1. 콜백
■ MNIST 데이터 셋같이 데이터의 개수가 6만장, 7만장이 아닌 60만장, 700만장, 6000만장, .... 인 대규모 데이터셋에서 fit( ) 메서드를 사용해 수십 수백 번의 에포크를 긴 시간 동안 수행했을 때, 이를 저장하지 못하거나 결과에서 이상 징후가 발견되는 등 처음부터 다시 긴 시간 동안 학습을 시작해야 한다.
■ 이를 방지하기 위해 사용하는 것이 바로 콜백(callback)이다.
■ 콜백은 모델 훈련 시 사용하는 fit( ) 메서드에 callbacks 매개변수로 지정하여 모델 체크포인트(checkpoint), 조기 종료(early stopping), 학습률 스케줄러(learning rate scheduler) 등 모델 훈련에 보조적인 옵션을 넣을 수 있다.
1.1 모델 체크포인트(ModelCheckpoint)
■ 모델 학습 과정에서 미리 정해 놓은 규칙에 따라 특정 시점의 가중치와 파라미터를 저장하는 콜백이다.
■ 특정 지점을 저장할 수 있기 때문에 중단된 학습을 재개할 때 유용하다.
tf.keras.callbacks.ModelCheckpoint | TensorFlow v2.16.1
tf.keras.callbacks.ModelCheckpoint | TensorFlow v2.16.1
Callback to save the Keras model or model weights at some frequency.
www.tensorflow.org
checkpoint_filepath = '/tmp/ckpt/checkpoint.weights.h5'
model_checkpoint_callback = keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath,
save_weights_only=True,
monitor='val_accuracy',
mode='max',
save_best_only=True,
verbose = 1)- filepath는 체크포인트 저장 경로.
- save_weights_only는 가중치만 저장할지에 대한 설정으로 True면 가중치만 저장한다.
- monitor는 저장 시 기준이 되는 측정 지표로 accuracy나 loss로 지정할 수 있다.
- mode는 'min', 'max', 'auto'로 지정할 수 있으며, min/max는 설정한 monitor가 최솟값/최댓값일 때만 저장한다.
- save_best_only는 설정한 monitor를 기준으로 가장 높은 epoch만 저장할지, 모든 epoch를 저장할지 설정할 수 있다.
- verbose = 1로 설정하면 매 epoch별 저장 여부를 알려주는 로그 메시지가 출력된다.
checkpoint_filepath = '파일 경로/my_checkpoint' # 저장 경로
model_checkpoint_callback = keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath,
save_weights_only=True,
monitor='val_loss',
mode='min',
save_best_only=True,
verbose = 1)
model_C.fit(train_set, train_labels,
batch_size = 256, validation_data=(valid_set, valid_labels), epochs=5,
callbacks = [model_checkpoint_callback])
```#결과#```
Epoch 1/5
187/188 [============================>.] - ETA: 0s - loss: 0.0014 - categorical_accuracy: 0.9995
Epoch 1: val_loss improved from inf to 0.19470, saving model to 파일 경로/my_checkpoint
188/188 [==============================] - 2s 12ms/step - loss: 0.0014 - categorical_accuracy: 0.9995 - val_loss: 0.1947 - val_categorical_accuracy: 0.9775
Epoch 2/5
186/188 [============================>.] - ETA: 0s - loss: 0.0019 - categorical_accuracy: 0.9993
Epoch 2: val_loss improved from 0.19470 to 0.16530, saving model to 파일 경로/my_checkpoint
188/188 [==============================] - 2s 11ms/step - loss: 0.0020 - categorical_accuracy: 0.9993 - val_loss: 0.1653 - val_categorical_accuracy: 0.9803
Epoch 3/5
187/188 [============================>.] - ETA: 0s - loss: 0.0034 - categorical_accuracy: 0.9990
Epoch 3: val_loss did not improve from 0.16530
188/188 [==============================] - 2s 11ms/step - loss: 0.0034 - categorical_accuracy: 0.9990 - val_loss: 0.1786 - val_categorical_accuracy: 0.9784
Epoch 4/5
184/188 [============================>.] - ETA: 0s - loss: 0.0015 - categorical_accuracy: 0.9996
Epoch 4: val_loss did not improve from 0.16530
188/188 [==============================] - 2s 9ms/step - loss: 0.0015 - categorical_accuracy: 0.9996 - val_loss: 0.1701 - val_categorical_accuracy: 0.9789
Epoch 5/5
185/188 [============================>.] - ETA: 0s - loss: 0.0017 - categorical_accuracy: 0.9993
Epoch 5: val_loss improved from 0.16530 to 0.16364, saving model to 파일 경로/my_checkpoint
188/188 [==============================] - 2s 9ms/step - loss: 0.0017 - categorical_accuracy: 0.9993 - val_loss: 0.1636 - val_categorical_accuracy: 0.9795
````````````Epoch 5: val_loss improved from 0.16530 to 0.16364, saving model to 파일 경로/my_checkpoint- 마지막 epoch = 5에서 val_loss 값이 개선되어 미리 정해 놓은 체크포인트 규칙에 따라 설정한 경로에 my_checkpoint라는 체크포인트가 저장되는 것을 볼 수 있다.
■ 저장한 체크포인트를 작업 환경에 불러오려면 load_weights( ) 메소드에 체크포인트 파일 경로를 지정해서 체크포인트를 호출하면 된다.
model_C.load_weights('파일 경로/my_checkpoint') # 체크 포인트 불러오기
test_loss, test_acc = model_C.evaluate(test_set, test_labels)
print(test_loss, test_acc)
```#결과#```
375/375 [==============================] - 1s 4ms/step - loss: 0.1636 - categorical_accuracy: 0.9795
0.16363593935966492 0.9794999957084656
`````````````- 마지막 epoch = 5일 때와 val_loss 값과 val_acc 값이 일치하는 것을 볼 수 있다. 즉, val_loss가 가장 낮았던 저장된 모델 가중치를 불러온 것이다.
1.2 조기 종료(EarlyStopping)
■ 훈련 데이터의 손실은 감소하는데 검증 데이터의 손실이 계속 커지는 경우 이는 과적합의 신호이다.
■ 조기 종료는 이 신호에 따라 과적합을 방지하기 위해 모델 훈련을 조기에 중단하는 콜백이다.
tf.keras.callbacks.EarlyStopping | TensorFlow v2.16.1
tf.keras.callbacks.EarlyStopping | TensorFlow v2.16.1
Stop training when a monitored metric has stopped improving.
www.tensorflow.org
keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0.1, patience=3, mode='auto', verbose = 1)- monitor는 저장 시 기준이 되는 측정 지표로 accuracy나 loss로 지정할 수 있다.
- min_delta는 모니터링되는 지표 값이 성능 개선으로 간주되기 위한 최소한의 변화량이다. 예를 들어 min_delta = 0.1로 설정한 경우 epoch k에서 k+1로의 지표 값이 0.05만큼 개선되었다면, 이는 min_delta 기준을 충족하지 못했기 때문에 성능이 개선된 것으로 간주하지 않는다.
- patience에 지정된 수만큼 monitor에 지정된 지표가 개선되지 않으면 학습을 중단시킬 수 있다.
- mode는 monitor에 지정된 지표가 최소가 되어야 하는지, 최대가 되어야 하는지에 따라 'min' 또는 'max'로 설정할 수 있으며, 디폴트 값은 'auto'이다. 만약 모니터링하는 값이 정확도이면, 값이 클수록 좋기 때문에 max, loss이면 작을수록 좋기 때문에 min으로 설정한다.
