■ 기존의 LLM 연구에서는 reasoning(예: CoT prompting)과 acting(예: action plan generation)이 별개의 주제로 연구되어 왔다. ReAct에서는 reasoning과 acting을 교차하여 생성하는 방식으로 이 둘의 시너지 효과를 보여준다.
[2210.03629] ReAct: Synergizing Reasoning and Acting in Language Models
ReAct: Synergizing Reasoning and Acting in Language Models
While large language models (LLMs) have demonstrated impressive capabilities across tasks in language understanding and interactive decision making, their abilities for reasoning (e.g. chain-of-thought prompting) and acting (e.g. action plan generation) ha
arxiv.org
1. INTRODUCTION
■ 인간 지능의 가장 독특한 특징은 행동을 언어적 추론(또는 내면의 목소리)과 매끄럽게 결합하는 능력이다. 이 능력은 self-regulation이나 전략 수립을 가능하게 하고 working memory를 유지하게 함으로써 사람의 인지 과정에서 중요한 역할을 한다.
■ 예를 들어 요리하는 상황에서 사람은 다음과 같이 언어를 사용하여 추론한다.
- 진행 상황을 추적하기 위해: "재료를 모두 손질했으니 이제 물을 끓여야겠다"
- 예외 상황을 처리하거나 상황에 맞게 계획을 수정하기 위해: "소금이 없으니 간장과 후추로 대체하자"
- 외부 정보가 필요할 때: "반죽을 어떻게 만들지? 인터넷을 찾아보자"
■ 그리고 내면의 질문(예: "지금 당장 무슨 요리를 만들 수 있을까?")에 답하기 위해, 동시에 실제 행동(예: 요리책 읽기, 냉장고 문 열기, 재료 확인)도 한다.
■ acting과 reasoning 사이의 이러한 시너지는 인간이 새로운 작업을 빠르게 학습하고, 이전에 본 적 없은 낯선 상황이나 정보의 불확실성에 직면했을 때 robust한 의사결정이나 추론을 수행할 수 있게 해준다.
■ 저자들은 당시 LLM이 둘 중 하나밖에 못 하고 있다고 판단했다.
■ 예를 들어 CoT는 step-by-step 방식을 통해 LLM이 산술, 상식, 기호적 추론에서 질문으로부터 답을 도출하기 위해 여러 단계의 추론 과정을 수행하는 emergent capabilities을 보여주었다.
■ 그러나 CoT reasoning은 모델이 오직 자신의 internal representations만을 사용하여 thoughts을 생성할 뿐 외부 세계에 기반하지 않는다는 점에서 "static black box"와 같다.
■ 상황에 맞게 추론하거나 knowledge를 업데이트하는 데에는 한계가 있기 때문에, 결국 추론 과정 전반에 걸쳐 hallucination (Fig 1b)이나 error propagation 같은 문제로 이어질 수 있다.

■ 그리고 working memory를 유지하지 않는 act-only 에이전트는 Fig 1 2a처럼 잘못된 무한 루프에 빠질 수 있다.
■ 일반적인 문제 해결을 위해 reasoning과 acting을 어떻게 시너지 효과가 나도록 결합할 수 있는지, 그리고 그러한 결합이 reasoning이나 acting을 단독으로 수행할 때에 비해 이점을 가져다줄 수 있는지에 대한 연구는 지금까지 없었다.
■ 논문에서는 다양한 언어 추론 및 의사결정 tasks (Fig 1)을 해결하기 위해 LM에 reasoning과 acting을 교차적으로 생성하는 ReAct를 제안한다.
■ ReAct는 LLM이 task와 관련된 언어적 추론 과정과 행동을 interleaved한 방식으로 생성하도록 프롬프팅한다.
■ 이를 통해 모델은 acting을 위한 high-level plans을 세우고, 유지하고, 조정하기 위해 동적으로 reasoning하는(reason to act) 동시에, reasoning 과정에 필요한 추가 정보를 통합하기 위해 외부 환경과 적극적으로 상호작용(act to reason)할 수 있게 해준다.
2. REACT: SYNERGIZING REASONING + ACTING
■ 에이전트가 문제를 풀기 위해 환경과 상호작용하는 일반적인 상황을 고려해 보자.
