■ SLM에 관한 연구들은 더 뛰어난 모델(예: GPT-4)의 output을 따라하는 imitation learning에 의존해 왔다.
■ 기존의 imitation learning은 small model을 학습시킬 때 large model의 output을 그대로 따라하게 한다. 저자들은 large model이 하는 방식이 small model에서는 효과가 없을 수 있으며, SLM에게 imitation을 지나치게 강제할 경우 SLM의 잠재력을 제한할 수 있다고 주장한다.
■ 이에 대한 해결책으로 다양한 strategies을 사용하여 SLM을 학습시키는 것을 목표로 한다.
■ 예를 들어, large model은 복잡한 task에서도 direct answer가 가능하지만, small model이 large model과 같은 능력을 갖추지 못했다면, 동일한 task에서 direct answer가 불가능하고 다른 방식(예: step-by-step)으로 풀어야만 answer를 맞힐 수도 있다.
■ 즉, 단순히 large model의 방식을 흉내 내게 하면 small model은 capacity 한계로 large model이 하는 방식을 제대로 배우지 못할 수 있다.
■ 그래서 Orca 2에서는 모델에게 다양한 reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer 등)을 가르친다. 더 나아가, 모델이 각 task에 대해 가장 효과적인 솔루션을 결정하는 방법을 학습시키는 것을 목표로 한다.
■ 이렇게 학습된 Orca 2는 zer-shot setting에서 advanced reasoning abilities을 테스트하는 복잡한 tasks에서 평가했을 때, 5~10배 더 큰 모델들과 비슷하거나 더 나은 성능을 달성했다.

[2311.11045] Orca 2: Teaching Small Language Models How to Reason
Orca 2: Teaching Small Language Models How to Reason
Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned models on benchmarks like BigBench Hard and AGIEval. In Orca 2, we continue exploring how improved training signals can enhance smaller LM
arxiv.org
1. Introduction
■ GPT-4나 PaLM-2와 같은 LLM은 더 많은 파라미터로 확장함에 따라, 더 작은 모델(약 10B 미만의 모델)에서는 볼 수 없었던 emergent abilities이 나타났다. 그중에서도 가장 놀라운 ability는 zero-shot reasoning ability이다.
■ imitation learning은 SLM을 개선하기 위한 main approach로 부상했으며, imitation learning의 목표는 이러한 LLM을 teacher model로 사용하여, teacher의 output을 SLM이 따라하게 하는 것이다.
■ imitation learning으로 학습된 SLM은 teacher model의 스타일과 일치하는 콘텐츠를 생성할 수는 있다. 단, reasoning이나 comprehension skills에서는 어느 정도 효과가 있지만, teacher model을 따라가지 못한다.
■ imitation learning은 reasoning tasks와 같은 complex tasks와 SLM의 capacity를 고려한다면 최적의 솔루션이라고 할 수 없다.
■ 저자들은 SLM에게 reasoning ability를 향상시키기 위한 접근으로, 다음과 같은 두 가지 목표를 설정하였다.
- (1) small model에게 step-by-step processing, recall-then-generate, recall-reason-generate, extract-generate, and direct-answer과 같은 reasoning techniques을 가르치는 것
- (2) 각 task에 대해 가장 효과적인 reasoning strategy를 언제 사용할지 결정하도록 가르치는 것
- 이를 통해 모델의 크기와 관계없이 SLM이 낼 수 있는 best performance를 발휘할 수 있도록 하고자 하였다.
■ Orca 1처럼, 다양한 tasks 전반에 걸쳐 여러 reasoning strategies을 demonstrate하기 위해 LLM을 활용한다. 단, Orca 2에서는 student model이 teacher와 동일한 행동을 수행할 수 있는지를 염두에 두고 reasoning strategies을 각 task에 맞게 신중하게 조정한다.
■ 이러한 미묘한 데이터를 생성하기 위해, LLM에게는 specific strategic behaviors 및 더 정확한 결과를 이끌어내도록 정교하게 설계한 프롬프트를 제공한다. (Fig 3)
■ 더 나아가 training phase에서 small model은 task와 그에 따른 결과 행동만 볼 수 있다. 행동을 유발했던 original prompts은 볼 수 없다. 이러한 "프롬프트 소거(prompt erasure)" technique은 Orca 2를 "Cautious Reasoner"로 만든다.
- 어떤 문제가 있으면 teacher model에게는 매우 구체적이고 상세한 프롬프트(해당 문제에 어떻게 접근해야 하는지)를 주어 고품질의 답변을 얻어낸다.
- student model을 학습시킬 때는, teacher가 받았던 구체적인 instruction을 지우고 아주 일반적인 instruction만 제공한다. 이를 통해 student는 문제와 teacher의 output만 보고 그 기저에 있는 solution strategy와 그 strategy가 수반하는 reasoning ability를 배우도록 유도한다.
- 이러한 학습 전략으로 student가 teacher를 단순히 모방하는 대신, task에 가장 적합한 행동을 신중하게 선택할 수 있도록 유도한다.
■ small model training에 관한 일부 이전 연구들은 적은 수의 tasks로만 평가하거나, 다른 모델을 사용하여 "어떤 응답이 더 나은가?"와 같은 프롬프트로 두 모델의 output을 비교하게 하는 평가에 의존했다.
■ 기존의 제한된 평가 방식에서 벗어나, 논문에서는 총 15개 의 benchmarks(covering ~100 tasks and over 36,000 unique prompts)을 사용하여 포괄적인 평가를 수행한다.
