■ LLM은 math problems을 해결하는 데 있어 놀라운 reasoning capabilities을 보여주고 있다.
■ 논문에서는 LLM의 reasoning capabilities을 더욱 향상시키기 위한 방법으로, 인간의 학습 과정과 유사하게 LLM이 "실수로부터 배울 수 있는지(LEMA: LEarn from MistAkes)"를 새로운 방법론으로 제안하고 이를 검증한다.
■ 수학 문제를 푸는 데 실패한 human student를 생각해보면, 문제에서 자신이 어떤 실수를 했는지, 그리고 그것을 어떻게 바로잡아야 하는지로부터 배움을 얻는다. 이러한 error-driven learning process를 모방한 것이 LEMA이다.
- LEMA(https://github.com/microsoft/LEMA)
■ 이를 위해, 먼저 다양한 LLM으로부터 inaccurate reasoning paths을 수집한 다음, GPT-4를 corrector로(즉, teacher로) 사용하여 실수 단계를 식별하고, 실수의 이유를 설명하며, 실수를 수정하여 최종 정답을 생성하도록 한다.
■ 그리고 correction data를 생성하기 위해 question set을 확장하는 "correction-centric evolution" strategy를 적용한다.
[2310.20689] Learning From Mistakes Makes LLM Better Reasoner
Learning From Mistakes Makes LLM Better Reasoner
Large language models (LLMs) recently exhibited remarkable reasoning capabilities on solving math problems. To further improve their reasoning capabilities, this work explores whether LLMs can LEarn from MistAkes (LEMA), akin to the human learning process.
arxiv.org
1. Introduction
■ LLM은 chain-of-thought (CoT) reasoning을 필요로 하는 수학적인 문제 해결에서 상당한 진전을 보여주었다.
■ 수학적인 tasks을 해결하기 위해, open-source LLM의 CoT reasoning capabilities을 향상시키고자 하는 일반적인 접근법은 "question-rationale" data 쌍(이를 CoT data라 함)을 사용하여 모델을 fine-tuning하는 것이다. 즉 어떤 task에 대한 CoT data를 보여줌으로써, CoT reasoning을 수행하는 방법을 직접 보여주고 따라 하게 만드는 것이다.
■ 이러한 straightforward learning process가 효과를 보이긴 했지만, 저자들은 LLM의 reasoning capabilities이 "backward learning process", 즉 LLM이 저지른 mistakes로부터 학습하는 것을 통해 더욱 향상될 수 있는지 확인하고자 하였다.
■ 예를 들어, 막 수학을 배우기 시작한 학생이 있다고 하자. 책에 있는 예제와 정답을 통해서만 배우는 것을 넘어, 연습 문제도 풀 것이다. 그리고 틀린 문제는 자신이 어떤 실수를 했는지 그리고 그것을 어떻게 바로잡을지를 배울 것이다. 이 과정을 통해 수학 능력은 더욱 향상될 것이다.
■ 이러한 error-driven learning process에서 영감을 받아, LLM의 reasoning capabilities도 실수를 이해하고 교정하는 것으로부터 이점을 얻을 수 있는지 확인한다.
■ 이를 위해 mistake-correction data 쌍(이를 correction data라 함)을 생성하고, 이 correction data를 CoT fine-tuning 과정에 사용한다. (Fig 1)
■ correction data를 생성하기 위해, LLaMA와 GPT 시리즈 모델들을 포함한 여러 개의 LLM을 사용하여 inaccurate한 reasoning paths(즉, 틀린 최종 정답을 가진 reasoning path들)을 수집한다.
■ 그런 다음, GPT-4를 corrector로 사용하여 inaccurate reasoning paths에 대한 corrections을 생성한다.
■ GPT-4로 생성된 corrections에는 세 가지 정보가 포함되어 있다: (1) 원래 풀이에서 잘못된 step (2) 이 step에서 왜 잘못되었는지에 대한 설명 (3) 올바른 최종 정답으로 이어지기 위해 원래 풀이를 어떻게 수정해야 하는지
■ correction data를 생성하기 위해 original training questions을 사용하지만, training questions에 가지고 있는 questions의 수는 한정되어 있다. 모델을 잘 가르치려면 더 많이 필요하다.
■ 그래서 저자들은 correction data를 확장하기 위해 question sets을 확장하는 것도 고려하였으며, CoT data를 위한 evolution techniques에서 영감을 받아 "correction-centric evolution" 전략을 사용한다.
■ 전체 questions에서 무작위로 questions을 선택하여 evolution시키는 것과 비교할 때, correction-centric evolution은 correction data를 확장하기 위해 적당히 어려운 questions만 evolution시킨다(즉 변형시켜 questions을 확장한다).
■ 생성된 correction data를 CoT data와 혼합한 다음, LLM을 fine-tuning하여 mistakes을 학습시킨다.
■ ablation studies에서는 training data의 크기와 training tokens의 수를 동일하게 설정했을 때, CoT data와 correction data를 혼합해서 사용하는 것이 CoT data만 단독으로 사용하는 것보다 성능이 우수함을 보여준다. 이러한 결과는 CoT data와 correction data의 효과가 서로 다른 성지을 갖고 있음을 시사한다.
- CoT data는 정답으로 가는 길을 가르친다고 하면, correction data는 오답을 피하는 길을 가르친다. 즉, 이 두 가지 지식은 서로 대체재가 아니라 보완재이다.
■ 그리고 questions을 무작위로 선택하는 것과 비교했을 때, 논문의 correction-centric evolution 전략이 LMEA의 성능을 더 크게 향상시킨다. 이는 "적당히 어려운" questions이 correction data를 확장하는 데 더 적합하다는 것을 의미한다.

2. Methodology
■ LEMA의 세 가지 주요 단계로 구성된다: generating correction data, correction-centric evolution, 그리고 fine-tuning
2.1 Correction Data Generation

■ Fig 2는 correction data 생성 과정을 간략히 나타낸 것이다.
