■ 단계별 answer examples을 통해 복잡한 multi-step reasoning의 성능 향상을 이끌어낸 CoT prompting은, LLM의 standard scaling laws을 따르지 않는 어려운 task인(즉, LLM의 모델 크기만으로 해결하기 어려운) arithmetics 및 symbolic reasoning에서 SOTA를 달성하였다.
■ 단, CoT prompting은 few-shot 방식이다. 그래서 CoT prompting을 하기 위해선 사람이 직접 chain of thought을 작성했어야 했다.
■ 논문에서는 단순히 각 answer 앞에 "Let’s think step by step"라는 문구를 추가함으로써, 복잡한 few-shot examples을 하나도 주지 않아도(즉, zero-shot setting에서도), task types에 상관없이 모델이 그럴듯한 reasoning steps을 생성할 수 있음을 보여준다.
■ 이렇게 examples에 대한 수작업 없이도 동일한 하나의 프롬프트 템플릿을 사용하여, arithmetics 및 symbolic reasoning 그리고 다른 logical reasoning tasks을 포함한 다양한 reasoning tasks에서 zero-shot LLM의 성능을 크게 능가하였다.
[2205.11916] Large Language Models are Zero-Shot Reasoners
Large Language Models are Zero-Shot Reasoners
Pretrained large language models (LLMs) are widely used in many sub-fields of natural language processing (NLP) and generally known as excellent few-shot learners with task-specific exemplars. Notably, chain of thought (CoT) prompting, a recent technique f
arxiv.org
1. Introduction
■ 단순히 몇 가지 examples (few-shot)이나 task를 설명하는 instructions (zero-shot)을 LLM에 조건부로 제공하여 다양한 NLP tasks을 해결할 수 있다.
■ 언어 모델을 조건화하는 이런 방법을 "프롬프팅(prompting)"이라고 부르며, 프롬프트를 수동으로 또는 자동으로 설계하는 연구도 활발히 이뤄지고 있다.
■ task-specific zero-/few-shot prompting을 사용했을 때, single-step task에서 LLM이 보여준 뛰어난 성능과는 달리, multi-step reasoning이 필요한 task는 100B 규모 이상의 LLM에게조차 여전히 어려운 문제로 남아 있다.
■ 이러한 문제를 해결하기 위해 제안된 CoT prompting은 step-by-step reasoning examples을 LLM에게 보여줘서, 모델이 복잡한 추론을 여러 개의 더 쉬운 단계들로 분해하는 reasoning path를 생성하도록 유도하였다.
■ 주목할 점은, CoT를 사용하면 LLM의 추론 성능이 scaling laws을 더 잘 따르게 되며 LM의 크기가 커짐에 따라 성능이 급격히 향상된다는 것이다.
■ CoT prompting이나 다른 task-specific prompting 연구들의 성공은 주로 LLM의 few-shot 학습 능력 덕분으로 여겨지지만, 논문에서는 "Let’s think step by step"라는 간단한 프롬프트를 추가하여 단계적 사고 과정을 촉진시켜 LLM이 뛰어난 zero-shot reasoners가 될 수 있음을 보여준다.
■ 이런 단순함에도 불구하고, Zero-shot CoT는 zero-shot 방식으로 그럴듯한 reasoning path를 성공적으로 생성하며, standard zero-shot이 실패하는 문제에서 정답에 도달한다.
■ 중요한 점은, examples (few-shot)이나 templates (zero-shot) 형태의 기존의 task-specific prompt engineering과 달리, Zero-shot CoT는 task-agnostic하다는 것이다.
- Few-shot CoT에서는 예를 들어 수학 문제를 풀려면 수학 문제에 대한 examples을, 상식 문제를 풀려면 상식 문제에 대한 examples을 사람이 직접 작성하여 넣어줘야 했다. 이는 task-specific하며 번거롭다.
- 그러나 Zero-shot CoT는 task마다 task-specific prompt를 만들지 않아도, 다양한 reasoning tasks에 걸쳐 step-by-step으로 answer를 생성할 수 있다.

