■ 이 논문의 요지는 현재의 LLM이 외부의 도움 없이 스스로 자신의 오류를 교정하는 능력에는 분명한 한계가 있다는 것이다.
■ LLM은 전례 없는 text generation capabilities을 보여주지만, 생성된 content의 정확성과 적절성에 대한 우려는 여전히 존재한다.
■ 이러한 문제에 대한 해결책으로 LLM이 혼자서 스스로 오류를 고치는, "self-correction"이라는 방법론이 등장했다.
■ 그러나 논문에서는 LLM이 외부 피드백의 도움 없이 오직 자신의 파라미터(즉, inherent capability)에만 의존하여 초기 responses을 수정하는 "intrinsic self-correction"은 self-correction 후 오히려 성능이 저하되기도 함을 보여준다.
[2310.01798] Large Language Models Cannot Self-Correct Reasoning Yet
Large Language Models Cannot Self-Correct Reasoning Yet
Large Language Models (LLMs) have emerged as a groundbreaking technology with their unparalleled text generation capabilities across various applications. Nevertheless, concerns persist regarding the accuracy and appropriateness of their generated content.
arxiv.org
1. INTRODUCTION
■ LLM의 오류를 줄이기 위해, LLM이 previous outputs에 대한 feedback을 기반으로 자신의 responses을 refine하는 "self-correction" 개념이 등장했지만, LLM에서 self-correction의 근본적인 메커니즘과 효능은 아직 충분히 탐구되지 않았다.
■ 저자들은 이러한 "self-correction"에 의문을 가진다: 만약 LLM이 self-correction 능력을 갖추고 있다면, 왜 애초에 첫 번째 시도에서 정답을 내놓지 못하는 걸까?
■ 고칠 수 있는데 틀렸다는 것은 모델 내부의 지식이나 과정에 모순이 있다는 것이다. 이러한 역설을 파고들어, reasoning 능력에 중점을 두고 LLM의 intrinsic self-correction에 대한 한계를 검토한다.
■ intrinsic self-correction은 모델이 외부의 feedback 없이 오직 자신의 내재적 능력에만 의존하여 초기 response를 수정하는 것을 말한다. 실제 많은 응용 분야에서 고품질의 외부 feedback을 구하는 것은 어렵기 때문에, 이러한 설정은 매우 중요하다.
■ 논문에서는 self-correction에 대한 이전 연구들의 낙관과는 달리, LLM이 이러한 설정에서 추론을 self-correction하는 데 어려움을 겪으며, 대부분의 경우 self-correction 후 성능이 오히려 저하된다는 결과를 보여준다.
■ 그리고 이전 연구들에서 self-correction이 성능 향상을 이끌어낸 이유는, self-correction 과정을 가이드하기 위해 oracle labels(정답지)을 사용했기 때문이라고 결론 짓는다. 이는 oracle labels이 없을 때는 성능 향상이 사라진다는 관찰에 근거한다.
■ oracle labels에 대한 의존성 외에도, self-correction으로 달성된 개선을 측정하는 것과 관련하여 이전 연구들의 다른 문제들도 검토한다.
■ 첫 번째는 추론 비용이다. self-correction이 설계상 여러 번의 LLM responses을 사용한다는 점에 주목하여, 동등한 추론 비용을 가진 베이스라인과 비교하는 것이 중요하다고 본다.
- self-correction은 필연적으로 모델을 여러 번 호출(생성, 검토, 수정)한다. 그렇다면 동등한 추론 비용이 발생하는 방식과 비교해야 공정하다는 것이다.
■ 이러한 관점에서 추론을 개선하기 위한 수단으로 다중 에이전트 토론(multi-agent debate)를 조사한다. 이는 여러 LLM 인스턴스(동일한 LLM의 여러 카피본일 수 있음)가 서로의 responses을 비평하는 방식(예: voting)이다.
■ 실험을 통해 동등한 수의 responses을 고려할 때, 그 효능이 self-consistency보다 나을 것이 없다는 것을 보여준다.
- 비용 대비 효과 면에서 나을 게 없다면 좋은 방식이 아니라고 본 것이다.
■ self-correction에 대한 또 다른 중요한 고려 사항은 프롬프트 설계이다. self-correction의 process는 초기 response generation과 self-correction 단계 모두를 위해 프롬프트를 사용하기 때문이다.
■ 이에 대해, 일부 기존 연구에서 주장하는 self-correction의 성능 향상 효과는 최적화되지 않은 초기 프롬프트에서 기인했다는 것을 보여준다.
■ 즉, 해당 연구들에서는 초기 질문을 모호하게(나쁜 프롬프트) 던져놓고, self-correction 단계에서야 비로소 자세하고 유익한 instructions를 제공하여 성능을 높였다는 것이다.
■ 저자들의 실험에서는, 오히려 처음부터 구체적인 instructions을 초기 프롬프트에 통합하여 제공했을 때, 더 나은 결과를 얻을 수 있으며, 이렇게 최적화된 프롬프트를 먼저 제공한 다음 self-correction을 적용하면 오히려 성능이 하락하는 것을 보여준다.
2. BACKGROUND AND RELATED WORK
■ self-correction에 대한 연구들은 LLM이 자신의 생성한 outputs의 정확성을 인식하고 refined answers을 제공할 수 있는지에 초점을 맞췄다.
■ 예를 들어, mathematical reasoning에서 LLM은 복잡한 문제를 처음 풀 때, 계산 단계 중 하나에서 실수를 할 수 있다. 이상적인 self-correction 시나리오에선 모델이 실수를 인식한 다음, 문제를 다시 검토하여 오류를 수정하고 결과적으로 더 정확한 솔루션을 도출할 것을 기대된다.
