbations에 대한 resilience 측정 (문제에 함정이 있어도 풀 수 있는지)
■ memorization이 아닌 모델의 실제 추론 능력을 평가하기 위해, 모델이 학습한 적 없는 최신 데이터셋(실험에 사용된 모델들의 release보다 더 이후에 공개된 데이터셋)을 사용하여 memorization 가능성을 배제하였다.
■ 실험 결과는 Qwen2.5-32B와 같은 특정 open-sourced SLMs이 intermediate reasoning에서 GPT-4-Turbo와 같은 proprietary LLMs과 경쟁력 있음을 보여준다. 이는 reasoning이 단순히 규모의 함수가 아니라 구조화된 training 및 최적화의 결과임을 시사한다.
2. Related Work
SLM Reasoning
■ 최근 연구들은 Hymba-1.5B 및 Llama-3-1B와 같은 SLM의 reasoning abilities, 특히 mathematical and logical tasks에서의 능력에 초점을 두었다.
■ 일부 approaches은 MCTS와 process preference model을 사용하는 rStar-Math와 같이, reasoning tasks에 대해 SLM을 directly training시킨다. 이런 방식은 fine-tuning을 통해 특정 datasets에 대해선 reasoning을 향상시킬 수 있지만, generalization가 떨어진다.
■ 또 다른 연구 라인은 knowledge distillation을 사용하여 LLM에서 SLM으로 reasoning capabilities을 transfer시키는 것이다. feedback-driven 및 counterfactual distillation과 같은 strategies은 reasoning abilities을 refine하고 out-of-distribution tasks에서도 좋은 성능을 보여준다.
■ Instruction-tuning CoT와 fine-tuning on CoT-generated outputs 방법들도 multi-step reasoning에서의 개선을 보여주었다.
■ 더 나아가, equation-only formats이나 synthetic data training(예: Orca-Math)도 성능을 향상시킬 수 있음을 보여주었다.
Reasoning Evaluation
■ LM reasoning에서는 response의 open-ended 및 multi-step 특성으로 인해, reasoning을 평가하기 어렵다.
■ rule-based parsing은 정확한 채점이 가능하지만, format 문제로 오히려 불이익(예: 정답인데 format 차이로 오답 처리)을 주는 경우가 많다.
■ human evaluation의 경우 그 평가 결과를 신뢰할 수 있지만 비용이 많이 들고 평가가 주관적이다.
■ 최근에는 인간의 판단과 강한 agreement를 보이는 LLM-as-a-Judge가 대안으로 부상했다.
■ 그러나 SLM의 reasoning을 평가하기 위해 이러한 방법들을 체계적으로 비교한 연구가 아직 없다. 이에 논문에서는 rule-based parsing, human ratings, lm-eval-harness, 그리고 LLM-as-a-Judge를 사용하여 평가 방법을 확립하고자 하였다.
3. THINKSLM Setup
■ SLM의 reasoning에 영향을 미치는 요인들의 다차원적인 상호작용을 분석하기 위한 experimental setup을 설계했다.
3.1 Dimensions Influencing SLM Reasoning
■ SLM의 추론 능력 요인들을 다각도로 분석하기 위해, 다음과 같은 6가지의 dimensions을 선택하였다.
- (1) model capacity and family: trained from-scratch, Qwen2.5, Llama-3, Mistral
- (2) training and architecture choices: data scale, reinforcement learning-based post-training, hybrid-head architectures
- (3) inference-time prompting strategies: Direct I/O, Chain-of-Thought (CoT), few-shot scenarios
- (4) post-compression methods: quantization, pruning, distillation
- (5) task domains: maths, science, commonsense, algorithmic reasoning
- (6) robustness stressors: adversarial perturbations, intermediate reasoning steps, error detection
3.2 Tasks & Datasets
■ 선택한 tasks 및 datasets은 다음과 같다.
- (1) mathematical reasoning: GSM8K, MATH, MathQA dataset
- (2) science reasoning: ARC-Easy, ARC-Challenge dataset
- (3) commonsense reasoning: CommonsenseQA, OpenBookQA, HellaSwag
- (4) algorithmic reasoning: 복잡성, 길이, 수치적 구성(positive-only and mixed positive-negative scenarios)이 체계적으로 변화하는 customized SORTING tasks을 도입하여 수치 및 순차적 추론을 테스트하도록 설계했다.
