1. Seq2Seq 개선
■ Seq2Seq 모델의 학습 진행 속도와 정확도를 개선할 수 있는 방법으로 입력 데이터를 반전(reverse)하는 것과
Peeky Decoder를 사용하는 방법이 있다.
1.1 Encoder에 들어가는 입력 시퀀스 반전(reverse)
■ 첫 번째 방법은 Encoder에 입력되는 입력 시퀀스 데이터의 순서를 반전시켜 Encoder 모델어 입력하는 것이다. 이 기법은 단순하지만 성능을 개선시킬 수 있다.
■ 입력 시퀀스 반전 기법이란, 예를 들어 '나', '는', '고양이', '로소', '이다.'라는 순서를 가지는 시퀀싀의 순서를 반전시켜 '이다', '로소', '고양이', '는', '나'와 같이 역순으로 Encoder 모델에 입력하는 것이다.
■ 단순히 입력 시퀀스의 순서를 바꾸는 것만으로 Seq2Seq 모델의 성능을 개선시킬 수 있다.
■ 이 기법이 효과적인 이유는 Encoder 입력 초반부의 정보가 Decoder 초반부에 도달하기까지 거쳐야 하는 경로의 길이가 짧아지기 때문이다. 즉, 역전파 과정에서의 기울기 전파 경로가 짧아지기 때문이다.
■ 예를 들어, 일반적인 (순서) 방법으로 입력 시퀀스로 '나', '는', '고양이', '로소', '이다.'를 Encoder에 입력했을 때, Decoder에서는 'I', 'am', 'a', 'cat'라는 출력 시퀀스를 생성하는 다음과 같은 Seq2Seq 모델을 생각해보자.

■ 일반적인 순서로 입력 시퀀스를 배치했을 때, Decoder의 첫 번째 출력 시퀀스 'I'와 이에 대응되는 입력 시퀀스 '나' 사이의 경로를 생각해보자.
■ Decoder에서 'I'를 생성할 때의 오차를 Encoder의 '나'에 전달하려면 Encoder의 '는', '고양이', '로소', '이다' 총 4개의 단어(또는 time step)를 거쳐야 한다. 즉, 각 시점의 순환 신경망 셀을 거쳐 역전파를 수행해야 한다.
■ 이 예에서는 문장이 단순하여 역전파 과정에서 순환 신경망 계층을 몇 단계 거치지 않지만, 많은 time step을 거치게 된다면 역전파 과정에서 더 많은 기울기 전파가 발생하므로 기울기가 약해지거나 소실될 수 있다.
■ 반면, 다음과 같이 입력 시퀀스의 순서를 반전시켜 배치한다면, Encoder의 마지막 입력이 '나'이며 Decoder의 첫 번째 출력이 'I'가 된다. 즉, '나'와 'I'간의 기울기 전파 경로가 더 짧아지므로 역전파 시 기울기를 최대한 보존하면서 전달할 수 있다.

■ 이렇게 입력 데이터 반전은 긴 문장에서도 학습 안정성을 높여줄 수 있는 핵심적인 트릭이다. 단, 입력 시퀀스를 반전시킨다고 해서 모든 단어 쌍의 거리가 줄어드는 것은 아니다. 즉, 평균 거리는 입력 시퀀스를 반전시키기 전/후가 동일하다.
■ 입력 시퀀스가 토큰의 정수 인덱스로 구성되어 있다고 하자. '나', '는', '고양이', '로소', '이다'라는 토큰에 대응되는 정수 인덱스가 각각 0, 1, 2, 3, 4, 5라고 할때, '나는 고양이로소이다'라는 문장은 [0, 1, 2, 3, 4, 5]라고 할 수 있다. 입력 시퀀스를 반전시키면 [5, 4, 3, 2, 1]이 되는 것이다.
■ 예를 들어 시퀀스투시퀀스(Sequence‑to‑Sequence, seq2seq) (2) 에서는 입력 시퀀스가 영어 단어였다. 그러므로 이 예에서 입력 시퀀스 반전은 단순히 영어 시퀀스의 순서만 뒤집으면 된다.
■ 일반적인 순서를 Encoder에 배치할 때는 다음과 같은 함수를 사용하였다. 해당 함수는 입력된 데이터(tokenized_data)를 순서대로 읽으면서 단어 집합에 해당 단어(토큰)가 있다면, 그 단어(토큰)에 해당하는 정수 인덱스를, 없다면 <unk> 토큰의 정수 인덱스로 처리하는 함수이다. 최종적으로 각 문장의 토큰들은 원래 순서 그대로 유지한 채 토큰의 정수 인덱스로 반환된다.
def texts_to_sequences(tokenized_data, word_to_index):
encoded_data = []
for sent in tokenized_data:
index_sequences = [] # 단어 집합(word_to_index)에서 단어(word)의 인덱스를 찾아 index_sequences에 저장
for word in sent:
try:
index_sequences.append(word_to_index[word]) # 단어 집합에 단어(word)가 있으면 해당 단어의 인덱스를 index_sequences에 저장
except:
index_sequences.append(word_to_index['<UNK>']) # 없으면 OOV이므로 <unk> 토큰으로 처리
encoded_data.append(index_sequences)
return encoded_data
encoder_input = texts_to_sequences(en_input, src_vocab)
encoder_input
```#결과#```
[[27, 2],
[27, 2],
...,
[27, 114, 2],
[27, 88, 2],
...,
[210, 6, 2],
...]
````````````■ 입력 시퀀스를 반전시키는 방법은 단순히 [27, 2], [27, 114, 2], .. 등으로 매핑된 정수 인덱스들을 단순히 거꾸로 뒤집어 [2, 27], [2, 114, 27], .... 등으로 만드는 것이다. 이를 위해 texts_to_sequences 함수에 다음과 같이 reverse 기능을 추가하여 사용하면 된다.
def texts_to_reverse_sequences(tokenized_data, word_to_index):
encoded_data = []
for sent in tokenized_data:
index_sequences = [] # 단어 집합(word_to_index)에서 단어(word)의 인덱스를 찾아 index_sequences에 저장
for word in sent:
try:
index_sequences.append(word_to_index[word]) # 단어 집합에 단어(word)가 있으면 해당 단어의 인덱스를 index_sequences에 저장
except:
index_sequences.append(word_to_index['<UNK>']) # 없으면 OOV이므로 <unk> 토큰으로 처리
encoded_data.append(index_sequences)
reverse_encoded_data = []
for i in encoded_data:
i.reverse()
reverse_encoded_data.append(i)
return reverse_encoded_data
encoder_reverse_input = texts_to_reverse_sequences(en_input, src_vocab)
encoder_reverse_input
```#결과#```
[[2, 27],
[2, 27],
...,
...,
[2, 6, 210],
...]