■ 그러나 self-correction의 정의는 문헌마다 다양하여 모호하다. 논문에서는 self-correction의 차이를 feedback의 출처에 둔다. feedback은 순수하게 LLM 자체에서 나올 수도 있고, 외부 입력에서 도출될 수도 있다.
■ 이때 LLM 자체에서 나온 내부 feedback은 output을 재평가하기 위해 결국 모델의 knowledge와 파라미터에 의존한다.
■ 대조적으로 외부 feedback은 사람이나 다른 모델, 혹은 외부의 tools이나 외부의 knowledge sources로부터의 입력들을 사용한다.
■ reasoning은 인간 인지의 근본적인 측면으로, 사람이 세상을 이해하고, reasoning을 도출하고, 결정을 내리고, 문제를 해결할 수 있게 한다.
■ 논문에서는, LLM으로 이러한 reasoning 성능을 향상시키기 위해 제안된 다양한 intrinsic self-correction techniques을 평가함으로써, LLM이 외부 feedback 없이 스스로 오류를 수정할 수 있는 intrinsic self-correction 능력을 얼마나 갖추고 있는지 확인한다.
3. LLMs CANNOT SELF-CORRECT REASONING INTRINSICALLY
■ 이 섹션에서는 기존의 self-correction 방법들을 평가하고, answer의 정확성에 대한 oracle labels의 유무에 따른 성능을 비교한다.
3.1 EXPERIMENTAL SETUP
Benchmarks
■ oracle labels을 사용한 기존의 self-correction 방법들이 상당한 성능 향상을 입증했던 데이터셋들(GSM8K, CommonSenseQA, HotpotQA)을 사용한다.
■ GSM8K는 사람이 작성했으며, 언어적으로 다양한 1,319개의 초등 수학 단어 문제 test set으로 구성되어 있다. 이전 연구에서는 self-correction 후 약 7%의 향상이 있었다.
■ CommonSenseQA는 commonsense reasoning을 테스트하는 multi-choice questions로 구성되어 있다. 이전 연구에서는 self-correction을 통해 약 15%의 인상적인 성능 향상을 보여주었다.
■ CommonSenseQA에서의 평가를 위해 이전 연구들을 따라 1,221개의 questions을 포함하는 dev set을 사용한다.
■ HotpotQA는 open-domain에 대한 multi-hop question-answering dataset이다.
■ HotpotQA에서는 모델의 성능을 closed-book 설정에서 테스트하고, 이전 연구와 동일한 set을 사용하여 평가한다. 평가에 사용되는 set은 100개의 questions을 포함하고 있다. 평가 지표로는 exact match를 사용한다.
Test Models and Setup
■ 먼저 이전 연구들을 따라 GPT-3.5-Turbo와 GPT-4를 사용하여 oracle labels이 있는 self-correction을 평가한다.
■ intrinsic self-correction의 경우, 더 철저한 분석을 위해 GPT-4-Turbo와 Llama-2도 사용한다.
■ GPT-3.5-Turbo의 경우 full evaluation set을 사용하며, 다른 모델들의 경우 비용 절감을 위해 각 데이터셋에서 200개의 questions을 무작위로 샘플링하여 테스트한다(HotpotQA는 100개).
■ 모델이 최대 2라운드의 self-correction을 거치도록 프롬프트한다.
■ 그리고 다양한 디코딩 알고리즘에 대한 평가를 위해, 모델별로 다른 temperature를 사용한다: GPT-3.5-Turbo와 GPT-4에는 temperature 1을, GPT-4-Turbo와 Llama-2에는 temperature 0을 사용한다.
Prompts
■ 마찬가지로 이전 연구들을 따라 self-correction을 위한 3단계 프롬프팅 전략을 적용한다.
- (1) 모델에게 초기 생성을 수행하도록 프롬프트한다.
- (2) 모델에게 이전 생성을 검토하고 feedback을 생성하도록 프롬프트한다.
- (3) 모델에게 feedback과 함께 원래 질문에 다시 답하도록 프롬프트한다.
■ 실험을 위해 주로 원본 논문의 프롬프트를 따른다. (detailed prompts Appendix A)
■ GSM8K와 CommonSenseQA의 경우, 더 정밀한 자동 평가를 위해, 이전 연구의 프롬프트에 출력 형식을 통일하는 instruction을 추가한다. HotpotQA의 경우 이전 연구와 동일한 프롬프트를 사용한다.
