■ LLaMA와 같은 오픈소스 LLM들은 상당한 발전을 이루었음에도, 외부 도구(API)를 사용하여 user instruction을 수행하는 "tool-use" 능력에서는 여전히 큰 한계를 보인다.
■ 저자들은 그 이유가 현재의 instruction tuning이 주로 기본적인 language tasks에 집중해 왔고, tool use 영역을 충분히 다루지 못했기 때문이라고 본다.
■ 이는 ChatGPT와 같은 closed-source SOTA LLMs의 뛰어난 tool use 능력과 대조된다. 논문에서는 이 격차를 해소하기 위해, tool use 관점에서의 데이터 구축, 모델 학습 및 평가를 포괄하는 프레임워크 ToolLLM을 소개한다.
■ 구체적으로 논문에서 제시하는 세 가지 솔루션은 ToolBench, ToolLLaMA, ToolEval이다.
■ ToolBench는 ChatGPT를 이용해 구축한 tool-use를 위한 instruction-tuning dataset이다.
■ ToolBench의 구축 과정은 세 단계로 나눌 수 있다.
- (1) API 수집: RapidAPI Hub에서 49개 카테고리에 걸친 16,464개의 실제 RESTful API를 수집한다.
- (2) instruction generation: ChatGPT에게 (1)에서 수집한 API들을 포함하는 다양한 instructions을 생성하게 한다. 여기에는 single-tool뿐 아니라 multi-tool 사용 시나리오도 포함된다.
- (3) solution path annotation: 각 instruction에 대해 유효한 solution path (chain of API calls)를 ChatGPT로 탐색하여 annotate한다.
- 또한, 논문에서는 LLM의 추론 능력을 향상시키기 위한 depth-first search-based decision tree (DFSDT) 알고리즘을 제안하며, 이 알고리즘을 통해 LLM이 여러 추론 경로를 평가하고 탐색 공간을 확장할 수 있다고 설명한다.
■ ToolEval은 LLM의 tool-use capabilities을 평가하기 위한 automatic evaluator이다.
■ ToolBench로 LLaMA를 파인튜닝하여 ToolLLaMA라는 LLM을 만들고, 각 instruction에 적절한 API를 추천하기 위한 neural API retriever를 이 모델에 결합한다.
■ 실험 결과, ToolLLaMA는 complex instructions을 수행하고 unseen APIs도 일반화할 수 있는 능력을 보여준다.
■ 성능 면에서 ChatGPT와 비견될 만한 수준을 달성했으며, tool-use dataset인 APIBench(즉, out-of-distribution dataset)에서 강한 zero-shot 일반화 성능을 나타냈다.

[2307.16789] ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Despite the advancements of open-source large language models (LLMs), e.g., LLaMA, they remain significantly limited in tool-use capabilities, i.e., using external tools (APIs) to fulfill human instructions. The reason is that current instruction tuning la
arxiv.org
1. INTRODUCTION
■ ChatGPT나 GPT-4와 같은 SOTA closed-source LLMs은 도구 활용에 있어 인상적인 역량을 입증했다.
■ 반면, LLaMA와 같은 오픈소스 LLM은 instruction tuning을 통해 다재다능한 능력을 갖추었음에도, 여전히 복잡한 인간의 지시를 이행하기 위해 도구와 적절히 상호작용하는 능력은 부족하다.
■ 저자들은 그 이유를 기존의 instruction tuning이 주로 기본적인 language tasks에만 focus를 두고, tool use 영역은 충분히 다뤄지지 않았기 때문이라고 주장한다.
■ 이전 연구들에서 tool use를 위한 instruction tuning data를 구축하려는 시도는 있었지만, 이들은 LLM의 tool use 능력을 충분히 이끌어내지 못했으며 다음과 같은 한계를 지닌다.
- (1) limited APIs: real-world APIs (예: REST API)을 다루지 않거나, 다루더라도 소수의 APIs만 고려한다.
- (2) constrained scenario:기존 연구들은 대체로 single tool만 사용하는 instructions에 한정되어 있다. 실제 환경에서는 multiple tools을 여러 단계에 걸쳐 조합해야 complex task를 해결할 수 있다.
- 게다가 특정 instruction에 적합한 API set을 사용자가 미리 지정한다고 가정하는 경우가 많은데, 대규모 실제 API 환경에서는 이러한 가정은 비현실적이다.
- (3) inferior planning and reasoning: 기존 연구들은 모델 추론을 위해 CoT 또는 ReAct를 채택했는데, CoT나 ReAct는 단일 경로로 사고하는 특성으로 인해 대규모 API 공간을 충분히 탐색하기 어려워 복잡한 instruction을 잘 처리하지 못한다.
■ 논문에서는 오픈소스 LLM의 tool use 능력을 이끌어내기 위해, 데이터 구축, 모델 훈련, 평가를 포함하는 general tool-use framework인 ToolLLM을 제안한다. 전반적인 프로세스는 Fig 1과 같다.
■ ChatGPT(gpt-3.5-turbo-16k)를 사용하여, high-quality instruction-tuning dataset ToolBench를 구축한다. ToolBench 구축 절차는 세 단계로 구성된다.