2. Preliminaries
2.1 Instruction Tuning
■ instruction tuning은 input이 natural language task description이고 output이 그에 따른 원하는 behavior의 demonstration인, input-output pairs을 학습시키는 것을 포함한다.
■ 많은 연구들에서 이러한 instruction tuning이 seen tasks와 unseen tasks 모두에서 모델의 instruction following ability를 향상시키고, generation의 전반적인 quality를 개선시키며, 나아가 모델에게 향상된 zero-shot 및 reasoning abilities이 부여됨을 보여주었다.
■ Alpaca, Vicuna, WizardLM, Baize, Koala를 포함한 여러 연구들은 larger foundational models이 생성한 outputs을 사용하여 smaller "student" language models을 학습시키기 위해 instruction tuning을 사용했다.
■ 이러한 behavior cloning은 student가 teacher model의 스타일을 모방하는 데 매우 효과적인 것으로 나타났다.
■ 그러나 이런 방식은 정답 여부가 단순히 스타일로만 판단되지 않는 knowledge-intensive 또는 reasoning-intensive tasks에서 한계를 보여주었다.
- instruction following ability가 통하지 않는 복잡한 논리나 지식이 필요한 문제에서는 틀린 답을 내놓는 경우가 많다.
■ 기존의 instruction tuning은 모델에게 새로운 지식을 가르치는 것보다 모델에게 task를 해결하는 방법을 가르치는 데 유익한 방법이기 때문이다.
■ 그러므로, instruction tuned models은 pre-training 과정에서 배운 지식(모델 파라미터에 내재된 implicit knowledge) 범위 내에서만 의존하여 추론을 수행할 수밖에 없다. small models은 파라미터 수가 적어 사용할 수 있는 지식이 더 제한적이다.
2.2 Explanation Tuning
■ instruction tuning의 약점 중 하나는 student model이 스타일적으로는 올바르지만, 궁극적으로는 틀린 output을 생성하는 법을 배울 수 있다는 것이다.
■ 예를 들어, 지나치게 간결한 target에 초점을 둔 instruction tuning은 student model에게 복잡할 수 있었던 추론 과정에 대한 정보를 충분히 학습시키지 못하게 만들기 때문에, 결과적으로 다른 tasks로의 일반화 능력을 저해시킨다.
■ Orca 1에서는 student를 더 풍부하고 표현력 있는 reasoning signals로 학습시킴으로써, 이러한 문제를 해결하기 위해 "Explanation Tuning"을 도입했다.
■ 이러한 signals을 얻는 메커니즘은 teacher model이 어떤 task에 대해 추론할 때 상세한 설명을 얻도록 제작된 system instructions이다.
■ system instructions은 LLM이 user prompts를 처리할 때 준수해야 하는 추가적인 high level guidelines이며, ChatML dialogue interface에서 "system" role flag에 의해 user prompts와 구분된다.
■ explanation tuning은 더 신중한 reasoning을 이끌어내기 위해 고안된 \( N \)개의 hand-crafted, general purpose system instructions을 사용한다.
- system instruction의 몇 가지 예로는 "think step-by-step", "generate detailed answers"
■ 이러한 system instructions의 주된 목적은 GPT-4와 같은 LLM으로부터 "Slow Thinking"의 demonstrations을 추출하는 것이다. 그런 다음, 이것들을 user prompts와 결합하여 (system instruction, user prompt, LLM answer)의 triplets으로 구성된 dataset으로 만든다.
■ student model은 여기서 나머지 두 개의 inputs(system instruction, user prompt==question)을 통해 LLM answer를 예측하도록 학습된다.
■ 만약, user prompts이 \( M \)개의 고유 클러스터로 그룹화된다고 하자. 같은 문제라도 GPT-4와 같은 유능한 LLM일수록, 다른 system instructions을 주면 다른 답변 방식이 나오기 때문에 결과적으로 \( M \times N \) 개의 다양한 답변을 생성할 수 있다.
■ 그러므로, 쉽게 학습 데이터의 양과 다양성을 증가(=training signals의 양과 다양성을 증가)시킬 수 있다.
■ Orca 1, StableBeluga, Dolphin과 같은 수많은 모델들이 이러한 explanation tuning을 활용하여, complex zero-shot reasoning tasks에서 기존의 traditional instruction-tuned models보다 상당한 개선을 입증했다.
3. Teaching Orca 2 to be a Cautious Reasoner
■ explanation tuning의 핵심은 system instructions을 기반으로 LLM에게 상세한 설명이 포함된 answers을 추출하는 것이다. 그러나 system instructions과 tasks 간 적절하지 않은 조합이 존재하며, system instruction에 기술된 strategy에 따라 model response quality가 크게 달라질 수 있다.
- 즉, task의 종류에 따라 적합한 system instruction, reasoning strategy이 다르다.

■ GPT-4와 같은 강력한 모델도 이러한 변동에 영향을 받는다.
- Fig 3은 story reordering question에 대해, GPT-4에 네 가지 다른 system instructions을 사용하여 얻은 네 가지 다른 answers이다.
- 첫 번째 답변(default answer)은 틀렸으며, 두 번째 답변(CoT prompt 사용)은 첫 번째 답변보다 더 낫지만 마찬가지로 정답이 틀렸다.
