1. Perplexity(PPL)
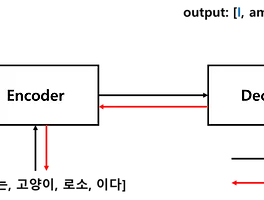
■ 시퀀스투시퀀스(Sequence‑to‑Sequence, seq2seq) (2)에서 언어 모델(Language Model)인 Decoder가 얼마나 정확하게 번역했는지 평가하는 번역 성능 지표로 Perplexity(PPL)를 사용했다.
1.1 Perplexity 의미
■ 입력 데이터가 여러 개인 경우 Perplexity(PPL)의 공식은 다음과 같다.

■ 계산된 perplexity 값의 해석은 '과거 단어 다음에 출현할 수 있는 단어의 후보 수'이다. 그러므로 값이 낮을수록 모델의 예측 성능이 좋은 것으로 간주할 수 있다.
- 만약 perplexity 값이 10이라면, 이는 과거 단어의 다음 단어로 출현할 수 있는 단어의 후보가 10개임을 의미한다.
- perplexity 값이 1.25라면, 이는 출현할 수 있는 단어의 후보가 1개 정도로 좁혀진 것을 의미한다.
- 그러므로 perplexity 값이 작아질수록 출현할 수 있는 단어의 후보 수가 줄어든 것이므로, 값이 작을수록 좋은 모델이라고 평가할 수 있다.
참고) 순환 신경망(RNN) (2)
순환 신경망(RNN) (2)
1. RNN 언어 모델(Recurrent Neural Network Language Model, RNNLM)■ RNN으로 만든 언어 모델을 RNN Language Model, RNNLM이라고 한다. 가장 단순한 RNNLM의 신경망 구조는 다음과 같다.■ RNN은 시점(time step)이라는
hyeon-jae.tistory.com
1.2 기계 번역 성능 지표로의 Perplexity
■ 기계 번역기에도 PPL을 사용할 수는 있지만, PPL은 번역의 성능을 직접적으로 반영하는 수치라 보기는 어렵다.
■ 왜냐하면, Perplexity(PPL)은 얼마나 자연스러운 문장을 생성했는지. 즉, 언어 모델이 “다음 토큰을 얼마나 잘 예측하는가”를 수치화한 지표로, 단어의 확률 분포만을 고려한다.
■ 하지만 기계번역의 성능은 원문(source)에서 목표문(target)으로 얼마나 정확하게 옮겼는지 '번역 품질'을 따져야 하기 때문에 PPL만으로는 한계가 있다.
■ 즉, PPL은 “언어 모델로서 얼마나 자연스러운 문장을 만들 수 있는지”만 재는 지표이므로, “원문을 얼마나 정확·충실하게 번역했는지”를 평가하는 번역 성능 지표로 쓰기에는 적합하지 않다.
■ 기계 번역의 성능(번역의 품질)이 얼마나 뛰어난지 측정하기 위해 사용되는 대표적인 방법으로 BLEU(Bilingual Evaluation Understudy)가 있다.
2. BLEU Score(Bilingual Evaluation Understudy Score)
■ BLEU Score는 PPL처럼 확률이 아니라, 실제 출력과 참조(reference) 간의 텍스트 일치를 수치화하기 때문에 기계 번역 품질 평가에 더욱 적합하다.
■ BLEU 스코어는 기계 번역 결과와 사람이 번역한 참조 번역 간의 유사도를 측정하는 평가 지표로 사람이 번역한 것과 유사할수록 더 좋은 기계 번역으로 간주한다.
■ 그러므로, 기계 번역의 품질을 판단하려면 번역된 문장과 정답으로 비교되는 문장이 존재해야 한다. 이때 성능을 측정하는 측정 기준은 n-gram에 기반한다.
■ BLEU는 완벽한 방법이라고는 할 수 없지만 언어에 구애받지 않으며, 계산 속도가 빠르다. 또한, PPL과 달리 값이 높을수록 성능이 좋음을 의미한다.