- verbose = 1로 설정하면 조기 종료가 작동했을 때, 조기 종료되었다는 메시지가 출력된다.
early_stopping = keras.callbacks.EarlyStopping(monitor='val_loss', patience=5, mode='auto', verbose = 1)
model_C.fit(train_set, train_labels,
batch_size = 256, validation_data=(valid_set, valid_labels), epochs=20,
callbacks = [early_stopping])
```#결과#```
Epoch 1/20
188/188 [==============================] - 3s 11ms/step - loss: 0.0080 - categorical_accuracy: 0.9973 - val_loss: 0.1238 - val_categorical_accuracy: 0.9750
Epoch 2/20
188/188 [==============================] - 2s 10ms/step - loss: 0.0083 - categorical_accuracy: 0.9971 - val_loss: 0.1106 - val_categorical_accuracy: 0.9770
Epoch 3/20
188/188 [==============================] - 2s 8ms/step - loss: 0.0061 - categorical_accuracy: 0.9977 - val_loss: 0.1365 - val_categorical_accuracy: 0.9755
Epoch 4/20
188/188 [==============================] - 2s 8ms/step - loss: 0.0064 - categorical_accuracy: 0.9980 - val_loss: 0.1282 - val_categorical_accuracy: 0.9761
Epoch 5/20
188/188 [==============================] - 2s 8ms/step - loss: 0.0071 - categorical_accuracy: 0.9976 - val_loss: 0.1214 - val_categorical_accuracy: 0.9778
Epoch 6/20
188/188 [==============================] - 2s 9ms/step - loss: 0.0067 - categorical_accuracy: 0.9978 - val_loss: 0.1096 - val_categorical_accuracy: 0.9793
Epoch 7/20
188/188 [==============================] - 2s 10ms/step - loss: 0.0063 - categorical_accuracy: 0.9977 - val_loss: 0.1132 - val_categorical_accuracy: 0.9780
Epoch 8/20
188/188 [==============================] - 2s 10ms/step - loss: 0.0068 - categorical_accuracy: 0.9973 - val_loss: 0.1223 - val_categorical_accuracy: 0.9758
Epoch 9/20
188/188 [==============================] - 2s 9ms/step - loss: 0.0070 - categorical_accuracy: 0.9975 - val_loss: 0.1255 - val_categorical_accuracy: 0.9808
Epoch 10/20
188/188 [==============================] - 2s 10ms/step - loss: 0.0066 - categorical_accuracy: 0.9978 - val_loss: 0.1307 - val_categorical_accuracy: 0.9771
Epoch 11/20
188/188 [==============================] - 2s 10ms/step - loss: 0.0062 - categorical_accuracy: 0.9976 - val_loss: 0.1208 - val_categorical_accuracy: 0.9790
Epoch 11: early stopping
````````````- epoch = 20으로 늘렸음에도 patience = 5로 설정했기 때문에 epoch 7부터 성능이 개선되지 않아 epoch 11에서 early stopping이 발생한 것을 볼 수 있다.
■ 보통 ModelCheckpoint 콜백과 EarlyStopping 콜백을 함께 사용한다. 에포크 과정에서 가장 좋은 모델, 즉 최고의 성능을 기록한 모델만 저장할 수 있기 때문이다.
■ 예를 들어 다음과 같이 EarlyStopping 콜백에는 검증 정확도를 ModelCheckpoint 콜백에는 검증 손실을 지정하여, 지정한 에포크 동안 정확도가 향상되지 않으면 훈련을 중지하되, val_loss가 개선되지 않으면 모델 파일을 덮어쓰지 못하도록 설정하여 훈련하는 동안 가장 좋은 모델을 저장할 수 있다.
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath,
monitor='val_loss',
save_best_only=True),
keras.callbacks.EarlyStopping(
monitor='val_accuracy',
patience=5)
]
model_C.fit(train_set, ...,
callbacks = [callbacks])
1.3 학습률 스케줄러
■ 학습률을 사용자가 정의한 특정 로직에 따라 조정하고자 할 때 사용하는 콜백으로 현재 epoch와 학습률을 입력으로 사용한다.
tf.keras.callbacks.LearningRateScheduler | TensorFlow v2.16.1
tf.keras.callbacks.LearningRateScheduler | TensorFlow v2.16.1
Learning rate scheduler.
www.tensorflow.org
def scheduler_function(epoch, lr):
if epoch < 5: # epoch 5 동안은 학습률 유지
return lr
else:
return lr * tf.math.exp(-0.1) # 그 뒤부터 학습률 감소lr_scheduler = keras.callbacks.LearningRateScheduler(scheduler_function)
model_C.compile(
optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.1, momentum=0.5),
loss = tf.keras.losses.CategoricalCrossentropy(),
metrics = [tf.keras.metrics.CategoricalAccuracy()]
)
print(model_C.optimizer.learning_rate)
```#결과#```
<tf.Variable 'learning_rate:0' shape=() dtype=float32, numpy=0.1> # 설정한 학습률 0.1
````````````model_C.fit(train_set, train_labels,
batch_size = 256, validation_data=(valid_set, valid_labels), epochs=10,
callbacks = [lr_scheduler])
print(round(model_C.optimizer.learning_rate.numpy(), 4))
```#결과#```
Epoch 1/10
188/188 [==============================] - 3s 11ms/step - loss: 0.3230 - categorical_accuracy: 0.9766 - val_loss: 0.9177 - val_categorical_accuracy: 0.9439 - lr: 0.1000
Epoch 2/10
188/188 [==============================] - 2s 10ms/step - loss: 0.1596 - categorical_accuracy: 0.9800 - val_loss: 0.4029 - val_categorical_accuracy: 0.9643 - lr: 0.1000
Epoch 3/10
188/188 [==============================] - 2s 10ms/step - loss: 0.1249 - categorical_accuracy: 0.9820 - val_loss: 0.6795 - val_categorical_accuracy: 0.9547 - lr: 0.1000
Epoch 4/10
188/188 [==============================] - 2s 10ms/step - loss: 0.1563 - categorical_accuracy: 0.9818 - val_loss: 0.4908 - val_categorical_accuracy: 0.9563 - lr: 0.1000
Epoch 5/10
188/188 [==============================] - 2s 10ms/step - loss: 0.1411 - categorical_accuracy: 0.9809 - val_loss: 0.5028 - val_categorical_accuracy: 0.9625 - lr: 0.1000
Epoch 6/10
188/188 [==============================] - 2s 10ms/step - loss: 0.1102 - categorical_accuracy: 0.9846 - val_loss: 0.8612 - val_categorical_accuracy: 0.9323 - lr: 0.0905
Epoch 7/10
188/188 [==============================] - 2s 10ms/step - loss: 0.0871 - categorical_accuracy: 0.9878 - val_loss: 0.5023 - val_categorical_accuracy: 0.9625 - lr: 0.0819
Epoch 8/10
188/188 [==============================] - 2s 10ms/step - loss: 0.0952 - categorical_accuracy: 0.9894 - val_loss: 0.4464 - val_categorical_accuracy: 0.9591 - lr: 0.0741
Epoch 9/10
188/188 [==============================] - 2s 10ms/step - loss: 0.0606 - categorical_accuracy: 0.9904 - val_loss: 0.5004 - val_categorical_accuracy: 0.9626 - lr: 0.0670
Epoch 10/10
188/188 [==============================] - 2s 9ms/step - loss: 0.0497 - categorical_accuracy: 0.9924 - val_loss: 0.3709 - val_categorical_accuracy: 0.9758 - lr: 0.0607
0.0607
````````````- 0.1로 시작한 학습률이 epoch 10에서 0.0607로 감소한 것을 볼 수 있다. 이렇게 학습률 스케줄러를 이용하면 특정 시점을 기준으로 사용자가 정의한 감쇠율에 따라 학습률 감소 크기를 다르게 적용할 수 있다.
1.4 텐서보드(Tensorboard)
■ 텐서보드는 epoch별 평가지표 시각화, 모델 구조 시각화 등을 제공하는 콜백이다.
tf.keras.callbacks.TensorBoard | TensorFlow v2.16.1
tf.keras.callbacks.TensorBoard | TensorFlow v2.16.1
Enable visualizations for TensorBoard.
www.tensorflow.org
log_dir = '텐서보드 저장 경로' # 로그 데이터를 저장할 경로
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)model_C.compile(
optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.1, momentum=0.5),
loss = tf.keras.losses.CategoricalCrossentropy(),
metrics = [tf.keras.metrics.CategoricalAccuracy()]
)
model_C.fit(train_set, train_labels,
batch_size = 256, validation_data=(valid_set, valid_labels), epochs=10,
callbacks = [lr_scheduler, tensorboard_callback])■ 이렇게 학습이 끝나면 prompt를 통해 tensorboard --logdir="텐서보드 저장 경로"를 입력하면 다음과 같이 주소를 출력해준다. 이 주소는 텐서보드의 디폴트 포트 번호이다. 해당 주소에 들어가서 학습 결과를 볼 수 있다.
