■ mathematical reasoning tasks을 위해 LM을 효과적으로 학습시키려면 고품질의 supervised fine-tuning data가 필요하다. human experts로부터 annotation을 얻는 방법 외에도, 흔히 사용되는 대안은 더 크고 강력한 LM으로부터 샘플링하는 것이다.
■ 그러나 이러한 knowledge distillation 접근법은 비용이 많이 들고 불안정할 수 있다. 특히 GPT-4와 같은 closed-source, proprietary LM에 의존할 때 그렇다. 이런 모델들의 행동은 종종 예측하기 어렵기 때문이다.
■ 논문에서는 small-scale LM의 추론 능력이 self-training을 통해 향상될 수 있음을 보여준다. 또한 기존의 self-training이 선호도 학습 알고리즘인 DPO를 통해 더욱 강화될 수 있음을 보여준다.
■ DPO를 self-training에 통합함으로써, 저자들은 preference data를 활용해 언어 모델이 더 정확하고 다양한 chain-of-thought reasoning을 하도록 유도한다.
[2407.18248] Self-Training with Direct Preference Optimization Improves Chain-of-Thought Reasoning
Self-Training with Direct Preference Optimization Improves Chain-of-Thought Reasoning
Effective training of language models (LMs) for mathematical reasoning tasks demands high-quality supervised fine-tuning data. Besides obtaining annotations from human experts, a common alternative is sampling from larger and more powerful LMs. However, th
arxiv.org
1. Introduction
■ 최근의 연구들은 chain-of-thought prompting, continual pretraining (Azerbayev et al., 2024), 그리고 외부의 verifiers 추가를 포함한 다양한 방법을 통해 large-scale LM의 reasoning abilities을 강화하는 데 초점을 맞추어 왔다.
■ 그러나 더 작은 크기의 LM의 추론 능력을 어떻게 향상시킬 것인가에 대한 연구 질문은 상대적으로 충분히 탐구되지 않았다.
■ 최근 연구들은 작은 언어 모델의 추론 능력이 Codex, PaLM, GPT-4와 같은 더 크고 발전된 언어 모델의 출력으로부터 학습함으로써 크게 향상될 수 있음을 보여주었다. 단, 이 방법은 구현하기는 간단하지만, 관련 비용은 상당할 수 있다.
■ large LM을 사용하는 경우, floating-point operations (FLOPs)로 측정되는 계산 요구량은 상당히 증가한다. 또한 데이터 annotation을 위해 proprietary large LM에 의존하는 것은 높은 비용을 발생시킬 뿐만 아니라, 지속 가능성과 확장 가능성에 대한 문제도 있다.
■ 예를 들어 Large Language Models Are Reasoning Teachers에서는 large LM을 annotator로 사용하면 smaller LM의 성능을 크게 향상시킬 수 있지만, costs와 performance gains 사이에 명확한 trade-off가 생긴다고 지적했다.
■ 또 다른 연구 흐름은 self-improvement 방법을 통한 성능 향상이다. 이러한 방법들은 larger model의 출력을 사용하는 방식에서 벗어나, 언어 모델이 자신이 생성한 데이터로부터 학습하도록 한다.
■ 이러한 self-improvement techniques의 효과는 분명하지만, 그 성공은 base model이 본래 가지고 있는 능력에 크게 의존한다.
■ 예를 들어 Star에서는 large LM에서 주로 나타나는 emergent ability인 rationales 생성을 위해, 6B 파라미터를 가진 비교적 큰 LM인 GPT-J에 few-shot prompting을 적용하여 rationale을 생성하게 함으로써 self-improvement를 수행했다.
■ 그러나 small-scale LM에서도 이러한 self-improvement로부터 어느 정도 gain을 얻을 수 있을지는 여전히 불확실하다.
■ 이 연구에서 저자들은 DPO를 통합하여 기존의 self-training framework를 개선한 새로운 방법을 제안한다.
■ 이 통합은 특히 chain-of-thought reasoning 안에서의 성능 향상을 목표로 하며, 그중에서도 mathematical reasoning에 초점을 둔다.
■ mathematical solutions이 가진 명확한 특성은 모델 출력값에 대한 검증을 쉽게 만들고(예: 정답이 10인데 모델이 5를 출력했으면 틀렸다고 판단할 수 있음), 그 결과 DPO를 위한 preference dataset 구축을 매우 용이하게 한다.
■ 실험 결과는 이 방법이 LM의 reasoning capabilities을 눈에 띄게 향상시키는 동시에 계산 부담도 줄인다는 것을 보여준다. Fig 1은 다양한 모델들의 GSM8K 성능과 연산 비용 간의 관계를 시각화한 것이다.

2. Background
Math word problem solving
■ math word problem solving task는 input \( x \)가 어떤 미지의 값을 묻는 question이고, output \( y \)가 answer \( a \)로 이어지는 rationale인 sequence-to-sequence task로 formulate할 수 있다.
■ 일반적으로 answers은 정규 표현식과 같은 rule-based method를 통해 rationale에서 추출할 수 있다.
