■ CoT prompting을 활용한 self-consistency는 LLM에서 다양한 reasoning paths을 샘플링함으로써 여러 어려운 tasks에서 획기적인 성능 향상을 보여줬다.
■ 그러나 self-consistency는 투표를 통해 정답을 추출하는 방식이기 때문에, 자유 형식(free-form)의 answer에는 적용할 수 없다는 한계가 있다.
- 수학 문제처럼 답이 숫자로 딱 떨어져서 정답을 추출할 수 있는 경우에는 사용할 수 있지만, 요약이나 생성과 같은 tasks에는 적용할 수 없다. 예를 들어 요약을 10번 생성하면 10번 다 문장이 다르기 때문에 투표를 할 수가 없다.
■ 논문에서는 기존 self-consistency를 적용할 수 없었던 open-ended generation tasks에서도 사용할 수 있는 Universal Self-Consistency (USC)를 제안한다.
■ USC는 별도의 추출이나 code executor를 사용하는 대신, LLM 자체를 활용하여 여러 candidate answers 중 가장 일관성(consistency) 있는 answer를 선택하는 방식이기 때문에, 기존 self-consistency로는 적용 불가능했던 tasks에도 사용할 수 있다.
■ 특히 mathematical reasoning에서는 기존 방식처럼 answer format을 통일할 필요가 없으며, code generation의 경우 코드를 실제로 실행해보지 않고 텍스트만 보고도, 실행 결과를 보고 고른 것만큼 정확한 코드를 찾아내기 때문에 코드 실행 결과에 접근할 필요가 없다.
[2311.17311] Universal Self-Consistency for Large Language Model Generation
Universal Self-Consistency for Large Language Model Generation
Self-consistency with chain-of-thought prompting (CoT) has demonstrated remarkable performance gains on various challenging tasks, by utilizing multiple reasoning paths sampled from large language models (LLMs). However, self-consistency relies on the answ
arxiv.org
1. INTRODUCTION
■ LLM이 생성한 responses은 길이가 길어질수록 그 내용이 틀리는 경우가 많다.
■ 이 문제를 개선하기 위해, 여러 model의 responses을 샘플링한 후 특정 기준에 따라 최종 output을 선택함으로써 output quality를 향상시키려는 연구들이 등장했다.
■ 예를 들어, 이전 연구들은 model의 outputs을 rerank하기 위해 신경망을 학습시키거나, 최근 연구들은 LLM 자체를 사용하여 response를 채점하는 방법을 제안하고 있다.
■ USC는 output을 선택하는 기준으로 model responses 간의 consistency를 고려한다. consistency는 reasoning 및 code generation 분야에서 엄청난 성능 향상을 가능하게 한 지표이다.
■ 특히, CoT prompting을 활용한 self-consistency는 샘플링을 통해 reasoning paths을 marginalizing함으로써, 가장 빈번하게 등장하는 answer를 최종 answer로 선택하게 하여 다양한 벤치마크에서 성능을 크게 높였다.
■ 그러나 self-consistency는 math problems에서의 single number answer와 같이 final answer가 exact match를 통해 집계될 수 있는 tasks에서만 적용할 수 있다는 한계가 있다.
- 예를 들어, 수학 문제 답이 "5"이면, 여러 모델이 생성한 responses 중에서 "5"가 몇 개인지 셀 수 있다.
- 그러나 요약문이나 코드는 표현이 다를 수 있기 때문에 answer인지 판단하기 어렵다.
■ 이러한 self-consistency의 한계를 해결하기 위해, free-form generation tasks을 포함한 다양한 애플리케이션에서 사용할 수 있는 USC를 제안한다.
■ 이 방법은 여러 candidate responses이 주어졌을 때 USC는 단순히 LLM을 호출하여 그중 가장 consistent한 response를 final output으로 선택하게 한다.
■ LLM이 final output을 선택하기 때문에, USC는 별도의 answer 추출 과정을 설계할 필요를 없애주며, free-form answers을 요구하는 tasks에도 사용할 수 있다.
■ 이전 연구들에서 position bias(내용과 상관없이 특정 위치의 답변을 선호하는 경향)나 혹은 아예 정답을 잘못 판단하는 등 response 선택에 있어 LLM 자체를 활용하는 방식의 약점을 보여줬지만, 그럼에도 불구하고 직관적으로, candidate answers 간의 consistency를 평가하는 것은 answer 자체의 quality를 측정하고 비교하는 것보다는 훨씬 더 쉬운 작업이다.
2. BACKGROUND: SELF-CONSISTENCY
■ self-consistency는 여러 개의 reasoning chains을 샘플링한 다음, final answer set에 대해 majority voting을 수행한다.