- 두 번째 답변은 모델이 step-by-step reasoning을 하고 있음을 볼 수 있지만, 결과 과정을 안내하는 세부 사항이 여전히 누락되어 있다. 세 번째 답변(explain-your-answer prompt 사용)은 틀렸지만 설명은 맞다.
- Fig 3에서 유일하게 정답을 맞춘 것은 네 번째 답변이며, 다음과 같은 system instruction을 사용하여 얻어진 결과이다.

■ 이렇게 GPT-4도 주어진 system instructions에 의해 상당히 영향을 받으며, 정교하게 제작된 system instruction을 사용하면 GPT-4 답변의 품질과 정확성을 크게 향상시킬 수 있다.
■ 이런 instruction이 없으면 GPT-4는 어려운 문제를 인식하는 데 어려움을 겪을 수 있으며, 신중한 사고 없이 즉답을 생성할 수 있다.
■ 저자들은 이러한 관찰에 따라, task의 종류에 따라 적합한 추론 전략이 다르다는 결론을 내렸다.
■ 이 논문의 focus는 "smaller models을 학습시키기 위한 best answer는 무엇인가?"이다. 저자들은 small models이 task에 따라 가장 효과적인 해결 전략을 선택하도록 가르쳐야 한다고 가정한다. 그 이유는
- (1) 최적의 전략은 task에 따라 다를 수 있다
- (2) smaller model을 위한 최적의 전략은 larger model의 전략과 다를 수 있다.
■ 예를 들어, GPT-4와 같은 모델은 쉽게 즉답을 생성할 수 있지만, smaller model은 이러한 능력이 부족하여 step-by-step thinking과 같은 다른 approach가 필요할 수 있다.
■ 그러므로, small model에게 추론 행동을 단순히 "imitate"하도록 가르치는 것은 차선책일 수 있다는 것이다.
■ step-by-step으로 전개된 추론 과정이 담긴 answer를 small model에게 학습시키는 것이 유익한 것으로 증명되었지만, 다수의 strategies로 학습시키면 task에 더 적합한 것을 선택할 수 있는 유연성을 가능하게 한다.
■ 논문에서는 주어진 task에 대해 어떤 해결 전략을 선택할지 결정하는 행위를 지칭하기 위해 "Cautious Reasoning"라는 용어를 사용한다.
■ 이 전략에는 즉답 생성(direct answer generation)이나 "Slow Thinking" strategies (step-by-step, guess and check or explain-then-answer 등) 중 하나가 포함된다.
■ Cautious Reasoning LLM의 training process는 다음과 같다.
- (1) 다양한 tasks의 collection에서 시작한다.
- (2) Orca의 성능을 지표로 삼아, 어떤 task가 어떤 해결 전략(예: direct-answer, step-by-step, explain-then-answer 등)을 필요로 하는지 결정한다.
- (3) 각 task에 대해 teacher responses을 얻기 위해, 선택된 전략에 상응하는 task-specific system instruction(s)을 작성한다.
- (4) Prompt Erasing: 학습 시, student의 system instruction을 task를 어떻게 풀어야 하는지에 대한 details이 제거된 generic 버전의 instruction으로 바꾼다.
■ (3) 단계에서는 teacher responses을 얻기 위해 multiple calls이나 매우 디테일한 instructions을 활용할 수 있다.
■ 이 접근법의 핵심 아이디어는, task에 어떻게 접근해야 하는지 상세히 기술했던 원래의 system instruction가 없더라도, student mode이 generic instruction과 문제, 그리고 teacher가 작성한 상세한 답변을 보고 "이런 유형의 문제는 이 전략으로 푸는 것이 best이다"라는 적절한 추론 전략 선택 능력을 배양시키는 것이다.
■ teacher가 추론의 틀을 잡았던 구조(원래의 system instruction)를 제거하기 때문에, 이 technique을 "Prompt Erasing"이라고 부른다.
4. Technical Details
■ Orca 2를 학습시키기 위해 ~817K 개의 training instances로 구성된 새로운 dataset을 구축했다. 이를 Orca 2 dataset이라고 부른다.
■ Orca 1을 따라, Orca 2를 progressive learning으로 학습시켰으며, original FLAN annotations, Orca 1 dataset, 그리고 Orca 2 dataset을 사용했다.
4.1 Dataset Construction
■ Orca 2 dataset의 main sources은 다음과 같다.
FLAN
■ synthetic data generation을 위한 프롬프트의 main source는 FLAN-v2 Collection이며, 이는 CoT, NiV2, T0, Flan 2021, Dialogue라는 5개의 sub collections로 구성되어 있다. 각 sub collection은 multiple tasks을 포함하고 있다.
■ Orca 1을 따라 CoT, NiV2, T0, Flan 2021 sub-collections의 tasks만 고려하며, 여기에는 총 1913개의 tasks이 포함된다.
■ FLAN의 1913개 tasks 중 일부는 다른 task를 inverting시켜 synthetically적으로 생성되었다.
- 예를 들어, question answering task를 question generation task로 변환하는 것
■ Cautious-Reasoning-FLAN dataset을 구축하기 위해, 1913개 tasks 중 1448개의 high quality tasks의 training split에서 약 602K 개의 ero-shot user queries을 선택했다.
■ 선택된 1448개의 tasks을 23개의 카테고리(예: Text Classification, Claim Verification, Data2Text, Text Generation, Logic, Math 등)로 그룹화했으며, 각 카테고리에 대해 하위 카테고리들로 더 나누어 총 126개의 하위 카테고리를 생성했다.