■ question-answer example \( (q_i, a_i) \in \mathcal{Q} \), corrector model \( \mathcal{M}_c \)와 reasoning model \( \mathcal{M}_r \)이 주어지면, 이를 통해 mistake-correction data pair \( (q_i \oplus \tilde{r}_i, c_i) \in \mathcal{C} \)를 생성한다.
- 여기서 \( \tilde{r}_i \)는 question \( q_i \)에 대한 inaccurate reasoning path를 의미하며, \( c_i \)는 \( \tilde{r}_i \)에 대한 correction을 의미한다.
- \( \mathcal{C} \)는 [question + 이 question에 대한 틀린 reasoning path, 교정 내용]으로 구성된다.
Collecting Inaccurate Reasoning Paths
■ 먼저 reasoning model \( \mathcal{M}_r \)을 사용하여 각 question \( q_i \)에 대해 여러 개의 reasoning paths을 샘플링하고, 올바른 최종 정답 \( a_i \)를 맞추지 못한 reasoning path(즉, 오답으로 이어진 reasoning path)를 수집한다.

■ 여기서 \( \mathcal{P}_r \)은 \( \mathcal{M}_r \)에게 CoT reasoning을 수행하도록 지시하는 few-shot prompt이며, \( \text{Ans}( \cdot ) \)는 reasoning path에서 final answer \( a_i \)를 추출한다.
- rationale이 맞았는지 틀렸는지 판단하지 않고, final answer이 틀린 경우만 확실한 mistake로 간주한다.
Generating Corrections for Mistakes
■ question \( q_i \)와 inaccurate reasoning path \( \tilde{r}_i \)에 대해, corrector model \( \mathcal{M}_c \)를 사용하여 correction을 생성하고, 생성된 correction 내용 안에서 final answer를 확인한다.
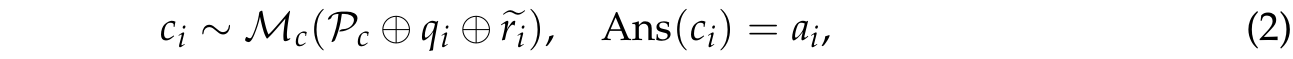
■ 여기서 \( \mathcal{P}_c \)는 생성된 corrections에 어떤 종류의 정보가 포함되어야 하는지 corrector model을 guide하기 위한 4개의 annotated mistake-correction examples이 포함되어 있다.
■ Fig 3은 이러한 \( \mathcal{P}_c \)를 간략히 나타낸 것이다. 구체적으로, annotation이 달린 correction은 다음 세 가지 정보로 구성된다.
- (1) Incorrect Step: original reasoning path의 어느 단계에서 mistake가 발생했는지
- (2) Explanation: 어떤 종류의 mistake가 발생했는지 설명
- (3) Correct Solution: correct answer에 도달하기 위해 original reasoning path를 어떻게 수정해야 하는지

Human Evaluation for Generated Corrections
■ 대규모로 data를 생성하기 전에, 먼저 GPT-4가 생성한 corrections이 정말 효과적인지를 확인하기 위해, 저자들은 생성된 corrections의 quality를 수동으로 평가(즉, human evaluation)했다.
■ LLaMA-2-70B를 \( \mathcal{M}_r \)로, GPT-4를 \( \mathcal{M}_c \)로 사용하여, GSM8K training set을 기반으로 50개의 mistake-correction data pairs을 생성한 다음, corrections의 quality를 다음 세 가지로 분류한다.
- quality level에 대한 예시는 Appendix B.1
- (1) Excellent: corrector model(GPT-4)이 \( \tilde{r}_i \)에서 incorrect step을 성공적으로 식별하고, 합리적인 설명을 제공하며, corrected된 reasoning path가 original reasoning path의 이전 steps과 높은 연속성을 보인다. (즉, 앞의 풀이 흐름을 자연스럽게 이어받은 다음, 틀린 부분을 잘 식별해서 개선된 설명을 제공한다)
- (2) Good: corrector model이 \( \tilde{r}_i \)에서 incorrect step을 성공적으로 식별하고, 합리적인 설명을 제공하지만, corrected된 reasoning path의 연속성에 약간의 문제가 있다.
- (3) Poor: corrector model이 \( \tilde{r}_i \)에서 incorrect step을 식별하지 못하거나 비합리적인 설명을 제공한다.
■ 평가 결과, 생성된 50개의 corrections 중 35개가 Excellent, 11개가 Good, 4개가 Poor이었다고 한다.
■ 이러한 human evaluation의 결과를 토대로, 저자들은 GPT-4로 생성된 corrections의 전반적인 품질이 fine-tuning stage에서 사용하기에 충분하다고 판단했다.
2.2 Correction-Centric Evolution
■ 초기 단계에서 생성한 correction data만으로는 충분하지 않으므로, 저자들은 correction data의 데이터의 다양성을 확보하고 scale up시켰다.
■ 구체적으로, CoT augmentation에 대한 evolution techniques의 성공(Wizardlm, Metamath 등)에서 영감을 받아, evolution method를 사용하여 correction data를 확장시키고자 하였다.
■ 여기서 "evolution"이란 강력한 LLM에 prompt를 입력하여 주어진 seed questions(즉, 기존 questions)로부터 새로운 question-answer pairs의 set를 생성하는 것을 의미한다.
■ CoT augmentation을 위한 일반적인 evolution method는 evolve시킬 seed questions을 무작위로 선택하는 것이다. 그러나 저자들은 이 전략이 correction data의 특성에는 잘 맞지 않는다고 판단하였다.
■ 왜냐하면 너무 쉽거나 너무 어려운 questions은 correction 내용을 collecting하고 evolving시키는 데 가치가 떨어지기 때문이다.