2.1 BLEU(Bilingual Evaluation Understudy)
■ 먼저, 기계 번역 결과가 참조 번역에 가까울수록(유사할수록) 높은 점수를 주는 직관적인 평가 방법들을 살펴본 뒤, 이러한 방법들의 한계를 보완하면서 최종적으로 사용하는 BLEU 평가 방식을 완성해 나간다.
2.1.1 Unigram Precision - 단어 개수 카운트로 측정하기
■ 한국어-영어 번역기의 성능을 측정한다고 가정하자. 기계 번역 문장을 각각 Candidate1, 2라고 하고, 세 명의 사람에게 한국어를 영작한 세 개의 번역 문장을 각각 Reference 1, 2, 3이라고 하자.


■ Candidate 1, 2를 Reference 1, 2, 3과 비교하여 기계 번역의 성능을 측정하고자 한다.
■ 가장 기본적인 성능 평가 방법은 기계 번역문이 참조 번역문과 얼마나 많은 단어나 구절이 겹치는지 측정하는 것이다.
■ 이 예에서 Candidate 1은 세 개의 Reference 문장들과 겹치는 부분이 많지만, Candidate 2는 그렇지 않은 것을 볼 수 있다. 이에 대한 성능 측정 방법으로 유니그램 정밀도(Unigram Precision)이 있다.
■ 유니그램 정밀도는 Reference에 등장하는 Candidate 단어(유니그램)의 수를 Candidate에 등장하는 총 단어의 수로 나누어 계산한다. 이를 식으로 표현하면 다음과 같다.
\( \text{Unigram Precision} = \dfrac{\text{the number of 'Ca' words(unigrams) which occur in any 'Ref'}}{\text{the total number of words in the 'Ca'}} \)
■ 대소문자 구분은 없다고 했을 때,
- Ca 1의 'it is a guide to action'은 Ref 1에서
- 'which'는 Ref 2에서
- 'ensures that the militrary'는 Ref 1에서
- 'always'는 Ref 2와 Ref 3에서
- 'commands'는 Ref 1에서
- 'of the party'는 Ref 2에서 등장한다.
■ Ca1에 있는 단어 중 Ref 1, 2, 3 어디에도 등장하지 않은 단어는 obeys 뿐이다. 반면, Ca2는 Ca1과 비교하여 상대적으로 Ref 1, 2, 3에 등장한 단어들이 적다.
■ 유니그램 정밀도 계산 방법에 따르면 Ca 1의 유니그램 정밀도는 \( \dfrac{17}{18} \), Ca 2의 유니그램 정밀도는 \( \dfrac{8}{14} \)이다. 이는 Ca 1이 Ca 2보다 더 좋은 번역 문장임을 의미한다.
2.1.2 Modified Unigram Precision - 중복을 제거하여 보정하기
■ 위와 같은 유니그램 정밀도는 완벽해 보이지만 허점이 있다. 예를 들어 다음과 같은 기계 번역 문장과 사람이 번역한 문장이 있다고 했을 때,

■ Example 2의 Candidate는 the가 7개 등장하는 터무니 없는 기계 번역이다.
■ 그러나 이 기계 번역은 유니그램 정밀도에 따르면, 기계 번역 Ca 내의 유니그램(the)이 모두 Ref에 속하므로 7/7 = 1이라는 완벽한 정밀도를 가지게 된다는, 즉 Ca가 완벽하다는 평가를 받게 된다.
■ 이러한 문제는 Ca 문장의 특정 단어가 중복되어 등장했기 때문이다.
■ 이를 보정하려면, 정밀도를 계산할 때 참조 문장(Ref)과 매칭하며 카운트하는 과정에서 기계 번역 문장(Ca)의 단어(여기서는 유니그램)가 이미 Ref에서 한 번 매칭된 적이 있는지를 확인하는 과정이 필요하다.
■ 즉, 유니그램 정밀도 계산 시 분자에 해당하는 카운트 방식을 수정할 필요가 있다. 수정 방식은 Ca에 있는 특정 유니그램이 Ref에서 이미 매칭된 횟수를 고려하는 방식이다.
■ 이를 위해 Max_Ref_Count라는 값을 도입한다. 이 값은 특정 유니그램이 하나의 Ref 내에서 최대 몇 번 등장했는지를 카운트한 값이다.
