■ 논문에서는 CoT prompting에서 사용되는 단순한 greedy decoding을 대체하기 위한 새로운 디코딩 전략으로 "self-consistency"을 제안한다.
■ self-consistency는 greedy한 reasoning path 하나만 선택하는 대신, 다양하고 풍부한 reasoning paths의 집합을 먼저 샘플링한 다음, 샘플링된 reasoning paths을 marginalizing하여 가장 일관성 있는 answer를 선택한다.
■ 이러한 self-consistency는, 일반적으로 복잡한 추론 문제는 푸는 방법은 여러 가지일 수 있어도 정답은 하나이기 때문에 여러 가지 다른 사고 방식을 허용한다는 intuition이 있다.
[2203.11171] Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Chain-of-thought prompting combined with pre-trained large language models has achieved encouraging results on complex reasoning tasks. In this paper, we propose a new decoding strategy, self-consistency, to replace the naive greedy decoding used in chain-
arxiv.org
1. INTRODUCTION
■ CoT prompting을 통해 언어 모델은 사람이 문제를 해결할 때 사용할 법한 reasoning process를 모방하는 일련의 짧은 문장을 생성하도록 유도된다.
■ 예를 들어, "If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot?"라는 question이 주어졌을 때, 언어 모델은 "5"라고 directly하게 대답하는 대신 chain-of-thought로 대답하도록 유도된다: "There are 3 cars in the parking lot already. 2 more arrive. Now there are 3 + 2 = 5 cars. The answer is 5."
■ 여러 연구들에서 이러한 CoT prompting을 통해 다양한 multi-step reasoning tasks에서 모델 성능을 크게 향상시킬 수 있음을 보여주고 있다.
■ 논문에서는 original CoT prompting에서 사용되는 greedy decoding 대신, 언어 모델의 추론 성능을 더욱 큰 폭으로 향상시키는 "self-consistency"이라는 새로운 디코딩 전략을 제안한다.

■ Fig 1을 보면, CoT prompting으로 언어 모델을 프롬프트한 다음, 최적의 reasoning path 하나를 greedily하게 디코딩하는 대신 "sample-and-marginalize" 디코딩을 진행한다.
■ 이를 위해 먼저 언어 모델의 디코더에서 샘플링을 통해 다양한 reasoning paths의 집합을 생성한다.
■ 이때 각 reasoning path는 서로 다른 final answer로 이어질 수 있으므로, 샘플링된 reasoning paths을 marginalizing out하여 final answer set에서 가장 일관된 정답(consistent answer)을 찾아 최적의 answer로 결정한다.
■ 이러한 접근법은 여러 가지 다른 사고 방식들이 동일한 answer로 이어진다면 final answer이 옳을 가능성이 높다는 직관에 기반한다.
■ 다른 디코딩 방법과 비교할 때, self-consistency는 반복적이고 뻔한 답변을 피하고, 한 번의 실수로 전체가 틀리는 상황을 방지할 수 있는(vs greedy) 동시에, single sampled generation의 우연성(변동성으로 봐도 될 것 같다)을 완화할 수 있다.
- original CoT는 greedy decoding을 사용하여, 매 순간 가장 확률이 높은 단어만 선택해서 딱 하나의 reasoning path만을 따라간다. 이 방식은 모델이 잘못된 길로 들어서면 global optimality을 달성할 수 없다. 즉, local ogptimality 문제를 가진다.
- 한 번만 샘플링하는 방식은 그 확률에 따라 answer가 바뀔 수 있다. self-consistency는 여러 번 샘플링해서 하나의 answer를 찾아가기 때문에 이러한 stochasticity을 완화할 수 있다. robust하다고 볼 수 있다.
■ self-consistency는 generation quality를 향상시키기 위해 verifier를 추가하여 학습시키거나, 추가적인 human annotations을 받아 re-ranker를 학습시키는 이전 접근법들보다 훨씬 간단하다.
■ self-consistency는 전적으로 unsupervised 방식이며, off-the-shelf PLMs을 사용할 수 있고, 추가적인 human annotations을 요구하지 않으며, 어떠한 추가 훈련이나 auxiliary models 또는 fine-tuning이 필요하지 않다.
■ 여러 모델을 학습시킨 다음, 각 모델의 출력을 통합하는 일반적인 앙상블 방식과도 다르며, single LM으로 작동하는 "self-ensemble"과 같이 작동한다.
- 즉, self-consistency는 하나의 모델만 가지고 여러 번 생성해서 결과를 합치는 self-ensemble 방식과 같다.
■ 다양한 규모의 네 가지 언어 모델들(UL2-20B, GPT-3-175B, LaMDA-137B, PaLM-540B)을 사용하여 arithmetic 및 commonsense reasoning tasks에서 self-consistency의 효과를 평가한 결과, 모든 모델에서 self-consistency는 모든 tasks에 걸쳐 CoT prompting보다 꽤 큰 차이로 성능을 향상시킨다.