■ 생성된 rationale \( \hat{y} \)에서 추출한 answer \( \hat{a} \)가 gold answer \( a \)와 일치하면, 그 생성된 rationale \( \hat{y} \)는 correct한 것으로 간주된다.
■ \( l \)개의 instance를 갖는 math word problem solving task의 labeled dataset은 다음과 같이 표현될 수 있다.
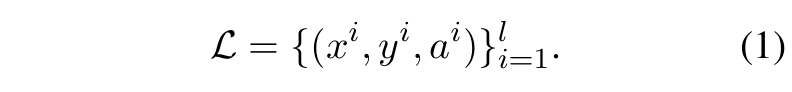
■ labeled dataset \( \mathcal{L} \)을 사용하여 LM \( f_{\theta} \)를 math reasoning에 specializing시키는 일반적인 방법은 supervised fine-tuning (SFT)이다. SFT는 negative log likelihood loss \( \mathcal{L}_{\text{SFT}} ( \theta ) \)를 최소화함으로써 \( f_{\theta} \)를 최적화한다.

- 여기서 \( T \)는 rationale \( y \)의 길이이며, \( y_t \)는 \( y \)의 \( t \)번째 토큰을 나타낸다.
Self-training
■ self-training은 semi-supervised learning의 approaches 중 하나로, labeled dataset \( \mathcal{L} \)로 학습된 base model을 teacher로 간주하고, 그 teacher를 사용해 unlabeled dataset \( \mathcal{U} \)에 annotation을 달아 pseudo-labeled dataset \( \mathcal{S} \)를 만든다.
■ 그런 다음, student model은 \( \mathcal{L} \)과 \( \mathcal{S} \)를 결합한 데이터로 학습되며, 이 student model은 teacher model보다 더 좋은 성능을 내는 것이 기대된다.
■ 이러한 framework는 natural language understanding과 generation을 포함한 다양한 NLP tasks에서 효과적인 것으로 나타났다.
■ CoT reasoning task를 위한 self-training algorithm은 아래 Algorithm 1에서 볼 수 있다.

■ 이전 연구들은 pseudo-label의 품질이 self-training algorithm의 전반적인 성능에 큰 영향을 미친다는 것을 보여주었다.
■ 예를 들어 ReST에서는 학습된 reward function을 사용하여 고품질의 pseudo-label을 선택하는 방법을 제안했다. Star에서는 생성된 rationales을 필터링하여 정답으로 이어지는 rationale들만 포함시켰다.
■ pseudo-label을 선택하는 많은 방법들이 제안되었지만, 더 높은 품질의 pseudo-label이 생성될 수 있도록 fine-tuned model \( f_{\theta'} \) 자체를 어떻게 개선할 것인지 논의한 연구는 거의 없다.
■ 논문에서는 각 iteration마다 \( f_{\theta'} \)를 개선하여 더 높은 품질의 pseudo-labeled data가 생성될 수 있도록 하는 방법을 제시한다.
Direct Preference Optimization
■ RLHF methods은 LM을 human preference와 align시킨다. RLHF의 standard pipeline은 먼저 human preference data로부터 reward model을 학습시킨다.
■ 그런 다음, PPO와 같은 reinforcement learning objective를 통해 LM을 fine-tuning하는 데 reward model이 사용된다.
■ 이후 reward model을 만들지 않고 LM이 human preference data로 직접 튜닝될 수 있도록 하는 DDO가 제안되었다.
■ DPO pipeline은 다음과 같이 설명될 수 있다. 어떤 prompt \( x \)가 주어졌을 때, reference model \( \pi_{\text{ref}} \)(일반적으로 reference model은 supervised fine-tuning 이후의 모델)로부터 여러 개의 completion을 샘플링한다.
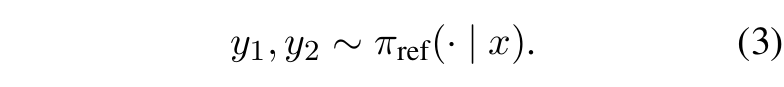
■ 다음으로, human preference를 기반으로 completions로부터 DPO dataset \( \mathcal{D} \)를 구축한다.

- 여기서 \( y^{w}_{i} \)와 \( y^{l}_{i} \)는 각각 winning completion과 losing completion을 나타낸다.
■ 그런 다음, 언어 모델 \( \pi_\theta \)가 \( \mathcal{L}_{\text{DPO}}(\pi_\theta; \pi_{\text{ref}}) \)를 최소화하도록 최적화한다.
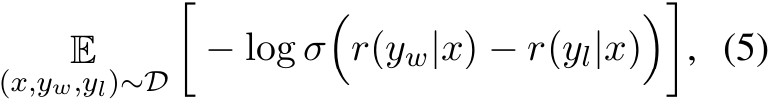
- 여기서 \( r(\cdot|x) = \beta \log \frac{\pi_\theta(\cdot|x)}{\pi_{\text{ref}}(\cdot|x)} \)이며, \( \beta \)는 \( \pi_\theta \)가 \( \pi_{\text{ref}} \)로부터 얼마나 벗어나는지를 조절하는 계수이다.
3. Method
3.1 DPO-augmented Self-Training
■ 저자들의 접근법은 warm-up stage로 시작하여, 각각 DPO 단계와 SFT 단계라는 두 개의 하위 단계로 구성된 반복 프로세스로 이어진다.

