■ 논문에서는 일반적인 프롬프팅 방법으로는 해결하기 어려운 복잡한 reasoning problems을 해결하기 위해, task 고유의 reasoning 구조를 스스로 발견하도록 돕는 general framework인 self-discovery를 제안한다.
[2402.03620] Self-Discover: Large Language Models Self-Compose Reasoning Structures
Self-Discover: Large Language Models Self-Compose Reasoning Structures
We introduce SELF-DISCOVER, a general framework for LLMs to self-discover the task-intrinsic reasoning structures to tackle complex reasoning problems that are challenging for typical prompting methods. Core to the framework is a self-discovery process whe
arxiv.org
1. Introduction
■ LLM의 추론(reason) 능력과 복잡한 문제 해결 능력을 향상시키기 위해, 인간이 추론하는 방식에 대한 인지 이론에서 영감을 받은 다양한 프롬프팅 방법들이 제안되었다.
- 예를 들어, (1) few-shot 및 zero-shot chain-of-thought은 인간이 단계별로(step-by-step) 문제를 해결하는 방식과 유사하며,
- (2) decomposition-based prompting은 인간이 복잡한 문제를 일련의 하위 문제로 나누고 이를 하나씩 해결하는 방식에서,
- (3) step-back prompting은 인간이 task의 본질을 파악하여 task에 대한 일반적인 원칙들을 도출하는 방식에 영감을 받았다.
■ 그러나 기존 방법들의 근본적인 한계는 모든 문제에 대해 하나의 고정된 방식을 사용한다는 것이다.
- 어떤 문제는 step-by-step으로 접근하는 CoT가 맞지만, 어떤 문제는 잘게 쪼개는 것(decomposition)이 맞다.
- decomposition이 필요한 문제에서 CoT만 쓰면 문제에서 성능이 떨어질 수 있다.
■ 저자들은 각 task마다 고유한 intrinsic structure를 가지고 있다고 가정한다. 즉, 문제마다 그 문제를 해결하기 위한 방법이 다르다는 것이다.
- 예를 들어 symbolic manipulation이나 compositional generalization과 같은 task에서는 task의 decomposition structure때문에 CoT보다 least-to-most prompting을 사용하는 것이 훨씬 더 효과적임이 입증된 바 있다.
■ 저자들은 모델이 각 task마다 고유한 reasoning structure를 스스로 발견(self-discovering)하면서도 연산 측면에서 매우 효율적인 방법을 찾고자 하였다.
■ "self-discover"는 인간이 문제 해결을 위해 내적으로 reasoning program 고안하는 방식에서 영감을 받았다. (Fig 2)
■ "breakdown into sub tasks(하위 작업으로 분해하기)", "critical thinking(비판적 사고)"와 같이 자연어로 기술된 atomic reasoning modules의 set과 LLM, 그리고 labels이 없는 task examples이 주어지면, self-discover는 task에 내재된 일관된 reasoning structure를 발견하고(stage 1), 발견한 reasoning structure를 사용하여 해당 task의 문제들을 해결(stage 2)한다.
■ stage 1은 task-level에서 작동하며 세 가지 action을 사용하여 LLM이 task에 맞는 reasoning structure를 생성하도록 유도하는 단계이다.
■ stage 2는 최종 디코딩 중에 LLM이 단순히 self-discovered된 reasoning structure를 따라가며 final answer에 도달하는 단계이다.
■ 이러한 self-discover는 다른 LLM reasoning methods과 비교했을 때, 다음과 같은 장점들을 가진다.
- (1) 하나의 reasoning module(예: CoT)만 사용하는 게 아니라 다양한 reasoning modules을 사용하기 때문에, 다양한 reasoning modules의 장점을 활용할 수 있다.
- (2) 연산 측면에서 효율적이다. task-level에서 단 3번의 추가적인 inference steps만 사용해도, self-consistency와 같이 inference cost가 많이 드는 앙상블 접근법보다 더 높은 성능을 달성한다.