■ time step \( t \)에서 에이전트가 무슨 일을 하는지 수식으로 표현하면, 환경으로부터 관찰(observation) \( o_t \in \mathcal{O} \)를 받고, policy \( \pi(a_t|c_t) \)에 따라 행동(action) \( a_t \in \mathcal{A} \)를 취한다.
- 여기서 \( c_t = (o_1, a_1, \cdots, o_{t-1}, a_{t-1}, o_t) \)는 에이전트에게 주어진 context이다. \( c_t \)에는 첫 번째 time step부터 \( t \)번째 time step까지의 모든 관찰과 행동의 기록이다.
- policy \( \pi(a_t|c_t) \)는 \( c_t \)라는 맥락이 주어졌을 때, \( a_t \)라는 행동을 선택할 확률이다.
■ \( c_t \to a_t \) 매핑은 highly implicit 하며(\( c_t \)를 보고 \( a_t \)를 결정하는 과정이 명확하게 드러나지 않기 때문), 방대한 연산을 요구할 때, policy를 학습하는 것은 매우 어렵다.
■ 예를 들어, Fig 1(1c)의 act-only 에이전트는 trajectory의 context 전반(Act1~3과 Obs1~3)에 걸친 복잡한 추론을 수행하지 못해, 결국 올바른 final action인 Act4를 생성에 실패했다.
■ 유사하게 Figure 1(2a)의 에이전트 역시 'sinkbasin 1에는 peppershaker 1이 없다'는 사실을 context로부터 전혀 이해하지 못해 계속해서 환각적인 actions만을 생성한다.
■ ReAct의 아이디어는 단순하다. 에이전트의 action space을 \( \hat{\mathcal{A}} = \mathcal{A} \cup \mathcal{L} \)로 확장한다. 여기서 \( \mathcal{L} \)은 자연어로 표현할 수 있는 모든 것의 집합, language space이다.
■ language space에 속하는 action \( \hat{a}_t \in \mathcal{L} \)은 외부 환경에 물리적인 영향을 주지 않으므로, 외부 환경으로부터의 어떠한 observation feedback도 없다.
- 논문에서는 이 \( \hat{a}_t \)를 thought 또는 reasoning trace라고 부른다.
■ 대신, thought \( \hat{a}_t \)는 현재의 context \( c_t \)에 대해 추론함으로써 유용한 정보를 구성하고, 미래의 추론으나 다음 행동을 위해 \( c_t \)를 \( c_{t+1} = (c_t, \hat{a}_t) \)로 업데이트한다.
- \( c_t = (o_1, a_1, \cdots, o_{t-1}, a_{t-1}, o_t) \)이며, \( c_{t+1} \)에는 thought가 추가된다.
- \( c_{t+1} = (o_1, a_1, \cdots, o_{t-1}, a_{t-1}, o_t, \hat{a}_t) \), 이렇게 되면 이 thought 이후의 모든 행동과 추론은 이 thought를 기반으로 이루어진다.
- 즉, 한번 정리한 생각이 이후 단계에 계속 영향을 미치는 것이다.
■ Figure 1에서 볼 수 있듯이, \( c_{t+1} \)에 추가되는 thought에는 다양한 유형이 존재할 수 있다.
- 예를 들어, task goals을 분해하여 action plans 세우기 (2b의 Act 1; 1d의 Thought 1)
- task solving과 관련된 commonsense knowledge 주입 (2b의 Act 1)
- 관찰 결과로부터 핵심적인 부분만 추출(1d의 Thought 2, 4)
- 현재의 진행 상황을 추적하고 action plans로 전환 (2b의 Act 8)
- 예외 상황을 처리하고 action plans을 조정 (1d의 Thought 3)
■ 그러나 language space \( \mathcal{L} \)은 무한하기 때문에, \( \hat{\mathcal{A}} \)라는 확장된 action space에서 학습하는 것은 어렵다. 이 문제를 해결하기 위해서는 강한 language priors가 필요하다.
- \( \mathcal{L} \)은 사실상 무한하기 때문에, 에이전트에게 "지금 어떤 Thought를 생성해야 한다"를 학습시키는 것이 매우 어렵다. 가능한 선택지가 너무 많기 때문이다.