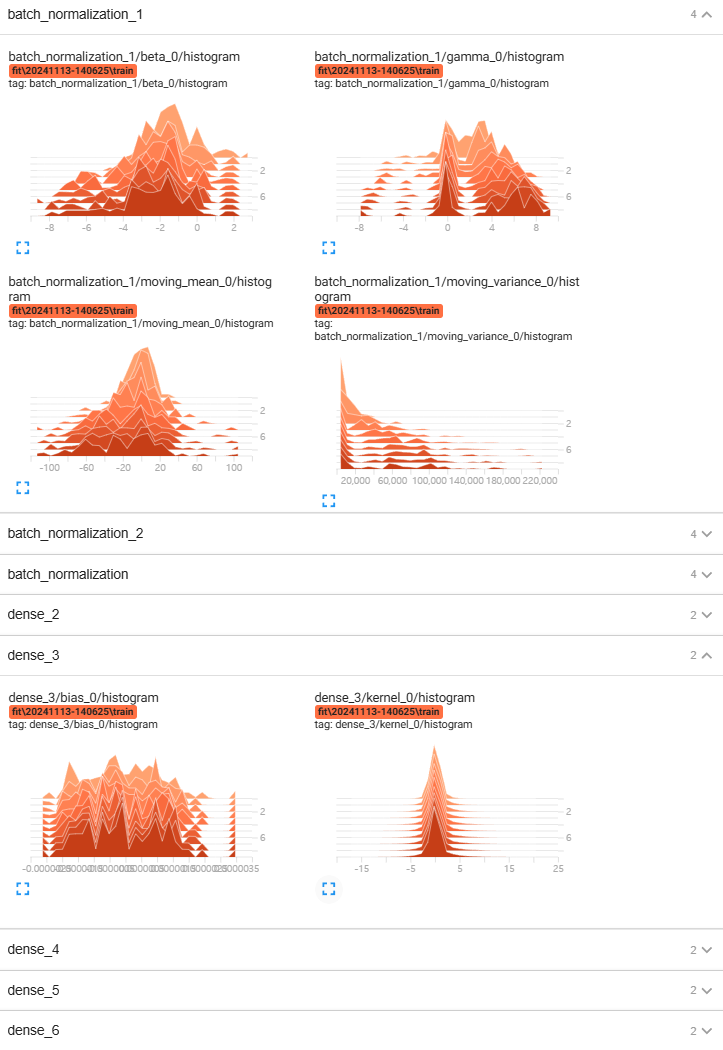
TensorBoard 2.10.0 at http://localhost:6006/ (Press CTRL+C to quit)- 다음과 같이 train set과 valid set에 대해 매 epoch별 평가지표로 설정한 정확도와 loss 그리고 학습률 변화를 확인할 수 있다.


- 그리고 epoch별 각 층의 가중치 분산 변화와 가중치 분포를 확인할 수 있다.

- 또한, 모델의 흐름을 그래프 구조로 확인할 수 있다. 예를 들어 gradient_tape, 즉 역전파 과정을 보고 싶으면 gradient_tape을 눌러서 확인해 볼 수 있다.
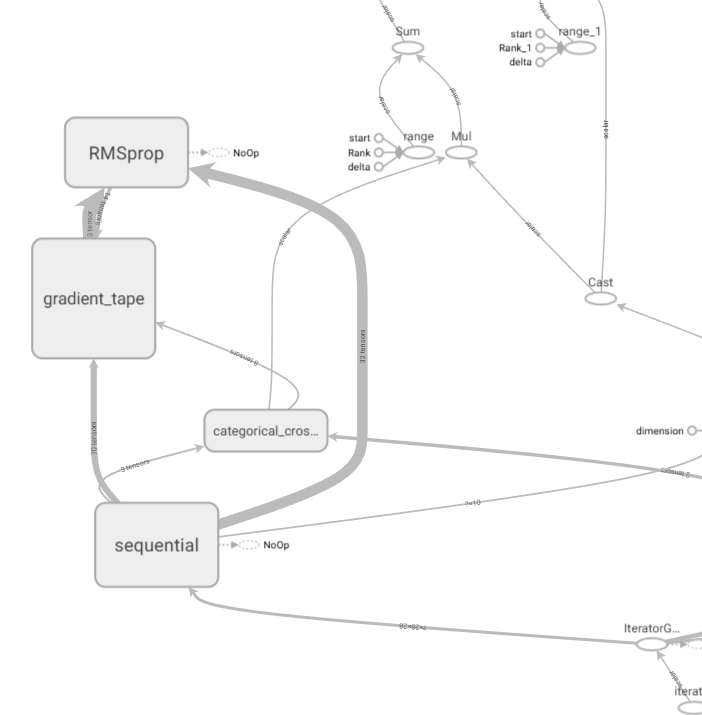
- softmax 계층과 cross entropy 계층의 역전파 결과가 순전파 과정에서 마지막 Dense 계층이었던 dense 6 층의 입력값으로 전달되고, 이후 dense 5 → 활성화 함수 층 → 배치 정규화 층 → dense 4 →… 순으로 역전파 신호가 흐르는 것을 확인할 수 있다.

cf) 활성화 함수로 ReLU를 사용했을 때 가중치 초깃값을 He 초깃값을 사용한 경우와 그렇지 않은 경우 Dense 레이어 가중치 분포를 비교해 볼 수도 있다.
- 다음과 같이 각각의 활성화 함수 계층에 He 초깃값을 적용한 결과 텐서보드에서 Dense 레이어 가중치 분포를 보면
initializer = tf.keras.initializers.HeNormal(seed=2024)
model_A = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape = (28, 28)),
tf.keras.layers.Dense(256, kernel_initializer = initializer, activation = 'relu'),
tf.keras.layers.Dense(64, kernel_initializer = initializer, activation = 'relu'),
tf.keras.layers.Dense(32, kernel_initializer = initializer, activation = 'relu'),
tf.keras.layers.Dense(16),
tf.keras.layers.Dense(10, activation = 'softmax')
])
model_A.summary()
```#결과#```
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
dense_7 (Dense) (None, 256) 200960
dense_8 (Dense) (None, 64) 16448
dense_9 (Dense) (None, 32) 2080
dense_10 (Dense) (None, 16) 528
dense_11 (Dense) (None, 10) 170
=================================================================
Total params: 220,186
Trainable params: 220,186
Non-trainable params: 0
_________________________________________________________________
````````````층이 깊어져도 분포가 균일하게 유지되는 것을 볼 수 있다.

2. 모델 저장 및 불러오기
■ save( ) 메소드를 사용해서 모델을 저장할 수 있다. 이때 저장 형식으로는 HDF5 포맷과 SavedModel 포맷 2 가지가 있다.
- SavedModel 포맷은 텐서플로2에서 기본으로 지원하는 포맷이고, HDF5 포맷은 대용량 데이터를 저장할 때 사용하는 포맷이다.
■ 모델을 저장할 때, 다음과 같이 .h5 확장자를 생략하면 자동으로 SavedModel 포맷으로 저장된다.
model_C.save('model_C.h5')
model_A.save('model_A') # SavedModel 포맷으로 저장■ 저장된 모델을 불러올 때는 tf.keras.models.load_model( ) 메서드를 사용하면 된다.
■ 모델을 저장할 때와 마찬가지로 .h5 확장자를 생략하면 SavedModel 포맷으로 저장된 모델을 불러온다.
model_c = tf.keras.models.load_model('model_C.h5')
model_a = tf.keras.models.load_model('model_A')
model_c.summary()
```#결과#```
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense_2 (Dense) (None, 256) 200960
batch_normalization (BatchN (None, 256) 1024
ormalization)
leaky_re_lu_1 (LeakyReLU) (None, 256) 0
dense_3 (Dense) (None, 64) 16448
batch_normalization_1 (Batc (None, 64) 256
hNormalization)
leaky_re_lu_2 (LeakyReLU) (None, 64) 0
dense_4 (Dense) (None, 32) 2080
batch_normalization_2 (Batc (None, 32) 128
hNormalization)
leaky_re_lu_3 (LeakyReLU) (None, 32) 0
dense_5 (Dense) (None, 16) 528
dense_6 (Dense) (None, 10) 170
=================================================================
Total params: 221,594
Trainable params: 220,890
Non-trainable params: 704
_________________________________________________________________
````````````
model_a.summary()
```#결과#```
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
dense_7 (Dense) (None, 256) 200960
dense_8 (Dense) (None, 64) 16448
dense_9 (Dense) (None, 32) 2080
dense_10 (Dense) (None, 16) 528
dense_11 (Dense) (None, 10) 170
=================================================================
Total params: 220,186
Trainable params: 220,186
Non-trainable params: 0
_________________________________________________________________
````````````
3. 함수형 API (Functional API)
■ 텐서플로 케라스는 3 가지 방식으로 모델을 생성할 수 있으며, 그 중 하나인 Sequential API는 Sequential 모델은 순차적으로 층을 쌓고, 그 순서대로 딥러닝 연산이 진행되기 때문에 단방향 모델만 구현할 수 있다.
■ 따라서 특정 레이어를 건너뛰거나 병합 & 분리하는 등의 유연한 구조의 모델을 만들 수 없다.
■ 3 가지 방식 중 다른 하나인 케라스의 함수형 API는 Sequential API가 만들지 못하는 유연한 모델을 만들 수 있다.
- Functional API는 다음 그림과 같이 같은 레벨에 여러 개의 층을 배치하여 입력과 출력을 공유하는 층을 구현할 수 있고, 다중 입력과 다중 출력을 가지는 모델을 만들 수도 있다.