- (1) 너무 쉬운 questions의 경우: LLaMA와 같은 models은 이러한 questions을 쉽게 맞출 수 있다. 너무 쉬운 문제들에 대해선 모델이 mistake를 하지 않으므로, 많은 mistakes을 수집하기 어렵다. 즉, mistakes을 수집하는 데 비효율적이다.
- (2) 너무 어려운 questions의 경우: 가장 powerful한 LLMs도 풀지 못하거나 잘못된 correction을 제공할 수 있다. 그러므로 너무 어려운 questions을 evolving시키는 것은 생성된 correction의 내용에 부정확한 정보를 많이 포함시킬 위험이 있다.
■ 그래서 저자들은 적당히 어려운 questions에만 집중하는 전략, correction-centric evolution을 채택했다.
■ 실행 방법은 다음과 같이 entire set \( \mathcal{Q} \)에서 무작위로 question을 샘플링하는 대신, 위의 과정에서 만들어 놓은 correction data \( \mathcal{C} \)에 포함된 questions만을 seed questions로 샘플링한다.
■ 여기서 \( q_i \)는 seed question이고, \( \mathcal{M}_e \)와 \( \mathcal{P}_e \)는 각각 questions을 evolving시키기 위한 LLM과 prompt이다.
- \( \mathcal{P}_e \)의 예시는 Appendix B.3
■ 이 전략이 효과적인 이유은 \( \mathcal{C} \)에 포함된 questions의 특성 때문이다. \( \mathcal{C} \)에 포함되어 있다는 것은 student model이 틀렸지만, teacher model은 풀 수 있는 문제들이다.
■ 즉, 적당히 난이도가 있어서 개선 여지(배울 점)이 존재하며, 너무 어렵지는 않아서 teacher가 정답과 해설을 만들어 student에게 가르쳐 줄 수 있는, "적당히 어려운" 문제들, 혼자서는 못 풀지만 도움을 받으면 풀 가능성이 있는 문제들이다.
- 만약 어떤 question이 \( \mathcal{C} \)에 빈번하게 등장한다면, 해당 question은 student가 풀기 어려워하는 문제이다.
- 단, teacher(corrector model, 예: GPT-4)는 student가 어려워하는 그 문제를 풀 수 있으므로, 이를 통해 student의 inaccurate reasoning path를 accurate reasoning path로 교정할 수 있다.
2.3 Fine-Tuning LLMs
■ correction data를 생성한 후, 이 correction data가 CoT reasoning을 촉진할 수 있는지 확인하기 위해 LLM을 fine-tuning한다. 저자들은 두 가지 setting에서의 결과를 비교한다.
- (1) Fine-Tuning on CoT Data Alone: 오직 CoT data만을 활용하는 fine-tuning baselines을 설정하기 위해, 각 task의 annotated data 외에도, 기존 방법들을 따라 CoT data augmentation을 추가로 수행했다. GPT-4를 사용하여 training sets의 각 question에 대해 더 많은 reasoning paths을 생성하고, 틀린 최종 정답을 가진 paths은 걸러낸다.
- CoT data만 사용하는 setting은 CoT data + correction data를 같이 사용하는 아래의 setting에 비해 학습에 사용하는 data의 절대적인 양이 부족하다.
- 저자들은 학습에 사용한 data가 부족해서 Fine-Tuning on CoT Data Alone setting에서 성능이 낮은 것이라는 해석을 방지하기 위해, 기존 방법들을 따라 CoT data를 augmentation한 것이다.
- 즉, correction data가 주는 performance gain을 명확히 측정하려 한 것이다.
- (2) Fine-Tuning on CoT Data + Correction Data: CoT data와 생성한 mistake-correction data 모두에 대해 LLM을 fine-tuning시킨다. 이 setting을 LEMA(LEarn from MistAkes)라고 부른다.
■ fine-tuning 및 evaluation에 사용된 CoT data와 correction data의 입력-출력 format은 Appendix B.2의 Fig 6에서 볼 수 있다.
3. Experimental Setup
3.1 Tasks
■ 네 가지 mathematical reasoning tasks (GSM8K, MATH, SVAMP, ASDiv)과 한 가지 commonsense reasoning task (CSQA)를 포함하여 총 다섯 가지의 challenging reasoning tasks에 대해 실험을 수행한다.
■ GSM8K, MATH, CSQA의 각 training sets을 기반으로 correction data를 생성한다.
GSM8K
■ high-quality의 grade school math word problems이다. CoT가 포함된 7,473개의 training examples과 1,319개의 test cases로 구성되어 있다.
MATH
■ challenging competition mathematics problems을 해결하는 math reasoning을 검증하기 위해 사용한다. 7,500개의 training CoT data와 5,000개의 test cases로 구성되어 있다.
SVAMP
■ state descriptions으로서 짧은 자연어 서술을 가진 questions로 구성()되어 있다. SVAMP에 대한 평가를 위해, GSM8K와 동일한 training data를 사용하며 SVAMP의 1,000개 examples 전체를 test cases로 사용한다.
ASDiv
■ 언어 패턴과 문제 유형 측면에서 모두 다양한 math dataset이다. ASDiv에 대한 평가를 위해, GSM8K와 동일한 training data를 사용하며 ASDiv의 2,084개 examples에 대해 테스트한다.
- 같은 수학적 연산이라도 다양한 단어와 구문 사용(예: 뺄셈을 나타내기 위해 "take away", "how many more", "difference" 등 다양한 표현 사용)
- 덧셈, 뺄셈, 곱셈, 나눗셈 등 다양한 유형의 문제들로 구성
CSQA
■ commonsense reasoning을 위한 question answering dataset이다. training set에 9,741개의 examples, dev set에 1,221개의 examples을 가지고 있다. training examples에는 어떠한 CoT annotation도 달려 있지 않다.
■ 그래서 저자들은 먼저 CoT examples에 annotation을 달고(Fig 8), training set을 사용하여 CoT data를 증강하고 correction data를 생성하였다.