- 그래서 strong language priors가 필요하다. 이 상황에서 어떤 언어 표현이 자연스럽고 유용한가에 대한 사전 지식이다.
■ 저자들은 strong language priors를 위해 frozen PaLM-540B를 사용하며, few-shot in-context examples로 프롬프팅하여 domain-specific actions과 free-form language thoughts를 생성한다. (Figure 1의 1d, 2b)
■ 각각의 in-context example은 task instance를 풀기 위한 actions, thoughts, environment observations로 구성된 인간이 작성한 trajectory이다 (Appendix C).
- 추론이 중요한 task(예: Fig 1의 1)에서는, thought와 action을 번갈아 생성하여 task-solving trajectory가 여러 thought-action-observation 단계로 구성되게 한다.
- 많은 수의 actions이 필요한 의사결정 task(예: Fig 1의 2)에서는 매 action마다 thought을 붙이면 비효율적이다.
- 그래서 이런 task는 trajectory에서 꼭 필요한 순간에만 thought을 붙인다. 그리고 언제 thought을 넣을지 LM이 스스로 판단하게 한다. LM의 판단에 따라 thoughts와 actions이 비동기적으로 발생하게 된다.
3. KNOWLEDGE-INTENSIVE REASONING TASKS
■ multi-hop QA, fact verification과 같은 knowledge를 많이 필요로 하는 knowledge-intensive reasoning tasks을 다룬다.
■ Fig 1(1d)에서 볼 수 있듯이, ReAct는 Wikipedia API와 상호작용함으로써 reasoning을 뒷받침할 정보를 검색해 올 수 있으며, 동시에 다음에 무엇을 검색할지를 추론으로 결정하며, 이것이 reasoning과 acting의 시너지를 보여준다.
- Fig 1(1d)에서 추론이 검색을 안내하고("Apple Remote가 뭔지 알아야 해" → Search[Apple Remote]), 검색 결과가 다시 추론을 풍부하게 만드는("Front Row를 찾을 수 없음" → "다시 검색") 구조를 볼 수 있다.
3.1 SETUP
Domains
■ knowledge retrieval과 reasoning 능력을 시험하는 두 가지 데이터셋을 사용한다.
- (1) HotpotQA: 두 개 이상의 Wikipedia passages에 걸쳐 추론을 수행해야만 답을 찾을 수 있는 multi-hop question answering benchmark
- (2) FEVER: 특정 주장을 검증할 수 있는 Wikipedia passage가 존재하는지 여부에 따라, 각 주장을 SUPPORTS / REFUTES / NOT ENOUGH INFO로 판단해야 하는 fact verification benchmark
Action Space
■ interactive information retrieval을 지원하기 위해 세 가지 유형의 actions을 가진 단순한 Wikipedia web API를 설계한다.
- (1) search[entity]: 해당 entity의 wiki page가 존재하면 첫 5문장을 반환하고, 검색에 실패하면 위키피디아 검색 엔진에서 가장 유사한 상위 5개 entities을 제안한다.
- (2) lookup[string]: page 내에서 string을 포함하는 그다음 문장을 반환하며, 이는 웹 브라우저의 Ctrl+F 기능을 시뮬레이션한 것이다.
- (1) search를 통해 page에 진입하고, lookup으로 그 page 내에서 원하는 정보를 핀포인트 방식으로 찾는 것이다.
- (3) finish[answer]: answer를 도출하고 현재 task를 완전히 종료한다.
■ 이 API는 정확한 엔티티 이름을 알아야 하고 페이지의 일부만 검색할 수 있다. 이는 의도적으로 SOTA 성능의 lexical retriever나 neural retriever에 비해 현전히 약하게 설계되었다.
- 만약 ReAct가 좋은 성능을 낸다면, 그건 강한 retriever를 쓴 덕분이 아니라 순전히 reasoning 덕분이라고 할 수 있다.
- 즉, 성능이 약한 tool을 사용해도 reasoning을 잘하면 된다는 것을 보여주기 위한 설계이다.