■ 이 반복 프로세스는 모델의 성능이 수렴하거나 최대 반복 횟수에 도달하면 종료된다.
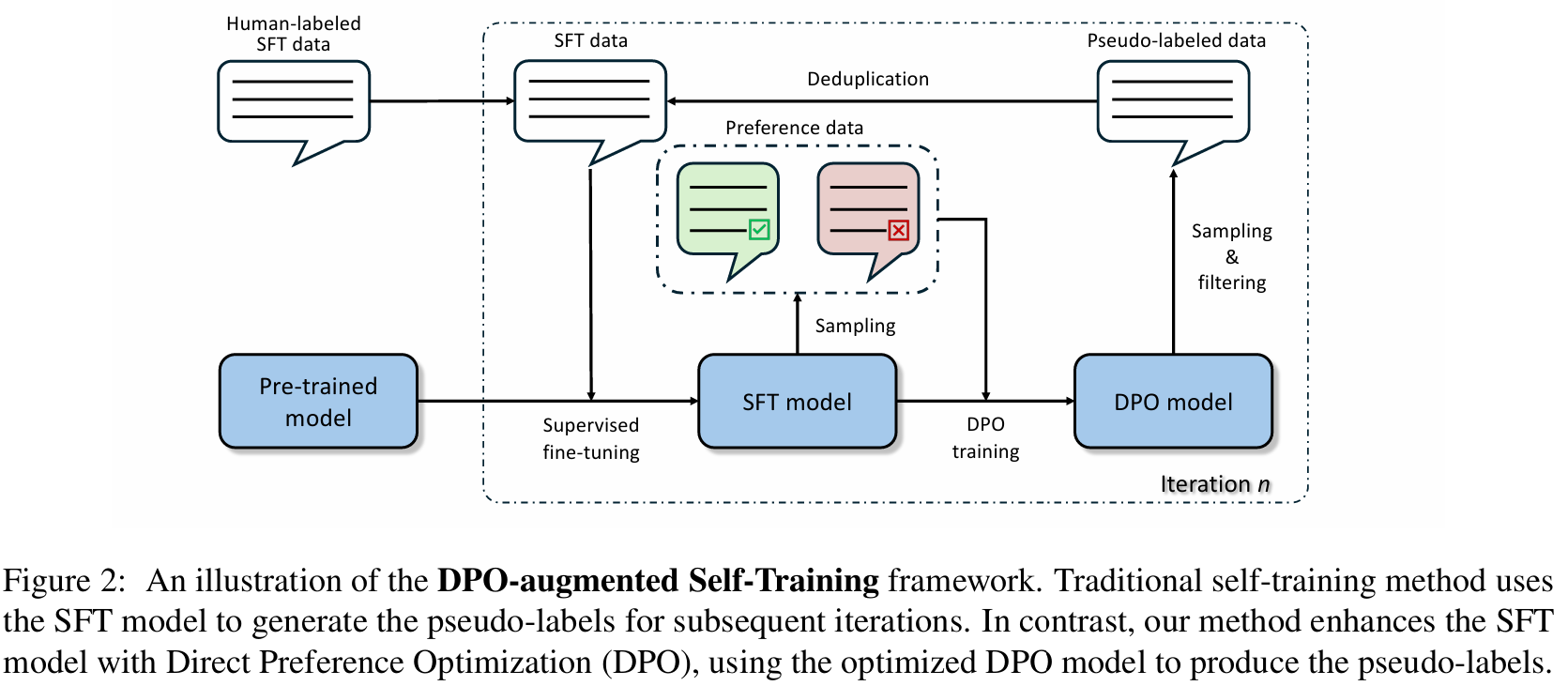
Warm-up stage
■ 기존의 self-training과 마찬가지로, labeled data \( \mathcal{L} \)에서 \( \mathcal{L}_{\text{SFT}}(\theta) \)를 최적화하도록 base model \( f_\theta \)를 fine-tuning하는 것으로 시작한다. 이 fine-tuning 결과로 업데이트된 모델 \( f_{\theta'} \)를 얻는다.
■ 이 단계 이후, \( f_{\theta'} \)가 특정 math problems을 풀 수 있는 능력을 갖췄다고 가정하자. 구체적으로 math question \( x \)가 주어지면, \( f_{\theta'} \)는 answer \( \hat{a} \)를 포함하는 rationale \( \hat{y} \)를 생성할 것이다.
Iterative step 1: DPO step
■ 이 단계에서는 먼저 \( \mathcal{U} \)에 있는 questions \( x \)가 주어졌을 때, fine-tuned model \( f_{\theta'} \)로부터 rationales \( \hat{y} \)를 샘플링한다.
■ 각각의 question \( x \)에 대해 여러 개의 rationales을 생성하여 DPO training dataset \( \mathcal{D} \)를 구축한다. (올바른 rationales은 winning completion, 잘못된 rationales은 losing completion)
■ 앞서 언급했듯이, math problem solving tasks의 경우 생성된 rationale \( \hat{y} \)가 correct한지 아닌지 쉽게 알 수 있다. correct answers을 가진 rationales을 winning completions으로 레이블링하고, incorrect answers을 가진 rationales을 losing completions으로 간주한다.
