■ 논문에서 제안하는 self-refine은 인간이 자신이 쓴 글을 더 좋은 글로 만들기 위해 다듬는 방식에서 영감을 얻은 것이다.
■ LLM도 항상 첫 번째 시도에서 best output을 생성하지는 않는다. 그러므로 LLM을 사용하여 initial output을 생성했다면, 동일한 LLM으로 initial output에 대한 "feedback"을 제공하고, 이를 사용하여 스스로 반복적으로 "refine"하자는 것이다. 이것이 self-refine의 핵심 아이디어이다.
■ 그러므로, 이러한 self-refine은 어떠한 supervised training data, additional training or reinforcement learning도 필요로 하지 않으며, 오직 하나의 LLM을 generator, refiner 그리고 feedback provider로 사용한다.
■ LLM이 첫 번째 시도에서 최적의 output을 생성하지 못하더라도, LLM이 스스로 유용한 feedback을 제공하고 그에 따라 자신의 output을 개선할 수 있음을 보여준다.
■ 즉, self-refine은 반복적인 (self-)feedback과 refinement를 통해 추가적인 training 없이도 single model로부터 더 나은 output을 이끌어낼 수 있다.

[2303.17651] Self-Refine: Iterative Refinement with Self-Feedback
Self-Refine: Iterative Refinement with Self-Feedback
Like humans, large language models (LLMs) do not always generate the best output on their first try. Motivated by how humans refine their written text, we introduce Self-Refine, an approach for improving initial outputs from LLMs through iterative feedback
arxiv.org
1. Introduction
■ LLM은 복잡한 요구사항을 해결하는 데에는 종종 한계를 드러낸다. 특히 다면적인 목표를 갖는 dialogue response generation이나, 목표 자체를 명확하게 정의하기 어려운 프로그램 가독성 향상과 같은 task에서는 이러한 한계가 두드러진다.
■ 이러한 시나리오들에서 최신 LLM은 합리적이고 이해할 수 있는 initial output을 생성할 수는 있지만, 사용자가 원하는 품질을 달성하기 위해 추가적인 반복적인(iterative) refinement을 진행할 수 있다.
■ 일반적인 iterative refinement는 domain-specific data에 의존하는 refinement model을 학습시키는 것이다.