■ 이 방법은 greedy decoding을 통해 얻은 하나의 reasoning path는 최적이 아닐 수 있으므로, 다양한 reasoning chains을 샘플링하는 것이 더 합리적이며, 샘플링된 것들 중 일부가 동일한 answer로 이어진다면, 이 consistent answer가 정답일 가능성이 더 높다는 직관에 기반한다.
■ 다양한 연구들에서 consistency-based answer selection은 question answering tasks이나 code generation에도 사용되었는데, 이는 코드 실행을 필요로 한다.
■ 구체적으로, 먼저 주어진 inputs에 대해 예측된 프로그램들을 실행해보고, 실행 결과가 같은 코드들은 의미적으로 동일한 코드라고 가정하여 함께 클러스터링한다음, 최종적으로 가장 큰 클러스터에 속한 코드를 최종 예측으로 선택한다.
■ 이러한 성과에도 불구하고, self-consistency는 final answer candidates에 대해 majority voting을 해야 하기 때문에, final answer가 숫자로 딱 떨어지는 고유한 형태의 정답을 가진 문제에만 적용할 수 있다는 한계를 가진다.
■ 이러한 한계로 인해 summarization, creative writing, open-ended question answering과 같이 open-ended generation을 요구하는 tasks에는 적용하기 어렵다.
3. UNIVERSAL SELF-CONSISTENCY

■ Fig 1은 LLM을 활용하여 free-form text generation과 같은 광범위한 tasks에서 self-consistency를 가능하게 하는 universal self-consistency (USC)의 workflow이다.
■ 먼저, 기존 self-consistency와 똑같이 LLM을 사용하여 여러 개의 responses을 샘플링한다.
■ 그 후, 생성된 모든 responses을 하나로 연결한 다음, 언어 모델에게 가장 일관성 있는 response를 요청하는 instruction이 포함된 프롬프트를 사용하여, final answer를 생성한다.
■ 이 방식을 통해 USC는 standard self-consistency에서처럼 정답에 대한 빈도를 계산할 필요가 없으므로, 정답 형식이 고정되지 않은 tasks에도 적용할 수 있다.
■ 대신, 서로 다른 responses 간의 consistency를 판단하는 과정이 LLM 자체의 능력에 의존하게 된다.