3.3 Evaluation Protocol
먼저, 신뢰할 수 있는 평가 방법을 선택하기 위해,
- (1) 평가 문제를 model output \( y \)와 ground truth \( y^* \)를 correctness scores로 매핑하는 scoring function \( S : \mathcal{Y} \times \mathcal{Y}^* \rightarrow \{0, 1\} \)를 찾는 것으로 정의하고
- (2) 평가 방법들 \( \mathcal{M} = \{m_1, ..., m_k\} \) 중에, 인간의 평가 \( S_h \)와의 agreement \( \rho \)를 최대화하는 방법 \( m^* = \arg \max_{m \in \mathcal{M}} \rho(S_m, S_h) \)을 찾는 식으로, 인간의 판단과 가장 일치하는 평가 방법을 선택하고자 하였다.
Parsing Issues
■ standard parsing techniques은 고정된 패턴에 의존(예: 답이 #### 42처럼 정확한 포맷으로 나와야만 정답으로 인정)하기 때문에, 생성 모델이 이를 일관되게 따르기 어려울 수 있다.
■ 이는 \( S_{\text{parse}}(y, y^*) = \mathbb{I}[\text{extract}(y) = y^*] \)로 공식화할 수 있다. 여기서 \( \text{extract}(\cdot) \)은 정규표현식 적용을 의미한다. 정규표현식을 통해 정답(예: 42)을 추출하는 것이다.
■ 그러나 small models은 대부분 instruction-following 능력이 부족하기 때문에, 이렇게 특정 출력 형식을 맞추는 것에 어려움을 겪어 포맷 문제로 불이익을 받는 경우가 발생한다.
■ Manual CoT paper에서는 instruction-following capabilities이 model scale (~100B)에 따라 향상됨을 보여주었다. 그러므로 parsing은 small models에게 불공정한 지표가 된다.
Empirical Validation
■ 신뢰할 수 있는 평가지표를 선택하기 위해, 저자들은 SmolLM2-1.7B와 Llama-3.1-8B를 사용하여 GSM8K, ARC-E, ARC-C, CommonsenseQA, GSM-Plus datasets에서 1,000개의 샘플에 대해 human evaluation을 진행했다.
■ 세 명의 annotators이 majority voting으로 각 샘플에 label을 지정했으며: \( S_h(y_i, y^*_i) = \mathbb{I}[\sum_{j=1}^3 a_{ij} \ge 2] \), annotator간 agreement \( \kappa = 0.87 \)을 달성했다.
Statistical Significance Testing
■ 선택한 평가 방법(LLM-as-a-Judge)이 통계적으로 human evaluation과 차이가 없다는 것을 입증하기 위해 McNemar’s test를 사용했다.
■ 인간 판단에 대한 각 평가 방법 \( m \)에 대해, agreements와 disagreements의 \( 2 \times 2 \) 분할표를 구성했다.
- 예를 들어 다음과 같은 분할표를 만든 것이다.
| human: yes | human: no | 계 | |
| method: yes | a | b | a+b |
| method: no | c | d | c+d |
| 계 | a+c | b+d |
■ 검정 통계량은 다음과 같다.

- 여기서 \( b \)와 \( c \)는 disagreement로, 각각 human-yes/method-no와 human-no/method-yes이다.
- human evaluation과 선택한 평가 방법의 성능이 동등하다는 귀무가설 하에서, \( \chi^2 \)은 자유도가 1인 카이제곱 분포를 따른다.
- 이 귀무가설을 기각해야 차이가 있다고 주장할 수 있다.
■ 실험 결과, GPT-4-turbo가 human evaluation과 가장 높은 agreement를 달성(\( \rho = 0.99, p = 0.249 \))하며, GPT-4-turbo를 judgement로 사용했을 때, human evaluation과 통계적으로 유의미한 차이가 없었다(\( \chi^2 = 1.33 \))고 한다.
■ GPT-4o도 비슷한 결과를 달성했다고 한다. (\( \rho = 0.98, \chi^2 = 2.01, p = 0.156 \))
■ 반면, parsing methods은 \( \rho < 0.40, p < 0.001 \)를 기록하여, 통계적으로 human evaluation과 다르다고 주장할 수 있다.
Cost-Performance Trade-off
■ evaluation cost를 다음과 같이 모델링하였다.

- 여기서 \( n \)은 평가 횟수, \( c_{\text{token}} \)은 토큰당 비용, \( l_{\text{avg}} \)는 평균 프롬프트 길이, \( c_{\text{base}} \)는 API 비용이다.
