■ CoT prompting에서는 LLM이 중간 추론 단계를 생성함으로써 복잡한 추론을 수행할 수 있음을 보여주었다.
■ 이러한 CoT prompting에는 두 가지 패러다임이 있다.
- (1) Zero-shot CoT: "Let's think step by step"과 같은 간단한 프롬프트를 활용
- (2) Few-shot CoT(Manual CoT): 질문과 그 답으로 이어지는 reasoning chain으로 구성된 소수의 demonstrations을 사용
■ Few-shot CoT가 Zero-shot CoT보다 조금 더 우수한 성능을 보이지만, Few-shot CoT를 위해서는 task별로 task-specific demonstrations을 사람이 어떻게 만드냐에 따라 달려 있다.
■ 논문에서는 "Let's think step by step" 프롬프트를 사용하여 LLM이 demonstrations을 위한 reasoning chain을 하나씩 생성하게 함으로써 이러한 수작업을 없앨 수 있음을 보여준다.
■ 그러나 이렇게 생성된 chains에는 오류가 포함되어 있을 수 있다. 이러한 오류의 영향을 완화하기 위해, demonstrations을 자동으로 구성하는 데 있어 다양성이 중요하다는 것을 보여준다.
[2210.03493] Automatic Chain of Thought Prompting in Large Language Models
Automatic Chain of Thought Prompting in Large Language Models
Large language models (LLMs) can perform complex reasoning by generating intermediate reasoning steps. Providing these steps for prompting demonstrations is called chain-of-thought (CoT) prompting. CoT prompting has two major paradigms. One leverages a sim
arxiv.org
1. INTRODUCTION

■ CoT prompting은 두 가지 패러다임으로 분류할 수 있다.
■ 하나는 "Let’s think step by step"과 같은 프롬프트를 추가하여 LLM의 reasoning chains을 이끌어내는 방법은 task-agnostic하며 input-output demonstrations이 필요하지 않기 때문에 "Zero-Shot-CoT"라고 불린다.
■ 다른 하나는 수동으로 작성된 manual reasoning demonstrations을 one-by-one으로 사용하는 few-shot prompting이다. 각 demonstration은 question과 reasoning chain으로 구성된다. 이때, reasoning chain은 rationale(일련의 intermediate reasoning steps)과 expected answer로 구성된다.
■ 이 방법은 모든 demonstrations이 manually designed되므로, "Manual-CoT"라고 불린다.
■ Manual-CoT는 Zero-Shot-CoT보다 더 강력한 성능을 보여주었다. 그러나 이러한 성능은 효과적인 demonstrations을 어떻게 작성하는가에 따라 달려 있으며, demonstrations을 만들기 위해 questions과 reasoning chains을 모두 설계하는 것은 상당한 노력을 필요로 한다.
■ 더욱이 Manual-CoT는 task-specific demonstrations을 설계해야 하므로, 이를 준비하는 데 필요한 사람의 노력은 더욱 커진다.
■ 저자들은 이러한 manual designs을 없애기 위해, questions과 reasoning chains이 포함된 demonstrations을 자동으로 구성하는 Auto-CoT를 제안한다.
■ Auto-CoT는 "Let's think step by step" 프롬프트를 사용하여 LLM이 demonstrations을 위한 reasoning chains을 하나씩 생성하도록 활용한다. 즉, "단순히 단계별(step by step)로 생각하는 것뿐만 아니라, 하나씩(one by one) 생각해 보는 것"이다.
■ 그러나 저자들은 이러한 아이디어가 단순한 방법으로는 해결될 수 없음을 발견하였다. Zero-Shot-CoT는 여전히 reasoning chains에서 실수가 발생하기 때문이다.
■ Zero-Shot-CoT의 reasoning chain mistakes로 인한 영향을 완화하기 위해, 논문에서는 demonstration questions의 다양성이 핵심임을 보여준다. 이를 바탕으로 demonstrations을 자동으로 구성하는 Auto-CoT 방법을 제안한다.
2. Related Work
2.1 Chain-of-thought Prompting
■ CoT prompting은 LLM이 최종 정답으로 이어지는 중간 추론 단계를 생성하도록 유도하는, 그래디언트 업데이트가 없는 gradient-free technique이며, Zero-Shot-CoT와 Few-Shot-CoT(Manual-CoT)로 나뉜다.
Zero-Shot-CoT
■ "Large Language Models are Zero-Shot Reasoners"에서 LLM은 훌륭한 zero-shot reasoners이며, LLM이 생성한 rationales이 CoT reasoning을 반영하고 있음을 보여주었다. 여기서 저자들은 자체 생성된 rationales을 demonstrations로 활용하는 아이디어를 얻었다.
■ LLM이 생성한 rationales을 활용하는 기존 연구 중에는, LLM이 rationales을 생성하도록 프롬프트한 뒤, 정답으로 이어지는 rationales만 선택하는 접근이 있었다.
■ 그러나 이러한 선택 과정은 정답이 있는 question training dataset을 필요로 한다. "올바르게 푼 풀이"를 선택하려면 정답 정보가 있어야 하기 때문이다.