2. Background
Large language models and prompting
■ LM은 텍스트에 대한 확률분포를 추정하는 모델이다. 수백만 개에서 수억 개, 수천억 개에 이르는 파라미터와 더 큰 데이터를 통한 scaling은 pre-trained LLM들이 많은 downstream NLP tasks에서 뛰어난 성능을 보여주었다.
■ 그리고 "pre-train and fine-tune" 패러다임 외에도, 100B 이상의 파라미터로 확장된 LM들은 in-context learning이 few-shot의 성능 향상에 기여할 수 있음을 보여주었다.
■ 여기서 사용자는 "프롬프트"라고 불리는 텍스트나 템플릿을 사용하여 원하는 task에 대한 answer를 출력하도록 생성 과정을 유도할 수 있게 되었고, 이러한 방식은 기존의 "pre-train and fine-tune"에서 "pre-train and prompt"로의 패러다임 전환으로 이어졌다.
■ 논문에서는 몇 개의 task examples을 명시적으로 조건화하는 프롬프트를 few-shot prompt, 템플릿만 있는 프롬프트를 zero-shot prompt라고 부른다.
Chain of thought prompting
■ 모델 크기카 커지면 대부분의 언어 능력은 좋아지지만, multi-step reasoning benchmarks에서는 단순히 모델의 크기만 키운다고 해결되지 않았다.
■ few-shot prompting의 일종인 CoT prompting은 few-shot examples 내의 answer를 step-by-step answer로 수정하는 간단한 방법으로, PaLM과 같은 very large LM과 결합될 때 이러한 어려운 benchmarks에 걸쳐 상당한 성능 향상을 달성했다.
■ 단, 기존 CoT 연구에서는 어려운 tasks를 해결하기 위해 few examples을 제공하는 것이 당연하게 여겨졌고, zero-shot 성능은 아예 평가 대상에서 제외되었다.
■ 논문에서는 original CoT와 Zero-shot CoT와 구별하기 위해, original CoT를 Few-shot CoT라고 부른다.
3. Zero-shot Chain of Thought
■ 논문에서 제안하는 zero-shot template-based prompting인 Zero-shot CoT는, step-by-step few-shot examples 요구하지 않는다는 점에서 original CoT prompting과 다르며, task-agnostic한 single template으로 광범위한 tasks에 걸쳐 multi-hop reasoning을 이끌어낸다는 점에서 대부분의 이전 template prompting 연구들과 다르다.
■ Zero-shot CoT의 핵심 아이디어는 Fig 1에 묘사된 바와 같이 간단하다. step-by-step reasoning을 추출하기 위해 "Let’s think step by step" 또는 그와 유사한 텍스트(Table 4)를 추가하는 것이다.
3.1 Two-stage prompting
■ Zero-shot CoT는 개념적으로 간단하지만, Fig 2에 설명된 바와 같이 추론과 정답을 모두 추출하기 위해 프롬프팅을 두 번 사용한다.
■ Zero-shot CoT와 대조적으로 standard zero-shot은 정답을 추출하기 위해 "The answer is"와 같은 형식의 정답 추출 프롬프팅을 사용하고 있다. (Fig 1)
■ standard 또는 CoT 방식의 few-shot prompting은 few-shot examples의 답변이 그러한 형식으로 끝나도록 명시적으로 설계함으로서 이러한 정답 추출 프롬프팅의 필요성을 피한다. (Fig 1)
■ Few-shot CoT는 task별로 특정한 답변 형식을 갖춘 few prompt examples를 준비해야 하므로 사람의 신중한 엔지니어링이 요구된다. 반면 Zero-shot CoT는 이러한 엔지니어링 부담은 적지만, LLM을 두 번 프롬프팅해야 한다.

1st prompt: reasoning extraction
■ 이 단계에서 먼저 간단한 템플릿 "Q: \( x \). A: \( t \)"를 사용하여 input question \( x \)를 prompt \( x' \)로 수정한다. 여기서 \( t \)는 \( x \)에 답하기 위한 CoT를 추출하는 (hand-crafted) trigger sentence이다.