2. SELF-CONSISTENCY OVER DIVERSE REASONING PATHS
■ 신중한 사고를 요하는 tasks(예: complex reasoning tasks)에는 문제를 공략하는 여러 가지 방법이 있을 가능성이 높다고 가정하는 것이 자연스럽다. 저자들은 이러한 사고 과정이 언어 모델의 디코더에서 샘플링을 함으로써 시뮬레이션될 수 있다고 생각했다.
■ 예를 들어 Fig 1에서 보여지듯이, 모델은 math question에 대해 모두 동일한 정답에 도달하는 몇 가지 그럴듯한 응답을 생성할 수 있다. (Fig 1의 output 1과 3)
■ 단, 언어 모델은 완벽한 reasoners가 아니므로, 부정확한 reasoning path를 생성하거나 reasoning steps 중 하나에서 실수를 범할 수도 있다. (Fig 1의 output 2)
■ 즉, 올바른 reasoning processes들은 다양하더라도 부정확한 reasoning processes보다 final answer에 있어 더 큰 agreement를 보이는 경향이 있다는 가설을 세운다.
- 즉, 논리적으로 타당한 풀이 방법들은 서로 과정이 달라도 결국 같은 정답에 도달한다. 논리적으로 틀린 풀이들은 중간에 실수를 범하게 되는데, 이 실수의 방향성은 제각각이다. 따라서 오답들은 서로 다른 값으로 흩어질 확률이 높다.
- 그러므로 이 가설은, 여러 번 풀어서 가장 많이 나온 답을 고르면, 그게 정답일 확률이 매우 높다는 것이다.
■ 저자들은 이러한 직관을 활용하여 다음과 같은 self-consistency method를 제안한다.
■ 먼저, 언어 모델은 manually written chain-of-thought exemplars의 set으로 프롬프트된다.
■ 다음으로, 언어 모델의 디코더로부터 candidate outputs의 set을 샘플링하여 다양한 candidate reasoning paths의 set을 생성한다.
- 이때 self-consistency은 temperature sampling, top-\( k \) sampling, nucleus sampling을 포함한 대부분의 기존 샘플링 알고리즘과 호환된다.
■ 마지막으로, 샘플링된 reasoning paths을 marginalizing out하고 생성된 answers 중에서 가장 일관성 있는 answer를 선택한다.
■ 더 자세히 설명하면, 생성된 answers \( \mathbf{a}_i \)가 fixed answer set \( \mathbf{a}_i \in \mathbb{A} \)에 속한다고 가정하자. 여기서 \( i = 1, \cdots, m \)은 디코더에서 샘플링된 \( m \)개의 candidate outputs의 인덱스이다.
■ 프롬프트와 question이 주어졌을 때, self-consistency는 \( i \)번째 output의 reasoning path를 나타내는 token sequence인 \( \mathbf{r}_i \)를 도입하여 \( (\mathbf{r_i}, \mathbf{a}_i) \)를 생성한다.
■ 여기서 reasoning path \( \mathbf{r}_i \)를 생성하는 것은 선택 사항이며, \( \mathbf{r}_i \)은 final answer \( \mathbf{a}_i \)에 도달하기 위해서만 사용된다.
■ 예를 들어 Fig 1의 output 3에서, "She eats 3 for breakfast, ... So she has 9 eggs * $2 = $18"이 \( \mathbf{r}_i \)이며, 마지막 문장 "The answer is $18"에서의 18이 \( \mathbf{a}_i \)로 파싱된다.
■ 모델의 디코더에서 여러 개의 \( (\mathbf{r_i}, \mathbf{a}_i) \)를 샘플링한 후, self-consistency는 \( \mathbf{a}_i \)에 대해 다수결 투표(majority vote)를 하여 \( \mathbf{r}_i \)에 대한 marginalization을 적용한다.
■ 즉, \( \arg \max_a \sum_{i=1}^m \mathbb{1}(\mathbf{a}_i = a) \)이며, 이는 final answer set 중에서 가장 "consistent"한 answer로 정의된다.
- \( \arg \max_a \sum_{i=1}^m \mathbb{1}(\mathbf{a}_i = a) \)는 majority voting을 나타낸 것이다.
- \( \mathbb{1}(\mathbf{a}_i = a) \)는 \( i \)번째 생성된 answer \( \mathbf{a}_i \)이 \( a \)와 같으면 1, 다르면 0을 반환한다. 즉, \( i \)번째 데이터(\( \mathbf{a}_i \))가 확인하려는 값 \( a \)와 같으면 1점, 다르면 0점을 부여한다.
- 이는 전체(\( \mathbf{a}_1, \cdots, \mathbf{a}_m \)) 중에서 \( a \)가 몇 번 등장했는지 빈도수를 세는 것이다.
- 이를 통해 생성된 모든 answers 중에서 빈도수가 가장 높은(즉, majority voting에서 최종 승리한) \( a \)를 찾는다.
■ Table 1은 다양한 answer 집계 방법들을 사용하여 reasoning tasks에 대한 test accuracy를 비교한 결과이다.