````````````■ 이 함수는 처음에 texts_to_sequences와 동일하게 동작하여 각 문장을 인덱스 리스트로 변환한다. 그리고 변환된 각 문장의 인덱스 리스트를 역순(reverse)으로 변경하여 반환한다. 즉, 이 함수는 각 문장의 시퀀스 순서를 뒤집은 결과를 반환한다.
■ 예를 들어, 20011번째 문장에 대하여 토큰의 정수 인덱스를 다음과 같이 다시 토큰으로 변환하면, 일반적인 문법의 순서가 뒤집어져 주어 'he'가 문장의 마지막에 있으며, Encoder의 마지막 시점에 입력될 것임을 알 수 있다.
index_to_src ={value: key for key, value in src_vocab.items()}
index_to_tar ={value: key for key, value in tar_vocab.items()}
## 인코더의 입력인 영어 문장에 해당하는 정수 시퀀스를 영어 단어로 변환하는 함수
def seq2scr(input_seq):
sentence = ''
for int_seq in input_seq:
if int_seq != 0 : sentence += index_to_src[int_seq] + ' ' # input seq 중 값이 0인 것 제외 # <pad> 토큰 제외
return sentence
## 디코더의 입력인 프랑스어 문장에 해당하는 정수 시퀀스를 프랑스어 단어로 변환하는 함수
def seq2tar(input_seq):
sentence = ''
for int_seq in input_seq:
# input seq 중 값이 0인 것 제외 # <pad> 토큰 제외 그리고 <sos> 토큰과 <eos> 토큰도 제외해야 함
if int_seq != 0 and int_seq != 3 and int_seq != 4 : sentence += index_to_tar[int_seq] + ' '
return sentenceseq2scr(encoder_input[20011])
```#결과#```
'he blew the deal . '
````````````
seq2scr(encoder_reverse_input[20011])
```#결과#```
'. deal the blew he '
````````````■ 이 문장이 입력되면 Seq2Seq 모델이 출력(생성)해야 할 문장은 다음과 같다.
decoder_input = texts_to_sequences(fra_input, tar_vocab)
decoder_target = texts_to_sequences(fra_output,tar_vocab)
seq2tar(decoder_input[20011])
```#결과#```
'il a saborde le contrat . '
````````````■ 위와 같이 Encoder의 입력으로 들어갈 데이터에 대해서만 texts_to_reverse_sequences( ) 함수를 적용하고 디코더의 입력과 타깃에 대해서는 texts_to_sequences( ) 함수를 적용한 다음, 동일하게 패딩 처리 및 데이터셋, 데이터로더를 생성하고 학습을 수행하면 된다.
1.2 Peeky Decoder
■ 1.1의 Encoder-Decoder 전체 그림을 보면, 일반적인 Encoder-Decoder 모델 구조에서는 Encoder가 입력 시퀀스를 처리하여 생성한 context vector는 Decoder의 첫 번째 시점의 순환 신경망 셀에만 전달된다.
■ 그리고 Decoder의 첫 번째 셀은 첫 번째 시점의 입력을 받아 첫 번째 출력 시퀀스가 생성한다.
■ Decoder의 첫 번째 시점 이후의 순환 신경망 셀들은 context vector를 직접 받지 않고, 이전 시점의 셀을 통해 간접적으로만 context vector의 정보를 전달받는다고 볼 수 있다.
■ 두 번째 방법은 Encoder로부터 생성된 context vector를 Decoder의 모든 시점의 순환 신경망 셀에 직접적으로 전달되도록 Deocder의 구조를 개선하는 방법이다.
■ 이러한 구조적 개선을 통해 Decoder의 각 시점의 순환 신경망 계층들은 Encoder로부터 전달된 context vector를 참조 혹은 엿본다고 하여 Peeky Decoder라고 부른다. Peeky Decoder의 구조는 다음과 같다.