3.2 METHODS
ReAct Prompting
■ HotpotQA와 Fever를 위해, training set에서 각각 6개와 3개의 케이스를 무작위로 선택하고, 수작업으로 ReAct 형식의 trajectory를 직접 작성하여 이를 few-shot exemplar로 사용한다.
- 이보다 더 많은 예시를 넣는 것이 성능 향상에 도움이 되지 않음을 확인했다고 한다.
■ 각 trajectory는 여러 thought-action-observation 단계로 구성되며, 여기서 free-form thoughts는 매우 다양한 목적으로 사용된다. 사용 예시는 다음과 같다. (Appendix C)
- decompose questions: "x를 검색하고 y를 찾은 다음, z를 찾아야겠다"
- Wikipedia observations에서 정보 추출: "x는 1844년에 시작되었다", "이 페이지는 x에 대해 알려주지 않는다"
- commonsense reasoning: "x는 y가 아니니까, z임에 틀림없다"
- arithmetic reasoning: "1844 < 1989"
- search reformulation: 검색에 실패했을 때, "대신 x를 search/look up한다."
- synthesize the final answer: "... 그러므로 정답은 x이다"
Baselines
■ ReAct에서 어떤 요소가 중요한지 확인하기 위해, ReAct trajectory에서 특정 요소들을 하나씩 제거해서 각각을 baseline으로 만들었다. baselines은 다음과 같다.
- (1) Standard prompting (Standard): ReAct에서 모든 thoughts, actions, observations을 제거한 모델. 질문을 받으면 바로 답하는 가장 기본적인 방식.
- (2) Chain-of-thought prompting (CoT): actions과 observations을 완전히 제거하고, 오직 reasoning만 수행.
- 추가로, inference 과정에서 temperature 0.7로 설정하여, 21개의 서로 다른 CoT trajectories을 샘플링한 뒤, 다수결 투표에 따라 가장 많이 나온 답변을 선택하는 self-consistency baseline (CoT-SC).
- (3) Acting-only prompt (Act): ReAct에서 thoughts만 제거한 모델.
Combining Internal and External Knowledge
■ ReAct가 보여주는 문제 해결 과정은 더 사실적이고 근거가 있는 반면, CoT는 논리적인 추론 구조를 형성하는 데 더 정확하지만 환각에 취약하다는 점을 관찰했다.
■ 그래서 ReAct와 CoT-SC의 장점만을 취합하여 결합하고, 아래의 heuristics을 기반으로 언제 다른 방법으로 전환할지를 모델이 스스로 결정하도록 했다.
- (1) ReAct → CoT-SC: ReAct가 주어진 steps 내에 정답을 찾지 못하면, CoT-SC로 전환(즉, 내부 지식 추론으로 진행)한다. steps을 HotpotQA는 7, FEVER는 5로 설정했는데, 그 이상 steps을 늘려도 ReAct의 성능이 향상되지 않음을 확인했다고 한다.
- (2) CoT-SC → ReAct: \( n \)개의 CoT-SC 샘플 중 다수결을 통해 도출된 정답의 비율이 전체의 절반 \( n/2 \) 미만으로 나타나면, ReAct로 전환(즉, 내부 지식만으로 부족하니 외부 검색을 진행)한다.
Finetuning
■ 방대한 양의 reasoning traces과 actions을 사람이 수작업으로 만들기는 어렵기 때문에, 저자들은 bootstraping approach를 채택했다.
■ ReAct(다른 베이스라인들도 포함)가 생성하여 최종적으로 정답을 맞힌 3,000개의 trajectory들을 사용해서, 더 작은 언어 모델(PaLM-8B 및 62B)을 파인튜닝한다. 정답을 맞힌 trajectory들만 사용하여 검증된 올바른 경로만 학습에 사용하는 것이다.
■ 이 파인튜닝의 목적은 작은 모델들이 input questions/claims을 조건으로 하여 trajectories(모든 thoughts, actions, observations)을 생성하도록 가르치는 것이다.