■ 그런 다음 DPO dataset \( \mathcal{D} \)에서 \( f_{\theta'} \)를 학습시켜 objective function \( \mathcal{L}_{\text{DPO}} \)를 최적화하고, 최종적으로 DPO model인 \( f_{\theta^d} \)를 얻는다.
Iterative step 2: SFT step
■ DPO를 통해 \( f_{\theta^d} \)를 얻은 뒤, 다음 라운드의 supervised fine-tuning을 위한 새로운 pseudo-labeled dataset \( \mathcal{S} \)를 생성하는 데 \( f_{\theta^d} \)를 다음과 같이 사용한다.

- \( \mathcal{S} \)는 \( \mathcal{U} \)에서 뽑은 \( x \)와, DPO model \( f_{\theta^d} \)가 그 \( x \)에 대해 생성한 rationale \( \hat{y} \)로 이루어진 pseudo-labeled dataset이다.
■ rationales 생성 이후, incorrect answer를 가진 rationale은 제거하고, 중복도 제거함으로써 \( \mathcal{S} \)를 정제한다. 그러므로 최종적으로 얻게 되는 pseudo-labeled dataset은 original \( \mathcal{S} \)의 부분집합, \( \mathcal{S}^\alpha \subset \mathcal{S} \)가 된다.
■ 최종 training dataset은 original labeled dataset \( \mathcal{L} \)과 새로 생성된 pseudo-labeled dataset \( \mathcal{S}^\alpha \)의 combination이다.
■ 이전 연구들을 따라, 이 과정에서 새로운 dataset을 수집하면 overfitting을 방지하기 위해 \( f_{\theta'} \)를 계속 fine-tuning하는 대신, original base model \( f_\theta \)부터 새로 학습을 시작한다.
3.2 Batch Decoding with Calculator
■ 일반적으로, GPT-3에서 설명된 것과 같은 LLM은 기본 산술 계산에서 더 뛰어난 능력을 보이는 반면, Flan-T5 Large와 같은 더 작은 LM은 유사한 산술 tasks에서 어려움을 겪는 경향이 있다. 이러한 한계는 math reasoning tasks에서 작은 모델들의 성능에 큰 영향을 미친다.
■ 이를 해결하기 위해, 여러 연구들은 small-scale models의 arithmetic capabilities을 높이기 위해external calculator를 결합하는 방법을 탐구해 왔다. 그러나 이러한 기존 방법들 중 다수는 decoding 시 batch size가 1로 제한된다. 이 제약은 inference speed를 상당히 낮추고, 실제 적용 가능성을 제한한다.
■ 저자들은 이 문제를 해결하기 위해, external calculator를 사용하는 inference 과정에서 더 큰 batch size를 사용할 수 있게 하는 단순하지만 효율적인 방법을 제안한다.
■ 저자들의 접근법은 original GSM8K dataset에 제공된 calculator annotation을 활용하는 것이다. Fig 3은 이러한 annotation의 예시이며, annotation이 decoding 중에 어떻게 사용될 수 있는지를 보여준다.

■ 이러한 annotation을 최적으로 활용하기 위해, 저자들은 Transformers library를 사용하여 모델을 구축한다.
■ inference 과정에서 모델의 generation process를 조정하기 위해 Transformers 공식 문서에서 제공되는 customized LogitsProcessor를 사용한다.
■ 이 LogitsProcessor는 interface 역할을 하며, generation 중 모델의 output을 수정할 수 있게 하고, 이를 통해 더 큰 batch size를 효율적으로 관리할 수 있게 한다.
■ 제안한 방법의 효율성을 보여주기 위해, T5 Large 기반의 open-source tool-using method인 Calcformer와 Flan-T5 Large에 자신들의 방법을 적용했을 때의 inference speed를 비교한다.
■ 비교 대상은 세 가지이다: 저자들의 방법에서 calculator를 사용하는 버전, 저자들의 방법에서 calculator를 사용하지 않는 버전, Calcformer

■ batch size가 1일 때, 세 방법 모두 약 40 tokens per second 정도로 비슷한 inference speed를 가진다는 것을 볼 수 있다. 그러나 inference batch size가 증가함에 따라, 저자들의 방법의 speedup이 크게 증가한다.
4. Experiments
4.1 Setup
Base models
■ 저자들은 Flan-T5 모델들을 base model들로 사용한다. 구체적으로, Flan-T5 family에서 두 가지 variant: Flan-T5-Base와 Flan-T5-Large를 고려한다.
■ 기존 연구의 근거를 바탕으로 original T5 대신 Flan-T5를 backbone model로 선택한다. 해당 연구들은 Flan-T5와 같은 instruction-tuned model이 수학 reasoning task에서 단순 pre-trained model보다 더 좋은 성능을 보인다는 것을 보여주었기 때문이다.
■ 그리고 비교를 위해 추가 base model로 Llama 모델들도 포함한다.
Datasets
■ 실험에서 사용한 labeled dataset \( \mathcal{L} \)은 GSM8K dataset의 training split에서 가져왔다.