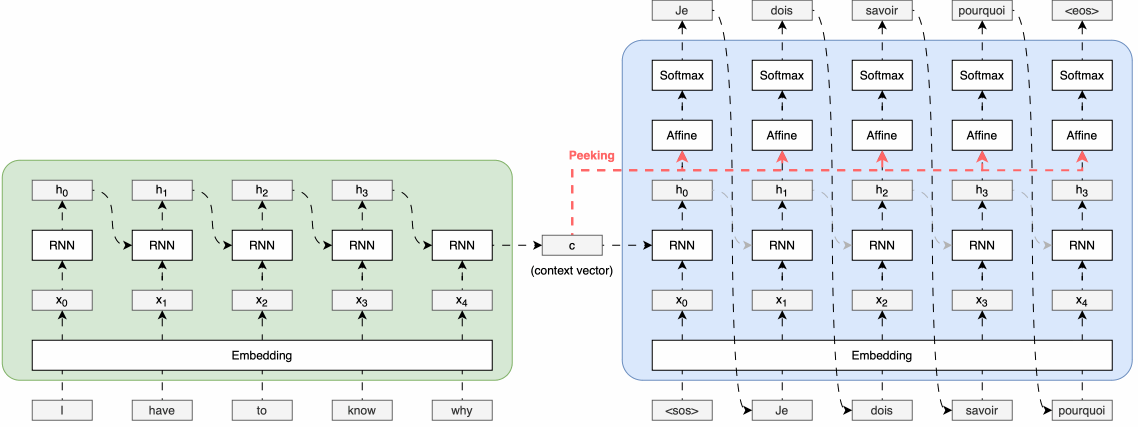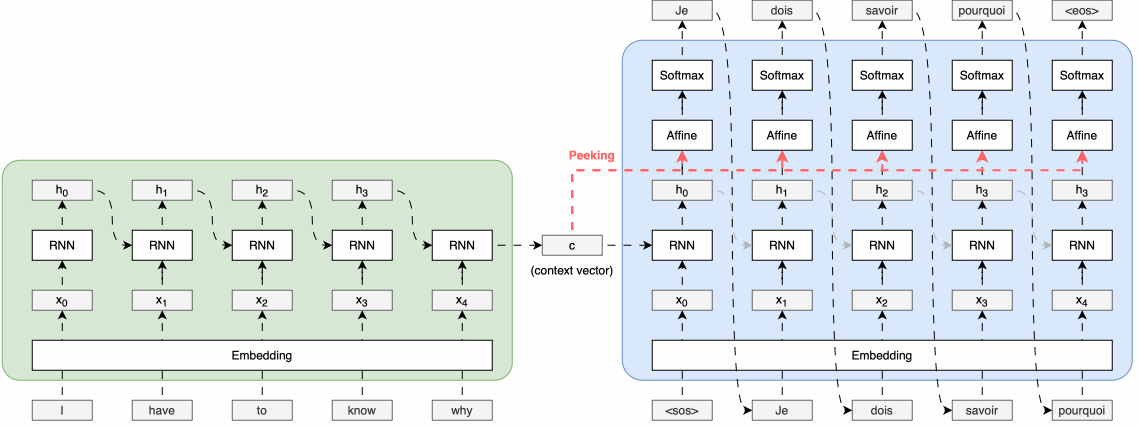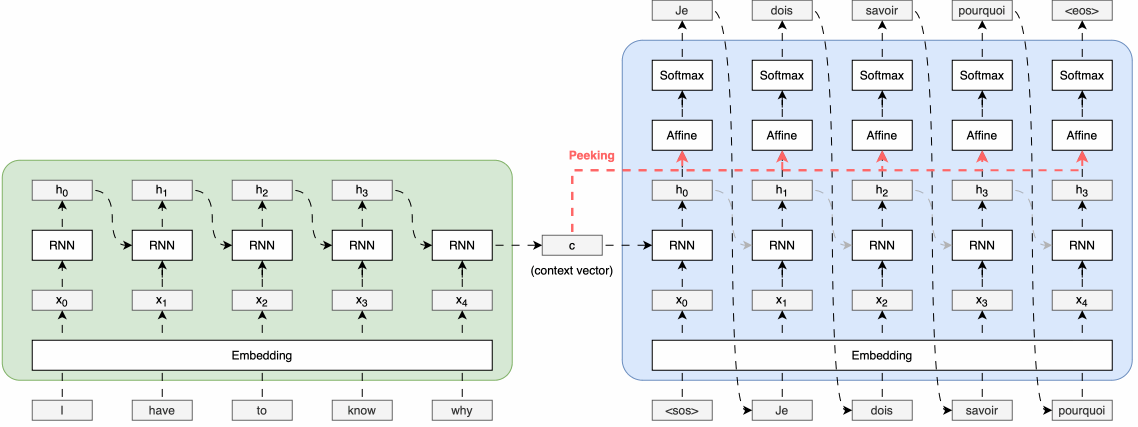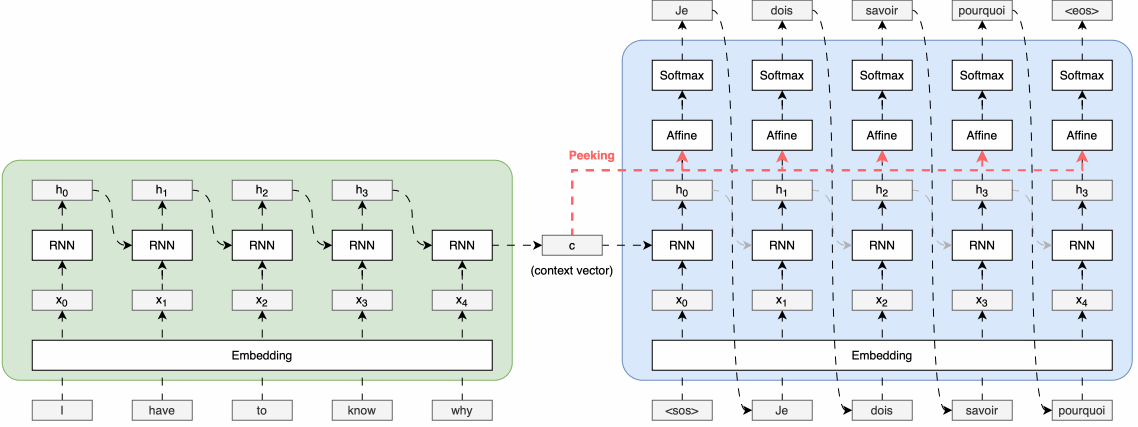
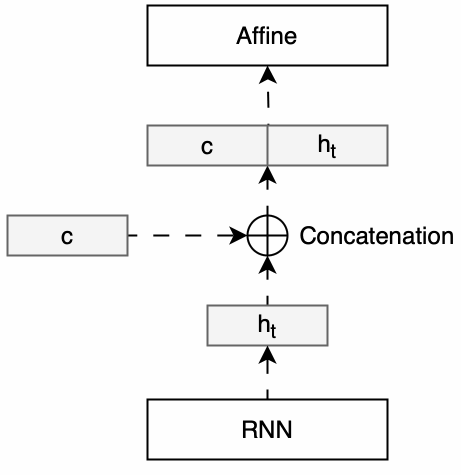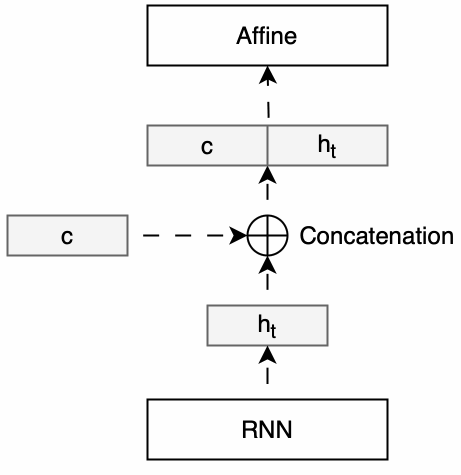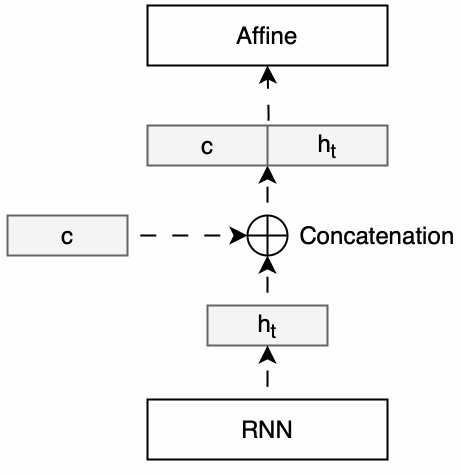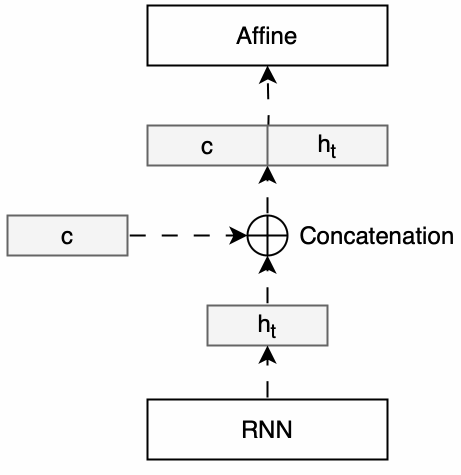
■ 일반적인 Seq2Seq 모델에서는 Encoder가 생성한 context vector가 Decoder의 초기 상태로만 전달되는 반면,
Peeky Decoder는 이 인코딩된 정보를 더 광범위하게 활용한다.