- CoT는 세 부분으로 구성된다: 각 candidate answers에 대한 설명, 예측된 final answer, 그리고 해당 answer를 선택한 이유

■ SVAMP와 ASDiv에 대해서는 해당 tasks의 training data로 학습하지 않고(GSM8K data로만 학습) 테스트만 진행한다. 이는 모델이 GSM8K 문제를 외워서 푸는 것이 아니라, 수학적 원리를 깨우쳐서 OOD에서도 풀 수 있는지 검증하기 위한 설계이다.
■ 그리고 수학뿐만 아니라, CSQA를 통해 일반적인 상식 추론 영역에서도 LEMA가 통하는지 확인하고자 한 것이다.
3.2 Data Construction
CoT Data
■ GSM8K(및 SVAMP, ASDiv)의 경우, CoT data는 GSM8K의 모든 training examples과, 24,948개의 증강된 reasoning paths로 구성된다.
- 먼저 GPT-4로 30,000개의 reasoning paths을 생성하고, final answer이 틀린 경우나 예상치 못한 형식을 가진 5,052개의 reasoning paths을 필터링했다.
■ MATH의 경우 CoT data는, 모든 training examples과 12,509개의 증강된 reasoning paths로 구성된다.
- 먼저 GPT-4로 30,000개의 reasoning paths을 생성하고, 17,491개의 paths을 걸러냈다.
■ CSQA의 경우, GPT-4로 15,000개의 reasoning paths을 생성한 후 4,464개의 paths을 걸러냈다.
Correction Data
■ LLaMA-2, WizardLM, WizardMath, Text-Davinci-003, GPT-3.5-Turbo, GPT-4를 포함한 LLM들을 활용하여 inaccurate reasoning paths을 수집한다.
■ GPT-4는 corrector model로 사용한다.
■ 최종적으로, GSM8K, MATH, CSQA의 training sets을 기반으로 각각 12,523개, 6,306개, 7,241개의 mistake-correction pairs을 수집했다.
Correction-Centric Evolution
■ correction data \( \mathcal{C} \)에 있는 questions 중에서 10K 개를 부트스트랩 방식으로 추출하여 seed questions로 사용한다. 그리고 해당 questions을 evolve시키기 위해 GPT-4를 사용한다.
■ evolved된 questions에 대한 정답(ground-truth)을 생성하기 위해, GPT-4를 사용하여 각 question당 세 개의 answers을 샘플링하고 majority voting을 진행한다. 세 개의 answers이 모두 다르게 나오는 question은 사용하지 않는다.
■ 이렇게 evolved된 data는 오직 섹션 4.2 How Beneficial Is Correction-Centric Evolution? 실험에서만 사용된다.
3.3 Fine-Tuning and Evaluation
■ LLaMA, LLaMA-2, CodeLLaMA, WizardMath, MetaMath families의 여러 open-source LLMs을 fine-tuning한다.
■ 이 모델들에 대해 PEFT를 수행하기 위해 QLoRA를 사용한다. low-rank 차원을 64로, dropout rate는 0.05로 설정한다.
■ learning rate는 34B 이상인 LLM에 대해서는 0.0001로, 34B 미만인 LLM에 대해서는 0.0002를 사용한다.
■ batch size는 96으로 설정하고, 2,000 steps 동안 학습시키며, 매 100 training steps마다 체크포인트를 저장한다.
■ evaluation을 위해서는 vLLM 라이브러리를 기반으로, 저장된 모든 체크포인트의 성능을 평가하고 가장 좋은 체크포인트의 정확도를 reporting한다.
■ inference time에서는 temperature를 0으로(즉, greedy decoding) 설정하고 max sample length를 2,048로 설정한다.
■ training 중 random disturbances의 영향을 명확히 하기 위해, 상위 3개 체크포인트의 성능을(Appendix D.1), 전체 training 과정 동안의 성능 곡선(Appendix D.2)을 확인한다.
- Appendix D.1의 Table 5는 fine-tuning 과정에서 저장된 가장 우수한 세 개의 체크포인트의 성능과 세 결과의 평균이다.
- D.2의 Fig 9.는 2,000번의 fine-tuning steps 동안 LLaMA-2-70B의 성능 곡선이다. correction data를 추가하면 training 중에 뚜렷한 개선이 나타나는 것을 볼 수 있다.