■ 대조적으로 Auto-CoT는 original Zero-Shot-CoT와 original CoT prompting (Manual-CoT)의 연구를 따르며, 별도의 training dataset 없이 오직 test questions의 set만 주어지는 더욱 challenging한 시나리오를 고려한다.
Manual-CoT
■ Manual-CoT는 효과적인 manual demonstrations을 통해 CoT reasoning ability를 이끌어냄으로써 Zero-Shot-CoT보다 더 강력한 성능을 달성한다.
■ 그러나 questions과 reasoning chains를 모두 설계하는 데에는 상당한 인간의 노력이 필요하다.
■ 당시 후속 연구들은 이러한 한계를 해결하는 대신, 더 복잡한 demonstrations을 사람이 만들거나 앙상블과 유사한 방법을 활용하는 데 집중하고 있었다.
- 복잡한 문제를 하위 문제들로 분해한 다음, 하위 문제들부터 순차적으로 해결하는 방식
- test questions에 대한 여러 reasoning paths을 투표하는 방식: LLM의 여러 outputs을 샘플링 한 다음, final answer에 대해 다수결 투표를 하는 self-consistency decoding strategy
■ 사람이 직접 설계한 demonstrations에 의존하는 연구 흐름들과 달리, 저자들은 경쟁력 있는 성능을 유지하면서 manual designs을 제거하고자 하였다.
2.2 In-Context Learning
■ CoT prompting은 in-context learning (ICL)과 밀접하게 관련되어 있다.
■ ICL은 input의 일부로 few prompted examples을 제공함으로써 LLM이 target task를 수행할 수 있게 한다. gradient update 없이, ICL은 하나의 모델로 다양한 tasks에 대해 범용적으로 수행할 수 있다.
■ 그러나 ICL의 단점은 demonstrations의 선택에 따라 성능이 크게 달라질 수 있다는 것이다. 단어 선택이나 demonstrations 순서가 달라진 프롬프트는 성능 변동을 초래할 수 있다.
■ 당시 최신 연구 중 input-output mapping의 필요성에 의문을 제기한 연구가 있었는데, examples에 잘못된 레이블을 사용해도 성능이 아주 미미하게 낮아진다는 결과를 보고하였다.
■ 그러나 이 분석은 주로 단순한 <input \( \rightarrow \) output> mappings을 가진 standard한 classification이나 multi-choice datasets에 기반하고 있다.
■ 저자들은 이러한 분석이 더 복잡한 <input \( \rightarrow \) rationale \( \rightarrow \) output> mappings을 가진 CoT prompting 시나리오에는 적용되지 않을 수 있음을 발견한다.
- 예를 들어, <input \( \rightarrow \) output> mapping이나 <rationale \( \rightarrow \) output> mapping 중 하나라도 실수가 있으면 급격한 성능 저하로 이어질 수 있다. (Appendix A.1)
Appendix A.1 Impact of demonstration elements
■ Fig 1과 같이 <question, rationale, answer> 구성한 다음, 성능 변화를 확인하기 위해 구성 요소 중 하나를 섞었다.
■ 아래의 Table 5를 보면, questions을 섞는 것이 성능 저하가 가장 적은 것을 볼 수 있으며, 이는 모델이 rationale-answer mapping 패턴을 학습했을 가능성이 높다.
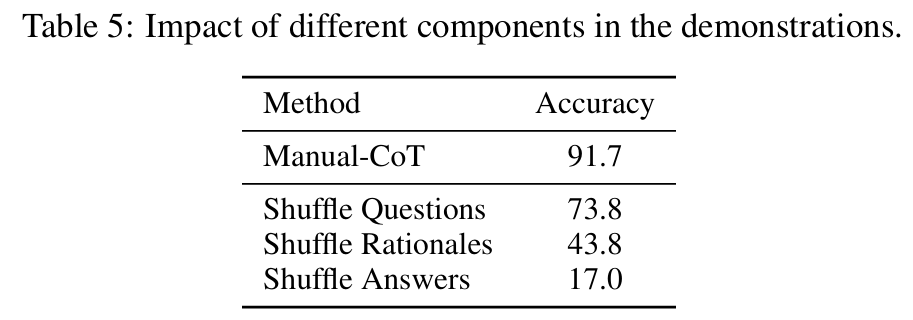
■ 반면, rationale이나 answer를 섞으면 정확도가 크게 떨어진다. (91.7%에서 43.8%/17.0%) 이러한 실험 결과는 rationale-answer 간의 일관성이 매우 중요함을 시사한다.
3. Challenge of Auto-CoT
■ ICL의 성능은 사람이 demonstrations을 어떻게 만드냐에 달려 있다. Manual-CoT에서는 demonstrations의 순서를 바꾸는 것보다, 서로 다른 annotators이 작성한 demonstrations을 사용하는 것이 성능에 훨씬 큰 영향을 미치는 것을 보여주었다. (symbolic reasoning task에서 성능 차이 2% vs 28.2%)
■ 이는 Auto-CoT의 성공 여부가 어떤 good questions을 뽑아서 그에 대한 reasoning chains을 가진 demonstrations을 어떻게 구성할 것인가에 달려 있음을 시사한다.