- (3) self-discover를 통해 발견된 reasoning structure는 task-intrinsic한 reasoning structure이기 때문에, 다른 프롬프트 방법들보다 LLM이 해당 task에 대해 가진 통찰력을 훨씬 더 해석 가능한 방식으로 전달할 수 있다.
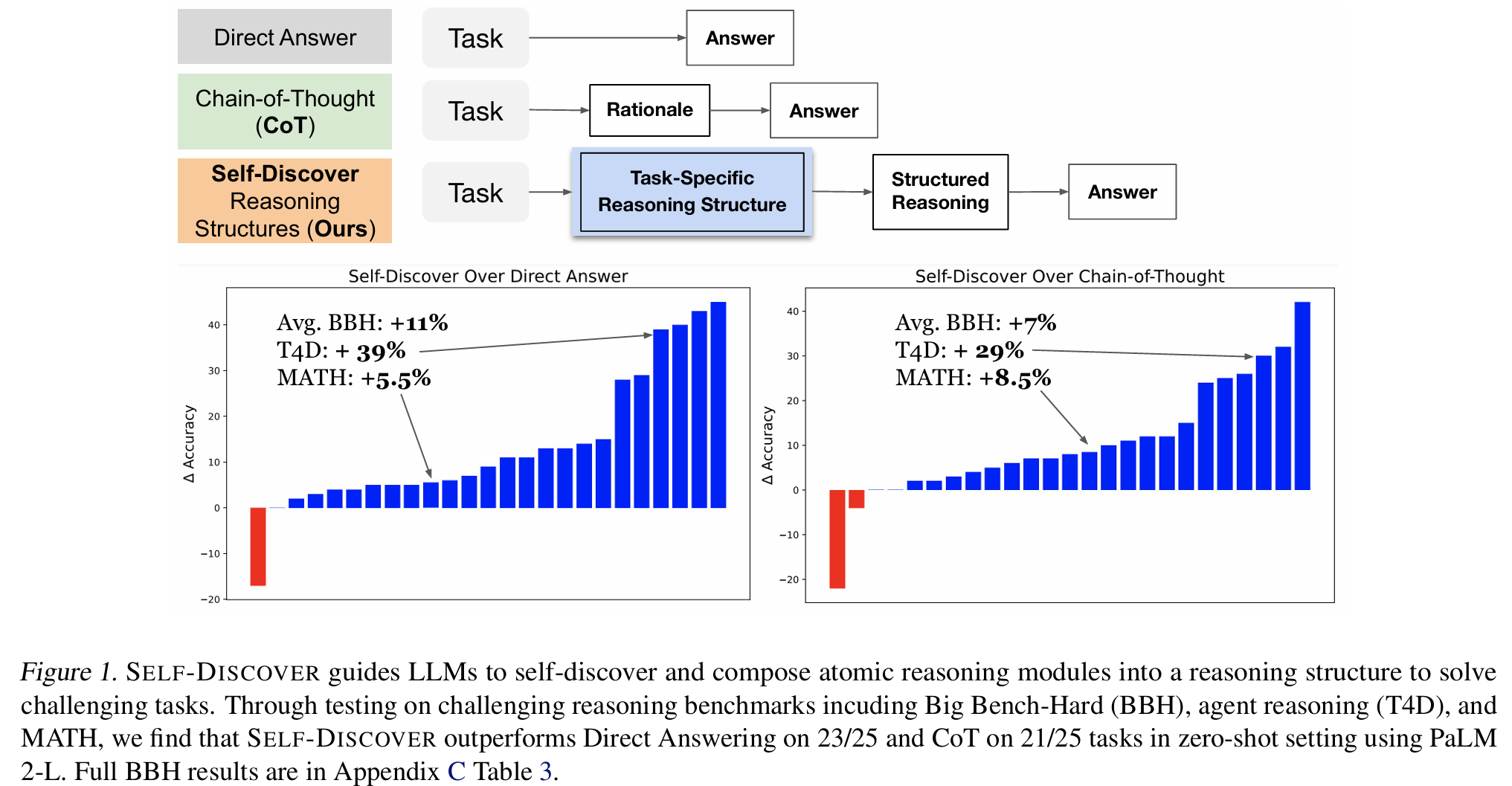
■ self-discover는 challenging reasoning tasks 중 21개의 tasks에서 CoT를 능가하며, 최대 42%의 성능 향상을 보인다. (Fig 1)
■ 그리고 우수한 성능을 달성하면서도, 다른 방법들보다 10~40배 더 적은 inference compute를 필요로 한다. 특히, 성능의 경우 world knowledge가 필요한 tasks에서 우수한 성능을 보인다.
