 시퀀스투시퀀스(Sequence‑to‑Sequence, seq2seq) (3)
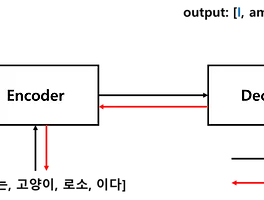
1. Seq2Seq 개선 ■ Seq2Seq 모델의 학습 진행 속도와 정확도를 개선할 수 있는 방법으로 입력 데이터를 반전(reverse)하는 것과 Peeky Decoder를 사용하는 방법이 있다. 1.1 Encoder에 들어가는 입력 시퀀스 반전(reverse)■ 첫 번째 방법은 Encoder에 입력되는 입력 시퀀스 데이터의 순서를 반전시켜 Encoder 모델어 입력하는 것이다. 이 기법은 단순하지만 성능을 개선시킬 수 있다.■ 입력 시퀀스 반전 기법이란, 예를 들어 '나', '는', '고양이', '로소', '이다.'라는 순서를 가지는 시퀀싀의 순서를 반전시켜 '이다', '로소', '고양이', '는', '나'와 같이 역순으로 Encoder 모델에 입력하는 것이다.■ 단순히 입력 시퀀스의 순서를 바꾸는 ..
시퀀스투시퀀스(Sequence‑to‑Sequence, seq2seq) (3)
1. Seq2Seq 개선 ■ Seq2Seq 모델의 학습 진행 속도와 정확도를 개선할 수 있는 방법으로 입력 데이터를 반전(reverse)하는 것과 Peeky Decoder를 사용하는 방법이 있다. 1.1 Encoder에 들어가는 입력 시퀀스 반전(reverse)■ 첫 번째 방법은 Encoder에 입력되는 입력 시퀀스 데이터의 순서를 반전시켜 Encoder 모델어 입력하는 것이다. 이 기법은 단순하지만 성능을 개선시킬 수 있다.■ 입력 시퀀스 반전 기법이란, 예를 들어 '나', '는', '고양이', '로소', '이다.'라는 순서를 가지는 시퀀싀의 순서를 반전시켜 '이다', '로소', '고양이', '는', '나'와 같이 역순으로 Encoder 모델에 입력하는 것이다.■ 단순히 입력 시퀀스의 순서를 바꾸는 ..
 LSTM, GRU (2)
1. nn.LSTM( ), nn.GRU( )1.1 (일반적인) LSTM/GRU■ 파이토치에서 LSTM/GRU 셀을 사용하는 방법은 RNN 셀을 사용하려고 했을 때와 유사하다.torch.nn.LSTM(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0.0, bidirectional=False, proj_size=0, device=None, dtype=None) torch.nn.GRU(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0.0, bidirectional=False, device=None, dtype=..
LSTM, GRU (2)
1. nn.LSTM( ), nn.GRU( )1.1 (일반적인) LSTM/GRU■ 파이토치에서 LSTM/GRU 셀을 사용하는 방법은 RNN 셀을 사용하려고 했을 때와 유사하다.torch.nn.LSTM(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0.0, bidirectional=False, proj_size=0, device=None, dtype=None) torch.nn.GRU(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0.0, bidirectional=False, device=None, dtype=..
 RNN (2)
3. 파이토치 nn.RNN( )■ 파이토치의 torch.nn.RNN( )을 통해서 RNN 셀을 구현할 수 있으며, torch.nn.RNN( )의 파라미터를 통해 깊은 RNN과 양방향 RNN도 구현할 수 있다. 파라미터는 다음과 같다.torch.nn.RNN(input_size, hidden_size, num_layers=1, nonlinearity='tanh', bias=True, batch_first=False, dropout=0.0, bidirectional=False, device=None, dtype=None)- input_size: 입력할 특성(feature)의 개수이다. - hidden_size: 은닉 상태 벡터의 차원이다.- num_layers: RNN 레이어를 입력-출력 방향으로 쌓아 ..
RNN (2)
3. 파이토치 nn.RNN( )■ 파이토치의 torch.nn.RNN( )을 통해서 RNN 셀을 구현할 수 있으며, torch.nn.RNN( )의 파라미터를 통해 깊은 RNN과 양방향 RNN도 구현할 수 있다. 파라미터는 다음과 같다.torch.nn.RNN(input_size, hidden_size, num_layers=1, nonlinearity='tanh', bias=True, batch_first=False, dropout=0.0, bidirectional=False, device=None, dtype=None)- input_size: 입력할 특성(feature)의 개수이다. - hidden_size: 은닉 상태 벡터의 차원이다.- num_layers: RNN 레이어를 입력-출력 방향으로 쌓아 ..