■ 저자들은 GPT-4o가 GPT-4-turbo 정확도의 98%를 50%의 비용으로 달성할 수 있다는 점을 고려하여 mixed strategy를 사용한다: 정밀도가 중요한 mathematical reasoning에서는 GPT-4-turbo를, commonsense 및 scientific reasoning tasks에서는 GPT-4o를 사용
Choosing the Best Judge

■ 위의 통계적 분석과 평가 비용을 기반으로, 다음 두 가지를 사용하여 GPT 모델을 평가했다: (1) agreement with human assessment \( \rho(S_m, S_h) \) (2) McNemar’s test를 통한 통계적 유의성
■ GPT-4-turbo가 가장 높은 agreement(\( \rho = 0.99 \))를 달성하여 human judgment와 유의미한 차이가 없음(\( $\chi^2 = 1.33, p = 0.249 \))을 Table 1에서 확인할 수 있다.
■ GPT-4o는 GPT-4-turbo와 비슷하게 수행(\( \rho < 0.40, p < 0.001 \))하는 반면, parsing methods은 \( \rho < 0.40, p < 0.001 \)로 human judgment와 상당한 차이가 있다.
■ utility function \( \text{Utility} = \rho - \lambda \cdot \text{Cost} \)을 도입했을 때, GPT-4o가 50% 낮은 비용으로 98%의 정확도를 달성하므로, 우리는 ARC-Easy, ARC-Challenge, CommonsenseQA의 evaluator로 GPT-4o를 사용한다.
- utility function에서 \( \lambda \ge 0 \)은 agreement \( \rho \)와 cost의 balance를 맞추기 위해 사용
- \( \lambda = 0 \)이면, cost를 전혀 고려하지 않으므로, 가장 정확하게 agreement \( \rho \)를 반영할 수 있다.
- 단, \( \lambda > 0 \)이라면 cost를 고려하게 된다. \( lambda \)값이 커질수록 더 저렴한 방법을 선택하는 것으로 이해할 수 있다.
■ GSM8K의 경우, mathematical reasoning tasks에서 약간 더 높은 신뢰성을 보인 GPT-4-turbo를 사용한다.
■ bootstrap analysis (B=1000)를 수행한 결과, GPT-4-turbo는 95% 신뢰구간에서 agreement \( \rho \) 값이 [0.98, 1.00]이었다고 한다: \( \text{CI}_{95\%}(\rho) = [0.98, 1.00] \)
- 즉, 100번 중 95번은 agreement \( \rho \) 값이 0.98~1.00 사이에 있다.
■ 이 신뢰구간 결과와 위의 통계적 유의성 검정 결과를 통해 저자들은 LLM-as-judge를 reasoning tasks위한 최적의 evaluation method로 선택하였다.
Task-specific Evaluators
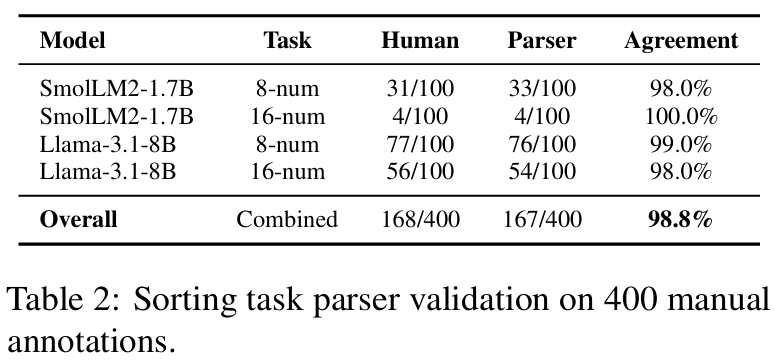
■ SORTING tasks에서 LLM evaluator는 exact sequence matching에 어려움을 겪으며, 지수적인 오류 증가를 보였다고 한다: \( P(\text{all correct}) \approx e^{-\lambdan} \), \( n \)은 sequence length
■ 그래서 저자들은 13가지 response formats을 포괄하는 정규표현식 패턴을 사용하였다. (Appendix C.3)
■ 그 결과, human judgment와 98.8% agreement를 달성했다. 이전 연구와 달리, 부분 점수 부여 없이 엄격한 binary scoring을 적용(즉, 완전히 맞거나 완전히 틀리거나)했다고 한다.
3.4 Experimental Matrix
■ reasoning에 영향을 미치는 핵심 요소들 간 상호작용을 확인하기 위해, 모든 모델을 다양한 tasks와 prompting strategies에 걸쳐 평가한다.
■ 그리고 small 및 large models에 모두 compression methods(예: 양자화)을 적용한다. 이를 통해 compression이 다양한 크기의 모델에 미치는 영향을 평가할 수 있다.
