2. 트랜스포머 아키텍처
■ 트랜스포머 아키텍처는 다음 그림과 같다.

2.5 디코더(Decoder) 구조
■ 트랜스포머 디코더도 \( N = num layers \)개의 동일한 디코더 계층 스택을 쌓을 수 있다.
- 논문에서 사용한 \( N = 6 \)
■ 또한, 인코더처럼 디코더 계층의 sub layer 주위에는 잔차 연결을 사용하고, 그 뒤에 계층 정규화를 적용한다.
- 논문에서 적용한 층 정규화 방식은 사후 정규화
■ 그리고 sub layer로 멀티 헤드 셀프 어텐션을 가지고 있는데, 인코더의 멀티 헤드 셀프 어텐션과 다른 점은 현재 위치가 다음 위치들을 참조하지 못하도록 마스킹한 "Masked Multi-head Self-Attention"이라는 점이다.
■ 이외에도, 인코더 연산이 끝난 다음, 디코더가 \( N = num layers \)만큼의 연살을 수행하는데, 이때마다 인코더가 보낸 출력(인코더에서 생성된 표현)과 디코더의 입력에 어텐션을 사용한다.
- 이 과정에서 사용되는 어텐션을 셀프 어텐션이 될 수 없다. 인코더의 정보와 디코더의 정보가 어텐션 함수에 들어가기 때문이다.
■ 디코더에서도 피드 포워드 계층을 가지고 있다.
■ 디코더의 모든 연산이 끝나면, 그 결과는 선형 층과 소프트맥스 함수를 거쳐 output에 대한 확률을 반환한다.
2.5.1 디코더의 첫 번째 서브 층: 마스크드 셀프 어텐션(Masked Self Attention)
■ 인코더는 기본적인 멀티 헤드 셀프 어텐션을 사용하지만, 디코더에서는 마스크드 멀티 헤드 셀프 어텐션을 사용한다.
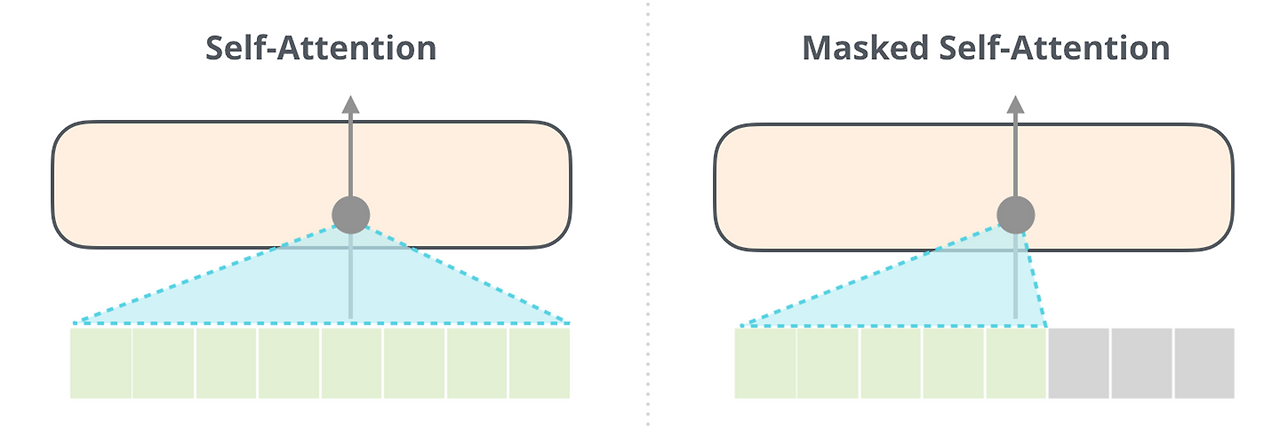
■ 트랜스포머 디코더에서 셀프 어텐션에 마스킹을 적용하는 이유는 아래와 같다.
■ 디코더는 생성을 담당하는 부분으로, 앞에서 생성한 토큰을 기반으로 다음 토큰을 생성한다. 이렇게 순차적으로 생성하는 것을 인과적(causal) 또는 자기 회귀적(auto regressive)이라고 한다.
■ 인코더와 동일하게 임베딩 층과 포지셔널 인코딩을 거친 후의 문장 행렬을 입력으로 받으며, 학습 과정에서는 인코더와 디코더 모두 완성된 텍스트(문장 행렬)를 한 번에 입력받는다. 이 문장 행렬로부터 자기 회귀적으로 토큰을 생성하는 것이다.
- 트랜스포머도 Seq2Seq와 마찬가지로 교사 강요(teacher forcing)을 사용하여 훈련할 수 있다.
■ 이렇게 하면, 문제가 되는 부분이 바로 학습 과정에서 트랜스포머의 디코더는 완성된 문장 행렬을 한 번에 입력받는다는 부분이다.
■ RNN 계열의 신경망을 디코더에 사용할 경우, RNN 특성상 입력 단어를 매 시점(time step)마다 순차적으로 입력받기 때문에 \( t \) 시점의 단어를 예측할 때, \( t \) 시점을 포함한 이전 시점에 입력된 단어들만 참고할 수 있었다. 미래 시점의 단어인 \( t + 1 \) 시점부터의 단어를 참고할 수 없는 것이다.
■ 그러나 학습 과정의 트랜스포머는 모두 완성된 문장 행렬을 한 번에 입력받기 때문에, 그대로 어텐션 연산을 수행할 경우 미래 시점에 작성해야 하는 단어까지 참고할 수 있는 현상이 발생한다.
■ 예를 들어, 영어-프랑스어 번역 문제에서 디코더가 <SOS> je suis étudiant의 문장 행렬을 학습하는 과정이라고 하자.
■ suis라는 단어를 예측해야 하는 시점을 \( t \)라고 할 때, RNN 계열의 디코더라면, 현재까지 입력된 단어는 <SOS>와 je 뿐이다.
■ 그러나 트랜스포머는 <SOS> je suis étudiant를 한 번에 입력받기 때문에 \( t+1 \) 시점의 étudiant까지 입력으로 들어가 버리는 상황이 발생한다.
■ 이를 막기 위해 트랜스포머에서는 위의 Masked 그림처럼, 특정 시점에는 그 이전에 생성된 토큰(또는 단어)까지만 확인할 수 있고, 미래에 있는 토큰들은 참고하지 못하도록 마스크를 추가한다.
■ 이 마스크를 룩-어헤드 마스크(look-ahead mask)라고 부른다. 학습 과정에서 'étudiant'에 대한 정보를 참고할 수 없도록 가려버리는 것이다. 즉 \( t \)보다 작은 위치(또는 시점)의 정보에만 의존하도록 만드는 것으로 볼 수 있다.