■ LLM 프롬프팅에 유사도 기반 검색 방법이 널리 채택되고 있으므로, 해결책 중 하나는 유사도 기반 검색을 사용하여 demonstration questions을 샘플링하는 것이다.
■ 저자들은 questions을 인코딩하기 위해 Sentence-BERT를 사용한다. training dataset 없이 오직 test questions만 사용하므로, test dataset의 각 question \( q^{\text{test}} \)에 대해, 나머지 questions 중에서 demonstration questions \( q_i^{\text{demo}} \; (i=1, \cdots, k) \)를 샘플링한다.
■ 코사인 유사도를 기반으로 top-\( k \)개의 유사한 questions을 검색하는 "Retrieval-Q-CoT" 방법을 설계한다.
■ 즉, "Retrieval-Q-CoT"의 아이디어는 \( q^{\text{test}} \)와 비슷한 \( k \)개의 \( q_i^{\text{demo}} \)를 찾은 다음, Zero-Shot-CoT에게 해당 questions을 풀게 시켜서 예시로 만드는 것이다. 일반적으로 ICL에서는 비슷한 예시를 보여주는 것이 성능이 좋다.
■ 이 유사도 기반 방법인 Retrieval-Q-CoT와 비교하기 위해, 각 test question에 대해 서로 다른 \( k \)개의 test questions을 무작위로 샘플링하는, 다양성 기반의 방법인 "Random-Q-CoT"도 테스트한다.
■ "Retrieval-Q-CoT"와 "Random-Q-CoT" 모두, 각 샘플링된 question \( q_i^{\text{demo}} \)에 대한 reasoning chain \( c_i^{\text{demo}} \) (rationale and answer)를 생성하기 위해 Zero-Shot-CoT를 호출하여 사용한다. 이는 LLM이 괜찮은 zero-shot reasoners이기 때문이다.
- 기본적으로 LLM은 175B GPT-3 (text-davinci-002)를 사용한다.
■ Retrieval-Q-CoT와 Random-Q-CoT 모두 \( q_i^{\text{demo}}, c_i^{\text{demo}} \) pairs \( (i=1, \cdots, k) \)와 \( q^{\text{test}} \)의 concatenation을 입력으로 받아 \( q^{\text{test}} \)에 대한 reasoning chain을 예측하며, 마지막에 answer을 포함한다. (Fig 1의 right와 유사)
■ arithmetic dataset인 MultiArith에서 Retrieval-Q-CoT는 Random-Q-CoT보다 성능이 떨어진다.

■ 기존의 검색 방법이 성공했던 이유는 정답이 있는 데이터를 사용했기 때문이다. Retrieval-Q-CoT는 정답 없이 test set으로 Zero-Shot-CoT가 즉석에서 만든 정답을 사용하지만, Zero-Shot-CoT를 사용한다고 해서 전적으로 올바른 reasoning chains을 보장하지는 않는다.
■ 저자들은 Retrieval-Q-CoT의 성능이 Zero-Shot-CoT에 의한 잘못된 reasoning chains 때문이라고 가정하였다.
■ 이 가설을 검증하기 위해, annotated reasoning chains이 있는 training sets을 가진 GSM8K와 AQuA에서 Retrieval-Q-CoT를 실험하였다. 결과는 Table 1에 \( \dagger \) 기호와 함께 표시되어 있다.
■ annotated reasoning chains이 있는 설정에서는 Retrieval-Q-CoT가 Manual-CoT보다 더 나은 성능을 보이기도 한다. 이 결과는 human annotations이 있을 때 Retrieval-Q-CoT가 효과적임을 나타낸다. 즉, 문제는 Zero-Shot-CoT가 만든 풀이에 오류가 섞여 있다는 점이다.
■ human annotations이 유용하긴 하지만, 이를 위한 수작업 비용은 적지 않다. 그러나 Zero-Shot-CoT를 통해 reasoning chains을 자동으로 생성하는 것은 Manual-CoT보다 성능이 떨어진다.
3.1 Retrieval-Q-CoT Fails due to Misleading by Similarity
■ Retrieval-Q-CoT는 Manual-CoT처럼 few prompting demonstrations을 사용하므로, Retrieval-Q-CoT에서도 경쟁력 있는 성능을 보일 것으로 예상했으나, Retrieval-Q-CoT의 reasoning chains(rationales and answers)은 모두 Zero-Shot-CoT에 의해 생성되므로, 오답으로 이어지는 경우가 있을 수 있다.
- 논문에서는 wrong answers을 가진 demonstrations을 wrong demonstrations이라 부른다.
■ test question과 유사한 questions을 검색된 후, Zero-Shot-CoT에 의해 생성된 wrong demonstrations은 동일한 LLM이 test question에 대해서도 유사한 방식으로 잘못된 answer를 추론하도록 misleading할 수 있다.
- 논문에서는 이러한 현상을 misleading by similarity이라고 부른다.
■ 저자들은 misleading by similarity가 Retrieval-Q-CoT의 성능 저하에 기여하는지 다음과 같이 조사하였다.