■ 하위 카테고리들은 동일한 하위 카테고리에 속한 모든 tasks이 동일한 system instruction을 공유한다.
■ 그리고 cautious reasoning을 위해, 모든 system instructions을 다음과 같은 generic system instruction으로 교체한다.

■ 논문에서는 이것을 "cautious system instruction"라고 부른다.
Few Shot Data
■ 위의 데이터셋은 프롬프트 내에 examples의 demonstrations을 포함하고 있지 않다. 모델이 few-shot demonstrations을 사용하는 방법을 가르치기 위해, 55K samples로 구성된 Few-Shot dataset을 구축했다.
■ 이 samples은 Orca 1 dataset의 zero-shot data를 re-purposing하여 구축되었다.
■ 구체적으로, Orca 1 data를 (task, system instruction, user prompt, answer) 튜플로 구조화하고 task 및 system instruction별로 그룹화하였다.
■ 각 그룹과 각 user prompt에 대해, 나머지 데이터에서 3~5개의 (user prompt, answer) pairs을 무작위로 선택하여 이를 in-context examples로 사용한다.
Math
■ Deepmind Math dataset과 기존 datasets의 training splits에서 약 160K math problems을 수집했다.
Fully synthetic data
■ GPT-4를 사용하여 2000개의 Doctor-Patient Conversations을 생성했다. 그런 다음 모델에게 conversation을 요약하여 네 가지(HISTORY OF PRESENT ILLNESS, PHYSICAL EXAM, RESULTS, ASSESSMENT AND PLAN)를 작성하도록 지시한다.
■ 여기서 두 가지 다른 프롬프트를 사용했다. 하나는 high-level의 task instruction가 포함된 것이고, 다른 하나는 모델이 누락이나 날조를 최소화하도록 하기 위한 detailed instructions이 포함된 것이다.
■ 이 데이터는 specialized skills의 learning을 평가하는 데 사용한다.
4.2 Training
Progressive Learning
■ LLaMA-2-7B/13B 체크포인트로, 먼저 FLAN-v2 dataset의 train split에 대해 1 epoch 동안 finetune한다. FLAN-v2 dataset은 zero-shot 및 few-shot problems을 모두 포함하고 있다.
■ 그런 다음, Orca 1에서 사용된 5M 개의 ChatGPT data로 3 epoch 동안 학습시킨다. 그 후 Orca 1의 1M 개 GPT-4 data와 Orca 2의 817K data를 결합하여 4 epochs 동안 학습시킨다.
- 한 번에 모든 데이터를 섞어서 학습시키는 것이 아니라 기초부터 학습시키기 위해 FLAN, Orca 1, Orca 2 순으로 단계적으로 학습시킨다.
Tokenization
■ LLaMA의 tokenizer를 사용하되, 가변 길이의 시퀀스를 처리하기 위해 [[PAD]]라는 패딩 토큰을 LLaMA tokenizer vocabulary에 추가한다.
■ 그리고 ChatML format을 지원하기 위해, ChatML special tokens인 <|im_start|>와 <|im_end|>를 추가한다. 그 결과로 vocabulary는 32,003개의 tokens을 포함한다.
Packing
■ 학습 속도를 높이고 계산 자원을 효율적으로 활용하기 위해, packing technique을 사용한다.
■ packing은 여러 input examples을 하나의 시퀀스로 연결하여 모델 학습에 사용하는 것이다. 연결된 시퀀스의 길이가 max_len = 4096 tokens을 초과하지 않도록 설정했다.
■ 저자들은 input examples을 섞은 다음, 각 그룹 내 연결된 시퀀스의 길이가 최대 max_len이 되도록 examples을 그룹으로 분할했다. 그런 다음 연결된 시퀀스에 패딩 토큰을 추가하여 입력 시퀀스 길이를 max_len으로 맞췄다.
Loss
■ Orca 2를 학습시키기 위해, 오직 teacher model에 의해 생성된 tokens(즉, teacher model response)에 대해서만 loss를 계산한다. 즉, 모델은 system instruction과 task instructions이 조건부로 주어졌을 때 response를 생성하는 것을 학습한다.
■ 이러한 접근 방식은 모델이 가장 관련성 높고 유익한 tokens로부터 학습하는 데 집중하도록 하여 학습 과정의 효율성과 효과를 향상시킨다.
5. Experimental Setup
5.1 Baselines
■ 모든 baseline models은 instruction-tuned models이다. instruction-tuned models을 사용하는 이유는, 이들이 instructions을 따르는 데 훨씬 뛰어나고, 더 강력한 reasoning capabilities을 가지며, zero-shot settings에서 훨씬 더 우수하다는 것이 여러 연구들에서 입증되었기 때문이다.
- (1) LLaMA-2 Models: LLaMA 2 series의 70B 및 13B 모델을 모두 사용한다. 구체적으로, LLaMA2-70B-hf-chat과 LLaMA2-13B-hf-chat을 사용한다.
- (2) WizardLM: WizardLM은 LLaMA 2의 instruction-tuned version으로, 다양하고 복잡한 instruction data를 자율적으로 생성하는 Evol-Instruct technique을 통해 튜닝되었다. 13B 및 70B 버전을 모두 사용한다.
- (3) Orca: Orca 1은 LLaMA model에 기반하여 explanations, step-by-step thought processes, complex instructions을 통해 학습된 13B 모델이다.
- (4) GPT Models: ChatGPT (GPT-3.5-Turbo)와 GPT-4의 성능을 확인하기 위해 사용한다.