■ 룩-어헤드 마스크는 트랜스포머 디코더의 첫 번째 서브 층인 멀티 헤드 셀프 어텐션 층에서 이루어진다. 그래서 해당 층을 마스크드 멀티 헤드 셀프 어텐션 층이라고 부르는 것이다.
■ 즉, 디코더의 첫 번째 서브 층은 인코더의 첫 번째 서브 층처럼 동일한 멀티 헤드 셀프 어텐션 연산을 수행하되, 차이점은 어텐션 연산을 위해 다음과 같이 어텐션 스코어 행렬에 마스킹을 적용한다는 점이다.
■ 룩-어헤드 마스크를 적용하는 방법은 다음과 같다.
■ 예를 들어, 트랜스포머 디코더에서 <SOS> je suis étudiant에 대해 셀프 어텐션을 수행한다고 하자. 먼저 셀프 어텐션을 통해 다음과 같은 어텐션 스코어 행렬을 얻었다고 했을 때,

- 하나의 배치를 처리하는 배치 크기를 4라고 가정
■ 어텐션 스코어 행렬에 자기 자신보다 미래에 있는 단어들은 참고하지 못하도록, 어텐션 스코어 행렬의 대각선 아랫부분만 어텐션 스코어를 남길 것이다. 즉, 대각선 윗부분은 마스크를 적용한다.
■ 이 어텐션 스코어 행렬을 어텐션 가중치로 변환하기 위해 소프트맥스 함수를 통과시킬 것이다. 이 점을 이용하여 다음과 같이 마스킹할 어텐션 스코어 행렬 대각선 윗부분에 "-무한대" 또는 "매우 큰 음수"로 설정하면 된다.

■ 그다음, 마스킹 처리된 어텐션 스코어 행렬을 소프트맥스 함수에 통과시키면 다음과 같은 어텐션 가중치 행렬을 얻을 수 있다.

■ 마스킹된 어텐션 스코어 행렬이 소프트맥스 함수를 통과한 결과, 어텐션 가중치 행렬의 각 행을 보면, 현재 단어는 자기 자신과 그 이전 단어들만 참고할 수 있고, 미래의 단어는 참고할 수 없는 것을 볼 수 있다. (정확히는 미래 단어에 대한 가중치가 0.0이므로)
■ 예를 들어, 모델이 첫 번째 단어 <SOS>를 처리할 때, 어텐션의 100%가 해당 단어에 집중된다. 미래 시점의 단어 je, suis, étudiant에는 0%(혹은 0%에 가까운 값)가 집중되므로, 미래 시점의 모든 단어들을 참고할 수 없다.
■ 두 번째 단어 je를 처리할 때, 어텐션의 52%는 <SOS>에, 48%는 je에 집중된다. 마찬가지로 미래 시점의 단어 suis, étudiant에는 0%(혹은 0%에 가까운 값)가 집중되므로, 미래 시점의 모든 단어들을 참고할 수 없다. 이런 식으로 계속된다.
■ 파이토치에서 위와 같은 마스크 기능은 ,torch.tri()l과 masked_fill()을 이용하여 구현할 수 있다.
import torch
mask = torch.ones(4, 4, dtype = torch.bool).tril(diagonal=0)
mask
```#결과#```
tensor([[ True, False, False, False],
[ True, True, False, False],
[ True, True, True, False],
[ True, True, True, True]])
````````````
a = torch.rand(4, 4)
a.masked_fill(mask==False, float("-inf"))
```#결과#```
tensor([[0.5902, -inf, -inf, -inf],
[0.4486, 0.8768, -inf, -inf],
[0.5041, 0.1122, 0.7473, -inf],
[0.3199, 0.1619, 0.2048, 0.0388]])
````````````- 먼저 모든 원소가 True인 mask를 생성한다.
- torch.tril의 파라미터인 diagonal을 0으로 설정하면, 주대각성분부터 주대각선의 왼쪽 하단의 원소만 모두 살리겠다는 의미가 된다.
- 이를 부울(bool)값을 원소로 갖는 mask에 적용하면 주대각선 위쪽 상단의 원소는 모두 False, 주대각성분과 왼쪽 하단의 원소는 모두 True가 된다. 이렇게 해서 마스크를 만들 수 있다.
-- True인 부분은 값을 유지하고, False인 부분은 마스킹될 영역을 나타낸다.
- 그다음 파이토치 tensor의 특정 값을 다른 값으로 바꿔주는 masked_fill() 함수를 마스크를 적용할 tensor에 위와 같이 사용하면 된다. tensor a는 mask의 원소가 False인 부분에 해당하는 a의 모든 요소들을 음의 무한대(-inf)로 바뀌게 된다.
- 파이썬에서 음의 무한대를 만드는 방법은 위와 같이 "float('-inf')"로 만들거나, import math를 통해 "-math.inf"로 만들 수도 있다.
■ 위와 같은 과정을 스케일드 닷 프로덕트 어텐션을 연산하는 함수 내에 어텐션 스코어를 계산하는 부분에 적용하면 된다.
def scaled_dot_product_attention(querys, keys, values, is_causal=False):
dim_k = querys.size(-1)
scores = querys @ keys.transpose(1, -1) / sqrt(dim_k)
if is_causal:
query_len = querys.size(-2) # querys.shape: (B, T, d_model)
key_len = keys.size(-2) # keys.shape: (B, T, d_model)
look_ahead_mask = torch.ones(query_len, key_len, dtype=torch.bool).tril(diagonal=0)
scores = scores.masked_fill(look_ahead_mask==False, float("-inf"))
weights = F.softmax(scores, dim=-1)
return weights @ values
result = scaled_dot_product_attention(querys, keys, values)- 디코더(causal)인 경우, query와 key의 길이(또는 모든 시점(time steps))를 가져와서 "query의 길이 x key의 길이"의 형상을 갖는 룩-어헤드 마스크를 만든 다음, 이를 어텐션 스코어(유사도) 행렬에 적용하면 된다.
■ 트랜스포머는 총 3가지 어텐션이 존재하며, 모두 멀티 헤드 어텐션을 수행하고, 멀티 헤드 어텐션 함수 내부에서 스케일드 닷-프로덕트 어텐션 함수를 호출하여 연살을 수행한다. 이때, 각 어텐션 연산 과정에서 전달되는 마스킹은 다음과 같다.
- (1) 인코더의 첫 번째 서브 층인 셀프 어텐션에는 "패딩 마스크"를 전달
- (2) 디코더의 첫 번째 서브 층인 마스크드 셀프 어텐션에는 "룩-어헤드 마스크"를 전달
- (3) 디코더의 두 번째 서브 층인 인코더-디코더 어텐션(크로스 어텐션)에는 "패딩 마스크"를 전달
2.5.2 디코더의 두 번째 서브 층: 인코더-디코더 어텐션(크로스 어텐션)
■ 디코더의 두 번째 서브 층은 인코더의 첫 번째 서브 층처럼 멀티 헤드 어텐션을 수행한다는 공통점이 있다.
