■ 논문에서는 수학 문제 풀이의 각 단계에 reward score를 부여하는 "process-oriented math process" reward model인 MATH-SHEPHERD를 제안한다.
■ manual annotation(즉, human annotation)에 크게 의존하던 기존 연구들과 달리, MATH-SHEPHERD의 학습은 자동으로 구축된 process supervision data를 사용하여 이루어진다.
[2312.08935] Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
In this paper, we present an innovative process-oriented math process reward model called \textbf{Math-Shepherd}, which assigns a reward score to each step of math problem solutions. The training of Math-Shepherd is achieved using automatically constructed
arxiv.org
1. INTRODUCTION
■ LLM은 여전히 복잡한 multi-step mathematical reasoning problems에서 어려움을 겪고 있다.
■ 이 문제를 해결하기 위해 선행 연구들은 pre-training, fine-tuning, prompting, 그리고 verification과 같은 다양한 방법론을 제안했다.
■ 그중에서 verification이 최근 선호되는 방법이다. verification의 등장 배경에는 top-1 result에만 의존하는 것이 항상 신뢰할 수 있는 결과를 낳지 않다는 점이 있다.
■ verification model은 candidate responses의 순위를 rerank하여 LLM outputs의 정확성과 일관성(consistency)을 높일 수 있다. 또한, 좋은 verification model은 LLM의 개선을 위한 좋은 feedback을 제공할 수도 있다.
■ verification models은 일반적으로 outcome reward model (ORM)과 process reward model (PRM)로 나뉜다. ORM은 generation sequence의 전체를 기반으로 confidence score를 부여하는 반면(즉, 최종 결과만 보고 점수를 매김), PRM은 reasoning path를 step별로 평가한다.
■ PRM의 주요 이점은 발생할 수 있는 오류의 구체적인 위치를 식빌하여 정밇한 feedback을 제공할 수 있다는 점이며, 이는 강화 학습 및 automatic correction에 있어 가치 있는 signal이 된다.
■ 게다가 PRM은 reasoning problem을 평가할 때 human behavior와 유사성을 보인다: 만약, 어떤 steps에 오류가 포함되어 있다면 최종 결과가 틀릴 가능성이 더 높은데, 이는 인간의 판단 방식과 유사하다.
■ 그러나 PRM의 단점은, 학습을 위한 데이터를 수집하는 것이 힘들다는 것이다. 선행 연구들은 human annotators을 활용하여 process supervision annotations을 통해 PRM의 성능을 향상시켰다.
■ 고도의 annotator skills이 필요한 multi-step reasoning tasks의 경우 humans의 annotation은 비용이 상당히 많이 들 수 있으며, 이는 PRM의 발전과 실질적인 적용에 걸림돌로 작용한다.
■ 이런 human annotation의 문제를 해결하기 위한 방법으로, 논문에서는 automatic process annotation 프레임워크를 제안한다.
■ 논문에서는 intermediate step의 quality를 "correct final answer를 도출해낼 수 있는 잠재력"으로 정의한다.
■ 구체적으로, 정답(golden answer)과 step별로 풀이가 있는 수학 문제가 주어졌을 때, 특정 step의 label을 얻기 위해, fine-tuned LLM을 사용하여 해당 step으로부터 이어지는 여러 개의 reasoning paths을 디코딩한다.
■ 그 후 디코딩된 final answer가 golden answer와 일치하는지 검증한다. 만약 어떤 reasoning step이 다른 step보다 더 많은 정답을 도출해낼 수 있다면, 그 step에는 더 높은 correctness score를 부여한다.
■ 이러한 자동화된 방식을 사용하면 비싼 human labeling 없이도 PRM training data를 만들 수 있다.
■ 두 가지 시나리오에서 MATH-SHEPHERD의 효과를 확인한다.
- 1) verification: MATH-SHEPHERD를 사용하여 LLM이 생성한 여러 outputs을 reranking한다.
- 2) reinforcement learning: MATH-SHEPHERD를 사용하여 step별 PPO를 통해 LLM을 reinforce한다.
2. RELATED WORKS
Improving and eliciting mathematical reasoning abilities of LLMs
■ mathematical reasoning tasks은 LLM에게 가장 어려운 tasks 중 하나이다. 선행 연구들은 LLM의 mathematical reasoning ability를 향상시키거나 이끌어내기 위해 다양한 방법을 제안했으며, 이는 다음과 같이 크게 세 그룹으로 나뉜다.
- (1) pre-training
- pre-training methods은 Proof-Pile이나 ArXiv와 같이 math problems과 관련된 방대한 datasets에 대해, 단순한 next token prediction objective를 사용하여 LLM을 pre-train시킨다.
- (2) fine-tuning
- fine-tuning methods로도 LLM의 mathematical reasoning ability를 향상시킬 수 있다. fine-tuning의 핵심은 보통 chain-of-thought reasoning process를 포함하는 high-quality의 question-response pair datasets을 구축하는 데 있다.
- (3) prompting
- prompting methods은 모델 파라미터를 업데이트하지 않고 prompt를 잘 설계해서 LLM의 mathematical reasoning ability를 이끌어내는 것을 목표로 하며, 이는 매우 편리하고 실용적인 방법이다.
Mathematical reasoning verification for LLMs
■ 위의 pre-trianing, fine-tuning, prompting 외에도, 여러 개의 디코딩된 candidates 중에서 best answer를 선택하는 verifier를 사용하는 방법도 있다.
■ verifier에는 크게 두 가지 유형이 있다: Outcome Reward Model (ORM), Process Reward Model (PRM)
■ ORM은 전체 솔루션(즉, 최종 생성 결과)에 score를 할당하는 반면, PRM은 reasoning process의 각 개별 단계(step)에 score를 할당한다. 최근 연구(Let’s verify step by step)는 PRM이 ORM보다 더 우수한 성능을 보인다는 결과를 제시하였다.
■ verification 외에도, reward model은 generator의 추가 학습을 위한 귀중한 feedback을 제공할 수 있다. ORM과 비교하여, PRM은 더 상세한 feedback을 제공하며, generator를 향상시킬 더 큰 잠재력을 보여준다.