■ 또한, 서로 다른 모델 간의 transferability 실험을 통해 저자들의 접근법이 universality함을 보여준다.
2. Self-Discovering Reasoning Structures for Problem-Solving

■ 저자들은 인간이 사전 지식과 skills을 활용하여 문제 해결을 위한 reasoning program을 고안하는 방식에서 영감을 얻었다.
■ 일반적으로 사람은 새로운 문제에 직면했을 때, 먼저 (1) 이전 경험에서 어떤 knowledge와 skills이 문제 해결에 도움이 될지 먼저 확인한다. 그런 다음, (2) 문제 해결에 도움이 될 수 있는(즉, 문제와 관련된) knowledge와 skills을 해당 문제에 적용하려고 시도한다. (3) 최종적으로, 서로 다른 다양한 skills과 knowledge를 연결하여 문제를 해결한다.
■ 저자들은 self-discover가 Fig 2에 묘사된 것처럼, 이러한 단계들을 두 번의 stage로 실행하도록 설계했다.
■ "Use critical thinking", "Let’s think step by step"과 같은 높은 수준의 문제 해결 heuristics을 나타내는 reasoning module descriptions의 set이 주어졌을 때, self-discover의 stage 1에서는 meta-reasoning을 통해 해당 task를 해결하기 위한 intrinsic reasoning structure를 밝혀내는 것을 목표로 한다.
■ 구체적으로, 세 가지 meta-prompts을 사용하여 LLM이 label이나 training 없이도 reasoning structure를 "select"하고, "adapt"하고, "implement"하도록 유도한다.
■ 그리고 reasoning structure를 JSON과 유사한 key-value pairs으로 포맷팅하는데, 이는 해석 가능성 때문이며 JSON 형식을 따르는 것이 reasoning 및 generation quality를 높인다는 이전 연구들의 결과에 근거한 것이다.
- meta-prompts 및 full prompts은 Appendix에서 볼 수 있다.
■ stage 1에서 각 task에 대해 self-discover를 단 한 번만 실행한 다음, stage 2에서는 모델에게 제공된 structure를 따라 각 key에 해당하는 내용을 채우고 final answer에 도달하도록 모델을 instruct함으로써, discovered된 reasoning structure를 사용하여 해당 task의 모든 instance를 간단히 해결할 수 있다.
2.1 Stage 1: Self-Discover Task-Specific Structures
■ stage 1은 다음과 같은 세 가지 actions로 구성된다.
- 1) SELECT: task-solving에 적합한 reasoning modules을 reasoning module descriptions의 set에서 선택
- 2) ADAPT: 선택된 reasoning modules의 descriptions을 task에 더 fit하게 재구성
- 3) IMPLEMENT: adapted된 reasoning descriptions을 structured actionable plan으로 구현하여, 이 structure를 따름으로써 task를 해결할 수 있도록 한다.

SELECT
■ 모든 reasoning module이 항상 모든 task에 도움이 되는 것은 아니다. 그래서 self-discover의 first stage에서는 task examples을 기반으로 유용한 modules을 선택하도록 모델을 유도한다.