■ 또한, compression을 적용한 모델(SLM)이 원본 모델(LLM)의 성능에 얼마나 근접하는지 평가하기 위해 larger LLMs(예: 32B, 70B)을 사용한다.
4. Results & Insights
4.1 Model Capacity & Family Effects
■ 실험 결과(Table 3), SLM의 reasoning capability는 단순히 size에 의해 결정되는 것이 아니라, family와 training methodology에 의존한다는 것을 보여준다.
- (1) Qwen2.5 (7B)와 같은 모델은 GSM8K와 같은 tasks에서 Mistral-7B와 같은 다른 families의 비슷한 크기의 모델을 30% 이상 차이로 크게 능가한다.
- 이러한 차이는 Qwen2.5의 extensive pre-training dataset (∼18 trillion tokens)과 multi-stage reinforcement learning 및 supervised fine-tuning을 포함하는 alignment strategies에서 비롯된다.
- (2) 모델 성능은 크기에 비례하여 선형적으로 확장되지 않는다.
- 예를 들어, Qwen2.5 family 내에서 0.5B에서 7B 파라미터로 증가하면 GSM8K 정확도가 45% 향상된다. 그러나 다시 두 배인 14B로 증가하면 3%만 증가한다.
- 14B를 넘어서면, 더 큰 모델들은 특정 하나의 task에서 성능이 크게 향상되기보다는, tasks 전반에 걸쳐 커버리지에서 더 많은 개선을 보인다. 즉, 모델 크기가 커질수록 특정 문제를 더 잘 푼다기보다는, 못 푸는 문제가 줄어들며 전반적인 범용성이 향상되는 경향을 보인다.
■ 이러한 결과는 training methodology가 reasoning performance에 큰영향을 미치며, robust training pipelines이 smaller model과 관련된 한계를 완화할 수 있음을 시사한다.
4.2 Training Recipe & Architecture Effects
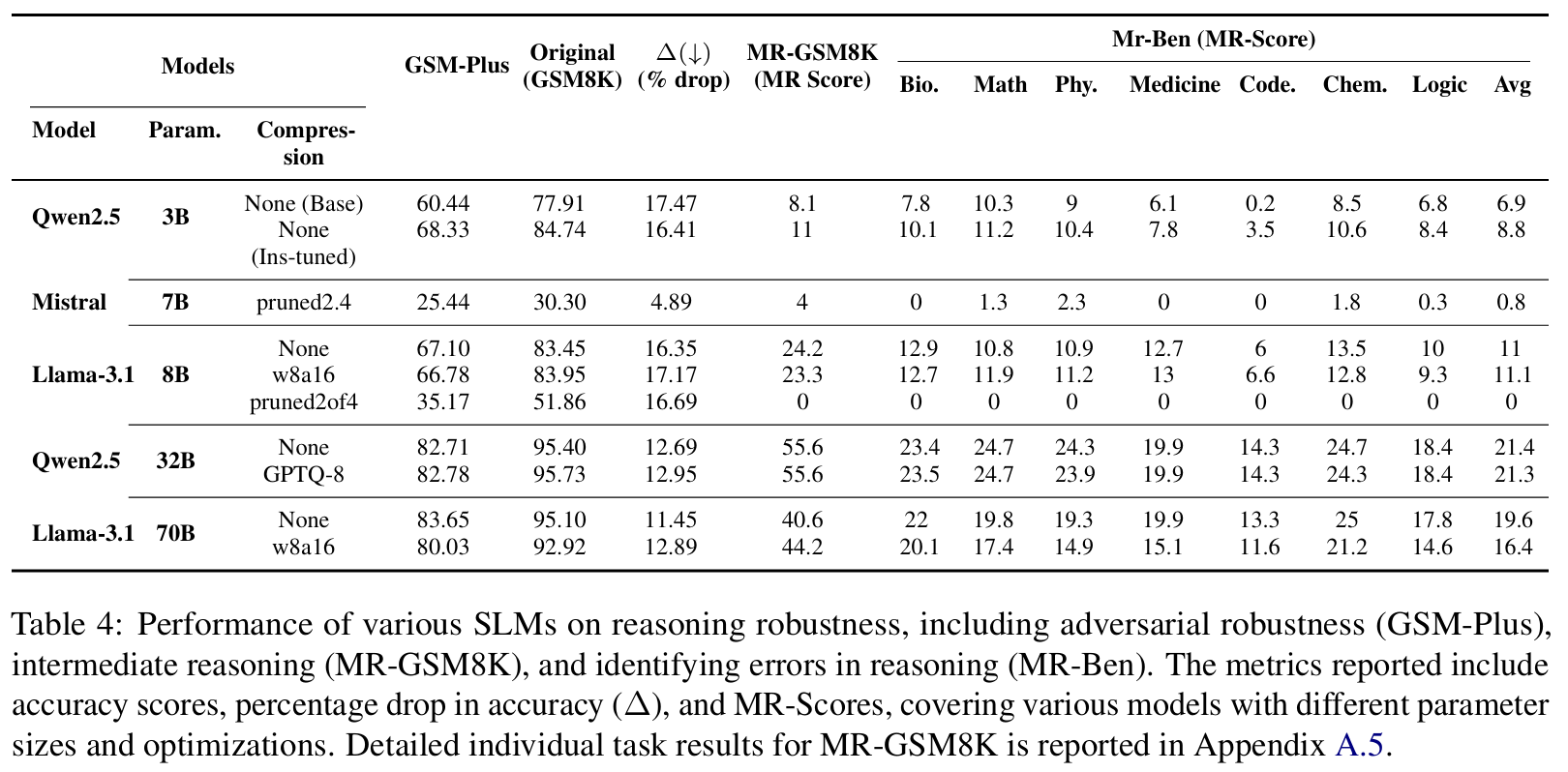
■ model size보다는 instruction tuning, high-quality teacher-driven distillation, 그리고 architecture-level의 innovations이 reasoning performance에 더 큰 영향을 미친다.
- (1) instruction-tuned models은 동일한 아키텍처의 base model보다 성능이 월등히 뛰어나다.
- Qwen2.5-3B는 GSM8K에서 77.91% (base)에서 84.74% (instruction-tuned)로, GSM-Plus에서는 60.44%에서 68.33%로 급상승한다. (Table 4)