■ 함수형 API로 모델을 만드는 방법은 먼저 입력층, 은닉층, 출력층을 정의하되, 각 층을 변수로 저장한다.
initializer = tf.keras.initializers.HeNormal(seed=2024) # He 초깃값 - 정규분포 방법
img_inputs = tf.keras.Input(shape=(28, 28), name = 'Input') # 입력되는 이미지 크기가 (28 x 28)
flatten = tf.keras.layers.Flatten(name = 'Flatten') # FCN의 구조로 네트워크를 만들 경우, 입력 데이터의 차원은 1차원
hidden1 = tf.keras.layers.Dense(256, kernel_initializer = initializer, activation='relu', name='Hidden1')
hidden2 = tf.keras.layers.Dense(64, kernel_initializer = initializer, activation='relu', name='Hidden2')
hidden3 = tf.keras.layers.Dense(32, kernel_initializer = initializer, activation='relu', name='Hidden3')
output = tf.keras.layers.Dense(10, kernel_initializer = initializer, activation='softmax', name='Output')■ 각 층을 변수로 저장하는 이유는 변수명을 통해 다음 층의 입력으로 연결하기 위해서이다. 이렇게 여러 개의 레이어를 마치 체인 구조로 계속 연결할 수 있다.
img_inputs = tf.keras.Input(shape=(28, 28), name = 'Input')
flatten = tf.keras.layers.Flatten(name = 'Flatten')(img_inputs)
hidden1 = tf.keras.layers.Dense(256, kernel_initializer = initializer, activation='relu', name='Hidden1')(flatten)
hidden2 = tf.keras.layers.Dense(64, kernel_initializer = initializer, activation='relu', name='Hidden2')(hidden1)
hidden3 = tf.keras.layers.Dense(32, kernel_initializer = initializer, activation='relu', name='Hidden3')(hidden2)
output = tf.keras.layers.Dense(10, kernel_initializer = initializer, activation='softmax', name='Output')(hidden3)img_inputs
```#결과#```
<KerasTensor shape=(None, 28, 28), dtype=float32, sparse=None, name=Input>
````````````
flatten
```#결과#```
<KerasTensor shape=(None, 784), dtype=float32, sparse=None, name=keras_tensor_120>
````````````
hidden2
```#결과#```
<KerasTensor shape=(None, 64), dtype=float32, sparse=False, name=keras_tensor_122>
````````````
output
```#결과#```
<KerasTensor shape=(None, 10), dtype=float32, sparse=False, name=keras_tensor_124>
````````````
img_inputs.shape, flatten.shape, hidden1.shape, hidden2.shape, hidden3.shape, output.shape
```#결과#```
((None, 28, 28), (None, 784), (None, 256), (None, 64), (None, 32), (None, 10))
````````````- img_inputs, flatten, hidden1, ... , output 객체는 모델이 처리할 데이터의 크기와 dtype에 대한 정보를 가지고 있다. 이런 객체를 심볼릭 텐서(symbolic tensor)라고 부른다. 실제 데이터를 가지고 있지 않지만 모델이 보게 될 데이터 텐서의 사양이 인코딩되어 있다.
- 심볼릭 텐서 크기에 있는 None의 위치는 배치 크기를 나타내며, None은 어떤 크기의 배치도 가능하다는 뜻이다. 즉, 이 모델은 어떤 크기의 배치에서도 사용 가능하다.
■ 이렇게 체인 방식으로 연결한 다음, keras.Model( )에 입력층과 출력층을 지정하여 모델을 생성할 수 있다.
model = keras.Model(inputs=img_inputs, outputs=output, name="functional api model")
model.summary()
tensorflow.keras.utils.plot_model(model, show_shapes = True)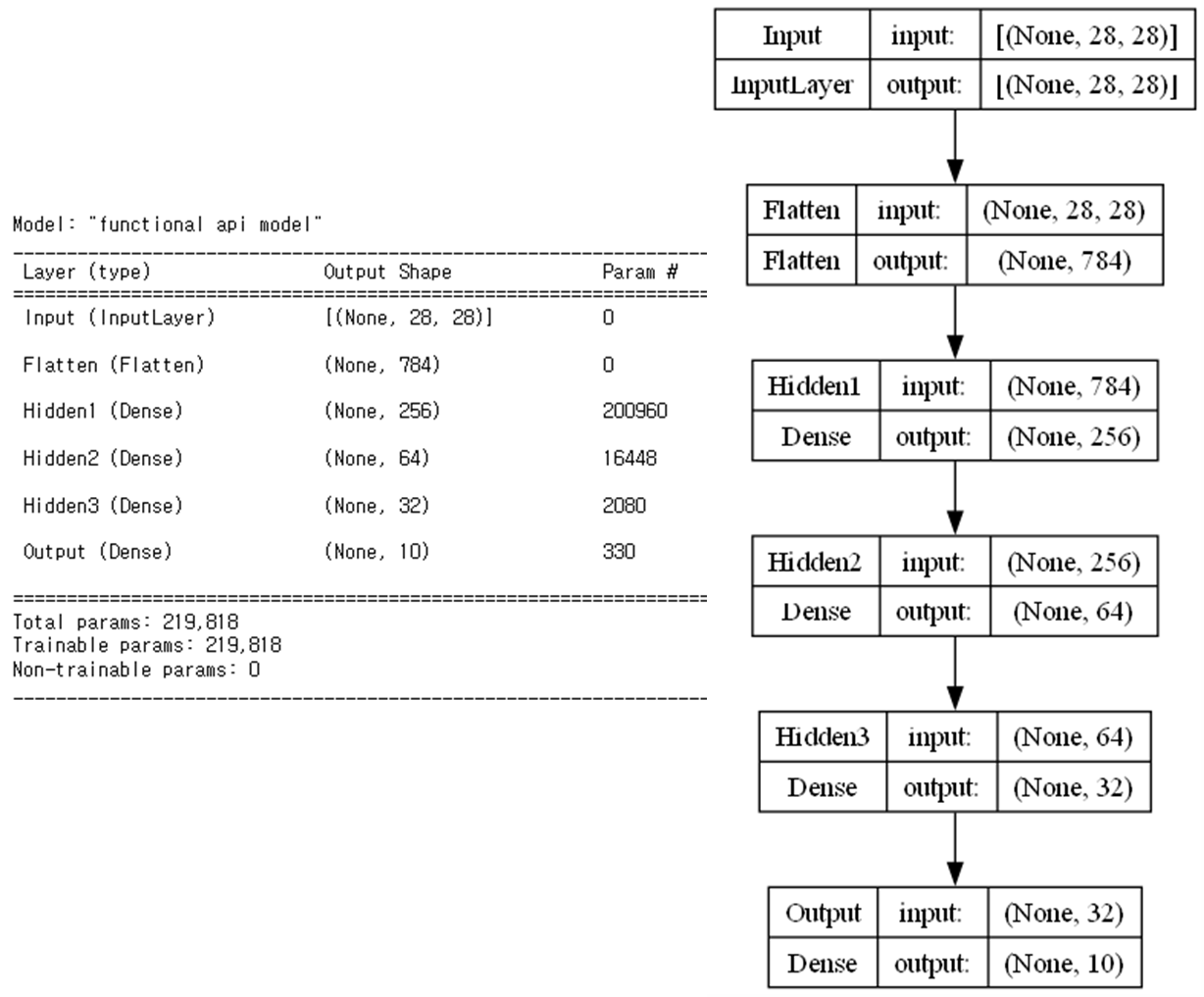
■ Functional API로 생성한 모델도 Sequential API로 생성한 모델처럼 모델을 생성한 다음, compile( )과 fit( ) 메서드를 통해 모델을 컴파일하고 훈련한다.
model.compile(
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001, beta_1 = 0.9, beta_2 = 0.99),
loss = tf.keras.losses.CategoricalCrossentropy(),
metrics = [tf.keras.metrics.CategoricalAccuracy()]
)
history = model.fit(train_set, train_labels, batch_size = 256, validation_data=(valid_set, valid_labels), epochs=100)
3.1 다중 입력, 다중 출력 모델
■ Sequential 모델처럼 간단한 모델과 달리 대부분의 모델은 입력이 여러 개이거나 출력이 여러 개인 다중 입력, 다중 출력 모델이며 분기 또는 병합이 되는 유연한 구조를 갖는 그래프 형태이다.
■ 함수형 API에서 그래프 형태의 모델을 주로 다룬다. 체인 방식으로 유연하게 각 층을 '연결'할 수 있기 때문이다.
■ 예를 들어 입력이 3개이고, sigmoid 출력과 tanh 출력 2개의 출력을 갖는 모델을 함수형 API를 이용해 다음과 같이 정의할 수 있다.