■ external supervision이나 reward models에 의존하는 다른 접근법들은 대규모 training sets이나 비용이 많이 드는 human annotations을 필요로 한다.
■ 이때 필요한 대규모 training sets이나 human annotations은 항상 확보할 수 있는 자원이 아니다.
■ 이러한 한계점들은, 광범위한 supervision 없이도 다양한 tasks에 적용 가능하며 LLM 스스로 출력을 개선할 수 있는 효과적인 refinement approach의 필요성을 더욱 분명하게 보여준다.
■ Iterative self-refinement는 human problem-solving의 근본적인 특성이다: 초기 초안을 작성한 후 스스로 제공한 피드백을 바탕으로 이를 다듬는 과정
- 예를 들어, 동료에게 문서를 요청하는 이메일을 작성할 때, 처음에 "데이터를 빨리 보내줘"와 같이 직설적인 요청을 초기 초안으로 작성할 수 있다.
- 그러나 사람은 이 초안에서 잠재적인 무례함을 인식하고, "안녕하세요 편하신 시간에 데이터를 보내주실 수 있으신가요?"로 수정한다.
- 코드를 작성할 때에도, 초기에 "quick and dirty" 구현을 한 다음, 다시 코드를 읽어보면서 더 효율적이고 읽기 쉽게 코드를 리팩토링할 수 있다.
■ 논문에서는 이러한 인간의 방식에 영감을 받은 Iterative self-refinement를 통해, LLM이 추가 학습 없이 광범위한 tasks에서 더 높은 품질의 output을 이끌어낼 수 있음을 보여준다.
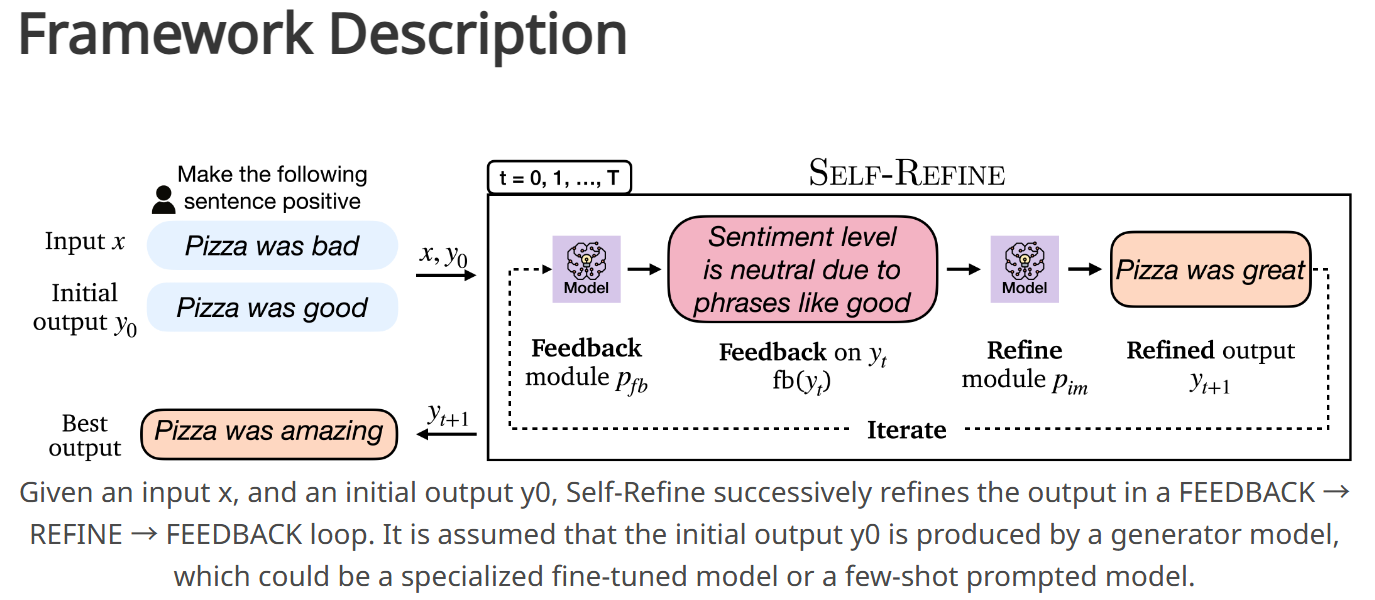
■ 논문에서 제안하는 self-refine은 "feedback"과 "refine"이라는 두 가지 생성 단계 사이를 번갈아 가며 수행하는 iterative self-refinement algorithm이다. 구체적으로, 다음과 같은 과정을 통해 고품질의 output을 생성할 수 있다.
■ model \( \mathcal{M} \)에 의해 생성된 initial output이 주어지면, 이를 다시 동일한 model \( \mathcal{M} \)에 전달하여 feedback을 얻는다. 그 다음, 이 feedback은 다시 동일한 model로 전달되어 이전에 생성된 draft를 refine한다. 이 과정은 지정된 횟수만큼 반복되거나 더 이상의 refinement가 필요 없다고 판단할 때까지 반복된다.
■ 저자들은 few-shot prompting을 사용하여 \( \mathcal{M} \)이 feedback을 생성하고, 그 feedback을 개선된 draft에 반영하도록 유도하였다.
■ Fig 1은 self-refinement가 어떤 방식으로 작동하는지를 개략적으로 나타낸 것으로, 동일한 LM이 feedback 생성과 output 수정 단계 모두에 사용되는 것을 볼 수 있다.