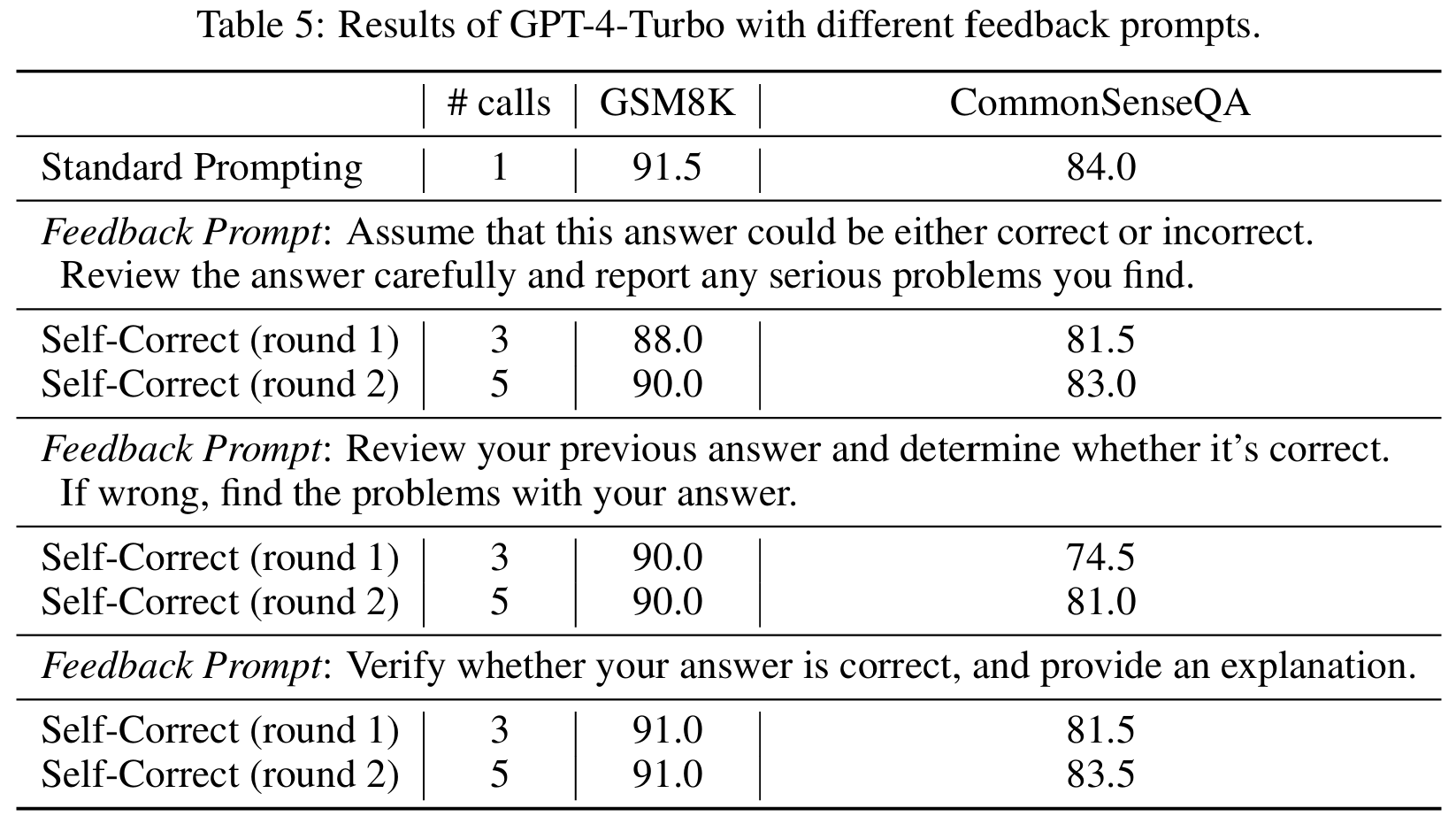
■ 또한, intrinsic self-correction을 위한 다양한 self-correction 프롬프트들의 성능도 평가한다. 예를 들어, "이 답이 맞을 수도 있고 틀릴 수도 있다고 가정하고 답을 주의 깊게 검토하고 발견한 문제를 보고해줘"라는 문구를 GPT-4-Turbo와 Llama-2 평가를 위한 기본 피드백 프롬프트로 사용한다.
3.2 RESULTS
Self-Correction with Oracle Labels
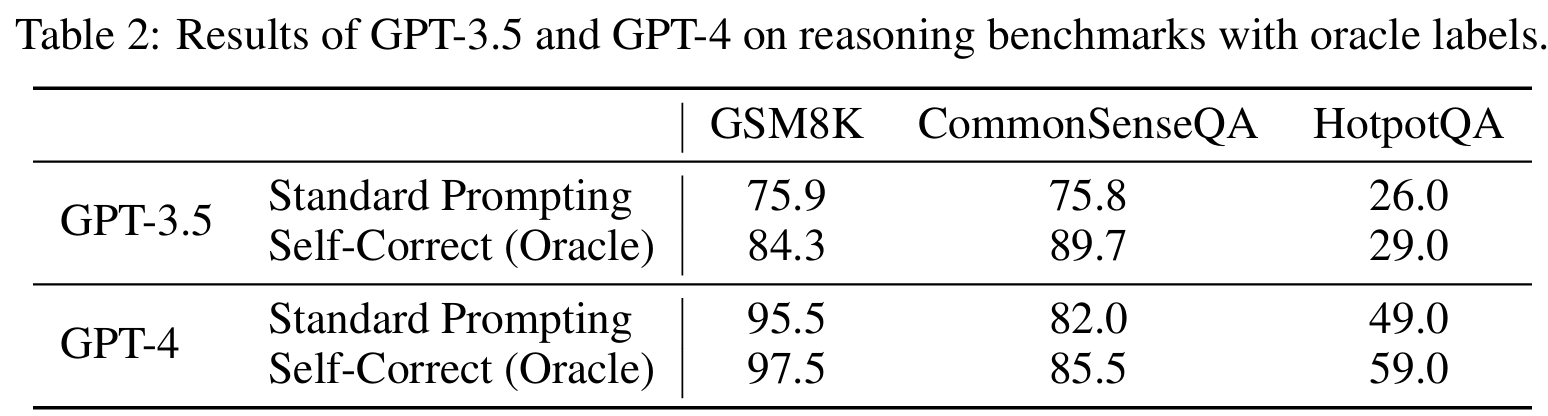
■ 이전 연구들을 따라, self-correction loop를 언제 중단할지 결정하기 위해 정답 라벨을 사용한다. 이는 각 단계에서 생성된 답이 올바른지 확인하기 위해 실제 정답(ground-truth label) 활용하는 것이다.
■ 만약, 답이 이미 맞다면 (추가적인) self-correction은 수행되지 않는다.