## 모델 입력 정의
input_1 = keras.Input(shape = (10000, ), name = 'input1')
input_2 = keras.Input(shape = (10000, ), name = 'inpu2')
input_3 = keras.Input(shape = (100, ), name = 'inpu3')
features = layers.Concatenate()([input_1, input_2, input_3]) # 입력 특성을 하나의 텐서 변수로 연결
features = layers.Dense(32, activation = 'relu')(features) # 은닉층 적용
## 모델 출력 정의
output_1 = layers.Dense(1, activation = 'sigmoid', name = 'outpu1')(features)
output_2 = layers.Dense(1, activation = 'tanh', name = 'outpu2')(features)
## 입력과 출력을 지정하여 모델 정의
ex_model = keras.Model(inputs = [input_1, input_2, input_3],
outputs = [output_1, output_2], name = 'ex_model')ex_model.summary()
```#결과#```
Model: "ex_model"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ input1 (InputLayer) │ (None, 10000) │ 0 │ - │
├───────────────────────────────┼───────────────────────────┼─────────────────┼────────────────────────────┤
│ inpu2 (InputLayer) │ (None, 10000) │ 0 │ - │
├───────────────────────────────┼───────────────────────────┼─────────────────┼────────────────────────────┤
│ inpu3 (InputLayer) │ (None, 100) │ 0 │ - │
├───────────────────────────────┼───────────────────────────┼─────────────────┼────────────────────────────┤
│ concatenate_6 (Concatenate) │ (None, 20100) │ 0 │ input1[0][0], inpu2[0][0], │
│ │ │ │ inpu3[0][0] │
├───────────────────────────────┼───────────────────────────┼─────────────────┼────────────────────────────┤
│ dense_9 (Dense) │ (None, 32) │ 643,232 │ concatenate_6[0][0] │
├───────────────────────────────┼───────────────────────────┼─────────────────┼────────────────────────────┤
│ outpu1 (Dense) │ (None, 1) │ 33 │ dense_9[0][0] │
├───────────────────────────────┼───────────────────────────┼─────────────────┼────────────────────────────┤
│ outpu2 (Dense) │ (None, 1) │ 33 │ dense_9[0][0] │
└───────────────────────────────┴───────────────────────────┴─────────────────┴────────────────────────────┘
Total params: 643,298 (2.45 MB)
Trainable params: 643,298 (2.45 MB)
Non-trainable params: 0 (0.00 B)
````````````
keras.utils.plot_model(ex_model, show_shapes = True, rankdir='LR')
- None의 위치는 배치 크기를 나타내며, None은 어떤 크기의 배치도 가능하다는 뜻이다. 즉, 이 모델은 어떤 크기의 배치에서도 사용 가능하다.
■ 모델 훈련은 입력과 출력 데이터를 리스트로 각각 묶어 fit( ) 메서드를 호출하면 된다. 리스트 내 순서는 Model 클래스로 모델을 정의할 때 전달한 순서와 같아야 한다.
import numpy as np
## 더미 입력 데이터
data_input_1 = np.random.randint(0, 2, size = (1000, 10000))
data_input_2 = np.random.randint(0, 2, size = (1000, 10000))
data_input_3 = np.random.randint(0, 2, size = (1000, 100))
## 더미 타겟 데이터
data_output_1 = np.random.random(size = (1000, 1))
data_output_2 = np.random.random(size = (1000, 1))ex_model.compile(optimizer='sgd', loss=['mse','mse'], metrics=[['mse'], ['mse']])
ex_model.fit([data_input_1, data_input_2, data_input_3],
[data_output_1, data_output_2], epochs = 10)
```#결과#```
Epoch 1/10
32/32 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - loss: 0.5825 - output_1_mse: 0.1952 - output_2_mse: 0.3874
...,
Epoch 10/10
32/32 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.3625 - output_1_mse: 0.0487 - output_2_mse: 0.3137
````````````
ex_model.evaluate([data_input_1, data_input_2, data_input_3],
[data_output_1, data_output_2])
```#결과#```
[0.37346959114074707, 0.035250473767519, 0.33454325795173645]
````````````
pred_output_1, pred_output_2 = ex_model.predict([data_input_1, data_input_2, data_input_3])
pred_output_1[0], pred_output_2[2]
```#결과#```
(array([0.5235653], dtype=float32), array([1.], dtype=float32))
````````````■ 입력 순서를 신경 쓰고 싶지 않다면, 다음과 같이 층에 부여한 이름을 지정해서 딕셔너리로 전달할 수도 있다.
ex_model.compile(optimizer='sgd',
loss={'output1':'mse', 'output2':'mse'},
metrics={'output1':['mse'], 'output2':['mse']})
ex_model.fit({'input1':data_input_1, 'input2':data_input_2, 'input3':data_input_3},
{'output1':data_output_1, 'output2':data_output_2}, epochs = 10)
ex_model.evaluate({'input1':data_input_1, 'input2':data_input_2, 'input3':data_input_3},
{'output1':data_output_1, 'output2':data_output_2})
pred_output_1, pred_output_2 = ex_model.predict({'input1':data_input_1, 'input2':data_input_2, 'input3':data_input_3})
2. 모델 서브클래싱(Model Subclassing)
■ 3 가지 모델 생성 방법 중 마지막 방법으로, 텐서플로 케라스의 클래스를 직접 상속받아서 사용자 정의 모델을 만들 때 사용하는 방법이다.
■ 모델 서브클래싱으로 생성하고자 하는 모델 클래스를 구현하기 위해서는 tf.keras.Model 클래스를 상속받아야 한다.
class MyModel(tf.keras.Model):
pass■ 모델의 생성자 메서드에는 모델이 사용할 레이어를 정의한다.
class MyModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.flatten = tf.keras.layers.Flatten()
self.hidden1 = tf.keras.layers.Dense(256, kernel_initializer='he_normal', activation='relu')
self.hidden2 = tf.keras.layers.Dense(64, kernel_initializer='he_normal', activation='relu')
self.hidden3 = tf.keras.layers.Dense(32, kernel_initializer='he_normal', activation='relu')
self.output = tf.keras.layers.Dense(10, activation='softmax')■ 그리고 모델 학습 과정에서 fit( ) 메서드가 호출될 때 순전파를 수행하는 함수가 필요하다. 이 함수는 call( ) 함수를 메소드 오버라이딩을 이용해 구현할 수 있다.
https://www.tensorflow.org/api_docs/python/tf/keras/Model
tf.keras.Model | TensorFlow v2.16.1
A model grouping layers into an object with training/inference features.
www.tensorflow.org
class MyModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.flatten = tf.keras.layers.Flatten()
self.hidden1 = tf.keras.layers.Dense(256, kernel_initializer = 'HeNormal', activation = 'relu')
self.hidden2 = tf.keras.layers.Dense(64, kernel_initializer = 'HeNormal', activation = 'relu')
self.hidden3 = tf.keras.layers.Dense(32, kernel_initializer = 'HeNormal', activation = 'relu')
self.outputs = tf.keras.layers.Dense(10, activation = 'softmax')
def call(self, inputs):
x = self.flatten(inputs)
x = self.hidden1(x)
x = self.hidden2(x)
x = self.hidden3(x)
x = self.outputs(x)
return xmodel = MyModel()
print(dir(model)) # MyModel 클래스로 만든 객체 model의 모든 속성과 메서드 확인- 이제 모델의 input_shape까지 정의해 주면, 전체 모델의 구조가 완성되며 모델의 구조를 summary( )로 확인할 수 있다.
model._name = 'Model_Subclassing'
model(tf.keras.layers.Input(shape=(28, 28))) # 모델 input
model.summary()
```#결과#```
Model: "Model_Subclassing"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_7 (Flatten) multiple 0
dense_27 (Dense) multiple 200960
dense_28 (Dense) multiple 16448
dense_29 (Dense) multiple 2080
dense_30 (Dense) multiple 330
=================================================================
Total params: 219,818
Trainable params: 219,818
Non-trainable params: 0
_________________________________________________________________
````````````■ 모델 서브클래싱으로 생성한 모델도 compile( ), fit( ), evaluate( ), predict( ) 메서드를 통해 모델 컴파일, 훈련, 평가, 추론을 수행할 수 있다. 이는 상속받은 Model 클래스가 compile( ), fit( ), evaluate( ), predict( ) 메서드를 가지고 있기 때문이다.
model.compile(
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001, beta_1 = 0.9, beta_2 = 0.99),
loss = tf.keras.losses.CategoricalCrossentropy(),
metrics = [tf.keras.metrics.CategoricalAccuracy()]
)
history = model.fit(train_set, train_labels, batch_size = 256, validation_data=(valid_set, valid_labels), epochs=100)
■ 모델 서브클래싱의 장점은 클래스로 구현하기 때문에 동적으로 레이어의 하이퍼파라미터를 변경할 수 있다는 점이다.