■ 위의 Peeky Decoder 그림은 Encoder가 생성한 인코딩 정보인 context vector를 Decoder의 모든 시간 단계의 Affine 계층에 직접 전달하는 구조를 보이고 있다.
■ 이러한 구조를 통해 Encoder가 압축한 정보를 여러 계층들이 직접적으로 활용할 수 있게 된다.
■ 더 나아가, Peeky Decoder는 Affine 계층뿐만 아니라 다음과 같이 순환 신경망 계층에도 Encoder의 context vector를 전달할 수 있다.

■ 그리고 이미지의 오른쪽 부분에서 볼 수 있듯이, Affine 계층이나 순환 신경망 계층에 context vector를 전달하여 계층의 입력으로 사용하기 위해서는 두 개의 데이터를 연결(concatenate)하여 하나의 입력을 만들어야 한다.
■ 이렇게 데이터를 연결하면 해당 부분의 차원이 늘어나게 되지만, Encoder의 중요한 정보가 Decoder의 여러 계층에 직접 전달됨으로써 모델이 더 올바른 결정을 내릴 것이란 기대를 할 수 있다.
■ 정리하면, Peeky Decoder는 인코딩된 정보를 Decoder의 다른 계층에도 전해주는 기법이라고 할 수 있다. 이러한 Peeky Decoder를 이용하는 Seq2Seq를 Peeky Seq2Seq라고 부른다.
■ 위의 그림과 같이 Peeky Decoder를 이용하여 Affine 계층과 LSTM 계층 모두에 Encoder의 context vector를 직접 전달하기 위해서는 다음과 같은 3가지 부분을 고려하면 된다.

- (1) Decoder의 입력 벡터와 Encoder의 은닉 상태를 연결
- (2) Decoder의 LSTM 계층에서는 (1)에서 전달되는 것과 Encoder의 은닉 상태를 입력으로 받아서 Affine 계층으로 출력
- (3) Decoder의 Affine 계층에서는 LSTM 계층에서 전달되는 것과 Encoder의 은닉 상태를 입력으로 받아서 점수(score) 계산
■ 예를 들어, Encoder의 LSTM 계층과 입력 x와 입베딩 계층의 크기가 다음과 같다고 하자.
input_size, hidden_size, embedded_dim = 5, 3, 7
lstm_cell = nn.LSTM(7, hidden_size, batch_first=True)
embedding_layer = nn.Embedding(num_embeddings=input_size+1, embedding_dim=embedded_dim)
x = torch.randint(0, input_size+1, (2, 5))
embedded = embedding_layer(x)
x = x.float()
x.shape # [batch_size, sequence_length]
```#결과#```
torch.Size([2, 5])
````````````
embedded.shape # [batch_size, sequence_length, embedde_dim]
```#결과#```
torch.Size([2, 5, 7])
````````````■ 그리고 Encoder의 LSTM 계층에 embedded를 넣어서 반환되는 encoder_hidden가 Decoder에 전달해야 하는 은닉 상태라고 하자.
_, (encoder_hidden, encoder_cell) = lstm_cell(embedded) # 인코더의 lstm 계층이라고 치자.
encoder_hidden.shape # [1, batch_size, hidden_dim]
```#결과#```
torch.Size([1, 2, 3])
````````````■ Peeky Decoder는 위와 같은 은닉 상태 encoder_hidden을 다른 계층에도 전달하기 위해서 Encoder가 전달한 은닉 상태인 encoder_hidden을 seq_len만큼 복제해야 한다.
# [1, batch_size, hidden_dim]
encoder_hidden.shape, encoder_hidden
```#결과#```
torch.Size([1, 2, 3]),
tensor([[[-0.0539, -0.6849, 0.2635],
[ 0.0775, -0.5767, -0.0309]]], grad_fn=<StackBackward0>))
````````````
encoder_hidden = encoder_hidden.squeeze() # 또는 shape이 [1, batch_size, hidden_dim]이므로 encoder_hidden[0]
encoder_hidden.shape #[batch_size, hidden_dim]
```#결과#```
torch.Size([2, 3])
````````````■ 여기서 seq_len은 두 번째 차원이므로 다음과 같이 두 번째 차원을 만든 다음, repeat 함수를 통해 두 번째 차원의 값을 복제한다. 두 번째 차원을 seq_len의 수만큼 복제한 것을 encoder_hidden_repeated라고 하자.