■ 그리고 다음과 같이 기존의 단순 카운트한 값과 Max_Ref_Count값을 비교해서 둘 중 더 작은 값을 최종 카운트 값으로 사용한다.
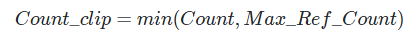
■ 위와 같은 수정 방식은 Ca의 유니그램을 카운트할 때, 해당 유니그램이 하나의 Ref에 존재하는 최대 카운트를 초과하면 그 이후로는 더 이상 카운트하지 않는다는 의미이다.
■ 이러한 카운트 방식(count clip)을 사용하여 분자를 계산한 정밀도를 보정된 유니그램 정밀도(Modified Unigram Precision)라고 한다. 식은 다음과 같다.
\( \text{Modified Unigram Precision} = \dfrac{\sum_{\text{unigram} \in \text{Candidate}} \text{Count}_{\text{clip}}(\text{unigram})}{\sum_{\text{unigram} \in \text{Candidate}} \text{Count}(\text{unigram})}\)
- 분모는 이전과 동일하게 Ca의 모든 유니그램에 대해 각각 카운트하고 모두 더한 값을 사용한다.
■ 예를 들어, Example 2에서 Ca는 'the'만 7번 등장하는 문장이므로 Count('the') = 7이다.
■ 그리고 Ca의 'the'는 Ref 1에서 총 2번 등장했으므로
Count_clip = min(Count('the')=7, Max_Ref_Count=2) = 2로 'the'라는 유니그램의 카운트는 2로 보정된다.
■ Ca의 기존 유니그램 정밀도는 7/7 = 1이었으나 보정된 유니그램 정밀도는 2/7로 계산된다.
■ 다른 예로, Example 1에서 Ca 1의 보정된 유니그램 정밀도를 계산하면, 기존의 유니그램 정밀도의 계산 결과와 동일하게 17/18이 계산된다. 그러나 이 결과를 얻는 과정은 다르다.
■ Ca 1에서 'the'는 3번 등장하지만, Ref 2와 Ref 3에서 'the'는 4번 등장하므로 'the'는 3으로 카운트된다. 'the' 외에 Ca 1의 모든 유니그램은 전부 1개씩 등장하므로 보정 전과 동일하게 카운트한다.
- 'the'에 대한 정밀도는 3/18이며, 나머지 유니그램 중 'obeys'는 모든 Ref에 등장하지 않으므로 제외된다.
- 따라서 전체 18개 유니그램 중 'obeys' 1개와 'the' 3개를 제외한 14개는 모두 Ref에 존재하고, 14개는 각각 1개씩 등장하므로 계산하면 14/18이 된다.
- 이를 더하면 총 17/18이 되어 보정된 유니그램 정밀도로 계산한 값은 17/18이 된다.
2.1.3 순서를 고려하기 위해 n-gram으로 확장
■ 유니그램 정밀도처럼 각 단어의 빈도수로 접근하는 방법은 단어의 순서를 고려하지 않는다는 특징이 있다.
■ 예를 들어 Example 1에 다음과 같은 Ca 3이라는 새로운 문장을 추가해보자.
Candidate3:the that military a is It guide ensures which to commands the of action
obeys always party the.
■ Ca 3는 Ca 1의 모든 유니그램의 순서를 랜덤으로 섞은 문장이라서 문법적으로 완전히 잘못된 문장이다.
■ 그럼에도 불구하고 Ref 1, 2, 3과 비교하여 유니그램 정밀도를 계산하면 Ca 1과 Ca 3의 정밀도는 동일하다.
■ 이는 유니그램 정밀도가 각 단어(유니그램)의 등장 여부만 계산하고 순서는 전혀 고려하지 않기 때문이다.
■ N-gram은 이러한 문제를 해결하기 위한 효과적인 방법이다. 왜냐하면 단일 단어(유니그램)만 고려하는 것이 아니라, 연속된 n개 단어를 고려하기 때문에 연속된 단어 시퀀스를 어느 정도 평가할 수 있기 때문이다.
