■ LM은 단 몇 개의 examples이나 textual instructions만으로도 new tasks을 풀어내는 놀라운 능력을 보이며, 이는 특히 model scale이 클 때 더욱 두드러진다.
■ 그러나 역설적으로, 훨씬 더 단순하고 작은 모델들도 탁월하게 해내는 산술연산이나 사실 검색같은 기본적인 기능에서는 어려움을 겪는다.
■ 논문에서는 언어 모델이 단순한 API를 통해 "외부 도구를 사용하는 방법을 스스로 학습"하여, 어떤 API를 호출할지, 언제 호출할지, 어떤 arguments을 전달할지, 그리고 그 결과를 미래의 토큰 예측에 어떻게 잘 통합할지를 스스로 결정하도록 학습된 모델인 Toolformer를 소개한다.
■ 이는 self-supervised 방식으로 이루어지며, 각 API에 대한 단 몇 개의 demonstrations만을 필요로 한다.
■ Toolformer는 language modeling 능력을 희생시키지 않으면서도 다양한 downstream tasks에 걸쳐 향상된 zero-shot 성능을 달성했다.
[2302.04761] Toolformer: Language Models Can Teach Themselves to Use Tools
Toolformer: Language Models Can Teach Themselves to Use Tools
Language models (LMs) exhibit remarkable abilities to solve new tasks from just a few examples or textual instructions, especially at scale. They also, paradoxically, struggle with basic functionality, such as arithmetic or factual lookup, where much simpl
arxiv.org
1. INTRODUCTION
■ LLM은 다양한 NLP tasks에서 인상적인 zero-shot 및 few-shot 결과를 달성하고, 여러 가지 emergent capabilities을 보여주었지만, 여전히 다음과 같은 한계들을 지니고 있다: (1) 최근 사건들에 대한 최신 정보에 접근할 수 없음 (2) 환각 (3) low-resource languages를 잘 이해하지 못함 (4) 정확한 수학 계산 능력 부족 (5) 시간의 흐름을 인지하지 못함
■ 언어 모델이 가진 이러한 한계들을 극복하는 간단한 방법은 모델에게 검색 엔진, 계산기, 캘린더와 같은 외부 도구를 직접 사용할 수 있는 능력을 부여하는 것이다.
■ 그러나 기존의 방법들은 비용이 높고 비효율적인 human annotations에 지나치게 의존하거나, 도구의 사용을 특정 task에만 제한하는 등 언어 모델이 다양한 상황에서 스스로 적절한 도구를 사용하는 generality 능력을 충분히 보여주지 못한다.
■ 논문에서는 다음의 바람직한 조건들을 충족하는 새로운 방식으로 도구 사용을 학습하는 모델인 Toolformer를 제안한다.
- (1) 도구 사용은 대량의 human annotations 없이 self-supervised 방식으로 학습되어야 한다.
- 이는 human annotations에 수반되는 비용 때문이기도 하지만, 더 본질적으로는 "인간이 유용하다고 생각하는 정보"와 "AI 모델이 다음 단어를 예측하는 데 실제로 유용하다고 느끼는 정보"가 서로 다를 수 있기 때문이다.
- 즉, 대량의 텍스트에 사람이 직접 하나씩 API 호출을 annotate하는 것은 현실적으로 불가능하며, 사람과 모델 간의 관점의 차이를 고려해야 한다.
- 언어 모델의 주된 목표는 next token을 더 잘 예측하는 것이다. 그러므로, 모델의 관점에서 유용한 API 호출을 모델이 직접 판단하는 게 더 바람직하다는 주장이다.
- (2) 언어 모델은 자신이 원래 가진 generality를 전혀 잃지 않아야 하며, 언제(when), 어떻게(how) 어떤(which) 도구를 사용할지 스스로 결정할 수 있어야 한다.
- 이를 통해 기존 접근법과 달리, 에이전트가 특정 task에만 얽매이지 않고 보다 general한 tool usage를 수행할 수 있다.
■ Toolformer의 접근 방법은 크게 세 가지 단계로 나눌 수 있다: (1) Annotation → (2) Filtering → (3) Fine-tuning
■ LLM의 in-context learning을 활용한다. 구체적으로, API가 어떻게 사용될 수 있는지 보여주는 단 몇 개의 human-written examples을 주고, LLM이 examples을 보면서 스스로 data에 대한 potential API calls을 annotate하게 한다.
■ 그런 다음, self-supervised loss를 사용하여 potential API calls 중 실제로 모델의 future tokens 예측에 도움이 되는 것들만 남도록 필터링한다.
■ 필터링을 통해 모델이 스스로 유용하다고 판단한 API calls 데이터를 사용하여 모델을 파인튜닝시킨다.
■ 이를 통해 LLM은 다양한 도구를 제어하는 방법을 학습하고, 언제 어떻게 어떤 도구를 사용할지 스스로 결정하는 능력을 갖추게 된다.

■ 이러한 접근법은 사용되는 데이터셋의 종류에 구애받지 않으므로, 처음에 모델을 pretrain시킬 때 사용된 것과 동일한 데이터셋에 적용할 수 있다. 이는 모델이 자신이 원래 가지고 있는 일반성과 언어 모델링 능력을 잃지 않도록 보장한다.
- 기존 fine-tuning을 생각하면, pre-training에서 학습한 데이터와 분포가 다른, new task의 data로 모델을 학습시킨다.
- Toolformer는 처음에 모델을 사전학습시킬 때 사용한 데이터와 동일한 데이터로 fine-tuning을 시킬 수 있다. 원래 텍스트와 내용은 동일하며, 단지 API call이 중간에 삽입된 버전일 뿐이다.
2. Approach
■ 목표는 LM \( M \)에게 API calls을 통해 다양한 도구를 사용할 수 있는 능력을 갖추게 하는 것이다.
■ 각 API의 입력과 출력은 text sequence로 표현될 수 있도록 설계하였으며, 각 API call의 시작과 끝을 표시하기 위해 special token을 사용함(<API>, </API>)으로써, 어떤 텍스트에도 API call을 삽입할 수 있도록 하였다.
■ 논문에서는 각 API call을 튜플 \( c = (a_c, i_c) \)로 표기한다. 여기서 \( a_c \)는 API의 name이고 \( i_c \)는 input이다.
- 예를 들어 \( c = (\text{Calculator}, \text{"400 / 1400"}) \)라면, \( \text{Calculator} \)는 API name, \( \text{"400 / 1400"} \)가 API input이다.
■ 호출 결과 \( r \)을 동반하는 API call \( c \)가 주어졌을 때, 그 API call이 결과를 포함하지 않은 상태와 포함한 상태의 텍스트 시퀀스를 다음과 같이 표기한다.
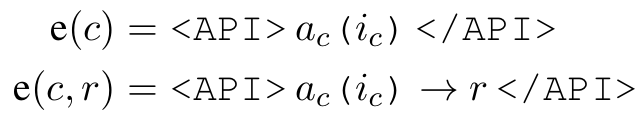
- \( e(c) \)는 결과가 없는 형태, \( e(c, r) \)은 결과가 포함되는 형태를 텍스트로 표현한 것이다.