- (1) API Collection
- RapidAPI라는 실제 플랫폼에서 representational state transfer (REST) APIs을 수집한다. 이 APIs은 소셜 미디어, 전자 상거래, 날씨 등 49개의 다양한 카테고리에 걸쳐 있다.
- 각 API에 대해 RapidAPI로부터 기능 설명, 필수 파라미터, API call을 위한 코드 스니펫 등 API documents을 크롤링한다.
- 모델에게 이러한 내용을 학습시킴으로써, LLM은 학습 중에 보지 못한 새로운 API에 대해서도 일반화할 수 있다.
- (2) Instruction Generation
- 이 단계에서는 (1)에서 수집한 전체 API set에서 API를 샘플링한 다음, ChatGPT를 프롬프팅하여 해당 API에 대한 다양한 instructions을 생성한다.
- 여기에는 single-tool뿐 아니라 여러 tools을 조합해서 사용해야 하는 multi-tool scenarios이 포함되며, 이를 통해 모델이 single tool use뿐 아니라 여러 tools의 조합 및 활용까지 학습시킨다.
- (3) Solution Path Annotation
- solution path를 생성하는 과정에서 CoT나 ReAct는 단일 경로만을 따른다는 한계를 가져, LLM이 여러 추론 경로를 평가하거나, 잘못된 경로면 되돌리거나, 더 유망한 경로를 선택하는 방식의 사고 과정을 사실상 불가능하게 만든다.
- 이를 해결하기 위해 논문은 DFSDT(depth-first search-based decision tree)라는 새로운 추론 전략을 제안한다.
- 실험에서 DFSDT는 annotation efficiency를 크게 향상시키며, ReACT를 사용해서는 완수할 수 없는 complex instructions을 성공적으로 완료한다.
■ ToolEval은 LLM의 tool use 능력을 평가하기 위한 automatic evaluator로, 모델의 tool use 성능을 두 가지 지표로 평가한다.
- (1) pass rate: 제한된 예산 내에서, LLM이 instruction을 성공적으로 완수할 수 있는지를 측정.
- (2) win rate: 두 개의 solution path를 비교하여 품질과 유용성을 비교.
■ ToolBench로 LLaMA를 fine-tuning하여 만든 ToolLLaMA에 대해, ToolEval을 기반으로 평가한 몇 가지 핵심 결과는 다음과 같다.
- (1) ToolLLaMA는 single-tool 및 complex multi-tool instructions을 모두 처리할 수 있는 강력한 능력을 보였으며, Text-Davinci-003 및 Claude-2를 능가하고, teacher인 ChatGPT보다는 약간 뒤처지는 성능(Fig 2)을 달성했다.
- (2) DFSDT는 여러 개의 reasoning traces을 고려하여 탐색 공간을 넓히고 ReAct보다 훨씬 더 나은 성능을 달성했다.
- (3) neural API retriever는 대규모 API pool에서 사용자가 직접 적절한 API를 고를 필요를 덜어준다.
- 주어진 instruction에 대해 관련성 있는 API들을 추천하고, 이 추천 결과를 ToolLLaMA가 multi-round decision making에 활용하도록 한다. (Fig 1)
- 이 retriever는 대규모 API pool을 샅샅이 뒤져야 하는 상황에서도 ground truth에 가까운 API를 반환하는 검색 정밀도를 보인다.
- (4) ToolLLaMA는 out-of-distribution (OOD) dataset에서 강한 일반화 성능을 보이며, 해당 dataset(APIBench)의 어떠한 APIs나 instructions에 대해 학습되지 않았음에도 불구하고, 해당 데이터셋 전용으로 설계된 Gorilla와 비슷한 수준의 성능을 달성했다.
2. DATASET CONSTRUCTION
■ ToolBench의 구축 과정은 3단계(섹션 2.1, 2.2, 2.3)로 구성된다. 모든 절차는 ChatGPT(gpt-3.5-turbo-16k)를 기반으로 하여 최소한의 human supervision만을 필요로 하며, 새로운 API에 대해서도 쉽게 확장할 수 있다.
2.1 API COLLECTION
RapidAPI Hub
■ RapidAPI는 API 마켓플레이스로 스포츠, 금융, 날씨 등 49개의 카테고리가 있다.
■ 추가로 Chinese APIs, database APIs와 같은 500개 이상의 "collections"이라고 불리는 fine-grained categorization도 제공된다. 컬렉션에 속한 API들은 공통된 특성을 공유하며 비슷한 기능이나 목표를 가지고 있다.
Hierarchy of RapidAPI

■ Fig 3에서 볼 수 있듯이, 각 tool은 여러 개의 API로 구성될 수 있다.
■ 각 tool에 대해, tool의 name과 description, 호스트 url, 그리고 해당 tool에 속한 사용 가능한 모든 API를 크롤링한다.
■ 그리고 각 API에 대해서는 name, description, HTTP method, required parameters, optional parameters, request body, executable code snippets, 그리고 API call response 예시를 기록한다.