■ Table 2는 이 설정 하에서의 self-correction 결과를 나타낸 것으로, 이전 연구들에서 제시한 것과 같이 상당한 성능 향상을 볼 수 있다.
■ 그러나 Table 2의 결과는 정답지, 즉 oracle labels을 사용한 결과이다.
■ 수학 문제 해결과 같은 reasoning tasks에서 oracle labels을 사용할 수 있다는 것은 올바르지 않은 설정이다. real world에서는 이러한 정답을 사용하지 못하는 경우가 많으며, 이렇게 이미 정답을 알고 있는 상황에서는 문제 해결을 위해 LLM을 사용할 이유가 거의 없기 때문이다.
■ 따라서, Table 2의 결과들은 단지 oracle의 성능을 나타내는 지표로 볼 수 있다.
Intrinsic Self-Correction
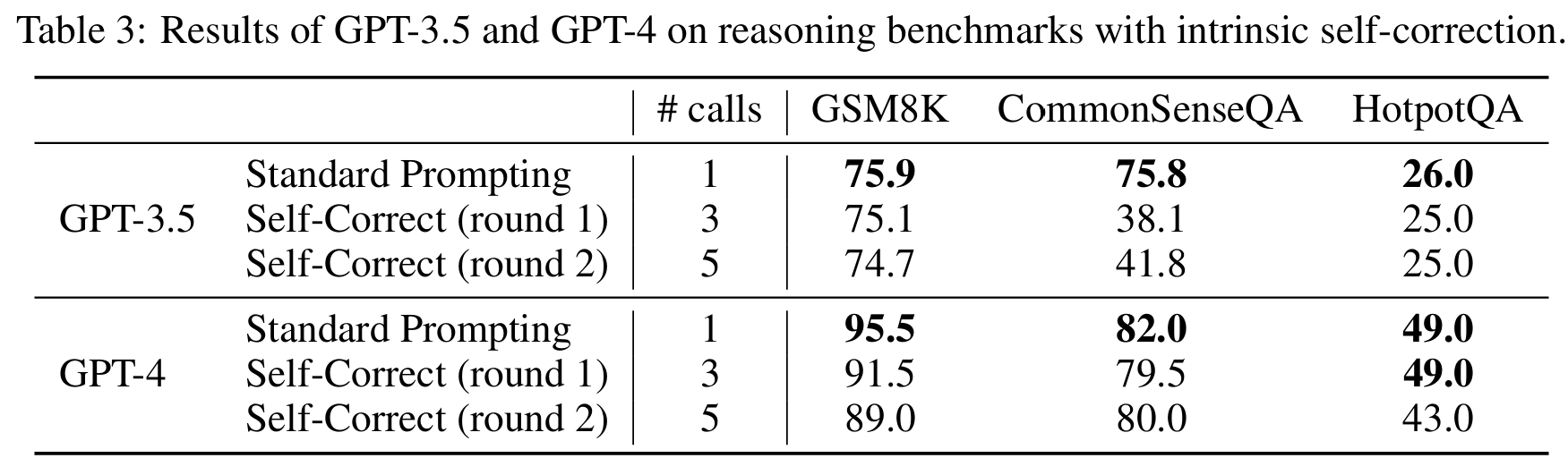

■ oracle labels을 사용하여 달성한 성능 향상은 진정한 self-correction이라고 할 수 없다.
■ 이런 관점에 oracle labels을 사용하지 않고, 모델 스스로 답이 맞았는지 틀렸는지 판단하는 intrinsic self-correction을 평가한다.
■ 이 실험을 위해 labels을 사용하지 않고, LLM이 독립적으로 self-correction 과정을 언제 멈출지, 즉 이전 답을 유지할지 여부를 결정하도록 설정하였다.
■ Table 3과 4는 정확도와 모델 호출 횟수를 나타낸 것으로, self-correction 후 모든 벤치마크에 걸쳐 모든 모델의 성능이 하락한 것을 볼 수 있다.
■ 혹시나 reasoning performance를 향상시킬 수 있는 더 나은 프롬프트가 있는지 확인하고자 여러 다른 self-correction 프롬프트들도 설계하여 사용했지만, Table 5와 6에서 볼 수 있듯이, oracle labels을 사용하지 않으면 self-correction은 일관되게 성능 감소를 초래한다.