- 여기서 "<API>", "</API>", 그리고 "→"는 special tokens이다.
- 실제 구현에서는 기존 언어 모델의 vocabulary를 수정하지 않고도 작동할 수 있도록 "<API>", "</API>", "→"를 각각 "[", "]", "->"토큰으로 대체하여 사용한다.
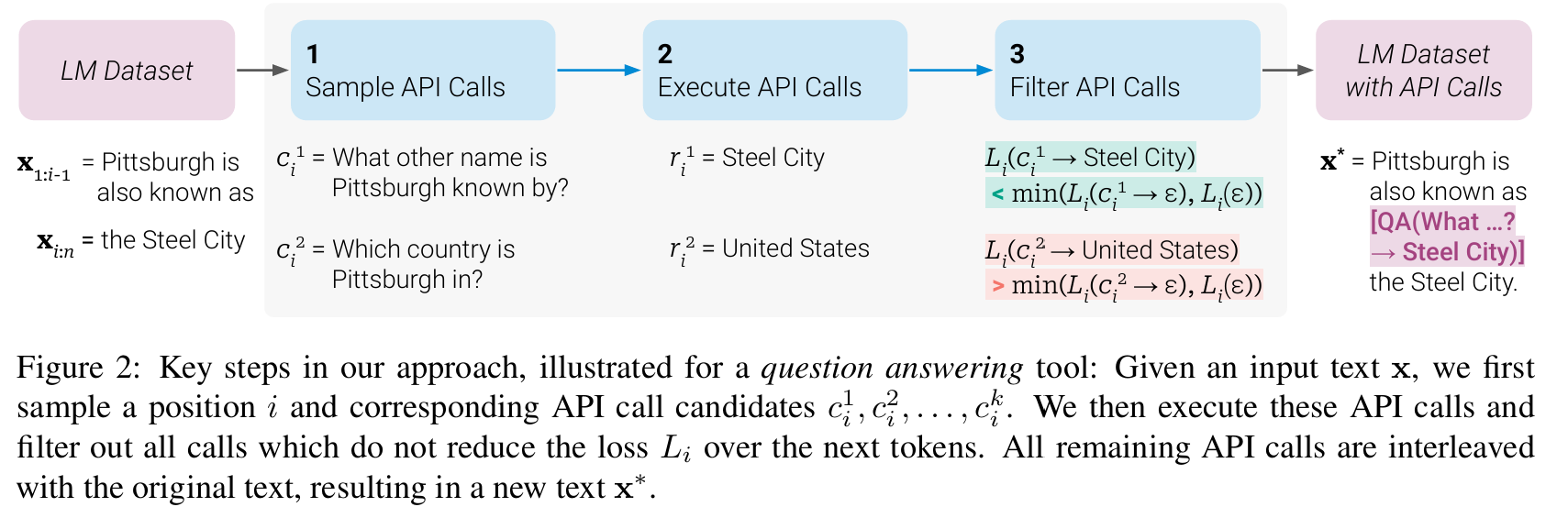
■ 저자들이 제안하는 방법의 전반적인 과정은 Fig 2와 같다.
■ 평범한 텍스트들로 구성된 dataset \( \mathcal{C} = \{\mathbf{x}^1, \ldots, \mathbf{x}^{|\mathcal{C}|}\} \)가 주어졌을 때, 가장 먼저 이 데이터셋을 API calls이 삽입된 dataset \( \mathcal{C}^* \)로 변환한다.
■ Fig 2에 묘사된 바와 같이 이 변환은 크게 세 가지 단계로 우리어진다: (1) Sample API Calls (2) Execute API Calls (3) Filter API Calls
■ 먼저 모델 \( M \)의 in-context learning 능력을 활용하여 많은 수의 'potential API calls'을 샘플링한다. 그런 다음 이 API calls을 실제로 실행하고 얻어진 응답이 모델이 미래의 토큰을 예측하는 데 실제로 도움이 되는지를 확인한다. 이것이 API를 걸러내는 필터링 기준으로 사용된다.
■ 필터링이 끝난 뒤 남은 API calls이 포함된 dataset \( \mathcal{C}^* \)를 산출하고, 모델 \( M \) 자체를 \( \mathcal{C}^* \)로 파인튜닝한다.
Sampling API Calls
■ 먼저 각 API에 대해, LM이 주어진 example \( \mathbf{x} = x_1, \ldots, x_n \) 곳곳에 API calls을 스스로 annotate하도록 유도하는 프롬프트 \( P(\mathbf{x}) \)를 작성한다.
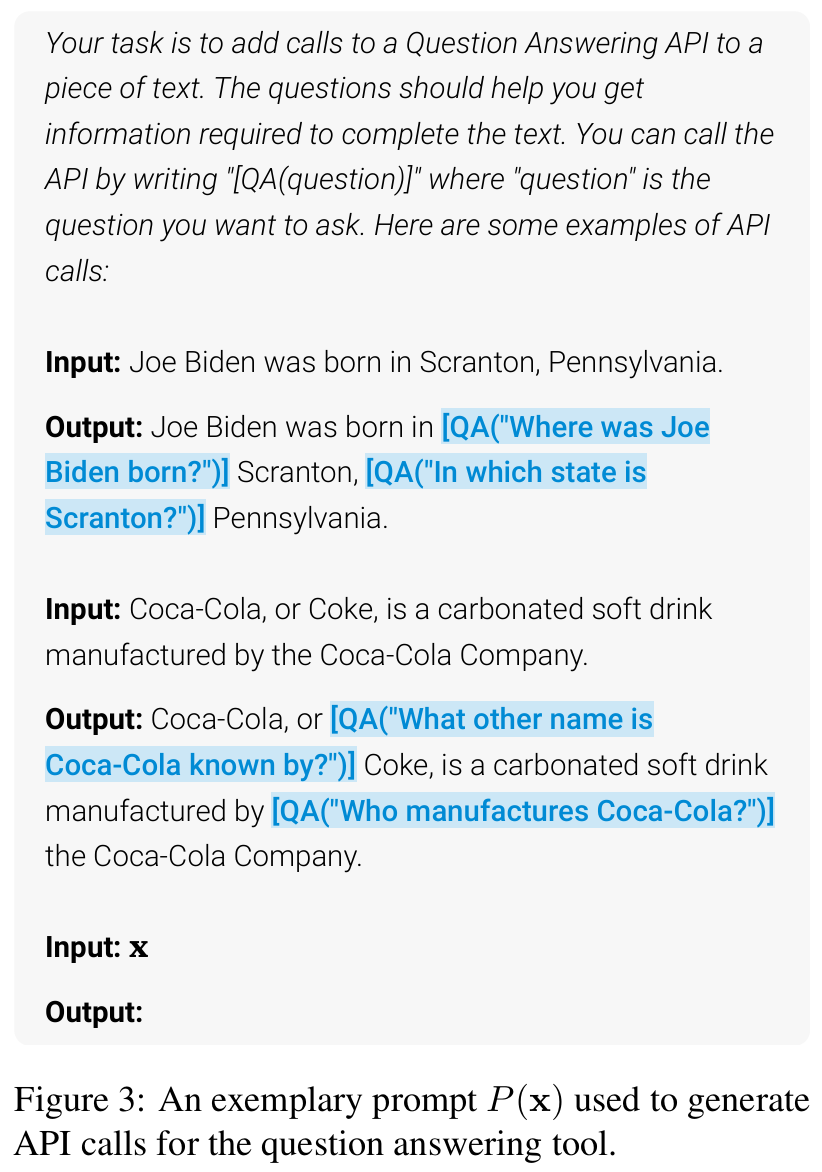
■ Fig 3은 QA tool을 위한 프롬프트 \( P(\mathbf{x}) \)이다. (Appendix A.2 참고)
■ \( p_M(z_{n+1} \mid z_1, \ldots, z_n) \)을 모델 \( M \)이 시퀀스 \( z_1, \ldots, z_n \)의 연속으로 token \( z_{n+1} \)에 할당하는 확률이라고 하자.