■ "critical thinking", "break the problem into sub-problems"와 같은 reasoning module descriptions의 raw set \( D \)와 labels이 없는 few task examples \( t_i \in T \)가 주어졌을 때, self-discover는 먼저 model \( \mathcal{M} \)과 meta-prompt \( p_S \)를 사용하여 task-solving에 도움이 되는 reasoning modules의 subset \( D_S \)를 선택한다.
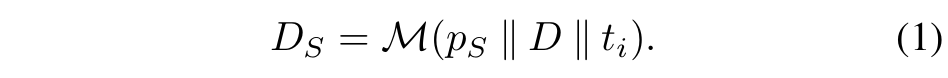
- 식 (1)처럼 model \( \mathcal{M} \)에게 meta-prompt \( p_S \), reasoning module list \( D \), few task examples \( t_i \)를 연결해서 입력으로 주면, model이 스스로 판단하여 \( D_S \)를 출력한다.
ADAPT
■ 각 reasoning module은 문제 해결 방법에 대한 범용적인 description을 제공할 뿐이다. 그래서 SELECT의 next step에서는 선택된 module을 풀고자 하는 task에 맞게 adapt하는 것을 목표로 한다.
■ 예를 들어 arithmetic problems의 경우, general description인 "break the problem into sub problems"를 더 구체적으로 "calculate each arithmetic operation in order"와 같은 task-specific description으로 adapt하는 것이다.
■ 이렇게 SELECT step에서 선택된 \( D_S \)가 주어지면, ADAPT step에서는 선택된 각 module을 해당 task에 더 구체적이 되도록 재구성한다.
■ SELECT와 유사하게, meta-prompt \( p_A \)와 generative model \( \mathcal{M} \), 그리고 \( t_i \)를 사용하여 adapted된 reasoning module descriptions \( D_A \)를 생성한다.

IMPLEMENT
■ 마지막으로 \( D_A \)가 주어지면, reasoning modules이 각 단계에서 무엇을 생성해야 하는지에 대한 specified instruction(예: 이 문제는 1단계에는 ~를 하고, 2단계에는 ~를 하라)가 포함된 reasoning structure \( D_I \)를 구체화한다.
■ 이를 위해 meta prompt \( p_I \) 외에도, natural language descriptions을 reasoning structure로 더 잘 변환하기 위해 다른 task에 대해 사람이 작성한 reasoning structure의 demonstration \( S_{human} \)을 model \( \mathcal{M} \)에게 제공한다.
- 모델이 구조화된 format(key-value pairs)을 잘 생성하도록, 사람이 작성한 모범 답안(demonstration of a human-written reasoning structure)을 가이드라인으로 주는 것이다.

2.2 Stage 2: Tackle Tasks Using Discovered Structures
■ stage 1의 three stages(SELECT, ADAPT, IMPLEMENT)을 거친 후, 해결해야 할 task \( T \)에 uniquely하게 adapted된 reasoning structure \( D_I \)를 얻을 수 있다.
■ 그런 다음, 단순히 이 reasoning structure를 task의 모든 instances에 덧붙이고, 모델이 answer \( A \)를 생성하기 위해 덧붙인 reasoning structure를 따르도록 프롬프트한다. (식 (4))
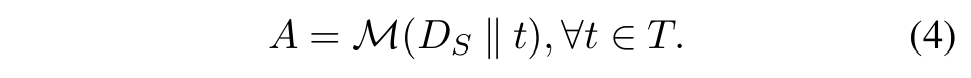
3. Experiment Setup
3.1 Tasks
■ LLM이 풀기 어려워하는 고난도 문제들을 모아놓은 BIG-Bench Hard (BBH)에서 self-discover를 평가한다.
■ BBH tasks은 (1) Algorithmic and Multi-Step Arithmetic Reasoning (2) Natural Language Understanding (3) Use of World Knowledge (4) Multilingual Knowledge and Reasoning이라는 4가지 범주에 걸쳐 광범위한 reasoning problems을 포괄하고 있다.