■ 예를 들어 다음과 같이 레이어의 뉴런(노드) 개수, 가중치 초깃값 등의 하이퍼파라미터를 유연하게 변경할 수 있다.
class MyModel2(tf.keras.Model):
def __init__(self, units, num_classes, initializer, activation_function, use_dropout = True, dropout_rate = 0.5):
super().__init__()
self.use_dropout = use_dropout
self.dropout_rate = dropout_rate
if num_classes < 2: raise ValueError('출력층의 함수는 softmax')
if self.use_dropout:
self.flatten = tf.keras.layers.Flatten(name = 'flatten')
self.hidden1 = tf.keras.layers.Dense(units, kernel_initializer=initializer, activation=activation_function, name = 'hidden1')
self.drop1 = tf.keras.layers.Dropout(rate = dropout_rate, name = 'drop1')
self.hidden2 = tf.keras.layers.Dense(max(1, units // 4), kernel_initializer=initializer, activation=activation_function, name = 'hidden2')
self.drop2 = tf.keras.layers.Dropout(rate = dropout_rate, name = 'drop2')
self.hidden3 = tf.keras.layers.Dense(max(1, units // 8), kernel_initializer=initializer, activation=activation_function, name = 'hidden3')
self.drop3 = tf.keras.layers.Dropout(rate = dropout_rate, name = 'drop3')
self.outputs = tf.keras.layers.Dense(num_classes, activation='softmax', name = 'output')
else:
self.flatten = tf.keras.layers.Flatten(name = 'flatten')
self.hidden1 = tf.keras.layers.Dense(units, kernel_initializer=initializer, activation=activation_function, name = 'hidden1')
self.hidden2 = tf.keras.layers.Dense(max(1, units // 4), kernel_initializer=initializer, activation=activation_function, name = 'hidden2')
self.hidden3 = tf.keras.layers.Dense(max(1, units // 8), kernel_initializer=initializer, activation=activation_function, name = 'hidden3')
self.outputs = tf.keras.layers.Dense(num_classes, activation='softmax', name = 'output')
def call(self, inputs, training=False):
x = self.flatten(inputs)
x = self.hidden1(x)
if self.use_dropout:
x = self.drop1(x, training=training)
x = self.hidden2(x)
if self.use_dropout:
x = self.drop2(x, training=training)
x = self.hidden3(x)
if self.use_dropout:
x = self.drop3(x, training=training)
x = self.outputs(x)
return x- use_dropout이라는 플래그를 설정해 필요 시, 드롭아웃 계층을 활성화한다.
- MNIST 데이터 셋을 이용할 것이기 때문에 출력층의 함수는 softmax 함수를 사용할 것이다. 따라서 출력층의 뉴런 수로 2 미만의 값이 들어오면 에러를 발생시킨다.
- 활성화 함수 계층의 뉴런 수는 입력값에 의해 결정되게 설정하였다. 단, 뉴런 수가 0 이 되는 것을 방지한다.
- call 메서드에 training 플래그를 설정하면 케라스에서 fit( )으로 모델을 학습할 때는 드롭아웃을 적용하고, 학습 과정이 아닌 경우에는 드롭아웃을 적용하지 않는다
참고) tf.keras.layers.Dropout | TensorFlow v2.16.1,
model_2 = MyModel2(256, 10, 'HeUniform', 'relu', use_dropout = False)
model_3 = MyModel2(256, 10, 'HeUniform', 'LeakyReLU', use_dropout = True, dropout_rate = 0.4)
model_2(tf.keras.layers.Input(shape=(28, 28)))
model_3(tf.keras.layers.Input(shape=(28, 28)))
model_2.compile(
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01, beta_1 = 0.9, beta_2 = 0.99),
loss = tf.keras.losses.CategoricalCrossentropy(),
metrics = [tf.keras.metrics.CategoricalAccuracy()]
)
model_3.compile(
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01, beta_1 = 0.9, beta_2 = 0.99),
loss = tf.keras.losses.CategoricalCrossentropy(),
metrics = [tf.keras.metrics.CategoricalAccuracy()]
)model_2.fit(train_set, train_labels, batch_size = 256, validation_data=(valid_set, valid_labels),
epochs=100, callbacks = [lr_scheduler, tensorboard_2])
model_3.fit(train_set, train_labels, batch_size = 256, validation_data=(valid_set, valid_labels),
epochs=100, callbacks = [lr_scheduler, tensorboard_3])

- 먼저 드롭아웃을 적용하지 않은 model_2는 학습이 진행되면서 step size가 작아져도 과적합된 모습을 보이고 있다.

- 그러나 드롭아웃을 적용한 model_3는 다음과 같이 val_loss가 안정적으로 수렴되며, 정확도도 train set과 큰 차이를 보이지 않아 model_3의 성능이 더 우수할 것으로 보인다.

- 실제로 model_3와 model_2로 학습과 검증에 사용되지 않은 test set에 대해 예측한 결과, 성능에서 큰 차이를 보이는 것을 확인할 수 있다.
pred_3 = model_3.predict(test_set)
pred_2 = model_2.predict(test_set)
pred_3_labels = np.argmax(pred_3, axis=1) # array([7, 2, 1, ..., 4, 5, 6], dtype=int64)
pred_2_labels = np.argmax(pred_2, axis=1)
test_labels_labels = np.argmax(test_labels, axis=1) # array([7, 2, 1, ..., 4, 5, 6], dtype=int64)
from sklearn.metrics import accuracy_score
pred_3_accuracy = accuracy_score(test_labels_labels, pred_3_labels)
print('model_3 test set 정확도:', pred_3_accuracy)
pred_2_accuracy = accuracy_score(test_labels_labels, pred_2_labels)
print('model_2 test set 정확도:', pred_2_accuracy)
```#결과#```
model_3 test set 정확도: 0.9805
model_2 test set 정확도: 0.0901
````````````
3. Sequential, Functional, Model Subclassing 혼합하여 사용하기
■ 중요한 것은 케라스 API로 만든 모든 모델은 Sequential API로 만든 모델인지 Functional API로 만든 모델인지 서브클래싱 모델인지에 상관없이 서로 혼합하여 사용할 수 있다는 점이다.
■ 예를 들어 다음과 같이 함수형 모델에 서브클래싱 모델의 레이어나 모델을 사용할 수 있고
class MyModel2(tf.keras.Model):
def __init__(self, units, num_classes, initializer, activation_function, use_dropout = True, dropout_rate = 0.5):
super().__init__()
self.use_dropout = use_dropout
self.dropout_rate = dropout_rate
if num_classes < 2: raise ValueError('출력층의 함수는 softmax')
if self.use_dropout:
self.flatten = tf.keras.layers.Flatten(name = 'flatten')
self.hidden1 = tf.keras.layers.Dense(units, kernel_initializer=initializer, activation=activation_function, name = 'hidden1')
self.drop1 = tf.keras.layers.Dropout(rate = dropout_rate, name = 'drop1')
self.hidden2 = tf.keras.layers.Dense(max(1, units // 4), kernel_initializer=initializer, activation=activation_function, name = 'hidden2')
self.drop2 = tf.keras.layers.Dropout(rate = dropout_rate, name = 'drop2')
self.hidden3 = tf.keras.layers.Dense(max(1, units // 8), kernel_initializer=initializer, activation=activation_function, name = 'hidden3')
self.drop3 = tf.keras.layers.Dropout(rate = dropout_rate, name = 'drop3')
self.outputs = tf.keras.layers.Dense(num_classes, activation='softmax', name = 'output')
else:
self.flatten = tf.keras.layers.Flatten(name = 'flatten')
self.hidden1 = tf.keras.layers.Dense(units, kernel_initializer=initializer, activation=activation_function, name = 'hidden1')
self.hidden2 = tf.keras.layers.Dense(max(1, units // 4), kernel_initializer=initializer, activation=activation_function, name = 'hidden2')
self.hidden3 = tf.keras.layers.Dense(max(1, units // 8), kernel_initializer=initializer, activation=activation_function, name = 'hidden3')
self.outputs = tf.keras.layers.Dense(num_classes, activation='softmax', name = 'output')
def call(self, inputs, training=False):
x = self.flatten(inputs)
x = self.hidden1(x)
if self.use_dropout:
x = self.drop1(x, training=training)
x = self.hidden2(x)
if self.use_dropout:
x = self.drop2(x, training=training)
x = self.hidden3(x)
if self.use_dropout:
x = self.drop3(x, training=training)
x = self.outputs(x)
return x
inputs = tf.keras.layers.Input(shape=(28, 28))
outputs = MyModel2(256, 10, 'HeUniform', 'relu', use_dropout = True, dropout_rate = 0.4)(inputs)서브클래싱 모델의 레이어나 모델의 일부로 함수형 모델을 사용할 수 있다.
inputs = tf.keras.layers.Input(shape=(64, ))
outputs = tf.keras.layers.Dense(1, activation = 'sigmoid')(inputs)
functional_model = tf.keras.Model(inputs = inputs, outputs = outputs)
class MyModel3(tf.keras.Model):
def __init__(self, num_classes = 2):
super().__init__()
self.dense = layers.Dense(64, activation = 'relu')
self.functional_model = functional_model
def call(self, x):
x = self.dense(x)
return self.functional_model(x)
model = MyModel3()
4. 사용자 정의
4.1 사용자 정의 손실 함수
■ 텐서플로에서 제공되는 손실 함수 외에 사용자 정의 함수로 직접 손실 함수를 정의해서 모델을 훈련시킬 수 있다.