■ 예를 들어 "Let's think step by step"을 trigger sentence로 사용한다면, prompt \( x' \)는 "Q: \( x \). A: Let's think step by step" 이 된다. (이런 trigger sentence에 대한 더 많은 예시는 Table 4)

■ 이러한 \( x' \)는 LM에 입력되어 subsequent sentence \( z \)를 생성한다.
■ \( z \)를 생성하기 위해 다양한 디코딩 전략이 사용될 수 있지만, 저자들은 단순함을 위해 greedy decoding을 사용하였다.
2nd prompt: answer extraction
■ 두 번째 단계에서는 LM으로부터 최종 정답을 추출하기 위해, 생성된 문장 \( z \)를 prompt \( x' \)와 함께 사용한다.
■ 구체적으로, "\( x' \; z \; a \)"와 같이 세 가지 요소를 단순히 연결한다. 여기서 \( a \)는 정답을 추출하기 위한 trigger sentence이다.
■ 이 단계에서의 프롬프트는 동일한 언어 모델에 의해 1단계에서 생성된 문장 \( z \)를 포함하고 있으므로 self-augmented(즉, "네가 방금 이렇게 생각했잖아, 그러니까 결론이 뭐야?"라고 묻는 것)이다.
■ 논문의 실험에서는 정답 형식에 따라 약간 다른 answer trigger \( a \)를 사용한다.
■ 예를 들어, multi-choice QA에서는 "Therefore, among A through E, the answer is"를 사용하고, 숫자 값이 정답인 math problem에서는 "Therefore, the answer (arabic numerals) is"를 사용한다.
- answer trigger에 대한 더 많은 예시는 Appendix A.5
■ 마지막으로, LM은 \( x' \)를 입력으로 받아 sentences \( \hat{y} \)를 생성하고 최종 정답을 파싱한다. (섹션 4)
4. Experiment
Tasks and datasets
■ reasoning tasks의 네 가지 범주(arithmetic, commonsense, symbolic, 그리고 기타 logical reasoning tasks)에 속하는 12개 datasets에 대해 Zero-shot CoT의 효과를 평가한다.
■ arithmetic reasoning에서는 6가지 datasets을 고려한다: (1) SingleEq (2) AddSub (3) MultiArith (4) AQUA-RAT (5) GSM8K (6) SVAMP
- 여기서 (1)과 (2)는 다단계 계산을 필요로 하지 않는 쉬운 문제들이 포함되어 있다. 나머지 4개의 task들은 다단계 추론을 요구하는 challenging datasets이다.
■ commonsense reasoning의 경우 CommonsenseQA와 StrategyQA를 사용한다.
■ CommonsenseQA는 사전 지식에 기반한 추론을 요구하는 복잡한 semantics을 가진 question들이 포함되어 있다. StrategyQA는 question에 답하기 위해 implicit한 multi-hop reasoning이 요구된다.
■ symbolic reasoning의 경우 original CoT에서 수행한 Last Letter Concatenation과 Coin Flip을 수행한다.
■ Last Letter Concatenation의 경우 각 샘플당 무작위로 선택된 4개의 이름을 사용하고, Coin Flip에서는 4번의 flip 또는 not flip 시도로 구성된 샘플을 사용한다.
■ Last Letter Concatenation과 Coin Flip은 사람에게는 쉬운 task이지만, LM은 일반적으로 평평한 스케일링 곡선(즉, 모델 크기가 커져도 해당 task에서 성능이 잘 안 오름)을 보인다.
■ other logical reasoning tasks의 경우, BIG-bench의 두 가지 evaluation sets을 사용한다: Date Understanding과 Tracking Shuffled Objects
Models
■ 주요 실험에서는 instruct-GPT3 (text-ada/babbage/curie/davinci-001 and text-davinci-002), original GPT-3 (ada, babbage, curie, and davinc), 그리고 PaLM(8B, 62B, 540B)을 사용한다.