- (2) 모델 아키텍처도 결정적인 역할을 한다.
- Hymba-1.5B는 attention과 SSM을 결합한 hybrid head designs을 도입했음에도 GSM8K에서 53.75%를 기록하여 Qwen2.5-1.5B의 70%에 크게 뒤처진다.
- 이 격차는 효율성이 높은 아키텍처를 사용하더라도, 아키텍처 자체만으로는 부족한 추론 능력 자체를 제고할 수 없으며, 고품질의 대규모 pre-training data를 사용한 사전학습과 supervised alignment이 더 큰 영향을 미침을 의미한다.
- (3) distillation quality의 영향은 Phi와 같은 모델에서 가장 두드러진다.
- 3.8B의 Phi-3.5는 GSM8K에서 85.47%의 성능을 달성(Table 3)하여 Minitron-4B(27.95%) 및 일부 더 큰 open-weight LLMs보다 훨씬 뛰어난 성능을 보인다.
- 이러한 극적인 성능 차이는, Phi는 추론에 초점을 맞춰 엄선한 고품질 합성 데이터를 사용하는 teacher-forced distillation을 사용한 반면, Minitron는 비슷한 크기임에도 불구하고 structured pruning에 의존했으며, compression 후 충분한 adaptation 과정(예: fine-tuning)이 부족했다.
■ 이러한 결과는 model compression을 사용할 경우, 어떻게 knowledge를 transfer할 것인지에 대한 training recipe의 중요성을 보여준다.
4.3 Domain-Specific Performance
■ reasoning capabilities이 domain에 매우 민감하다는 것을 보여준다. 예를 들어, sorting numbers와 같은 복잡한 reasoning tasks에서는 small 및 large models 모두 한계를 보인다.
■ ARC-Easy와 같은 단순한 task에서는 모델 크기에 관계없이 많은 모델들이 포화 상태에 가까운 높은 성능을 보이며, 표준편차는 6.4%로 낮다.
■ 이러한 tasks은 pattern matching과 factual recall에 의존하므로 성능의 원인이 memorization인지, 아니면 모델이 정말로 추론했는지 모델의 진짜 추론 깊이를 판별하기 어렵다.
■ 대조적으로, GSM8K 및 GSM-Plus와 같은 math-focused benchmarks에서는 모델 간 성능 차이가 뚜렷하다. GSM8K에서 표준편차는 19.7%이다. 이는 이러한 tasks이 모델의 추론 수준을 명확하게 가려낼 수 있다는 것을 보여주는 결과이다.
■ 더 어려운 GSM-Plus에서는 성능 격차가 더욱 커진다.