■ MultiArith dataset의 600개 questions 전체에 대해 Zero-Shot-CoT를 실행한다. 그중 Zero-Shot-CoT가 wrong answers을 생성한 128개 questions (denoted as \( \mathcal{Q} \))을 수집한다. (error rate: 21.3% = 128/600)
■ Zero-Shot-CoT가 실패한 \( \mathcal{Q} \) 중에서, Retrieval-Q-CoT나 Random-Q-CoT가 여전히 실패하는 questions을 "unresolved questions"라고 하자. 저자들은 unresolved questions의 수를 128(\mathcal{Q}의 개수)로 나누어 "unresolving rate"를 계산하였다.
■ unresolving rate가 높다는 것은 해당 방법이 Zero-Shot-CoT와 같은 실수를 여전히 범할 가능성이 높다는 것을 의미합니다. Fig 2는 Retrieval-Q-CoT의 unresolving rate (46.9%)가 Random-Q-CoT (25.8%)보다 훨씬 높음을 보여준다.
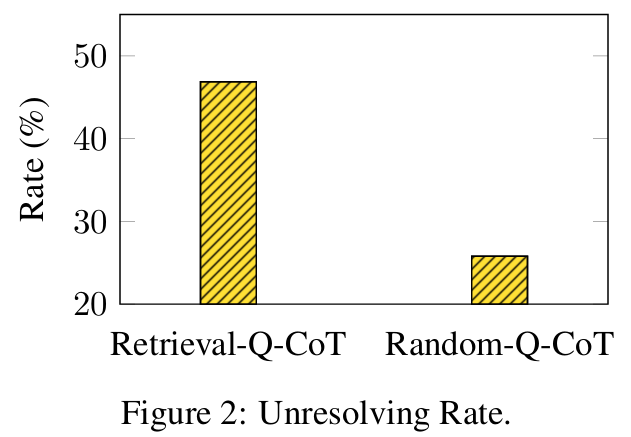
■ 이는 test questions에 대한 similar questions이 샘플링될 때, Retrieval-Q-CoT가 misleading by similarity로 인해 부정적인 영향을 받는다는 것을 나타낸다.
■ 즉, Random 방식은 운 좋게 "맞게 푼 다른 유형의 문제"를 예시로 보여줄 가능성이 있으며, 이를 통해 올바른 추론 과정을 보고 모델이 오류를 교정할 수 있다. 반면, Retrieval 방식은 "비슷한 오류를 범한 문제"만 보기 때문에 교정 기회를 얻기 어렵다. Table 2는 이러한 경향을 잘 보여준다.

■ Table 2의 Retrieval-Q-CoT 부분을 보면, 검색된 demonstration questions은 test question과 유사하며 "'the rest'를 요리하는 데 얼마나 걸릴까?"라고 묻고 있다. 그러나 Zero-Shot-CoT에 의해 생성된 reasoning chains은 "the rest" 대신 "the total of"에 관한 answer를 생성한다. 이러한 demonstrations을 따라, Retrieval-Q-CoT 또한 "the rest"의 의미를 잘못 이해하고 실패로 이어진다.
■ 대조적으로 Table 2의 Random-Q-CoT 부분을 보면, Random-Q-CoT는 더 다양한(랜덤) demonstrations 덕분에 Retrieval-Q-CoT와 유사한 실수를 범하지 않고 "the rest"를 더 잘 이해한다.
3.2 Errors Frequently Fall into the Same Cluster
■ 저자들은 Table 2와 같은 관찰을 통해, \( k \)-means를 사용하여 600개의 모든 test questions을 \( k = 8 \)개의 클러스터로 분할하였다. 각 클러스터는 유사한 questions을 포함하고 있다.
■ 이러한 클러스터들과 Zero-Shot-CoT에 의해 생성된 reasoning chains을 가지고, 특정 클러스터가 Zero-Shot-CoT가 자주 실패하는 questions을 포함하고 있는지 섹션 3.1과 동일한 실험을 수행하였다.
■ 여기서는 각 클러스터에 대해 error rate (wrong Zero-Shot-CoT answers을 가진 questions의 수 / total questions의 수)을 계산한다.
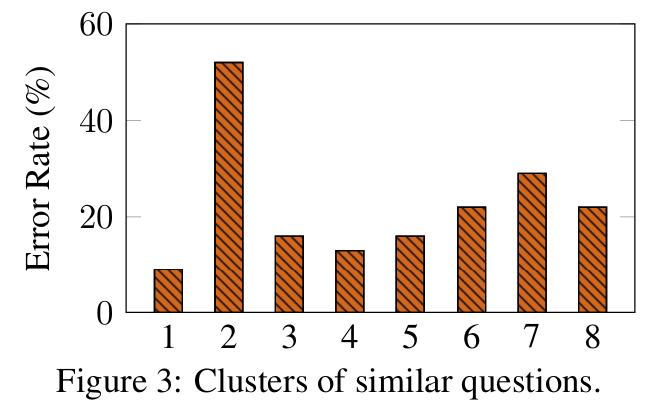
■ Fig 3에서 볼 수 있듯이, error rate가 매우 낮은 클러스터가 존재하고(즉, LLM이 잘 푸는 유형, 예: 클러스터 1, 3, 4), 빈번한 Zero-Shot-CoT error (52.3%)를 가진 클러스터(Fig 3의 클러스터 2)가 존재한다.