3.3 RESULTS AND OBSERVATIONS
ReAct outperforms Act consistently
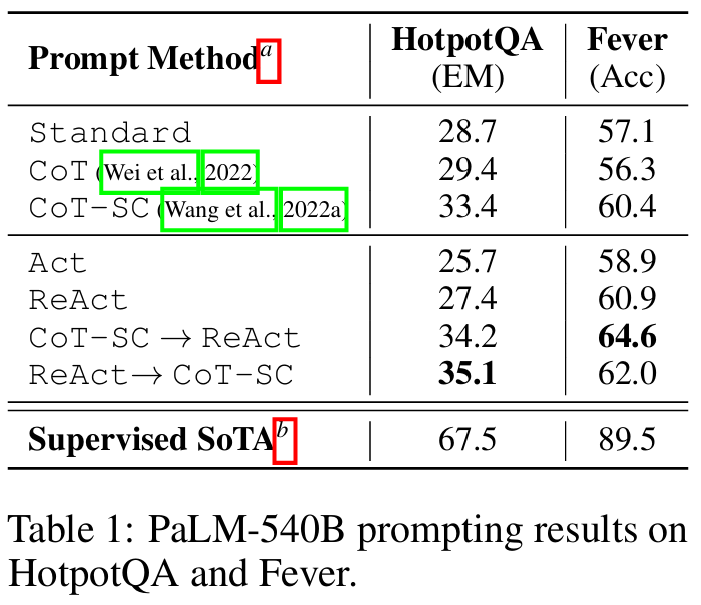
■ Table 1은 PaLM-540B를 사용하여 여러 프롬프팅 기법을 적용했을 때의 HotpotQA와 Fever 결과이다.
■ ReAct는 두 task 모두에서 act-only 모델(Act)보다 높은 성능을 달성했다. 이는 acting을 올바른 방향으로 가이드하고, 흩어진 정보들을 모아 최종 정답을 종합해 내는 데 있어 reasoning이 중요함을 보여준다.
■ 파인튜닝 결과 역시 추론 과정이 정보에 입각한 acting을 이끌어낸다는 이점을 보여준다.
ReAct vs. CoT
■ ReAct는 FEVER에서 CoT를 능가(60.9 vs. 56.3)하지만, HotpotQA에서는 CoT보다 약간 뒤처진다(27.4 vs. 29.4).
■ FEVER에서 SUPPORTS와 REFUTES 주장들은 아주 미세한 단어 하나 차이일 수 있어서, 정확하고 최신 지식을 검색해 오는 acting이 필수적이다.
■ 저자들은 HotpotQA에서 ReAct와 CoT 간의 행동 차이를 확인하기 위해, 두 모델에서 정답과 오답을 낸 trajectory를 각각 50개씩 랜덤 샘플링하여(총 200개), 이들의 성공 및 실패 원인을 수작업으로 레이블링했다. (Table 2)

A) Hallucination is a serious problem for CoT
■ CoT의 문제는 hallucination이다. CoT는 성공에서 ReAct보다 훨씬 높은 false positive rate를 보였으며, 오답을 낸 원인이 56%가 hallucination에서 비롯되었다.
■ 반면, ReAct의 문제 풀이 trajectory는 외부의 knowledge base에 접급할 수 있어, 훨씬 더 사실적이고, 근거가 있으며, 신뢰할 수 있다.
B) While interleaving reasoning, action and observation steps improves ReAct’s groundedness and trustworthiness, such a structural constraint also reduces its flexibility in formulating reasoning steps
■ reasoning, action, observation steps을 interleaving하는 것은 ReAct의 groundedness와 trustworthiness를 높여주지만, 이러한 구조적 제약은 추론 단계를 유연하게 만드는 능력을 감소시켜 CoT보다 더 높은 reasoning error rate를 가지는 원인이 된다.
- ReAct의 reasoning, action, observation steps 구조는 CoT와 비교했을 때, 모델이 완전히 자유롭게 생각을 전개하도록 허용하는 구조가 아니다. \( \hat{a}_t \) 사용이 추론의 유연성을 제한하는 제약이 된다.
■ ReAct에 특유한 빈번한 오류 패턴은, 모델이 이전에 썼던 thoughts과 actions을 반복적으로 생성하는 것이다.
■ 저자들은 이 문제가 최적이 아닌 greedy decoding 때문일 수 있으며, beam search와 같은 더 나은 디코딩 방식을 사용하면 이 문제를 해결하는 데 도움이 될 수 있다고 주장한다.