■ 그러나 PRM을 학습시키려면 비싼 human-annotated datasets을 사용해야 한다.
■ 그래서 논문에서는 이 문제를 해결하고자, human annotation 없이 mathematical reasoning을 위한 PRM을 구축하는 것을 목표로 한다.
3. METHODOLOGY
3.1 TASK FORMULATION
■ 아래의 두 가지 시나리오에서 reward model의 성능을 평가한다.
Verification
■ Let’s verify step by step을 따라, best-of-N selection evaluation를 사용한다.
■ 구체적으로, test set의 problem \( p \)가 주어지면, generator에서 N개의 candidate solutions을 샘플링한다.
■ reward model을 사용하여 이 candidates에 점수를 매긴다. 최종적으로 가장 높은 점수를 받은 solution이 final answer로 선택된다.
Reinforcement learning
■ 자동으로 구축된 PRM을 사용하여 step-by-step PPO로 LLM을 supervise한다.
■ 이 시나리오에서는 LLM의 greedy decoding output의 accuracy를 평가한다.
3.2 REWARD MODELS FOR MATHEMATICAL PROBLEM
ORM
■ ORM은 일반적으로 cross-entropy loss를 통해 학습된다.
■ mathematical problem \( p \)와 \( p \)의 solution인 \( s \)가 주어졌을 때, ORM은 \( s \)가 정답인지 나타내기 위해 \( s \)에 대한 하나의 실수 값 \( r_s \)를 할당한다.
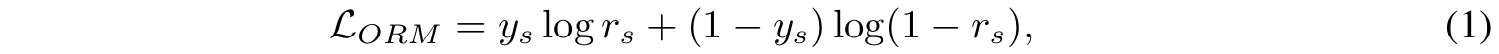
- 여기서 \( y_s \)는 solution \( s \)의 정답(golden answer) 여부이며, \( s \)가 맞으면 \( y_s=1 \), 그렇지 않으면 \( y_s = 0 \)이다.
- \( r_s \)는 ORM이 할당한 \( s \)의 sigmoid score이다. ORM이 \( s \)를 보고 예측한 "이 solution \( s \)가 정답일 확률(0과 1사이의 실수, sigmoid score)"
- solution \( s \)가 정답이면 \( y_s \)는 1, 오답이면 0이다.
- \( s \)가 정답이면 두 번째 항이 0이 되어 사라진다. 남는 항은 \( 1 \cdot \log r_s \)이므로, 모델은 loss를 줄이기 위해 sigmoid 값인 \( r_s \)를 1에 가깝게 예측하도록 학습된다.
- \( s \)가 오답이면 첫 번째 항이 0이 되어 사라진다. 남는 항은 \( \log(1-r_s) \)이므로, 모델은 loss를 줄이기 위해 \( r_s \)를 0에 가깝게 예측하도록 학습된다.
■ reward model의 성공은 high-quality training dataset에 달려 있다.
■ 수학 문제의 경우 보통 정해진 답이 있기 때문에, 두 단계를 거쳐 ORM의 training set을 자동으로 구축할 수 있다: 1) generator에서 problem에 대한 candidate solutions을 샘플링한다. 2) 샘플링된 각 solution의 정답 여부를 확인하여 label을 할당한다.
■ 잘못된 reasoning으로도 정답에 도달한 false positive solutions을 걸러내지 못하지만, 선행 연구들은 이것이 여전히 좋은 ORM을 학습시키는 데 효과적임을 입증했다.
PRM
■ PRM은 \( s \)의 각 reasoning step에 점수를 할당한다. PRM은 보통 다음과 같이 학습된다.
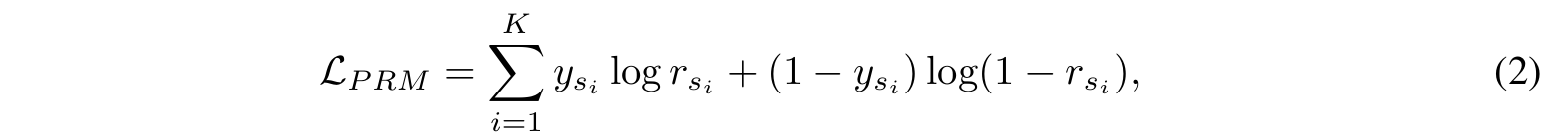
- 여기서 \( y_{s_i} \)는 \( s \)의 \( i \)번째 step의 정답 여부이고, \( r_{s_i} \)는 PRM이 할당한 \( s_i \)의 sigmoid score이며, \( K \)는 solution \( s \)의 reasoning steps의 개수이다.
- 식 (2)는 식 (1)의 확장판이다. solution \( s \)로 귀결되는 모든 \( K \)개의 reasoning steps에 대해 각각 오차를 계산하고 이를 모두 더한 것이다.
- 그러므로, PRM은 "각 step이 맞는가?"를 판단하도록 학습된다.
■ 선행 연구에서는 PRM trainingg을 각 reasoning step이 'good', 'neutral', or 'bad' 중 하나로 분류되는 three-class classification 문제로 처리한 바 있다.
■ 논문에서는 선행 연구의 three classification과 binary classification 사이에 큰 차이가 없음을 발견했으며, 따라서 PRM training을 binary classification으로 다룬다.
■ ORM과 비교했을 때, PRM은 더 상세하고 신뢰할 수 있는 feedback을 제공할 수 있다.
■ 그러나 high-quality의 PRM training datasets을 구축하기 위해 사용할 수 있는 자동화된 방법이 없어, 이전 연구들은 값비싼 human annotations에 의존했다.
■ PRM이 ORM보다 성능이 뛰어나긴 하지만, annotation cost는 필연적으로 PRM의 개발과 적용을 모두 방해한다.
- 사람이 각 step을 검토하며 label을 부텨야 하는데, 예를 들어 1,000개 문제에 대해, 각 문제마다 5개의 step이 있다면 5,000개의 label이 필요하다.
- 또한, 수학과 같은 전문적인 지식이 필요한 도메인의 경우, 고급 인력이 필요하다.
