■ 실제 에이전트 서비스에서는 human user와의 interaction이나 domain-specific rules을 따르는 능력이 중요하지만, 기존 벤치마크들은 이러한 능력들을 충분히 평가하지 못한다.
■ 논문에서는 τ-bench를 제안하며, 이를 통해 language agent가 (language models에 의해 시뮬레이션된) user와의 dynamic conversations 속에서, 제공받은 API tools 및 policy guidelines을 바탕으로 문제를 해결하는 능력을 종합적으로 평가하고자 한다.
■ 대화가 끝난 후, database state를 annotated goal state와 비교하는 효율적이고 신뢰할 수 있는 평가 프로세스를 채택한다.
■ 또한, 여러 번의 시도에 걸쳐 에이전트의 행동의 신뢰성을 평가하기 위한 새로운 지표 pass^k를 제안한다.
■ 저자들의 실험에 따르면, gpt-4o와 같은 SOTA function calling agents조차도 tasks의 절반 미만만 성공적으로 해결하며, 상당히 일관성이 부족(retail 도메인에서는 pass^8이 25% 미만)한 것으로 나타났다.
[2406.12045] $τ$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
$τ$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Existing benchmarks do not test language agents on their interaction with human users or ability to follow domain-specific rules, both of which are vital for deploying them in real world applications. We propose $τ$-bench, a benchmark emulating dynamic co
arxiv.org
1. Introduction
■ language agent를 실제 서비스에 배포하려면 다음과 같은 필수 조건들이 충족되어야 한다.
- (1) long horizons에 걸쳐 사용자와 프로그래밍 방식의 API와 자연스럽게 상호작용하여 정보를 점진적으로 수집하고 사용자의 의도를 해결할 수 있어야 한다.
- (2) 특정 task나 도메인에 대한 복잡한 정책과 규칙을 정확하게 준수해야 한다.
- (3) 수백만 번의 상호작용 전반에 걸쳐 일관성과 신뢰성을 유지해야 한다.
■ 논문에서는 이를 Fig 1의 항공권 예약 에이전트의 사례로 설명한다.
- 사용자가 예약 변경을 요청할 때, 에이전트는 사용자와 상호작용하여 필요한 정보를 수집하고,
- 제공된 가이드라인을 사용하여 항공사 규정을 확인한 다음,
- reservation API들을 사용하여 새로운 항공편을 찾고 가능한 경우 재예약까지 수행해야 한다.
- 또한, 에이전트는 동일한 요청을 하는 다양한 종류의 사용자에게 일관된 행동을 보여야 한다. 동일한 요청이라도 사용자마다 대화 흐름이 조금씩 달라질 수 있는데, 에이전트는 이런 변화에도 robust하게 일관성을 유지해야 한다.

■ 실제 서비스 환경에서 신뢰할 수 있는 에이전트를 개발 및 배포하려면, 사람과의 상호작용 속에서 규칙을 준수하며 긴 문맥의 reasoning 및 planning하는 능력을 체계적으로 평가할 필요가 있다.
■ language agents을 위한 기존 벤치마크들은 종종 단순화된 instruction-following 설정을 채택하고 있는데, 이러한 설정에서는 모든 정보를 사전에 제공받은 상태로 환경(웹, 코드 터미널, APIs)과 자율적으로 상호작용한다. 그래서 human-in-the-loop 상호작용 없이, 그리고 특정 도메인의 가이드라인을 참조할 필요가 없기 때문에, 현실적인 에이전트의 능력을 충분히 검증할 수 없다.
■ 이 문제를 해결하기 위해 논문에서는 τ-bench(Tool-Agent-User Interaction Benchmark)를 제안한다.
■ τ-bench는 세 가지 요소를 포함하는 modular framework로 구축되었다: (1) realistic databases와 APIs (2) domain-specific policy documents (3) 다양한 user scenarios에 대한 instructions 및 그에 대응되는 ground truth annotations
■ 저자들은 첫 번째 demonstration으로 customer service 영역에 초점을 맞추어, 에이전트가 (다양한 요청을 가진 시뮬레이션된) 사용자를 지원해야 하는 두 개의 서로 다른 도메인 τ-retail과 τ-airline을 구축한다.