■ inference에서, LLaMA2와 Orca 모델에는 fp32를 사용한다. WizardLM 모델의 경우 fp16으로 학습되었으므로 fp16을 사용할 수 있다.
5.2 Benchmarks
■ 평가는 각 데이터셋의 test split를 사용하여 수행되었으며, 모든 benchmarks과 models에 대해 zero-shot settings으로 평가를 수행한다.
■ reasoning과 같은 advanced capabilities, text completion과 같은 더 기본적인 abilities, 그리고 grounding, truthfulness, safety를 측정할 수 있는 benchmarks을 선택했다. benchmark 선택은 OpenLLM Leaderboard와 InstructEval을 따랐다.
- (1) Reasoning Capabilities: AGIEval, Discrete Reasoning Over Paragraphs (DROP), CRASS, RACE, Big-Bench Hard (BBH), GSM8K
- (2) Knowledge and Language Understanding: MMLU, ARC
- (3) Text Completion: HellaSwag, LAMBADA
- (4) Multi Turn Open Ended Conversations: MT-bench
- (5) Grounding and Abstractive Summarization: ACI-BENCH, MS-MARCO, QMSum
- (6) Safety and Truthfulness: ToxiGen, HHH, TruthfulQA, Automated RAI Measurement Framework
- Automated RAI Measurement Framework는 conversational setting에서 챗봇 모델의 safety를 평가하기 위해 제안된 프레임워크로, 하나의 LLM이 user인 척하며 테스트 대상 LLM과 대화에 참여하여 잠재적인 harmful content, IP leakage, jailbreaks 여부를 평가한다.
5.3 Evaluation Settings
■ 모든 tasks에 대해 exemplars나 CoT prompting이 없는 zero-shot setting으로 모델의 능력을 평가한다. 그리고 모든 실험에서 greedy decoding을 사용한다.
Prompts
■ 프롬프트 엔지니어링으로 인한 품질 변화를 피하기 위해, 일부 task의 answer formats에 대한 일반적인 가이드라인을 제외하고는 모든 모델에 대해 empty system messages와 simple prompts를 사용하였다.
■ 그리고 다양성을 최소화하고 신뢰할 수 있는 평가 프로세스를 만들기 위해, system messages에 answer 추출의 정확도를 높이기 위한 formatting 가이드라인을 포함시켰다.
- 예를 들어, 마지막에 "###Final answer: {answer choice}를 출력하라"나 "제공된 선택지 중에서 answer를 선택하라"와 같은 system message
- Appendix F에서 각 데이터셋에 사용된 프롬프트를 볼 수 있다.
■ Orca 2는 "empty" system message와 "cautious" system message 두 가지 경우의 성능을 reporting한다.
Answer parsing
■ generative model의 free-form responses에서 answers을 파싱하는 것은 어려운 작업이다. 그래서 저자들은 task의 유형과 필요한 추출 방식에 따라 평가 작업을 다음 3가지 카테고리로 나누었다.
- (1) MCQ (Multiple-Choice Questions): 모델이 final answer로 선택한 선택지를 추출한다. classification tasks에서도 이 방법으로 포맷팅했는데, 여기서 class들은 모델이 선택해야 할 선택지들이다. 이러한 tasks의 프롬프트는 질문과 그 뒤를 잇는 정답 선택지들로 구성된다.
- (2) Exact Match/Span Extraction: response 내에서 정확한 final answer를 추출하거나, 제공된 context에서 특정 span을 추출한다.
- (3) No extraction required: 추출이 필요 없는 tasks이다. 예를 들어, open-ended question answering이 이 카테고리에 속한다.
■ 모델의 free-form format response에서 추출이 필요한 경우(MCQ 및 Exact Match/Span Extraction), answer를 포함할 가능성이 있는 부분을 찾기 위해 "Final answer", "So, the answer is", "Final option:"와 같은 다양한 패턴을 사용한다.
■ 그런 다음 정규표현식을 사용하여 선택지 ID(예: A, B, C)나 모델이 정답으로 선택한 선택지의 텍스트를 추출한다.
■ 그리고 파싱 로직이 답변을 성공적으로 추출한 샘플의 비율인 Format-OK 지표도 계산한다. 이는 모델이 지시된 출력 형식을 얼마나 잘 따르는지 측정하기 위함이다.
■ 공정한 비교를 위해 모든 모델들의 responses에 동일한 파싱 로직을 적용한다. 그러나 모델들이 항상 이러한 formatting 가이드라인을 준수하여 output을 생성하지는 않지만, 모든 모델에 동일하게 적용되었으므로 비교는 유효하다.
6. Evaluation Results
6.1 Reasoning

■ Fig 4는 AGIEval, BBH, DROP, RACE, GSM8K, CRASS와 같은 벤치마크에 대한 평균 성능을 나타낸 것이다.
■ Orca-2-13B는 zero-shot reasoning tasks에서 동일한 크기의 모델들을 능가한다. 주목할 점은 Orca-2-13B, LLaMA-2-Chat-13B, WizardLM-13B 세 모델 모두 동일한 베이스 모델(LLaMA-2)를 사용한다는 것이다. 이는 Orca 2에 사용한 학습 과정의 효용성을 보여주는 결과이다.
■ 더 나아가, Orca-2-13B는 LLaMA-2-Chat-70B의 성능을 넘어서며 WizardLM-70B 및 ChatGPT와 대등한 성능을 보인다.