■ majority vote 외에도, answers을 집계할 때 \( P(\mathbf{r}_i, \mathbf{a}_i \mid \text{prompt}, \text{question}) \) 값을 각 \( (\mathbf{r}_i, \mathbf{a}_i) \)에 가중치로 부여할 수도 있다.
■ \( P(\mathbf{r}_i, \mathbf{a}_i \mid \text{prompt}, \text{question}) \)는, \( (\text{prompt}, \text{question}) \)이 주어졌을 때 모델이 \( (\mathbf{r}_i, \mathbf{a}_i) \)를 생성할 (비정규화된 단순한) 확률로 계산하거나, 출력 길이 \( K \)로 정규화된 조건부 확률(Table 1의 Weighted sum (normalized))로 계산할 수 있다.

- 여기서 \( \log P(t_k \mid \text{prompt}, \text{question}, t_1, \cdots, t_{k-1}) \)은 이전 토큰들이 주어졌을 때 \( (\mathbf{r}_i, \mathbf{a}_i) \)의 \( k \)번째 토큰 \( t_k \)를 생성할 로그 확률이며, \( K \)는 \( (\mathbf{r}_i, \mathbf{a}_i) \)의 총 토큰 수이다.
■ Table 1에서 "unweighted sum", 즉 \( \mathbf{a}_i \)에 대해 majority vote를 하는 것이 식 (1)의 "normalized weighted sum"을 사용하여 answers을 집계하는 것과 매우 유사한 정확도를 달성한 것을 볼 수 있다.
■ 저자들은 "unweighted sum"과 "normalized weighted sum"에 대해 모델의 output probabilities을 확인한 결과, 언어 모델이 생성한 '그럴듯한' 답변들은 확률값도 서로 비슷한 것을 확인하였다.
- "언어 모델이 생성한 '그럴듯한' 답변들은 확률값도 서로 비슷하다"는 것은 언어 모델이 제대로 보정되지 않아 정답과 오답을 잘 구분할 수 없음을 의미하기도 한다.
- 그래서 이전 연구들에서는 정답의 품질을 더 잘 판단하기 위해 추가적으로 re-rankers을 학습시켜 사용하였다.
■ reasoning tasks은 일반적으로 고정된 정답을 가지므로 이전 연구들은 greedy decoding을 사용했다.
■ 그러나 저자들은 정답이 고정되어 있더라도 reasoning processes에 다양성을 도입하는 것이 매우 유익할 수 있음을 발견했다. 그래서 저자들은 open-ended text generation에 흔히 사용되는 샘플링을 활용한다.
3. EXPERIMENTS
3.1 EXPERIMENT SETUP
Tasks and datasets
■ arithmetic reasoning tasks로는 AddSub, MultiArith, ASDiv를 포함한 Math Word Problem Repository와 AQUA-RAT, GSM8K, 그리고 SVAMP를 사용한다.
■ commonsense reasoning은 CommonsenseQA, StrategyQA, AI2 Reasoning Challenge (ARC)를, symbolic reasoning은 last letter concatenation, Coinflip을 사용
Language models and prompts
■ 다양한 규모를 가진 네 가지 transformer-based LM들을 사용한다.
- (1) UL2: 20B 개의 파라미터를 가진 mixture of denoiser (MoD)로 학습된 encoder-decoder model이다. 20B 파라미터만으로 zero-shot SuperGLUE에서 GPT-3와 유사하거나 더 나은 성능을 보여 계산 효율적인 모델이다.
- (2) GPT-3: 175B 파라미터를 가지는 Codex 시리즈의 code-davinci-001과 code-davinci-002를 사용한다.
- (3) LaMDA-137B: web documents, dialog data, Wikipedia의 mixture로 사전학습된 137B decoder-only LM이다.
- (4) PaLM-540B: filtered webpages, books, Wikipedia, news articles, source code, social media conversations로 구성된 780B 토큰의 high quality corpus로 사전학습된 540B decoder-only LM이다.
■ 언어 모델을 training하거나 fine-tuning하지 않고 few-shot setting에서 모든 실험을 수행한다.
■ 그리고 공정한 비교를 위해 original CoT prompting에서 사용한 것과 동일한 프롬프트들을 사용한다: 모든 arithmetic reasoning tasks에 대해 동일한 8개의 manually written exemplars을 사용한다; 각 commonsense reasoning task에서는 manually하게 구성된 chain-of-thought prompts과 함께 training set에서 4-7개의 exemplars를 무작위로 선택해 사용한다.
- full sets of prompts (Appendix A.3)
Sampling scheme
■ 다양한 reasoning paths을 샘플링하기 위해, 이전 연구들에서 open-text generation을 위해 제안된 것과 유사한 설정을 따랐다.
- 구체적으로 UL2-20B와 LaMDA-137B의 경우 \( T = 0.5 \)의 temperature sampling을 적용하고, 가장 확률이 높은 top-\( k \)개(\( k = 40 \)) 토큰에서 잘라냈으며(즉, 확률이 너무 낮은 단어들은 배제),
- PaLM-540B의 경우 \( T = 0.7 \), \( k = 40 \)을, GPT-3의 경우 top-\( k \) truncation 없이 \( T = 0.7 \)을 사용한다.