C) For ReAct, successfully retrieving informative knowledge via search is critical
■ ReAct의 경우, 검색을 통해 유용한 지식을 검색하는 것이 중요하다. non-informative search는 전체 오류 케이스의 23%를 차지하며, 모델의 추론 방향을 이탈시키고, thoughts을 회복하고 재구성하기 어렵게 만든다.
■ 그리고 Fig 4의 예시처럼 데이터셋이 구식이라 발생한 오류도 있다. HotpotQA의 레이블은 2,885개인데 ReAct가 검색한 실제 정보는 3,104개이다.

■ 이렇게 HotpotQA의 일부 질문들이 옛날 데이터로 만들어져 있어, 모델이 위키피디아에서 검색해 온 현재의 팩트와 정답 라벨 자체가 어긋나는 오류도 존재한다. 이러한 점을 고려하면 ReAct의 성능이 실제보다 낮게 평가될 수 있다.
ReAct + CoT-SC perform best for prompting LLMs
■ Table 1에서 볼 수 있듯이, HotpotQA와 FEVER에서 가장 뛰어난 성능을 낸 프롬프팅 방법은 ReAct → CoT-SC와 CoT-SC → ReAct이다.
■ Fig 2는 CoT-SC를 몇 번 샘플링하느냐에 따라 각 방법의 성능이 어떻게 달라지는지 시각화한 것이다.

■ 두 종류의 'ReAct + CoT-SC' 결합 모델은 각각 하나의 task에서 유리하지만, 둘 다 다양한 샘플 수에서 CoT-SC를 크게 그리고 일관되게 능가하며, 21개 샘플의 CoT-SC 성능을 단 3-5개의 샘플만으로 달성한다.
■ 이러한 결과들은 reasoning tasks에서 model internal knowledge과 external knowledge를 적절히 결합하는 것의 장점을 보여준다.
ReAct performs best for fine-tuning

■ Fig 3은 네 가지 방법(Standard, CoT, Act, ReAct)을 HotpotQA에 적용했을 때, 모델 크기와 파인튜닝 유무에 따른 scaling effect이다.
■ PaLM-8/62B에서 prompting ReAct는 모델 용량의 한계로 인해 in-context examples로부터 추론과 행동을 모두 학습하는 데 어려움을 보이며, 그 결과 네 가지 방법 중 가장 낮은 성능을 나타낸다.
- 몇 개의 examples만 보고 추론과 행동이라는 멀티태스킹을 동시에 배우기에는 모델 용량이 부족하다.
■ 그러나 3000개의 examples로 파인튜닝했을 때 ReAct는 네 가지 방법 중 최고가 되며, PaLM-8B finetuned ReAct가 모든 PaLM-62B prompting 방법을 능가하고, PaLM-62B finetuned ReAct가 모든 540B prompting 방법을 능가한다.
■ 반면, Standard나 CoT를 파인튜닝하는 것은 PaLM-8/62B 모두에서 ReAct나 Act를 파인튜닝하는 것보다 현저히 나쁘다.
4. DECISION MAKING TASKS
■ language-based interactive decision-making tasks인 ALFWorld와 WebShop에서 ReAct를 테스트한다.
■ 이 tasks은 모두 sparse rewards가 주어지는 환경 속에서 에이전트가 긴 시간에 걸쳐 행동할 것을 요구한다. 이 두 특성 때문에 에이전트의 강한 reasoning이 필요하다.
ALFWorld
■ ALFWorld는 embodied ALFRED benchmark의 텍스트 버전이다. 이 게임에선 에이전트가 텍스트 명령어(예: "go to coffeetable 1", "take paper 2", "use desklamp 1")를 통해 시뮬레이션된 집안을 탐색하고 상호작용함으로써 목표(예: "examine paper under desklamp")를 달성해야 한다.
■ 6가지 유형의 tasks가 포함되어 있다. 하나의 task instance에는 50개가 넘는 장소가 존재할 수 있으므로, expert policy를 사용하더라도 문제를 해결하는 데 50 step 이상이 필요할 수 있다. 에이전트가 subgoals을 계획하고 추적하며 체계적으로 탐색해야 하는 어려운 문제이다.