■ 그러나 두 어텐션 메커니즘에는 중요한 차이가 있다. 인코더에서 사용되는 셀프 어텐션은, 동일한 입력 시퀀스 내에서 Q, K, V를 모두 생성하여 토큰 간의 관계를 파악한다.
■ 반면, 디코더의 두 번째 서브 층은 디코더의 Q와 인코더의 K, V를 사용하여 어텐션이 수행된다. 이 어텐션을 "인코더-디코더 어텐션(Encoder-Decoder Attention)" 또는 "크로스 어텐션(Cross-Attention)"이라고 부른다.
- 이때 사용되는 인코더의 Key, Value는 인코더의 마지막 층에서 출력된 결과이다.
■ 다음 그림에서 인코더와 디코더를 연결하는 선이 바로 디코더가 인코더의 결과를 K, V로 활용하여, 자신(디코더)의 정보 Q와 크로스 어텐션 연산을 수행하는 과정을 나타낸 선이다.
- 인코더의 출력에서 연결되는 두 개의 화살표가 각각 Key, Value를 나타낸다고 보면 된다.

■ 인코더의 출력에서 연결되는 두 개의 화살표(Key, Value)와 디코더에서 연결되는 한 개의 화살표(Query)가 만나 다음과 같이 어텐션 연산을 수행한다.

■ 예를 들어, 기계 번역에서 영어를 프랑스어로 번역한다고 했을 때, 인코더는 영어 문장(예: "I am a student")을 입력으로 받아 contextual representation을 생성할 것이다.
■ 디코더에서는 타겟인 프랑스어 문장(예: "je suis étudiant")을 한 단어씩 생성해 나갈 때, 인코더의 결과(contextual representation)를 Key, Value로받아 크로스 어텐션을 사용하여, 디코더가 현재 생성하려는 단어와 영어 문장의 어떤 단어들이 관련 있는지 파악하게 된다.
■ 이러한 크로스 어텐션 과정을 제외하면, 그 외에 멀티 헤드 어텐션을 수행하는 과정은 다른 어텐션들과 동일하다.
■ 정리하면, 인코더에서 생성된 표현과 디코더의 정보를 상호 작용하는 크로스 어텐션 메커니즘을 통해 디코더는 인코더가 제공하는 컨텍스트 정보를 바탕으로 각 타임 스텝에서 가장 관련 있는 부분에 집중하여, 출력 시퀀스의 다음 요소를 예측한다. 인코더의 출력 결과를 효과적으로 활용할 수 있는 것이다.
- 이렇게 서로 다른 컴포넌트 간의 정보를 교환하기 때문에 크로스 어텐션이라고 불린다.
2.5.3 Linear Layer와 Softmax Layer
■ 2.5.2의 크로스 어텐션의 결과는 디코더의 세 번쨰 서브 층인 피드 포워드 층의 입력으로 들어간다. 그리고 사후 정규화를 거친 디코더의 출력은 선형 층과 소프트맥스 함수를 통과하게 된다.
■ 디코더가 마지막 출력한 결과가 벡터라고 했을 때, 선형 층에서 이를 로짓(logits) 벡터로 투영시키게 된다. 만약 번역 문제라면, 이 로짓 벡터의 차원은 타겟 단어 집합의 개수가 될 것이다.
■ 타겟 단어 집합의 개수를 tar_vocab_size라고 했을 때, 로짓 벡터의 각 셀은 tar_vocab_size에 대응하는 각 단어에 대한 점수가 된다.
■ 이제, 이 로짓 벡터를 소프트맥스 함수에 통과시키면, 점수들이 확률로 변환되고,
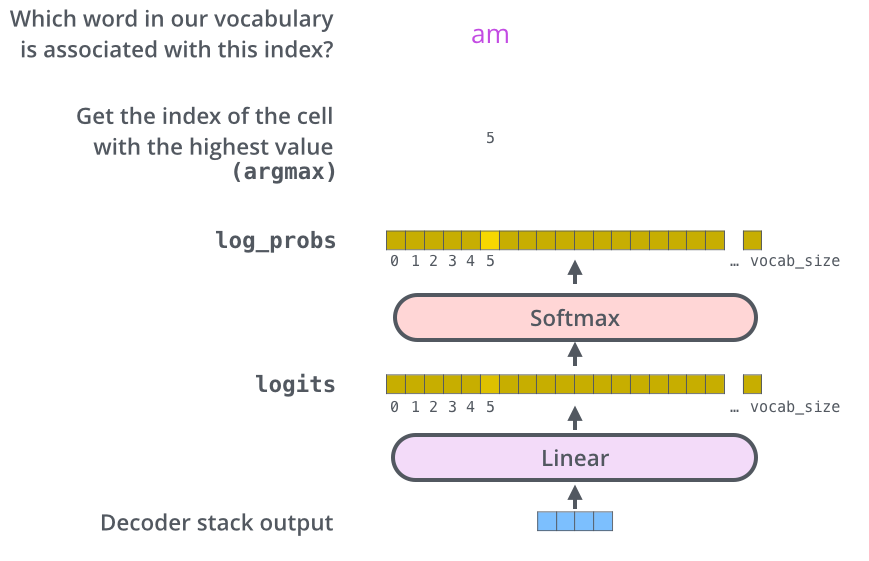
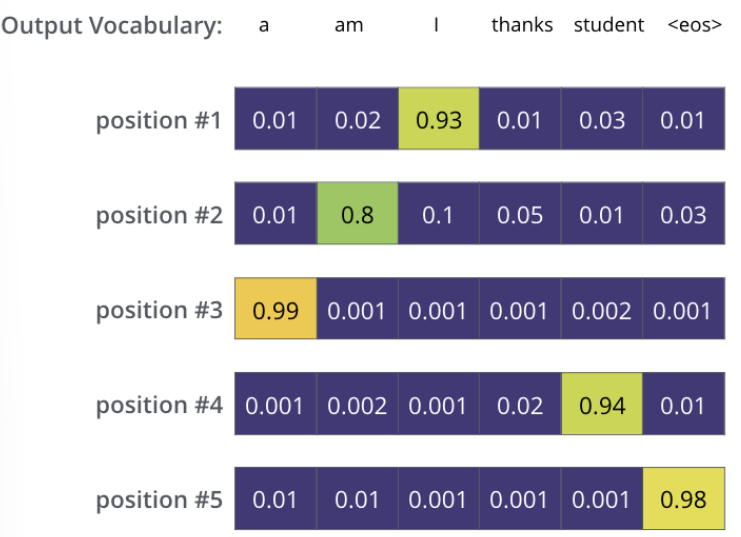
가장 높은 확률값을 가지는 셀에 해당하는 단어가 다음 그림과 같이 해당 time step의 최종 결과물로서 출력된다.