■ sorting tasks은 기호 조작 능력에 대한 대리 지표 역할을 한다. 음수("-", 추상적인 기호)를 추가하거나 더 긴 길이로 인해 시퀀스 복잡성이 증가할 때, 가장 강력한 모델(예: LLaMA-3-70B)조차도 최대 12%의 성능 저하를 보인다.
■ 이러한 실패는 모델이 견고한 알고리즘적 추론(예: 버블 정렬)을 구사하기보다는 얕은 휴리스틱에 의존하여 문제를 풀고 있으며, 그 휴리스틱이 복잡한 상황에서 쉽게 무너진다는 것을 시사한다.
■ 주목할 점은 sorting performance가 GSM8K 정확도와 강한 상관관계(0.78)를 보인다는 것인데, 이는 두 task 모두 수치적 추상화 및 단계별 추론이라는 인지 능력을 공통적으로 요구하기 때문으로 해석할 수 있다.
■ 이러한 결과는 복잡한 추론 영역으로의 확장성에 근본적인 한계가 있음을 보여준다. 이는 알고리즘 및 기호 추론 성능을 향상시키기 위해 task별로 최적화나 외부 tool 사용과 같은 개선이 필요함을 시사한다.
4.4 Prompting Effects
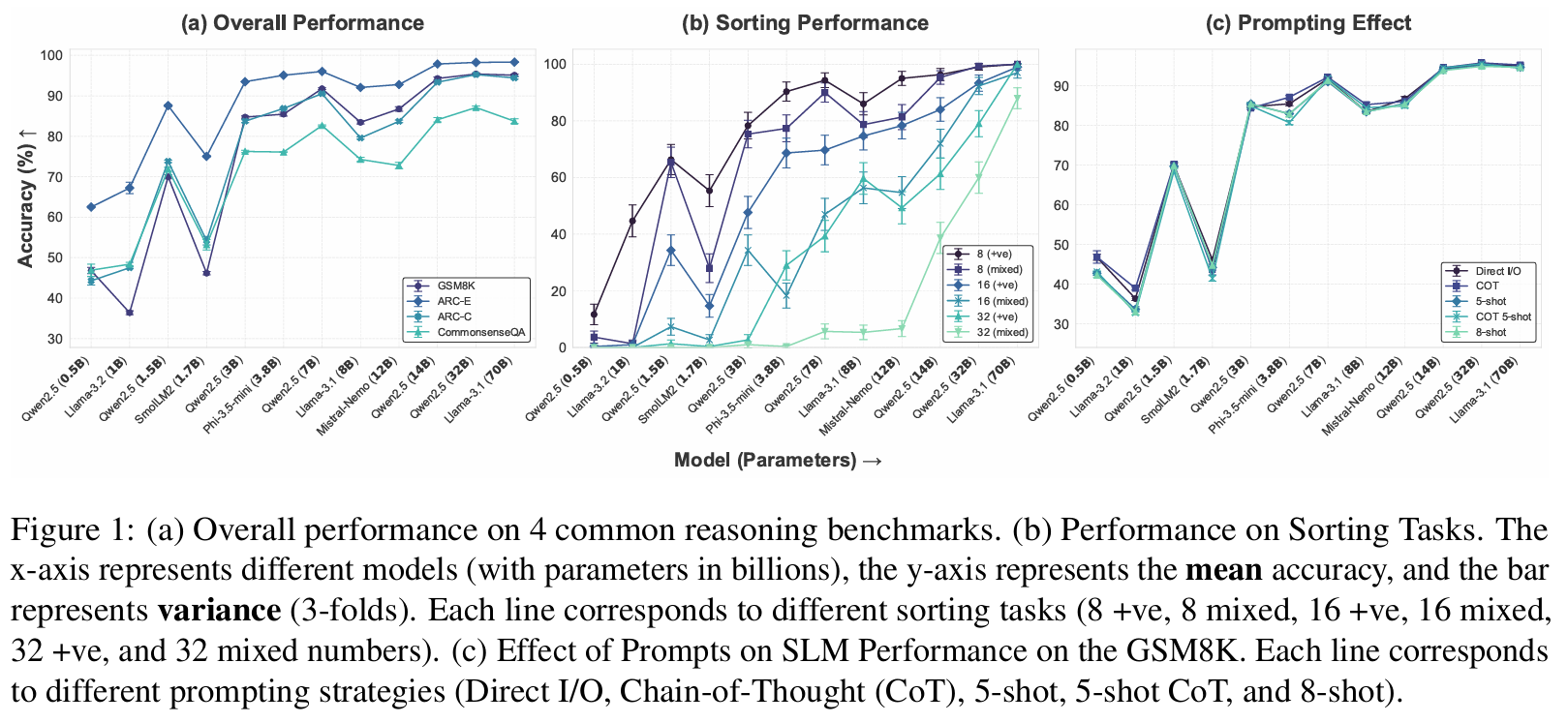
■ Fig 1은 CoT나 few-shot examples와 같은 prompting strategies이 항상 reasoning performance를 향상시키는 것은 아님을 보여준다.