■ 특히, challenge한 문제 중 하나는 '흔한 일상 가정용품들이 있을 만한 그럴싸한 위치'를 스스로 판단해야 한다는 점이다. (예: 책상 조명은 책상이나 선반, 서랍장 위에 있을 확률이 높음)
■ 이는 LLM이 사전학습된 commonsense knowledge을 활용하기에 좋은 환경이 된다.
■ 저자들은 다음과 같은 ReAct 프롬프트를 사용한다. (Appendix C.4)
- 각 task 유형별로 training set에서 3개의 trajectory를 무작위로 선택하여 annotate한다.
- 각 trajectory는 (1) decompose the goal (2) track subgoal completion (3) determine the next subgoal (4) reason via commonsense where to find an object and what to do with it
■ 평가를 위해 134개의 unseen evaluation games을 사용한다. 그리고 3개의 trajectory에서 2개를 무작위로 뽑아 조합하는 방식으로 6개의 서로 다른 프롬프트를 구성하여 사용한다. 이 평가 설정은 변동성을 측정하기 위한 것이다.
■ Act의 프롬프트 역시 동일한 trajectory들을 사용하여 구성되며, thoughts 부분만 완전히 제거된 상태이다.
■ ReAct나 Act 모두 training set에서 task instance를 랜덤으로 선택했기 때문에, 이 평가 설정은 ReAct나 Act 어느 쪽에도 편향되지 않으며, thoughts의 중요성을 테스트할 수 있다.
■ baseline으로는 각 task 유형에 대해 \( 10^5 \)개의 expert trajectories로 학습된 imitation learning 에이전트인 BUTLER를 사용한다.
WebShop
■ ReAct가 노이즈가 많은 real-world language environments에서도 잘 상호작용할 수 있는지 WebShop을 통해 평가한다.
■ WebShop은 실제 현실 세계 제품들과 12k 개의 human instructions로 구성된 온라인 쇼핑 웹사이트 환경이다.
■ ALFWorld와 달리, WebShop은 다양한 구조화된/비구조화된 텍스트(예: Amazon에서 크롤링한 상품 제목, 설명, 옵션)를 포함하고 있으며, 에이전트가 실제 웹 사이트와의 상호작용을 통해 사용자 지시에 기반하여 상품을 구매해야 한다.
■ 이 task는 500개의 테스트 지시에 대한 평균 점수(선택한 제품이 사용자가 요구한 옵션 속성들을 얼마나 포함하고 있는지의 비율, 전체 에피소드에 걸쳐 평균)와 성공률(선택한 제품이 사용자의 모든 요구 사항을 100% 충족한 에피소드의 비율)로 평가된다.
■ 저자들은 검색, 제품 선택, 옵션 선택, 구매하기라는 단순한 actions만 포함하는 Act 프롬프트를 구성하고, ReAct 프롬프트에는 추가적으로 무엇을 탐색할지, 언제 구매할지, 어떤 상품 옵션이 사용자의 지시와 관련이 있는지를 결정하는 추론 과정을 포함시켰다.
■ baseline으로 1,012개의 human annotated trajectories로 학습된 imitation learning (IL) 방법과, 10,587개의 training instructions로 학습된 imitation + reinforcement learning (IL + RL) 방법을 사용한다.