■ 각 위치 \( i \in \{1, \ldots, n\} \)에 대해, 모델 \( M \)이 위치 \( i \)에서 API call을 시작할 확률(위치 \( i \)에서 <API> 토큰이 등장할 확률) \( p_i = p_M(\text{<API>} \mid P(\mathbf{x}), x_{1:i-1}) \)를 계산한다.
■ 그리고 API call을 수행할 후보 위치들을 최대 \( k \)개까지 샘플링한다. 사전에 정의한 threshold \( \tau_s \)를 기준으로, \( \tau_s \)를 넘는 확률 \( p_i \)들만 API call 후보 집합 \( I = \{i \mid p_i > \tau_s\} \)에 담는다. 만약 threshold \( \tau_s \)를 넘는 위치가 \( k \)개를 초과한다면, 확률이 가장 높은 상위 \( k \)개만 선택한다.
■ 이렇게 뽑힌 각 위치 \( i \in I \)에 대해, 시퀀스 \( [P(\mathbf{x}), x_1, \ldots, x_{i-1}, \text{<API>}] \)를 prefix로 주고 </API>를 시퀀스의 종료 토큰으로 주어 모델 \( M \)으로부터 텍스트를 샘플링하게 함으로써, 해당 위치에 들어갈 최대 \( m \)개의 potential API calls \( c_i^1, \ldots, c_i^m \)을 생성한다. 이때 모델 \( M \)이 </API>를 종료 토큰으로 제대로 생성하지 못한 것들은 사용하지 않는다.
■ \( c_i^1, \ldots, c_i^m \) 중에서 어떤 것이 실제로 유용한지는 필터링 단계에서 판별한다.
Executing API Calls
■ 샘플링으로 생성된 potentail API calls을 실제로 실행시켜 그에 상응하는 결과 \( r \)을 얻어온다.
■ 이 작업이 수행되는 방식은 철저히 API 자체의 성격에 달려 있다. 예를 들어, 또 다른 신경망을 호출할 수도 있고, 파이썬 스크립트를 실행하거나 검색 시스템을 사용할 수도 있다.
■ 각 API call \( c_i \)에 대한 response는 반드시 single text sequence \( r_i \)여야만 한다.
- 이는 이후 loss 계산을 위해 response를 텍스트에 자연스럽게 삽입하기 위함이다.
Filtering API Calls
■ 시퀀스 \( \mathbf{x} = x_1, \ldots, x_n \) 내에서 API call \( c_i \)가 삽입된 위치를 \( i \)라 하고, \( r_i \)를 해당 API call로부터 돌아온 응답 결괏값이라고 하자.
■ 가중치 시퀀스 \( (w_i \mid i \in \mathbb{N}) \)가 주어졌을 때, 다음을 정의한다.

- \( w \)는 API 호출 위치 \( i \)로부터 떨어진 거리에 따른 가중치이다. API의 효과는 바로 인접한 토큰에서 가장 크게 나타난다는 직관을 반영한 설계이다. (섹션 4.1)
- 예를 들어, "피츠버그는 [QA: What other name is Pittsburgh known by?] 또한 __로 알려져 있다"에서 [QA: What other name is Pittsburgh known by?]라는 API call의 response가 "Steel City"라고 하자.
- "피츠버그는 [QA: What other name is Pittsburgh known by? → Steel City] 또한 __로 알려져 있다"에서 "Steel City"라는 응답은 바로 뒤 빈칸을 예측하는 데는 중요하지만, 문서 맨 끝까지 동일한 영향을 미치지는 않는다.
- 그래서 API를 호출하는 위치와 가까운 토큰에 더 큰 가중치를 주고, 멀어질수록 가중치가 0으로 줄어들도록 설정한다.
■ \( L_i(\mathbf{z}) \)는 모델 \( M \)에게 \( \mathbf{z} \)를 prefix로 주었을 때, 토큰 \( x_i, \ldots, x_n \)에 대한 weighted cross entropy loss이다.
■ 저자들은 이 loss에 대한 두 가지 서로 다른 instantiations을 비교한다.

- 여기서 \( \varepsilon \)은 empty sequence를 나타낸다.
■ \( L_i^+ \)는 API call과 해당 call에 대한 response가 모두 모델 \( M \)에게 prefix로 주어졌을 때, \( x_i, \ldots, x_n$ \) 토큰들에 대한 loss이다.
■ \( L_i^- \)는 (1) API call을 아예 하지 않았을 때와 (2) API call은 했지만 그에 대한 response가 없는 경우에 얻어지는 두 loss 중 최솟값이다.
■ 직관적으로, 어떤 API call을 실행하고 그 결과를 모델에게 제공했을 때(즉, \( L_i^+ \)), 모델이 이후 토큰들을 예측하는 데 있어, API call을 아예 사용하지 않았거나(즉, \( L_i^- \)의 (1)), 빈손(입력만)으로 돌아왔을 때(\( L_i^- \)의 (2))보다 loss가 감소한다면(즉, 이후 토큰들에 대한 예측을 더 쉽게 만들어 준다면), 그 API call은 모델 \( M \)에게 유용한 것이다.
■ 이러한 직관을 따 유용성을 판단하기 위해 다음을 만족하는 API calls만 유지한다.

■ \( L_i^- - L_i^+ \ge \tau_f \)가 성립하는 API calls만 유지한다는 것은, API를 아예 쓰지 않거나 결과를 얻지 못했을 때에 비해 최소한 \( \tau_f \) 이상의 loss 감소 효과를 가져오는, 모델 \( M \)에게 유용한 도구 사용법들만 고려한다는 것이다.
- \( L_i^- - L_i^+ \ge \tau_f \)를 \( L_i^- \tau_f \ge L_i^+ \)로 보면, 도구를 사용했을 때의 loss \( L_i^+ \)가 베이스라인 손실 \( L_i^- \)에서 \( \tau_f \)를 뺀 값과 같아야 한다로 해석할 수 있다.
- 즉, 도구를 써서 얻은 결과가 베이스라인(API call이 없음 혹은 API call의 response가 없음) 대비 loss를 \( \tau_f \) 이상 낮춘 것은 '유용한 사용'으로 판별하는 것이다.