3.3 WHY DOES THE PERFORMANCE NOT INCREASE, BUT INSTEAD DECREASE?
Empirical Analysis
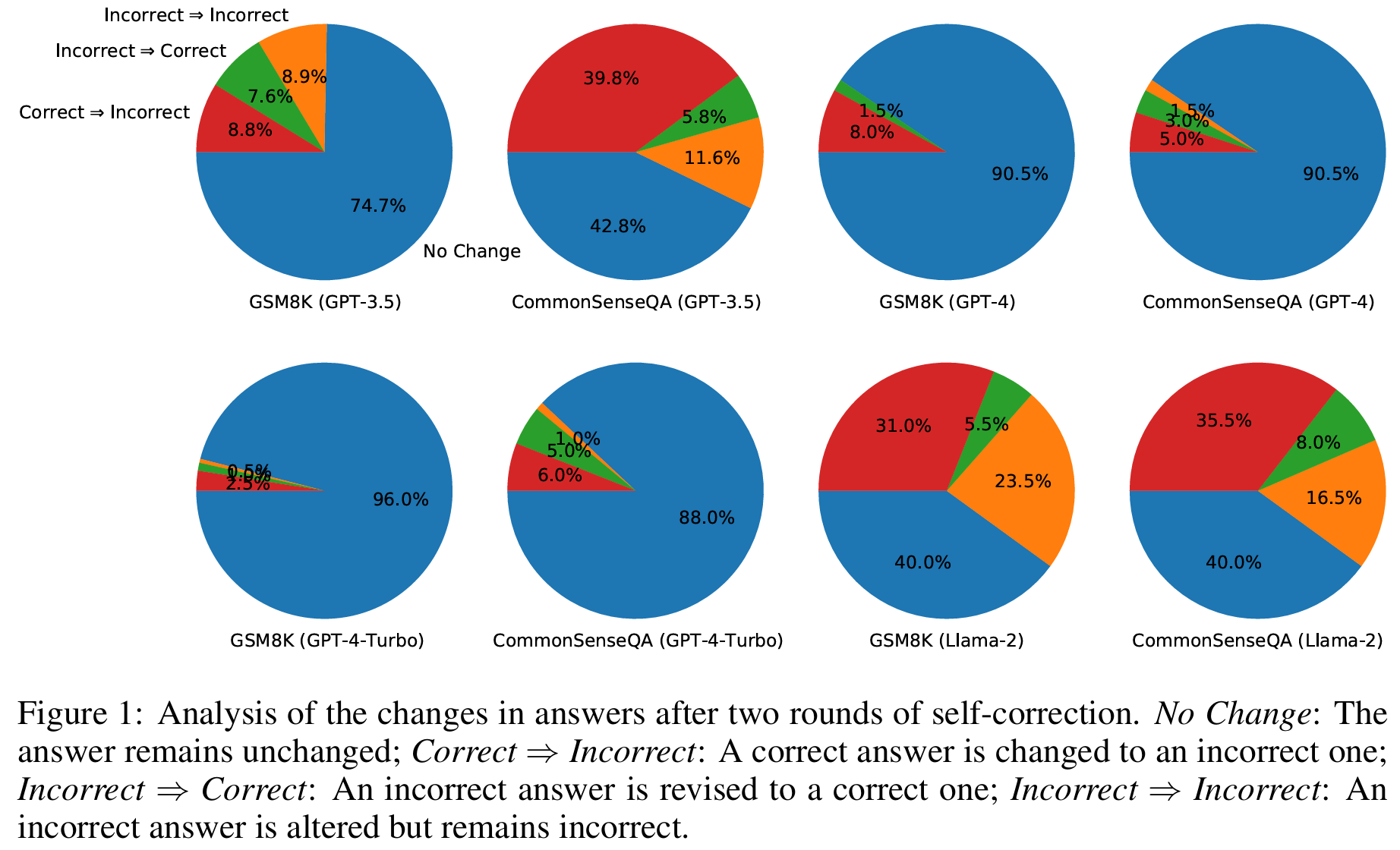
■ Fig 1은 두 번의 self-correction 후 answers의 변화 결과를 나타낸 것이며, Fig 2에서 예시를 볼 수 있다.
■ GSM8K의 경우, 74.7%의 확률로 GPT-3.5는 초기 답변을 유지하지만, 나머지 사례들(Incorrect -> Incorrect, Incorrect -> Correct, Correct -> Incorrect) 중에서, 모델이 틀린 답을 맞는 답으로 수정하기보다는 맞는 답을 틀린 답으로 수정할 가능성이 더 높은 것을 볼 수 있다.
■ 이는 LLM이 자신이 한 reasoning의 정확성을 제대로 판단할 수 없음을 시사한다.
■ CommonSenseQA의 경우, GPT-3.5가 답변을 변경한 확률이 더 높은 것을 볼 수 있다. 이에 대한 주된 이유는 CommonSenseQA의 오답 선택지들이 종종 질문과 어느 정도 관련 있어 보이는 매력적인 오답인 경우가 있기 때문이다.
■ 그러므로 CommonSenseQA에서 self-correction을 사용하는 것이 모델로 하여금 다른 선택지를 고르도록 유도하여 높은 "correct => incorrect" 비율로 이어질 수 있다.
■ 마찬가지로 Llama-2 또한 빈번하게 정답을 오답으로 바꾸는 것을 볼 수 있다.
■ GPT-3.5 및 Llama-2와 비교했을 때, GPT-4와 GPT-4-Turbo는 초기 답변을 유지하는 경우가 더 많은 것을 볼 수 있다
■ 이는 GPT-4와 GPT-4-Turbo가 자신의 초기 답변에 대해 더 높은 확신을 가지고 있거나, 혹은 더 robust하여 self-correction 프롬프트에 의해 편향될 가능성이 적기 때문일 수 있다.
■ Table 2에 제시된 결과들은 모델이 정답을 오답으로 바꾸는 것을 방지하기 위해 ground-truth labels을 사용한 결과이며, 저자들은 이렇게 잘못된 변경을 방지하는 방법이 self-correction의 성공을 보장하는 key였다고 지적한다.

Intuitive Explanation
■ 직관적으로, 신중하게 설계된 초기 프롬프트와 잘 aligned된 모델이 결합된다면, 초기 응답은 해당 프롬프트에 대해 최적의 답변일 가능성이 높다.
■ 여기에 feedback을 도입하는 것은 추가적인 프롬프트를 더하는 것으로 볼 수 있으며, 오히려 feedback을 추가하는 것 때문에 잠재적으로 모델이 이미 생성한 최적의 답변이 왜곡될 수 있다.
■ 모델이 원래의 질문에 집중하기보다, 기존 답변과 "다시 생각하라"는 형태의 feedback 자체에 초점을 두고 새로운 응답을 생성할 가능성이 있기 때문이다.
- 만약, feedback이 "계산 실수가 있다"처럼 구체적이고 유용한 정보라면 도움이 될 수 있다.
- 그러나 이미 정답이 맞은 상황에서 "틀렸을 수도 있어"와 같은 피드백은 결국 노이즈에 불과하다.