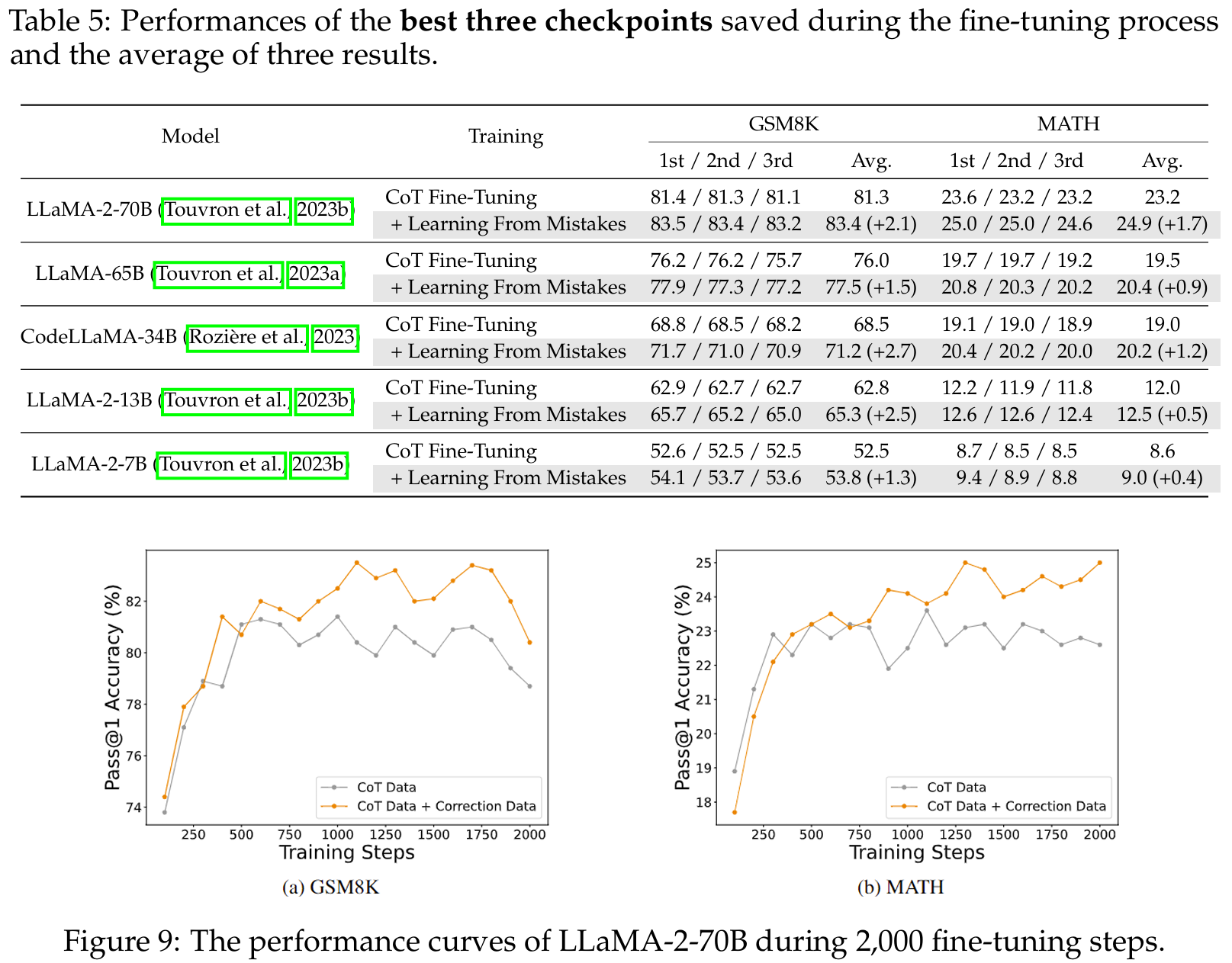
- 이는 correction data의 효과가 training 중에 발생할 수 있는 어떤 랜덤한 요인들로 인해 성능이 일시적으로 높게 나온 결과가 아님을 증명하기 위한 실험 설계이다.
■ 기본적으로 fine-tuning과 evaluation 모두에서 prompt에 demonstration examples을 추가하지 않는다.
■ 모든 evaluations은 동일한 CoT instruction 하에서 수행된다.
■ 그리고 LEMA로 학습된 모델의 경우, evaluations 중에 correction을 생성하지 않았다. (즉, 모든 실험 결과들은 evaluation용의 data에 대해 correction data를 생성하고 사용하지 않은 결과들이다)
■ 모든 실험은 4개의 A100 GPU stations에서 수행되었다고 한다.
4. Results and Analysis
4.1 Can LLMs Learn From Mistakes?
LEMA effectively improves CoT-alone fine-tuning
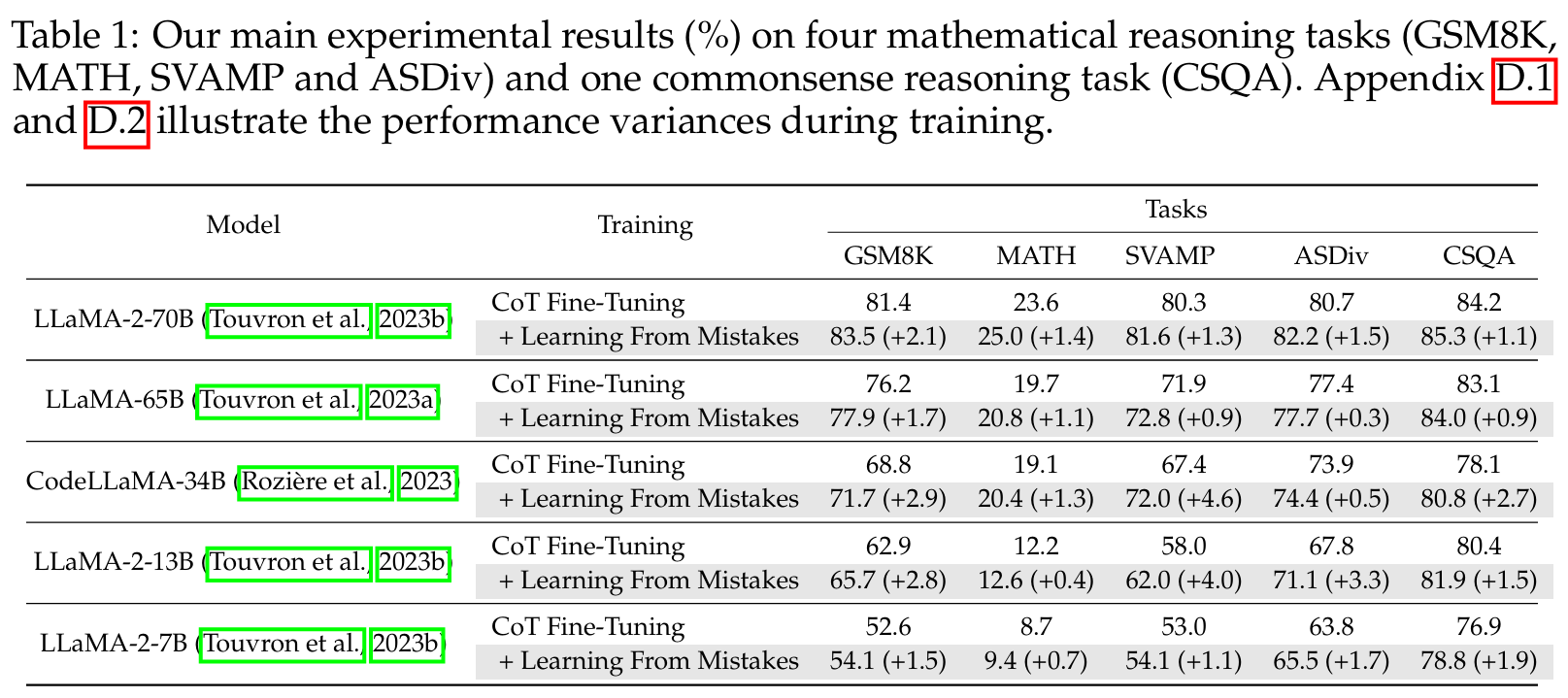
■ CoT data로만 fine-tuning하는 것과 비교할 때, correction data를 통합해서 사용하는 것이 5개의 모든 LLM과 5개의 tasks 전반에 걸쳐 성능 향상으로 이어진 것을 Table 1에서 볼 수 있다.