3.2 MAIN RESULTS
■ 논문에서는, 10회 실행(각 실행마다 디코더로부터 독립적으로 40개의 outputs을 샘플링)에 대한 self-consistency의 평균 결과를 보고한다.
■ self-consistency와 비교하는 베이스라인은 greedy decoding을 사용하는 CoT prompting이다.
Arithmetic Reasoning
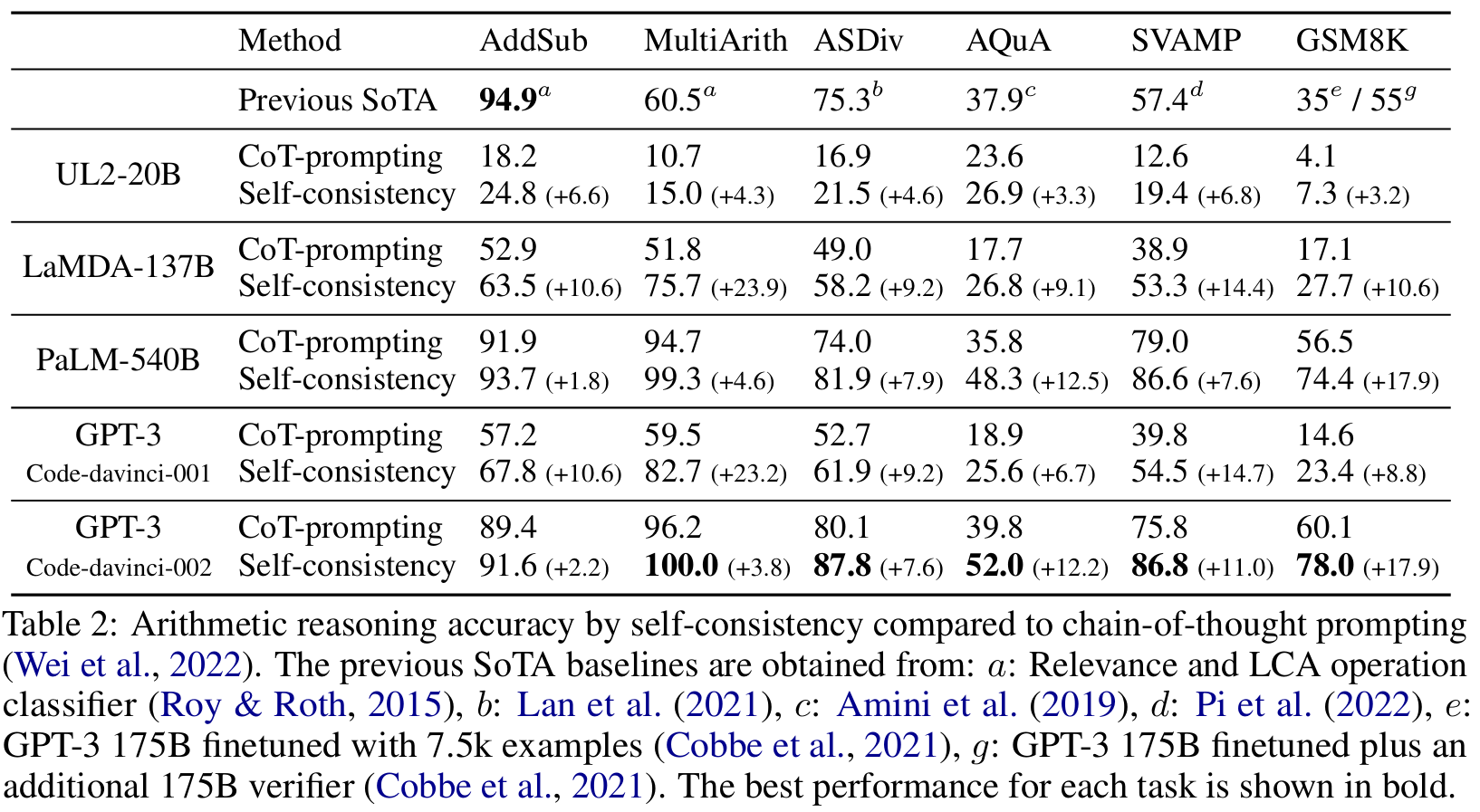
■ self-consistency가 네 가지 언어 모델 모두에서 CoT prompting보다 arithmetic reasoning 성능을 크게 향상시킨 것을 볼 수 있다.
■ 주목할 점은 언어 모델의 크기가 커질수록 성능 향상이 더 커진다는 것이다. 예를 들어 UL2-20B에서는 +3~6%의 향상을 보이지만, LaMDA-137B와 GPT-3에서는 +9~32%의 향상을 보인다.