# [batch_size, seq_len, hidden_dim]
encoder_hidden.unsqueeze(1).repeat(1, 5, 1).shape, encoder_hidden.unsqueeze(1).repeat(1, 5, 1)
```#결과#```
(torch.Size([2, 5, 3]),
tensor([[[-0.0539, -0.6849, 0.2635],
[-0.0539, -0.6849, 0.2635],
[-0.0539, -0.6849, 0.2635],
[-0.0539, -0.6849, 0.2635],
[-0.0539, -0.6849, 0.2635]],
[[ 0.0775, -0.5767, -0.0309],
[ 0.0775, -0.5767, -0.0309],
[ 0.0775, -0.5767, -0.0309],
[ 0.0775, -0.5767, -0.0309],
[ 0.0775, -0.5767, -0.0309]]], grad_fn=<RepeatBackward0>))
````````````
encoder_hidden_repeated = encoder_hidden.unsqueeze(1).repeat(1, 5, 1)■ encoder_hidden에 unsqueeze(1)을 적용하여 1번 인덱스 위치에 차원을 하나 추가한다. encoder_hidden의 shape은 [2, 1, 3]이 된다.
■ repeat 함수는 각 차원별로 텐서를 볓 번 반복할지를 정한다. [2, 1, 3].repeat(1, 5, 1)은 첫 번째 차원과 세 번째 차원은 1번 반복. 즉, 첫 번째와 세 번째 차원은 그대로 유지하며 두 번째 차원은 5번 반복한다.
encoder_hidden_repeated.shape # (batch_size, seq_len, hidden_dim)
```#결과#```
torch.Size([2, 5, 3])
````````````■ 여기서 두 번째 차원이 Decoder의 seq_len이 되므로 encoder_hidden을 5 time step에 맞춰 복제한 것으로 볼 수 있다. 이렇게 repeat 함수를 이용해서 Decoder 내 여러 계층에 전달할 수 있다.
■ Decoder의 입력 시퀀스가 Decoder의 임베딩 계층을 통과한 결과의 shape은 다음과 같으며, encoder_hidden_repeated와 embedded를 연결하여 다음과 같이 Decoder의 순환 신경망 계층의 입력으로 만들어서 Encoder로부터 전달받은 context vector와 함께 순환 신경망 계층에 통과시키면 된다.
embedded.shape # (batch_size, seq_len, embedded)
```#결과#```
torch.Size([2, 5, 7])
````````````
## (batch_size, seq_len, hidden_dim + embedded_dim)
torch.cat((embedded, encoder_hidden_repeated), 2).shape
```#결과#```
torch.Size([2, 5, 10])
````````````
decoder_lstm_input = torch.cat((embedded, encoder_hidden_repeated), dim=2)
decoder_lstm_output, (decoder_hidden, decoder_cell) = lstm(decoder_lstm_input, (encoder_hidden, encoder_cell))■ 이때, encoder_hidden_repeated 텐서와 embedded 텐서를 연결한 결과의 형상을 보면, 마지막 차원은 embedding_dim + hidden_dim인 것을 확인할 수 있다.
■ Peeky Decoder의 초기화는 앞 절의 Decoder와 거의 같다. 다른 점은 마지막 차원이 다른 두 텐서를 연결하기 때문에 마지막 차원의 수가 이렇게 더해진다는 것이다.
1.3 일반적인 Seq2Seq 모델과 성능 비교
■ 일반적인 Seq2Seq 모델과 입력 시퀀스에 reverse를 적용한 Seq2Seq 모델 그리고 Peeky Decoder를 Decoder로 사용하는 Peeky Seq2Seq의 성능을 비교하고자 한다.
1.3.1 일반적인 Seq2Seq 모델
■ 먼저, 일반적인 Seq2Seq의 모델에 대한 Encoder, Decoder, Seq2Seq 클래스는 다음과 같이 구현할 수 있다. 아래 코드는 파이토치를 사용한 기본적인 Seq2Seq 모델 구현 예시이다.
class Encoder(nn.Module):
def __init__(self, src_vocab_size, embedding_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(src_vocab_size, embedding_dim, padding_idx=0) # 임베딩 계층
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True) # LSTM 계층
def forward(self, x):
embedded = self.embedding(x) # 입력값을 embedding_dim 차원으로
_, (hidden, cell) = self.lstm(embedded)
return hidden, cell
class Decoder(nn.Module):
def __init__(self, tar_vocab_size, embedding_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(tar_vocab_size, embedding_dim, padding_idx = 0) # 임베딩 계층
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first = True) # LSTM 계층
self.fc = nn.Linear(hidden_dim, tar_vocab_size) # Affine 계층 #
def forward(self, x, hidden, cell):
embedded = self.embedding(x)
output, (hidden, cell) = self.lstm(embedded, (hidden, cell))
output = self.fc(output)
return output, hidden, cell
class seq2seq(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src, trg):
hidden, cell = self.encoder(src)
output, _, _ = self.decoder(trg, hidden, cell)
return outputdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
encoder = Encoder(src_vocab_size, embedding_dim, hidden_dim)
decoder = Decoder(tar_vocab_size, embedding_dim, hidden_dim)
baseline_model = seq2seq(encoder, decoder).to(device)■ 먼저, Encoder는 입력 시퀀스(이 예에서는 영어 문장)를 처리하여 고정된 크기의 벡터, 즉 컨텍스트 벡터(context vector)로 압축하는 역할을 한다.
■ Encoder에서 src_vocab_size는 입력 시퀀스인 영어 단어 집합(vocabulary)의 크기를 의미한다.
■ Encoder의 임베딩 계층에서는 입력 언어인 영어의 단어 집합을 위한 임베딩 계층이다. 단어 집합 내에서 0번 인덱스에 해당하는 토큰이 패딩 토큰이므로 임베딩 계층에 padding_idx = 0으로 지정한다.
■ Encoder에서는 입력 x가 들어오면 임베딩 계층을 통해 고정 길이의 임베딩 벡터로 변환된다. 이때 변환된 임베딩 차원 수는 embedding_dim이다.
■ 그다음, LSTM 계층이 임베딩된 시퀀스를 받아 은닉 상태와 셀 상태를 생성한다. LSTM 계층을 사용할 경우 Encoder가 Decoder에 전달할 context vector는 Encoder가 생성한 은닉 상태와 셀 상태이다.