■ 이처럼 풍부하고 상세한 메타데이터는 LLM이 zero-shot 방식으로도 API를 이해하고 효과적으로 사용할 수 있게 하는 기반이 된다.
API Filtering
■ 저자들은 RapidAPI에서 처음에 10,853개의 tools (53,190개 API)를 수집하였으나, 이들 중에는 404 error나 기타 내부 에러를 반환하는 등 유지보수가 제대로 이루어지지 않은 API도 다수 포함되어 있다.
■ 그래서 ToolBench가 신뢰할 수 있고 정상 작동하는 API 집합이 되도록 필터링(Appendix A.1)을 적용했으며, 최종적으로 3,451개의 high-quality tools (16,464개 API)만을 남겼다.
2.2 INSTRUCTION GENERATION
■ 이전 연구들과 달리, 논문에서는 instruction generation 단계에서 다음 두 가지 측면에 중점을 둔다.
- (1) diversity: LLM이 광범위한 API 사용 시나리오를 처리하도록 학습시켜 일반화 능력과 robustness를 향상시키고자 한다.
- (2) multi-tool usage: 여러 도구의 연계 사용을 요구하는 경우가 많은 real-world situations을 반영하여, LLM의 실용성과 유연성을 높이고자 한다.
■ 저자들은 이 두 가지 목표를 위해, 처음부터 instructions을 브레인스토밍한 다음 관련 API를 찾는 대신, 서로 다른 API 조합을 샘플링하고 이들을 포함하는 다양한 instructions을 만드는 방법을 채택했다.
Generating Instructions for APIs
■ 전체 API 집합 \( \mathbb{S}_{API} \)에서, 매번 일부 API들의 부분집합 \( \mathbb{S}_{N}^{sub} = \{API_1, \cdots, API_N\} \)을 샘플링한다.
■ ChatGPT를 프롬프팅하여 이 API들의 기능을 이해하도록 한 다음, (1) \( \mathbb{S}_{N}^{sub} \)에 있는 API들을 활용하는 instructions \( \text{Inst}_*$ \)을 생성하고 (2) 각 instruction(\( \text{Inst}_* \))에 관련된 API들 \( \mathbb{S}_{*}^{rel} \subset \mathbb{S}_{N}^{sub} \)을 생성한다.
■ 즉, \( \{[\mathbb{S}_{1}^{rel}, \text{Inst}_1], \cdots,[\mathbb{S}_{N'}^{rel}, \text{Inst}_{N'}]\} \)를 생성하며, 여기서 \( N' \)은 생성된 인서턴스의 개수를 나타낸다.
■ 이 (instruction, relevant API) 쌍들은 API retriever를 학습시키는 데 사용된다. (섹션 3.1)
■ 이때, 모든 API와 그 조합의 대부분을 다루고 instructions의 다양성을 확보하기 위해 다양한 sampling strategies을 사용한다. (Sampling Strategies for Different Scenarios)
■ ChatGPT를 위한 프롬프트의 구성은 다음과 같다. (Appendix A.7)
- (1) instruction generation task에 대한 설명
- (2) ChatGPT가 API의 기능과 상호작용을 이해할 수 있도록 도움을 주는 \( \mathbb{S}_{N}^{sub} \)에 포함된 각 API의 문서
- (3) human experts이 작성한 세 개의 in-context seed examples \( \{seed_1, seed_2, seed_3\} \)로 구성된다.
- 각 seed examples은 human experts이 작성한 이상적인 instruction generation이다.
- 이 seed examples을 사용하는 이유는 in-context learning을 통해 ChatGPT의 행동을 보다 안정적으로 유도하기 위함이다.
- single-tool / multi-tool setting을 위해 각각 12개, 36개의 다양한 seed examples(\( \mathbb{S}_{seed} \))를 작성했으며, 매번 임의로 3개의 examples을 샘플링한다.
■ 생성 과정을 수식화하면 다음과 같다.
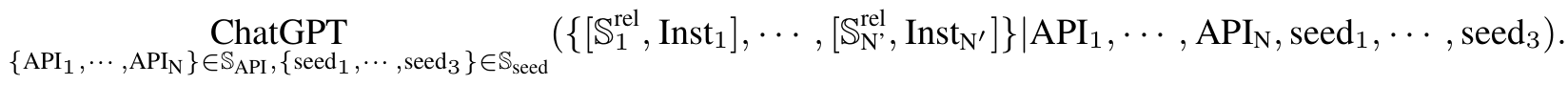
- ChatGPT는 샘플링된 API 집합 \( \{\text{API}_1, \cdots, \text{API}_N\} \in \mathbb{S}_{API} \)와 seed examples \( \{ seed_1, \cdots, seed_3 \} \in \mathbb{S}_{seed} \)를 입력으로 받아, \( N' \)개의 (relevant API, instruction) 쌍을 출력한다.
- 수식에서 볼 수 있듯이, instruction generation은 주어진 API 집합과 예시들을 조건부로 사용하여 진행된다.
Sampling Strategies for Different Scenarios
■ 저자들은 ChatGPT를 프롬프팅하여 복잡한 시나리오들(즉, insturctions)을 생성하게 하였다. (Generating Instructions for APIs)
■ 이때 시나리오의 난이도는 다음과 같은 세 가지 수준으로 구분하여 설계하였다.