■ 이미 대부분의 tasks에서 높은 성능을 달성한 더 큰 모델(예: GPT-3 및 PaLM-540B)의 경우에도, self-consistency는 AQuA 및 GSM8K와 같은 task에서 +12~18%, SVAMP 및 ASDiv에서 +7~11%의 성능 향상을 달성하였다.
■ 이러한 큰 폭의 성능 향상 결과는, task-specific training이나 수천 개의 examples로 fine-tuning이 필요한 기존 접근 방식과 비교할 때, unsupervised이며 task-agnostic한 self-consistency가 더 우수한 방식임을 보여준다.
Commonsense and Symbolic Reasoning
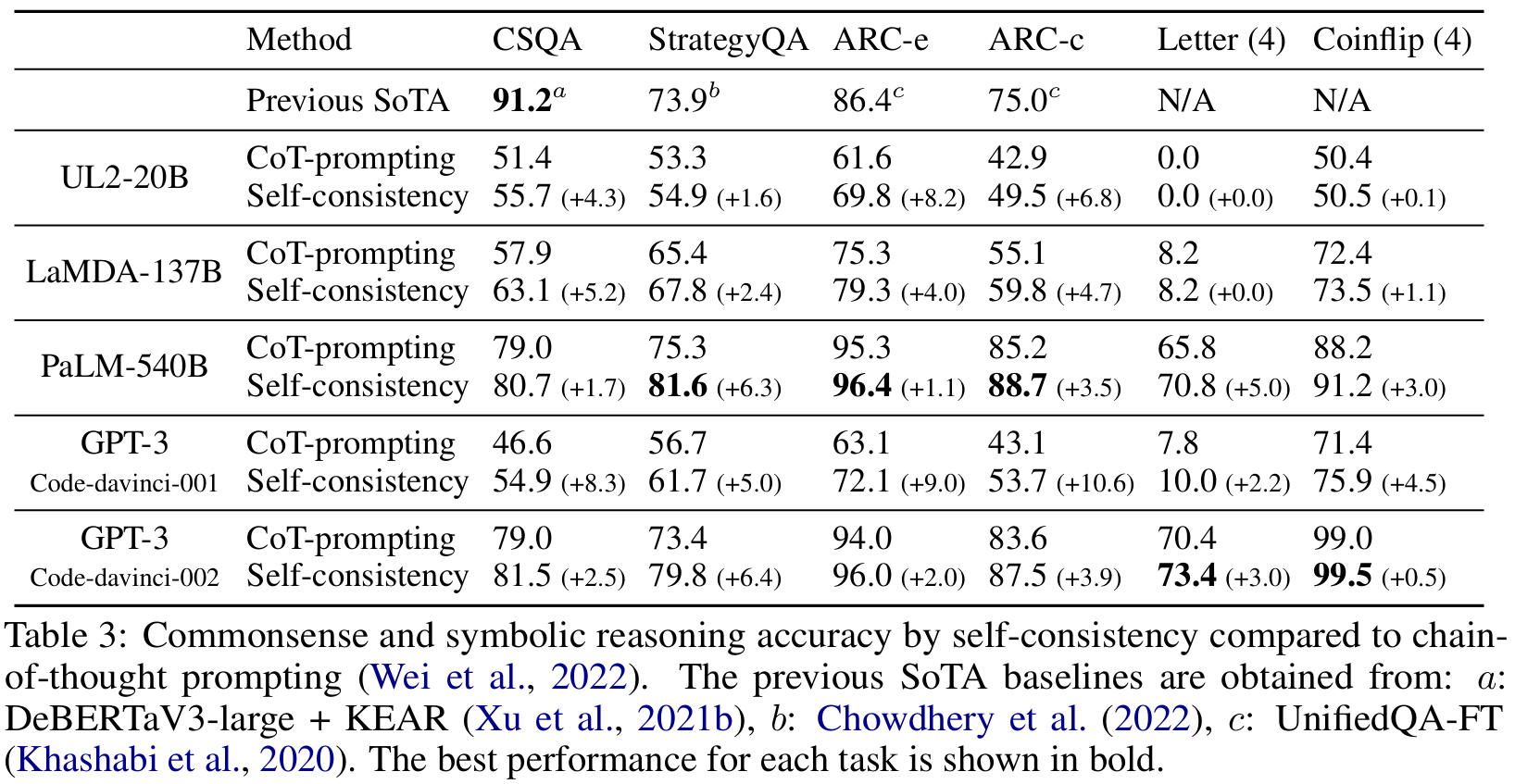
■ arithmetic reasoning에서의 결과와 마찬가지로, self-consistency는 네 가지 언어 모델 모두에서 CoT prompting보다 성능을 크게 끌어올린다.
■ symbolic reasoning의 경우, out-of-distribution (OOD) 평가를 위해 입력 프롬프트에는 2글자, 2번 flip하는 예시만 제시하고, 4글자, 4번 flip하는 경우에 대해 테스트를 진행하였다.
■ 이는 이미 in-distribution 내 높은 성능을 달성한 PaLM-540B나 GPT-3같은 대규모 모델에게도 어려울 수 있다.