■ 이전 연구들에서 LLM이 특히 reasoning problems에 대해 예측의 정확성(correctness)을 평가하는 데에는 어려움을 겪는다는 것을 보여주었지만, 저자들은 LLM이 responses 간의 consistency를 측정하는 능력은 충분하다는 것을 실험을 통해 관찰했다고 한다.
- 예를 들어, A와 B가 선택직로 있는 문제에서 5개의 모델 중 4개가 A라 하고 1개가 B라고 하면, 정답이 A인지 B인지는 몰라도 A가 대세라는 건 알 수 있다. USC는 이 점을 활용한다.
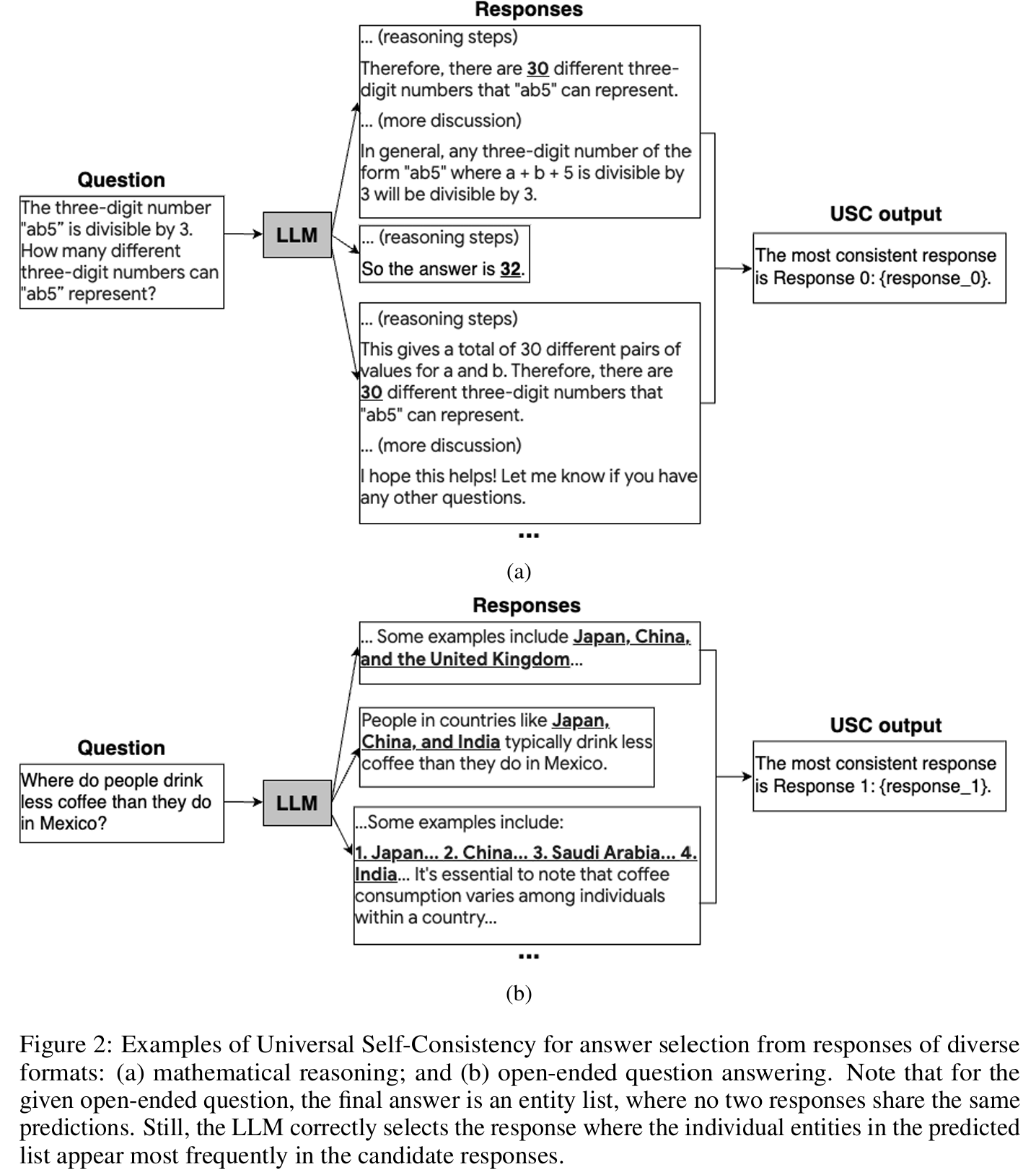
■ LLM을 이용한 consistency 평가의 큰 장점은 다양한 tasks에서 서로 다른 consistency criteria를 유연하게 적용할 수 있는 점이다. Fig 2는 이러한 유연성이 유용하게 사용될 수 있는 예시들을 나타낸 것이다.
■ 구체적으로 Fig 2 (a)는 수학 문제에 대한 다양한 model responses을 보여주는데, output format들이 다양하여 rule-based 방법으로는 정답을 추출하기 어렵다.
■ 그러나 Fig 2 (a)와 같은 수학 문제는 final answers이 올바르게 추출된다면, 다양한 format 속에서 최종 정답(하나의 숫자 값)을 추출하고, 이를 기반으로 exact match 여부를 판단하면 되기 때문에 standard self-consistency를 적용하는 것이 크게 어렵지는 않다.
■ 반면 Fig 2 (b)처럼 정답이 여러 요소로 구성된 경우에는, 각 responses이 부분적으로만 겹칠 수 있어 exact match를 적용하기 어려운 상황이 발생한다.
- question은 "멕시코보다 커피를 덜 마시는 나라는?"이며 이 question에 대해 3개의 response가 존재한다.
- 첫 번째 response는 "일본, 중국, 영국", 두 번째는 "일본, 중국, 인도", 세 번째는 "일본, 중국, 사우디, 인도"이다.
- 모두 문자열이 다르다. 이러면 standard self-consistency에선 이를 서로 다른 3개의 답으로 처리하기 때문에 exact match를 적용하기 어렵다.
- 그러나 USC에서는 LLM(예: GPT-4 API)을 사용하기 때문에 개별 요소의 등장 빈도를 분석하여 합의점을 도출할 수 있다.
- 예를 들어 일본과 중국은 3개의 응답 모두에 등장하고, 인도는 2개의 응답, 나머지 나라는 각각 1개의 응답에만 등장한다. 이런 식으로 LLM은 Fig 2 (b)처럼 가장 빈번하게 등장한 요소들(일본, 중국, 인도)로만 구성된 두 번째 응답을 선택할 수 있다.