Model Finetuning
■ 모든 API에 대해 calls을 샘플링하고 필터링한 후, 살아남은 API calls을 모두 병합하여 original inputs에 삽입한다.
■ 즉, 위치 \( i \)의 API call과 결과 \( (c_i, r_i) \)를 갖는 input text \( \mathbf{x} = x_1, \ldots, x_n \)에 대해, \( \mathbf{x}^* = x_{1:i-1}, e(c_i, r_i), x_{i:n} \)라는 새로운 형태의 시퀀스로 재구성한다. 한 텍스트 내에 여러 개의 API calls이 있는 경우에도 동일한 방식으로 처리한다.
■ 이를 모든 \( \mathbf{x} \in \mathcal{C} \)에 대해 수행하면, API calls로 증강된 새로운 dataset \( \mathcal{C}^* \)를 얻게 된다.
■ 이 새로운 데이터셋으로 standard language modeling objective를 사용하여 모델 \( M \)을 파인튜닝한다.
■ 중요한 포인트는, 새로 중간에 끼워 넣은 API calls을 제외하면 augmented dataset \( \mathcal{C}^* \)는 original dataset \( \mathcal{C} \)와 정확히 동일한 텍스트를 포함하고 있다는 사실이다.
■ 결과적으로 \( \mathcal{C}^* \)로 \( M \)을 파인튜닝하는 것은 \( \mathcal{C} \)로 파인튜닝하는 것과 동일한 언어 지식에 모델 \( M \)을 노출시키는 셈이다.
■ 더욱이, API calls(필터링 단계에서 통과된 API calls임)은 future tokens을 예측하는 데 도움이 되는 바로 그 위치에, 바로 그 입력으로 삽입되었기 때문에, \( \mathcal{C}^* \)에 대한 파인튜닝은 언어 모델로 하여금 오직 자기 자신의 피드백에 기반하여 언제, 어떻게, 어떤 도구를 사용할지 결정하도록 해준다.
- \( \mathcal{C}^* \)에 있는 API calls이 증강된 데이터는, 각 위치에 삽입된 API call이 그 문맥에서 실제로 유용한 도구 사용(질문, 계산, 검색 등)에 해당된다. 이 데이터를 통해 모델은 언제, 어떻게, 어떤 도구를 사용해야 하는지를 학습할 수 있다.
Inference
■ Toolformer의 접근법은 파인튜닝된 모델 \( M \)을 사용해 텍스트를 생성할 때, \( M \)이 "→" token을 생성할 때까지는 일반적인 디코딩을 수행한다.
■ "→" token은 모델이 API call에 대한 response를 기다리고 있다는 것을 의미한다. 즉, 이제 API call에 대한 응답이 올 차례라는 신호이다.
■ 이 시점에서는 디코딩 과정을 중단하고, 적절한 API를 호출하여 response를 얻은 뒤, response와 </API> token을 삽입한 후 디코딩 과정을 다시 진행한다.
■ 정리하면, Toolformer는 언제 도구를 불러야 할지 결정하는 별도의 알고리즘이나 규칙이 없다. 즉, 특별한 스케줄링 로직이 불필요하다. 모델이 다음 토큰을 예측하다가 <API> 토큰이 가장 가능성 높다고 판단하면 스스로 부르기 때문이다.
■ 이는 필터링 단계에서 "어떤 도구를 어떤 위치에서 불렀을 때 loss가 낮아지는 위치"의 데이터를 학습했기 때문이다.
■ 결과적으로 모델은 "생성 도중 필요할 때만, 스스로 판단하여, 적절한 도구를 호출하고, 그 결과를 이어지는 생성에 활용" 하는 능력을 가지게 된다.
■ 그리고 디코딩 과정은 중단 → 삽입 → 재개 구조이므로, 단순히 하나의 시퀀스를 생성하다가 중간에 외부 값을 주입하는 방식이다.
■ 디코딩 과정 재개 시 future tokens 예측에 도움이 되는 API call의 응답 \( r_i \)를 context로 사용하여 모델이 디코딩을 수행하기 때문에, 앞서 언급했던 한계들을 완화할 수 있다.
3. Tools
■ 논문에서는 LM이 가진 여러 단점들을 해결하기 위해 다양한 tools을 탐색한다.
■ 이 도구들에 부과하는 제약조건은 두 가지이다: (1) 도구의 입력과 출력이 모두 text sequences로 표현될 수 있어야 하고 (2) 도구의 의도된 사용법을 보여주는 몇 가지 demonstrations을 쉽게 얻을 수 있어야 한다.
■ 저자들은 다섯 가지 도구를 탐색한다: question answering system, Wikipedia search engine, calculator, calendar, machine translation system
■ Table 1은 API들의 호출 및 반환 예시이다.

Question Answering
■ 첫 번째 tool은 사실 기반 질문에 답할 수 있는, 또 다른 언어 모델을 기반으로 한 question answering system이다.
■ 이 QA system은 Natural Questions로 파인튜닝된 retrieval-augmented LM인 Atlas이다.
Calculator
■ 두 번째 도구로 간단한 숫자 계산을 수행할 수 있는 계산기를 사용한다. 이 계산기는 오직 사칙연산만 지원하며, 결과는 항상 소수점 둘째 자리까지 반올림된다.
Wikipedia Search
■ 세 번째 도구는 검색어가 주어지면 위키피디아에서 짧은 text snippets을 반환하는 search engine이다.
■ 앞선 QA tool과 비교했을 때, 이 검색은 모델이 주제에 대해 훨씬 더 포괄적인 정보를 얻을 수 있게 해주지만, 모델이 반환된 내용에서 가장 관련성 높은 부분을 스스로 추출해야 한다.
■ search engine으로는 KILT의 위키피디아 덤프를 인덱싱한 BM25 retriever를 사용한다.
Machine Translation System
■ 네 번째 도구는 어떤 언어든 영어로 번역할 수 있는 LM 기반의 machine translation system이다.
■ 200개의 언어를 처리할 수 있는 multilingual machine translation model인 600M 파라미터의 NLLB를 사용한다.
■ source language는 fastText classifier를 통해 자동 감지되며, target language는 항상 영어이다.
Calendar
■ 마지막 도구는, 호출되었을 때 아무런 입력값도 받지 않고 그저 현재 날짜를 반환하는 calendar API이다.
■ 이는 시간에 대한 인지가 필수적인 텍스트 예측을 수행할 때, 모델에게 시간적 문맥(temporal context)을 제공한다.
4. Experiments
■ 실험을 통해, 제안한 접근법이 모델로 하여금 추가적인 supervision 없이도 언제, 어떻게, 어떤 도구를 호출할지를 스스로 결정할 수 있게 하는지를 평가한다.
■ 이를 검증하기 위해 앞서 고려한 도구들 중 적어도 하나 이상이 확실히 유용할 것이라고 판단되는 downstream tasks을 선정하고, zero-shot settings에서 성능을 평가한다.