■ 2글자나 2번 던지기는 175B, 540B 규모의 모델에게는 쉬운 문제일 수 있다. 그래서 해당 문제들에 대한 분포를 완벽히 학습해 높은 성능을 달성할 가능성이 높다.
■ 따라서 2글자나 2번 던지기보다 더 복잡한 상황인 4글자 4번 던지기(즉, out-of-distribution setting)를 보여주면, 이미 examples을 통해 파악한 분포와 실제 해결해야 할 문제의 분포가 달라지므로, 간단한 문제에 대한 분포만 학습한 모델에게는 훨씬 challenging task가 된다.
■ 그럼에도 불구하고, OOD setting에서도 충분한 모델 크기(Table 3의 PaLM-540B, GPT-3)를 갖춘 경우 CoT-prompting에 비해 더 우수한 성능을 달성한 것을 볼 수 있다.
■ 추가로, 샘플링된 reasoning paths의 개수에 대한 효과를 확인하기 위해, 다양한 sampled paths의 수(1, 5, 10, 20, 40)에 따른 정확도(10회 실행에 대한 평균 및 표준편차)를 측정하였다.
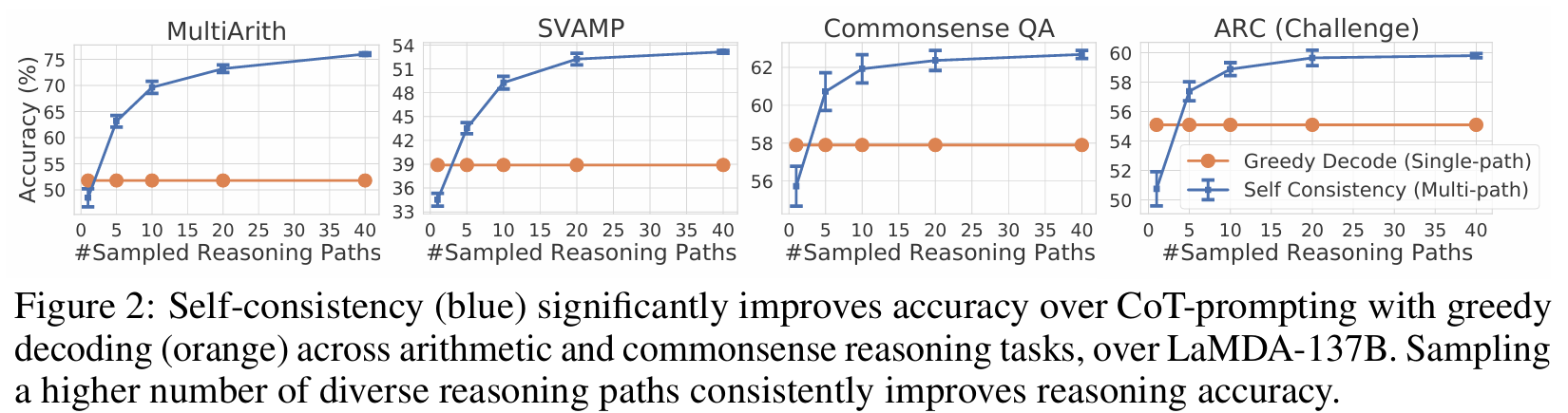
■ Fig 2에서 더 많은 수(예: 40개)의 reasoning paths을 샘플링하는 것이 일관되게 더 나은 성능으로 이어진다는 것을 볼 수 있으며, 이는 reasoning paths에 다양성을 도입하는 것이 성능 향상에 중요하다는 것을 나타낸 결과이다.
■ 아래의 Table 4에서 self-consistency가 greedy decoding에 비해 더 풍부한 reasoning paths을 생성함을 볼 수 있다.

3.3 SELF-CONSISTENCY HELPS WHEN CHAIN-OF-THOUGHT HURTS PERFORMANCE
■ 이전 연구에서는 arithmetic, commonsense, symbolic reasoning에서는 CoT prompting이 few-shot in-context learning에서 standard prompting보다 더 효과적이지만, 다른 유형의 tasks(예: multi-step reasoning을 요구하지 않는 tasks)에서는 오히려 standard prompting에 비해 CoT prompting이 성능을 저하시킬 수 있음을 보여주었다.
■ 저자들은 self-consistency가 이러한 격차를 메우는 데 도움이 될 수 있는지 확인하기 위해, (1) Closed-Book Question Answering: BoolQ, HotpotQA (2) Natural Language Inference: e-SNLI, ANLI, RTE를 포함한 일반적인 NLP tasks에서 그 효과를 검증하였다.

■ Table 5는 PaLM-540B를 사용한 결과이다. 일부 tasks(ANLI-R1, e-SNLI, RTE)의 경우, CoT prompting을 사용하는 것이 standard prompting보다 성능을 저하시키지만, self-consistency는 성능을 향상시키고 standard prompting을 능가한 것을 볼 수 있다.