■ 또한, SVAMP와 ASDiv의 결과를 통해 LEMA가 OOD 시나리오에서 일정 수준의 generalizability를 가지고 있음을 시사한다.
■ 이는 LEMA가 CoT fine-tuning에 효과가 있는 방법론임을 보여주는 결과이다.
The effectiveness of CoT data and correction data are non-homogeneous
■ 만약, CoT data와 correction data의 효과가 비슷하다면(즉, 질적으로 비슷한 학습 효과를 낸다면), 두 데이터의 크기를 동일하게 설정했을 때 Table 1에서의 performance gain들은 사라질 것이다.
- 즉, Table 1의 성능들이 단지 모델이 학습한 데이터의 양이 CoT data보다 correction data가 더 많아서 발생한 것이라면, 두 데이터의 수를 동일하게 설정했을 때, 두 데이터의 역할이 같다면 성능 개선이 사라질 것이다.
■ 저자들은 이를 검증하기 위해 두 가지 ablation studies을 수행한다.
■ default setting에서는 CoT-alone fine-tuning을 위해 약 32K 개, LEMA를 위해 45K 개의 examples을 가지고 있다. 다음은 두 가지 controlled settings이다.
- (1) LEMA-32K: 13K 개의 correction data는 유지하고, 13K 개의 CoT data를 무작위로 제거하여 총량 32K로 맞춤. LEMA-32K로 CoT-32K와 비교
- (2) CoT-45K: CoT data 양을 늘리기 위해, 각 correction example에서 corrected CoT를 추출하여 총량 45K로 맞춤. CoT-45K로 LEMA-45K와 비교

■ Fig 4에서 데이터 개수가 동일한 상황에서도 LEMA가 5개 중 4개의 LLM에서 여전히 더 높은 성능을 보인 것을 확인할 수 있다.
■ 이는 LLM들이 CoT data에서는 제공되지 않는 추가적인 정보를 correction data로부터 학습한다는 것을 의미한다.
■ 유일한 예외는 LLaMA-2-7B이다. 이는 LEMA로 효과를 보려면 어느 정도 강력한 모델을 사용해야 함을 시사한다.
■ 앞선 실험에서 데이터의 크기(개수)를 똑같이 맞췄지만, 데이터의 길이가 다르다. CoT data 대비 LEMA data는 왜 틀렸는지 설명과 고친 풀이가 들어가 있기 때문에 더 많은 training tokens을 가지게 된다.
- 구체적으로 CoT-45K는 5.4M의 training tokens, LEMA-45K has 5.8M
■ 그래서 저자들은 LEMA의 효과가 시퀀스의 길이에서 발생하는지 확인하기 위해, 동일한 크기의 training tokens 하에서 CoT-alone fine-tuning과 비교하여 LEMA의 training-token efficiency를 확인했다.
■ 이를 위해 섹션 2.3을 따라 더 많은 reasoning paths을 샘플링하여 CoT-45K에 추가함으로써 CoT-5.8M을 구축했다.
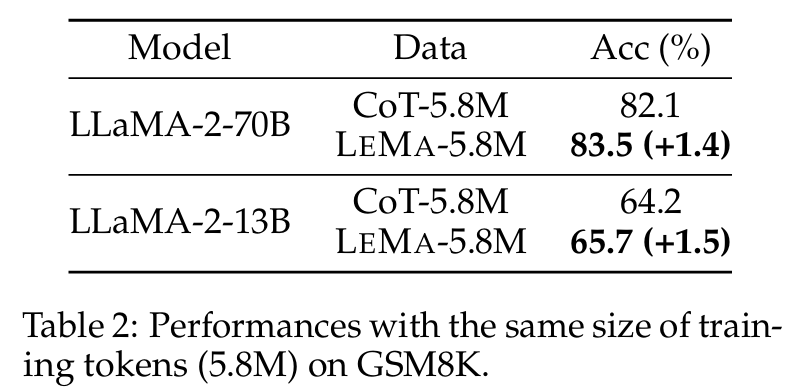
■ Table 2는 동일한 수의 training tokens을 사용하더라도 LEMA가 여전히 CoT-alone fine-tuning보다 우수함을 보여준다.
■ 그리고, Fig 4와 Table 2를 통해 LLaMA-2-70B의 경우 더 많은 reasoning paths을 증강(즉, 더 많은 CoT data를 사용)하는 것이 GSM8K에서 성능을 지속적으로 높여주지 않는다는 것을 볼 수 있다.
■ 이를 검증하기 위해 CoT-5.8M을 CoT-6.8M으로 더 확장해 보았으니 정확도는 82.2%였다고 한다. 저자들은 이 결과에 대해 "같은 질문에 대해 너무 많은 reasoning paths을 샘플링하는 것은 오히려 training에서 중복된 정보만을 가져오기 때문"이라고 추측한다.