■ 추가적으로, 모델 스케일링 연구를 위해 GPT-2, GPT-Neo, GPT-J, T0, OPT를 사용한다.
Baselines
■ chain of thought reasoning의 효과를 검증하기 위해 Zero-shot CoT를 standard zero-shot prompting과 비교한다. zero-shot 실험을 위해, Zero-shot CoT와 유사한 정답 유도 프롬프트가 기본으로 사용된다. (결과는 Table 1, 사용된 프롬프트에 대한 details은 Appendix A.5 Table 9, 10)
■ reasoning tasks에서 LLM의 zero-shot 능력을 더 잘 평가하기 위해, original CoT의 few-shot 및 Few-shot CoT 베이스라인과도 비교하며, 이때 동일한 in-context examples을 사용한다.
■ 모든 실험에서 모든 방법에 대해 greedy decoding을 사용한다.
Answer cleansing
■ Zero-shot CoT의 2단계에서 정답을 추출하는 방법은, 모델이 정답 추출 단계를 통해 텍스트를 출력하면, 정답 형식을 만족하는 텍스트의 첫 번째 부분만을 잡아내는 것이다.
■ 예를 들어, arithmetic tasks에서 정답 프롬프팅이 "probably 375 and 376"을 출력한다면, 첫 번째 숫자인 "375"를 추출하여 모델 예측값으로 사용한다 (Fig 2). multiple-choice의 경우, 처음 마주치는 대문자를 예측값으로 사용한다. standard zero-shot도 동일한 방법을 따르게 하였다.
4.1 Results
Zero-shot-CoT vs. Zero-shot
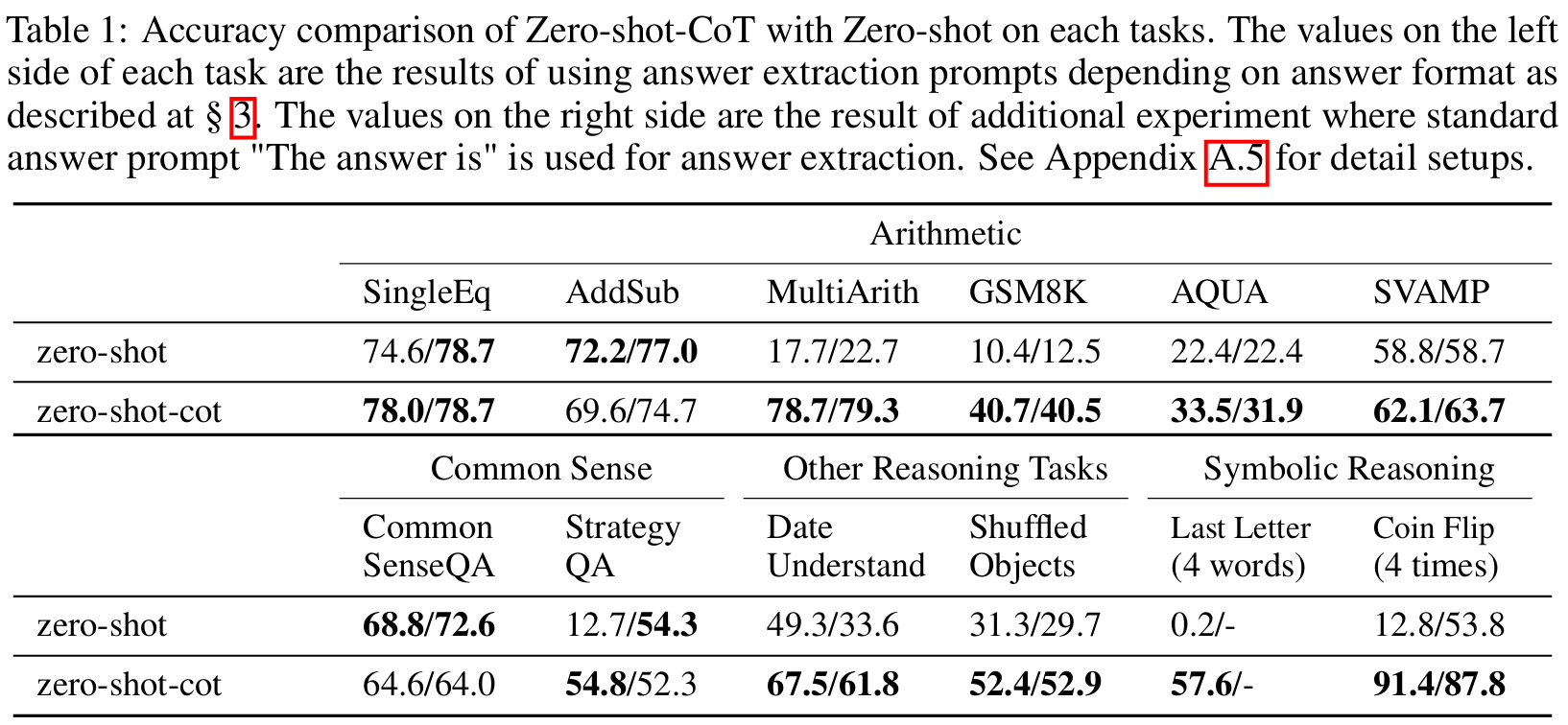
■ Zero-shot CoT는 6개의 arithmetic reasoning tasks 중 4개, 모든 symbolic reasoning, 그리고 모든 logical reasoning tasks에서 standard zero-shot의 성능을 상당히 능가한다.