2. Iterative Refinement with SELF-REFINE
■ input sequence가 주어지면, self-refine은 initial output을 생성하고, 그 output에 대한 feedback을 제공하며, feedback에 따라 output을 refine한다. 이때 stopping condition이 충족될 때까지 feedback과 refinement를 반복한다.
■ self-refine은 별도의 training을 필요로 하지 않는 대신, 언어 모델과 세 가지 프롬프트(initial generation, feedback, refinement 단계에서의 프롬프트)가 필요하다.

Initial generation
■ input \( x \), prompt \( p_{gen} \), 그리고 model \( \mathcal{M} \)이 주어지면, self-refine은 initial output \( y_0 \)을 생성한다.

- 여기서 prompt \( p_{gen} \)은 initial output \( y_0 \)을 생성하기 위한 task-specific few-shot prompt (또는 instruction)이다. \( || \)는 concatenation을 나타낸 것이다.
- few-shot prompt는 "input-output" pairs \( <x^{(k)}, y^{(k)} > \)를 포함하고 있다. 예를 들어 Fig 2 (d)에서 "Generate sum of 1, ... , N"이 input \( x \)이며, 이에 대한 코드가 \( y \)이다.
FEEDBACK
■ 다음으로, feedback 생성을 위한 task-specific prompt \( p_{fb} \)가 주어졌을 때, 동일한 model \( \mathcal{M} \)을 사용하여 자신의 output에 대한 feedback \( fb_t \)를 제공한다.

- 여기서 \( p_{fb} \)는 "input-output-feedback" triples \( <x^{(k)}, y^{(k)}, fb^{(k)} > \) 형태의 feedback examples을 제공한다. (예: Fig 25)

- 여기서 "Concepts: [ ... ]"가 input \( x^{(k)} \), "Sentence: ... the sentence make sense?"가 \( y^{(k)} \)이며, Concept Feedback: ... and ride on it."이 feedback \( fb^{(k)} \)이다.
■ 직관적으로, feedback은 output의 여러 측면을 다룰 수 있다. 예를 들어 코드 최적화에서 feedback은 효율성, 가독성 등 코드의 전반적인 quality를 다룰 수 있다.
■ 그래서 저자들은 프롬프팅을 통해 model이 \( fb^{(k)} \)를 통해 'actionable'하고 'specific'한 feedback을 작성하도록 유도하였다.
- 여기서 'actionable'은 output을 향상시킬 수 있는 구체적인 action이 feedback에 포함되어야 함을 의미한다.
- 'specific'은 feedback이 output 내에서 바꿔야할 구체적인 phrase를 식별해야 함을 의미한다. (즉, 그러한 phrase이 feedback에 명시되어야 한다.)
- 예를 들어 Fig 2 (e)의 feedback에서, "... use the formula"가 논문에서 말하는 'actionable'이며, 그리고 "A better approach...(n(n+1))/2"가 어떤 식으로 바꿔야 하는지 구체적으로 알려주는 'specific'이다.
REFINE
■ 다음으로, self-refine은 자신의 feedback이 주어졌을 때, \( \mathcal{M} \)을 사용하여 가장 최근의 output을 refine한다.