■ 데이터 생성과 사용자 시뮬레이션에는 language model의 생성 능력을 활용하되, 여기에 manual annotation과 verification을 결합하여 벤치마크의 현실성과 품질을 확보한다.
■ τ-bench는 (1) manual schema 및 API design, (2) data entries에 대한 LM-assisted generation, (3) user simulator를 위한 manual scenario generation 및 verification의 세 단계를 거쳐 구축된다.
■ 평가 시에는 각 에피소드가 끝날 때의 데이터베이스 상태를 ground truth로 기대되는 상태와 비교한다. 이러한 방식은 대화 표현이나 상호작용 과정에는 확률적 변동(예: 사용자가 동일한 요청을 다른 방식으로 제기)이 존재하더라도, 결과적으로 도달해야 할 데이터베이스 상태가 동일하면 같은 성공으로 인정할 수 있게 해 준다.
■ 즉, 대화 자체는 다양하게 전개될 수 있지만, 최종 outcome을 기준으로 agent의 의사결정을 객관적으로 측정할 수 있도록 설계된 것이다.
■ 그리고 저자들은 \( k \)번의 i.i.d. trials에 걸쳐 에이전트의 consistency와 robustness를 측정하는 pass^k라는 지표도 제안한다.
2. Related Work
■ 에이전트 및 task-oriented dialogue systems을 위한 기존 벤치마크의 대부분은 대화 능력 또는 도구 사용 능력 중 하나만 평가하는 데 초점을 맞추어 왔다.
■ 반면 τ-bench는 이 둘을 현실적인 설정 하에서 통합적으로 평가하고, 더 나아가 에이전트가 특정 도메인 정책을 일관된 방식으로 잘 따를 수 있는지 함께 검증하는 것을 목표로 한다.
Benchmarks for language agents and tool use
■ LM 기반 에이전트를 평가하기 위해 여러 벤치마크가 개발되었다. 최근에는 LM의 도구 사용 능력, 즉 API 집합에서 올바른 함수 호출을 생성하는 능력을 평가하는 데 중점을 두고 있다.
■ Berkeley Function Calling Leaderboard (BFCL), ToolBench, MetaTool과 같은 연구들은 다수의 프로그래밍 언어에서 도구 사용 및 함수 호출을 테스트하며, 함수 호출의 정확도를 평가하기 위한 다양한 방법론을 제안한다.
■ 그러나 이러한 tool-use 능력을 평가하는 연구들은 에이전트와 상호작용하는 인간이 초기 instruction에 필요한 모든 정보를 담아 제공하는 single-step의 사용자 상호작용만을 포함하고 있다.
■ 즉, 사용자가 처음부터 필요한 모든 정보를 한 번에 제공하고, 에이전트는 그 정보를 바탕으로 적절한 도구 호출을 수행하기만 하면 된다.
■ 대조적으로 τ-bench는 에이전트가 필요한 정보와 권한을 얻기 위해 인간 사용자와 여러 차례 상호작용해야 하는 보다 현실적인 설정에 초점을 맞춘다.
Task-oriented dialogue
■ task-oriented dialogue 분야는 오랫동안 domain-specific offline datasets이나 user simulators를 구축하려는 노력이 있었다.
■ 전자의 벤치마크 유형은 정적이며, 미리 수집한 conversation trajectories에 대해서만 conversational agent를 테스트한다.
■ 후자의 경우 rule-based이거나 symbolic specifications에 의존하는 user simulators, 혹은 crowdsourcing platforms을 통해 실제 사람을 대상으로 테스트를 수행한다.
■ 최근에는 LM을 응답 평가자로 사용하거나, 사용자를 시뮬레이션하는 LM의 능력을 검증하는 연구도 등장하고 있다.
■ τ-bench는 에이전트를 평가할 목적으로, 텍스트 형태의 시나리오 설명을 사용하여 현실적인 사용자 발화와 긴 문맥의 대화를 시뮬레이션하기 위해 SOTA LM의 텍스트 생성 능력을 사용한다.
■ 이를 통해, 정확히 동일한 시나리오를 다시 실행하더라도, LM의 확률적 샘플링 덕분에 다양하면서도 시나리오에 충실한 대화 변형을 생성할 수 있으며, 이는 에이전트의 일관성을 테스트하는 데 매우 유용(섹션 5.1)하다.