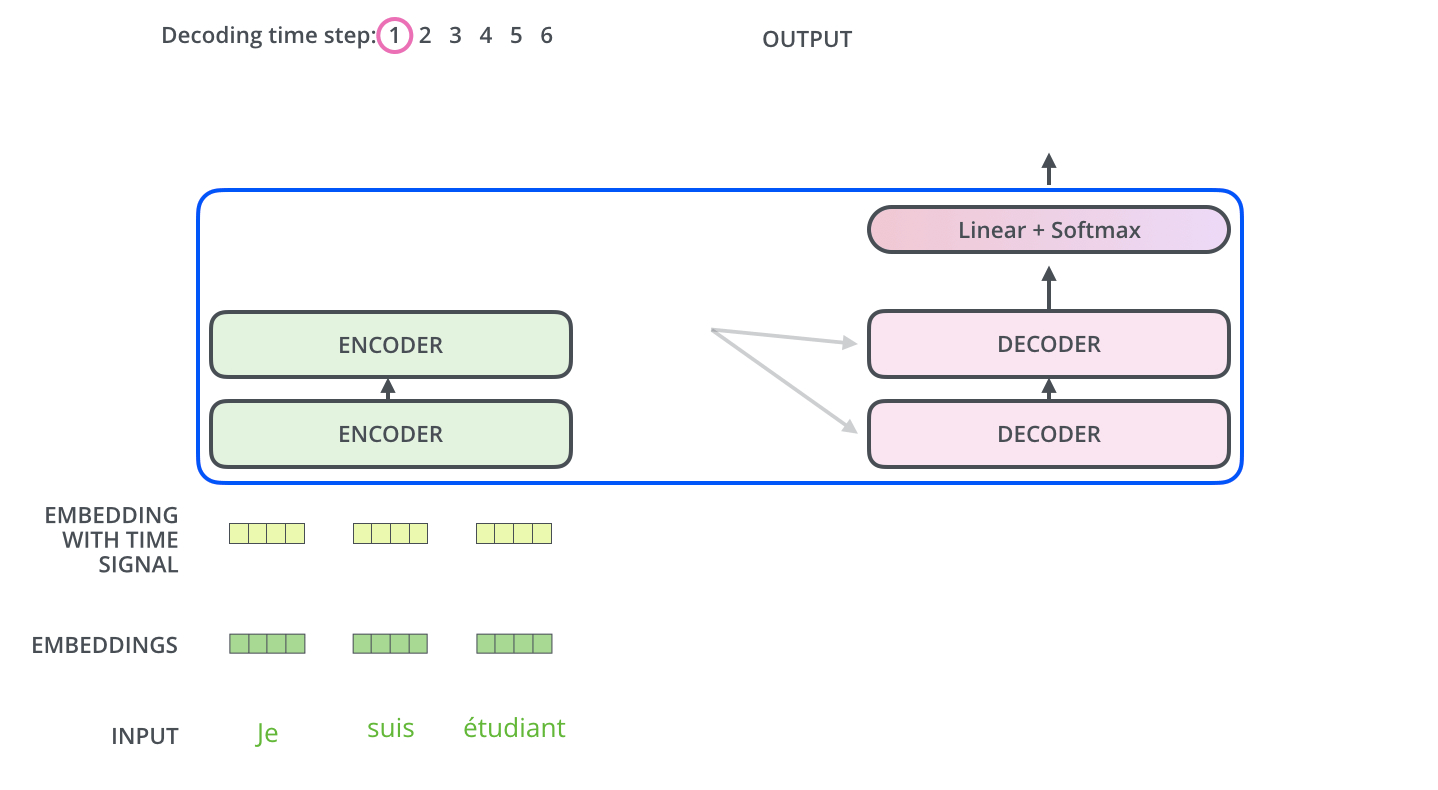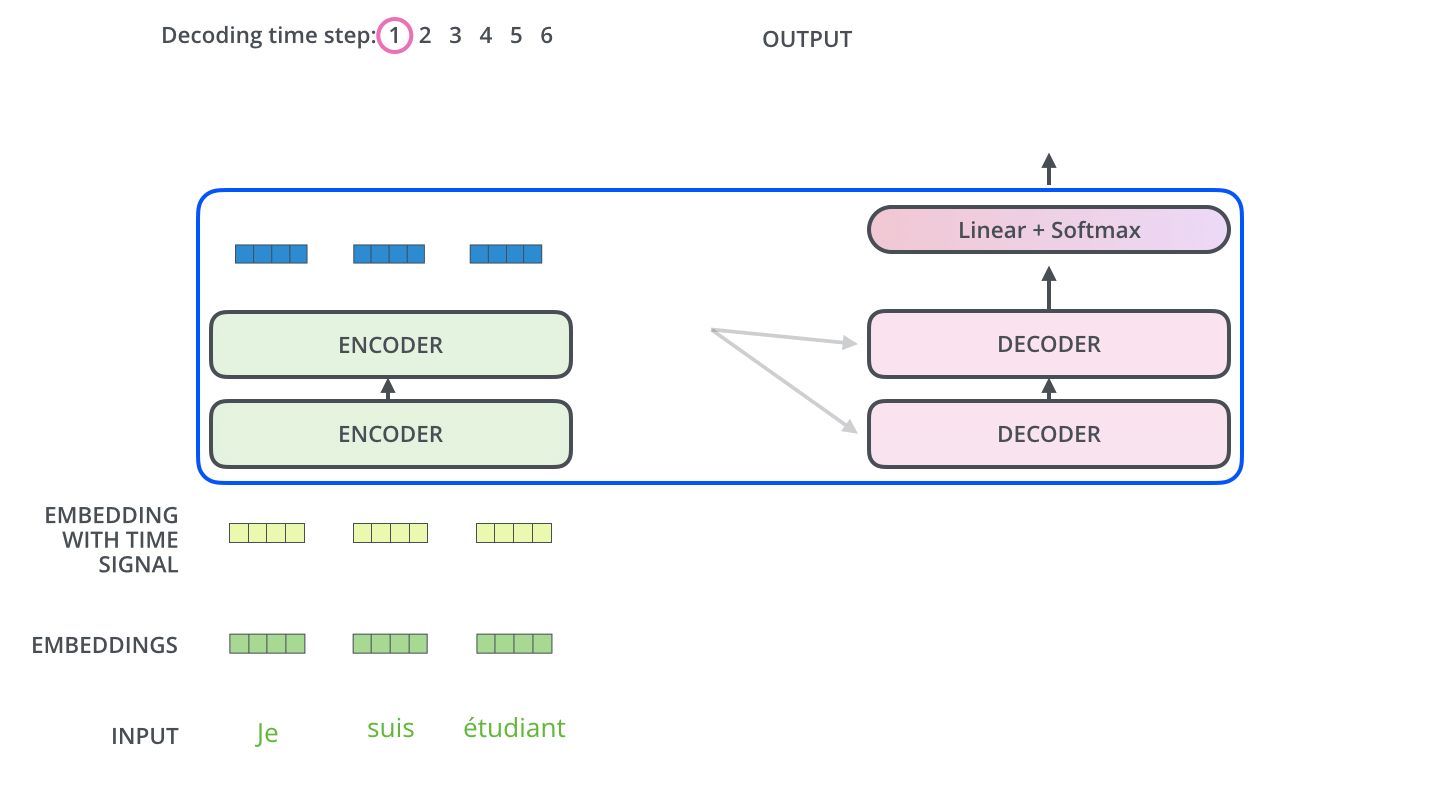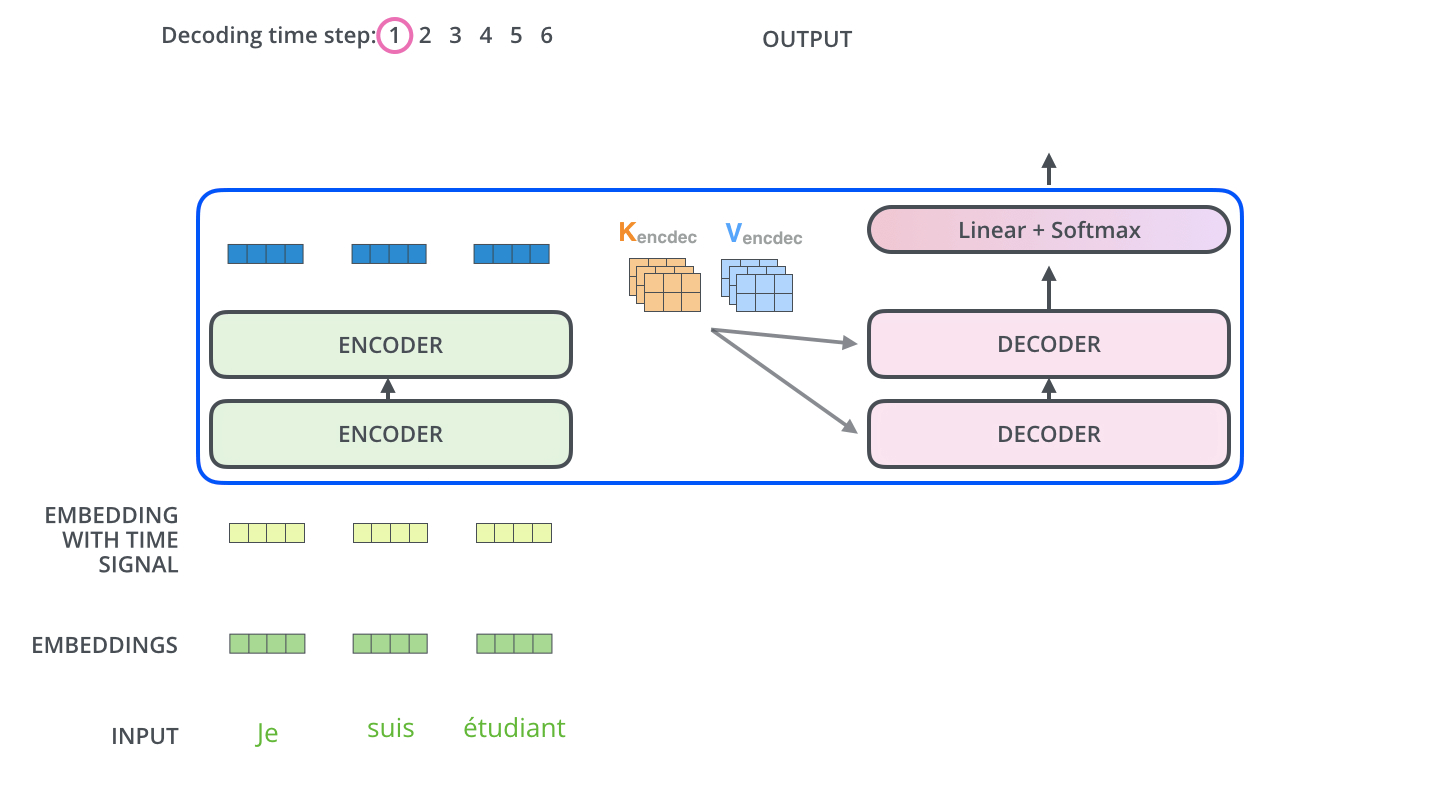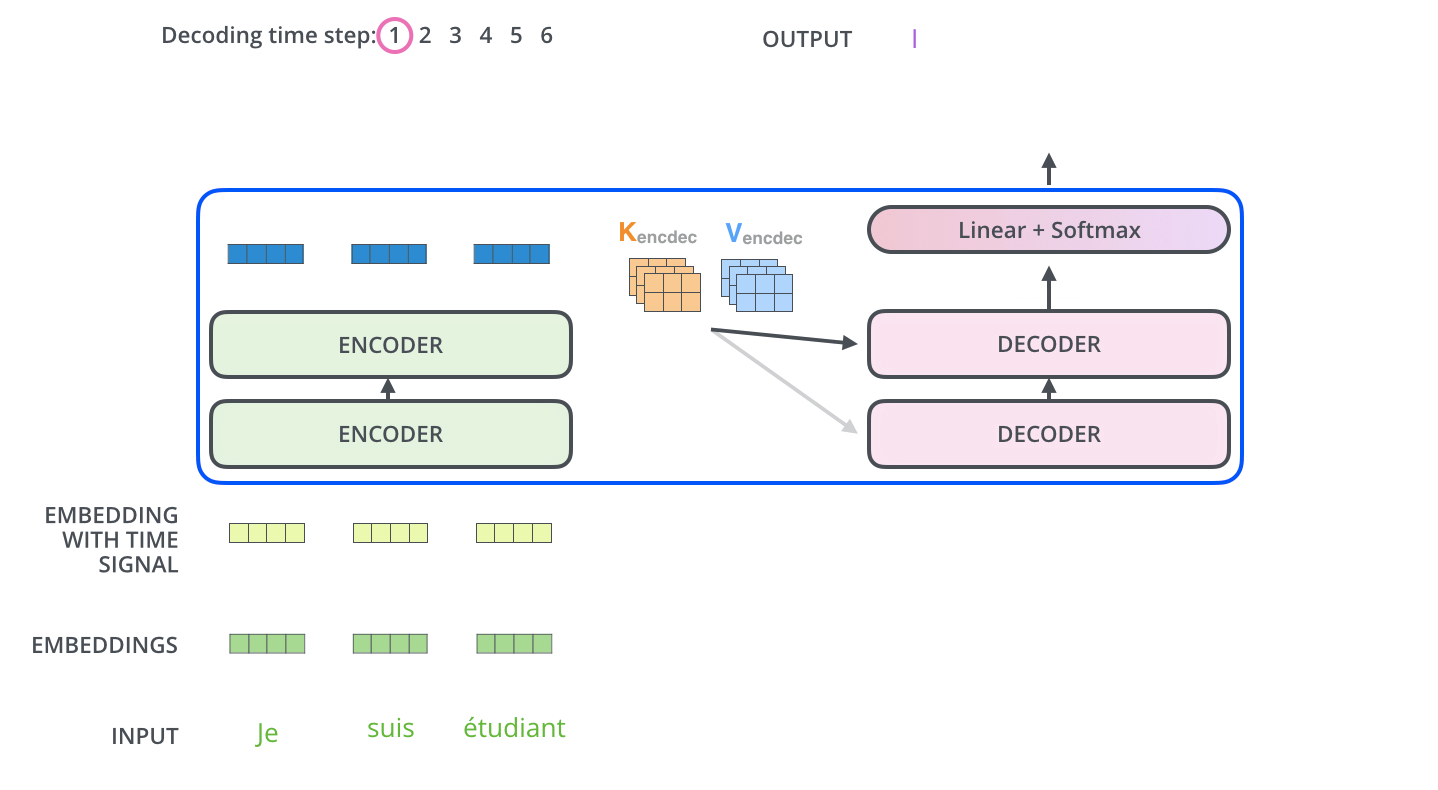
■ 예를 들어, 인코더 층과 디코더 층을 각각 2개씩 쌓는다면, 다음 그림과 같은 구조를 가질 것이다.

■ 첫 번째 인코더 층이 입력 시퀀스를 받아 처리하면, 첫 번째 인코더 층의 결과를 받은 두 번째 인코더 층이 입력 시퀀스의 문맥적 표현을 담은 벡터들을 출력한다.
■ 인코더의 최종 출력 결과는 크로스 어텐션에서 Key와 Value로 사용된다. 이때 Query는 첫 번째 디코더 층의 정보이다.