■ 오히려 direct input/output formats과 같은 더 단순한 prompt가 CoT/few-shot examples와 비슷하거나 더 나은 성능을 기록했다. 특히, 2024년 이후 출시된 모델에서 이러한 경향이 더 두드러진다. (GSM8K에서 약 2% 성능 향상)
■ 어떤 경우에는 지나치게 복잡한 instructions이 정확도를 떨어뜨리기도 하는데, 이는 모델이 task를 해결하는 것보다 prompt format을 따르는 데 더 집중하기 때문일 가능성이 크다.
■ 이러한 결과는 최신 모델들(2024년 이후)이 학습 과정에서 이미 강력한 reasoning abilities과 step-by-step reasoning을 학습했기 때문에, 전통적인 prompting strategies의 효과가 제한적임을 시사한다.
■ 그러므로 앞으로의 개선 방향은 프롬프트 복잡성을 높이는 것이 아니라 특정 도메인에 특화된 접근법이나 외부 tools을 사용하는 것이다. 즉, 프롬프트로 추론 능력을 끌어내는 접근 방식에서 벗어나, 학습 과정에서 모델 자체에 내재된 추론 능력을 어떻게 효과적으로 활용할 것인지가 더 중요하다.
4.5 Compression Effects

■ 양자화는 reasoning capabilities을 놀라울 정도로 잘 유지하며(Fig 2), large models에서도 상당한 memory 및 efficiency gains을 제공한다.
■ 예를 들어, 8비트 양자화는 정확도 손실을 거의 보이지 않으며, 4비트 GPTQ는 Qwen2.5-14B의 메모리 사용량을 최대 80%까지 줄이면서도 GSM8K에서 성능 저하가 1점 미만이다.
■ 주목할 점은 4비트로 양자화된 14B 모델이 그렇지 않은 dense 7B 모델보다 성능이 뛰어나다는 것이다. 즉, 7B 모델(작은 모델)을 사용하는 것보다 14B 모델(그것보다는 더 큰 모델)을 양자화해서 사용하는 것이 더 좋은 성능을 달성할 수 있어 효과적이다.
■ 대조적으로 가지치기는 추론을 상당히 저하시키며, 특히 mathematical problem-solving과 logical reasoning과 같은 복잡한 tasks에서 더욱 그렇다.
■ 예를 들어, Llama-8B에서 가중치의 절반을 제거하면 GSM8K에서 32%의 정확도 하락과 ARC-Challenge에서의 완전한 실패를 초래한다.
■ knowledge distillation은 math tasks에서 일부 성능을 recover하는 데 도움이 될 수 있지만, 더 넓은 추론이나 commonsense understanding에는 거의 도움이 되지 않는다.
■ 이러한 결과는 양자화가 reasoning ability를 보존하는 데 더 안전하고 효과적인 compression method인 반면, 가지치기는 더 높은 성능 손실 리스크가 있어 주의해서 사용해야 함을 시사한다.
4.6 Robustness Under Stressors
■ 더 큰 모델들은 adversarial perturbations에서 더 강한 robustness를 보여준다.
■ GSM-Plus와 같은 벤치마크에서 larger models은 정확도가 11–17% 떨어지지만 모델 간 성능 순위는 안정적으로 유지된다. 이는 robustness가 별개의 특성이라기보다는 전반적인 reasoning ability와 비례하여 확장됨을 시사한다. 즉, 근본적으로 추론을 잘하는 모델이, 왜곡된 문제에서도 상대적으로 더 잘 버틸 수 있다는 것이다.
■ 양자화는 이러한 robustness에 최소한의 영향을 미친다. 예를 들어, 양자화된 Qwen-32B는 MR-GSM8K에서 55.6점을 기록하며 full-precision 버전(즉, 양자화하지 않은 모델)과 동일한 점수를 기록했다. (Table 4)
■ 대조적으로, 가지치기된 된 Llama-8B는 동일한 벤치마크에서 0점을 기록하여, 가지치기는 robustness와 coherence를 크게 저하시킨다.