User simulation with LMs
■ 이 논문은 human characters의 시뮬레이터로서 LM을 사용하려는 연구들과도 관련이 있다.
■ 여기에는 text adventure game 내의 non-player characters (NPCs), 인간과 유사한 사회 내의 multiple agents, 또는 collaborative tasks을 시뮬레이션하고, 온라인 쇼핑이나 웹 검색과 같은 tasks에서 human-in-the-loop 상호작용을 수행하는 연구들이 포함된다.
■ 그러나 이러한 모든 연구들은 LM이 얼마나 현실적인 시뮬레이션을 가능하게 하는가를 보여주는 데 초점을 맞추었으며, 시뮬레이터를 사용하여 에이전트의 신뢰성을 평가하는 데까지 나아가지는 않았다.
■ 이에 비해 τ-bench는 인간과 수백만 번의 현실 세계 상호작용을 수행하는 시스템에 배치될 AI 에이전트의 reliability와 robustness에 대한 정확한 평가를 위해서 이러한 현실적인 사용자 시뮬레이션을 사용한다.
3. τ-bench: Abenchmark for Tool-Agent-User Interaction
■ 저자들은 τ-bench의 각 개별 task를 state space \( \mathcal{S} \), action space \( \mathcal{A} \), observation space \( \mathcal{O} \), transition function \( \mathcal{T} : \mathcal{S} \times \mathcal{A} \to \mathcal{S} \times \mathcal{O} \), reward function \( \mathcal{R} : \mathcal{S} \to [0, 1] \), 그리고 instruction space \( \mathcal{U} \)를 갖는 partially observable Markov decision process (POMDP) \( (\mathcal{S}, \mathcal{A}, \mathcal{O}, \mathcal{T}, \mathcal{R}, \mathcal{U}) \)로 공식화한다.
■ 에이전트는 task를 완료하기 위해 API tools을 통한 (1) databases (db) (2) 시뮬레이션된 user 양쪽 모두와 상호작용한다. 즉, \( \mathcal{S} = \mathcal{S}_{db} \otimes \mathcal{S}_{user} \), \( \mathcal{A} = \mathcal{A}_{db} \cup \mathcal{A}_{user} \), \( \mathcal{O} = \mathcal{O}_{db} \cup \mathcal{O}_{user} \)이다.
■ 그리고 에이전트에게는 반드시 준수해야 할 규칙이 포함된 domain-specific policy document가 제공되며, 이는 해당 도메인이 어떻게 돌아가는지를 설명하는 역할을 한다.

Databases and APIs
■ 각 τ-bench 도메인은 여러 데이터베이스와 이에 관련된 API들을 가지고 있다.
■ 데이터베이스의 내용은 상태 \( s_{db} \)(Fig 2a)로 구성되며, 에이전트와 사용자에게 숨겨져 있어, 에이전트와 사용자 모두 직접 볼 수 없다. 오직 "tool_name(**kwargs)" 형태의 API actions \( a_{db} \)를 통해서만 읽거나 쓸 수 있다.
■ 데이터베이스에 대한 action이 실행될 때 transition \( \mathcal{T}_{db} : (s_{db}, a_{db}) \to (s'_{db}, o_{db}) \)는 deterministic으로 일어나며, 파이썬 함수로 구현되어 있다. (Fig 2b)
- 특정 db 상태(\( s_{db} \))에서 에이전트가 특정 API action(\( a_{db} \))을 취하면, db가 새로운 상태(\( s'_{db} \))로 업데이트되고 에이전트에게 결과(\( o_{db} \))를 반환한다.
- db를 조작할 수 있는 API들이 파이썬 코드로 구현되어 있어(Fig 2b), 동일한 입력이 주어지면 동일한 결과를 내놓는 'deterministic'한 특성을 지닌다. 이를 통해 db의 상태를 변경할 수 있으며, 결과를 반환받는다.
Domain policy
■ 각 도메인은 domain databases, task procedures, 그리 상호작용 시 에이전트가 따라야할 제약을 설명하는 policy(Fig 2c)를 가지고 있다.
■ 일부 제약 사항은 API 내의 확인 절차로 구현되어 있다.