■ 7B 및 13B 모델 모두 cautious system message를 사용하는 것이 empty system message를 사용했을 때보다 작은 gains이 있다.
6.2 Knowledge and Language Understanding

■ Table 2는 knowledge and language comprehension benchmarks에 대한 결과이다. 전반적으로, 위의 reasoning tasks에서의 결과와 유사하다.
■ Orca-2-13B는 LLaMA-2-Chat-13B와 WizardLM-13B뿐만 아니라, 70B baseline models도 능가한다. 추가로, Orca-2-7B는 ARC 테스트 세트에서 두 70B baselines을 모두 능가한다.
6.3 Text Completion
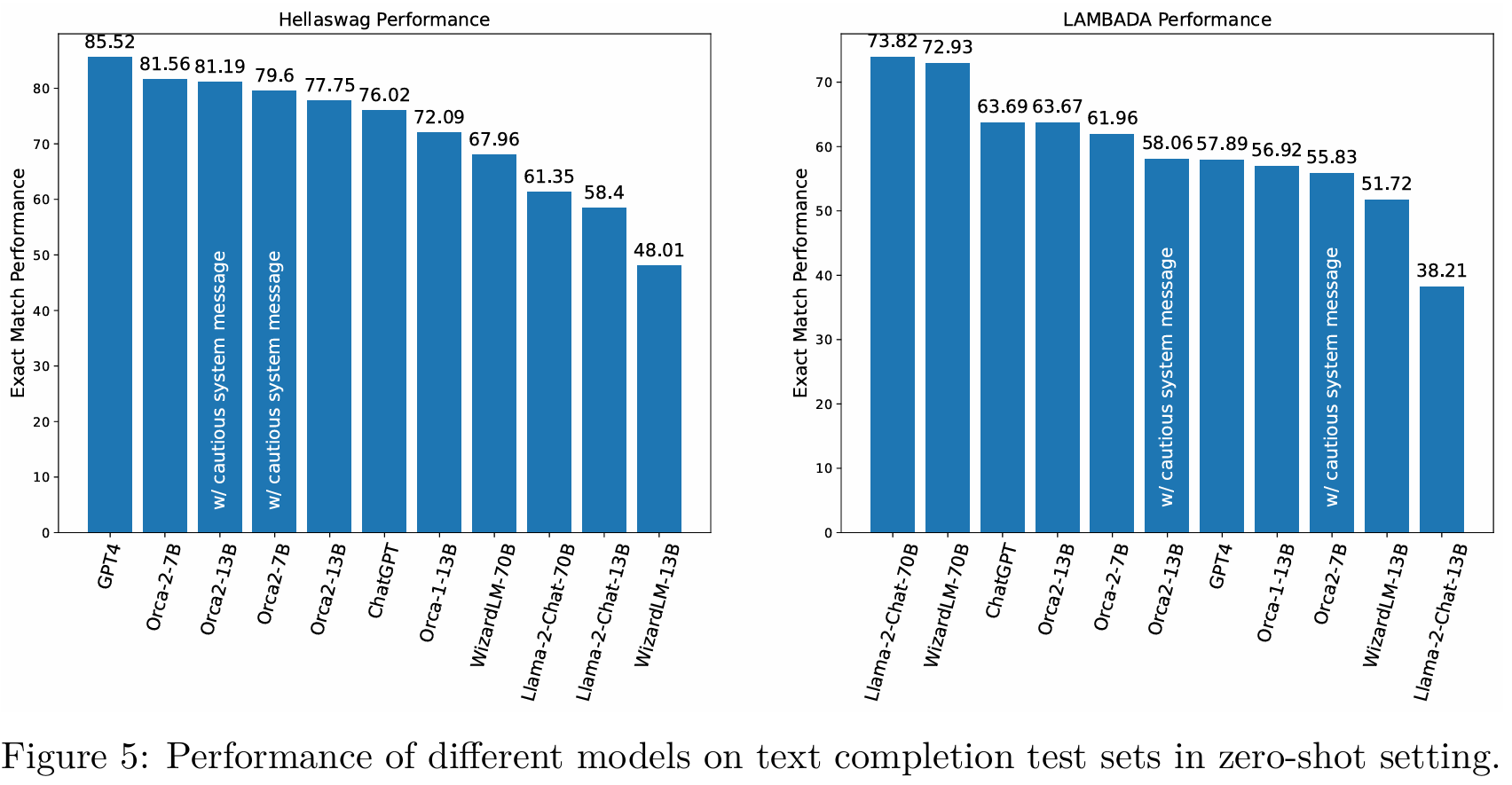
■ Orca-2-7B와 Orca-2-13B 모두 HellaSwag에서 강력한 성능을 보이며 13B 및 70B baselines을 능가한다.
■ 추가로, HellaSwag에서 LLaMA-2-13B(베이스 모델)가 LLaMA-2-Chat-13B(챗 모델)보다 훨씬 높은 성능을 보였으며, 저자들이 LLaMA-2-Chat-13B와 LLaMA-2-Chat-70B의 responses을 무작위로 샘플링하고 직접 검토한 결과, 실제로 많은 answers이 틀렸으며, 모델이 부적절하게 안전 우려를 이유로 답변을 거부하는 사례가 있었다고 한다.
■ 이는 챗 모델이 HellaSwag와 같은 text completion tasks에서 적합하지 않을 수 있음을 시사한다.