4. EXPERIMENTS
4.1 EVALUATION SETUP
Benchmarks
■ 다음과 같은 다양한 tasks에서 USC를 평가한다: Mathematical reasoning benchmarks, Code generation benchmarks, Long-context summarization, TruthfulQA benchmark
■ Mathematical reasoning benchmarks: 8,500개의 초등 수학 단어 문제 dataset GSM8K와 12,5000개의 고교 경시 대회 수학 문제 dataset인 MATH
■ ode generation benchmarks: text-to-SQL 생성을 위한 BIRD-SQL dataset, data science notebooks에서의 Python 코드 생성을 위한 ARCADE dataset
■ Long-context summarization: ZeroSCROLLS의 GovReport 및 SummScreen benchmarks을 사용한다.
■ GovReport에서 각 input은 ~7,900 단어로 구성된 document이며, reference output은 전문가가 작성한 약 500 단어로 구성된 요약문이다.
■ SummScreen에서 모든 input은 약 5,600 단어의 TV 쇼 에피소드 대본이며, 각 reference output은 약 100 단어로 구성된 사람이 작성한 요약이다.
■ 이전 연구를 따라 정답(요약)과 n-gram overlap(즉, 텍스트 일치도)을 측정하기 위해 ROUGE 1, ROUGE 2, ROUGE-Lsum을 사용한다. 그리고 텍스트의 표면적 위치를 넘어 의미적 정확성을 평가하기 위해 BERTScore F1도 사용한다.
■ TruthfulQA benchmark: open-ended question answering을 위한 벤치마크로, 진실한 answers을 생성하는 모델의 능력을 테스트하며 817개의 questions이 포함되어 있다.
■ 저자들은 answer의 quality를 평가하기 위해, 이전 연구를 따라 human feedback data로 fine-tuned된 GPT-3 모델인 GPT-judge와 GPT-info를 사용한다.
■ GPT-judge 모델은 진실성에 대한 binary rating(응답에 진실성이 있는지 아닌지)을, GPT-info 모델은 정보성에 binary rating(정보가 유익한지 아닌지)을 출력한다.
■ 이러한 GPT-3 기반 평가 모델들은 ROUGE, BLEU, BLEURT와 같은 지표보다 인간의 판단을 예측하는 데 있어 더 높은 정확도를 보이는 것으로 알려져 있다.
Decoding schemes
■ USC를 아래의 decoding 방식들과 비교한다.
- (1) Greedy decoding: temperature 0으로 single answer를 생성
- (2) Random: temperature > 0인 여러 샘플 중에서 무작위로 하나의 answer를 선택
- (3) standard self-consistency
- (3)의 경우 저자들은 최종 정답이 exact match를 통해 비교될 수 있는 reasoning benchmarks 같이, 적용 가능한 경우에 self-consistency (SC)를 평가한다.
■ 샘플링 방식들(즉, Greedy decoding을 제외한 Random, SC)의 경우 공정한 비교를 위해, 항상 동일한 initial model responses의 set에서 final answer를 선택한다.
■ code generation의 경우, execution-based self-consistency(code executor를 사용하는 self-consistency를 의미)와 비교한다.
■ 이때 USC와 execution-based self-consistency 모두 먼저 문법적으로 유효하지 않은 candidates을 필터링한 후, 남은 programs에 대해 voting을 수행한다. 필터링 후 남은 코드들의 실행 결과가 가장 많이 겹치는 것을 선택하는 방식이다.
■ ARCADE에서는 단순한 결과 일치가 아닌, 이전 연구에 기술된 'fuzzy matching'을 사용한 execution-based self-consistency를 평가한다. 이는 실행 결과가 문자열 그대로 일치하지 않더라도, 휴리스틱을 통해 의미적으로 동등하면 같은 답으로 간주하는 더 유연한 기준을 적용한 것이다.
Implementation details
■ instruction-tuned된 PaLM 2-L과 gpt-3.5-turbo model을 사용하여 실험을 수행한다.
■ 기본적으로 LLM은 SC와 USC 모두에서 8개의 초기 샘플들을 생성한다.
■ mathematical reasoning, summarization, 그리고 Python code generation을 위한 ARCADE의 경우, 초기 샘플은 zero-shot prompting으로 생성되므로 output format이 다양하다.
■ BIRD-SQL의 경우, 이전 연구를 따라 1-shot chain-of-thought prompt를 사용한다.
■ TruthfulQA에선 candidate responses의 quality를 높이기 위해 one-shot prompt를 사용한다.
■ temperature는 PaLM 2-L의 경우 0.6, gpt-3.5-turbo의 경우 1.0으로 설정한다.