■ I1 (single-tool instructions)은 특정 tool 하나만을 활용하는 단순한 시나리오이다. 각 도구를 순회하며 해당 도구에 속한 API들에 대한 instruction을 생성한다.
■ multi-tool setting에서는 문제가 더 복잡해진다. 그 이유는 RapidAPI 내 서로 다른 도구들 간의 직접적인 연관성이 희박하기 때문에, 단순히 전체 도구 집합에서 무작위로 도구들의 조합을 뽑을 경우 서로 무관한 도구들이 함께 선택되어 자연스러운 instruction으로 묶기 어려운 경우가 많기 때문이다.
■ 이러한 문제를 해결하기 위해 저자들은 RapidAPI의 계층 구조 정보를 활용한다.
■ 동일한 RapidAPI 카테고리 또는 컬렉션에 속하는 도구들은 일반적으로 기능과 목표 측면에서 서로 연관되어 있다.
■ 이에 따라 저자들은 동일한 카테고리나 컬렉션 안에서 2~5개의 도구를 무작위로 선택하고 각 도구에서 최대 3개의 API를 샘플링하여 instructions을 생성했다.
■ 같은 카테고리 안에서 생성된 것은 I2 (intra-category multi-tool instructions), 같은 컬렉션 안에서 생성된 것은 I3 (intra-collection multi-tool instructions)로 정의한다.
■ 마지막으로 저자들은 초기 instructions의 집합을 생성한 뒤, instruction에 연결된 API가 \( \mathbb{S}_{N}^{sub} \) 안에 존재하는지 확인하여, 존재하지 않는 API를 참조(즉, hallucination)하는 사례를 필터링했다.
■ 최종적으로, I1, I2, I3에 대해 각각 87,413개, 84,815개, 25,251개의 인스턴스를 포함하여 200k에 달하는 검증된 (instruction, relevant API) pairs을 수집했다.
2.3 SOLUTION PATH ANNOTATION
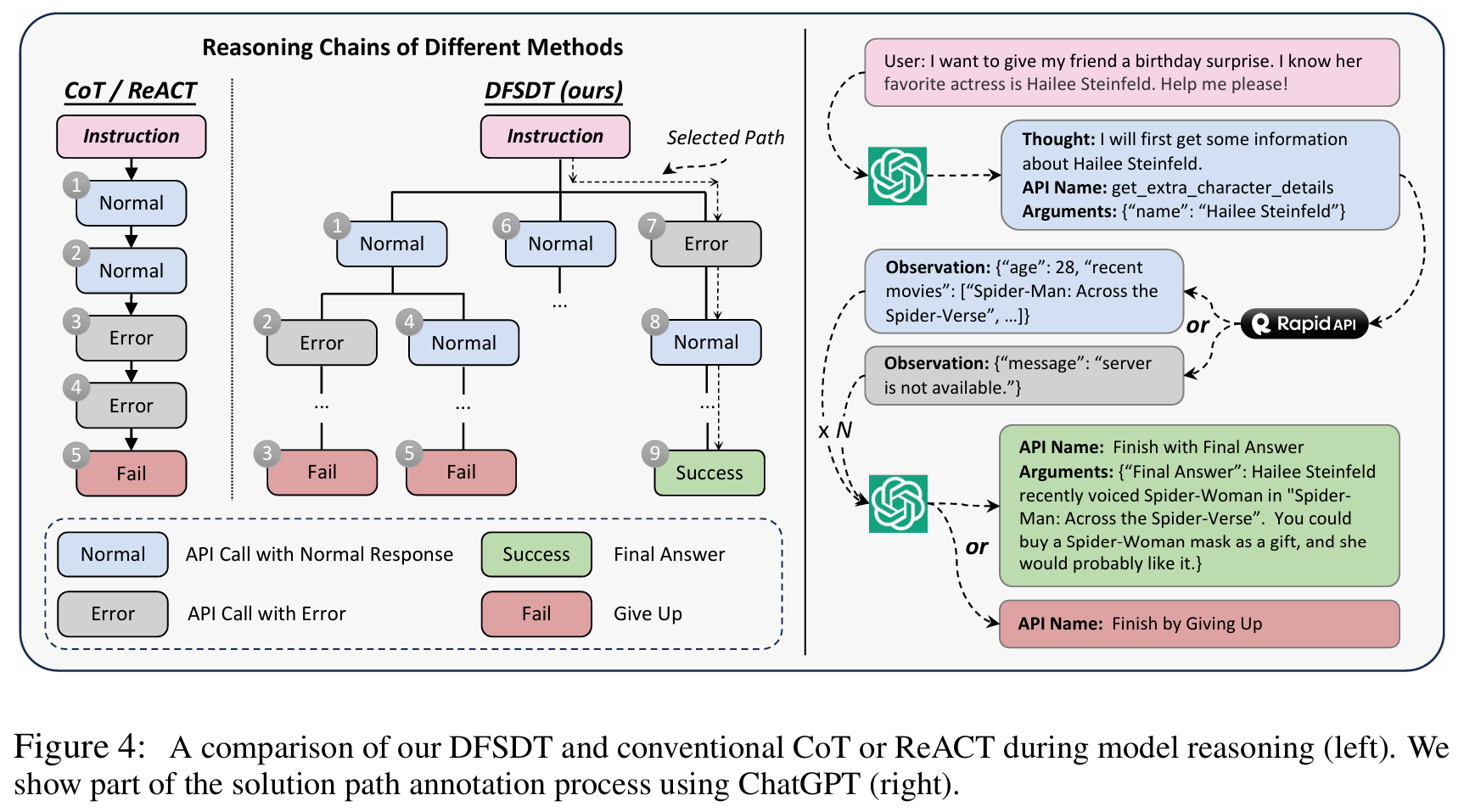
■ Fig 4에서 볼 수 있듯이, instruction \( \text{Inst}_* \)가 주어지면, 이를 ChatGPT를 프롬프팅하여 주어진 instruction을 해결할 수 있는 action sequence \( \{a_1, \cdots, a_N\} \)를 탐색하도록 한다.