6.4 Multi-Turn Open Ended Conversations
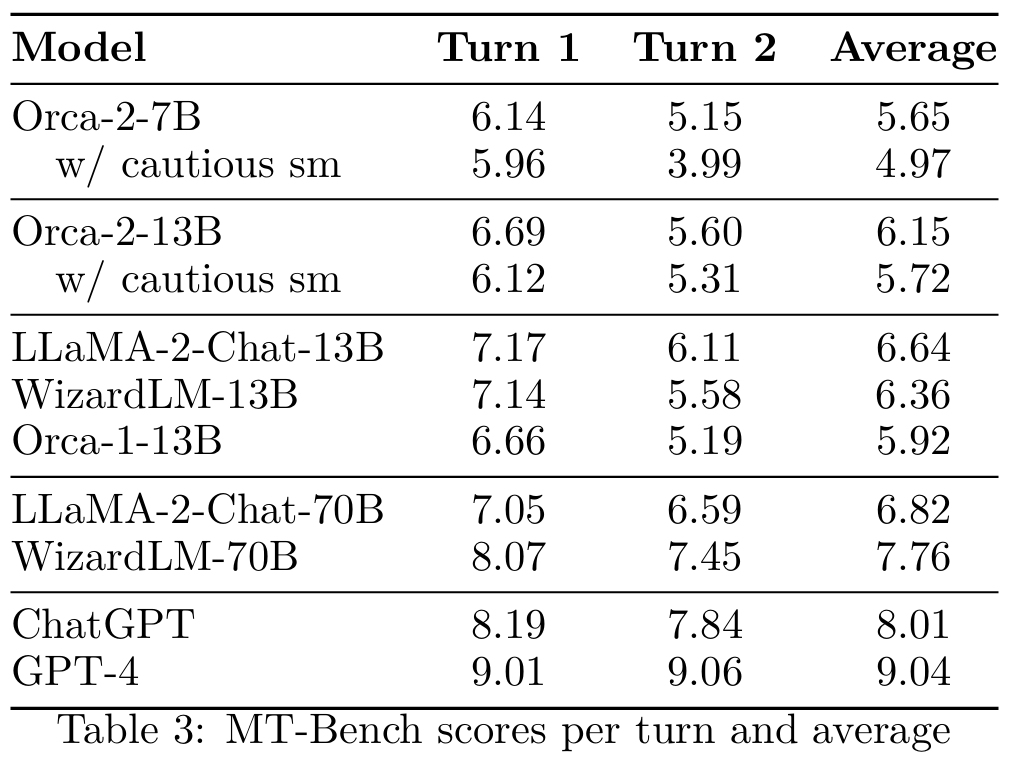
■ MT-Bench는 평가 목적으로 GPT-4를 사용한다. 각 턴마다 GPT-4를 사용하여 1점에서 10점 사이의 점수를 계산한다. 이렇게 계산한 턴별 점수와 평균 점수는 Table 3에서 확인할 수 있다.
■ 서로 다른 GPT-4 엔드포인트들을 사용하여 점수를 산출할 경우, 각 엔드포인트마다 서로 다른 평가 결과를 산출하는 문제가 있다. 이런 문제를 최소화하기 위해, 저자들은 평가 수행에 동일한 GPT-4 엔드포인트와 버전을 사용했다.
■ Orca-2-13B는 다른 13B 모델들과 대등한 성능을 보인다. Orca-2-13B의 평균 두 번째 턴 점수는 첫 번째 턴 점수보다 낮은데, 이는 training data에 conversations이 부족하기 때문으로 볼 수 있다.
6.5 Grounding
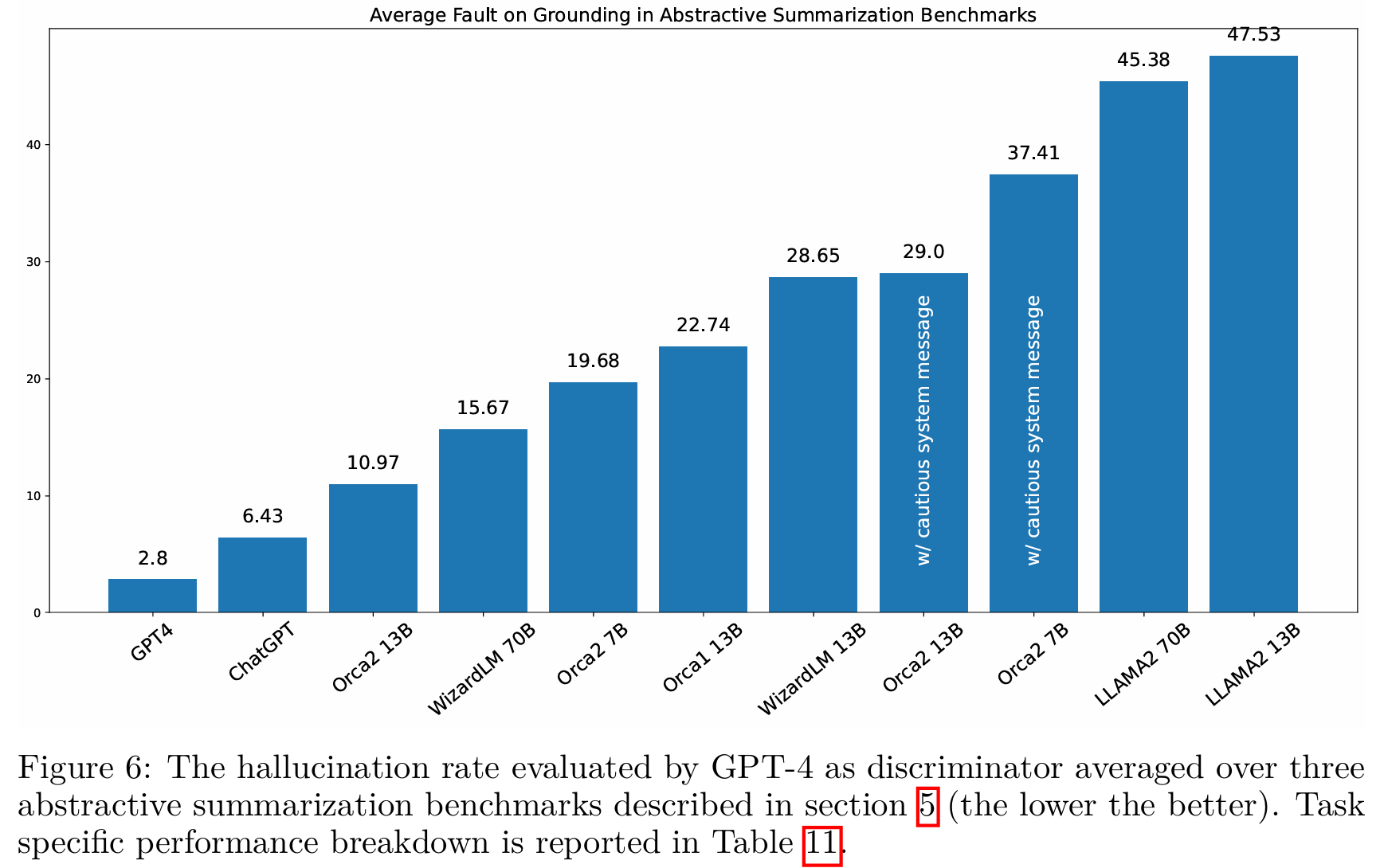
■ query-based meeting summarization, long format의 answers이 생성되는 web question answering, 그리고 doctor-patient conversation summarization을 통해 특정 문맥에 기반한(grounded) responses을 생성하는지 평가한다.
■ 이전 연구에서 제안된 grounding evaluation framework를 사용한다. 이 프레임워크는 in-context groundedness를 측정하기 위해 GPT-4를 judgement로 사용한다.
■ 단, judgement로 모델을 사용하는 것은 모델에 따라 한계가 있을 수 있다. 예를 들어, 모델이 자신이 생성한 것, 긴 텍스트, 또는 특정 순서(예: 첫 번째 답변)의 샘플과 같은 특정 특성을 가진 샘플을 선호하는 경향이 있을 수 있음을 여러 연구들에서 보여주었다.
■ Fig 6은 세 가지 벤치마크에 대해 평균을 낸, 서로 다른 모델들의 hallucination rate이다. Orca-2-13B가 모든 Orca 2 변형 및 다른 13B, 70B LLM들 중에서 가장 낮은 hallucination rate를 보인다.
■ 그러나 cautious system message를 사용할 경우 높은 hallucination rate를 보인다. 저자들이 직접 검토한 결과, cautious 메시지를 받은 모델이 그럴듯한 내용이지만, 주어진 context에 없는 내용을 추가로 생성했다고 한다.