■ 이러한 결과를 통해, self-consistency는 일반적인 NLP tasks의 few-shot in-context learning에서 rationales를 얻기 위해 신뢰할 수 있는 방법이라고 할 수 있다.
3.4 COMPARE TO OTHER EXISTING APPROACHES
Comparison to Sample-and-Rank

■ generation quality를 향상시키기 위해 일반적으로 사용하는 접근법 중 하나는 "sample-and-rank"이다: 디코더에서 여러 시퀀스를 샘플링한 다음, 각 시퀀스의 로그 확률에 따라 순위를 매긴다.
■ 저자들은 GPT-3 code-davinci-001에서 self-consistency와 동일한 수의 시퀀스를 디코더에서 샘플링하고, 가장 높은 순위의 시퀀스에서 최종 정답을 취하는 방식으로 self-consistency와 sample-and-rank를 비교하였다.
■ Fig 3을 보면, sample-and-rank가 순위 지정을 통해 정확도를 향상시키기는 하지만, 그 성능 향상은 self-consistency에 비해 훨씬 작은 것을 확인할 수 있다.
Comparison to Beam Search

■ UL2-20B 모델에서 self-consistency와 beam search decoding을 비교하였다. 공정한 비교를 위해 동일한 수의 beam과 reasoning path 하에서의 정확도를 측정하였다.
■ Table 6에서 self-consistency가 AQuA와 MultiArith에서 beam search를 크게 능가한 것을 볼 수 있다.
■ self-consistency도 각 reasoning path를 디코딩하기 위해 beam search를 사용할 수 있지만, 그 성능은 샘플링을 사용한 self-consistency에 비해 떨어진다. 그 이유는 beam search도 결국 outputs의 다양성을 낮추기 때문이다. 반면 self-consistency는 reasoning paths의 다양성이 성능의 핵심이다.
Comparison to Ensemble-based Approaches

■ self-consistency와 few-shot learning을 위한 ensemble-based 방법들과 비교하였다. 구체적으로,
- (1) prompt order permutation: 프롬프트 순서에 대한 모델의 민감도를 완화하기 위해, 프롬프트 내의 exemplars을 40번 무작위로 permutation
- (2) multiple sets of prompts: 저자들이 직접 작성한 3개의 서로 다른 prompts의 set을 사용
- 두 방법 모두 앙상블로서 greedy decoding으로 얻은 answers의 majority vote를 적용했다.
■ Table 7에서 self-consistency와 비교했을 때 두 방법이 훨씬 작은 수준의 개선만을 제공한다는 점을 알 수 있다.
■ self-consistency는 앞서 언급했듯 여러 모델을 따로 훈련한 뒤 outputs을 결합하는 전통적인 model ensemble 방식이 아닌, 하나의 모델이 생성한 다양한 reasoning paths을 활용하는 일종의 "self-ensemble"로 기능한다.
3.5 ADDITIONAL STUDIES
Self-Consistency is Robust to Sampling Strategies and Scaling
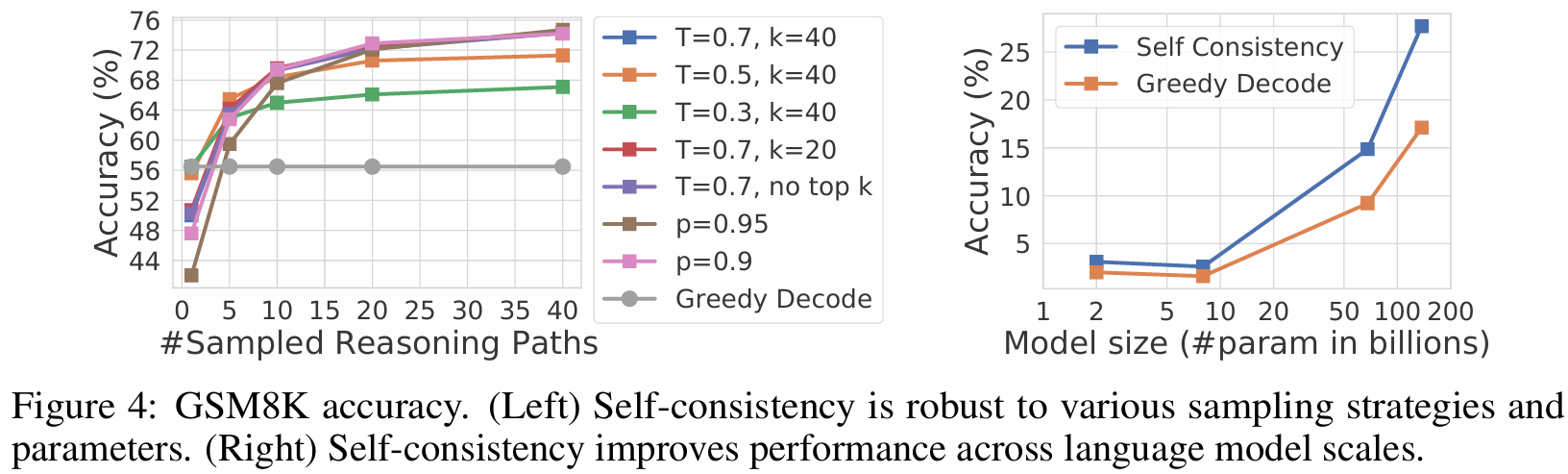
■ PaLM-540B에서 temperature sampling의 \( T \), top-\( k \) sampling의 \( k \), nucleus sampling의 \( p \)를 변화시키는 방식으로, self-consistency의 sampling strategies 및 parameters에 대한 robustness를 확인하였다.