- 논문에서는 가장 높은 error rate를 가진 클러스터를 frequent-error cluster라고 부른다. (예: Fig 3의 클러스터 2)
■ 이 현상은 Zero-Shot-CoT가 몇몇 공통적인 문제를 해결하는 기술이 부족할 수 있기 때문에 일반적인 결과일 수 있다.
■ 이 실험을 통해 Retrieval 방식이 실패하는 이유를 설명할 수 있다: zero-shot 방식으로 생성된 reasoning chains은 불완전하기 때문에, 유사도 기반 방법을 사용하면 frequent-error cluster 내부에 있는 questions이 여러 개 검색될 risk가 존재하며, 그 결과 모델이 잘못된 demonstrations을 보게 될 가능성이 매우 높아진다.
3.3 Diversity May Mitigate Misleading by Similarity
■ 지금까지의 분석은 LLM이 여전히 완벽한 zero-shot reasoners가 아님을 보여준다. 따라서 저자들은 Auto-CoT 설계 시 Zero-Shot-CoT errors의 영향을 완화하고, 특히 similarity에 의한 misleading을 완화하는 것을 목표로 하였다.
■ 모든 wrong demonstrations의 questions이 동일한 frequent-error cluster에 속한다고 가정하자.
■ 이 가정하에 서로 다른 각 cluster에서 question을 하나씩 샘플링하면, frequent-error cluster에서 뽑힌 1개가 틀리더라도, 나머지 7개 cluster에서 뽑힌 것들은 맞을 확률이 높다. 따라서 올바른 demonstrations을 모두 구성할 확률을 7/8 = 87.5% 이상이 될 수 있다.
■ 서로 다른 cluster는 questions의 다양한 semantics을 반영하므로, 클러스터링 기반 샘플링 방법은 다양성 기반 방법으로 볼 수 있으며, 이는 유사도 기반의 Retrieval-Q-CoT와 뚜렷하게 대조된다.
■ 다양성을 갖춘 questions 샘플링은 similarity에 의한 misleading의 영향을 완화할 수 있다. (섹션 3.1)
■ 그리고, 각 demonstration을 일종의 skill로 본다면, 다양한 demonstrations은 target questions을 해결하기 위한 더 많은 skills을 사용하는 것으로 볼 수 있다: 샘플링한 demonstrations의 적은 비율(예: 1/8)에서 여전히 mistakes이 존재하더라도 성능은 부정적인 영향을 받지 않는다. (Fig 6)
■ 그럼에도 불구하고, 클러스터링 기반 샘플링 방법은 frequent-error cluster의 questions과 같이 여전히 적은 비율의 wrong demonstrations을 구성할 수 있다.
■ 그러나 이러한 wrong demonstrations 중 일부는 휴리스틱으로 제거될 수 있다.
■ 예를 들어, wrong demonstrations은 종종 긴 questions과 긴 rationales을 동반하는데, 더 짧은 questions과 rationales만을 고려하는 간단하고 일반적인 휴리스틱을 사용하면, 불완전한 Zero-Shot-CoT 능력의 영향을 완화하는 데 추가적인 도움을 준다. (Appendix C.2)
Appendix C.2 Effectiveness of the simple heuristics
■ 섹션 4에서는 모델이 간단하고 정확한 demonstrations을 사용하도록 유도하기 위해 단순한 휴리스틱을 적용한다: 더 간단한 questions과 rationales을 선택하도록 하였다.
■ 구체적으로, question \( q_j^{(i)} \)의 길이가 60 토큰 이하이고, rationale \( r_j^{(i)} \)가 5개 이하의 reasoning steps로 구성된 경우에만 해당 demonstration \( d^{(i)} \)를 선택하였다.
■ multiple-choice problem인 AQuA를 제외한 arithmetic reasoning tasks의 경우, rationale과 answer의 mismatch risk를 줄이기 위해 answer \( a_j^{(i)} \)가 (1) 비어 있지 않으면서 (2) 동시에 rationale \( r_j^{(i)} \) 내용 안에 포함되어야 한다는 조건을 추가하였다.
- Appendix A.1에서 rationale과 answer의 mismatches가 성능에 악영향을 준다는 것을 확인하였다. (Table 5)
- 이 악영향을 줄이기 위해 이러한 조건을 추가한 것이다.
■ question, rationale, 그리고 answer가 위의 조건들을 모두 만족할 경우 이를 [Q: \( q_j^{(i)} \), A: \( r_j^{(i)} \circ a_j^{(i)} \)] 형태로 연결하여 \( i \)번재 클러스터를 위한 candidate demonstration \( d_j^{(i)} \)를 생성하였다.
■ 단순 휴리스틱의 효과를 정량적으로 분석하기 위해, 휴리스틱 적용 전과 후에 대한 demonstration 생성 과정을 각각 세 번씩 수행했으며, 그 결과는 Table 9에서 확인할 수 있다.