■ 순환 신경망 계층으로 LSTM 계층을 사용한다면 이 두 개의 값이 입력 시퀀스 전체의 정보를 압축한 context vector 역할을 한다. Encoder 클래스에서는 위와 같이 Encoder의 forward( )에서 계산된 context vector를 반환해야 한다.
■ Decoder에서 tar_vocab_size는 출력(타깃) 시퀀스인 프랑스어 단어 집합의 크기를 의미한다.
■ Decoder의 임베딩 계층은 타깃 언어인 프랑스어 단어 집합을 위한 임베딩 계층이다.
■ Decoder의 forward( ) 메서드에서는 초기 Decoder의 Encoder에서 받은 은닉 및 셀 상태와 Decoder의 입력 시퀀스 x로 출력 시퀀스를 생성하고,
■ 이후에는 첫 번째 출력 결과를 기반으로 Decoder의 은닉 상태와 셀 상태를 업데이트해가면서 이후 시점들에 대한 출력 시퀀스를 생성한다.
■ 이렇게 일반적인 Decoder의 순환 신경망 계층은 Encoder의 context vector를 간접적으로 전달받아 사용한다.
■ 시퀀스를 입력으로 넣어서 시퀀스를 생생하는 번역 문제이므로 모든 시점의 출력 시퀀스(output)을 반환해야 한다.
■ Decoder의 순환 신경망 계층에서 반환된 output은 완전 연결 계층(Affine 계층 또는 Dense 계층이라고도 함)을 통해 타겟 단어 집합의 크기의 차원으로 변환된다.
■ Seq2Seq 클래스는 전체 모델의 구조를 담당하며, Encoder와 Decoder를 결합하는 방법은 생성자에서 외부로부터 미리 생성된 encoder와 decoder 인스턴스를 받은 다음, Seq2Seq 클래스의 인스턴스가 호출될 때 Seq2Seq 클래스이 forward( ) 메서드를 통해서 결합된다.
■ 여기서 입력 시퀀스인 영어를 입력으로 받은 Encoder로부터 context vector를 반환받고, 이 context vector와 Decoder의 입력인 프랑스어를 입력으로 넣어서 시퀀스를 생성한다.
■ 여기서 Decoder의 예측 점수인 output만 반환한다. 이 output은 손실(loss)을 계산하는 데 사용된다.
1.3.2 반전(reverse)시킨 입력 데이터를 사용하는 Seq2Seq 모델
■ 이 방법은 1.1에서 본 것처럼 입력 시퀀스를 뒤집어서 데이터셋과 데이터로더를 만들고 1.3.1의 Encoder, Decoder, Seq2Seq 클래스를 그대로 사용하면 된다.
# 입력 시퀀스만 순서 반전
encoder_reverse_input = texts_to_reverse_sequences(en_input, src_vocab)
decoder_input = texts_to_sequences(fra_input, tar_vocab)
decoder_target = texts_to_sequences(fra_output,tar_vocab)
import numpy as np
def pad_sequences(sents):
max_len = max([len(sent) for sent in sents]) # 입력으로 들어온 리스트의 원소 중 가장 길이가 긴 것을 최대 길이로 지정
pad_result = np.zeros((len(sents), max_len), dtype = int) # 행은 정수 시퀀스의 총 개수, 열은 최대 길이, 정수 인덱스이므로 타입은 int
for idx, sent in enumerate(sents):
if len(sent) != 0: pad_result[idx, : len(sent)] = np.array(sent) # 패딩 처리 # np.array(sent)로 채워지지 않는 원소는 0
return pad_result
# 패딩 처리
encoder_input = pad_sequences(encoder_reverse_input)
decoder_input = pad_sequences(decoder_input)
decoder_target = pad_sequences(decoder_target)
...,
...,
reverse_encoder = Encoder(src_vocab_size,embedding_dim, hidden_dim)
decoder = Decoder(tar_vocab_size,embedding_dim, hidden_dim)
reverse_model = seq2seq(reverse_encoder, decoder).to(device)1.3.3 Peeky Decoder를 사용하는 Seq2Seq 모델
■ Peeky Decoder의 핵심 중 하나는 Encoder로부터 전달받은 context vector를 Decoder 내의 여러 계층에 전달한다는 것이다. 하나의 결과를 다수의 계층에 전달하기 위해서 생각할 수 있는 방법 중 하나는 하나를 다수의 개수로 복제하는 것이다.
■ 정확하게는 하나의 시점을 여러 개의 시점으로 복제해야 한다. Encoder에서 생성된 마지막 시점의 hidden state의 크기는 [1, batch_size, hidden_dim]이다. 여기에 시퀀스의 길이. 즉, time steps에 해당되는 새로운 축(차원)을 확장해주면 된다.
■ 이러한 복제를 하기위해서는 1.2에서 본 파이토치의 repeat와 expand 함수를 이용하면 된다. 예를 들어 다음과 같은 1차원 텐서 x가 있다고 하자.
x = torch.tensor([1, 2, 3, 4])
x.shape, x
```#결과#```
(torch.Size([4]), tensor([1, 2, 3, 4]))
````````````- 원본 x의 shape은 (4, )라고 볼 수 있다.
■ 다음과 같이 repeat(3, 2)를 적용하면, 파이토치는 (4, )인 x를 (1, 4)로 취급(=torch.tensor([[1, 2, 3, 4]]))한 뒤, 첫 번째 차원(dim=0)을 3번 반복하고, 두 번째 차원(dim=1)을 2번 반복한다. 그래서 shape이 (1*3, 4*2) = (3, 8)이 된다.
- 1D 텐서의 경우 [n]이 아닌 [1, n]으로 간주한다.
x.repeat(3, 2).shape, x.repeat(3, 2)
```#결과#```
(torch.Size([3, 8]),
tensor([[1, 2, 3, 4, 1, 2, 3, 4],
[1, 2, 3, 4, 1, 2, 3, 4],
[1, 2, 3, 4, 1, 2, 3, 4]]))
````````````■ 이번에는 세 번째 차원(dim=2)을 늘려 repeat를 적용할 경우, 파이토치는 텐서의 차원 수에 맞추기 위해서 1차원을 늘려 (1, 4)에서 (1, 1, 4)로 취급한다.