■ 예를 들어, MultiArith에서 standard zero-shot의 정확도는 17.7%지만, Zero-shot CoT는 78.7%를 달성하였다. GSM8K에서도 10.4%에서 40.7%로 성능이 향상된 것을 볼 수 있다.
■ 그리고 SingleEq와 AddSub에서는 Zero-shot CoT와 standard zero-shot이 대등한 성능을 보여주는데, 이는 해당 task들이 다단계 추론을 필요로 하지 않기 때문에 예상된 결과이다.
■ commonsense reasoning tasks에서 Zero-shot CoT가 standard zero-shot보다 낮은 성능을 보인다. original CoT의 Few-shot CoT조차 135B LaMDA에서 성능 향상을 달성하지 못했다.
- 다만, Few-shot CoT는 훨씬 더 큰 540B 모델과 결합될 때 StrategyQA 성능을 향상시켰다. 이는 Zero-shot CoT에도 적용될 수 있다.
■ 저자들은 CommonsenseQA에서 Zero-shot CoT가 생성한 결과들을 분석했을 때, 모델이 생성한 많은 chain of thought가 매우 논리적이라는 것을 확인하였다. 비록 이런 논리적인 추론 과정 자체는 지표(정확도)에 직접적으로 반영되지는 않지만, 이는 Zero-shot CoT가 더 나은 commonsense reasoning을 이끌어낸다는 것을 시사한다.

Comparison with other baselines

■ Table 2는 arithmetic reasoning benchmarks에서 다른 베이스라인들의 성능들을 비교한 결과이다.
■ standard prompting (첫 번째 블록)과 CoT prompting (두 번째 블록) 사이의 큰 격차는 다단계 추론을 이끌어내지 않고서는 해당 task들을 해결하기 어렵다는 것을 시사한다.
■ 그리고 Zero-shot CoT는 Few-shot CoT보다 성능이 낮지만, task당 8개의 examples를 사용한 few-shot prompting보다는 상당히 우수한 성능을 보인다.
Does model size matter for zero-shot reasoning?