■ unlabeled dataset \( \mathcal{U} \) 역시 GSM8K training data를 기반으로 만들었으며, 그 안의 annotated rationales를 제거하여 구축되었다.
■ 평가를 위해 GSM8K 외에도 일반적으로 사용되는 세 가지 math reasoning tasks을 고려한다: MultiArith, ASDiv, SVAMP
■ Table 1은 각 데이터셋의 통계 정보이다.
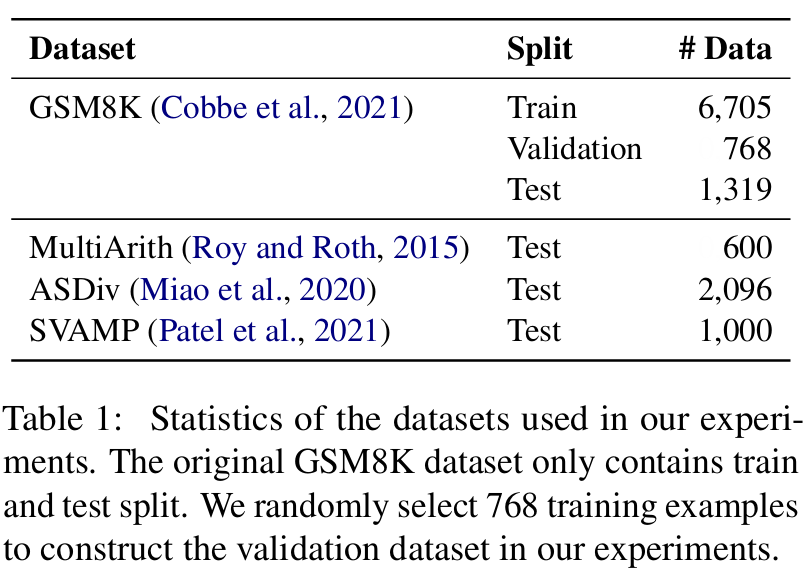
■ 이전 연구의 관행을 따라, base model을 오직 GSM8K training data에서만 fine-tuning하고, 공식적인 in-domain training split이 없는 나머지 세 데이터셋은 모델의 out-of-domain 성능을 평가하는 데 사용한다.
4.2 Implementation Details
■ warm-up stage에서는 original human-labeled annotations이 포함된 GSM8K training set을 사용해 base model을 fine-tuning하여 초기 SFT 모델을 얻는다.
■ 이후 DPO 단계를 위해, SFT model로부터 rationale들을 샘플링하여 preference dataset을 구축한다. 이때 각 question마다 temperature 0.7로 5개의 rationale을 샘플링한다.
■ 생성된 rationales \( \hat{y} \) 중 correct answer를 포함하는 것들은 winning rationale \( y_w \)로 분류하고, 나머지는 losing rationale \( y_l \)로 간주한다.
■ DPO learning objective \( \mathcal{L}_{\text{DPO}} \)에서 \( \beta=0.1 \)로 설정한다.
■ 이어지는 SFT 단계를 위해, DPO-tuned model \( f_{\theta^d} \)로부터 각 question마다 3개의 rationales을 생성하며, 이때도 temperature 0.7을 사용한다.
■ pseudo-labeled dataset을 만들기 위해 생성된 rationale \( \hat{y} \) 중 정답인 것들만 선택한다.
■ DPO와 SFT 단계 모두에서, Jaccard similarity score를 기준으로 threshold 0.7을 사용해 중복 제거를 수행한다.
■ 추가적인 implementation details은 Appendix A
Baselines
■ 저자들은 자신들의 방법과 비교하기 위해, Supervised Fine-Tuning (SFT) and Self-Training (ST) 두 가지 baseline methods을 사용한다.
■ SFT baseline은 warm-up stage 이후의 모델에 해당한다. Self-Training baseline은 Algorithm 1에 제시된 절차를 따른다.
■ 제안한 방법과 ST baseline 사이의 공정한 비교를 보장하기 위해, 각 iteration에서 두 방법 모두 동일한 hyperparameter set을 사용한다.
4.3 Main Results
comparison with baselines

■ Table 2는 4개의 데이터셋에서 두 가지 base models, Flan-T5-Base와 Flan-T5-Large를 baseline들과 비교한 결과이다.
■ ST baseline과 저자들이 제안한 DPO-augmented Self-Training 방법이 모두 SFT baseline을 큰 차이로 능가함을 볼 수 있으며, 이는 self-training framework 자체가 전반적으로 효과적임을 나타낸다.
■ ST baseline이 SFT baseline보다 상당한 성능 향상을 보이기는 하지만, 저자들의 DPO-augmented Self-Training 모델은 in-domain task인 GSM8K와 out-of-domain task인 MultiArith, ASDiv, SVAMP 모두에서 더 향상된 성능을 보인다.
Effect of iterative training

■ Fig 5는 Flan-T5-Base와 Flan-T5-Large 모델에서 iterative training의 영향을 보여준다.
■ 초기에는 저자들의 방법과 ST baseline 모두 warm-up stage에서 시작하며, iteration 0에서 비슷한 accuracy를 가진다.