- 이미 풀 줄 아는 문제에 대해 GPT-4를 사용하여 또 다른 정답 풀이를 계속 만들어도, 이렇게 생성된 풀이들은 워딩만 다를 뿐, 논리적 구조는 기존 풀이와 비슷할 확률이 높다.
- 즉, 모델 입장에서 새로운 지식이나 논리를 배우는 것이 아니라, 이미 아는 내용을 반복해서 보는 것에 불과할 수 있다는 주장이다.
- 그러므로, 같은 문제에 대한 reasoning paths을 많이 보여주는 것(CoT data 증강)보다는, 무엇을 틀렸는지와 어떻게 고치는지를 보여주는 것이 질적으로 다른 정보를 제공하므로 훨씬 효과적이라는 것이다.
A stronger backbone model can be more effective at learning from mistakes
■ Table 1에서 볼 수 있듯이, LLaMA-2-70B는 CoT-alone fine-tuning에서 가장 높은 baseline performances을 보이면서도, LEMA로도 5개 tasks 모두에서 상당한 향상을 달성했다.
■ 반면, 나머지 4개의 덜 강력한 모델들은 LEMA를 적용했을 때 성능 향상 폭이 미미하다(Fig 4, 모델 크기가 작아질수록 성능 향상 폭이 감소한다). 이는 모델의 체급이 너무 작으면 실수를 교정해도 잘 학습하지 못한다는 것을 시사한다.
LEMA can also facilitate specialized LLMs
■ pre-trained LLMs 중에는 수학 도메인에 특화된 WizardMath나 MetaMath와 같은 domain-specific LLMs이 있다. 저자들은 이러한 특화된 LLMs에도 LEMA가 효과가 있는지 확인했다.
■ 이 모델들은 math tasks을 위해 설계된 대량의 CoT data로 이미 학습되었으므로, LEMA를 이 특화 모델들의 original papers에 보고된 결과와 비교한다.
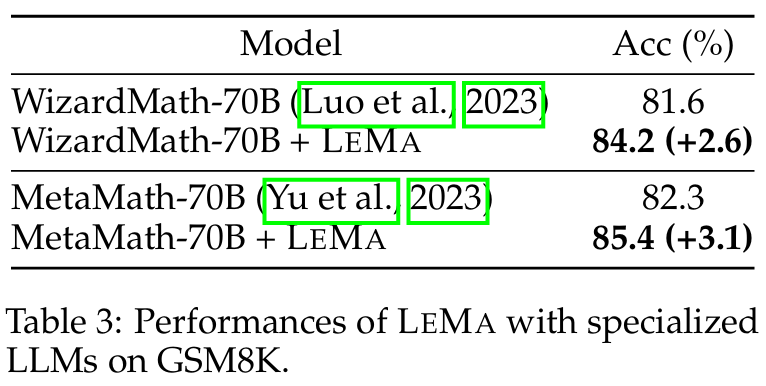
■ Table 3은 LEMA가 이러한 specialized LLM들을 더욱 향상시킬 수 있음을 보여준다. (detailed comparisons Appendix D.3)
4.2 How Beneficial Is Correction-Centric Evolution?

■ Fig 5에서 correction-centric evolution까지 적용했을 때, LEMA의 성능이 추가로 향상된 것을 볼 수 있다.
Correction-centric evolution can more effectively improve LEMA
■ Fig 5 (a)는 이전 연구들에서 적용한 일반적인 evolution strategy과 저자들이 제안한 correction-centric evolution strategy을 비교한 것이다. 공정한 비교를 위해, seed questions의 수는 두 방법 모두 동일(즉, 10K 개)하게 사용하였다.
■ 수학 관련 코퍼스로 사전 학습된 Llemma 모델도 테스트에 포함했으며, correction data의 규모가 크게 증가했으므로 저자들은 LLM을 full fine-tuning하였다.
■ Fig 5 (a)를 통해 알 수 있는 것은, (1) LEMA는 evolution techniques로부터 performance gain을 얻을 수 있다. 즉, 기존의 일반적인 evolution strategy를 사용해도 LEMA의 성능이 더욱 향상될 수 있다. (2) correction-centric evolution가 evolution strategy보다 더 효과가 좋다.
■ 이는 적당히 어려운 questions이 correction data를 확장하는 데 더 적합하다는 저자들의 주장을 뒷받침하는 결과이다.
Evolution techniques can better facilitate LEMA under full fine-tuning
■ LEMA의 scaling trend를 확인하기 위해, 또 다른 10K 개의 샘플링된 seed questions(Appendix C.5)로 correction-centric evolution을 적용했다.
■ Fig 5 (b)는 question set이 확장됨에 따른 LEMA의 성능 추세를 나타낸 것이다.
■ 각 선의 시작점은 MATH의 original question-answer pairs만 사용했을 때 얻은 성능이다. 즉, 데이터가 소량일 때는 QLoRA와 full fine-tuning 간에 LEMA의 성능 차이가 없다. 즉, 데이터가 소량일 때는 QLoRA를 사용하는 것이 이득이다.
■ 그러나 question set이 확장됨에 따라 full fine-tuning의 성능은 향상되는 반면, QLoRA fine-tuning은 full fine-tuning 대비 아주 약간 오른 것을 볼 수 있다.
D.4 Ablations of Correction Information
The explanations and corrected reasoning paths play important roles in LEMA

■ 섹션 2.1에서 소개된 바와 같이, correction data는 세 가지 정보를 포함하고 있다: mistake step(M.S.), corrected solution(C.S.), explanation to the mistake(Exp.)
■ Fig 12는 LEMA 성능에 대한 각각의 개별적 기여도를 평가하기 위해, correction data에서 각 정보를 따로따로 생략한 실험 결과이다.