- 예를 들어 사용자 프로필에 없는 결제 ID를 사용할 경우 \( o_{db} = \text{"Error: payment not found"} \)라는 에러가 발생할 수 있다.
■ 반면 어떤 제약 사항들은 API에 구현되어 있지 않다.
- 예를 들어 항공사 정책에는 항공사 정책에는 멤버십 등급과 객실 클래스에 따라 수하물 허용량이 다르게 명시되어 있지만, 실제 환경의 상담원에게 주어지는 자유도와 유사하게, 에이전트는 book_reservation API에서 요금을 지불해야 할 수하물의 개수를 정확히 기입해야 한다.
User simulation
■ 에이전트와 상호작용하는 인간 사용자를 시뮬레이션하기 위해 LM(gpt-4-0613)을 사용한다.
■ 사용자 상태 \( s_{user} \)는 task instruction이 포함된 초기 system prompt(Fig 2d)와 함께 현재까지 사용자와 에이전트 간의 전체 대화 기록으로 구성된다.
■ 사용자는 에이전트와 API tools 간의 상호작용 기록을 볼 수 없다. 에이전트는 임의의 자연어 메시지를 사용하여 사용자와 상호작용할 수 있다.
- 예를 들어 \( a_{user} \)는 예약이 변경되었는지 알리고 추가 요청이 있는지 묻는 식의 응답 "예약이 업데이트되었습니다. 더 도와드릴 일이 있습니까?"가 될 수 있다.
■ transition \( \mathcal{T}_{user} : (s_{user}, a_{user}) \to (s'_{user}, o_{user}) \)는 stochastic이며, 에이전트의 메시지를 대화 기록에 추가한 뒤 LM로부터 새로운 사용자 메시지를 샘플링하는 방식으로 이루어진다.
- 예를 들어, \( o_{user} \)는 그에 따라 "네, 다른 항공편도 취소하고 싶습니다."가 될 수 있다.
■ 사용자가 \( o_{user} = \text{"###STOP###"} \)을 출력하면, 에피소드가 종료되고 에이전트가 평가된다.
Task instances
■ τ-bench task의 instance는 두 부분으로 구성된다: 에이전트에게는 보이지 않는 사용자 시뮬레이션을 위한 instruction(Fig 2d)과 ground truth database write actions의 annotation
■ instruction은 도메인 정책 하에서 "오직 하나의 가능한 결과"만 나오도록 설계되며, 사용자의 identity, intent, 그리고 preferences이 규정된다.
■ 각 task episode는 시뮬레이션된 사용자가 요청을 먼저 제시하면서 시작되고, 에이전트는 대화 방식으로 이를 처리하는 동시에 언제든지 도구를 호출하고 제공된 정책을 참조할 수 있다.
■ 에피소드가 끝나면 데이터베이스 상태와 에이전트가 사용자에게 보낸 메시지를 사용하여 reward를 계산한다.
Reward
■ 저자들은 하나의 task episode의 reward \( r \)을 다음과 같이 정의한다: \( r = r_{action} \times r_{output} \in \{0, 1\} \)
■ 여기서 \( r_{action} \)은 최종 데이터베이스 상태가 정답 데이터베이스 상태와 일치하는지 여부, 그리고 \( r_{output} \)은 에이전트가 사용자에게 전달한 응답에 모든 필수 정보가 포함되어 있는지 여부를 평가하는 항이다.
■ Fig 2d의 경우, 해당 예시에서 agent–user 간 대화는 여러 방식으로 달라질 수 있고, 에이전트는 다양한 (read) actions을 호출할 수도 있다. 그러나 최종적으로 성공으로 인정되기 위한 유일한 database write action은 "return_delivered_order_items (order_id="#W2890441", item_ids=["2366567022"], payment_method_id="credit_card_1061405")"이어야 하며, 사용자 응답에 "54.04", "41.64"라는 필수 정보가 substrings로 포함되어 있어야 한다.
■ 다만 \( r = 1 \)이 항상 완전한 성공을 보장하는 것은 아니다. 예를 들어, 에이전트가 사용자 확인 없이 반품을 실행했다면, 최종 데이터베이스 상태는 정답과 같을 수 있어도 정책 위반이 발생한 것이다.