■ 첫 번째 디코더의 출력 결과는 두 번째 디코더 층의 입력으로 들어가고, 이제 인코더의 최종 출력 결과는 두 번째 디코더 층과 크로스 어텐션 연산을 수행하게 된다.
■ 그리고 디코더의 최종 출력 결과는 Linear와 Softmax를 거쳐 첫 번째 타겟 단어를 출력할 것이다. 이 과정에 대한 내용은 아래의 그림과 같다.
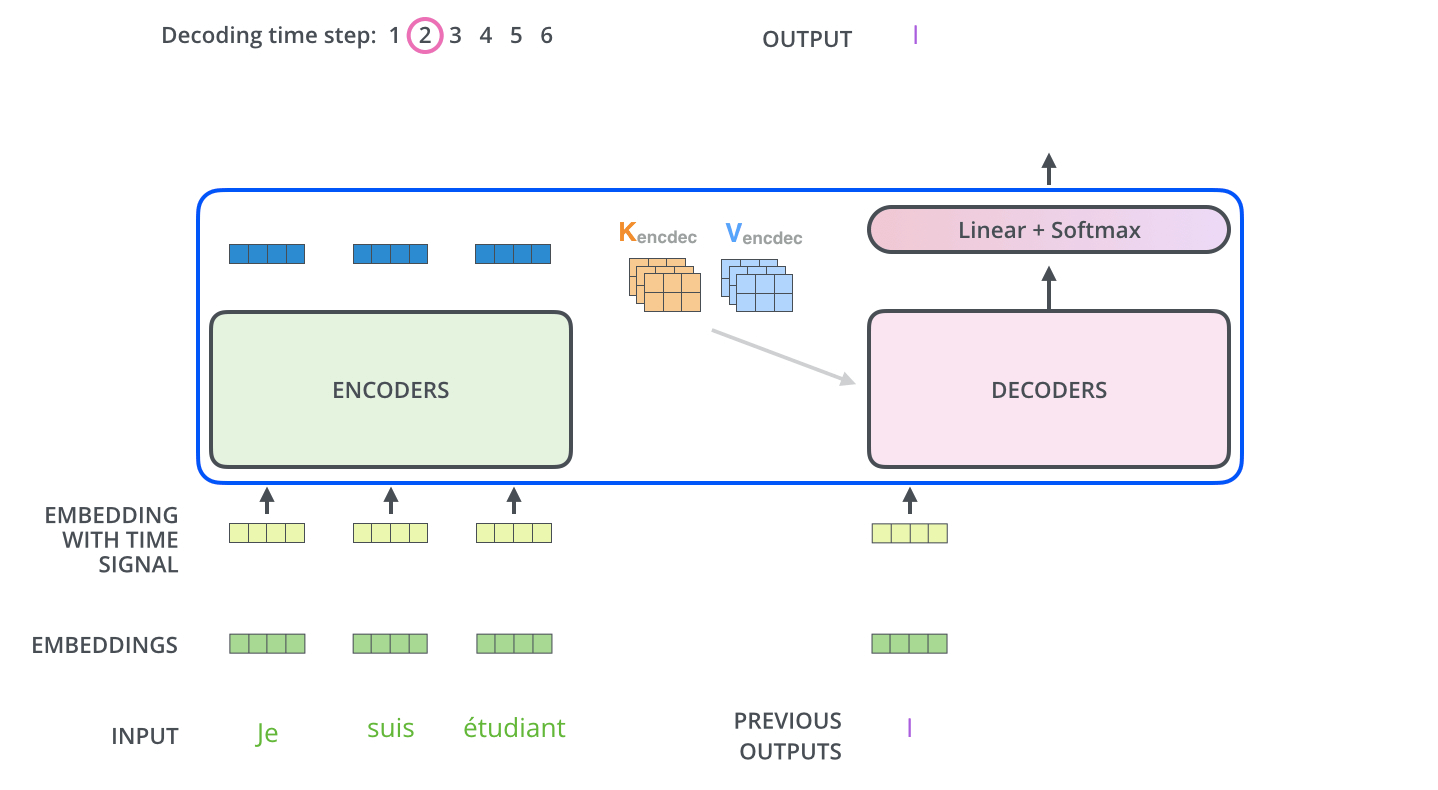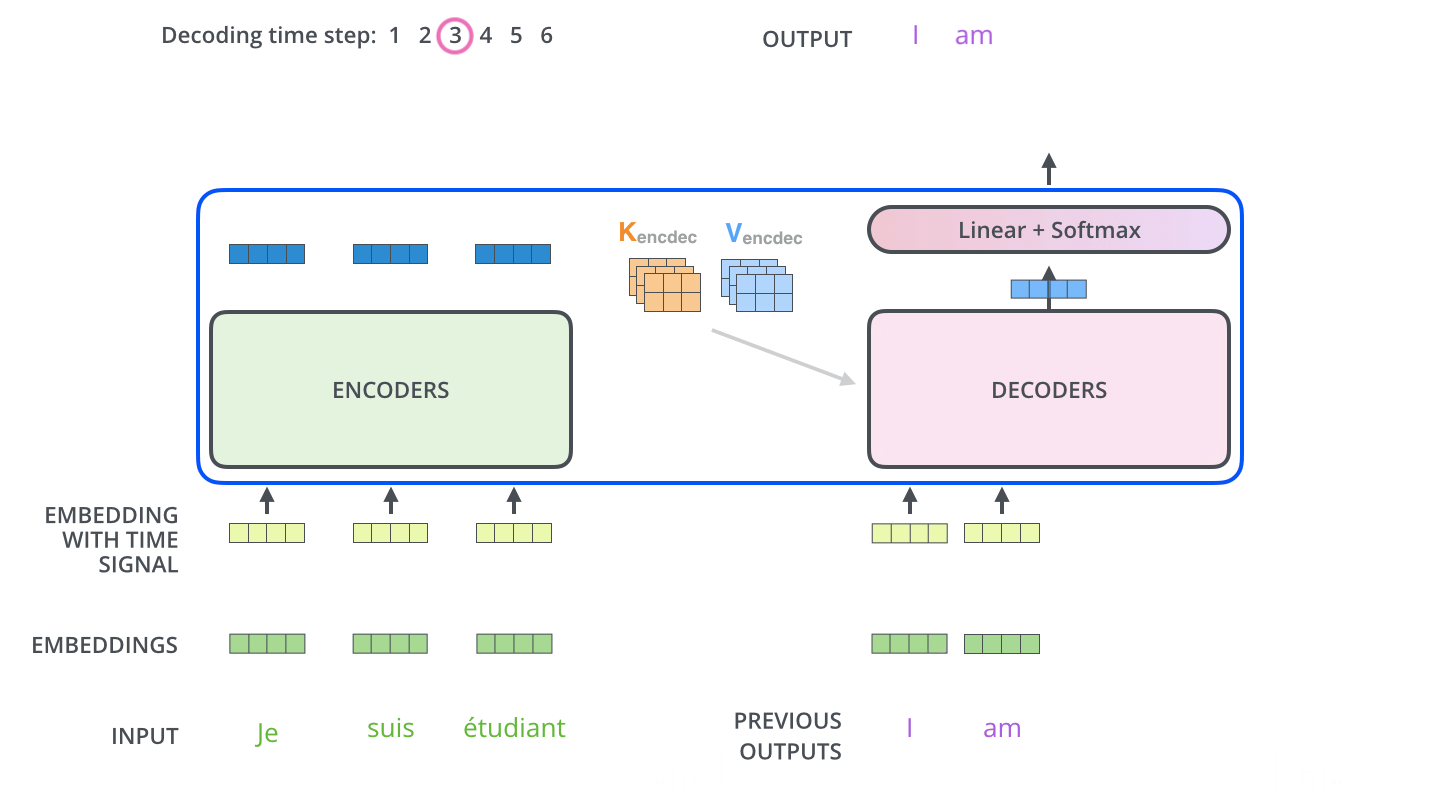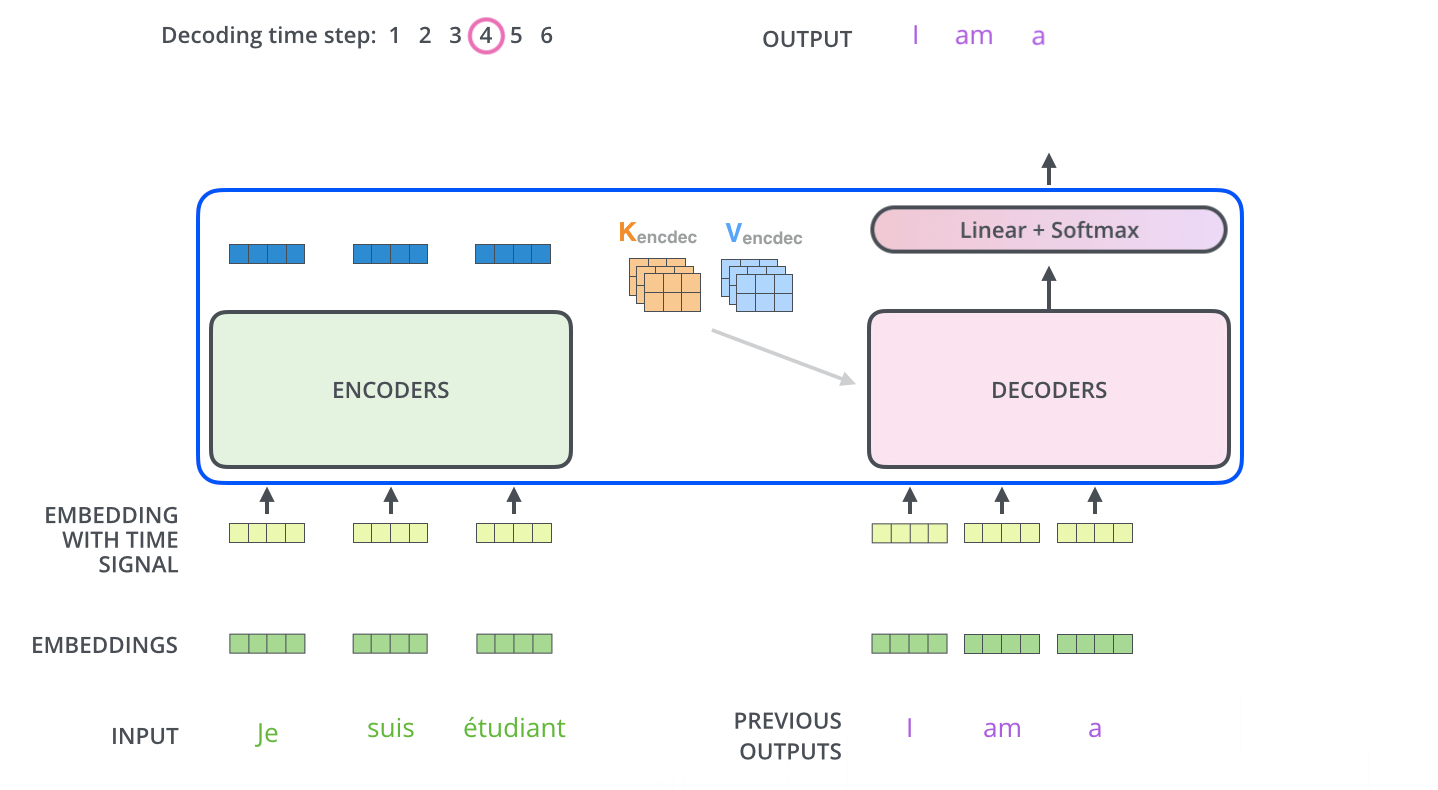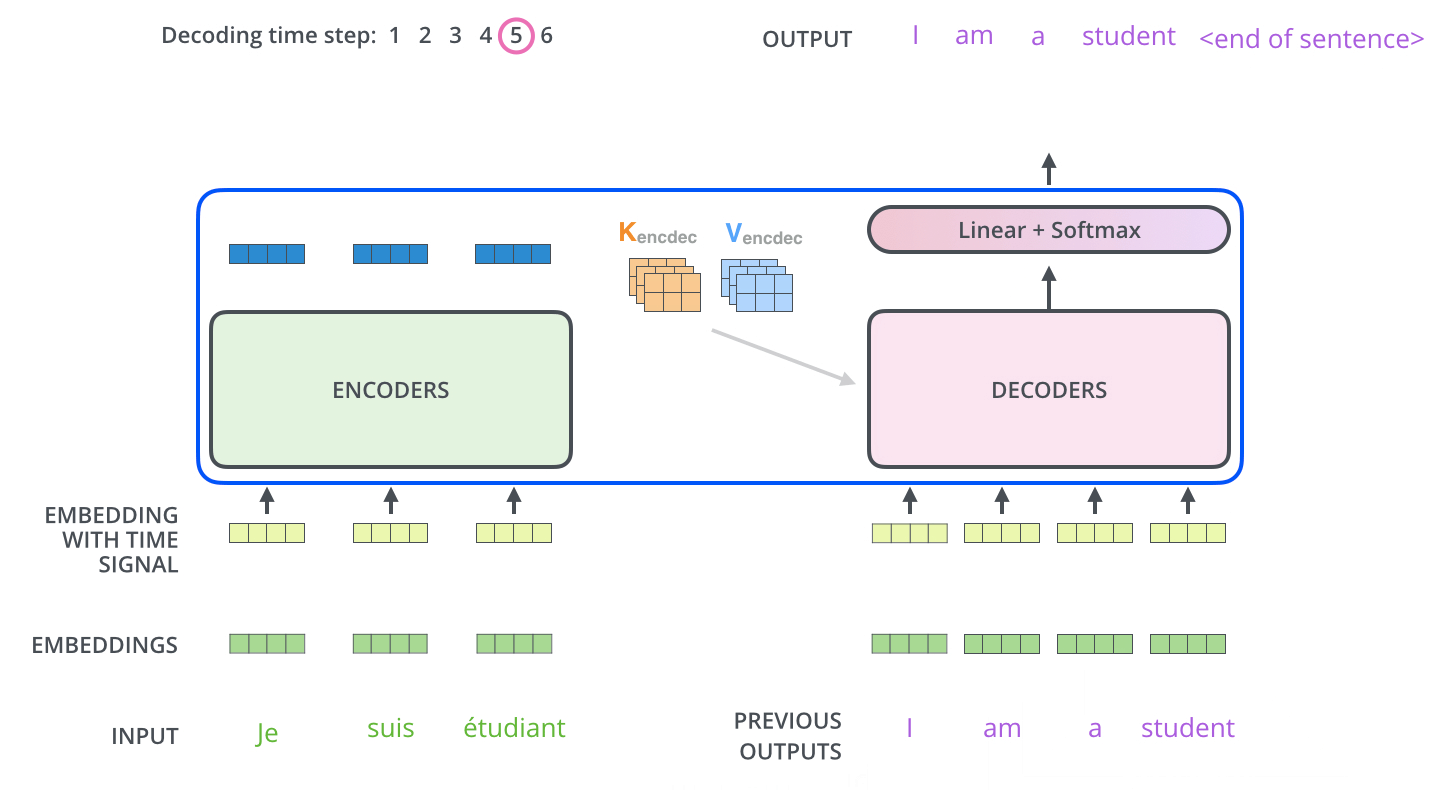