- 그래서 대규모이면서 고품질의 PRM training dataset을 구축하는 것은 많은 비용이 필요하다.
- 그리고 새로운 도메인에 PRM을 적용하려면, 해당 도메인에 대한 별도의 annotation data를 구축해야 한다는 점에서 확장성에 한계가 있다.
3.3 AUTOMATIC PROCESS ANNOTATION
■ 이 섹션에서는 PRM과 관련된 annotation cost 문제를 완화하기 위해 automatic process annotation framework를 제안한다.
■ 먼저, reasoning step의 quality를 정의한 다음, human annotation의 필요성을 제거하는 논문의 approach를 설명한다.
3.3.1 DEFINITION
■ 논문에서는 reasoning step의 품질을 "correct answer를 도출해낼 수 있는 잠재력"으로 정의한다.
■ 타당한 결과를 도출할 잠재력이 있는 step은 좋은 reasoning step으로 간주될 수 있다. reasoning process는 본질적으로 인간이나 지능형 에이전트가 타당한 결과에 도달하도록 돕는 인지적인 과정이기 때문이다.
■ 논문에서 제안하는 방법도 결국 해당 step의 정답 여부에 의존하므로, ORM처럼 noise(예: false positive solutions)가 생길 수 있다. 그럼에도 불구하고, 저자들은 이 노이즈가 좋은 PRM을 학습시키는 데 긍정적으로 작용함을 발견했다고 한다.

3.3.2 SOLUTION
Completion
■ Fig 2와 같이 주어진 reasoning step \( s_i \)에 대한 "potential"을 정량화하고 추정하기 위해, completer(즉, LM)를 사용하여 \( s_i \)로부터 이어지는 \( N \)개의 subsequent reasoning processes를 생성한다: \( \{(s_{i+1,j}, \cdot \cdot \cdot, s_{K_j,j}, a_j)\}_{j=1}^N \)
s_i (현재 단계)
↓
completer가 N개의 후속 경로 생성: 현재 단계까지의 풀이를 입력받아, 끝까지 풀이를 생성해 주는 모델. N번 다양하게 풀어보게 한다.
↓
경로 1: s_{i+1,1} → ... → s_{K1,1} → a1
경로 2: s_{i+1,2} → ... → s_{K2,2} → a2
...
경로 N: s_{i+1,N} → ... → s_{KN,N} → aN- 여기서 \( a_j \)와 \( K_j \)는 각각 \( j \)번째 완료된 solution의 디코딩된 answer와 총 steps 수이다.
■ 그런 다음, 디코딩된 모든 answer들 \( A = \{a_j\}_{j=1}^N \)의 correctness에 기반하여 \( s_i \)의 potential을 추정한다.
- 예를 들어 경로 1, 2, 3의 \( a_1, a_2, a_3 \)이 각각 5, 6, 1이고, 진짜 정답이 5라면 경로 1은 올바른 step이다.
Estimation
■ 논문에서는 \( s_i \)의 quality \( y_{s_i} \)를 추정하기 위해, hard estimation (HE)과 soft estimation (SE)라는 두 가지 방법을 사용한다.
■ HE는 reasoning step이 correct answer \( a^* \)에 도달할 수 있다면 good reasoning step으로 간주한다.
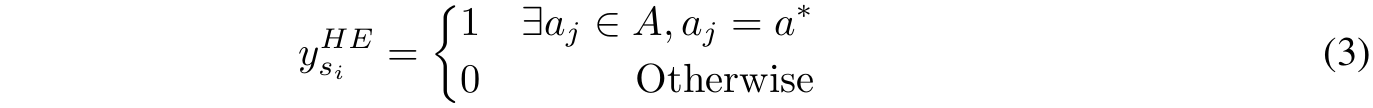
- 생성된 \( N \)개의 경로 중에서 하나라도 정답이 있으면 해당 \( s_i \)는 good reasoning step \( \rightarrow \) \( y^{HE}_{s_i} =1 \)
- \( N \)개에서 하나도 정답이 없으면 bad reasoning step \( \rightarrow \) \( y^{HE}_{s_i} =0 \)
■ SE는 step의 quality를 "correct answer에 도달하는 빈도"로 가정한다.
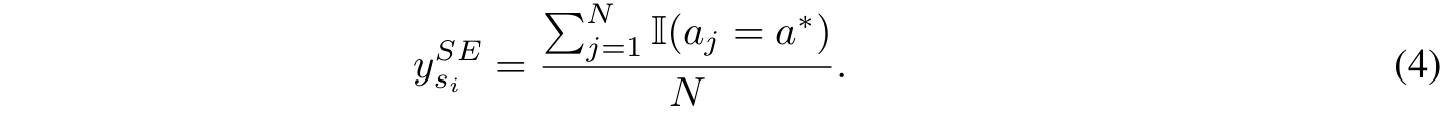
■ 식 (4)에서 볼 수 있듯이, 분자는 \( s_i \)에서 시작한 \( N \)개의 경로 중에서, 실제 \( a^* \)에 도달한 \( a_j \)의 개수이다. 그리고 분모는 \( N \)이므로, SE는 정답이 나온 비율로 볼 수 있다.
■ 논문에서 제안하는 automatic process annotation framework는 step의 quality를 "correct answer를 도출할 수 있는 potential"로 정의하며, 'completion'과 'estimation'을 통해 각 step의 label을 획득한다.
■ 이렇게 하면 human labeling을 단 하나도 하지 않고, 오직 golden answer 하나만 가지고도 모든 중간 단계에 대한 점수를 자동으로 생성해 낼 수 있다. 이렇게 만들어진 데이터로 PRM을 학습시키는 것이 MATH-SHEPHERD의 핵심이다.
■ 각 step의 label(점수)을 수집하면, cross-entropy loss를 사용하여 PRM을 학습시킬 수 있다.
3.4 RANKING FOR VERIFICATION
■ Let’s verify step by step을 따라, PRM이 할당한 모든 steps 중 minimum score를 해당 solution의 최종 점수로 사용한다.