■ 그럼에도 불구하고 저자들은 자신들이 제안한 rule-based reward가 계산이 빠르고 신뢰할 수 있으며, 실험(섹션 5)에서 보여주듯 이미 현재 모델들에게도 충분히 어려운 도전 과제를 제시한다고 주장한다.
Pass^k metric
■ 코드 생성과 같은 tasks의 경우, 동일한 task에 대해 \( k \)번의 i.i.d. 시도 중 적어도 한 번 이상 성공할 확률인 pass@k가 널리 사용되어 왔다. 이 지표는 inference-time compute를 늘렸을 때, 여러 시도 중 하나에서라도 해결책을 발견할 가능성을 측정하는 데 적합하다.
■ 그러나 고객 서비스와 같이 신뢰성과 일관성을 요구하는 real-world agent tasks에서는 "한 번쯤 맞히는 것"이 아니라, 반복 실행에서도 안정적으로 같은 수준의 올바른 행동을 보이는 것이 더 중요하다.
■ 이러한 문제의식에서 저자들은 여러 tasks에 걸쳐 평균적으로 \( k \)번의 i.i.d. task trials이 "모두 성공"할 확률로 정의되는 새로운 지표인 pass^k를 제안한다.
■ pass@k가 "\( k \)번 중 하나라도 성공하면 된다"는 관점이라면, pass^k는 "\( k \)번 모두 성공해야 한다"는 훨씬 더 엄격한 기준이다. 이를 통해 에이전트가 다양한 대화 상황에서도 항상 올바른 행동을 수행하는지 측정할 수 있다.
■ 어떤 task가 \( n \)번의 trials로 실행되고 그 중 \( c \)번이 성공(\( r = 1 \))으로 끝났다면, pass^k 및 pass@k에 대한 unbiased estimates는 다음과 같다.

■ 저자들은 τ-bench에서 pass^k가 더 적절한 이유에 대해 다음과 같이 설명한다.
■ 동일한 task에 대해서는 user prompt와 database transitions는 동일하며, 오직 LM이 생성하는 사용자 메시지와 에이전트 메시지의 샘플링에서만 확률적 변동성이 발생한다.
■ pass^k는 같은 의미를 가진 task를 여러 차례 반복했을 때, agent가 대화 표현의 변화나 흐름의 작은 차이에도 불구하고 도메인 정책을 지키며 안정적으로 같은 결과를 낼 수 있는지를 측정하게 된다. 즉, pass^k는 human-agent interaction에서 요구되는 robustness와 일관된 수행 능력(즉, 에이전트의 reliability)을 반영할 수 있는, τ-bench에 적절한 지표라고 할 수 있다.
■ 저자들은 에이전트들을 비교하기 위한 지표로서 여러 tasks에 걸친 평균 보상인 \( \text{pass\textasciicircum}1 = \text{pass@}1 = \mathbb{E}[r] = \mathbb{E}[c/n] \)을 report한다.
4. Benchmark Construction
■ τ-bench는 (1) 공통 구성: 여러 도메인에서 공통으로 사용할 수 있는 domain-agnostic environment와 user simulation classes, 그리고 (2) 도메인별 데이터: 각 도메인에 특화된 database JSON files, database API Python code and documentation, domain policy text, task instances로 구성된다.
■ 또한 각 도메인 데이터는 LM 활용, 코드 실행, 그리고 인간의 레이블링 및 검증을 수반하는 3단계 절차를 통해 생성된다.
Stage I: Manual design of database schema, APIs, and policies
■ 현실 세계의 도메인을 참고하되, 이를 단순화하여 가능한 가장 단순한 데이터베이스 스키마, API 및 정책을 설계한다.
■ 단순성은 다양한 구성 요소의 일관성과 API 및 annotation을 더 용이하게 한다.
■ 그럼에도 불구하고, 최소한의 현실성을 갖춘 도메인은 최소 수십 개의 스키마, API, 규칙을 필요로 하며, 이러한 구성만으로도 기존 에이전트들에게는 충분히 어려운 과제가 된다.
Stage II: Automatic data generation with LMs
■ 첫 번째 단계가 데이터베이스 스키마, API, 정책에 대한 설계이며, 두 번째 단계는 LM을 활용한 데이터 생성이다.