- 식 3의 \( y_{t+1} \)이 바로 refined된 output이다.
- 여기서 프롬프트 \( p_{refine} \)은 feedback을 기반으로 output을 개선하는 examples을 "input-output-feedback-refined" quadruples \( <x^{(k)}, y_t^{(k)}, fb_t^{(k)}, y_{t+1}^{(k)} > \) 형태로 제공한다. 즉, \( p_{refine} \)에는 feedback을 반영한 refined된 output \( y_{t+1} \)까지 프롬프트로 구성된다.
Iterating SELF-REFINE
■ self-refine은 stopping condition이 충족될 때까지 feedback과 refine 단계를 번갈아 가며 수행한다.
■ stopping condition \( \text{stop}(fb_t, t) \)는 지정된 timestep \( t \)에서 멈추거나 feedback에 명시된 stopping indicator(예: a scalar stop score)를 추출한다.
■ model \( M \)은 stopping indicator를 생성하도록 프롬프트(예: scalar stop score가 5점이면 iteration을 멈춰라)될 수 있으며, condition은 task마다 다르다.
■ 그리고 model에게 이전 iterations을 알려주기 위해, 이전 feedback과 outputs을 프롬프트에 추가하여 history를 유지할 수 있다. 이는 직관적으로 model이 과거의 실수로부터 배우고 이를 반복하지 않도록 도와주는 것으로 볼 수 있다.
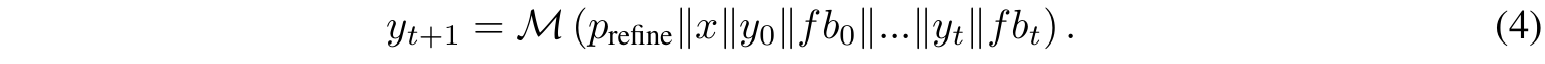
■ 최종적으로, 마지막 refinement \( y_t \)를 self-refine의 output으로 사용한다.

- 위의 pseudo code를 보면, input \( x \), model \( \mathcal{M} \), 그리고 3개의 프롬프트 \( p_{gen}, p_{fb}, p_{refine} \)과 stop condition \( \text{stop} (\cdot) \)이라는 function이 주어졌을 때,
- 먼저 initial output \( y_0 \)를 생성한 다음, \( t \)번의 iteration을 수행한다.
- iteration 내에서는, output \( y \)에 대한 feedback을 생성한 다음, 만약 feedback이 stop condition을 만족한다면 iteration을 종료하고, 만족하지 않았다면 refine을 수행한다.
- 최종적으로 iteration이 종료되면, \( y_t \)라는 final output을 반환한다.
■ self-refine의 핵심 아이디어는, 이렇게 동일한 LLM을 사용하여 생성하고, feedback을 받고, 이 feedback을 바탕으로 outputs을 refine한다는 것이다. 이는 오직 few-shot examples에 존재하는 supervision에만 의존하여 작동된다.
3. Evaluation
■ 7가지 tasks에서 self-refine을 평가한다: Dialogue Response Generation, Code Optimization, Code Readability Improvement, Math Reasoning, Sentiment Reversal
- 여기서 Code Optimization, Code Readability Improvement는 각각 파이썬 코드 효율성 향상, 파이썬 코드의 가독성을 리팩토링하는 task이다.
- Sentiment Reversal는 문장의 sentiment를 반대로 작성하는 task이다.
■ 그리고 논문에서는 두 가지 새로운 tasks을 제안한다: Acronym Generation, Constrained Generation
- Acronym Generation은 title이 주어졌을 때 title에 대한 acronym을 생성하는 task(예: World Health Organization \( \rightarrow \) WHO)이며,
- Constrained Generation은 한정된 키워드가 주어졌을 때 해당 키워드들을 사용해서 문장을 생성하는 task이다.