■ 첫 번째 차원에는 3번, 두 번째 차원에는 2번, 세 번째 차원에는 1번 반복하므로 shape은 (1*3, 1*2 , 4*1) = (3, 2, 4)가 된다.
x.repeat(3, 2, 1).shape, x.repeat(3, 2, 1)
```#결과#```
(torch.Size([3, 2, 4]),
tensor([[[1, 2, 3, 4],
[1, 2, 3, 4]],
[[1, 2, 3, 4],
[1, 2, 3, 4]],
[[1, 2, 3, 4],
[1, 2, 3, 4]]]))
````````````■ repeat는 위와 같이 텐서의 차원의 데이터를 반복한다. expand도 특정 텐서를 반복하여 생성하지만, 차원의 수가 1인 차원에만 적용할 수 있다. 예를 들어, 다음과 같은 원본 텐서 x가 있다고 했을 때
x = torch.tensor([[1], [2], [3]])
x.shape, x
```#결과#```
(torch.Size([3, 1]),
tensor([[1],
[2],
[3]]))
````````````■ expand는 차원의 수가 1인 차원에만 적용할 수 있다고 하였다. 그러므로 이 예에서 반복은 다음과 같이 차원의 수가 1인 두 번째 차원만 가능하다.
x.expand(3, 4).shape, x.expand(3, 4)
```#결과#```
(torch.Size([3, 4]),
tensor([[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3]]))
````````````
x.expand(-1, 2).shape, x.expand(-1, 2)
```#결과#```
(torch.Size([3, 2]),
tensor([[1, 1],
[2, 2],
[3, 3]]))
````````````
x.expand(3, -1).shape, x.expand(3, -1)
```#결과#```
(torch.Size([3, 1]),
tensor([[1],
[2],
[3]]))
````````````- 이렇게 -1을 차원에 지정하면 해당 차원의 수는 그대로 유지한다는 의미이다.
■ [3, 1]의 크기를 갖는 x를 차원의 수가 1인 두 번째 차원(dim=1)에 대해서만 4번 반복하는 것을 볼 수 있다. 차원의 수가 1이 아닌 첫 번째 차원의 수가 동일하지 않으면 다음과 같은 오류가 발생한다.
x.expand(2, 4).shape
```#결과#```
RuntimeError Traceback (most recent call last)
Cell In[399], line 1
----> 1 x.expand(2, 4).shape
RuntimeError: The expanded size of the tensor (2) must match the existing size (3) at non-singleton dimension 0. Target sizes: [2, 4]. Tensor sizes: [3, 1]
````````````■ 이 예에서는 Decoder 내 각 시점의 LSTM 계층과 Affine 계층에 모두 전달하고자 한다. 이를 구현하기 위해, 시점별 각 계층의 입력 벡터와 Encoder로부터 받은 context vector를 연결(concatenate)하여 해당 계층의 입력으로 사용한다.
■ 이렇게 함으로써 Decoder 내에서 원본 입력 문맥 전체의 정보(Encoder로부터 전달받은 context vector)를 참고하여 출력 시퀀스를 생성할 수 있게 된다.
■ Encoder의 context vector를 Decoder의 모든 LSTM 계층과 Affine 계층에 직접 전달하는 구조를 갖는 Peeky Decoder 클래스는 다음과 같다.
class PeekyDecoder(nn.Module):
def __init__(self, tar_vocab_size, embedding_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(tar_vocab_size, embedding_dim, padding_idx = 0)
self.lstm = nn.LSTM(embedding_dim+hidden_dim, hidden_dim, batch_first = True)
self.fc = nn.Linear(2*hidden_dim, tar_vocab_size)
def forward(self, x, hidden, cell):
# 현재 x.shape: [batch_size, sequence_length]
embedded = self.embedding(x)
# 현재 embedded.shape: [batch_size, sequence_length, embedding_dim]
h_context = hidden.squeeze() # 또는 shape이 [1, batch_size, hidden_dim]이므로 encoder_hidden[0]
# 현재 h_context.shape: [batch_size, hidden_dim]
# 인코더가 전달한 은닉 상태를 다른 계층에도 전달하기 위해 seq_len = time_steps만큼 복제
# 먼저, h_context에 시계열 길이(seq_len) = time steps 차원을 두 번째 차원으로 만들어주고, 시계열 길이에 맞게 복제
# 이는, 다른 계층에도 전달하기 위함
batch_size, seq_len, _ = embedded.shape
h_repeated = h_context.unsqueeze(1).repeat(1, seq_len, 1) # [batch_size, seq_len, hidden_dim]
# 디코더의 lstm 계층의 입력으로 들어오는 머시기 -> 말 다듬기
lstm_input = torch.cat((h_repeated, embedded), dim=2) # [batch_size, seq_len, embedding_dim + hidden_dim]
# 근데 왜 이렇게 차원을 합친걸까
# 디코더의 lstm 계층 통과 -> 말 다듬기
lstm_output, (hidden, cell) = self.lstm(lstm_input, (hidden, cell))
# 현재 lstm_output.shape: [batch_size, seq_len, hidden_dim]
# 이 lstm_output과 인코더가 전달한 은닉 상태를 결합해서 fc layer의 입력으로 -> 말ㄷ ㅏ듬기
fc_input = torch.cat((h_repeated, lstm_output), dim=2) # [batch_size, seq_len, hidden_dim + hidden_dim]
# 디코더의 fc 계층 |통과
output = self.fc(fc_input)
# 현재 output.shape: [batch_size, sequence_length, tar_vocab_size]
return output, hidden, cell- Encoder, Decoder의 순환 신경망 계층이 단층이라고 가정하였다.
■ 먼저, 생성자 함수 부분을 보면, LSTM 계층과 완전 연결 계층의 입력 차원이 달라진 것을 볼 수 있다.
■ LSTM 계층의 입력 차원이 embedding_dim + hidden_dim인 것을 확인할 수 있다. 이는 각 time step에서 LSTM 계층이 입력으로 (1) 현재 타깃 단어의 임베딩 벡터와 (2) Encoder의 context vector를 연결(concatenate)하여 사용하기 위함이다.