■ 이러한 결과는, 복잡한 reasoning task에서 양자화는 파라미터 간 구조는 유지한 채 정밀도만 낮추므로, 추론 능력과 adversarial perturbations에 대한 robustness를 유지할 수 있지만, 신경망 경로를 끊는 가지치기는 이러한 특성을 유지하지 못한다는 점을 시사한다.
■ 모델이 자신의 답변을 비판하는 능력(reasoning steps에서 잠재적인 오류를 찾아내고 분석하는 능력)을 평가하는 MR-Ben 벤치마크는 domain-specific robustness를 더욱 잘 보여준다.
■ 모델들은 생물학 및 기초 수학에서 좋은 성과(median score: 22)를 보이지만, 70B 규모에서도 논리 및 프로그래밍에서는 어려움(median score: 14)을 겪는다.
■ 주목할 점은 Qwen-32B와 같이 잘 정렬된 오픈소스 모델은 step-by-step reasoning tasks에서 GPT4-Turbo와 같은 proprietary system을 능가할 수 있으며, 이는 학습 데이터와 학습 방식의 중요성을 보여주는 결과이다.
4.7 Cross-axis Interactions
■ training, prompting, 그리고 compression 전반에 걸친 위와 같은 평가는 SLM의 reasoning performance가 단순히 model size를 넘어선 요인들의 조합에 더 많이 영향을 받는다는 것을 보여준다.
■ 위의 실험들에서 두 가지 일관된 패턴이 있는데, (1) 양자화는 더 큰 모델에 적용될 때 가장 효과적이며 (2) instruction tuning은 reflective prompting의 이점을 강화한다.
- 예를 들어, 4비트 양자화된 Qwen-14B는 동일한 메모리를 사용하면서도 모든 tasks에서 full-precision Qwen-7B를 일관되게 능가한다. 이는 이미 강력한 모델을 압축하는 것이 작은 모델을 처음부터 학습시키는 것보다 더 효과적임을 의미한다.
- self-reflection prompts은 instruction-tuned Qwen-3B에서 14% gain을 가져오는 반면, 강화학습으로 aligned된 version은 4% gain에 그친다.
- 이는 human feedback으로 학습된 모델들이 이미 일부 reflective behaviors(즉, 스스로 생각을 점검하고 수정)을 내재화하고 있기 때문에, 명시적인 프롬프팅을 사용하는 것이 큰 도움이 되지 않음을 시사한다.
■ 이러한 결과는 reasoning ability가 파라미터 수 이상의 것들에 의존한다는 것을 보여준다. training data quality, alignment techniques, 그리고 smart compression strategies(특히 양자화)은 reasoning을 향상시키는 데 중요하다.
■ 반면, 가지치기는 특히 복잡한 tasks에서 일관되게 성능을 저하시킨다.
■ 정리하면, modern SLM의 효과적인 reasoning은 다차원적인 설계에 의해 형성된다. 가장 promising한 설계는 (1) high-quality의 reasoning-rich data로 더 큰 모델을 학습시키고 (2) human feedback으로 align한 다음 (3) 효율적인 배포를 위해 양자화를 적용하는 것이다.
5. Limitations
■ 실험 결과를 해석할 때 고려해야 할 몇 가지 한계점은 다음과 같다.
■ 대부분의 평가에서 evaluator로 GPT-4를 사용했다. 이는 효율적이고 강력한 evaluation baseline을 제시하지만, 100% 정확하지 않다.
■ 그리고 무의미한 답변을 내놓은 모델이 GPT-4에 의해 정확하다고 표시된 사례를 관찰했다고 한다. 즉, 성능이 과대평가될 가능성이 있다.
■ 그리고 sorting tasks에서 모델이 올바른 정답을 산출했지만, 파싱 오류로 잘못 분류된 경우가 있을 수 있다. 즉, 모델의 실제 sorting 능력이 과소평가되었을 수 있다.
■ 마지막으로, 널리 사용되는 benchmarks을 평가에 사용했다. 이러한 standard benchmarks은 비교의 기준을 마련한다는 점에서 가치가 있지만, 추론 능력의 전체 스펙트럼을 대표하지는 못한다.
'자연어처리 > Reasoning' 카테고리의 다른 글
| Orca 2: Teaching Small Language Models How to Reason (0) | 2026.01.26 |
|---|---|
| Teaching Small Language Models to Reason (0) | 2026.01.24 |
| Self-Discover: Large Language Models Self-Compose Reasoning Structures (0) | 2026.01.17 |
| Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations (0) | 2026.01.12 |
| Let's Verify Step by Step (1) | 2026.01.10 |