■ 단순 휴리스틱을 적용하면 demonstrations을 구성할 때 잘못된 rationales이 포함되는 평균 횟수가 감소한 것을 볼 수 있다.
■ 아래의 Fig 10은 단순 휴리스틱 적용 여부에 따른 error rate이다. 여기서 error rate는 잘못된 rationales의 평균 개수를 demonstrations의 개수로 나누어 산출되었다.

■ Fig 10에서, 저자들이 제안한 휴리스틱 방법이 대부분의 tasks (10개 중 7개)에서 error rate를 20% 미만으로 유지함을 확인할 수 있다.
4. Auto-CoT: Automatic Chain-of-Thought Prompting
■ 섹션 3에서의 결과를 바탕으로, 저자들은 questions과 reasoning chains을 자동으로 구성하는 Auto-CoT를 제안한다.

■ Auto-CoT는 두 가지 단계로 구성된다
- (1) question clustering: 주어진 데이터셋의 questions을 몇 개의 클러스터로 분할한다.
- (2) demonstration sampling: 각 클러스터에서 representative question을 하나씩 선택하고 간단한 휴리스틱(Appendix C.2)을 사용하여 Zero-Shot-CoT로 선택한 question에 대한 reasoning chain을 생성한다.
- 기존의 접근법들과 Auto-CoT의 차이점은, Auto-CoT에서는 Fig 4의 왼쪽 부분에서 볼 수 있듯이 question clustering을 사용한다는 것이다.
4.1 Question Clustering
■ diversity-based clustering이 similarity에 의한 misleading을 완화할 수 있다(섹션 3.3).
■ 먼저, Sentence-BERT를 사용하여 주어진 questions의 set \( \mathcal{Q} \)의 각 question들에 대한 vector representation을 계산한다. 이 과정을 통해 contextualized된 vector들은 고정된 크기의 question representation을 형성하게 된다.
■ 그런 다음, question representations은 k-means clustering에 의해 처리되어 \( k \)개의 question clusters을 생성한다.
■ 각 cluster \( i \)의 questions에 대해, cluster \( i \)의 중심까지의 거리가 오름차순이 되도록 정렬하여 list \( \mathbf{q}^{(i)} = [q_1^{(i)}, q_1^{(2)}, \cdots] \)을 만든다. 중심에 가까울수록 그 그룹의 특성을 가장 잘 대표하는 질문이기 때문이다.

4.2 Demonstration Sampling
■ 두 번째 단계에서는 샘플링된 questions에 대한 reasoning chains을 생성하고, 저자들의 선택 기준(Appendix C.2)을 만족하는 demonstrations을 샘플링한다.
■ 구체적으로, 각 cluster \( i \; (i=1, \cdots, k) \)에 대해 demonstration \( d^{(i)} \) (즉, question, arationale, ananswer의 concatenation)를 구성한다.
■ cluster \( i \)에 대해 선택 기준을 만족할 때까지 Algorithm 1에서 얻은 정렬된 list \( \mathbf{q}^{(i)} = [q_1^{(i)}, q_1^{(2)}, \cdots] \)의 questions을 반복한다. 즉, cluster \( i \)의 중심에 더 가까운 question이 먼저 선택된다.
■ cluster \( i \)의 중심과 \( j \)번째로 가까운 question \( q_j^{(i)} \)가 있다고 하자. 프롬프트 입력은 [Q: \( q_j^{(i)} \), A: [P] ]로 형성되는데, 여기서 [P]는 single prompt "Let's think step to step"이다.
■ 이렇게 형성된 프롬프트 입력은 Zero-Shot-CoT를 사용하는 LLM에 입력되어 rationale \( r_j^{(i)} \)와 추출된 answer \( a_j^{(i)} \)로 구성된 reasoning chain을 출력한다.
■ 그런 다음, \( i \)번째 cluster를 위한 candidate demonstration \( d_j^{(i)} \)를 question, rationale, answer로 연결하여 만든다: [Q: \( q_j^{(i)} \), A: \( r_j^{(i)} \circ a_j^{(i)} \)]
- 이 \( d_j^{(i)} \)는 Appendix C.2의 휴리스틱이 적용된 상태이다.

■ Algorithm 2에서 볼 수 있듯이, \( k \)개의 모든 clusters에 대한 demonstration sampling 후에는 \( k \)개로 구성된 demonstrations \( [d^{(1)}, \cdots, d^{(k)}] \)가 있게 된다.