3.1 Instantiating SELF-REFINE
■ 섹션 2를 따라 self-refine을 구현한다: feedback-refine iteration은 원하는 output quality나 task-specific criterion에 도달할 때까지 계속되며, 최대 4번까지 반복된다.
■ 그리고 모델 간 평가의 일관성을 유지하기 위해, ChatGPT나 GPT-4와 같이 instructions에 잘 반응하는 모델에 대해서도 feedback과 refine 모두를 few-shot prompts로 구현한다.
Base LLMs
■ 저자들은 self-refine을 사용하여 LLM의 성능을 향상시킬 수 있는지 평가하기 위해, basic LLM(feedback-refine iteration이 없는 LLM, 즉 input을 넣으면 output을 출력함으로써 끝나는 basic LLM)과 self-refine LLM(basic LLM과 동일한 모델)을 비교한다.
■ 모든 tasks에 대해 세 가지 강력한 LLM을 사용한다: GPT-3.5 (text-davinci-003), ChatGPT (gpt-3.5-turbo), GPT-4
■ 단, code 기반의 tasks에 대해서는 CODEX (code-davinci-002)를 사용한다.
■ 프롬프트의 경우, 이전 연구들에서 사용된 프롬프트를 사용할 수 있는 경우 동일하게 사용하며(Code Optimization and Math Reasoning), 그렇지 않은 경우 직접 프롬프트를 작성(Appendix S)하여 사용한다.
■ 모든 setting에서 temperature 0.7의 greedy decoding을 사용한다.
3.2 Metrics
■ 세 가지 유형의 metrics을 사용한다.
- (1) Task specific metric
- task specific metric 사용할 수 있는 경우, 이전 연구의 자동화된 metrics을 사용한다. (Math Reasoning: % solve rate, Code Optimization: % programs optimized, Constrained Gen: coverage %)
- (2) Human-pref
- Dialogue Response Generation, Code Readability Improvement, Sentiment Reversal, Acronym Generation의 경우 사용 가능한 자동화된 metrics이 없으므로, outputs의 subset에 대해 blind human A/B evaluation를 수행하여 사람이 선호하는 output을 선택하도록 하였다.
- preference rate로성능을 평가했는데, 여기서 preference rate는 기존 방식의 output(basic LLM의 output)보다 self-refine을 통해 생성된 output을 선택한 횟수의 비율이다. (details: Appendix C)
- (3) GPT-4-pref
- Human-pref외에도, 이전 연구를 따라 GPT-4를 심판으로 사용한다. (details: Appendix D)
- 저자들은 실험을 통해 (3) GPT-4-pref와 (2) Human-pref는 높은 상관관계(Sentiment Reversal 82%, Acronym Generation 68%, Dialogue Response Generation 71%)를 갖는다는 것을 발견하였다.