- 모든 단계 점수 중에서 가장 낮은 점수를 고르는 방식은, solution으로 이어지는 단계 중 하나의 단계라도 오류가 발생하면 전체(즉, solution)가 틀릴 가능성이 높다는 직관에 기반한 것이라고 생각된다.
- 즉, 이는 보수적인 접근으로, 한 단계라도 확신이 없으면 전체 과정을 의심하는 것이다. 이를 통해 false positive를 줄일 수 있다고 생각된다.
- 다만, 단점으로 한 단계가 조금 불확실하다고 해서 전체를 저평가할 수 있다는 생각이 든다.
■ 논문에서는 self-consistency와 reward model을 결합해서 사용하는 접근법을 검토한다: final answer에 따라 solutions을 서로 다른 그룹으로 분류한다. 그 후, 각 그룹에 대한 aggregate score를 계산한다.
■ \( N \)개의 candidate solutions에 기반한 final prediction answer는 식 (5)와 같다.
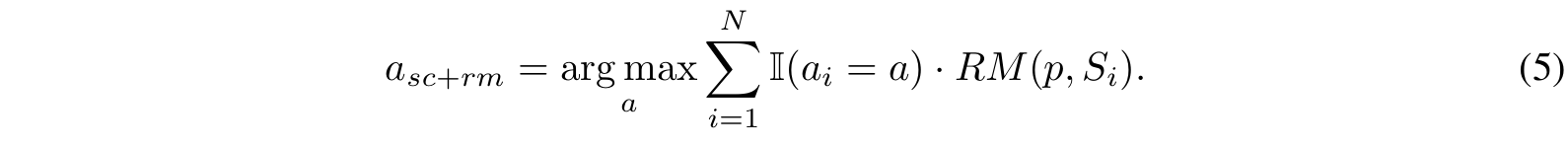
■ - 식 (5)는 논문에서 self-consistency와 reward model을 결합한 접근법이다.
- 여기서 \( RM(p, S_i) \)는 problem \( p \)에 대해 reward model(ORM or PRM)이 할당한 \( i \)번째 solution의 score이다.
- \( \sum_{i=1}^N \mathbb{I}(a_i = a) \)이므로 모든 \( N \)개의 candidate solutions 중에서 실제 정답으로 이어지는 \( a_i \)의 개수이므로, self-consistency로 볼 수 있다.
- 예를 들어, \( p \)가 "5+3x2=?"라고 하자. candidate solutions의 개수 \( N = 3 \)일 때, 각 solution에 대한 reward model의 점수가 다음과 같다고 하자.
| solution | \( a_i \) | RM 점수 \( RM(p, S_i) \) |
| \( S_1 \) | 11 | 0.95 |
| \( S_2 \) | 11 | 0.88 |
| \( S_3 \) | 16 | 0.75 |
- 정답이 \( a = 11 \)인 경우: \( 1 \times 0.95 + 1 \times 0.88 + 0 \times 0.75 = 1.83 \)
- 정답이 \( a = 16 \)인 경우: \( 0 \times 0.95 + 0 \times 0.88 + 1 \times 0.75 = 0.75 \)
- \( a = 11 \)은 1.83, \( a = 16 \)은 0.75이다. argmax를 적용하면 1.83인 \( a = 11 \)이 최종 선택된다.
- 이런 식으로 self-consistency에 reward model의 결과를 가중치로 적용해서, 점수를 합산한 다음, 가장 큰 값을 가진 \( a \)를 선택한다.
3.5 REINFORCE LEARNING WITH PROCESS SUPERVISION
■ LLM을 학습시키기 위해 강화 학습을 적용한다. 구체적으로, PPO를 step별로 적용한다. 저자들이 사용한 이 step-by-step PPO는 각 reasoning step이 끝날 때마다 reward를 제공하는 방식이다.
- 모델이 각 reasoning step을 생성할 때마다 reward를 준다는 것은, 각 step별로 feedback을 제공한다는 것이다. 그러므로 어떤 step이 올바른지 훨씬 정확하게 학습할 수 있다.
4. EXPERIMENTS
Datasets
■ math reasoning datasets인 GSM8K와 MATH를 사용하여 실험을 수행한다.
■ GSM8K dataset의 경우, verification 및 reinforcement learning 시나리오 모두에서 전체 test set을 사용한다.
■ Math dataset의 경우, verification 시나리오에서는 계산 비용 문제로 인해 Let’s verify step by step처럼 subset인 MATH500을 사용한다.
- 이 subset은 500개의 대표적인 문제로 구성되어 있으며, 저자들은 이 subset에 대한 평가가 전체 test set에 대한 평가와 유사한 결과를 산출함을 확인했다고 한다.
■ 다양한 verification methods을 평가하기 위해, 각 test problem에 대해 256개의 candidate solutions을 생성한다. 그리고 3개 그룹의 샘플링 결과에 대한 mean accuracy를 reporting한다.
■ 강화 학습 시나리오에서는 전체 test set을 사용하여 모델 성능을 평가한다. LLM 학습에는 MetaMATH를 사용한다.
Parameter Setting
■ 실험을 위해 LLaMA2-7B/13B/70B, LLemma-7B/34B, Mistral-7B, DeepSeek-67B 등의 LLM들을 사용한다.
■ generator와 completer를 MetaMATH dataset에서 3 epochs 동안 학습시킨다.
■ Mistral-7B는 5e-6의 학습률로, 다른 모델들의 경우 학습률은 7B/13B, 34B, 67B/70B LLM에 대해 각각 2e-5, 1e-5, 6e-6을 사용한다.
■ ORM과 PRM의 training dataset을 만들기 위한 과정은 다음과 같다.
- 7B 및 13B 모델을 GSM8K와 MATH training sets에서 1 epoch 동안 학습시킨다. 그 후, training set의 각 problem에 대해 각 모델에서 15개의 solutions을 샘플링한다.
- 샘플링 후 중복되는 solutions을 제거하고 각 step별로 label(점수)을 부여한다.
- LLemma-7B를 completer로 사용하며 \( N = 8 \)로 설정한다.