■ 이 demonstrations은 in-context learning을 위해 test question \( q^{\text{test}} \)를 해결하는 데 사용된다. 즉, \( [d^{(1)}, \cdots, d^{(k)}] \) 뒤에 [Q: \( q^{\text{test}} \), A: [P] ]를 붙인 형태가 LLM의 입력으로 사용된다. (Fig 4 right의 LLM In-Context Reasoning의 input)
■ 이 입력 형태는 LLM에 입력되며, LLM은 \( [d^{(1)}, \cdots, d^{(k)}] \)를 참고하여, 마지막 문제인 \( q^{\text{test}} \)를 풀게 된다. 최종적으로 \( q^{\text{test}} \)에 대한 answer를 포함한 reasoning chain을 얻는다. (Fig 4 right의 In-Context Reasoning의 output)
5. Experiments
5.1 Experimental setup
Tasks and Datasets
■ Auto-CoT는 세 가지 범주의 reasoning tasks에서 10개의 benchmark datasets으로 평가된다
- (1) arithmetic reasoning: MultiArith, GSM8K, AddSub, AQUA-RAT, SingleEq, SVAMP)
- (2) commonsense reasoning: CSQA, StrategyQA
- (3) symbolic reasoning: LetterConcatenation, CoinFlip
Implementation
■ 기본적으로 175B text-davinci-002 버전의 GPT-3를 LLM으로 사용한다.
- 당시 공개된 LLM 중 가장 강력한 CoT reasoning 능력을 가진 것으로 평가되었기 때문에 선택했다고 한다.
■ 그리고 Codex (code-davinci-002)도 LLM으로 사용해서 평가한다.
■ Manual-CoT를 따라 demonstrations의 수 \( k \)는 8개이며, 예외적으로 AQuA와 Letter는 4개, CSQA는 7개, StrategyQA는 6개로 설정하였다.
Baselines
■ Auto-CoT와 네 가지 베이스라인 방법을 비교한다: Zero-Shot, Zero-Shot-CoT, Few-Shot, Manual-CoT
■ Zero-Shot 베이스라인은 test question 뒤에 "The answer is"라는 프롬프트를 연결하여 LLM의 입력으로 사용한다.
■ Few-Shot 베이스라인은 모든 demonstrations에서 rationales가 제거된 것을 제외하고는 Manual-CoT와 동일한 LLM 입력을 사용한다. (즉, Manual-CoT에서 rationales가 제거된 버전)
5.2 Competitive Performance of Auto-CoT on Ten Datasets

■ Table 3은 reasoning tasks에서 10개 데이터셋에 대한 정확도를 측정한 결과이다.
■ 전반적으로 Auto-CoT는 demonstrations를 manually하게 설계해야 하는 CoT 패러다임(즉, Manual-CoT)의 성능과 비슷하거나 능가하는 모습을 보인다.
■ manual designs의 비용 때문에 Manual-CoT는 여러 데이터셋에 대해 같은 demonstrations를 사용하기도 했지만, 대조적으로 Auto-CoT는 더 유연하고 task-adaptive하다: 각 데이터셋에 맞는 고유한 demonstrations를 자동으로 만들어내기 때문이다.
5.3 Visualization of Question Clustering

■ Fig 5는 PCA projection을 사용하여 10개 데이터셋에서의 question clustering을 시각화한 것이다.
■ PCA 결과를 보면, 실제로 군집들이 형성되어 있는 것을 볼 수 있는데, 이는 "서로 다른 questions을 유형별로 나눌 수 있다"는 Auto-CoT의 전제가 타당함을 증명하는 결과이다.
5.4 General Effectiveness Using the Codex LLM

■ 서로 다른 LLM을 사용하여 Auto-CoT의 효과를 비교하기 위해, LLM을 Codex로 변경하였다.
■ Table 4에서 볼 수 있듯이, Codex는 GPT-3 (text-davinci-002)을 사용한 Table 3과 비교했을 때, Manual-CoT에서 더 나은 성능을 보여준다.
■ 그럼에도 불구하고, Codex를 사용하더라도 Auto-CoT의 전반적인 성능은 여전히 Manual-CoT에 비해 경쟁력이 있다.
5.5 Effect of Wrong Demonstrations
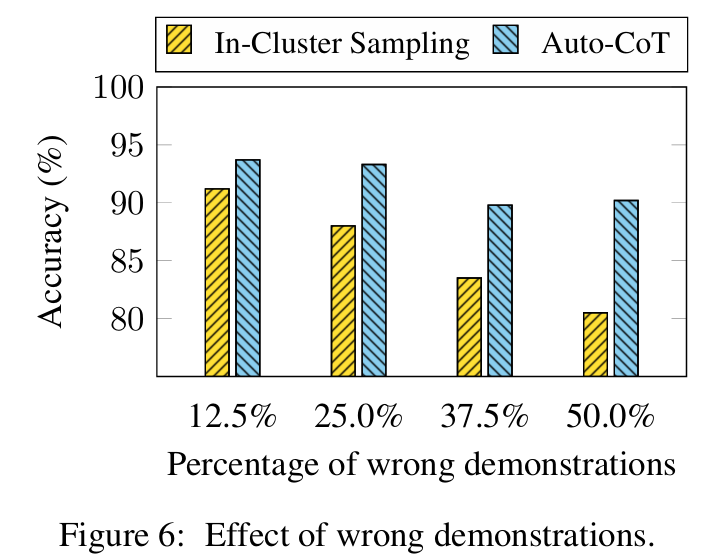
■ 섹션 3.3에서 제기된 wrong demonstrations(whose answers are wrong)의 영향을 다양성이 완화할 수 있는지 확인하기 위해, test question이 포함된 동일한 cluster에서 무작위로 questions을 샘플링하여 demonstrations을 구성하는 베이스라인(In-Cluster Sampling)을 설계하여 비교한다.