■ 학습이 진행됨에 따라, 저자들의 방법은 두 모델 모두에서 모든 iteration에 걸쳐 ST보다 일관되게 더 좋은 성능을 보인다.
■ Flan-T5-Base의 경우 accuracy 향상이 정체되지만, Flan-T5-Large는 명확하고 꾸준한 개선을 보여주며, iteration 3에서 눈에 띄게 더 높은 accuracy를 달성했다.
■ 이는 iterative training process의 효과성을 보여주며, 특히 더 큰 모델의 성능을 향상시키는 데 효과적임을 보여준다.
4.4 Comparison with Existing Methods

■ 저자들은 자신들의 방법을 강화하기 위해, 각 question마다 샘플링하는 pseudo-label의 수를 늘려 더 다양하고 robust한 pseudo-label dataset을 만든다.
■ Scaling Relationship on Learning Mathematical Reasoning with Large Language Models 연구를 따라 이 하이퍼파라미터를 \( K \)라고 표기한다.
■ Table 3은 비슷한 base model size를 사용하는 조건에서, 저자들의 방법과 기존 방법들을 비교한 결과이다. 저자들이 고려한 base model에는 각각 약 770M 파라미터를 가진 GPT-2-Large, T5-Large, Flan-T5-Large가 포함된다.
■ Table 3에서 보이듯이, 저자들의 접근법은 GSM8K benchmark에서 다른 방법들을 능가할 뿐만 아니라, original GSM8K dataset의 annotation만을 사용함으로써 뛰어난 label efficiency도 보여준다.
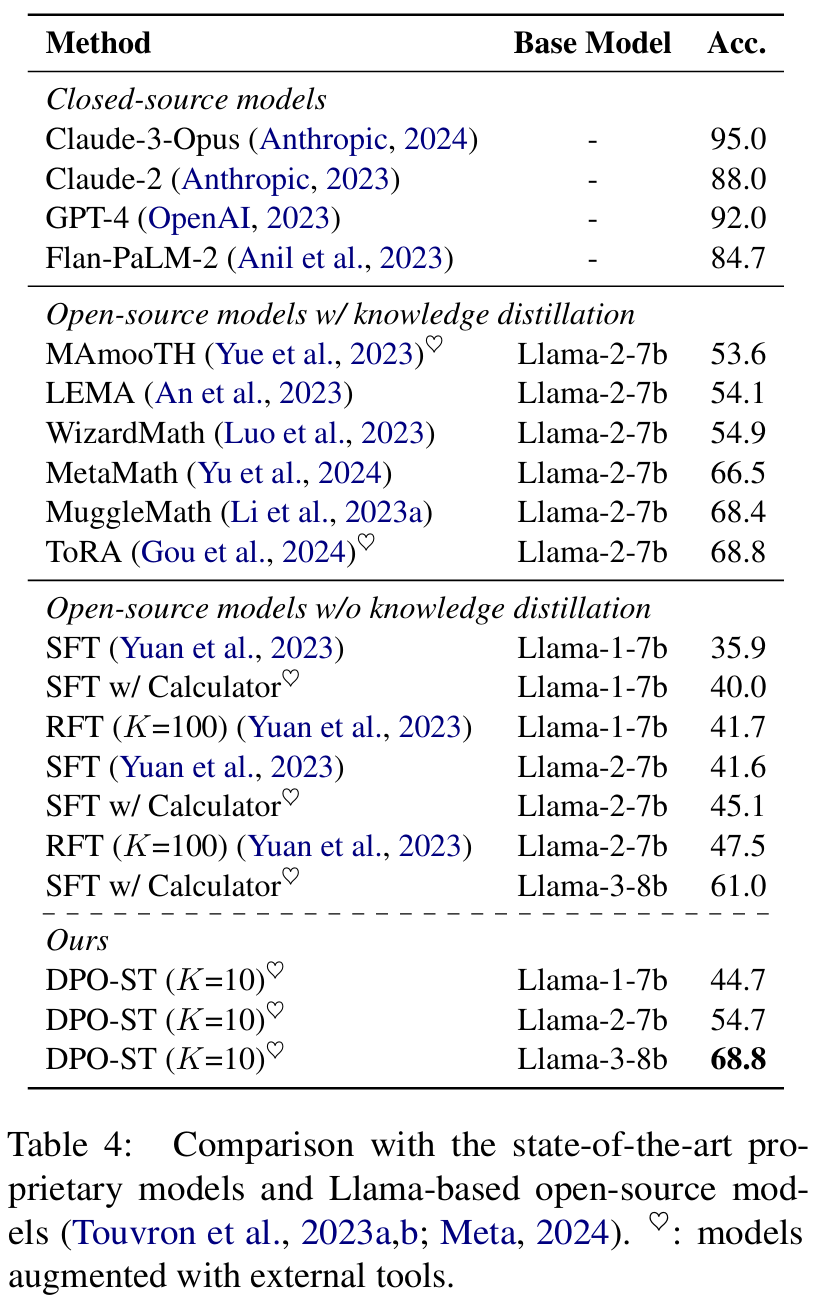
■ Table 4는 여러 SOTA closed-source models 및 비슷한 크기의 open-source models과 비교하여 Llama model family에 제안한 방법의 효과를 추가로 평가한 결과이다.