■ 이때 주의할 점은 계산 식을 작성할 때, 파이썬 내장 함수나 넘파이 함수를 사용하지 않고 텐서플로 계산 함수만 사용해야 한다는 점이다.
- 텐서보드에서 gradient tape이나 순전파 과정의 계산 그래프를 보면, 다음 층으로 전달하는 값이 텐서임을 확인할 수 있다.
- 그러므로 만약, 파이썬 내장 함수나 넘파이 함수를 사용하면 텐서플로의 계산 그래프에서 벗어나 자동 미분 기능이 제대로 작동하지 않을 수 있다.

- 따라서 손실 함수 계산 과정에서 텐서 연산이 수행될 수 있도록 텐서플로 계산 함수를 사용해야 한다.
■ 예를 들어 Huber Loss를 사용자 정의 함수로 만들어 보자.
- Huber Loss의 공식은 다음과 같다.
Huber Loss={1n∑ni=112(yi−ˆyi)2, |yi−ˆyi|≤δ1n∑ni=1δ(|yi−ˆyi|−12δ), |yi−ˆyi|>δ
for x in error:
if abs(x) <= delta: # delta의 디폴트는 1.0
loss.append(0.5 * x^2)
elif abs(x) > delta:
loss.append(delta * abs(x) - 0.5 * delta^2)
loss = mean(loss, axis=-1)참고) tf.keras.losses.huber | TensorFlow v2.16.1, tf.keras.losses.Huber | TensorFlow v2.16.1
- 이 공식을 기반으로 텐서플로 계산 함수만 사용하여 Huber Loss 함수를 만들면
def HuberLoss(y_true, y_pred):
error = y_true - y_pred # 오차 계산
delta = 1.0 # 임곗값
small = tf.abs(error) <= delta # 오차의 절댓값이 임곗값 이하인지
small_error = tf.square(error) / 2 # L2 lss 적용
big_error = delta * (tf.abs(error) - (delta / 2)) # L1 loss 적용
return tf.where(small, small_error, big_error) # small이 True이면 small_error, False이면 big_errory_pred = np.array([0., 1., 2., 3., 4.])
y_true = np.array([2., 4., 6., 8., 10.]) # y = 2x
model = tf.keras.Sequential([tf.keras.layers.Dense(units = 1, input_shape = [1])]) # 선형 모델
model.compile(optimizer = 'sgd', loss = HuberLoss)
model.fit(y_pred, y_true, epochs = 100, verbose = 0)
model.predict([6.0])
```#결과#```
array([[14.591809]], dtype=float32)
````````````
4.2 사용자 정의 레이어
■ 모델 서브클래싱에서 tf.keras.Model 클래스를 상속받아 새로운 모델을 구현했듯이 레이어도 tf.keras.layers의 Layer 클래스를 상속받아 필요한 부분만 레이어를 수정하거나 새로운 레이어를 정의해서 모델 훈련에 사용할 수 있다.
■ 예를 들어 Dense 레이어를 Layer 클래스를 상속받아 만들어 보자.
from tensorflow.keras.layers import Layer
class MyDense(Layer):
def __init__(self, units = 32, input_shape = None):
super().__init__()
self.units = units
def build(self, input_shape):
# 가중치
w_init = tf.random_normal_initializer()
self.w = tf.Variable(name = 'weight', initial_value = w_init(shape=(input_shape[-1], self.units),
dtype = 'float32', trainable = True))
# 편향
b_init = tf.zeros_initializer()
self.b = tf.Variable(name = 'bias', initial_value = b_init(shape=(self.units),
dtype = 'float32', trainable = True))
def call(self, inputs):
return tf.matmul(self.w, inputs) + self.b # y = w dot x + b참고) 하위 클래스화를 통한 새로운 레이어 및 모델 만들기 | TensorFlow Core
일단 이 부분 구현한거 블로그에 넣을지 말지 생각해보기 일단 진짜 Dense Layer랑 똑같이 만드는 것으로 연습하고 애는 비공개에 넣던가. 일단 패스
4.3 사용자 정의 훈련
4.3.1 train_on_batch
■ fit( ) 메서드로 모델을 훈련하면 1 epoch마다 배치 크기만큼 학습 데이터에 대해 훈련을 진행한 후, validation_data를 지정했으면 전체 배치에 대한 훈련 및 검증 데이터에 대한 손실 함수와 평가 지표에 대한 결과를, 지정하지 않았으면 전체 배치에 대한 훈련 데이터에 대한 손실 함수와 평가 지표에 대한 결과를 출력한다.
■ 예를 들어 학습 데이터가 48,000 개이고 배치 크기가 256이라면 1 epoch 당 처리해야 할 전체 배치 수는 188개이다.
model_2.fit(train_set, train_labels, batch_size = 256, validation_data=(valid_set, valid_labels),
epochs=100, callbacks = [lr_scheduler, tensorboard_2])
```#결과#```
Epoch 1/100
188/188 [==============================] - 2s 6ms/step - loss: 0.3355 - categorical_accuracy: 0.8945 - val_loss: 0.1602 - val_categorical_accuracy: 0.9517 - lr: 0.0100
...
...
````````````■ train_on_batch( ) 메서드를 활용하면 배치 단위로 구분해서 훈련을 진행할 수 있다.
참고) https://www.tensorflow.org/api_docs/python/tf/keras/Model#train_on_batch
tf.keras.Model | TensorFlow v2.16.1
A model grouping layers into an object with training/inference features.
www.tensorflow.org
■ 배치 단위로 구분해 학습을 하려면 다음과 같이 배치를 생성하는 함수가 필요하다.
def get_batches(x, y, batch_size):
for i in range(int(x.shape[0] // batch_size)): # 1 epoch 당 처리해야 할 전체 배치 수
x_batch = x[i * batch_size : (i+1) * batch_size]
y_batch = y[i * batch_size : (i+1) * batch_size]
yield(np.asarray(x_batch), np.asarray(y_batch))- yield 키워드를 사용하는 이유는 다음과 같이 함수로부터 이터레이터를 생성하기 위해서이다.
def Gen():
yield 'a'
yield 'first'
yield 'b'
yield 'second'
for g in Gen():
print(g, end = ' ')
```#결과#```
a first b second
````````````- 따라서, 만약 배치 크기가 2라면, get_batches 함수가 for 문을 통해 실행될 때 (x[0:2], y[0:2]), (x[2:4], y[2:4]), (x[4:6], y[4:6]), .... 식으로 값을 반환하기 때문에 올바르게 배치를 생성할 수 있다.
batch_gen = get_batches(train_set, train_labels, batch_size=2)
x, y = next(batch_gen)
y # train_labels[0:2]
```#결과#```
array([[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]], dtype=float32)
````````````
x2, y2 = next(batch_gen)
y2 # train_labels[2:4]
```#결과#```
array([[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]], dtype=float32)
````````````
train_labels[0:4] # 학습 데이터 레이블
```#결과#```
array([[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.], # 여기까지가 y[0:2]
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], # 여기서부터
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]], # 여기까지가 y[2:4] dtype=float32)
````````````■ 이렇게 배치 생성 함수와 train_on_batch( )를 사용하면 다음과 같이 배치 단위별 학습이 진행된다.
print(train_set.shape, train_labels.shape, valid_set.shape, valid_labels.shape)
```#결과#```
(48000, 28, 28) (48000, 10) (12000, 28, 28) (12000, 10)
````````````
initializer = tf.keras.initializers.HeNormal(seed=2024)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape = (28, 28)),
tf.keras.layers.Dense(256, kernel_initializer = initializer, activation = 'relu'),
tf.keras.layers.Dense(64, kernel_initializer = initializer, activation = 'relu'),
tf.keras.layers.Dense(32, kernel_initializer = initializer, activation = 'relu'),
tf.keras.layers.Dense(16),
tf.keras.layers.Dense(10, activation = 'softmax')
])
model.compile(
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01, beta_1 = 0.9, beta_2 = 0.99),
loss = tf.keras.losses.CategoricalCrossentropy(),
metrics = [tf.keras.metrics.CategoricalAccuracy()]
)monitoring_step = 50
for epoch in range(1, 3):
batch = 1
total_loss, total_acc = 0, 0
losses = []
accuracy = []
for x, y in get_batches(train_set, train_labels, batch_size = 64): # 학습 데이터 48000개 // 배치 크기 64 = 배치 수 750
loss, acc = model.train_on_batch(x, y)
total_loss += loss # 배치별 loss 누적
total_acc += acc # 배치별 정확도 누적
if batch % monitoring_step == 0: # 배치 번호 50, 100, 150, ... 일 때마다 출력 # 배치 수 750 // 50 = 15번 출력
losses.append(total_loss / batch) # 평균 손실
accuracy.append(total_acc / batch) # 평균 정확도
print(f'epoch {epoch}, batch {batch}번째, batch_loss {loss:.4f}, batch_acc {acc:.4f}, avg_loss : {total_loss / batch}, avg_acc : {total_acc / batch}')
batch += 1
fig, ax = plt.subplots(1, 2, figsize = (12, 3))
ax[0].plot(np.arange(1, batch//monitoring_step+1), losses, marker = 'o')
ax[0].set_title(f'epoch {epoch} loss')
ax[0].grid(True)
ax[1].plot(np.arange(1, batch//monitoring_step+1), accuracy, marker = 'o', color='#FF7F0E')
ax[1].set_title(f'epoch {epoch} accuracy')
ax[1].grid(True)
plt.tight_layout()
plt.show()
# test set은 최종 단계에서 딱 한 번 test 하기 위해 사용해야 하므로 valid set 사용
val_loss, val_acc = model.evaluate(valid_set, valid_labels)
print(f'epoch {epoch}, val_loss {val_loss:.4f}, val_acc {val_acc:.4f}')
print()
■이렇게 tarin_on_batch( )를 이용한다면,
- fit( ) 메서드로 모델을 훈련시키기 전에 배치 단위별로 손실 함수 값과 모델 성능을 확인할 수 있어 특정 배치에서 급격한 손실 증가 또는 정확도 감소 등을 확인하고,
- 필요에 따라 특정 배치에서만 학습률 조정 등의 커스텀이 가능하다.