■ Fig 6은 MultiArith 데이터셋에서 wrong demonstrations의 양을 변화시키며 정확도를 비교한 결과이다.
■ In-Cluster Sampling과 비교했을 때, Auto-CoT의 정확도가 훨신 높으며 50%의 wrong demonstrations가 제공되었을 때에도 성능이 크게 저하되지 않는 것을 볼 수 있다. 반면 In-Cluster Sampling은 wrong demonstrations의 양이 증가할수록 성능이 Auto-CoT에 비해 급격히 떨어진다.
■ 즉, Auto-CoT (using diversity-based clustering)는 wrong demonstrations의 영향을 덜 받는다.
5.6 More Challenging Streaming Setting
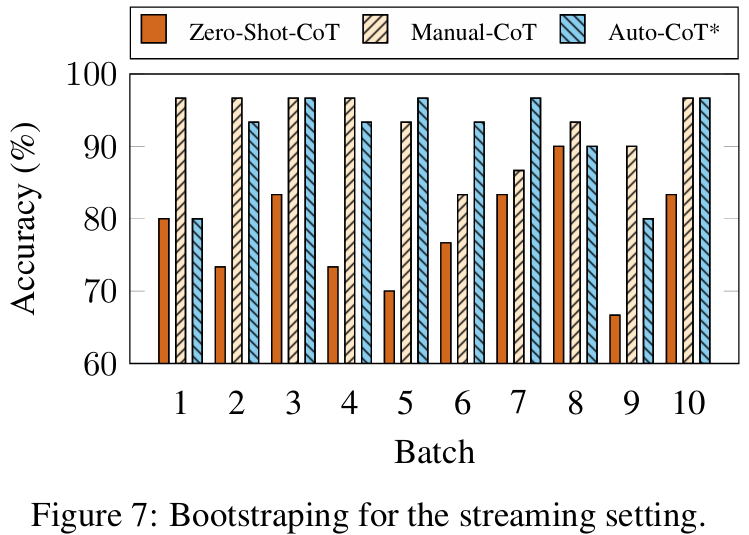
■ CoT 연구들은 일반적으로 test questions이 포함된 full dataset이 주어진다고 가정한다. 반면, Auto-CoT는 주어진 dataset을 기반으로 demonstrations을 구성하기 위해 questions을 샘플링한다.
■ 그래서 저자들은 이러한 Auto-CoT가 data streams처럼 한 번에 소규모 배치의 test questions(예: \( m \)개의 questions)이 도착하는 더 challenging한 "streaming setting"에서도 잘 작동하는지 평가하고자 하였다.
■ 그러나 streaming setting은 데이터가 한꺼번에 주어지지 않고 실시간으로 조금씩 들어오기 때문에, 이때는 클러스터링할 충분한 데이터가 없다.
■ 이러한 문제를 해결하기 위해, 저자들은 bootstrapping version인 Auto-CoT*를 사용하였다.
- (1) empty set \( \mathcal{M}_0 \)을 초기화한다.
- (2) 첫 번째 배치의 questions \( q_1^{(1)}, \cdots q_m^{(1)} \)이 도착하면, 각 \( q_i^{(1)} \)에 대해 Zero-Shot-CoT를 호출하여 reasoning chain \( c_i^{(1)} \)를 얻는다. 이때, 작은 \( m \)으로 인해 클러스터링이 없다.
- question과 reasoning chain 쌍 \( (q_1^{(1)}, c_1^{(1)}), \cdots, (q_m^{(1)}, c_m^{(1)}) \)을 \( \mathcal{M}_0 \)에 추가한다. (새롭게 업데이트되는 set은 \( \mathcal{M}_1 \)이 된다.)
- (3) \( b (b > 1) \)번째 배치의 questions \( q_1^{(b)}, \cdots q_m^{(b)} \)이 도착하면, \( \mathcal{M}_{b-1} \)에 있는 기존 questions과 reasoning chains을 사용하여 Auto-CoT처럼 demonstrations을 구성하고, 이를 각 \( q_i^{(b)} \)에 대한 in-context reasoning에 사용한다.
- question과 reasoning chain 쌍 \( (q_1^{(b)}, c_1^{(b)}), \cdots, (q_m^{(b)}, c_m^{(b)}) \)을 \( \mathcal{M}_{b-1} \)에 추가한다. 다음 새로운 set은 \( \mathcal{M}_b \)가 된다.
■ Fig 7은 streaming setting에서 각 배치( \( m =30 \))마다의 MultiArith에 대한 정확도를 측정한 결과이다.
■ 첫 번째 배치에서는 Auto-CoT와 Zero-Shot-CoT가 동일한 정확도를 달성했지만, 두 번째 배치에서부터 Auto-CoT가 Manual-CoT와 비슷한 성능을 달성하는 것을 볼 수 있다. 이는 Auto-CoT가 streaming setting에서도 여전히 효과적인 방법임을 보여준다.