- 결과적으로, GSM8K에 대해 약 170K 개, MATH에 대해 약 270K 개의 solutions을 획득했다고 한다.
■ verification을 위해, GSM8K와 MATH에 대한 reward models을 학습하기 위한 base model로 각각 LLaMA2-70B와 LLemma-34B를 사용한다.
■ reinforcement learning을 위해서는 Mistral-7B를 base model로 선택하여 reward model을 학습시키고, 이를 사용하여 LLaMA2-7B 및 Mistral-7B generators을 supervise한다.
■ reward model은 학습률 1e-6으로 1 epoch 동안 학습시킨다.
■ 편의를 위해, HE를 사용하여 PRM을 학습시켰다. 이는 'has potential'과 'no potential' label을 나타내는 두 개의 special token을 선택하는 방식(binary classification)이다. 언어 모델링 파이프라인을 그대로 사용해서 special token을 선택(즉, 생성)하기 때문에 별도의 모델 조정이 필요 없다.
■ reinforcement learning에서 학습률은 LLaMA2-7B와 Mistral-7B에 대해 각각 4e-7과 1e-7을 사용한다.
■ Kullback-Leibler coefficient는 0.04를 사용한다.
■ cosine learning rate scheduler를 사용했으며, 최소 학습률은 1e-8로 설정했다.
Baselines and Metrics
■ verification 시나리오에서 Let’s verify step by step을 따라, self-consistency (majority voting) 및 ORM을 비교군으로 사용한다.
■ best-of-N solution의 accuracy를 평가지표로 사용한다.
■ PRM의 경우 모든 steps 중 최소 점수를 선택한다. 선택한 최소 점수를 해당 solution의 최종 점수로 사용한다.
■ reinforcement 시나리오에서는, 저자들의 방식(step-by-step supervision)을 ORM이 제공하는 outcome supervision과, Rejective Sampling Fine-tuning (RFT)을 비교군으로 사용한다.
- RTF를 위해 MetaMATH의 각 question에 대해 8개의 responses을 샘플링했다.
■ 성능 평가에는 LLM의 greedy decoding output의 accuracy를 사용한다.
4.1 MAIN RESULTS
MATH-SHEPHERD as verifier

■ Table 1은 GSM8K와 MATH에서 다양한 방법들의 성능을 비교한 결과이다.
■ verifier로서 MATH-SHEPHERD는 두 데이터셋과 모든 generator에 대해 self-consistency 및 ORM보다 우수한 성능을 보인다.
■ PRM은 GSM8K보다 더 어려운 MATH dataset에서 ORM 대비 더 큰 이점을 보인다. 이는 MATH에 비해 GSM8K 데이터셋이 상대적으로 더 단순하기 때문일 수 있다.
■ 즉, GSM8K 데이터셋은 문제 해결에 더 적은 steps을 필요로 하기 때문에 ORM과 PRM이 큰 차이가 나지 않지만, MATH는 풀이 단계가 복잡해서, step별로 feedback을 주는 PRM이 ORM보다 더 유리하다.
■ GSM8K에서는 self-consistency와 MATH-SHEPHERD를 결합했을 때 성능 하락이 있는 반면, MATH에서는 성능이 향상된다. 이러한 결과는 reward model이 해당 task에 대해 이미 충분히 강력하다면, self-consistency를 결합하는 것이 오히려 성능을 저하시킬 수도 있음을 시사한다.
MATH-SHEPHERD as reward model on reinforcement learning

■ Table 2는 greedy decoding output을 사용한 LLM들의 성능을 나타낸 결과이다.
■ step-by-step PPO는 supervised fine-tuned된 model의 성능을 크게 향상시킨다. 예를 들어, step-by-step PPO를 적용한 Mistral-7B는 GSM8K와 MATH 데이터셋에서 각각 84.1%와 33.0%를 달성했다.
■ RTF는 모델 성능을 아주 약간만 향상시키는데, 저자들은 MetaMATH dataset이 이미 RFT와 유사한 data augmentation을 수행했기 때문이라고 추측한다.
■ ORM을 사용한 vanilla PPO 또한 모델 성능을 향상시킨다. 그러나 이는 MATH-SHEPHERD에 의해 supervised된 step-by-step PPO만큼 좋은 성능을 내지는 못한다.
MATH-SHEPHERD as both reward models and verifiers

■ Table 3은 reinforcement learning과 verification을 결합한 결과이다.
■ reinforcement learning과 verification은 상호 보완적이다. 예를 들어 MATH dataset에서 self-consistency를 verifier로 사용했을 때, step-by-step PPO를 적용한 Mistral-7B는 supervised fine-tuning Mistral-7B보다 정확도가 7.2%더 높다.
■ reinforcement learning 이후에는(MATH500에서 RL 후 Mistral-7B의 Math-Shepherd(41.1%)), 오직 reward model만 사용하는 vanilla verification methods보다 성능이 떨어진다. 저자들은 그 이유에 대해, 초기 reward model이 PPO 이후 더 강력해진 모델을 supervise하기에는 충분하지 않기 때문이라고 추측한다.
■ 이는 PPO를 통해 모델이 강화되면 reward model도 다시 학습시키는 iterative reinforcement learning이 필요함을 시사한다.