■ 그리고 Thinking for Doing (T4D)이라 불리는 social agent reasoning task에서도 self-discover를 평가한다.
■ T4D에서 모델은 수행할 행동을 결정하기 위해 mental state reasoning을 활용해야 하는데, 여기서 CoT를 사용한 GPT-4조차 약 50%의 성능밖에 내지 못한다.
■ 마지막으로, MATH test set에서 200개의 examples을 subsample하고, one-shot demonstration을 통해 instance-level의 reasoning structures을 생성한다.
- MATH는 경시 대회 수준의 문제로 구성된 벤치마크이다. 난이도가 높고 문제마다 유형이 너무 달라서, 일반적인 task-level의 structure로는 부족할 수 있다.
- 따라서 MATH에 한해서는 개별 문제(instance)마다 reasoning structure를 생성하는 방식을 사용한 것으로 보인다.
Appendix B. Evaluation Details
■ BBH, T4D, MATH에서 평가를 수행한 이전 연구들과 마찬가지로, accuracy와 exact matching을 평가 지표로 사용한다.
■ 이를 위해, LLM이 "Thus, the final answer is [X]"라는 문구로 answer를 적도록 프롬프트한다. 여기서 X는 'A'와 같은 선택지이거나 'valid'와 같은 문자열이다.
■ LLM이 각 task에 대해 출력한 결과물들을 직접 검토했으며, final answer를 추출하기 위한 heuristics을 사용했다.
■ MATH dataset은 answer를 정확하게 추출하는 것이 까다롭기 때문에, MATH dataset에서 200개의 test examples만 subsample하여 규모를 줄였다.
■ 그리고 테스트된 모든 방법론에 대해, 추출된 answers을 직접 검증한다.
3.2 Models
■ SOTA LLM들을 사용한다: GPT-4, GPT-3.5-turbo (ChatGPT), instruction-tuned된 PaLM 2-L, Llama2-70B
■ MATH의 경우, 더 복잡한 reasoning structures에 대한 instruction following 능력을 높이기 위해 더 강력하게 instruction-tuned된 PaLM 2-L을 사용한다.
3.3 Baselines
■ self-discover를 LLM reasoning을 위한 다른 zero-shot prompting methods과 비교한다.
- (1) Direct Prompting: intermediate reasoning steps 없이 모델이 answer를 생성
- (2) CoT: 모델이 final answer로 이어지는 reasoning process를 생성하도록 유도
- (3) Plan-and-Solve: 모델이 먼저 plan을 생성한 다음 문제를 풀도록 유도
- self-discover는 reasoning structure를 atomic reasoning modules에 기반하게 한다는 점, 그리고 디코딩 시 key-value reasoning structure를 따르도록 유도한다는 점에서 이와 다르다.
■ 그리고 self-discover에서 사용하는 reasoning modules을 활용하는 다른 baselines도 고려한다.
- (1) CoT-Self-Consistency: LLM에서 CoT를 사용하여 여러 outputs을 샘플링하고 answers을 집계하여 final answer를 도출한다. 단, self-consistency의 비용 때문에 일부 tasks에서만 비교한다.
- (2) Majority voting of each RM: 각 reasoning module (RM)을 덧붙여 task를 해결하도록 모델에 프롬프트하고, 모든 answers에 대해 majority voting을 사용하여 final answer를 얻는다.
- 여러 개의 RM을 하나의 일관된 reasoning structure로 통합하는 것이, 각 RM을 개별적으로 적용해 task를 해결한 뒤 앙상블하는 방식(Majority voting of each RM)보다 유리한지 확인한다.
- (3) Best of each RM: 이 방법은 oracle labels에 접근할 수 있다고 가정하고, 각 RM을 적용했을 때 가장 높았던 accuracy를 사용한다.