■ corrected solution이나 explanation이 없으면 LEMA의 성능이 크게 떨어지는 반면, mistake step을 생략하는 것은 성능에 미치는 영향이 적은 것을 볼 수 있다.
■ 즉, mistake의 위치를 명시적으로 식별하도록 유도하는 것은 LEMA 성능에 핵심적인 역할을 하지 않는다.
■ 이 결과에 대해 저자들은 corrected solution과 explanation이 어느 step에서 잘못되었는지를 이미 암시적으로 알려주고 있기 때문이라고 주장한다.
D.5 Additional Analysis to LEMA
LEMA can still bring improvements to CoT fine-tuning if the distributions of questions are controlled the same
■ correction data는 LLMs이 쉽게 해결할 수 없는 challenging questions(즉, 틀린 문제들)이 포함된다. 이는 training data 내 questions 난이도의 분포 변화(distribution shift)를 야기한다.
■ 이러한 training data의 분포 변화 자체가 LLM fine-tuning에 benefit을 주어 모델 성능이 좋아질 수 있다.
■ 그래서 저자들은 question distribution shifd의 영향을 제거하고 LEMA의 효과를 확인하고자 하였다. 이는 ablation setting인 CoT-45K가 이 점을 명확히 하는 데 사용될 수 있다.
- CoT-45K를 만들기 위해 추가한 data는 correction data로부터 변환된 것이므로, CoT-45K와 default LEMA-45K의 question distribution은 정확히 동일하기 때문이다.
■ Fig 4의 45K data size 결과는 question distribution shift의 영향이 동일하게 유지될 때에도 LEMA가 여전히 CoT-alone fine-tuning보다 우수함을 보여준다. 즉, 성능 향상 원인이 data distribution때문이 아니라, LEMA의 학습 방식에 있음을 의미한다.
QLoRA fine-tuning cannot fully “digest” a large amount of correction data
■ Fig 5 (b)에서 볼 수 있듯이, correction data의 양이 늘어날수록 full fine-tuning과 QLoRA fine-tuning 간의 성능 격차가 점점 벌어진다. 이러한 결과는 일부 기존 연구들의 결론과 잘 부합하지 않는다.
■ 일부 연구들은 모델 크기가 충분히 크다면 PEFT가 full fine-tuning과 비슷한 성능을 달성할 수 있다고 결론짓는다.
■ 저자들은 correction data의 특성이 이전 연구들의 결론과 불일치하는 원인이라고 추측한다.
■ 구체적으로, correction data는 in-task training에 직접적으로 기여하지 않는 auxiliary data일 뿐이다. 즉, 정답을 직접 알려주는 data가 아니라 틀린 문제에 대한 correction가 핵심인 data이다.
■ 그래서 저자들은 PEFT를 적용한 모델이 대량의 correction data를 "eat"할 수는 있지만(즉, 학습할 수는 있지만), 완전히 "digest"할 수는 없다(즉, 학습할 수는 있지만 correction data가 주는 깨달음을 온전히 내재화할 수는 없다)고 가정한다.
The comparison learned in the correction data also influences the CoT generation
■ correction data에 대한 training 중에, LLM은 올바른 CoT와 부정확한 CoT를 모두 접하게 되므로, 둘 사이의 차이를 인식할 수 있다.
■ 저자들은 이 과정에서 정답과 오답의 차이를 비교하는 법을 배워, 결과적으로 CoT 생성 중에 효과를 발휘할 수 있다(즉, 틀린 풀이는 피하고 맞는 풀이를 선호)고 가정하였다.
■ 이 가설을 증명하기 위해 다음과 같은 PPL 차이에 대한 지표를 정의했다.

- 여기서 \( \mathcal{C} \)는 set of correction data, \( \theta \)는 fine-tuning 후의 model parameters
- \( \text{PPL}(y \mid x; \theta) \)는 context \( x \)가 주어졌을 때 \( y \)에 대한 perplexity를 반환하는 함수
- \( \tilde{r}_i \)는 question \( q_i \)에 대한 잘못된 CoT, \( r_i \)는 correction \( c_i \)에서 추출한 올바른 CoT이다.
■ 그러므로 위의 식은, set of correction data \( \mathcal{C} \) 내의 각 샘플에 대해, 잘못된 CoT의 PPL에서 올바른 CoT의 PPL을 뺀 값의 평균이다.
■ 핵심은 "오답의 PPL - 정답의 PPL" 값이다.
■ 정답의 PPL 값이 낮을수록 올바른 CoT에 대해 모델이 자연스럽고 확실하다 판단한 것, 오답의 PPL 값이 높을수록 부정확한 CoT에 대해 모델이 부자연스럽고 틀린 것 같다고 판단한 것으로 해석할 수 있다.
■ 그러므로 \( \Delta \text{PPL} \) 값이 클수록, 모델이 정답에 비해 오답을 훨씬 더 이상한 것으로 인식하는, 즉 실수를 감지하고 구별하는 능력이 뛰어나다는 것을 의미한다.
■ 저자들은 GSM8K와 MATH의 correction data를 기반으로, fine-tuned LLaMA-2-70B와 LLaMA-65B에 대해 \( \Delta \text{PPL} \)을 계산했다.

■ Fig 11에서 볼 수 있듯이, LEMA가 CoT-alone fine-tuning보다 일관되게 더 높은 \( \Delta \text{PPL} \) 값을 달성한다.
'자연어처리 > Reasoning' 카테고리의 다른 글
| Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations (0) | 2026.01.12 |
|---|---|
| Let's Verify Step by Step (1) | 2026.01.10 |
| USC: Universal Self-Consistency for Large Language Model Generation (0) | 2025.12.22 |
| Large Language Models Cannot Self-Correct Reasoning Yet (0) | 2025.12.18 |
| Self-Refine: Iterative Refinement with Self-Feedback (0) | 2025.12.11 |