5. ANALYSIS
5.1 PERFORMANCE WITH DIFFERENT NUMBER OF CANDIDATE SOLUTIONS
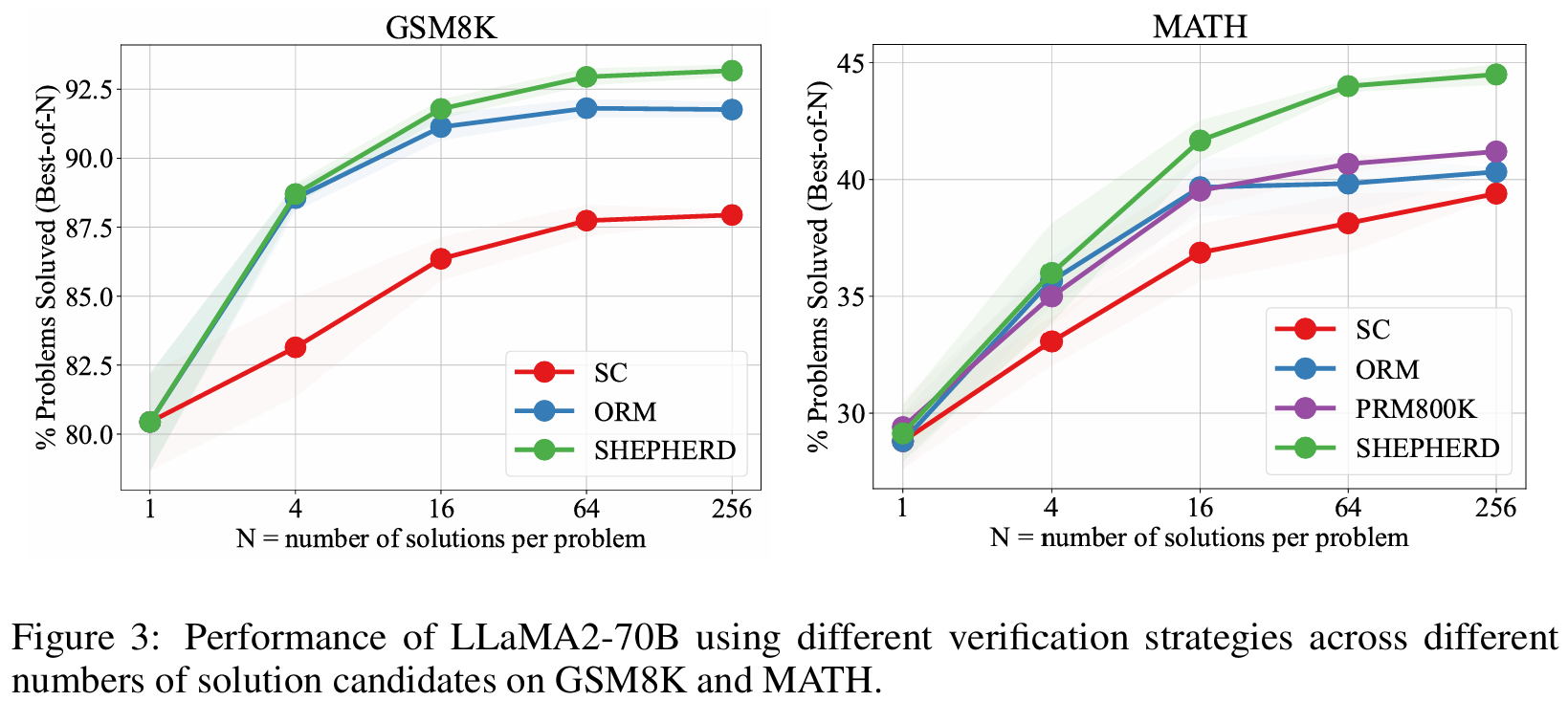
■ Fig 3은 GSM8K와 MATH에서 1개부터 256개까지의 서로 다른 candidates 개수를 사용했을 때, 각 방법들의 성능을 비교한 것이다.
■ PRM은 ORM 및 majority voting(즉, CS)과 비교했을 때, 일관되게 우수한 성능을 보이며, \( N \)이 증가할수록 이러한 우위의 정도가 더욱 두드러지게 나타난다.
■ 그리고 MATH dataset에서, 저자들이 제안한 방법으로 만든 automatically annotated datasets이 PRM800K보다 성능이 뛰어나다. 저자들은 이 결과가 distribution 차이와 데이터의 양 때문으로 추측한다.
■ 구체적으로, PRM800K는 GPT-4의 출력을 기반으로 annotated되었기 때문에, MetaMATH로 fine-tuned된 LLaMA models의 출력과는 불일치가 발생한다.
■ 게다가 데이터의 양을 고려할 때, 저자들의 방식은 높은 확장성과 낮은 labeling cost를 가진다. 결과적으로 PRM800K보다 4배 더 크게 만들 수 있었다.
5.2 QUALITY OF THE AUTOMATIC PROCESS ANNOTATIONS
■ 이 섹션에서는 저자들의 방식으로 만든 automatic PRM dataset의 quality를 평가한다.
■ 이 평가를 위해 GSM8K training set에서 160개의 steps에 직접 annotation을 달고, 각 step에서 얻은 label을 얻기 위해 서로 다른 completer를 사용하였다.