■ 그리고 접근법이 모델의 언어 모델링 능력을 해치지 않는지 확인한다. 이를 위해 두 개의 언어 모델링 데이터셋에서 perplexity를 측정한다.
■ 마지막으로 도구를 사용하여 학습하는 능력이 모델 크기에 따라 영향을 받는지 확인한다.
4.1 Experimental Setup
Dataset Generation
■ 모든 실험에서 language modeling dataset \( \mathcal{C} \)로는 CCNet의 subset을, 언어 모델 \( M \)으로는 GPT-J를 사용한다.
■ \( \mathcal{C} \)에 API calls을 annotate하는(섹션 2의 Sampling API Calls) 연산 비용을 줄이기 위해, 일부 API들에 대해서는 휴리스틱(Appendix A)을 정의하여, 일반 텍스트보다 API calls이 더 유용할 가능성이 높은 \( \mathcal{C} \)의 subset만 고려한다.
- 예를 들어, 숫자가 하나도 없는 텍스트에 계산기 호출을 샘플링하는 것은 낭비이다. 계산기 도구의 경우 텍스트 안에 "최소 3개 이상의 숫자가 포함"되어 있을 때만 계산기 호출을 고려한다.
■ \( \mathcal{C} \)로부터 \( \mathcal{C}^* \)를 얻기 위해, 섹션 2에 설명된 모든 단계를 수행한다. 필터링 단계에서 모든 API calls이 제거된 예시 문장들은 데이터셋에서 걸러낸다.
- 저자들은 이 필터링이 학습 예시의 분포를 변화시키지만, 남은 예시들이 원본 분포와 충분히 가까워 \( M \)의 언어 모델링 능력이 영향받지 않을 것이라 가정한다. 이 가정은 섹션 4.3에서 검증한다.
■ 가중치 함수(\( L_i ( \mathbf{z}) \)의 \( w \))로는 다음을 사용한다.

■ 이는 API가 제공한 정보가 모델에게 실제로 도움이 되는 그 위치에 최대한 가까이 API call이 발생하도록 유도하기 위해 사용한다.
- API call이 발생한 위치에서 인접한 토큰일수록 가중치가 높고, 다섯 토큰 이상 멀어지면(\( t \geq 5 \)) 웨이트가 0에 가까워진다.
- \( t = 0, 1, 2, 3, 4, 5 \)일 때 \( \tilde{w}_t = \max(0, 1 - 0.2 \cdot t) \)를 사용하면, \( t = 0 \)에서의 \( \tilde{w}_t \)는 1.0이다.
- \( t = 1, 2, 3, 4, 5 \)가 되면 \( \tilde{w}_t = 0.8, 0.6, 0.4, 0.2, 0.0 \)이 된다.
- \( w_t \) 식의 분모는 정규화를 위한 것으로, 이 예시에선 그 값이 3.0이 된다.
- 그러므로 \( w_0 = 0.333, w_1 = 0.267, w_2 = 0.2, w_3 = 0.133, w_4 = 0.067, w_5 = 0.0 \)이 된다.
- 이는 API의 효과가 바로 인접한 토큰에서 가장 크게 나타난다는 직관을 반영한 설계이다.
- 이 직관에 대해 예를 들어 설명하면, "The Nile has an approximate length of [QA → 6,853 km] 6,853 kilometers, the White Nile being its main source."처럼 QA 도구를 호출해서 6,853 km라는 결과가 반환되었다고 하자.
- [QA → 6,853 km] 다음의 "6,853"과 "kilometers"는 API 호출의 도움 정도가 높지만 ",", "the", ... 로 갈수록 API 호출 결과와 점점 무관해진다.
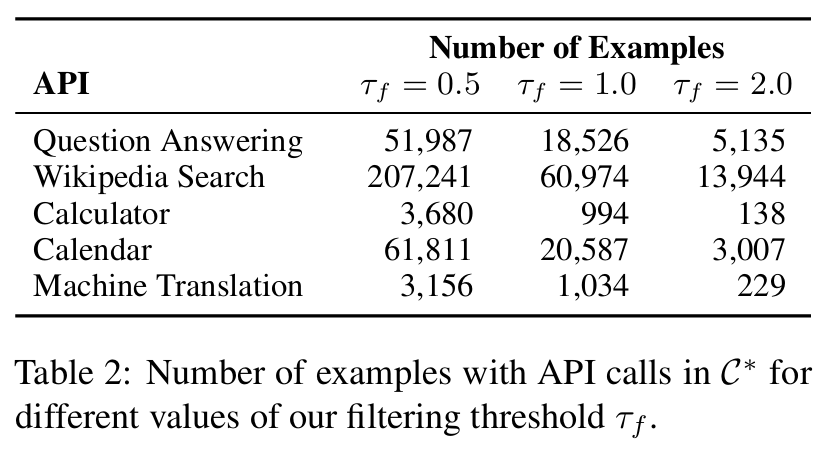
■ 샘플링 임곗값 \( \tau_s \)와 필터링 임곗값 \( \tau_f \)는 충분한 수의 예시를 확보하기 위해 각 도구별로 개별적으로 선택되었다. (Appendix A)
Model Finetuning
■ \( M \)을 \( \mathcal{C}^* \)로 파인튜닝할 때 batch size 128, learning rate \( 1 \cdot 10^{-5} \)를 사용하고, training의 처음 10% 동안 linear warmup을 적용한다. (Appendix B)
Baseline Models
■ 다음과 같은 모델들을 비교한다.
- GPT-J: 아무런 파인튜닝도 거치지 않은 GPT-J
- GPT-J + CC: API calls이 전혀 없는 CCNet의 subset \( \mathcal{C} \)로 파인튜닝된 GPT-J
- Toolformer: API calls이 추가된 CCNet의 subset \( \mathcal{C}^* \)로 파인튜닝된 GPT-J
- Toolformer (disabled): Toolformer와 동일한 모델이지만, 디코딩 중 API calls이 비활성화된 모델. 이는 <API> 토큰이 생성될 확률을 수동으로 0으로 설정하면 된다.
- Toolformer (disabled)는 <API> 확률을 0으로 설정하여 API 호출을 차단한다. 이는 실제 도구를 사용하는 것(즉 Toolformer)이 얼마나 성능 향상에 도움이 되는지 비교하기 위함이다.
4.2 Downstream Tasks
■ 모델을 downstream tasks에서 평가할 때, 모든 경우에서 prompted zero-shot 설정을 사용한다. 즉, 모델에게 자연어로 task를 해결하라는 지시를 내리지만, 그 어떤 in-context examples도 제공하지 않는다.
■ 이를 통해 Toolformer가 사용자가 사전에 "어떤 도구를 어떤 방식으로 사용하라"고 명시하지 않는 상황에서도 잘 작동하는지 평가한다.
■ 그리고 standard greedy decoding을 사용하되, Toolformer를 위해 한 가지 수정을 적용한다.
■ greedy decoding은 가장 확률이 높은 토큰 하나만 선택한다. 여기에 저자들이 적용한 수정 사항은, greedy decoding 과정에서 <API> 토큰이 가장 확률이 높은 토큰일 때만이 아니라, <API> 토큰이 상위 \( k \)개의 토큰에 포함되기만 하면 모델이 API 호출을 시작하도록 한 것이다.