4.2 MAIN RESULTS
Mathematical reasoning
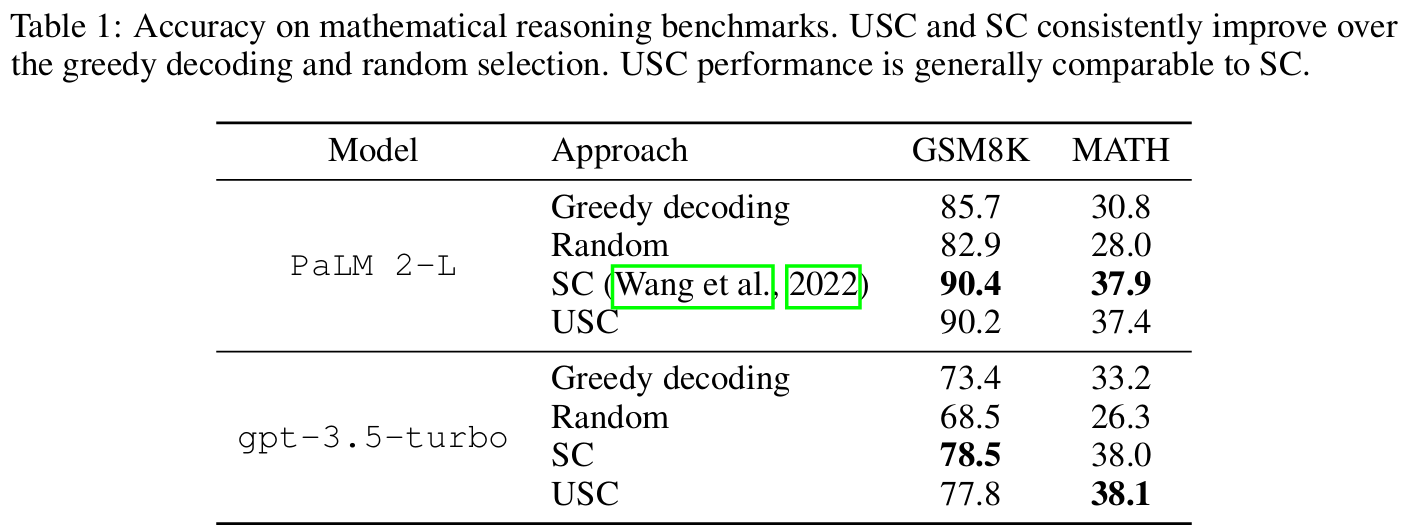
■ standard self-consistency를 위해 GSM8K에서 정규표현식 매칭을 사용하여 final answer를 추출하고, MATH에서는 이전 연구의 answer parsing 코드를 사용한다.
■ 전반적으로 USC는 greedy decoding 및 random selection보다 일관되게 성능을 향상시키며, 그 성능은 standard self-consistency와 비슷한 것을 볼 수 있다.
■ 중요한 차이는 USC의 경우 voting을 수행하기 위해 answer parsing을 필요로 하지 않는다는 것이다.
Code generation
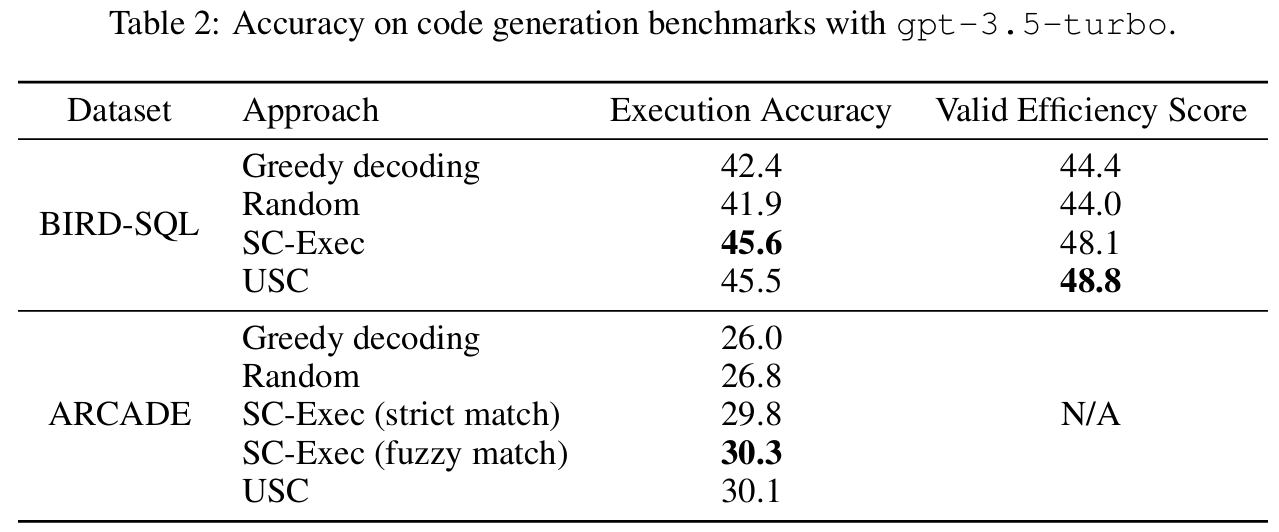
■ BIRD-SQL에서는 execution accuracy 외에도, 이전 연구를 따라 SQL 쿼리의 효율성을 측정하는 valid efficiency score도 평가한다.