■ 이 과정에서 초기 프롬프트에 대한 최적의 응답을 생성하지 못하도록 편향시켜 성능 저하를 초래할 수도 있다.
■ 그러므로 intrinsic self-correction에서 feedback 프롬프트는 질문을 답하는 데 어떠한 추가적인 이점도 제공하지 못할 가능성이 있다.
4. MULTI-AGENT DEBATE DOES NOT OUTPERFORM SELF-CONSISTENCY
■ LLM이 reasoning을 self-correct하는 또 다른 접근 방식은 multi-agent debate처럼 여러 개의 모델을 호출해 모델들이 서로 비평하고 토론하게 하는 것이다.
■ multi-agent debate 논문에서는 하나의 ChatGPT 모델의 여러 인스턴스를 활용하여 multi-agent debate 방법을 구현하고 reasoning tasks에서 상당한 개선을 보여주었다.
■ 저자들은 해당 논문의 방법을 재현하여 GSM8K에서 성능을 테스트하기 위해, 정확히 동일한 프롬프트를 사용하고 gpt-3.5-turbo-0301 모델을 사용하여 3개의 agent를 구성하고, 두 번의 토론 라운드를 진행하였다.
■ 차이점은 결과의 분산을 줄이기 위해 GSM8K의 전체 test set에서 테스트를 수행한다. (해당 논문에서는 100개의 examples에 대해서만 테스트)
■ 참고로, 모델이 여러 응답을 생성하고 majority voting을 수행하여 최종 답을 선택하는 self-consistency의 결과도 reporting한다.

■ Table 7을 보면, multi-agent debate와 self-consistency 모두 standard prompting에 비해 상당한 성능 개선을 달성했다.
■ 그러나 multi-agent debate와 self-consistency를 동일한 응답 수를 기준으로 비교했을 때, multi-agent debate는 단순히 majority voting을 사용하는 self-consistency보다 성능이 더 낮다.
■ 이러한 결과에 대해 저자들은 multi-agent debate를 "debate(토론)"이나 "critique(비평)"으로 명명하는 것은 부적절하며, 생성된 여러 결과물들 간의 일관성(consistency)을 확보하는 수단으로 보는 것이 타당하다고 주장한다.
■ multi-agent debate의 본질적인 개념은 self-consistency와 동일하기 때문이다. 어떤 안건을 토론하여 합의하는 과정은 결국 일종의 투표 과정으로 볼 수 있다.
■ 두 방법의 차이점은 최종 답안을 결정하는 투표 메커니즘에 있는데, 투표가 모델 주도적인지 아니면 순전히 개수에 기반하는지 여부이다.
■ 이 실험에서 관찰된 성능 개선은 명백히 "self-correction"에 기인한 것이 아니라, 여러 생성물 중 일관된 답을 선택하는 "self-consistency"에서 기인한 것이며, LLM이 multi-agent debate를 통해 reasoning을 self-correct할 수 있다고 주장하고 싶다면, 여러 생성물 중에서 정답을 골라내는 '선택'의 효과를 배제하고도 성능이 오르는지 증명하는 것이 바람직하다고 지적한다.
5. PROMPT DESIGN ISSUES IN SELF-CORRECTION EVALUATION
■ 저자들이 평가한 모든 유형의 feedback 프롬프트에서, self-correction이 reasoning 성능을 감소시키기는 하지만, feedback 프롬프트에 따라 성능이 달라진다는 것을 확인할 수 있다. (섹션 3의 Table 5, 6)
■ 이 섹션에서는 초기 LLM 응답을 생성할 때 적절한 프롬프트 설계의 중요성을 다룬다.
■ 이전 연구들은 대부분 초기 instruction에 구체적인 요구사항(예: output에 특정 단어가 포함되어야 함, 생성된 코드가 효율적이어 햠, 감정이 긍정적이어야 함 등)을 누락하고, feedback 단계에서 feedback 프롬프트에 포함시킨다.
■ 이렇게 초기 생성을 위한 instruction이 충분히 유익하지 않을 경우 성능이 향상되더라도, 그것이 self-correction 자체에서 온 것인지, 아니면 단순히 feedback 프롬프트에서 더 상세한 instruction을 받았기 때문인지 불분명해진다.
■ 그러므로 self-correction의 성능을 공정하게 측정하기 위해서는, feedback 프롬프트에 포함될 구체적인 요구사항들을 초기 프롬프트에서부터 명시적으로 통합해야 한다고 주장한다. 초기 instruction에 유익한 정보가 충분히 담긴 상태에서도 self-correction이 성능을 높이는지를 검증하기 위해서이다.
■ 저자들은 프롬프트 설계의 문제를 보여주기 위해 self-refine의 사례를 예로 보여준다.
■ 해당 연구에서 20~30개의 주어진 concepts을 모두 사용하여 일관된 문장을 생성하는 task가 있는데, 아래의 초기 프롬프트(Fig 7)를 보면 "모든 개념을 포함해야 한다", 즉, "주어진 concepts을 전부 사용하라"는 요구사항이 명확하게 명시되지 않은 것을 볼 수 있다.