■ \( k = 1 \)로 설정하면 이는 일반적인 greedy decoding에 해당한다. 저자들은 모델이 API들을 더 적극적으로 사용하도록 \( k = 10 \)을 사용한다.
■ 동시에, 모델이 실제 텍스트 출력은 하나도 생성하지 않은 채 끊임없이 API만 호출하는 루프에 빠지지 않도록, 입력당 최대 한 번의 API call만 허용한다.
4.2.1 LAMA
■ LAMA 벤치마크의 SQuAD, Google-RE, T-REx subsets에서 모델들을 평가한다. 각 subset에서 수행할 작업은 누락된 사실(예: 날짜나 장소)이 포함된 짧은 문장을 완성하는 것이다.
■ LAMA는 본래 BERT와 같은 masked language models을 평가하기 위해 설계되었기 때문에, 모델이 left-to-right으로 처리할 수 있는 mask 토큰이 마지막에 등장하는 예시들만 사용한다.
- mask 토큰이 문장 중간에 있으면 autoregressive LM을 사용하는 것이 적합하지 않다. 그래서 mask 토큰이 문장 끝에 있는 예시만 사용한다.
■ 여러 모델들을 평가하기 위해, 각 모델의 tokenization 방식이 다름을 고려한다. 구체적으로, exact match 대신 약간 더 관대한 평가 기준을 사용한다. 모델이 예측한 처음 5개의 단어 안에 정답이 있으면 맞는 것으로 간주한다.
■ 그리고 LAMA는 위키피디아에서 추출한 문장들을 기반으로 만들어졌기 때문에, 여기서는 Toolformer가 Wikipedia Search API를 사용하는 것을 금지한다.
■ Table 3에서 볼 수 있듯이, 도구를 사용하지 않는 GPT-J 모델들은 모두 비슷한 성능을 보인다. Toolformer는 이 모든 베이스라인 모델들을 능가하며, 가장 좋은 베이스라인 대비 점수가 각각 11.7점, 5.2점, 그리고 18.6점이 향상된다.

■ 또한, Toolformer는 자신보다 훨씬 더 거대한 OPT (66B)와 GPT-3 (175B)보다도 훨씬 뛰어난 성능을 보인다.
■ 이는 모델이 거의 모든 경우(98.1%)에서 정보를 얻기 위해 QA 도구에게 스스로 질문하기로 결정을 내렸기 때문이다. 매우 소수 예시에서만 다른 도구를 사용하거나(0.7%) 도구를 아예 사용하지 않는 경우(1.2%)도 존재한다.
4.2.2 Math Datasets
■ ASDiv, SVAMP, MAWPS 벤치마크를 통해 mathematical reasoning abilities을 평가한다.
■ zero-shot 설정임을 고려하여 약간 더 관대한 평가 기준을 사용한다. 요구되는 출력값이 항상 숫자이기 때문에, 모델이 예측한 첫 번째 숫자가 정답인지 확인한다.
- 단 모델의 예측에 방정식이 포함되는 경우(예: "5+3=8")에는 "=" 뒤에 나오는 첫 번째 숫자를 모델의 최종 예측으로 간주한다.
■ Table 4에 나타난 바와 같이, GPT-J와 GPT-J + CC는 비슷한 성능을 보이지만, Toolformer는 API calls이 disabled된 상태에서도 더 강력한 결과를 달성했다.

■ 저자들은 모델이 API calls과 그 결과가 담긴 수많은 예시들로 파인튜닝되는 과정에서, 모델에 잠재된 수학적 능력이 향상되었기 때문이라고 추측한다.
■ 모델에게 API를 호출하도록 허용하면 모든 작업에서 성능이 두 배 이상 향상되며, 훨씬 더 거대한 OPT 및 GPT-3 모델도 능가한다. 이는 모든 벤치마크에 걸쳐 97.9%의 예시에 대해 모델이 계산기 도구를 호출하기로 결정했기 때문이다.
4.2.3 Question Answering
■ Web Questions, Natural Questions, TriviaQA에서 모델들을 평가한다. exact match 대신 모델이 예측한 처음 20단어 안에 정답이 포함되는지 확인한다.
■ Toolformer에 대해서는 QA 도구를 disable시킨다. 내장한 QA 시스템(Atlas)이 이미 Natural Questions으로 파인튜닝되어 있었기 때문이다.
- 즉, QA 시스템(Atlas)이 이미 정답을 거의 알고 있기 때문에, 이를 사용하면 Toolformer의 능력이 아니라 Atlas의 능력을 측정하는 셈이 되기 때문이다.
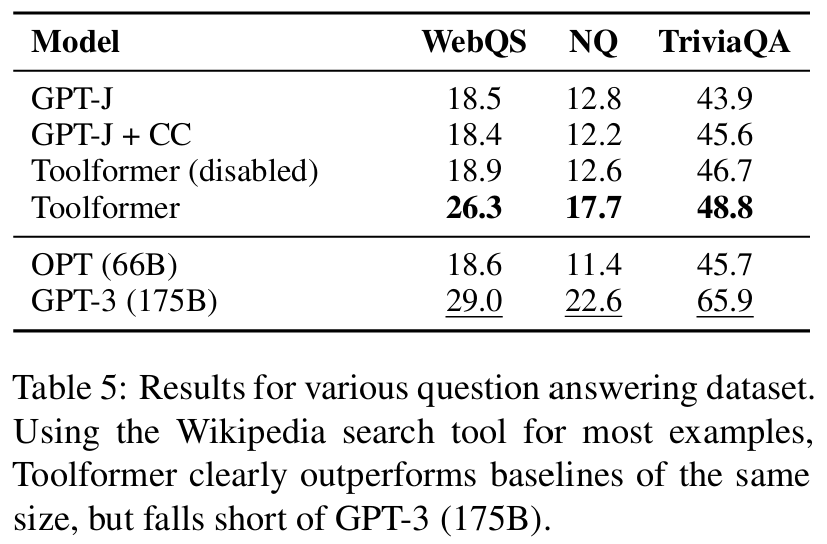
■ Toolformer는 GPT-J 기반의 다른 모든 모델들을 능가하며, 이번에는 관련 정보를 찾기 위해 Wikipedia Search API에 주로 의존(99.3%)했다. 그러나 Toolformer는 훨씬 큰 GPT-3(175B) 모델에는 여전히 못 미친다.
■ 이 결과에 대해 저자들은, (1) 사용한 search engine이 너무 단순하기 때문일 가능성이 높으며(많은 경우 주어진 쿼리와 일치하지 않는 엉뚱한 결과를 반환), (2) Toolformer가 search engine과 능동적으로 상호작용하지 못하기 때문이라고 주장한다.
- (2)는 예를 들어, 검색 결과가 도움이 되지 않으면 쿼리를 재구성하거나, 상위 여러 개의 검색 결과를 탐색하는 능동적 상호작용 능력이 현재 Toolformer에게는 없다.