Automatic process annotation exhibits satisfactory quality
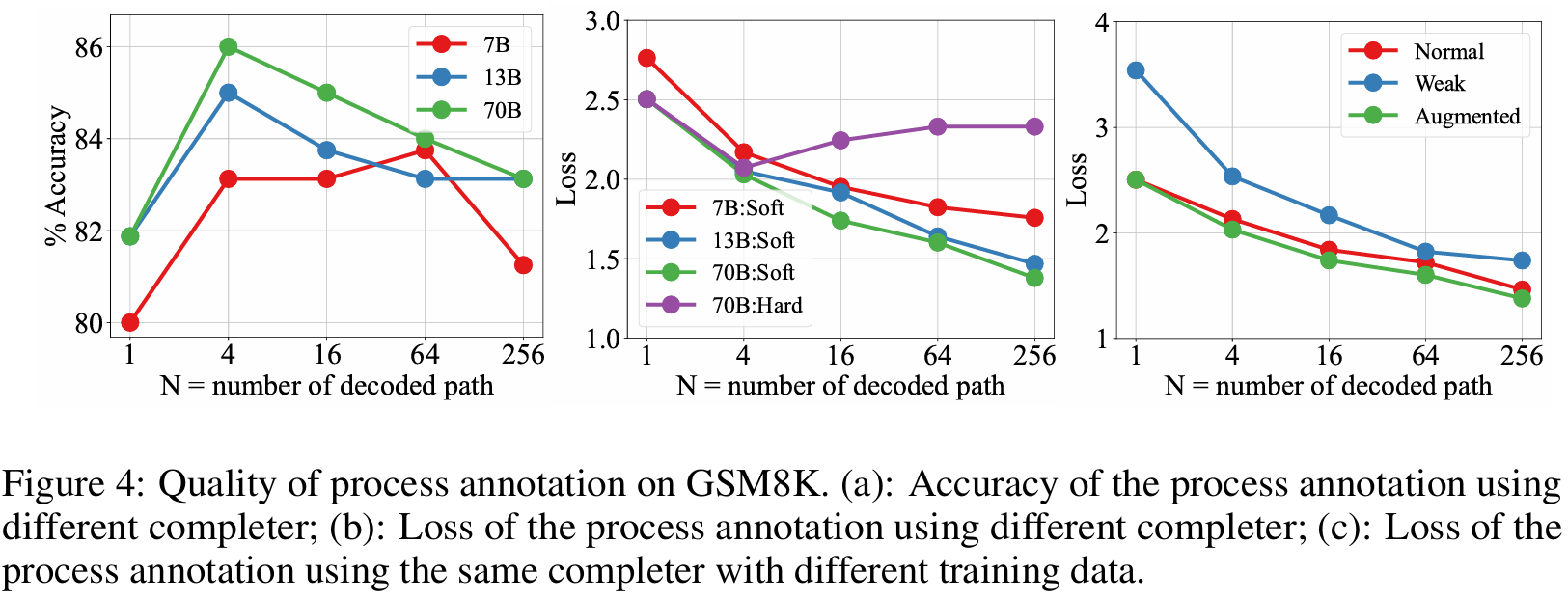
■ Fig 4 (a)는 MetaMATH로 학습된 LLaMA2-70B를 completer로 사용했을 때의 결과로, \( N = 4 \)에서 HE의 정확도가 86%에 도달한 것을 볼 수 있다. 이는 저자들의 방식으로, 자동으로 구축된 데이터셋이 high quality임을 시사한다.
■ 그러나 \( N \)이 더 증가함에 따라 정확도가 감소하는 것을 볼 수 있다. 논문에 따르면, \( N \)값이 커질수록 false positives(과정은 틀렸는데 우연히 답이 맞아 정답으로 처리된 경우)이 발생했다고 한다.
■ Fig 4 (b)는 human-annotated distribution과 비교했을 때 SE와 HE labels 간의 cross-entropy loss이다. loss 값이 낮을수록 human label과 비슷한 것이다.
- 즉, human-annotated distribution과 SE/HE 분포 간의 cross entropy 값
■ \( N \)이 증가함에 따라, HE와 달리 SE는 점차 standard distribution(즉, human-annotated distribution)에 더 가까워진다.
■ \( N = 4 \)에서 HE가 86%의 정확도를 달성했기 때문에, 이론적으로는 SE를 활용한다면 86%를 초과하는 더 고품질의 데이터를 얻을 수 있다.
■ 그러나 저자들은 verifier의 성능이 SE로 학습되든 HE로 학습되든 실질적인 차이를 보이지 않았음을 발견했다고 한다. 이는 HE가 제공하는 annotations이 이미 고품질이기 때문일 수 있다.
The ability of the LLM completer plays an important role in the data quality
■ 각 step에 대해 여러 개의 subsequent reasoning processes을 생성하기 위해 completer를 사용했다. 이때, completer에 따라 데이터의 품질이 달라지는지 확인하였다.
■ Fig 4 (b)는 MetaMATH로 학습된 다양한 completers에 걸친 cross-entropy loss이다. 크기가 더 큰 completer가 우수한 품질의 데이터셋을 생성하는 데 더 뛰어남을 확인할 수 있다.
■ Fig 4 (c)는 서로 다른 데이터셋으로 학습된 LLaMA2-70B의 cross-entropy loss이다.
- 'Normal'은 original GSM8K training dataset, 'Weak'는 evaluation set에 포함된 160개의 questions을 제외한 Normal를 의미하며, 'Augmented'는 Normal의 증강 버전인 MetaMath를 의미한다.
■ Fig 4 (c)의 결과는 high-quality training sets이 모델이 completer로서 더 능숙하게 작동하도록 한다는 것을 시사한다.
■ 그리고 'Weak'는 다른 데이터셋보다 더 큰 loss를 보이는데, 이는 LLM이 completer로서의 성능을 높이기 위해 사전에 questions을 습득해야 한다는 것으로 해석할 수 있다.
5.3 INFLUENCE OF THE PRE-TRAINED BASE MODELS

■ MATH-SHEPHERD의 효과를 철저히 평가하기 위해, 우리는 7B, 13B, 70B 모델 크기를 사용한 실험을 진행했다.
■ Fig 5 (a), 5 (b), 그리고 3 (a)는 각각 동일한 크기의 reward model과 짝을 이룬 7B, 13B, 70B generator의 결과이다.
■ 모든 크기의 모델에 걸쳐 PRM이 self-consistency과 ORM보다 우수하다는 것을 확인할 수 있다.
■ 또한, 크기가 더 큰 reward model일수록 더 robust하다. 예를 들어, 70B reward model의 정확도는 candidate solutions의 개수가 증가함에 따라 상승하는 반면, 7B reward model은 감소하는 경향을 보인다.
■ Fig 5 (c)와 5 (d)는 서로 다른 크기의 reward models과 연결된 7B 및 70B generator의 성능을 보여준다.