■ proprietary 및 open-source models 사이에 상당한 성능 격차가 있음을 볼 수 있다. open-source models 중에서는 knowledge distillation을 활용한 모델들이, 그러한 강화 방식을 사용하지 않은 모델들보다 일반적으로 더 좋은 성능을 보인다.
■ 특히 Llama-1-7B와 Llama-2-7B base model을 사용한 저자들의 모델은 knowledge distillation을 사용하지 않은 다른 open-source들을 능가하며, 각각 44.7%와 54.7%의 accuracy를 달성했다.
■ 더 나아가, Llama-3-8B를 사용한 저자들의 모델은 knowledge distillation을 사용한 이전 모델들의 성능과 맞먹거나 더 높은 성능을 보이며, 68.8%라는 accuracy를 달성했다.
4.5 Effects of the DPO Step
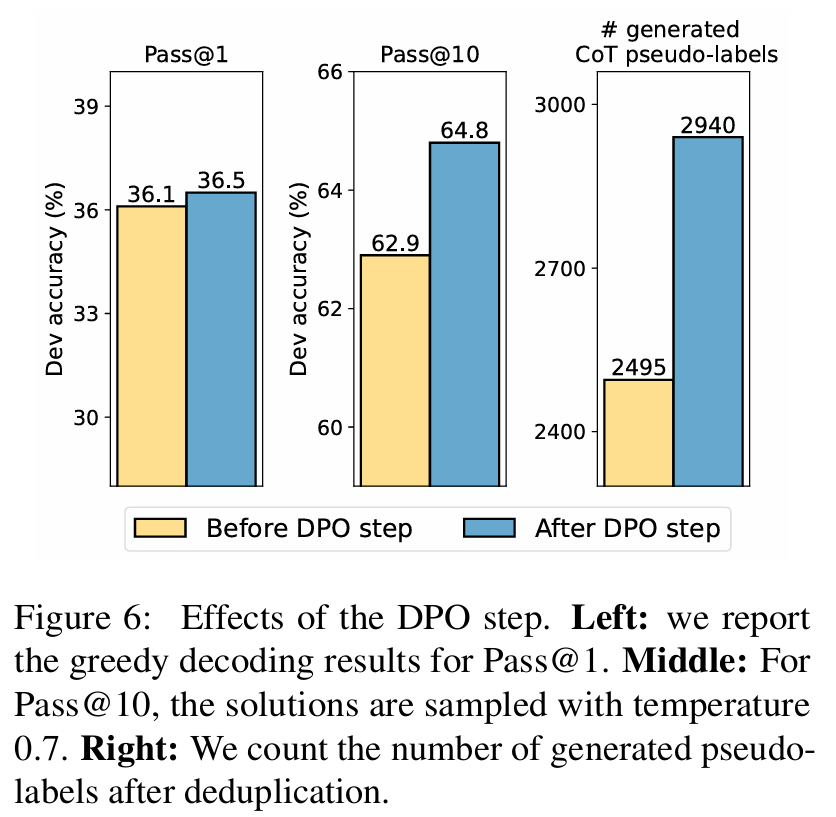
■ 저자들의 제안 방법과 classic self-training 사이의 주요 차이는, 매 iterative 과정마다 DPO 단계가 포함된다는 점이다. 이 섹션에서는 DPO 단계가 self-training을 어떻게 개선하는지 분석한다.
■ Fig 6은 첫 번째 iteration에서 DPO 단계 이전과 이후 모델의 성능을 Pass@K metric으로 비교한 결과이다. Pass@K는 한 문제에 대해 생성된 \( K \)개의 풀이 중 적어도 하나가 correct일 확률을 측정하며, 이는 모델이 생성한 풀이의 품질과 다양성을 모두 측정하는 지표 역할을 한다.
■ 이 실험에 사용된 모델들은 Flan-T5-Large에서 fine-tuning된 모델들이다.
■ Figure 6에서 나타난 바와 같이, DPO 단계는 development set의 Pass@1 성능에서 SFT model에 비해 아주 작은 개선만 가져온다.
■ 그러나 temperature 0.7로 question당 10개의 rationales을 샘플링했을 때(Pass@10으로 측정)는 성능이 크게 향상되었다.
■ 이는 DPO training objective가 언어 모델로 하여금 높은 품질과 다양성을 모두 가진 rationale들을 생성하도록 만드는 경향이 있음을 나타낸다.
■ 저자들은 또한 DPO 단계가 있는 모델과 없는 모델에 대해, training set \( \mathcal{L} \)에서 생성된 rationales의 개수(즉, correct rationale의 개수)를 비교한다. (Fig 6 right)
■ Fig 6 right에서 DPO 단계 이후의 모델이 다음 iteration을 위한 SFT data를 더 많이 생성할 수 있음을 볼 수 있다.
4.6 Effects of External Calculator

■ small-scale LM들이 기본적인 계산 오류를 자주 범한다는 관찰에 기반하여, 저자들은 external calculator를 모델의 decoding process에 통합하는 단순하지만 효율적인 방법을 개발했다.