■ 각 스텝마다 출력된 단어는 다시 가장 밑단의 첫 번째 디코더 층의 입력으로 들어가서 임베딩, 위치 인코딩, 여러 디코더 층, Linear & Softmax 층을 거쳐서 다음 스텝의 타겟 단어를 출력한다.
- 이 과정에서 룩-어헤드 마스크로 인하여 미래 시점의 단어들을 참고할 수 없고, 이전 시점들의 단어들만 참고하게 된다.
■ 이 과정은 <end of sentence>(=<EOS>)를 출력할 때까지 반복된다. 이 과정에 대한 내용은 아래의 그림과 같다.
참고) Optimizer의 학습률(Learning rate)
■ Attention is all you need 논문의 저자들은 옵티마이저로 Adam을 사용했으며, 하이퍼파라미터 \( \beta_1, \beta_2 \)를 \( \beta_1 = 0.9, \beta_2 = 0.98 \)로 설정하였다. 그리고 엡실론 값은 \( \epsilon = 10^{-9} \)
■ 그리고 학습 과정에서의 학습률은 다음과 같이 학습률 스케줄러처럼 적용했다. \[ \text{lrate} = d_{\text{model}}^{-0.5} \cdot \min(\text{step_num}^{-0.5}, \text{step_num} \cdot \text{warmup_steps}^{-1.5}) \] ■ 학습 초기(step_num < warmup_steps)에는 학습률을 선형적으로 증가시키고, 이후 단계(step_num이 warmp_steps에 도달)에는 step_num의 역제곱근에 비례하여 감소시키는 방식을 사용했으며, warmp_steps = 4000을 사용했다.
- step_num은 옵티마이저가 매개변수를 업데이트하는 한 번의 진행 횟수이다.
'자연어처리' 카테고리의 다른 글
| 트랜스포머(Transformer) (2) (0) | 2025.04.19 |
|---|---|
| 트랜스포머(Transformer) (1) (0) | 2025.04.15 |
| 어텐션(Attention) (4) (0) | 2025.04.14 |
| 어텐션(Attention) (3) (0) | 2025.04.13 |
| 어텐션(Attention) (2) (0) | 2025.04.07 |