■ 더 나아가, reasoning structures의 universality를 분석하기 위해, prompts을 개선하기 위해 training set을 필요로 하는 프롬프트 최적화 방법인 OPRO(LLMs as optimizers)와 비교한다.
■ 이 실험에선 한 모델에서 최적화된 reasoning structures이나 prompts을 다른 모델에 적용했을 때, reasoning structures이 prompts의 wordings보다 더 많은 performance gain을 얻을 수 있는지 확인한다.
4. Results
4.1 Does SELF-DISCOVER Improve LLM Reasoning?
Overall, SELF-DISCOVER improves PaLM2-L and GPT 4’s reasoning across diverse set of reasoning tasks

■ Table 1은 BBH, T4D, MATH에 대한 결과이다. self-discover를 direct prompting, CoT, Plan-and-Solve (PS)와 비교했을 때, self-discover를 사용한 PaLM 2-L과 GPT-4는 CoT와 PS에 비해 일관되게 더 나은 성능을 보인다.
■ PaLM-2 + self-discover의 direct answering 및 CoT 대비 각 task별 성능 향상에 대한 수치는 Fig 1에 나와 있다. 여기서 self-discover가 24개 중 20개 이상의 tasks에서 이들을 능가했다고 한다.
■ BBH에서는 self-discover가 24개 중 20개 이상의 tasks에서 direct answering과 CoT를 능가한다. (Appendix C, Table 3)
■ T4D에서 self-discover는 PaLM 2-L/GPT-4 기준 모든 베이스라인 대비 27%/32% 이상의 향상을 달성했다. 기존 SOTA인 FaR은 사람(전문가)가 설계한 reasoning structure를 사용한다. 반면, self-discover는 인간의 개입 없이 스스로 reasoning structure를 설계한다.
■ MATH의 경우, 약간의 성능 향상을 기록했다. error analysis (Appendix D) 결과, self-discover를 통해 PaLM 2-L이 생성한 reasoning structures은 87.5%가 올바른 것으로 나타났다.
■ 실패의 대다수는 계산을 실행하는 과정에서의 오류(74.7%)에서 비롯되었으며, 이는 선행 연구 결과와 일치한다.
4.2 Which Types of Problems Do SELF-DISCOVER Help the Most?
SELF-DISCOVER performs best on tasks that require diverse world knowledge
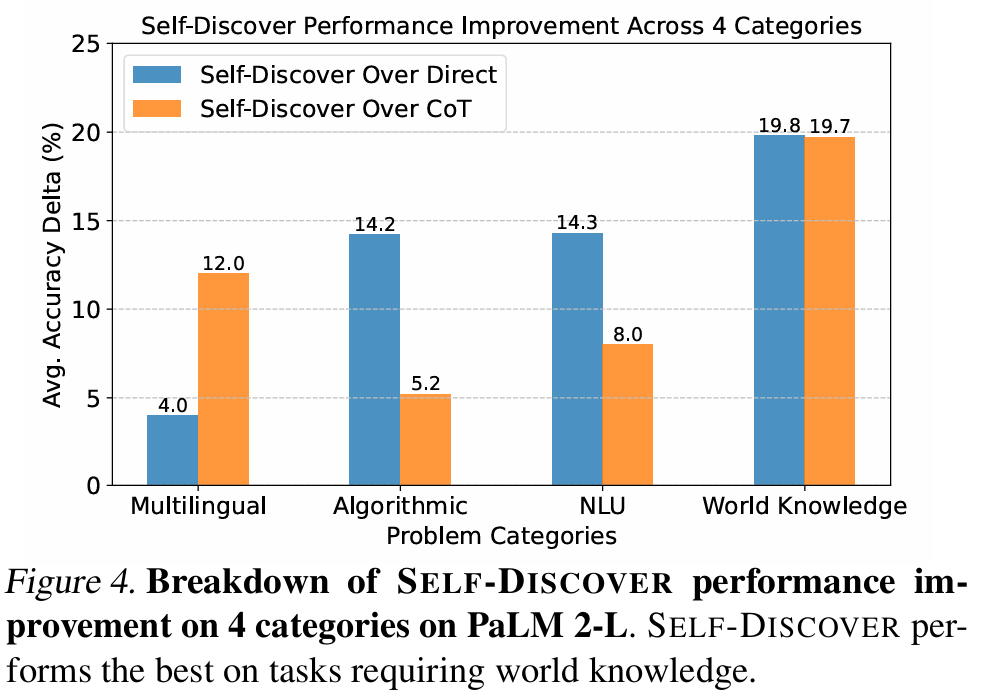
■ Fig 4는 reasoning tasks의 4가지 카테고리에 대해, direct answer 및 CoT 대비 self-discover의 accuracy 변화량 측면에서의 평균적인 성능 향상을 나타낸 것이다.