■ 이러한 multi-step decision-making process는 multi-round conversation로 진행된다.
■ 매 라운드 \( t \)에서 모델은 이전 상호작용들(action과 해당 action에 대한 response, 여기서 \( r_* \)는 API의 응답) \( \text{ChatGPT}(a_t|\{a_1, r_1, \cdots, a_{t-1}, r_{t-1}\}, \text{Inst}_*) \)를 기반으로 next action \( a_t \)를 생성한다.
■ 각 \( a_t \)에 ChatGPT는 자신의 "thought", 사용할 API, 그리고 이 API에 전달할 파라미터를 구체적으로 명시해야 한다. 즉, \( a_t \)는 다음과 같은 형식을 가진다: "Thought: ···, API Name: ···, Parameters: ···"
■ 그리고 저자들은 ChatGPT의 function call 기능을 활용하기 위해, 각 API를 하나의 특수한 함수처럼 취급하고, 해당 API의 문서를 ChatGPT의 function field에 입력한다. 이런 방식으로 모델은 API를 호출하는 방법을 이해하게 된다.
■ 각 instruction \( \text{Inst}_* \)에 대해서는 샘플링된 API 집합 \( \mathbb{S}_N^{sub} \) 전체를 사용 가능한 함수로 ChatGPT에게 제공하며, ChatGPT가 action sequence를 마칠 수 있도록 "Finish with Final Answer"와 "Finish by Giving Up"라는 두 개의 함수도 추가로 정의한다.
■ "Finish with Final Answer" 함수는 주어진 instruction에 대한 최종 답변을 제시하는 기능이고, "Finish by Giving Up" 함수는 제공된 API들만으로는 instruction을 해결할 수 없다고 판단될 때 사용된다.
■ 이러한 것들을 통해 solution path annotation을 단순한 API 실행 기록이 아니라, 행동 선택–실행–응답–종료 판단까지 포함하는 문제 해결 절차로 구성한다.
Depth First Search-based Decision Tree
■ 기존 추론 방식인 CoT와 ReACT는 아래와 같은 한계를 가지고 있다.
- (1) error propagation: 초기에 잘못된 action이 선택되면 이후 단계까지 오류가 이어져, 모델이 잘못된 방식으로 API를 계속 호출하거나 존재하지 않는 API를 환각하는 등의 잘못된 루프에 빠질 수 있다.
- (2) limited exploration: CoT나 ReACT는 하나의 방향만 탐색하므로 전체 action space를 충분히 탐색하지 못한다.
■ 이러한 한계로 인해 GPT-4와 같은 모델조차도 유효한 solution path를 찾지 못하는 경우가 많다.
■ 이 문제를 해결하기 위해 저자들은 DFSDT를 제안한다.
■ Fig 4에서 보이듯이, DFSDT는 모델이 서로 다른 추론 경로들을 평가하고 (1) 유망한 경로를 따라 계속 진행하거나 (2) "Finish by Giving Up" 함수를 호출하여 기존 노드를 버리고 새로운 노드로 확장하는 것 중 하나를 선택할 수 있게 해준다.
■ 또한 새로운 노드를 확장할 때는 자식 노드들을 다양화하고 탐색 공간을 넓히기 위해, ChatGPT에게 이전에 생성된 노드들의 정보를 프롬프트로 제공하고 모델이 이전과는 구별되는 노드를 생성하도록 유도한다.
■ 다양한 추론 경로를 평가할 수 있고, 체계적인 대안 탐색으로 더 넓은 공간을 탐색할 수 있어, 결과적으로 CoT나 ReACT보다 복잡한 instruction에 대한 유효한 solution path를 찾을 가능성이 높아진다.