4.2.4 Multilingual Question Answering
■ multilingual QA 벤치마크인 MLQA에서 Toolformer와 모든 베이스라인 모델을 평가한다.
■ 각 질문에 대한 context 문단은 영어로 제공되지만, 질문은 아랍어, 독일어, 스페인어, 힌디어, 베트남어, 중국어 간체로 주어질 수 있다. 이 task를 해결하려면 모델이 영어 문단과 다국어 질문을 모두 이해해야 하므로, 질문을 영어로 번역하는 것이 모델에게 유리할 수 있다.
■ 사용하는 평가 지표는 모델 생성 결과(10 단어로 제한) 안에 정답이 포함되는 비율이다.

■ API calls은 모든 언어에서 Toolformer 성능을 일관되게 향상시키며, 이는 모델 스스로 machine translation 도구를 영리하게 활용하는 법을 터득했음을 시사한다.
■ 그러나 Toolformer가 vanilla GPT-J를 일관되게 능가하지는 않는다. 주된 이유는 일부 언어의 경우 CCNet으로 파인튜닝하는 것이 성능을 악화시켰기 때문이다. 즉, 이는 GPT-J가 원래 학습했던 사전학습 데이터의 분포와 CCNet 데이터 분포 사이의 distribution shift 때문일 수 있다.
■ OPT와 GPT-3는 모든 언어에 걸쳐 취약한 성능을 보였는데, 그 이유는 영어로 답하라는 지시에도 불구하고 그러지 못했기 때문이다. 저자들은 GPT-J가 이 문제를 겪지 않는 이유에 대해, GPT-J가 OPT, GPT-3보다 더 많은 다국어 데이터로 학습되었기 때문으로 추정한다.
■ 상한선을 확인하기 위해, context와 질문이 모두 영어로만 제공되는 MLQA 변형에서 GPT-J와 GPT-3를 평가했다. 이 설정에서는 예상대로 더 거대한 모델인 GPT-3가 더 우수한 성능을 달성했다. 이는 MLQA에서 GPT-3의 저조한 성능이 학습한 다국어 데이터가 부족했기 때문이라는 가설을 뒷받침한다.
4.2.5 Temporal Datasets
■ calendar API의 유용성을 확인하기 위해, TEMPLAMA 벤치마크와 저자들이 DATESET이라고 명명한 새로운 데이터셋에서 모든 모델을 평가한다.
■ TEMPLAMA는 시간이 지남에 따라 변하는 사실들에 대한 빈칸 채우기(예: "Cristiano Ronaldo plays for ___")와 2010년에서 2020년 사이의 각 연도별 정답을 포함하도록 Wikidata에서 구축된 데이터셋이다.
■ DATESET (Appendix D)은 템플릿을 통해 생성되었으며, 무작위 날짜와 기간의 조합(예: "30일 전은 무슨 요일이었는가?")으로 채워진다. 이러한 질문들에 답변하려면 현재 날짜를 인지하고 있어야만 한다.
■ 두 tasks 모두 LAMA와 동일한 평가 기준을 적용한다.
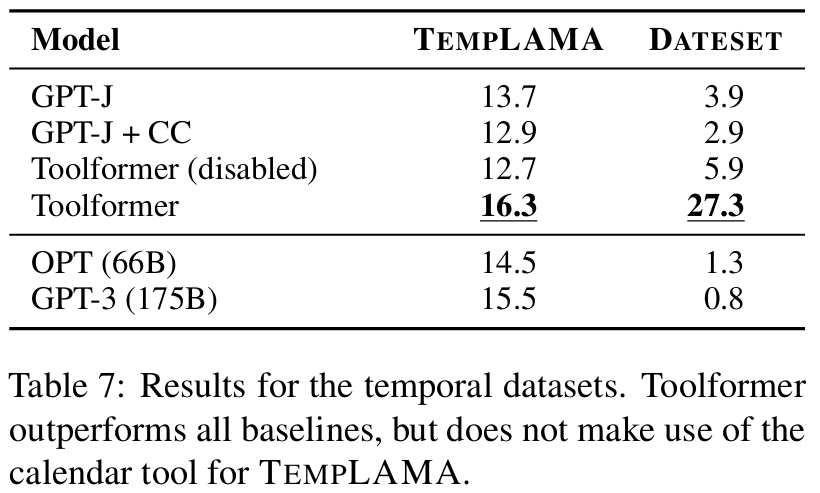
■ Table 7에 제시된 결과는 Toolformer가 TEMPLAMA와 DATESET 모두에서 baseline을 능가함을 보여준다.
■ 그러나 TEMPLAMA에서의 성능 향상은 calendar tool 덕분이 아니다. calendar tool은 0.2%만 호출되었고, 주로 Wikipedia Search와 QA tool이 호출되었다.
■ 이는 TEMPLAMA의 고유명사들이 너무 구체적이고 희귀해서, 설령 정확한 오늘 날짜를 안다고 해도 정답을 맞히는 데 거의 도움이 되지 않는다는 점을 감안하면 이치에 맞는 결과이다.
■ 사실 이 데이터셋을 풀기 위한 최선책은 "먼저 calendar API를 호출해 오늘 날짜를 알아낸 다음 → 그 날짜를 포함하여 QA 시스템에 다시 질문을 던지는 것"이다.
■ 그러나 저자들이 설정한 (1) '입력당 최대 1회의 API 호출만 허용'이라는 제약과 (2) 학습 데이터의 API calls이 독립적으로 샘플링되었기 때문에, 현재의 Toolformer가 두 도구를 연속해서 사용하는 법을 스스로 학습하기는 무척 어렵다.
■ 반면 DATESET의 경우는 전적으로 calendar tool 덕분이다. 전체 예시의 54.8%에서 calendar tool을 사용했다.
4.3 Language Modeling
■ 섹션 4.2를 통해 downstream tasks에서 성능이 향상되었음을 확인하는 것 외에도, Toolformer 본연의 언어 모델링 성능이 API calls 데이터를 활용한 파인튜닝 과정에서 전혀 저하되지 않았음을 검증한다.
■ 이를 위해 두 가지 언어 모델링 데이터셋에서 모델들을 평가한다: WikiText와 학습에 사용되지 않은 CCNet의 10,000개 (randomly selected) documents
■ Table 8은 모델들의 perplexity 값을 나타낸 것이다.

■ GPT-J의 원래 사전학습 데이터가 WikiText에 더 가까웠음을 알 수 있다. (WikiText 9.9 vs CCNet 10.6)
■ 여기에 CCNet으로 파인튜닝하면(GPT-J + CC), 분포가 이동하면서 CCNet에서의 성능은 약간 향상되고 WikiText에서의 성능은 약간 저하되는 것을 볼 수 있다. (WikiText 10.3 vs CCNet 10.5)
■ 가장 중요한 점은 \( \mathcal{C}^* \)로 학습한 것이, inference time에서 API calls을 비활성화한 상태에서 \( \mathcal{C} \)로 학습한 것 대비 perplexity 증가를 일으키지 않는다는 것이다.
- API calls이 활성화된 Toolformer의 perplexity는 평가하지 않았다.