■ USC가 두 벤치마크 모두에서 execution-based self-consistency의 성능과 비슷한 것을 볼 수 있다. 단, USC는 voting을 위해 별도의 코드 실행을 하지 않는다.
Summarization

■ 생성된 요약문은 free-form이므로 standard self-consistency은 사용할 수 없다. USC는 모든 지표에 걸쳐 대등하거나 더 뛰어난 성능을 보인다.
■ 저자들은 모델에게 "가장 상세한" 요약문을 선택하도록 프롬프트를 살짝 바꿔서 요청한 결과, 성능이 더 올랐다고 한다. (섹션 4.3)
TruthfulQA

■ 여기서도 생성되는 answer는 free-form이므로 standard self-consistency를 직접 적용할 수 없다.
■ USC는 나머지 두 모델 모두에서 가장 높은 truthfulness를 보여준다. informativeness의 경우 USC는 PaLM 2-L에서 가장 높은 점수를 gpt-3.5-turbo에서는 두 번째로 높은 점수를 기록했다.
■ 첫 번째로 높은 점수와 0.1 차이인데, GPT-judge 및 GPT-info 모델이 등급 예측에서 일반적으로 90-95%의 validation accuracy를 가진다는 점을 고려할 때, 0.1의 차이는 유의미한 것으로 간주되지 않는다.
4.3 ABLATIONS
Effect of response ordering

■ 이전 연구들은 LLM이 response quality 평가에 사용될 때, candidate responses의 순서에 영향을 받을 수 있음을 보여주었다. (position bias)
■ 이에 저자들은 모든 responses을 연결할 때 5가지 다른 무작위 순서로 USC를 수행하여 response 순서의 효과를 확인하고자 결과의 평균과 표준편차를 계산했다.
■ Table 5에서 볼 수 있듯이, 전체적인 모델 성능은 다른 response orders에서도 비슷하게 유지되며, 이는 response order의 영향이 미미함을 의미한다.
Different number of responses

■ Fig 3은 USC에서 서로 다른 수의 responses을 사용했을 때 그 효과를 나타낸 것이다.
■ USC는 TruthfulQA와 BIRD-SQL에서 더 많은 샘플로부터 성능 향상을 얻지만, SummScreen에서는 5개 샘플 이후에 성능을 더 이상 향상시키지 못하며, GSM8K의 정확도는 16개 샘플에서 감소하는 것을 볼 수 있다.
■ 이러한 결과에 대해 저자들은, 프롬프트에 많은 candidate responses이 포함될 경우 이러한 long context에 대한 LLM의 이해의 한계와 불완전한 셈 능력 때문일 수 있다고 설명한다.
■ 그리고 소수의 샘플(예: 8개)을 사용하는 것이 task accuracy와 compute cost 사이의 균형을 맞추는 sweet spot이라고 주장하며, 이 설정에서 USC가 전반적으로 성능을 안정적으로 향상시켰다고 한다.
Criteria for response selection

■ USC의 한 가지 장점은 일반성이다. 즉, 어떠한 task-specific knowledge 없이도 동일한 기준을 다양한 tasks에 적용할 수 있다.
■ 그리고 response selection에 대한 instruction을 task에 맞게 약간 조정하면 일반적인 프롬프트보다 USC 성능을 더욱 높일 수 있다.
■ Table 6은 long-context summarization에서 LLM에게 (가장 consistent한 response이 아닌) 가장 디테일한 response를 선택하도록 요청한 결과이다. ROUGE-1 및 ROUGE-Lsum에서 약 2점의 점수 향상을 볼 수 있다.
4.4 DISCUSSION: HOW WELL DOES USC MATCH SC SELECTION?


■ standard self-consistency를 사용할 수 있는 tasks에서 8개의 샘플을 사용할 때 USC와 SC가 비슷한 성능을 달성했지만, USC는 GSM8K에서 16개의 샘플을 사용했을 때 오히려 성능이 떨어졌었다.