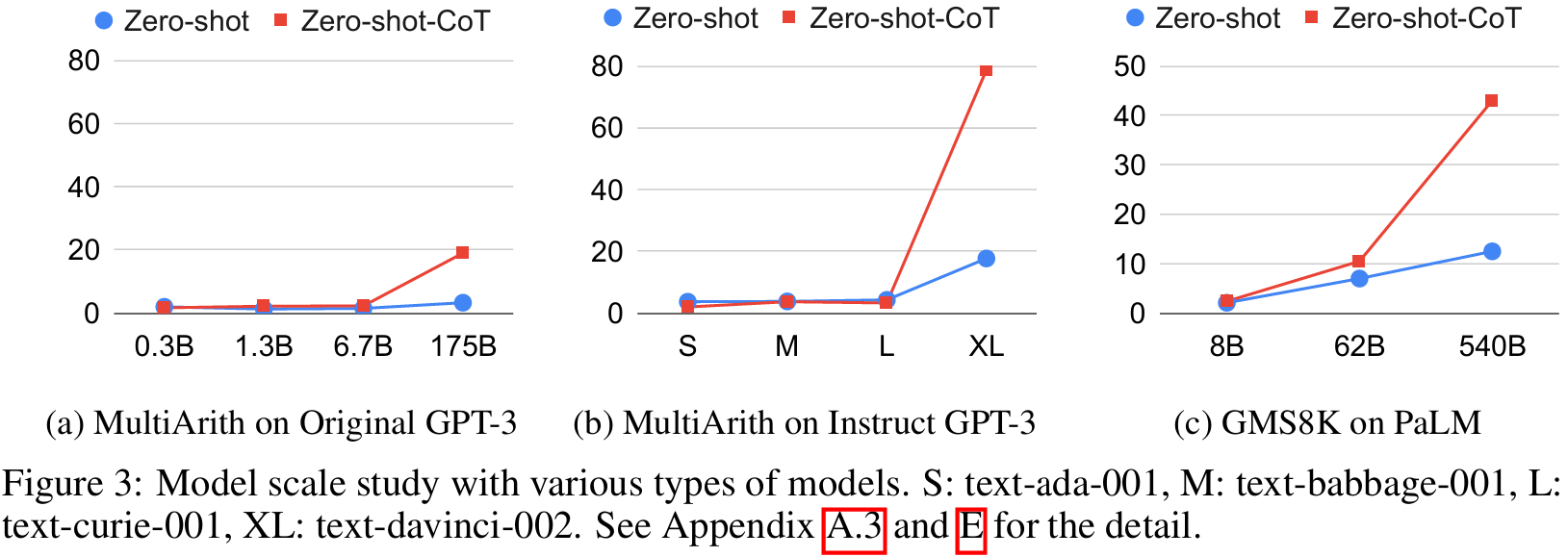
■ Fig 3에서 chain of thought reasoning 없이는 모델 크기가 커져도 성능이 증가하지 않거나 천천히 증가하는 것을 볼 수 있다. 즉, 스케일링 곡선이 대부분 평평하다.
■ 대조적으로, original/Instruct GPT-3와 PaLM의 경우 모델 크기가 작을 때는 chain of thought reasoning이 효과적이지 않지만, 모델 크기가 커짐에 따라 chain of thought reasoning을 사용했을 때 성능이 급격하게 증가하는 것을 볼 수 있다.
■ 이러한 Fig 3의 결과는 original CoT의 few-shot 실험 결과와 일치한다.
Error Analysis
■ Instruct-GPT3가 Zero-shot-CoT prompting으로 생성한 예시들을 무작위로 선택하여 조사하였다. (Appendix C)
■ 관찰 결과, (1) commonsense reasoning(CommonsenseQA)에서 Zero-shot CoT는 최종 예측이 틀리는 경우에서도 종종 유연하고 합리적인 chain of thought를 생성한다. 그리고 정답을 하나로 좁히기 어렵다고 느낄 때, 여러 개의 정답 선택지를 출력한다. (예: Table 3의 Example 2의 최종 예측)
■ (2) arithmetic reasoning(MultiArith)에서 Zero-shot CoT와 Few-shot CoT는 오류 패턴에서 상당한 차이를 보인다.
- (1) Zero-shot CoT는 올바른 예측을 얻은 후에도 불필요한 추론 단계를 출력하여, 결과적으로 정답을 오답으로 바꾼는 경향이 있다.