■ Fig 4의 left를 보면, sampling strategies 간의 성능에 큰 변동이 없는 것을 확인할 수 있다.
■ 또한, Fig 4의 right에서 self-consistency가 LaMDA 모델 시리즈의 모든 규모에 걸쳐 성능을 견고하게 향상시킴을 볼 수 있다.
■ 단, 언어 모델의 특정 능력(예: arithmetic)은 모델이 충분히 큰 규모에 도달했을 때만 나타나기 때문에(LLM의 emergent ability) 더 작은 모델에 대한 성능은 상대적으로 낮다.
Self-Consistency Improves Robustness to Imperfect Prompts
■ manually 구성된 prompts 사용한 few-shot learning의 경우, human annotators은 prompts을 생성할 때 실수를 저지를 수 있다.
■ 저자들은 self-consistency이 이러한 불완전한 prompts에 대해서도 성능을 향상시키는 데 도움이 될 수 있는지 확인하였다.
■ Table 8을 보면, 불완전한 prompts은 greedy decoding에서 정확도를 감소시키지만(17.1 \( \rightarrow \) 14.9),
self-consistency는 다양한 reasoning paths과 majority voting을 통해 그 공백을 메우고 성능을 향상시킬 수 있다.

■ 또한, Fig 5(Fig 5는 GSM8K에서 측정한 결과)에서 consistency가 정확도와 높은 상관관계를 갖는다는 것을 볼 수 있다.
- 여기서 consistency는 final answer와 일치하는 디코딩의 비율)

■ 이는 생성된 솔루션에 대한 모델의 불확실성 추정치를 계산하기 위해 self-consistency를 사용할 수 있음을 시사한다. 즉, 낮은 consistency는 모델의 신뢰도가 낮다는 지표로 사용할 수 있다.
Scaling Self-Consistency Works for Non-Natural-Language Reasoning Paths and Zero-shot CoT
■ 저자들은 방정식과 같은 형태의 intermediate reasoning에 대해 self-consistency의 generality을 테스트하였다.
- 예를 들어 "There are 3 cars in the parking lot already. 2 more arrive. Now there are 3 + 2 =5cars." 대신 방정식으로 구성된 "3+2=5"를 사용해서, 자연어로 설명하지 않고 수식만 써도 self-consistency가 잘 작동하는지 테스트한 것이다.
■ 결과는 Table 8의 Prompt with equations에서 볼 수 있다. self-consistency은 이러한 상황에 대해서도 정확도를 향상시킨다.
■ 그러나 natural language reasoning paths을 생성하는 것과 비교했을 때, natural language가 없는 equations은 훨씬 짧고 디코딩 과정에서 다양성을 생성할 기회가 적기 때문에 그 효과가 제한적이다.
■ 또한, Zero-shot CoT("Let's think step by step")로 self-consistency를 테스트했으며, self-consistency이 Zero-shot CoT에서도 잘 작동하며 성능을 크게 향상시킨다는 것(+26.2%)을 볼 수 있다.
5. CONCLUSION AND DISCUSSION
■ self-consistency은 기본적으로 (1) arithmetic 및 commonsense reasoning tasks에서의 성능을 크게 향상시키며 (2) 언어 모델로 reasoning tasks을 수행할 때 rationales를 수집하는 데 유용하며 (3) 언어 모델의 출력 보정에도 유용하며, 언어 모델의 불확실성 추정치를 제공할 수 있다.
■ 단, 한 가지 한계점은 더 많은 계산 비용을 초래한다는 것이다. 실제로는 대부분의 경우 성능이 빠르게 포화(Fig 2)되기 때문에, 너무 많은 비용을 들이지 않으면서도 40개를 샘플링했을 때와 거의 동일한 성능을 확보할 수 있으므로, 적은 수의 paths(예: 5개 또는 10개)를 시작점으로 시도해 볼 수 있다.
'자연어처리 > Reasoning' 카테고리의 다른 글
| Large Language Models Cannot Self-Correct Reasoning Yet (0) | 2025.12.18 |
|---|---|
| Self-Refine: Iterative Refinement with Self-Feedback (0) | 2025.12.11 |
| AutoCoT: Automatic Chain of Thought Prompting in Large Language Models (0) | 2025.12.10 |
| Zero-shot CoT: Large Language Models are Zero-Shot Reasoners (1) | 2025.12.08 |
| Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (0) | 2025.12.04 |