- Code Readability Improvement의 경우, GPT-4에게 문맥에 따라 적절하게 명명된 변수의 비율을 계산하도록 프롬프트한다. (예: x = [ ]에서 x 대신 input_buffer로 바꿨을 때, input_buffer가 context에 적절하면 count)
3.3 Results
SELF-REFINE consistently improves over base models
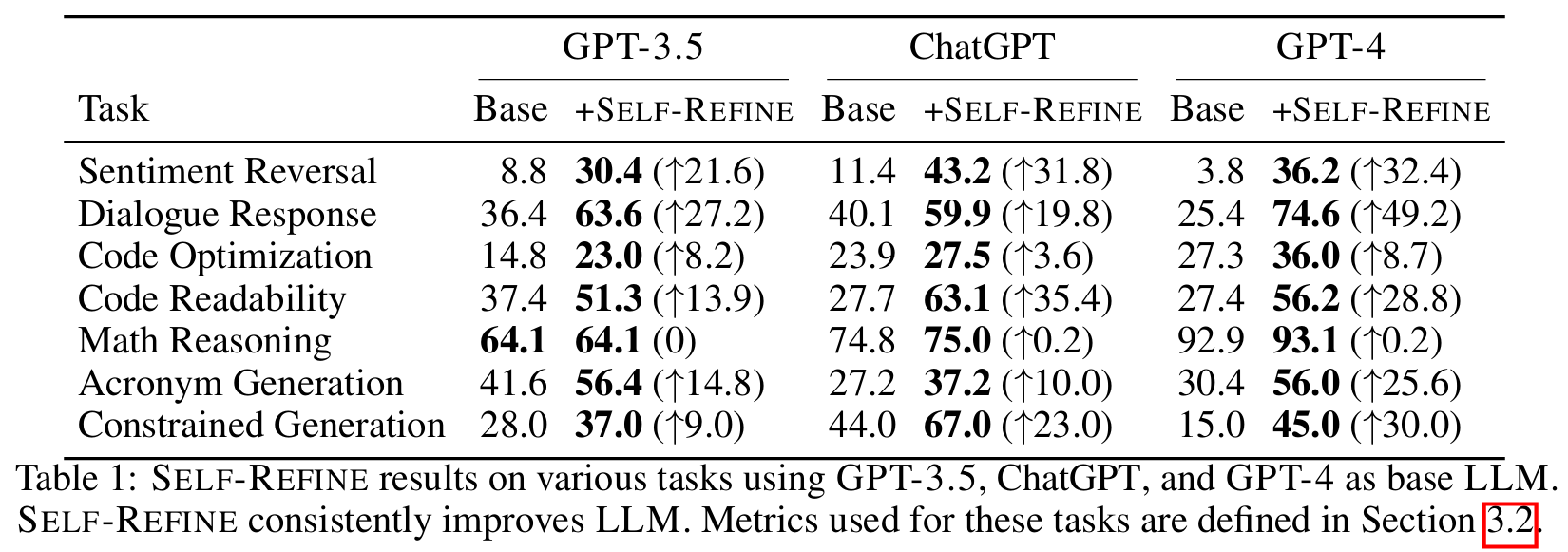
■ Table 1은 Code Optimization, Math Reasoning, Constrained Generation은 task specific metrics로, Sentiment Reversal, Dialogue Response, Code Readability, Acronym Generation은 GPT-4-pref로 평가한 결과를 나타낸 것이다.
■ self-refine은 모든 모델 크기에 걸쳐 성능 향상을 보이며, 모든 tasks에서 이전의 SOTA를 능가한다.
■ 특히, preference-based tasks인 Dialogue Response Generation, Sentiment Reversal, Acronym Generation, Code Readability는 나머지 세 가지 task에 비해 self-refine을 적용했을 때 전반적으로 더 큰 성능 향상 폭을 보인다.
■ Constrained Generation에 대해 모델은 주어진 30개의 concepts을 포함하는 문장을 생성하도록 요청받는데, 저자들은 이 task가 self-refine으로부터 상당한 performance gain을 얻었다고 주장한다.
■ 그 이유는, 첫 번째 시도에서 일부 concepts을 놓칠 기회가 더 많고(30개나 되는 concepts이 들어가므로), self-refine이 모델로 하여금 이러한 실수를 계속해서 수정할 수 있게 해주기 때문이다.
■ Math Reasoning의 성능 향상은 거의 없는 것을 볼 수 있는데, 저자들은 수학에서 오류는 되게 미묘한 부분(잘못된 문제 설명 또는 잘못된 연산)에서 발생할수 있으며, LLM이 해당 task에서 오류가 있는지 정확하게 식별하는 능력이 부족했기 때문(일관성이 있어 보이는 reasoning chain은 LLM을 속여 모든 것이 좋아 보인다고 생각하게 할 수 있다)이라고 주장한다.
- 논문에 따르면, ChatGPT의 경우 수학 문제가 틀렸음에도 94%의 경우에 "everything looks good"이라고 피드백했다고 한다.
■ 그래서 저자들은 만약 external source를 통해 답이 틀렸는지 식별할 수 있다면, Math Reasoning에서 self-refine이 효과적으로 작동하는지 평가하였다. (Appendix H.1)
Appendix H.1 Using Oracle Feedback
■ 저자들은 이전 연구를 따라 "Oracle Feedback"을 실험하였다. 이 방법은 정답 여부에 대한 정보를 사용하여 모델의 refinement를 유도하는데, 구체적으로는 현재 답이 틀렸을 때만 refine 단계로 진행하도록 하는 방식이다.
- 즉, 실제 ground truth를 알고 있는 시스템이나 외부의 verifier를 이용해서, 답이 틀렸을 때만 refine 단계를 진행하도록 한 것이다.