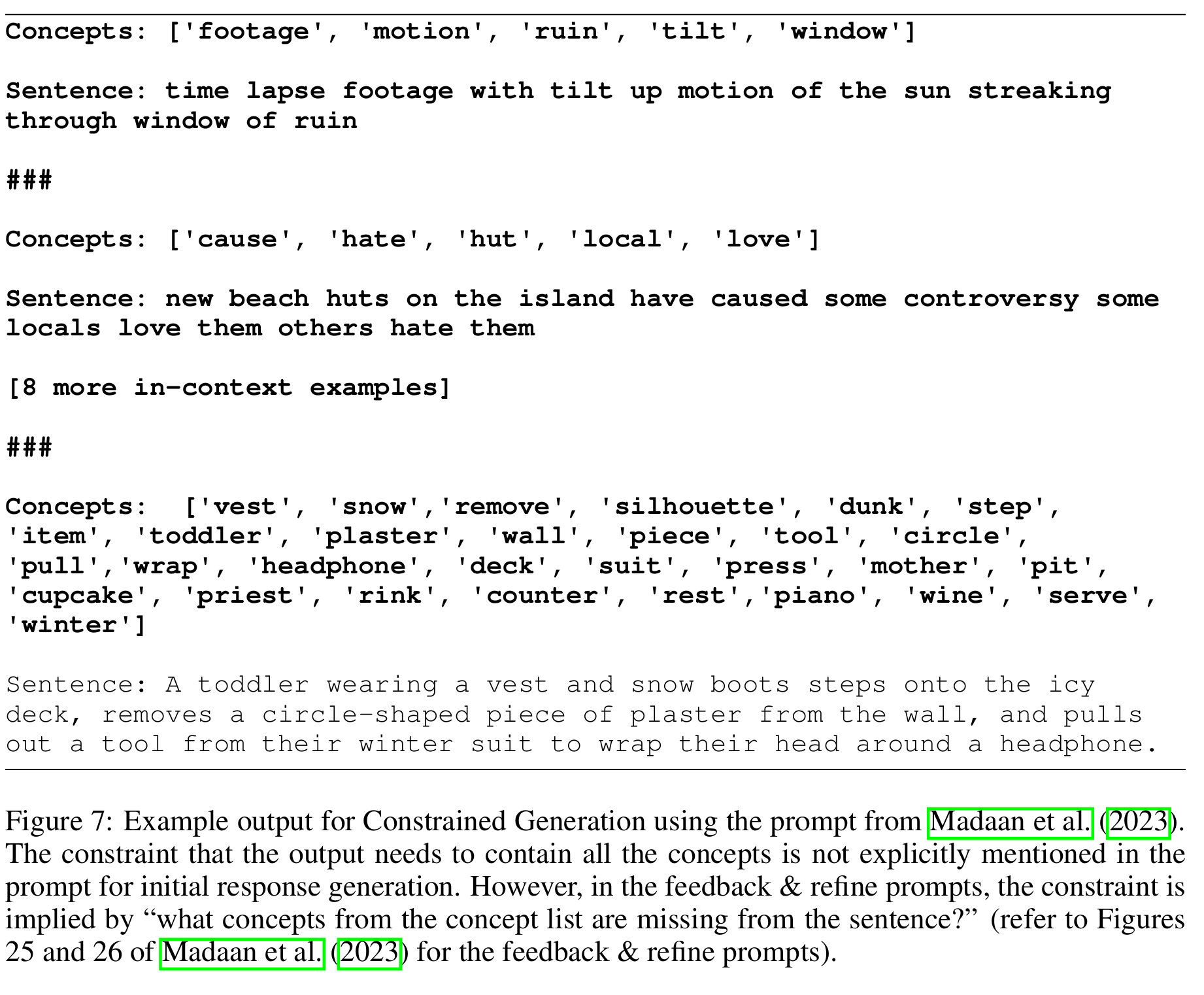
■ 이후 feedback 단계에서야 비로소 "누락된 개념을 포함하라"는 요청을 통해 성능을 향상시킨 다음, 이를 self-correction의 효과로 해석했다.
- Fig 26에서 "what concepts from the concept list are mssing from the sentence?"를 볼 수 있다.


■ 이러한 관찰을 바탕으로, 저자들은 self-refine의 실험을 그대로 따라하되, 초기 응답 생성을 위한 프롬프트에 "위의 concepts *모두*를 포함하는 합리적인 문단을 작성해라"라는 instruction을 추가하였다. (전체 프롬프트는 Fig 8)

■ Table 8을 보면, 'Standard Prompting (ours)'로 표기된 저자들의 프롬프트가 self-refine 논문에서의 self-correction 후 결과보다 훨씬 뛰어난 성능을 보인다.
- 저자들의 프롬프트는 한 번에 81.8%의 성능 달성, 그러나 self-refine은 여러 번 self-correct를 해도 이에 크게 못 미치는 성능
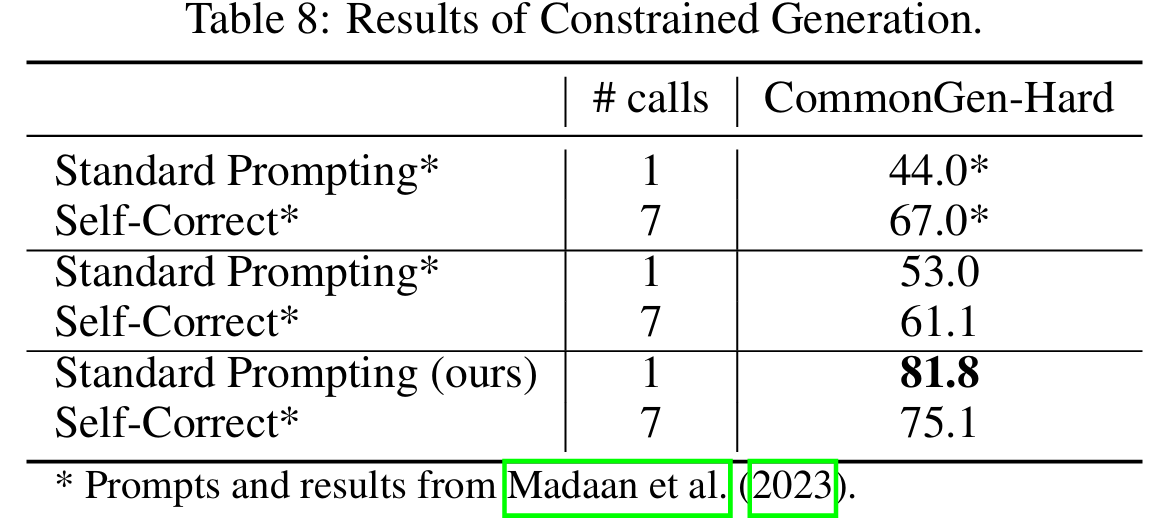
■ 그리고 저자들이 사용한 프롬프트의 결과로 얻은 모델의 응답에 self-refine 논문에서 사용한 self-correction 프롬프트를 적용하면 성능이 저하되는 것도 볼 수 있다. (81.8% \( \rightarrow \) 75.1%)
■ 이는 이미 충분히 잘 생성된 답변에 대해 self-correction을 수행할 경우, 오히려 성능이 저하될 수 있다는 저자들의 주장을 뒷받침하는 결과이다.