Results
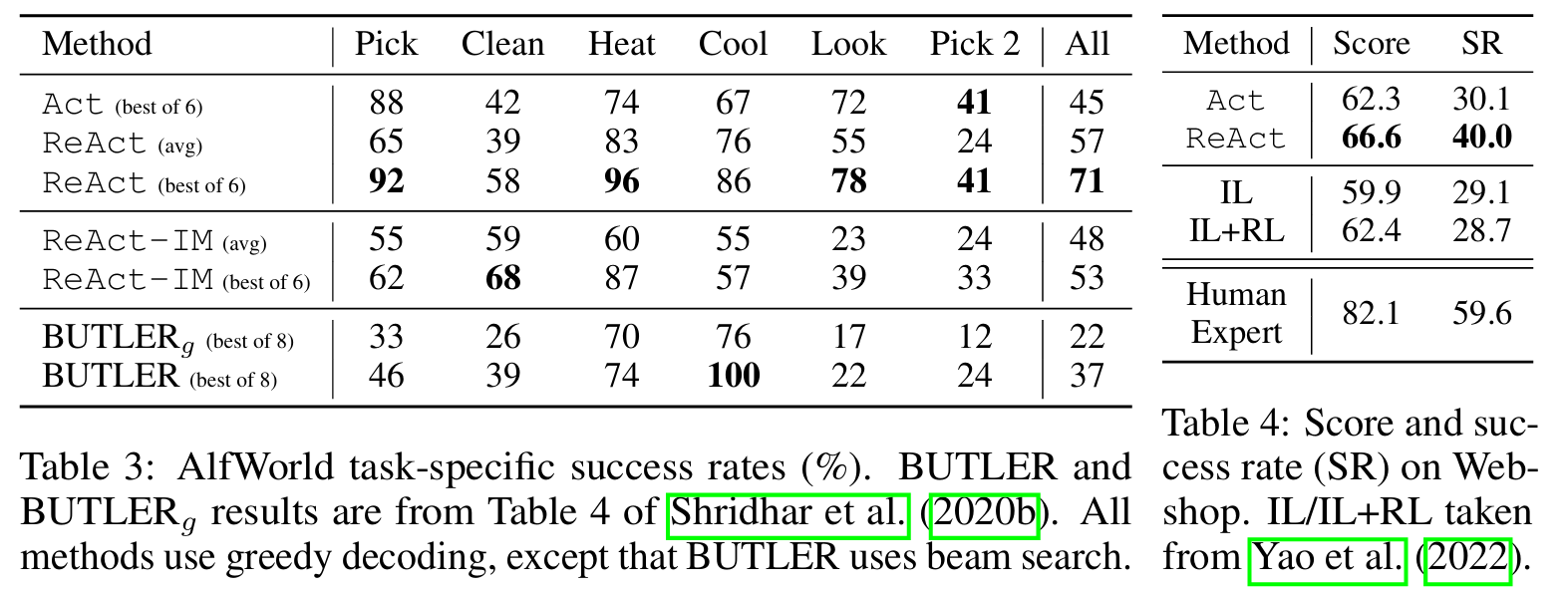
■ ReAct는 ALFWorld와 WebShop 모두에서 Act를 능가한다. 10만 번이나 훈련받은 BUTLER의 가장 좋은 점수를 크게 능가한다. 특히, ReAct의 최저점(48%)이 Act(45%)와 BUTLER(37%)의 최고점보다 높다.
■ WebShop에서 one-shot Act prompting은 IL과 IL+RL 방법과 동등한 성능을 보인다. 여기에 sparse reasoning(즉, 필요할 때만 Thought 사용)이 추가된 ReAct는 기존 최고 성공률보다 10% 향상된 훨씬 더 좋은 성능을 달성했다.
■ 그러나 모든 방법들은 여전히 human expert의 솜씨에는 한참 미치지 못하는 것을 볼 수 있다.
■ 인간은 AI보다 훨씬 더 폭넓게 제품을 탐색하고, 검색이 막히면 검색어 자체를 창의적으로 바꿔서 다시 시도하는 "쿼리 재구성"을 잘 수행한다. 이는 단순히 프롬프트를 사용하는 현재 AI에게는 여전히 풀기 힘든 과제이다.
5. CONCLUSION
■ ReAct는 LLM에서 reasoning과 acting을 시너지화하는 단순하지만 효과적인 방법이다.
■ multi-hop question-answering, fact checking, interactive decision-making tasks에서의 실험을 통해 ReAct는 결과를 해석할 수 있으면서도 가장 우수한 성능을 이끌어낸다는 것을 볼 수 있었다.
■ 그러나 ReAct는 거대한 action spaces을 가진 복잡한 tasks에서 한계가 있다. 복잡한 task를 해결하기 위해서는 더 많은 demonstrations가 필요한데, 이는 in-context learning의 입력 길이 제한(즉, 토큰 제한)을 쉽게 초과할 수 있다.
■ 이 한계는 fine-tuning approach로 어느 정도 해결할 수 있지만(섹션 3.3), 저자들은 모델의 성능을 더욱 끌어올리기 위해서는 high-quality human annotations이 필요하다고 본다.