■ 그리고 완전 연결 계층의 입력 차원이 2*hidden_dim인데, 이는 각 time step에서 FC 계층의 입력으로 (1) 해당 time step의 LSTM 출력(hidden state)과 (2) Encoder의 context vector(hidden state)를 연결하여 사용하기 때문이다.
- 이 예에서 Encoder와 Decoder의 LSTM 게층의 hidden_dim을 동일하게 설정하였기 때문에 2*dim으로 처리하였다.
■ 그다음 순전파 함수인 forward( ) 메서드를 보면, forward의 인수로 들어온 hidden 텐서에서 첫 번째 차원을 제거한다.
- 단방향 LSTM을 가정했으므로 hidden의 shape은 [1, batch_size, hidden_dim]이다.
- 여기에 squeeze()를 적용하여 hidden의 shape을 [batch_size, hidden_dim]으로 만들어준다.
■ batch_size, seq_len, _ = embedded.shape을 통해 배치 크기와 시퀀스 길이를 가져온다. 이는 [batch_size, hidden_dim] 텐서인 h_context에 seq_len 차원을 확장하기 위해서이다.
■ h_repeated = h_context.unsqueeze(1).repeat(1, seq_len, 1)은 Encoder의 context vector인 h_context를 Decoder의 각 time step에서 사용하기 위해 복제하는 과정이다.
- 이 예시에서 LSTM 계층은 batch_first = True이므로, 두 번째 차원을 확장시켜 seq_len 차원으로 사용한다. h_context.unsqueeze(1): [batch_size, hidden_dim] \( \rightarrow \) [batch_size, 1, hidden_dim]
- 그다음, repeat(1, seq_len, 1)을 통해 두 번째 차원(시퀀스 길이, seq_len = time steps)을 seq_len만큼 복제한다. \( \rightarrow \) [batch_size, seq_len, hidden_dim]
■ 이렇게 하는 이유는 Decoder의 시퀀스를 처리할 때마다 Encoder의 전체 문맥 정보(context vector)를 참고하기 위함이다.
■ lstm_input = torch.cat((h_repeated, embedded), dim=2)는 복제된 Encoder context(h_repeated)와 현재 time step의 단어 임베딩(embedded)을 마지막 차원을 따라 연결한다.
- lstm_input.shape: [batch_size, seq_len, hidden_dim + embedding_dim]
- 이는 seq_len의 시퀀스 길이를 갖는 각 배치 데이터에 대하여 각각 현재 입력 정보뿐만 아나라 Encoder의 전반적인 문맥 정보를 함께 고려하도록 하기 위함이다.
■ lstm_output, (hidden, cell) = self.lstm(lstm_input, (hidden, cell))을 통해 준비한 입력을 Decoder의 LSTM 계층에 통과시킨다.
■ fc_input = torch.cat((h_repeated, lstm_output), dim=2)은 다시 한번, 복제된 Encoder context(h_repeated)와 이번에는 Decoder의 출력(lstm_output)을 마지막 차원에 따라 연결한다.
- 이는 최종 단어 예측을 위한 FC 계층이 해당 time step의 Decoder LSTM (출력) 정보(=LSTM의 hidden state)뿐만 아니라 Encoder의 전반적인 문맥 정보를 다시 한번 직접 참고하도록 하기 위함이다.
- LSTM 계층들을 통과하며 희석될 수 있는 초기 context 정보를 보강하는 효과를 줄 수 있을 것이라 기대할 수 있다.
■ Peeky Decoder를 사용하는 Peeky Seq2Seq 모델을 만든 다음, 일반적인 Seq2Seq, 입력 시퀀스 반전 Seq2Seq 그리고 Peeky Seq2Seq의 검증 정확도를 비교한 결과는 다음과 같다.
encoder = Encoder(src_vocab_size,embedding_dim, hidden_dim)
peeky_decoder = PeekyDecoder(tar_vocab_size,embedding_dim, hidden_dim)
peeky_model = seq2seq(encoder, peeky_decoder).to(device)x = list(range(len(reverse_val_acc)))
plt.plot(x, baseline_val_acc, label='baseline', marker='o')
plt.plot(x, reverse_val_acc, label='reverse', marker='o')
plt.plot(x, peeky_val_acc, label='reverse+peeky', marker='o')
plt.xabel('epochs')
plt.ylabel('accuracy')
plt.legend(loc='best')
plt.grid(True)
plt.show()
■ 결과를 보면, 일반적인 Seq2Seq 모델에 Reverse, Reverse + Peeky Decoder를 적용할수록 성능이 향상되는 것을 확인할 수 있다.
■ Reverse는 단순히 입력 시퀀스 순서를 반전시키는 것이므로 계산에 큰 영향을 미치지 않는다. 반면, Peeky Decoder를 사용할 경우 계산량이 증가한다.
■ 계산량이 증가하는 이유는 (이 예에서는) Decoder의 LSTM 계층과 Affine 계층에도 Encoder의 context vector를 전달하기 위해, 두 텐서를 '연결(concatenate)'하게 되어 입력 차원이 기존보다 커지기 때문이다.
- 이 예에서는 두 텐서의 연결로 인해 다음과 깉이 입력 형상이 변경되었다.
- self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first = True)
\( \rightarrow \) self.lstm = nn.LSTM(embedding_dim+hidden_dim, hidden_dim, batch_first = True)
- self.fc = nn.Linear(hidden_dim, tar_vocab_size)
\( \rightarrow \) self.fc = nn.Linear(2*hidden_dim, tar_vocab_size)
■ 그러므로 Peeky Decoder를 사용할 경우, 순전파/역전파 시 필요한 계산량이 증가하는 것은 필연적이다.
'자연어처리' 카테고리의 다른 글
| 언어 모델의 평가 방법 - Perplexity, BLEU Score(Bilingual Evaluation Understudy Score) (0) | 2025.04.04 |
|---|---|
| 시퀀스투시퀀스(Sequence‑to‑Sequence, seq2seq) (4) (0) | 2025.04.02 |
| 시퀀스투시퀀스(Sequence‑to‑Sequence, seq2seq) (2) (0) | 2025.03.30 |
| LSTM, GRU (2) (0) | 2025.03.29 |
| LSTM, GRU (1) (0) | 2025.03.28 |