6. PROMPT DESIGN ISSUES IN SELF-CORRECTION EVALUATION
Leveraging external feedback for correction
■ 이 연구의 결과는 현재의 LLM이 intrinsic self-correction을 통해 reasoning 성능을 향상시키는 것은 어렵다는 것을 보여준다.
■ 이는 LLM이 자신의 reasoning mistakes을 바로잡을 수 있을 것이라 기대하는 것은 현재로서는 지나치게 낙관적임을 시사한다.
■ 그러므로, 외부의 feedback을 이용할 수 있을 때, 이를 적절히 활용하여 모델 성능을 높이는 것이 바람직하다고 본다.
■ 예를 들어, LLM이 예측한 코드의 문제를 수정하기 위해 feedback 프롬프트에 코드 실행 결과를 포함시켜 self-debugging을 통해 코드 생성 성능을 크게 향상시킬 수 있음을 보여준 연구가 있다.
■ 특히, code executor가 예측된 코드의 정확성을 판단하는 완벽한 verifier 역할을 했으며, 오류 메시지는 LLM이 응답을 개선하도록 안내하는 유익한 feedback으로 사용되었다.
■ LLM이 검색 엔진이나 계산기와 같은 외부의 다양한 tools과 상호작용할 때, 자신의 응답을 더 효과적으로 검증하고 수정할 수 있음을 보여준 연구도 있다.
■ 또는 LLM의 출력을 검증하거나 정제하기 위해, 고품질 데이터셋으로 학습된 verifier model(즉, 별도의 모델)을 사용하는 연구들도 있다. 이러한 별도의 모델은 LLM의 오류를 수정하도록 유도하는 feedback을 제공하는 데 사용될 수 있다.
■ 마지막으로 인간의 개입이 있다. LLM에 직접 사람의 피드백을 제공하여 사람의 선호도가 높은 콘텐츠를 생성하도록 모델을 유도하는 것이다.
Evaluating self-correction against baselines with comparable inference costs
■ self-correction은 여러 번의 LLM 호출을 필요로 하기 때문에, 필연적으로 인코딩 및 토큰 생성 비용을 증가시킨다.
■ 섹션 4에서는 multi-agent debate 방식과 같이 이전의 여러 응답들을 기반으로 최종 응답을 생성하도록 LLM에 요청하는 것의 성능이, 동일한 수의 응답을 가진 self-consistency보다 뒤떨어진다는 것을 보여주었다.
■ 이와 관련하여, 저자들은 새로운 self-correction 접근법을 제안할 때, 성능 향상을 입증하기 위해서는 추론 비용 분석이 포함되어야 하며, self-consistency와 같이 다수의 모델 응답을 활용하는 강력한 베이스라인이 비교를 위해 사용되어야 한다고 언급한다.
Putting equal efforts into prompt design
■ 섹션 5에서 초기 응답 생성을 위한 초기 프롬프트에 완전한 task 설명을 포함하는 것이 중요하다는 것을 확인하였다.
■ 그러므로 기존의 일부 self-correction처럼 feedback 프롬프트를 위해 task에 대한 설명을 일부 남겨두기보다는, 초기 응답 생성을 위한 프롬프트에 완전한 task 설명을 포함하는 것이 중요하다.
■ 넓게 보면, 초기 응답 생성과 self-correction을 위한 프롬프트를 설계하는 데 모두 동등한 노력을 투자해야 한다.
7. LIMITATIONS
■ 논문에서는 다양한 self-correction strategies, prompts, benchmarks에 걸쳐 포괄적인 평가를 수행했지만, 이 연구는 LLM의 reasoning 능력을 평가하는 데 초점을 두고 있다. 따라서 reasoning 이외의 다른 도메인에서는 LLM 성능을 향상시킬 수 있는 self-correction strategy가 존재할 가능성이 있다.
■ 예를 들어, 이전 연구들 중 응답의 스타일을 변경하거나 safety를 강화하는 것과 같이, 모델의 응답을 특정 선호도에 맞추는 데 있어 self-correction의 성공적인 사용 사례들이 있다.
■ 이러한 성능 차이의 근본적인 원인은 자신의 응답을 평가하는 LLM의 능력 차이에 있다.
■ LLM은 자신의 답변이 부적절한지 판단하는 평가(예: safety 평가)는 정확하게 수행할 수 있지만, 자신의 논리 전개 과정에서 발생하는 reasoning errors을 식별하는 데에는 어려움을 겪는다. 이러한 errors을 찾지 못하므로 self-correct가 어려운 것이다.