- 이전 토큰들이 주어졌을 때 현재 토큰의 확률을 계산하려면, 모델이 해당 위치에서 생성할 수 있는 모든 potential API calls에 대해 marginalizing을 해야 하는데, 이는 연산량 측면에서 불가능하기 때문이다.
4.4 Scaling Laws

■ 이 섹션에서는 LM의 size를 변화시킴에 따라, 외부 도구에 도움을 요청하는 능력이 성능에 어떤 영향을 주는지 확인한다.
■ 이를 위해 GPT-J뿐만 아니라 GPT-2 family에서 파생된 훨씬 더 작은 4개의 smaller models (각각 124M, 355M, 775M, 1.6B)에도 저자들의 접근법을 적용한다.
■ 이 실험에서는 QA system, calculator, Wikipedia search engine 세 가지 도구의 subset만 사용한다. 이를 제외한 나머지 조건은 섹션 4.1과 동일한 실험 설정을 따른다.
■ Fig 4는 제공된 도구를 제대로 활용하는 능력은 파라미터 크기가 대략 775M에 도달했을 때 발현되기 시작함을 보여준다. 그보다 더 size가 작은 모델들은 도구 유무와 관계없이 비슷한 성능을 달성한다.
■ 예외는 QA 벤치마크에 쓰인 Wikipedia search engine으로, 저자들은 이 검색 API가 다른 도구들보다 사용하기 비교적 쉬웠기 때문이라고 가설을 세운다.
■ 모델이 커질수록 API calls 없이도 task를 더 잘 풀게 되지만(빨간선), 제공된 API를 잘 활용하는 능력(파란선)도 향상된다. 결과적으로, 가장 큰 모델에서 API call 유무에 따른 성능 격차가 유지되는 것을 볼 수 있다.
5. Analysis
Decoding Strategy

■ 섹션 4.2에 소개한 디코딩 전략의 영향을 확인한다. 이 전략은 <API> 토큰이 "상위 \( k \)개의 확률 높은 토큰" 안에 포함되기만 하면 <API> 토큰을 생성하도록 만든 것이다.
■ Table 9에서 \( k \) 값이 증가함에 따라 모델이 더 많은 예제에서 API를 적극적으로 호출하는 것을 볼 수 있다.
■ \( k = 1 \)(일반적인 greedy decoding)일 때는 API calls의 비율이 각각 40.3%와 8.5%에 불과했지만, \( k = 10 \)으로 늘리자 호출 비율이 98.1%와 100%가 된다.
■ 중요한 점은 \( k = 1 \)일 때에도 모델은 도구의 도움 없이 풀었다가 틀릴 것 같은 문제들에 대해서는 API를 호출하기로 결정했다는 것이다.
■ 이는 \( k=1 \)에서의 성능(44.3, 19.9)이 처음부터 API calls을 전혀 하지 않았을 때의 성능(34.9, 18.9) 보다 높다는 사실에서 확인된다. 단, 이 능력은 \( k \) 값이 커질수록 도구 사용이 남발되어 사라진다.
Data Quality
■ 접근법으로 생성된 API calls의 품질을 분석한다. Table 10은 API calls로 증강된 CCNet 텍스트의 몇 가지 예시들과, 이를 필터링하는 기준으로 사용된 \( L_i^- - L_i^+ \) 점수, 그리고 모델이 삽입한 API calls이 주어진 문맥에서 직관적으로 유용한지 여부를 보여준다.

■ \( L_i^- - L_i^+ \)가 높은 것들은 대체로 유용한 API calls에 해당되며, 낮은 값은 미래 토큰 예측에 유용한 정보를 제공하지 않는 호출에 해당된다.
■ 무론 호출 결과가 아무런 관련 없는 정보임에도 불구하고 우연히 perplexity를 감소시킨 경우도 있다. ([WikiSearch("Fast train success")])
■ 저자들은 이렇게 필터링되지 않고 섞여 들어간 이러한 약간의 노이즈가 실제로 유용할 수 있다고 주장한다.
■ 왜냐하면 이러한 노이즈들은 \( \mathcal{C}^* \)로 파인튜닝된 모델이 맹목적으로 API가 반환한 결괏값을 따르지 않도록 만들기 때문이다.
- 만약 학습 데이터의 모든 API calls이 완벽하게 유용했다면, 모델은 학습 결과를 기반으로 "A라는 <API>의 응답이 주어지면 이를 반드시 다음 토큰 예측에 활용"과 같은 규칙을 맹목적으로 따라할 가능성이 크다.
- 이는 추론 시점의 실제 환경을 충분히 반영하지 못한다. 실제 API 응답은 문맥과 무관한 정보를 반환하거나, 오류가 포함된 결과, 혹은 부분적으로만 정확한 결과를 반화할 수 있기 때문이다.
- 즉, 모델이 API 응답을 무조건적으로 신뢰할 경우 잘못된 정보를 context로 삼아 next token 예측을 진행하여 최종 결과의 정확성을 떨어뜨릴 수 있다.
- 그래서 저자들이 주장하는 것은 적당한 노이즈가 이러한 문제에 대한 robustness를 향상시킬 수 있다는 것이다.
6. Limitations
■ 첫째, Toolformer는 도구들을 chain 방식으로 사용할 수 없다. 즉, 한 도구의 출력을 다른 도구의 입력으로 사용하는 능력이 부족하다.
■ 이는 각 도구에 대한 API calls이 독립적으로 생성되었기 때문이며, 파인튜닝 데이터셋에 체인 방식의 도구 사용의 예시가 존재하지 않기 때문이다.
■ 둘째, 현재의 접근법은 LM이 도구를 interactive로 사용하는 것을 허용하지 않는다.
■ 사람은 검색 엔진을 사용했을 때, 검색 결과를 보고 쿼리가 더 구체적이어야 하는지 아닌지 판단하고, 필요하면 쿼리를 재구성해서 검색한 다음, 여러 검색 결과들을 비교할 수 있다. 그러나 현재의 Toolformer는 이러한 능력이 없다.
■ 셋째, Toolformer로 학습된 모델들이 API 호출 여부를 결정할 때 입력된 프롬프트의 워딩에 민감하게 반응한다. 이는 LM의 zero-shot 및 few-shot 설정 모두에서 제공되는 프롬프트에 민감하다는 것이 알려져 있음을 고려하면 의외로운 결과는 아니다.
■ 넷째, 방법론이 매우 sample-inefficient이다. 예를 들어, 100만 개 이상의 문서에서 calculator API에 대한 유용한 호출 예시는 수천 개에 불과하다.
■ 이 문제에 대한 잠재적인 해결책은 bootstrapping 접근법들에서 수행되는 방식과 유사하게, 저자들의 접근 방식을 반복적으로 여러 번 적용하여 데이터를 늘려가는 것일 수 있다.
■ 마지막으로, API call 여부를 결정할 때 현재의 Toolformer는 API를 호출함으로써 발생하는 비용을 고려하지 않는다.
- 각 도구(예: GPT-4 API, calculator API 등)는 서로 다른 비용을 가진다.