■ Fig 4는 8개 및 16개의 candidate responses이 있는 mathematical reasoning benchmarks에서의 분석이며, Fig 5는 USC와 SC가 서로 다른 responses을 선택했 때의 성능을 나타낸 것이다.
■ voting 결과가 동점(tied votes)인 경우, 특히 8개의 candidate responses을 사용할 때 USC와 SC 간의 선택 결과가 꽤 불일치 한다.
■ 구체적으로 선택 불일치의 주요 원인은, 최대 득표를 한 모든 responses 중에서 SC는 항상 가장 작은 인덱스의 response 를 선택(즉, 가장 앞에 위치한 response, 예를 들어 response 0부터 n까지 있을 때 첫 번째 response 0을 선택)하는 반면, USC는 response와 format을 고려하여 더 나은 답을 선택할 수 있다.
■ USC와 SC가 같은 답을 고르는 비율은 일관되게 task accuracy보다 높게 나타났다. 이는 LLM이 correctness보다 consistency를 파악하는 것이 더 쉽다는 가설을 뒷받침하는 결과이다.
■ 샘플 수가 8개에서 16개로 늘어나면 USC와 SC의 일치율이 감소하는데, 이는 USC가 SC의 불완전한 근사로 행동함을 시사한다. 그러나 response selection의 차이가 항상 성능 저하로 이어지는 것은 아니다. 때로는 SC가 실패할 때 USC가 정답을 선택하기도 하기 때문이다.
- USC는 SC의 원리를 LLM을 통해 구현한 것이다. 즉, USC는 SC의 빈도수 계산(즉, 다수결 원칙)을 따르려고 하지만, LLM은 단순 빈도수 외에 문맥이나 format 등 다른 요소를 고려하기 때문에 오차가 존재하기 때문에 SC와 100% 똑같은 결과를 내지 않는다.
5. RELATED WORK
Response reranking and selection for language models
■ re-ranking은 여러 개의 outputs을 샘플링하고 사후 기준을 적용하여 순위를 매김으로써 언어 모델의 generation quality를 향상시키는 방법인데, 이를 위해 별도의 ranker model을 학습시키거나 human labeled data가 필요하다.
■ 이전 연구들에서는 human labels을 사용하여 생성된 각 response가 올바른지 여부를 검증하는 순위 지정 모델을 학습시키거나, math tasks에서의 성능 향상을 위해 generator와 ranker model을 jointly training하였다.
■ response generator와 ranker를 별도의 모델로 학습시키는 대신, dialog model이 human-annotated judgements을 통해 candidate responses의 등급을 예측하도록 파인튜닝시키는 연구도 있었다.
■ code generation의 경우 다양한 reranker models이 설계되었는데, 이들은 일반적으로 코드 실행 결과와 언어별 구문 특징을 활용하여 순위 지정 성능을 향상시켰다.
■ 이러한 연구들과 대조적으로, USC는 LLM 자체를 활용하기 때문에 추가적인 training data나 별도의 모델(reranking model)을 필요로 하지 않는다.
■ self-consistency는 동일한 task에 대해 생성된 여러 responses 중에서 가장 일반적인 answer로 이어지는 reasoning path를 선택하는 것이 chain-of-thought reasoning performance를 향상시킨다는 것을 보여주었다.
■ 단, 가장 일반적인 답변을 찾기 위해선 명시적인 기준이 필요했으며 math는 exact match, open-ended generation tasks에서는 n-gram 점수 계산, code에서는 코드 실행 결과와 일치 여부와 같은 기준을 사용해 final answer를 판단했다.
■ 반면, USC는 LLM에게 단지 consistency에 기반한 선택을 수행하도록 지시함으로써 다양한 tasks에 사용할 수 있다.
Response improvement with multiple candidates
■ 몇몇 연구들은 LLM이 candidate responses을 활용하여 더 개선된 output을 생성할 수 있음을 보여주었다.
■ 이전에 생성된 솔루션들의 경로가 주어졌을 때, LLM이 이 것들을 활용하여 점진적으로 더 나은 솔루션을 반복적으로 생성할 수 있음을 보여준 연구와 여러 개의 reasoning chains과 prompts을 종합해서 LLM이 최종적으로 더 개선된 답변을 작성하도록 하여 multi-hop question answering 및 medical question answering에서 성능 향상을 보여준 연구들이 있다.
■ USC는 LLM에게 더 나은 response를 생성하도록 요청하는 대신, 생성된 candidate responses에서 최적의 답을 선택하는 데 중점을 둔다. 생성된 여러 개의 candidate responses 안에 이미 고품질의 정답이 포함되어 있을 확률이 높고, consistency을 판단하여 선택하는 것이 정답의 correctness을 개선하는 것보다 훨씬 쉬운 작업이기 때문이다.