■ 더 큰 reward model을 사용하여 더 작은 generator의 output을 검증하는 것이 성능을 크게 향상시킨다는 것을 보여준다. (Fig 5 (d))
■ 반대로, 더 큰 generator의 output을 검증하기 위해 더 작은 reward model을 사용했을 때, SC보다 성능이 더 떨어지는 것을 볼 수 있다. (Fig 5 (c))
5.4 INFLUENCE OF THE NUMBER OF DATA
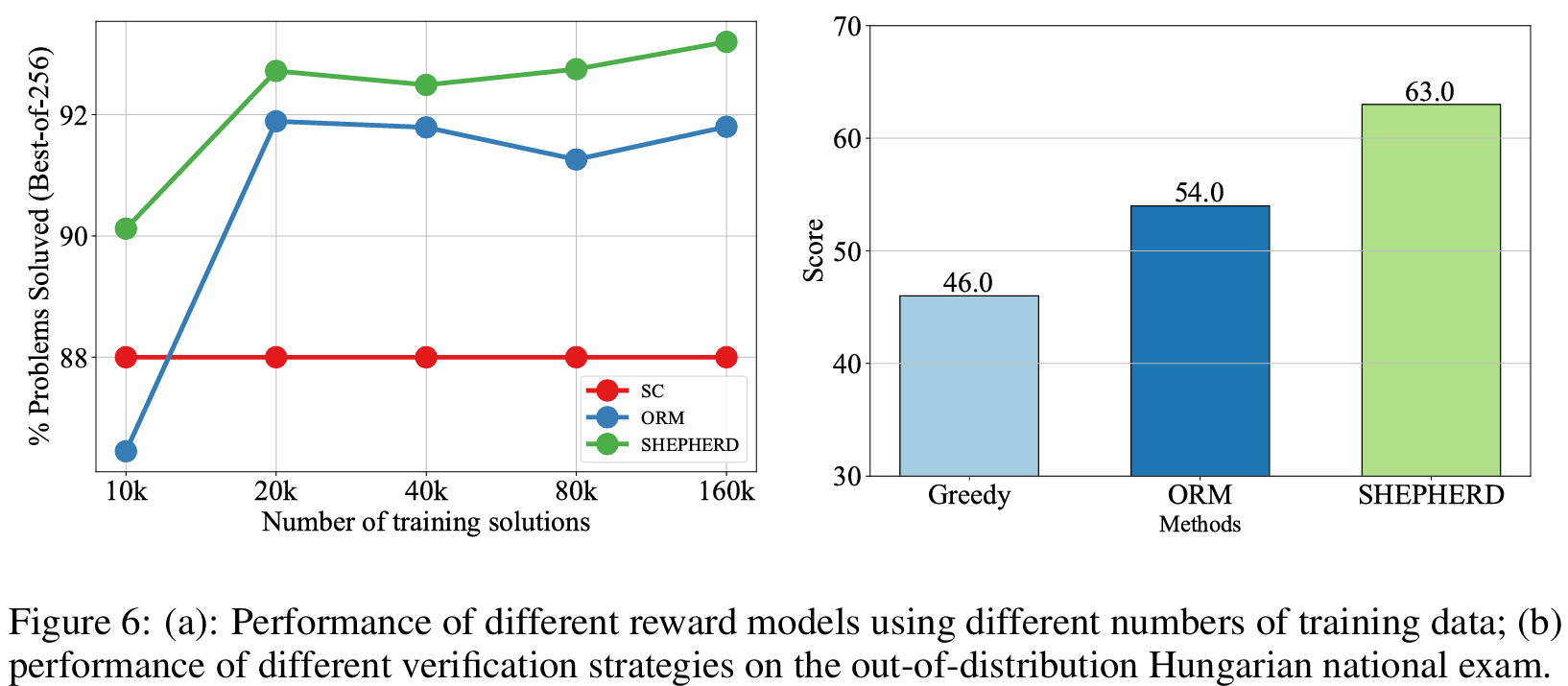
■ Fig 6 (a)는 training data의 양에 대한 실험 결과이다. PRM은 ORM보다 적은 데이터를 사용해도 성능 우위를 가진다.
5.5 OUT-OF-DISTRIBUTION PERFORMANCE
■ OOD에서도 저자들의 방법이 잘 작동하는지 평가한다. 이를 위해 33개의 문제로 구성된 Hungarian national final exam에 대해 평가를 수행한다.
■ MetaMATH로 학습된 LLemma-34B를 generator로 사용하여 각 question당 256개의 candidate solutions을 생성한다. 그리고 각 question의 solution을 선택하기 위해 LLemma-34B-ORM과 LLemma-34B-PRM을 사용한다.
■ Fig 6에서 볼 수 있듯이, LLemma-34B-ORM과 LLemma-34B-PRM 모두 origin LLemma-34B보다 성능이 뛰어나며, 이는 reward model이 다른 도메인으로 일반화될 수 있음을 보여준다.
■ 그리고 PRM은 ORM보다 9점 더 높은 점수를 기록한 것을 볼 수 있다.
6. LIMITATIONS
The computational cost of the completion process
■ 논문에서 제안하는 방법은, 각 reasoning step의 label을 결정하기 위해, completer를 사용하여 \( N \)개의 subsequent reasoning processes를 디코딩한다. \( N \)이 증가함에 따라 automatic annotations의 quality도 향상되었다.
■ 그러나 이 과정은 많은 computing resources을 요구한다. 그러나 human annotation보다 훨씬 저렴하다.
■ 저자들은 speculative decoding이나 vLLM과 같은 efficient inference techniques이 이러한 한계를 완화할 수 있을 것이라 주장한다.
The automatic process annotation consists of noise
■ automatic process annotation에도 결국 noise가 존재한다. 그럼에도 불구하고, 실험에서 PRM 학습에 있어 좋은 결과를 달성하였다.
■ 특히 저자들의 방식으로 만든 데이터셋으로 학습된 PRM은 human-annotated인 PRM800K dataset보다 성능이 뛰어나다.
■ 그러나 PRM800K 데이터(GPT-4 기반)와 논문에서 사용된 open-source models이 생성한 responses에는 눈에 띄는 격차가 존재한다. 그래서 PRM800K dataset보다 성능이 더 좋았던 이유는 PRM800K가 open-source models과 맞지 않아서 발생한 현상일 수 있다.
'자연어처리 > Reasoning' 카테고리의 다른 글
| ThinkSLM: Towards Reasoning Ability of Small Language Models (0) | 2026.01.22 |
|---|---|
| Self-Discover: Large Language Models Self-Compose Reasoning Structures (0) | 2026.01.17 |
| Let's Verify Step by Step (1) | 2026.01.10 |
| LEMA: Learning From Mistakes Makes LLM Better Reasoner (0) | 2026.01.02 |
| USC: Universal Self-Consistency for Large Language Model Generation (0) | 2025.12.22 |