- 이는 cautious system message로 추론 능력이 향상된 모델이 추론 능력을 지나치게 발휘해서 지나친 추측으로 이어진 것으로 볼 수 있다.
6.6 Effect of Task-Specific Data with Story Reordering

■ Fig 3의 프롬프트를 사용하여 story reordering을 위한 5,000개의 training samples을 생성했다. 이 data를 나머지 training dataset과 혼합하고, ROCStories corpus의 distinct set에서 Orca 2를 평가했다.
■ data contamination을 방지하기 위해 FLAN training split에 포함된 ROCStories의 instances을 모두 제거했다.
■ Fig 12는 다양한 system messages을 사용한 GPT-4와 Orca 2의 성능을 비교한 것이다. 이 실험은 "prompt erasing"으로 생성된 synthetic data를 통해 특정 task에 대해 specializing하면, large model도 능가할 수 있음을 보여준다.
7. Limitations
■ Orca 2의 성능은 튜닝 데이턴의 분포에 강하게 의존하고 있을 가능성이 높다. 그래서 학습 데이터에서 과소대표된 영역에서 성능이 제한될 수 있다.
■ 그리고 Orca 2는 system instructions에 따라 성능이 달라진다. 또한 모델 크기로 인해 non-deterministic responses 생성으로 이어질 수 있다.
■ 또한, 주로 zero-shot settings에 대한 데이터로 학습되어 zero-shot setting에서는 강력한 성능을 보여주지만, few-shot에서의 성능 향상은 zero-shot만큼 크지 않다.
■ synthetic data로 학습되었기 때문에, 데이터 생성에 사용된 모델과 methods의 장단점을 그대로 물려받을 수 있다.
■ 마지막으로, 저자들이 제안한 접근법은 모델에게 task를 어떻게 해결해야 할지 문제 해결 방법을 가르치는 것이지, 새로운 knowledge를 가르치는 것이 아니다.
■ 그러므로 knowledge는 pre-training에서 습득한 knowledge로 제한된다. 따라서 Orca 2는 모델에게 제공된 knowledge 위에서 추론하거나, 특정 도메인에 특화될 때 가장 효과적일 수 있다.