- 카운트 단위가 2개, 3개, 4개냐에 따라 2-gram precision, 3-gram precision, 4-gram precision이라고 부르기도 한다.
■ 예를 들어, Example 2에 다음과 같은 Ca 2를 추가한 다음, 바이그램(Bigram, 2-gram) 단위로 카운트하여 바이그램 정밀도를 계산해보자.
Ca 2: the cat the cat on the mat
■ Ca 2 바이그램의 Count와 Count_clip은 다음과 같다.
| 2-gram precision | the cat | cat the | cat on | on the | the mat | SUM |
| Count | 2 | 1 | 1 | 1 | 1 | 6 |
| Count_clip | 1 | 0 | 1 | 1 | 1 | 4 |
- Ca 2에 바이그램을 적용하면 'the cat'은 2번 등장, 'cat the'는 1번 등장, 'cat on'은 1번 등장, 'on the'는 1번 등장, 'the mat'은 1번 등장한다. 그러므로 단순 바이그램 카운트를 적용했을 때, Ca 2에 있는 모든 바이그램의 수를 합하면 총 6개가 된다.
- 'the cat'은 Ref 1에서 1번 등장, Ref 2에서 0번 등장하므로 참조 문장의 최대 등장 횟수인 Max_Ref_Count는 1이다. 그리고 Ca 2에서 'the cat'은 2번 등장하므로 클리핑된 카운트 값인 Count_clip = min(1, 2) = 1이 된다.
- 이러한 방식으로 나머지 바이그램에 대해서 Count_clip을 계산하면 위의 표와 같다.
■ 위의 표를 토대로 Ca 2의 보정된 바이그램 정밀도는 4/6이 된다. Ca 1의 경우 'the the'의 단순 바이그램 카운트는 6이지만, Count_clip이 0이기 때문에 Ca 1의 보정된 바이그램 정밀도는 0이 된다.
■ modified unigram precision를 식으로 정의했을 때 다음과 같았다.
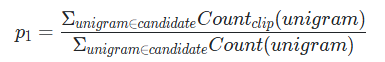
■ 이 식을 n-gram으로 확장한 식은 다음과 같으며, modified n-gram precision이라고 부른다.

- 유니그램 정밀도에서는 n이 1이므로 \( p_1 \)로 표현하지만,
- 일반화된 식에서는 \( p_n \)으로 표현한다.
■ BLEU는 다양한 크기의 n-gram에 대해 보정된 정밀도를 조합하여 최종 점수를 산출한다. 단, 각 n-gram의 크기(n=1, 2, ... N)에 대한 정밀도 \( p_n \)은 서로 다른 값을 가지므로, BLEU는 다음과 같이 가중치 부여한 로그 기하평균을 이용해서 보정된 정밀도 \( p_1, \; p_2, \; \cdots, \; p_n \)를 모두 조합하여 계산한다.
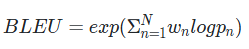
- \( p_n \)은 각 gram의 보정된 정밀도이다.
- \( N \)은 n-gram에서 n의 값이다. 보통은 N = 4로 설정한다.
-- N이 4라는 것은 \( p_1, \; p_2, \; p_3, \; p_4 \)를 사용한다는 것을 의미한다.
- \( w_n \)은 각 gram의 보정된 정밀도에 대한 서로 다른 가중치이다. 이 가중치의 합은 1로 한다.
-- 예를 들어 \( N = 4\)라고 할 때, \( p_1, \; p_2, \; p_3, \; p_4 \)에 대해서 동일한 가중치를 주고자한다면, \( \text{weights} = (w_1, w_2, w_3, w_4) = (0.25, 0.25, 0.25, 0.25) \)로 모두 0.25를 적용할 수 있다.
-- 만약, 바이그램(2-gram) 정밀도만 보려면 가중치를 \( \text{weights} = (w_1, w_2, w_3, w_4) = (0, 1, 0, 0) \)으로 설정하면 된다.