■ 모든 카테고리에서 self-discover는 이 두 가지 베이스라인보다 향상된 성능을 보이며, 특히 sports understanding, movie recommendation, ruin names와 같이 world knowledge를 필요로 하는 tasks에서 우수한 성능을 달성했다.
■ 이러한 tasks은 모델이 fact와 일반적인 commonsense knowledge를 사용하여 추론할 것을 요구한다. 저자들은 이 결과에 대해 다양한 관점의 여러 reasoning modules을 통합했기 때문이라고 추측한다.
■ 여러 reasoning modules을 통합해서 사용하는 다각적인 접근이 commonsense knowledge와 fact를 연결해야 하는 문제에서 더 풍부한 reasoning을 가능하게 하기 때문이다.
■ Algorithmic의 경우 performance gain이 크지 않는데, 이는 섹션 4.1의 MATH에 대한 결과와 일치한다. reasoning structure를 잘 설계해도 모델이 단순 계산 실수를 범하는 한계가 있었기 때문이다.
4.3 How Efficient is SELF-DISCOVER?
SELF-DISCOVER achieves better performance whilere quiring10-40x fewer inference computer compared to self-consistency or majority voting

■ Fig 5는 GPT-4를 사용한 각 방법에 대해 인스턴스당 average accuracy와 inference calls 횟수를 나타낸 것이다.
■ accuracy 측면(y축)에서, self-discover가 CoT-self-consistency나 각 RM을 적용한 majority voting과 같이 반복적인 inference calls을 요구하는 베이스라인들보다 뛰어난 성능을 보임을 확인할 수 있다.
■ 효율성 측면(x축, inference call 횟수)에서, self-discover는 인스턴스당 단 한 번의 call과 task-level에서의 세 번의 inference calls만을 필요로 한다.
■ 반면, 이 실험의 setting에서 CoT-self-consistency는 각 인스턴스마다 10번 샘플링해야 하므로 10배 더 많은 call이 필요하며, 각 RM을 사용하는 방법은 40개의 RM을 사용하므로 40배 더 많은 call이 필요하다.
■ 이는 문제를 한 번을 풀더라도 제대로 된 계획(즉, reasoning structure)을 세워 푸는 게 더 낫다는 것을 보여주는 결과이다.
4.4 QualitativeExamples
■ Fig 6은 PaLM 2-L을 사용하여 다양한 reasoning tasks에 대해 모델이 발견한 structures의 예시이다.
■ 각 structure가 task에 맞게 adapted되어 있고, 다양한 reasoning modules을 통합하여 task를 해결(causal_judgement에서 "chain of events", "cause-and-effect"를 확인하라는 식의 분석 구조)하는 방법을 볼 수 있다.

■ 아래의 Fig 7은 CoT, Plan-and-Solve, self-discover의 reasoning processes을 비교한 예시이다.
■ CoT와 Plan-and-Solve는 초반에 부정확한 단언("These pints do not ~", "it does not close~")을 하여 오답으로 이어지는 반면, self-discover는 모델이 논리적인 결론("시작 좌표와 끝 좌표가 같으므로 닫혀 있는 도형이다")을 생성하고 정답으로 이어지는 것을 볼 수 있다.