■ Fig 7은 이 통합의 영향을 평가하기 위해, calculator를 제거하는 ablation study를 수행한 결과이다.
■ 결과는 calculator 없이 decoding하면 모든 iteration에서 accuracy가 현저히 감소함을 보여준다. 저자들은 이것이 calculator가 없을 때 모델이 많은 양의 false positive pseudo-labels을 생성하기 때문이라고 본다.
■ 즉 생성된 pseudo-label이 correct final answer를 가지고 있더라도 intermediate reasoning steps에서는 errors을 포함할 수 있다는 것이다.
5. Related Work
Learning from pseudo-labels
■ supervised fine-tuning (SFT)은 특정 downstream tasks에서 pre-trained language models의 성능을 향상시키기 위해 널리 사용되는 기법이다.
■ 그러나 이 방법은 high-quality labeled data의 가용성에 크게 의존하며, 이러한 데이터를 확보하는 것은 비용이 많이 들고 labor-intensive일 수 있다.
■ 이러한 한계를 해결하기 위해, text classification, sentence representation learning, instruction tuning, math reasoning 등 광범위한 응용 분야에서 unlabeled data나 synthetic data를 사용하여 high-quality pseudo-labels을 생성하는 다양한 전략이 개발되었다.
■ 이 분야의 최근 발전은 주로 두 가지 방향, self-training과 knowledge distillation에 초점을 맞추고 있다. 두 방법의 핵심 차이는 pseudo-label의 출처에 있다.
■ self-training은 unlabeled data에 대한 모델 자신의 prediction을 사용하고, knowledge distillation은 더 크고 강력한 모델로부터 얻은 insights을 활용한다.
Self-training in language model
■ language models을 위한 self-training algorithms에 초점을 맞춘 다수의 연구들은 대부분 classic self-training framework에 기반을 두고 있다.
■ Revisiting self-training for neural sequence generation에서는 summarization과 translation 같은 natural language generation tasks에서 self-training의 효과를 연구했다.
■ gold rationales이 제공되지 않더라도 언어 모델이 자기 자신의 생성 결과를 통해 반복적으로 개선될 수 있음을 보여준 STaR가 등장했으며, Alibaba에서는 언어 모델의 math reasoning abilities을 향상시키기 위해 rejection sampling fine-tuning을 제안했다.
■ Google DeepMind에서는 expectation-maximization framework에 기반한 self-improving algorithm인 ReSTEM을 제안했다. 이 방법은 math reasoning과 code generation 같은 problem-solving tasks에서 상당한 성능 향상을 보여준다.
Knowledge distillation from LLMs
■ 많은 연구들은 LLM들이 math reasoning을 수행할 수 있음을 보여주었다. 그 결과, LLM으로부터 chain-of-thought pseudo-labels을 distill하여 smaller language models의 reasoning abilities을 향상시키려는 관심이 커지고 있다.
■ 예를 들어, Evol-Instruct framework에 기반한 Reinforcement Learning from Evol-Instruct Feedback이 있으며, 이 방법은 training signal을 제공하기 위해 ChatGPT를 필요로 한다.
■ supervised fine-tuning 과정에서 LLM이 수정할 수 있는 mistake들로부터 언어 모델이 효과적으로 학습할 수 있음을 보여준 연구도 있다.
■ 이러한 방법들이 유망한 실험 결과를 보였지만, 대형 모델은 inference 동안 더 많은 FLOPs를 요구하기 때문에 구현 비용이 크다.
■ 저자들의 연구는 small-scale LM들이 자기 자신의 생성 결과로부터 효과적으로 학습할 수 있음을 보여주며, knowledge distillation에 비해 더 자원 효율적인 대안임을 보여주었다.
■ 또한, 저자들의 방법은 개념적으로 knowledge distillation 기법들과 orthogonal하기 때문에, knowledge distillation을 저자들의 iterative training process에 통합하여 모델 성능을 더 향상시킬 수 있다.
6. Limitations
Use of unlabeled data
■ 저자들의 방법은 unlabeled data를 효율적으로 활용할 수 있는 효과적인 semi-supervised learning framework를 제공하는 classic self-training algorithm에 기반하고 있다. 그러나 이 연구는 unlabeled data의 사용을 충분히 실험하지 않았다
Generalization to other tasks
■ 이 연구의 한계 중 하나는 실험 범위가 좁다는 점이며, 실험은 오직 math reasoning task에만 국한되어 수행되었다. 저자들은 이러한 한계의 주된 이유가 다른 reasoning task에 적합한 training data가 부족하기 때문이라고 설명한다.
■ 저자들의 방법은 chain-of-thought label이 포함된 training data를 필요로 하지만, 기존의 많은 reasoning task들은 그러한 annotation을 가지고 있지 않다. 그래서 실험을 현재 범위 밖으로 확장하기 어렵다.
■ 향후 연구는 더 넓은 범위의 reasoning task에 적합한 dataset을 찾고 개발하는 데 초점을 맞출 수 있으며, 이를 통해 서로 다른 reasoning task 전반에서 이 방법의 적용 가능성과 효과성을 충분히 평가할 수 있다.