■ 이러한 조정을 통해 Math Reasoning의 성능을 향상시킨 것을 Table 9에서 볼 수 있다. (GPT-3.5 4.8%)
■ 이는 self-refine을 사용할 때 특정 tasks의 경우, 외부의 signals이 모델의 성능을 최적화하는 데 잠재력을 가지고 있음을 시사한다.
- 정답 여부를 알려주는 signal만 주더라도 모델이 refine 단계를 통해 output을 다시 검토하게 하여 성능 향상을 이끌어낼 수 있다.
Improvement is consistent across base LLMs sizes
■ self-refine을 사용햇을 때, 전반적으로 GPT-4가 GPT-3.5 및 ChatGPT보다 성능 향상 폭이 더 큰 것을 볼 수 있다.
■ 저자들은 이러한 결과에 대해, self-refine이 standard한 output generation에서는 드러나지 않았던 강력한 모델(예: GPT-4)의 잠재력을 끌어냈기 때문이라고 주장한다.
4. Analysis
■ self-refine의 세 가지 main steps은 feedback, refine, 그리고 이를 반복적으로 수행하는 것이다. 이 섹션에서는 각 단계의 중요성을 분석한다.
The impact of the feedback quality

■ feedback quality는 self-refine에 결정적인 역할을 한다. 그 영향을 정량화하기 위해, specific, actionable feedback을 활용하는 self-refine과 두 가지 ablation을 비교한다.
■ 하나는 일반적인 feedback을 사용하는 것이고, 다른 하나는 feedback이 아예 없는 것(모델이 반복적으로 output을 refine할 수 있지만, 명시적으로 그렇게 하라는 feedback을 제공하지 않음)이다.
- 예를 들어 Code Optimization task에서 "Avoid repeated calculations in the for loop"와 같은 actionable feedback은 문제를 정확히 지적하고 명확한 개선을 제안하지만,
- "Improve the efficiency of the code"와 같은 generic한 feedback은 actionable feedback에 비해 정밀함과 방향성이 부족하다.
■ Table 2에서 이러한 feedback의 차이를 볼 수 있다. Table 2의 모든 tasks에서 self-refine의 feedback에 비해 generic feedback의 성능은 약간 떨어지는데, 이는 generic feedback이 어느 정도의 guidance를 제공하지만, specific & actionable feedback이 더 우수한 결과를 산출한다는 것을 시사한다.
■ 이러한 효과는 Sentiment Reversal에서 더욱 두드러진다. 특히, No feedback에서는 아예 실험이 실패한 것을 볼 수 있다.
How important are the multiple iterations of FEEDBACK-REFINE?

■ Fig 4에서, iteration 횟수가 증가함에 따라 output의 quality가 향상되지만, iteration 횟수가 증가할수록(즉, output이 개선될수록) 그 효과가 감소하는 것도 볼 수 있다.

■ 단, 모든 tasks에 대해서 성능이 항상 iteration 횟수에 따라 증가하지 않는다: Table 10에서 볼 수 있듯이, Acronym Generation과 같은 task는 multi-aspect의 feedback(예: Pron에 대한 feedback, Spell에 대한 feedback 등)이 필요하다. 이러한 tasks에서는 iteration 중에 한 측면은 개선되지만 다른 측면은 저하되어 output quality가 변동할 수 있다.
Can we just generate multiple outputs instead of refining?