■ 탐색 과정에 있어, BFS를 사용하면 과도한 OpenAI API 호출 비용이 발생할 것이다. 유효한 경로들이 여러 개 있을 수 있지만, 학습 데이터를 위한 annotation 수집 관점에서는 성공한 경로 1개만 있으면 충분하기 때문에 DFS를 사용한다. (Appendix A.8)
■ 생성한 모든 instructions에 대해 DFSDT를 수행하고 통과한 solution path만 남긴다. 그 결과 126,486개의 (instruction, solution path) 쌍을 확보했으며, 이는 ToolLLaMA를 학습시키는 데 사용된다. (섹션 3.2)
3. EXPERIMENTS
3.1 PRELIMINARY EXPERIMENTS
ToolEval
■ RapidAPI의 API는 시간이 지남에 따라 변할 수 있고, 하나의 instruction에 대해서도 가능한 potential solution paths이 무한히 존재할 수 있다는 점을 고려할 때, 각 test instruction마다 고정된 ground-truth solution path를 주석화하는 것은 현실적으로 어렵다.
■ 또한, 서로 다른 모델을 비교하려면 동일한 API 버전에서 평가가 이루어져야 한다. 이러한 평가를 위해 human evaluation은 비용과 시간 측면에서 비효율적이다.
■ 이에 저자들은 AlpacaEval을 따라 ChatGPT를 기반으로 한 효율적인 evaluator인 ToolEval을 설계하였다. ToolEval은 두 가지 평가지표로 구성된다. (Appendix A.5)
- (1) Pass Rate: 제한된 예산 내에서 instruction을 성공적으로 완료한 비율로, LLM에 대한 instruction의 실행 가능성을 측정하며 이상적인 tool use를 위한 기본 요구사항으로 볼 수 있다.
- (2) Win Rate: 하나의 instruction에 대한 두 개의 solution paths을 ChatGPT evaluator에게 제시하여 어느 경로가 더 우수한지 평가하게 한다. 그리고 결과의 신뢰성을 높이기 위해 동일한 평가를 반복 수행한 뒤 평균 결과를 사용한다.
■ human annotators이 평가한 결과와 ToolEval을 사용한 결과를 비교했을 때(Appendix A.5), pass rate에서 87.1%, win rate에서 80.3%로 높은 agreement를 달성하였다.
■ 이러한 높은 agreement 결과에 대해 저자들은 ToolEval이 인간 평가를 상당한 수준까지 반영할 수 있다고 주장한다.
Efficacy of API Retriever
■ 저자들에 따르면 API retriever의 역할은 주어진 instruction에 대해 관련성이 높은 API를 검색하는 것이다. 이를 위해 BERT-BASE를 기반으로 dense retriever를 학습시키기 위해 Sentence-BERT를 사용한다.
■ API retriever는 instruction과 API 문서를 각각 임베딩으로 인코딩한 뒤, 두 임베딩 사이의 유사도를 계산해 그 관련성을 계산한다.
■ 학습을 위해 섹션 2.2에서 생성한 각 instruction의 relevant APIs을 positive examples로 사용하고, 여기에 몇 개의 다른 API들을 샘플링하여 contrastive learning을 위한 negative examples로 사용한다.
■ 베이스라인으로는 BM25와 OpenAI의 text-embedding-ada-002를 사용하고, 검색 성능은 NDCG를 사용하여 평가한다.
■ Table 2는 I1, I2, I3에서 API retriever를 평가한 결과로, 모든 설정에서 베이스라인들을 일관되게 능가한다. l1, l2, l3의 특징을 고려할 때, 이 API retriever는 대규모 API 환경에서도 충분히 효과적으로 작동할 것으로 기대할 수 있다.
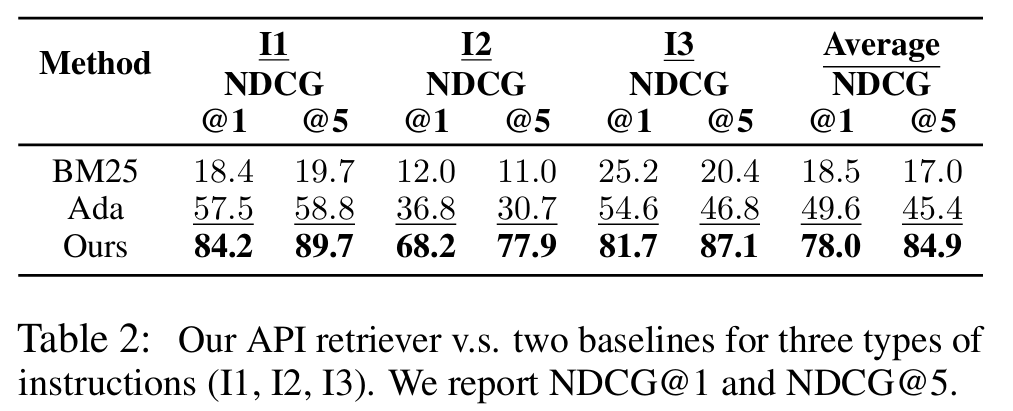
■ 또한 I1의 NDCG 점수가 일반적으로 I2나 I3보다 높은데, 이는 single-tool instruction retrieval의 경우 관련 API를 찾는 것이 여러 API의 조합과 연관성을 고려해야 하는 multi-tool보다 더 간단한 설정임 의미한다.