5. Deep Diving Into Self-Discovered Reasoning Structures
■ 이 섹션에서는 self-discover의 모든 actions이 필요한지, 그리고 self-discovered된 structures이 어떤 다른 이점을 가져올 수 있는지를 확인한다.
5.1 Importance of SELF-DISCOVER Actions

■ Fig 8은 self-discover의 actions의 효과를 분석하기 위해 세 가지 action인 SELECT, ADAPT, IMPLEMENT에 대한 ablation study를 수행한 결과이다.
■ 4가지 reasoning tasks에서 GPT-4를 사용하여 SELECT만 적용(-S)했을 때, SELECT와 ADAPT를 적용했을 때(-SA), 그리고 세 가지 action을 모두 적용했을 때(-SAI)의 결과를 비교했다.
■ 각 stage를 거칠 때마다 모델의 zero-shot reasoning capability가 task 전반에 걸쳐 일관되게 향상되는 것을 볼 수 있다. 이는 세 가지 action 모두가 유익함을 나타내는 결과이다.
■ 특히, 세 가지 action을 모두 거친 후(-SAI)에는 reasoning structures이 task-specific하게 조정되어, reasoning tasks solving에 가장 큰 performance gain을 가져온다.
5.2 Towards Universality of Discovered Reasoning Structures
Applying PaLM 2-L Discovered Structures to GPT-4

■ PaLM 2-L을 사용하여 4가지 reasoning tasks의 reasoning structures을 발견한 다음, 발견한 reasoning structures을 GPT-4에게 주어서 문제를 풀게 시켰다.
■ 그리고 이를 각 task에서 PaLM 2-L을 사용하여 최적화된 OPRO 프롬프트를 동일한 reasoning tasks에 적용한 결과와 비교한다.
■ 프롬프트 최적화(OPRO)를 위해 20%의 데이터를 사용했음에도 불구하고, self-discover가 4개 중 3개의 tasks에서 OPRO를 능가한다.
■ OPRO는 프롬프트 최적화를 위해 20%의 데이터를 사용한 것과 대조적으로, self-discover는 zero-shot 방식(즉, 어떠한 추가 데이터 없이)으로 수행되었으며, 이는 self-discover를 통해 discovered된 reasoning structures의 universality를 보여주는 결과이다.
Applying GPT-4 Discovered Structures to Llama2 and ChatGPT
■ Fig 9를 통해 LLM 간의 transferability 성능을 확인한 다음, 저자들은 스스로 reasoning structures을 고안해 내기 어려운 더 작은 LLM에서 LLM이 self-discover한 reasoning structures을 사용했을 때, smaller LMs의 reasoning 능력을 향상시킬 수 있는지 확인하였다.
■ 이 실험을 위해, BBH의 두 가지 subsets에서 GPT-4를 사용하여 발견된 task-intrinsic reasoning structures을 open-source인 Llama2-70B와 GPT-3.5-turbo에서 사용하였다.
■ 그 결과, Llama 2에서 GPT-4의 self-discovered structures을 사용하는 것이 disambiguation QA zero-shot에서 CoT를 능가하고, GPT-3.5-turbo에서도 structured reasoning process의 3-shot demonstration을 사용했을 때 geometry task에서 CoT보다 높은 성능을 보였다고 한다.
'자연어처리 > Reasoning' 카테고리의 다른 글
| Teaching Small Language Models to Reason (0) | 2026.01.24 |
|---|---|
| ThinkSLM: Towards Reasoning Ability of Small Language Models (0) | 2026.01.22 |
| Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations (0) | 2026.01.12 |
| Let's Verify Step by Step (1) | 2026.01.10 |
| LEMA: Learning From Mistakes Makes LLM Better Reasoner (0) | 2026.01.02 |