- (2) Zero-shot CoT는 때때로 추론을 시작하지 않고 단순히 입력 질문을 바꿔 말하기만 한다.
- (3) Few-shot CoT는 생성된 chain of thought가 3항 연산(예: (3+2) x 4)을 포함할 때 실패하는 경향이 있다.
How does prompt selection affect Zero-shot-CoT?

■ 입력 프롬프트에 대한 Zero-shot-CoT의 robustness를 검증하였다. Table 4는 세 가지 범주를 가진 16개의 서로 다른 템플릿을 사용한 성능을 요약한 것이다.
- 범주에는 instructive(추론을 잘 이끌어냄), misleading(추론을 저해하거나 잘못된 방식으로 이끌어냄), irrelevant(추론과 관련 없음)이 포함되어 있다.
■ Table 4를 보면, chain of thought reasoning을 instructive하는 방식으로 작성된 경우, 즉 템플릿이 "instructive" 범주 내에 있을 때 성능이 향상되는 것을 확인할 수 있다. 그러나 문장에 따라 정확도 차이가 꽤 상당하다.
■ 저자들의 실험에서는 "Let's think step by step."이 가장 좋은 성능을 달성했음을 볼 수 있다.
■ 실험을 통해, 서로 다른 템플릿이 모델이 추론을 표현하는 방식을 상당히 다르게 유도한다는 것을 발견(Appendix B)하였다. 즉, Zero-shot CoT를 위해 더 나은 템플릿을 만드는 방법은 open question이다.
How does prompt selection affect Few-shot-CoT?

■ Table 5의 두 번째 Few-shot CoT는 서로 다른 데이터셋의 examples을 사용할 때 Few-shot CoT의 성능을 나타낸 것이다: CommonsenseQA examples을 AQUA-RAT에 적용한 경우와, CommonsenseQA examples을 MultiArith에 적용했을 때의 성능
■ 두 경우 모두 도메인은 다르지만, CommonsenseQA와 AQUA-RAT은 정답 형식이 multiple-choice로 동일하다.
■ Table 5를 보면, 서로 다른 도메인(common sense에서 arithmetic로)이라도 정답 형식이 동일(multiple-choice)한 chain of thought examples은 zero-shot 대비 상당한 성능 향상을 제공하며(22.4 \( \rightarrow \) 31.9), 동일한 task의 examples을 사용한 Few-shot CoT와 비교했을 때에도 성능 차이가 크지 않음을 볼 수 있다. (31.9 vs 39.0)
■ 대조적으로, 정답 유형이 다른 examples을 사용할 경우(MultiArith로 적용, common sense는 객관식인데 arithmetic은 주관식), 동일한 task의 examples을 사용한 Few-shot CoT와 비교하면 성능 격차 매우 크게 나타난다. (27.0 vs 88.2)
■ 이러한 결과는 LLM이 in-context에서 task 자체보다는 주로 반복되는 형식을 추론하기 위해 few-shot examples을 활용한다는 것을 시사한다.
- 모델에게 수학 문제를 풀게 하면서 뜬금없이 상식 문제 풀이 예시를 보여줬을 때, 직관적으로는 상식 문제 풀이 예시가 수학 문제 해결에 아무 도움이 안 되어야 정상이다. 그러나 정답 형식(객관식)이 같은 경우, 엉뚱한 예시를 줘도 성능이 오른 것이다.
- 이는 LLM이 예시에서 수학적인 "논리"를 배우는 게 아니라, 정답 형식을 학습한다(객관식에서는 선택지 중 하나를 선택하기)는 것을 의미한다.
■ 두 경우 모두 결과는 Zero-shot CoT보다 나쁘며, 이는 Few-shot CoT에서 task에 특화된 샘플 엔지니어링의 중요성을 확인시켜 준다.
- 즉, Few-shot CoT으로 성공하려면 해당 task와 정답 형식, 도메인이 딱 맞는 맞춤형 샘플을 만들어서 사용해야 한다.