■ output이 개선되는 이유가 self-refine의 반복적인 refinement 때문인지, 아니면 더 많은 outputs을 생성하기 때문인지 확인하기 위해, feedback과 refinement 없이 ChatGPT가 생성한 \( k = 4 \)개의 샘플(즉, ChatGPT의 \( k \)개의 initial outputs)과 self-refine가 생성한 1개의 샘플을 비교한다.
■ 즉, 이 실험에서는 self-refine이 \( k \)개의 initial outputs을 모두 능가할 수 있는지 확인하고자 한 것이다.
■ Fig 6을 보면, 1 대 \( k \)의 대결에서 self-refine의 output이 \( k \)개의 initial outputs보다 더 선호된 것을 볼 수 있다. 이는 단순히 여러 개의 outputs을 생성하는 것보다 feedback에 따른 refinement가 더 효과적임을 보여주는 결과이다.
Does SELF-REFINE work with weaker models?
■ smaller or weaker models에서도 self-refine이 효과적으로 작동하는지 확인하기 위해, Vicuna-13B를 사용하였다.
■ Vicuna-13B의 경우 initial outputs은 strong model과 비슷하게 생성할 수 있으나, refinement process를 정확하게 수행하지 못한다. 구체적으로 feedback을 일관되게 생성하지 않는다.
■ 게다가, Oracle이나 하드 코딩된 feedback이 제공되었을 때조차도 refinement를 위한 프롬프트를 따르지 못하는 경우가 많다.
■ 이러한 결과에 대해 저자들은 Vicuna-13B가 conversation을 위해 학습되었기 때문에, test-time few-shot tasks에서 instruction-based models만큼 일반화하지 못한 데에서 비롯된 것이라고 설명한다.
Qualitative Analysis
■ 저자들은 self-refine에 의해 생성된 feedback과 refinements에 대한 질적 분석을 수행하기 위해, Code Optimization 및 Math Reasoning에서 총 70개의 samples(성공 사례 35개, 실패 사례 35개)을 직접 분석하였다.
■ 이 실험에서, 대부분의 feedback이 actionable하며, original generation의 문제점을 식별하고 이를 수정할 방법을 제안한다는 것을 발견하였다.
■ self-refine이 original generation을 개선하는 데 실패했을 때, 대부분의 문제는 잘못된 refinement보다 잘못된 feedback 때문이었다.
- 실패 사례의 33%는 feedback이 error의 위치를 부정확하게 지적한 경우, 61%는 feedback이 부적절한 수정을 제안한 경우, 6%는 refiner가 좋은 feedback이지만 잘못 만든 경우였다.
■ 이는 정확한 feedback이 self-refine 과정에서 중요 역할임을 보여주는 결과이다.
■ 성공 사례에서, refiner는 61%의 경우에서 original generation에 정밀한 수정을 가하기 위해 정확하고 유용한 feedback의 guide를 받았다.
■ 성공 사례에서 주목할 점은, feedback이 부분적으로 부정확한 경우에도 정확하게 refine되는 경우가 있었는데, 이는 성공 사례의 33%에 해당한다. 이는 feedback이 최적이 아닌 경우에 대한 resilience가 있음을 시사한다.
- 즉, feedback이 조금 틀려도 refiner가 그 feedback을 이해하고 올바르게 고치는 경우가 성공 사례의 1/3을 차지한 것이다.
Going Beyond Benchmarks
■ self-refine이 benchmark tasks뿐만 아니라, real world task에서도 적용될 수 있다는 것을 보여주기 위해, 웹사이트 생성을 수행한다.




■ 기초적인 초기 디자인에서 시작하여, self-refine은 HTML/CSS를 반복적으로 refine해서 사용성과 미적 측면 모두에서 웹사이트를 발전시킨 것을 볼 수 있다. 이는 complex하고 creative한 real-world tasks에서도 충분히 활용될 수 있음을 보여주는 결과이다.
5. Limitations and Discussion
■ self-refine의 main limitation은 self-refine을 사용할 모델들이 충분한 few-shot modeling 또는 instruction-following에 대한 능력을 갖추고 있어야 한다는 것이다. self-refine은 supervised models을 학습시키거나 supervised data에 의존하지 않고, in-context 방식으로 feedback을 제공하고 refinement를 진행하기 때문이다.
■ 즉, Vicuna-13B 실험의 실패 사례에서 볼 수 있듯, self-refine은 고성능 모델에서는 잘 작동하지만 small model에서는 효과가 제한될 가능성이 크다.
■ 또한, 논문의 실험들은 오픈 소스가 아닌 언어 모델들(GPT-3.5, ChatGPT, GPT-4, CODEX)로 수행되었다. 이러한 모델들을 실험에 사용하기 위해서는 어느 정도의 비용을 지불해야 한다.
■ 그리고 오직 영어 데이터셋으로만 실험했기 때문에, 다른 언어에서는 실험에 사용한 모델들이 동일한 성능을 발휘하지 못할 수도 있다.