■ 데이터 스키마가 설정되면, 예시 데이터 엔트리를 하나 만든 뒤, 이를 바탕으로 gpt-4를 사용해 데이터를 대량으로 샘플링할 수 있는 체계적인 코드 스니펫을 생성한다. 여기서 발생하는 코드 내의 사소한 버그는 수동으로 직접 수정한다.
Stage III: Manual task annotation and validation with agent runs
■ 이 단계에서의 핵심은 user instruction이 유일한 데이터베이스 결과로 이어지도록 보장하는 것이다.
■ 예를 들어, 선호하는 결제 수단이 명시되지 않은 경우, 사용자의 응답에 따라 서로 다른 최종 데이터베이스 상태가 나올 수 있다.
■ 이를 막기 위해 저자들은 먼저 초기 user instruction을 작성하고, 이를 gpt-4-turbo function-calling agent로 실행해 본 뒤, 생성된 trajectory를 검토하면서 user instruction을 수정하는 과정을 반복한다.
■ 이 과정은 더 이상 모호함이 존재하지 않는다고 판단될 때까지 계속되며, 실제로는 τ-retail의 각 task를 40회 이상 실행해 성공률이 낮거나 0인 task를 중점적으로 점검했다고 설명한다.
■ 또한 이 과정에서 ground truth annotation은 처음부터 새로 쓰기보다, 에이전트가 생성한 action과 output을 복사하고 편집하는 방식으로 작성할 수 있어 더 효율적이라고 말한다.
4.1 Domains
■ 앞서 설명한 구축 절차를 바탕으로 τ-retail과 τ-airline이라는 두 개의 도메인을 구축했다.
■ 저자들은 이 두 도메인을 선택한 이유에 대해, 상식에 기반하여 데이터(예: 제품, 가격, 항공편)를 합성하고 정책(예: 제품 반품, 수하물 허용량)을 제작하기가 비교적 쉽고, 다양한 작업을 허용하며, 현실 세계의 애플리케이션과 밀접하기 때문이라고 설명한다.
■ 저자들은 앞으로 더 유능한 에이전트를 평가하기 위해서는 의료, 세금, 법률과 같이 데이터와 규칙이 더 복잡한 도메인으로 확장할 수 있다고 언급한다.
τ-retail
■ 이 도메인에서 에이전트는 사용자의 대기 중인 주문의 취소 또는 수정, 배송된 주문의 반품 또는 교환, 사용자 주소 수정, 정보 제공 등의 임무를 처리해야 한다.
■ 각 제품(예: Fig 2a의 "Water Bottle")은 고유 ID를 가진 다양한 품목 옵션(예: 1000ml, 스테인리스 스틸, 파란색)을 갖는다.
■ 각 대기 중인 주문은 한 번만 취소하거나 수정할 수 있으며, 배송된 각 주문은 한 번만 반품하거나 교환할 수 있다. 그리고 품목은 다른 제품 유형으로 수정하거나 교환할 수 없다.
■ 이러한 제약조건들은 task와 AI 설계를 단순화시키며, 에이전트가 domain-specific rules을 따르고, actions을 취하기 전에 사용자에게 알리고 정보를 수집하도록 만드는 장치이다.
τ-airline
■ 에이전트는 사용자가 항공편 예약을 예매, 수정, 또는 취소하도록 돕거나 환불 처리를 도와야 한다.
■ 현실적인 비행 시간과 가격을 가진 미국 20개 도시 간의 항공편 300개를 구성하고, 직항 또는 경유 항공편을 조회할 수 있는 API tools을 만들었다.
■ 도메인 정책은 결제 수단의 조합 방식, 위탁 수하물 허용량, 항공편 변경 및 취소 등 특정 상황을 해결하기 위해 일시적으로 적용되는 제약조건이 있어 τ-retail보다 더 복잡하다.
■ 이러한 제약조건들은 멤버십 등급과 객실 클래스별로도 달라질 수 있어, 에이전트에게 multi-hop reasoning을 요구하게 된다.
4.2 Key Characteristics
Realistic dialogue and tool use
■ τ-bench는 LM을 활용하여 더 복잡한 데이터베이스와 현실적인 사용자 시뮬레이션을 갖추고 있다.