Superiority of DFSDT over ReACT

■ ChatGPT를 기반으로 pass rate 지표를 사용하여 DFSDT와 ReACT를 비교한다.
■ 다만, DFSDT가 ReACT보다 더 많은 OpenAI API 호출을 소비하므로 더 공정한 비교를 위해, 총비용이 DFSDT와 같은 수준에 도달할 때까지 여러 번 ReACT를 수행하는 "ReACT@N"이라는 베이스라인을 추가한다.
■ ReACT@N은 유효한 solution을 하나라도 찾으면 통과한 것으로 간주한다.
■ Table 3에서 볼 수 있듯이, DFSDT는 모든 시나리오에서 두 베이스라인을 크게 능가한다. 또한, single-tool instruction인 I1보다 복잡한 multi-tool instruction인 I2와 I3에서 DFSDT의 성능 향상이 더욱 뚜렷하다.
■ 저자들은 이를 탐색 공간 확장의 효과로 해석한다. 즉, DFSDT는 여러 추론 경로를 검토할 수 있기 때문에, ReACT를 아무리 여러 번 반복해도 해결하지 못하는 복잡한 instructions을 더 잘 해결할 수 있다는 것이다.
3.2 MAIN EXPERIMENTS
ToolLLaMA
■ ToolBench instruction-solution pairs을 사용하여 LLaMA-2 7B 모델을 파인튜닝한다.
■ original LLaMA-2는 sequence length가 4096이다. 단 실험 환경에서는 API 응답이 매우 길어질 수 있기 때문에, context length를 8192로 늘리기 위해 positional interpolation을 사용한다. (Appendix A.3)
Settings
■ ToolLLaMA의 목표는 training에서 보지 못한 새로운 instructions 및 APIs에 대한 일반화이다. 이를 위해 저자들은 다음 세 가지 수준에서 ToolLLaMA의 일반화 능력을 평가한다.
- (1) Inst: training data와 동일한 도구 집합을 전제로 하지만, training에서 보지 못한 instructions
- (2) Tool: training data에 있는 도구들과 동일한 카테고리에 속하지만, 처음 보는 tools
- (3) Cat: training data에서 보지 못한 카테고리에 속하는 처음 보는 tools
■ 실험은 l1, l2, l3 시나리오에서 수행된다. 이때 각 시나리오마다 평가 수준은 다르게 설정한다.
- l1의 경우, 앞서 언급한 세 가지 수준(I1-Inst, I1-Tool, I1-Cat)에 대해 평가를 수행한다.
- l2의 경우, training instructions에 이미 같은 카테고리의 다른 도구들이 포함되어 있기 때문에 일반화 평가를 위해 I2-Inst와 I2-Cat만 수행한다. 마찬가지로, l3도 다른 카테고리의 도구들의 다양한 조합을 포함할 수 있으므로, l3-Inst만 수행한다.
Baselines
■ general-purpose dialogue를 위해 파인튜닝된 두 가지 LLaMA 변형인 Vicuna와 Alpaca를 사용한다.
■ 또한, teacher model인 ChatGPT, Text-Davinci-003, GPT-4, Claude-2를 사용하고, 이들 모두에 대해 DFSDT와 ReACT를 적용한다. win rate를 계산할 때, 각 모델은 ChatGPT-ReACT와 비교된다.
Main Results

■ Vicuna와 Alpaca는 어떠한 instruction도 성공적으로 통과하지 못하여 지표가 0인 것을 볼 수 있다. 이는 기존의 instruction tuning이 주로 언어 능력에 집중되어 있으며, 이러한 튜닝은 tool-use 능력으로 확장되지 않음을 의미한다.
■ 모든 LLM에서 DFSDT를 사용하는 것이 pass rate와 win rate 모두에서 ReACT를 크게 능가한다.
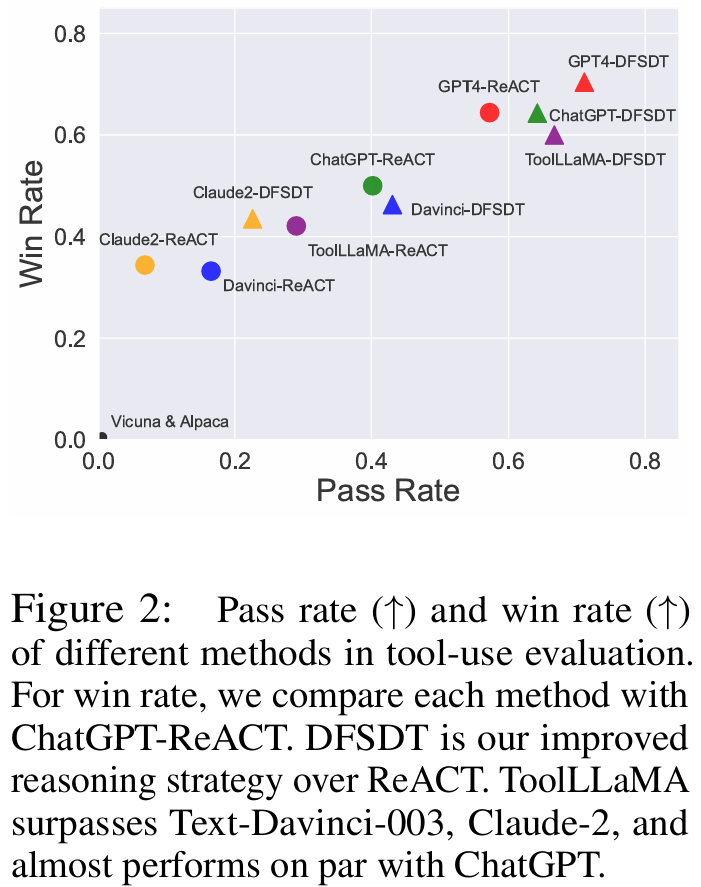
■ ChatGPT + DFSDT가 pass rate에서 GPT-4 + ReACT를 능가하고 win rate에서는 비슷한 성과를 달성했다. 이는 의사결정에 있어 ReACT보다 DFSDT가 우수함을 보여준다.