Large language models for response evaluation
■ USC의 기저에 깔린 가정은, LLM이 여러 개의 자체 생성된 output들 간의 consistency를 충분히 평가할 수 있다는 것이다.
■ 최근 연구들은 LLM이 model-generated texts를 평가하는 데에도 사용될 수 있음을 보여주었다. (LLm as a judgement)
■ 이런 연구들은 LLM 기반 평가가 human references 없이 natural language generations을 평가하는 데 사용될 수 있는 등 유망한 결과를 보여주었지만, 일부 연구는 LLM이 사람의 judgements와 잘 일치하지 않을 수 있으며, 때로는 model-generated texts에 대해 편향을 보일 수 있음을 보여주었다.
■ 또 다른 연구 흐름은 multiple choices의 quality를 측정하기 위해 LLM의 prediction probability를 활용하거나, LLM이 자신의 response에 대한 신뢰도 수준을 직접 출력하도록 프롬프트하여 arithmetic tasks에서 유망한 결과를 보여준 연구들이 있다.
■ USC에서는 LLM이 평가자로서의 역할을 할 수 있을 뿐만 아니라, 여러 개의 responses을 샘플링한 다음 consistency를 평가함으로써 자신의 output을 개선할 수 있음을 보여주었다.
6. LIMITATIONS AND FUTURE WORK
■ USC가 standard self-consistency를 사용할 수 있는 도메인뿐만 아니라, open-ended generation tasks에서도 사용할 수 있으며, 일반적으로 self-consistency와 대등한 성능을 달성함에도 불구하고, 논문의 USC는 extraction-based self-consistency와 비교하여 다음과 같은 본질적인 한계들을 가지고 있다.
■ 첫 번째 한계점은 context length에 따른 샘플 수 제한이다.
■ standard SC는 final answer만 추출할 수 있다면 샘플 수와 무관하게 적용 가능하다. SC의 핵심은 majority voting이기 때문에, answer만 추출할 수 있다면 샘플 수가 많거나 적은지는 제약이 되지 않기 때문이다.
■ 그러나 USC는 모든 responses을 연결하여 프롬프트에 입력해야 하므로, LLM의 context length(LLM이 처리할 수 있는 입력 길이)에 의해 샘플 수가 제한된다.
■ 다만, task에 대한 성능과 샘플링 비용 사이의 균형을 찾기 위해 실제로는 엄청나게 많은 샘플이 필요하지 않으므로, 충분히 사용할 수 있다.
■ 두 번째는 신뢰도(confidence)이다.
■ SC는 투표 메커니즘이기 때문에, 자연스럽게 각 response에 대한 confidence 또는 uncertainty에 대한 정보를 투표 비율이라는 수치로 제공한다.
■ 그러나 논문의 USC는 단순히 선택하는 방식이므로 confidence나 uncertainty를 수치화하기 어렵다.
■ 세 번째는 추론 비용이다.
■ USC는 설계상 선택 과정을 거쳐야 하므로 추가적인 LLM 쿼리 비용이 발생한다. 단, USC의 출력은 Fig 2에서 보았듯이 매우 짧은 인덱스 형태이므로 비용이 크지 않다.
■ 추론 비용을 더 줄이기 위한 한 가지 방법으로는 light-weight model을 사용하여 USC를 수행하고, long context encoding에 대한 효율성을 최적화(예: FlashAttention이나 long-context를 읽는데 특화된 small model을 사용)하는 것이다.
■ 마지막으로, SC와 USC 모두의 공통적인 한계는 consistency-based selection의 기준이다.
■ consistency가 효과적인 기준이지만, 가장 일관성 있는 답변이 반드시 최상의 답변인 것은 아니기 때문이다.
■ 저자들은 항상 최상의 response를 선택하도록 oracle reranker를 사용했을 때, 모든 tasks에서 oracle scores와 상당한 격차가 있음을 관찰하였다. (Appendix A)



'자연어처리 > Reasoning' 카테고리의 다른 글
| Let's Verify Step by Step (1) | 2026.01.10 |
|---|---|
| LEMA: Learning From Mistakes Makes LLM Better Reasoner (0) | 2026.01.02 |
| Large Language Models Cannot Self-Correct Reasoning Yet (0) | 2025.12.18 |
| Self-Refine: Iterative Refinement with Self-Feedback (0) | 2025.12.11 |
| AutoCoT: Automatic Chain of Thought Prompting in Large Language Models (0) | 2025.12.10 |