■ user instruction들 자체가 LM으로 합성된 것이더라도, LM이 생성한 사용자 발화는 자연스러운 형태를 띤다. 즉, τ-bench는 실제 human-agent interaction에 가까운 대화 환경을 재현하려는 벤치마크이다.
Open-ended and diverse tasks
■ 각 τ-bench 도메인의 데이터 스키마, API 및 규칙은 현실 세계의 도메인에 비해 단순화되었지만, 매우 다양하고 때로는 창의적인 task를 생성하기에 충분한 풍부함을 갖추고 있다.
■ 특히 저자들은 고품질 task를 여러 번 반복 실행하고 pass^k와 같은 지표로 평가함으로써, 서로 다른 모델, 방법론, research challenges을 더 신뢰성 있게 드러낼 수 있다고 본다.
Faithful rule-based evaluation
■ real-world의 에이전트들은 동일한 task에 대해서도 매우 다양한 trajectory를 보일 수 있고, 성공 기준 역시 여러 요소에 의해 결정되기 때문에 평가하기가 어렵다.
■ 결과적으로, 최종 사용자에게 task 해결 여부를 판단하고 도메인 전문가가 규칙 준수 여부를 판단하는 등 인간의 평가를 요구하는 경우가 많다.
■ 그러나 τ-bench는 이러한 느리고 주관적인 평가 대신, 도메인 정책과 사용자의 의도가 오직 하나의 데이터베이스 결과만을 허용하도록 설계함으로써, 최종 데이터베이스 상태 비교라는 단순하고 객관적인 방식으로 평가를 수행한다.
Modular extension
■ τ-bench의 코드베이스 구조는 모듈식으로 되어 있어, 새로운 도메인을 추가하거나 기존 도메인 데이터와 일관성이 있다는 전제하에 기존 도메인 안에서 데이터베이스 항목, 도메인 기능, 규칙, API, task 및 평가 지표를 추가하거나 업데이트하기가 쉽다.
5. Experiments
Models
■ SOTA 상용 및 오픈소스 LM들의 API를 통해 테스트한다.
- OpenAI GPT API (gpt-4o, gpt-4-turbo, gpt-4-32k, gpt-3.5-turbo)
- Anthropic Claude API (claude-3-opus, claude-3-sonnet, claude-3-haiku)
- Google Gemini API (gemini-1.5-pro-latest, gemini-1.5-flash-latest)
- Mistral API (mistral-large, open-mixtral-8x22b)
- AnyScale API (meta-llama-3-70B-instruct)
■ 벤치마크의 난이도 때문에 small models (7/13B)은 테스트하지 않는다.
Methods
■ 에이전트를 구성하는 방법은 function calling (FC)을 사용하는 것이다. 이는 Llama-3를 제외한 테스트된 모든 LM에서 기본적으로 지원된다.
■ FC 모드에서 모델의 시스템 프롬프트는 도메인 정책으로 설정되며, 매 턴마다 모델은 사용자에게 보낼 응답 메시지를 생성할지 도구 호출을 생성할지 자율적으로 결정한다.
■ 그리고 비교를 위해 text-formatted ReAct와 Act-only를 추가로 테스트한다. 여기서는 모델이 zero-shot으로 "Thought: {some reasoning} Action: {some JSON format action argument}"를 생성하거나 action만 생성하도록 지시받는다.
■ self-reflection이나 planning 계열의 일부 agent 방법은 이 벤치마크에 적합하지 않는데, 그 이유는 실제 사용자 응대 상황에서 사용자를 돕기에는 너무 느릴 수 있기 때문이다.
■ 각 task에서 에이전트가 수행할 수 있는 행동(도구 호출 또는 사용자 응답)을 30번으로 제한한다.
■ main results(Table 2)을 얻기 위해 각 task당 최소 3번의 trials을 실행한다.
■ LM의 temperature는 에이전트의 경우 0.0, 사용자의 경우 1.0으로 설정한다. 이는 에이전트가 가능한 결정적으로 행동하게 하고, 반대로 사용자 시뮬레이션은 더 다양한 발화를 생성하도록 설계한 것이다.
5.1 Main results
Model comparison

■ Table 2에서 function calling을 사용했을 때 gpt-4o가 가장 높은 성능을 보였으며, 모델들 사이에는 성능 편차가 상당히 큰 것을 볼 수 있다.