2.1.4 Brevity Penalty - 짧은 문장 길이에 대한 페널티
■ 2.1.3에서처럼 n-gram을 사용해 단어 순서를 반영하더라도, 여전히 하나의 문제가 남아 있다. 바로 Ca 문장의 길이에 따라 BLEU 점수가 지나치게 영향을 받을 수 있다는 점이다.
■ 예를 들어, 아래와 같이 길이가 짧은 Ca가 있다고 했을 때

■ 보정된 유니그램 정밀도와 보정된 바이그램 정밀도는 각각 2/2, 1/1 로 두 정밀도 모두 1이라는 높은 정밀도가 계산된다.
■ Ca가 제대로 된 번역이 아님에도 불구하고 문장의 길이가 짧다는 이유로 높은 점수를 받게 되는 것이다.
■ 그러므로 Ref보다 문장의 길이가 짧은 Ca에 대해서는 점수에 페널티를 주게 되는데, 이를 Brevity Penalty라고 한다.
cf) 반대로 Ca의 길이가 Ref보다 긴 경우가 존재할 수 있다. 다만 이 경우에는 n-gram 기반 평가로 인해 페널티가 반영되고 있다.
■ Brevity Penalty는 2.1.3에서 세운 BLEU 식에 페널티 PB를 곱하는 방식으로 사용한다.
■ Brevity Penalty를 반영한 최종 BLEU 식은 다음과 같다.

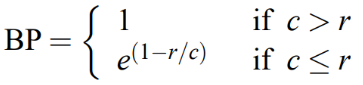
- c는 Ca의 길이
- r은 Ca와 가장 길이 차이가 작은 Ref의 길이
-- Ref가 여러 개일 수 있으므로 r은 모든 Ref들 중에서 Ca와 가장 길이 차이가 작은 Ref의 길이로 한다.
-- 서로 다른 길이의 Ref일 때, Ca와 길이 차이가 동일한 경우에는 더 작은 길이의 Ref를 선택한다.
-- 예를 들어 Ca의 길이가 10이라고 했을 때, Ref 1, 2의 길이가 각각 9와 10이라면, Ca와 Ref 1, Ca와 Ref 2의 길이 차이는 동일하게 1이지만, 더 작은 길이의 Ref 1을 선택한다.
■ 만약, Ca와 길이가 정확히 동일한 Ref가 있다면, 길이 차이가 0이므로 가장 좋은 매치라고 볼 수 있다.
3. BLEU Score의 한계와 대안 지표들
■ BLEU 스코어의 가장 큰 한계는 단순히 n-gram의 일치 여부만을 고려하기 때문에 문장의 의미나 문법 구조를 충분히 반영하지 못한다는 점이다.
■ 예를 들어, “The cat sat on the mat”과 “On the mat sat the cat”처럼 의미는 같지만 어순이 다른 문장은 n-gram 일치도를 기반으로 하는 BLEU 스코어에서 큰 차이를 보일 수 있다.
■ 또한, BLEU는 참조 번역의 품질과 다양성에 크게 영향을 받기 때문에 참조 번역이 부족하거나 품질이 낮다면, 평가 결과 역시 신뢰하기 어려워진다.
■ 이러한 BLEU 점수의 한계를 극복하기 위해 아래와 같이 다양한 대안 평가 지표들이 제안되었다.

■ METEOR, TER, NIST 등은 BLEU의 단점을 보완하고, 문장의 의미나 문법적 구조를 고려하여 보다 정교한 평가를 수행한다.
■ 그러므로 기계 번역의 품질을 보다 정확하게 평가하기 위해서는 BLEU 점수와 함께 다른 대안적 평가 지표들도 활용하는 것이 좋다.
'자연어처리' 카테고리의 다른 글
| 어텐션(Attention) (2) (0) | 2025.04.07 |
|---|---|
| 어텐션(Attention) (1) (0) | 2025.04.06 |
| 시퀀스투시퀀스(Sequence‑to‑Sequence, seq2seq) (4) (0) | 2025.04.02 |
| 시퀀스투시퀀스(Sequence‑to‑Sequence, seq2seq) (3) (0) | 2025.04.01 |
| 시퀀스투시퀀스(Sequence‑to‑Sequence, seq2seq) (2) (0) | 2025.03.30 |