■ DFSDT를 사용할 때, ToolLLaMA는 Text-Dainci-003 및 Claude-2보다 훨씬 더 나은 성능을 보이며, teacher인 ChatGPT에 필적하는 성능을 달성했다.
■ 이러한 결과는 ToolBench가 LLM 내부의 tool-use 능력을 충분히 이끌어낼 수 있으며, ToolBench로 학습된 모델은 unseen instructions 및 tools에 대해서도 다양한 instructions을 처리할 수 있음을 시사한다.
■ ToolLLaMA + DFSDT는 모든 시나리오에서 GPT4 + DFSDT 다음으로 높은 pass rate를 달성했으며, 상당한 일반화 성능을 보여준다.
Integrating API Retriever with ToolLLaMA
■ 이 섹션에서는 API retriever를 ToolLLaMA와 결합한 실험에 대해 설명한다.
■ real-world scenarios에서는 사용자에게 대규모 API pool에서 직접 적절한 API를 추천해 달라고 요청하는 것은 실용적이지 않을 수 있다.
■ API retriever의 효율성을 테스트하기 위해, 이러한 실용적인 설정을 따라하고자 API retriever가 추천한 상위 5개의 API를 ToolLLaMA에 입력으로 제공했다.
■ Table 4에서 볼 수 있듯이, 검색된 API를 사용하는 것이 오히려 ground truth API set을 사용한 경우보다 pass rate와 win rate가 모두 향상되었다.
■ 저자들은 그 이유를 ground-truth API set 안의 일부 API는, 더 나은 기능을 가진 다른 유사한 API들로 대체될 수 있으며, API retriever가 이러한 더 나은 대안을 성공적으로 찾아냈기 때문이라고 설명한다.
3.3 OUT-OF-DISTRIBUTION (OOD) GENERALIZATION TO APIBENCH
Settings
■ OOD dataset 상황에서 ToolLLaMA의 일반화 능력을 검증한다. 이 실험에서 사용되는 dataset은 APIBench이다.
■ 저자들은 ToolLLaMA가 새로운 API 환경에서도 얼마나 잘 적응할 수 있는지 확인하고자, APIBench의 세 도메인인 TorchHub, TensorHub, HuggingFace에서 평가를 진행한다.
■ 또한 ToolLLaMA에 (저자들이 학습시킨) API retriever와 정답 API를 제공하는 oracle retriever를 결합한다.
■ ToolLLaMA의 비교 대상으로 APIBench의 training data를 사용하여 파인튜닝된 LLaMA-7B 모델인 Gorilla를 사용한다.
■ Gorilla는 APIBench 원 논문 설정에 따라 zero-shot setting (ZS)과 retrieval-aware setting (RS) 두 방식으로 평가된다.
- RS는 검색된 API들이 프롬프트의 일부로 모델에 제공됨을 의미하고, ZS는 모델을 학습시킬 때 프롬프트에 API를 포함하지 않음을 의미한다.
Results

■ ToolLLaMA는 완전히 다른 API 도메인과 instruction 도메인에서 학습되었음에도, 세 데이터셋 전반에서 인상적인 OOD 일반화 성능을 달성했다.
■ 구체적으로, ToolLLaMA + Our Retriever는 HuggingFace 및 TorchHub에서의 AST 정확도 측면에서 두 훈련 설정(ZS / RS)의 Gorilla + BM25를 모두 능가한다.
■ 이는 Gorilla가 APIBench에 맞춰 설계되었다는 점을 고려할 때 의미 있는 결과이다.
'Agent' 카테고리의 다른 글
| [τ-bench] A Benchmark for Tool-Agent-User Interaction in Real-World Domains (0) | 2026.04.25 |
|---|---|
| [AgentTuning] Enabling Generalized Agent Abilities for LLMs (0) | 2026.04.22 |
| [Gorilla] Large Language Model Connected with Massive APIs (0) | 2026.04.20 |
| [Toolformer] Language Models Can Teach Themselves to Use Tools (0) | 2026.04.18 |
| [ReAct] Synergizing Reasoning and Acting in Language Models (0) | 2026.04.16 |