■ 특히 llama-3-70b와 mixtral-8x22b는 gpt-4o나 claude-3-opus 같은 SOTA 상용 모델과 비교했을 때 뚜렷한 성능 격차를 보인다.
■ 모든 모델이 τ-bench를 완벽히 해결하지 못하며, 특히 난이도가 더 높은 τ-airline에서는 gpt-4o조차 tasks의 35.2%만을 해결한다.
■ 저자들은 이처럼 모델 간 성능 스펙트럼이 넓고, task 난이도도 다양하며, 완전 해결까지의 격차가 아직 크다는 점이 τ-bench를 새로운 agent, tool-use, dialogue 모델을 평가하고 개발하기에 적합한 벤치마크로 만든다고 본다.
Method comparison

■ Fig 3은 동일한 모델이라도 function calling을 직접 지원하는 설정이 ReAct와 같은 방식보다 더 높은 성능을 달성함을 보여준다.
■ text-formatted 방법들 안에서는 reasoning trace를 포함한 ReAct가 action만 생성하는 Act-only보다 일관되게 더 도움이 되는 것을 볼 수 있다.
Agent consistency via pass^k
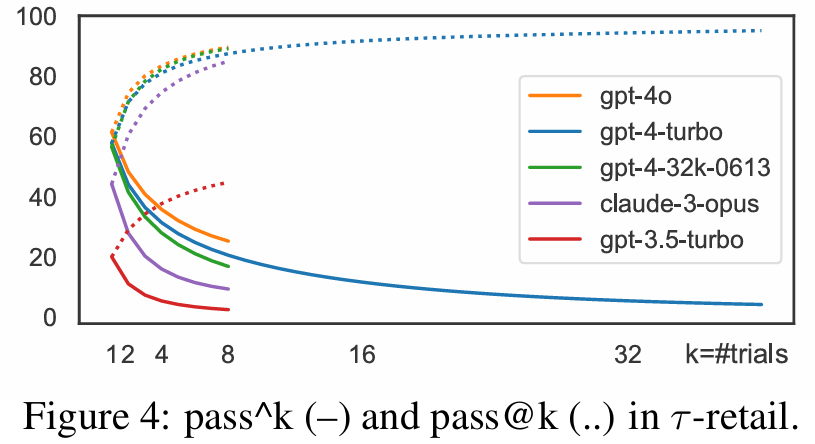
■ Fig 4에서 볼 수 있듯이, trials 수가 증가함에 따라 동일한 task를 안정적이고 일관되게 여러 번 해결할 확률은 급격히 감소한다.
■ 평균적으로 60%가 넘는 task 성공률을 갖춘 gpt-4o function calling agent도 pass^8은 25% 미만으로 하락한다.
■ 이 결과는 현재 모델들이 실제 배치에 필요한 수준의 robustness와 consistency에는 아직 크게 못 미친다는 점을 보여준다.
■ real-world scenarios에서는 단순히 평균 성공률(pass^1)이 높은 에이전트를 구축하는 것뿐만 아니라, 더 높은 robustness와 consistency을 갖추도록 구축하는 것이 매우 중요하면서도 어려운 과제이다.
Cost analysis
■ τ-retail에서 gpt-4o FC agent를 gpt-4 user simulation과 함께 사용했을 때, 각 task당 agent 및 user simulation 비용은 각각 0.38달러, 0.23달러 수준이며, task당 1회의 trial을 실행하는 데 약 200달러가 소모된다고 한다.
■ 에이전트에 대한 비용의 대부분은 입력 프롬프트에서 발생하는데, 비용의 주된 원인은 긴 시스템 프롬프트(도메인 정책 + 함수 정의)였다고 한다.
'Agent' 카테고리의 다른 글
| [Reflexion] Language Agents with Verbal Reinforcement Learning (0) | 2026.04.29 |
|---|---|
| [MemGPT] Towards LLMs as Operating Systems (0) | 2026.04.27 |
| [AgentTuning] Enabling Generalized Agent Abilities for LLMs (0) | 2026.04.22 |
| [ToolLLM] Facilitating Large Language Models to Master 16000+ Real-world APIs (0) | 2026.04.21 |
| [Gorilla] Large Language Model Connected with Massive APIs (0) | 2026.04.20 |