4.3.2 자동 미분
■ 텐서플로의 자동 미분 기능을 활용해 모델 컴파일을 하지 않고 모델을 훈련할 수도 있다.
■ GradientTape과 gradient( ) 함수로 계산한 미분 값을 optimizer에 적용하면 loss를 구할 수 있기 때문이다.
참고) 훈련 루프 처음부터 작성하기 | TensorFlow Core
훈련 루프 처음부터 작성하기 | TensorFlow Core
훈련 루프 처음부터 작성하기 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. !pip install -U tf-hub-nightlyimport tensorflow_hub as hubfrom tensorflow.keras import layers import ten
www.tensorflow.org
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape = (28, 28)),
tf.keras.layers.Dense(256, kernel_initializer = initializer, activation = 'relu'),
tf.keras.layers.Dense(64, kernel_initializer = initializer, activation = 'relu'),
tf.keras.layers.Dense(32, kernel_initializer = initializer, activation = 'relu'),
tf.keras.layers.Dense(16),
tf.keras.layers.Dense(10, activation = 'softmax')
])
model.summary()
```#결과#```
Model: "sequential_7"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_7 (Flatten) (None, 784) 0
dense_37 (Dense) (None, 256) 200960
dense_38 (Dense) (None, 64) 16448
dense_39 (Dense) (None, 32) 2080
dense_40 (Dense) (None, 16) 528
dense_41 (Dense) (None, 10) 170
=================================================================
Total params: 220,186
Trainable params: 220,186
Non-trainable params: 0
_________________________________________________________________
````````````# model.compile을 사용하지 않음
# 기록을 위한 옵티마이저, 손실 함수, 지표 별도로 정의
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01, beta_1 = 0.9, beta_2 = 0.99)
loss_function = tf.keras.losses.CategoricalCrossentropy()
train_loss = tf.keras.metrics.Mean(name = 'train_loss')
train_acc = tf.keras.metrics.CategoricalAccuracy(name = 'train_accuracy')
valid_loss = tf.keras.metrics.Mean(name = 'valid_loss')
valid_acc = tf.keras.metrics.CategoricalAccuracy(name = 'valid_accuracy')@tf.function
def train_step(images, labels): # 매개변수 - 이미지, 레이블
with tf.GradientTape() as tape: # tape에 pred와 loss를 기록
pred = model(images, training = True) # 예측
loss = loss_function(labels, pred) # 손실
grad = tape.gradient(loss, model.trainable_variables) # 미분 계산 # model.trainable_variables == dense_37부터 dense_41까지의 가중치와 편향
optimizer.apply_gradients(zip(grad, model.trainable_variables)) # optimizer 적용 # gradient 갱신
train_loss(loss) # train set 손실 계산
train_acc(labels, pred) # train set 정확도 계산- 텐서플로 2부터 지연 실행 모드에서 즉시 실행 모드가 기본값으로 변경되었다.
- 지연 실행 모드는 계산 그래프를 생성하고 계산 순서를 최적화한 다음, 연산을 수행한다.
- 반면, 즉시 실행 모드는 복잡한 연산을 수행하는 모델 훈련 시 연산이 느리고 비효율적이다. 따라서 데코레이터 @tf.function을 붙여 지연 실행 모드로 런타임을 변경한다.
- model.trainable_variables는 모델의 훈련가능한 변수, 즉 현재 모델의 각 레이어에 있는 가중치와 편향 값이다. loss를 이 변수들에 대해 미분을 계산한다.
print(model.trainable_variables[0]); print(); print(model.trainable_variables[1])
```#결과#```
<tf.Variable 'dense_37/kernel:0' shape=(784, 256) dtype=float32, numpy=
array([[-7.19847903e-02, -5.74599095e-02, -2.17129793e-02, ...,
-3.31069045e-02, -5.70148416e-02, 2.98639643e-03],
[-3.76287219e-03, -1.22943874e-02, 1.05322592e-01, ...,
-6.04476891e-02, -3.74533050e-02, -6.77790865e-02],
...,
[ 4.53772917e-02, -1.34323500e-02, -6.53809980e-02, ...,
-4.31516021e-02, 7.32241049e-02, -1.74596310e-02],
[-3.53412377e-03, 6.09558299e-02, -3.62763964e-02, ...,
3.25258896e-02, 8.47862539e-05, -1.60587896e-02]], dtype=float32)>
<tf.Variable 'dense_37/bias:0' shape=(256,) dtype=float32, numpy=
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
...,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0.], dtype=float32)>
````````````- 모델을 검증할 때는 gradient를 갱신할 필요가 없으므로 다음과 같이 model의 training 옵션을 꺼줘야 한다.
@tf.function
def valid_step(images, labels): # 매개변수 - 이미지, 레이블
with tf.GradientTape() as tape:
pred = model(images, training = False) # 예측 # training = False을 함으로써 train_step처럼 gradient가 갱신되지 않도록
loss = loss_function(labels, pred) # 손실
valid_loss(loss) # valid set 손실 계산
valid_acc(labels, pred) # valid set 정확도 계산for epoch in range(1, 11):
# 평가지표 초기화
train_loss.reset_states()
train_acc.reset_states()
valid_loss.reset_states()
valid_acc.reset_states()
for images, labels in get_batches(train_set, train_labels, batch_size = 64):
train_step(images, labels)
for images, labels in get_batches(valid_set, valid_labels, batch_size = 32):
valid_step(images, labels)
print(
f'epoch {epoch}, '
f'loss {train_loss.result():.4f}, '
f'acc {train_acc.result():.4f}, '
f'val_loss {valid_loss.result():.4f}, '
f'val_acc {valid_acc.result():.4f}')
```#결과#```
epoch 1, loss 0.1345, acc 0.9659, val_loss 0.1345, val_acc 0.9653
epoch 2, loss 0.1136, acc 0.9717, val_loss 0.1584, val_acc 0.9643
epoch 3, loss 0.1032, acc 0.9752, val_loss 0.1498, val_acc 0.9684
epoch 4, loss 0.0904, acc 0.9788, val_loss 0.1503, val_acc 0.9676
epoch 5, loss 0.0872, acc 0.9796, val_loss 0.1711, val_acc 0.9668
epoch 6, loss 0.0762, acc 0.9823, val_loss 0.1724, val_acc 0.9693
epoch 7, loss 0.0726, acc 0.9836, val_loss 0.1538, val_acc 0.9713
epoch 8, loss 0.0666, acc 0.9849, val_loss 0.1793, val_acc 0.9700
epoch 9, loss 0.0676, acc 0.9852, val_loss 0.2068, val_acc 0.9700
epoch 10, loss 0.0623, acc 0.9861, val_loss 0.1809, val_acc 0.9722
````````````- 각 epoch마다 평가 지표를 초기화해서 이전 epoch 때의 값이 누적되어 다음 epoch 때 영향을 미치지 않도록 평가지표에 reset_states( ) 메서드로 초기화한다.
'텐서플로' 카테고리의 다른 글
| 임베딩(Embedding) 순환신경망(Recurrent Neural Network, RNN) (0) | 2025.01.21 |
|---|---|
| 텐서플로 합성곱 신경망(CNN) (2) (0) | 2024.11.22 |
| 텐서플로 합성곱 신경망(CNN) (1) (0) | 2024.11.15 |
| 케라스(Keras) (1) (0) | 2024.08.18 |
| 텐서(Tensor) (1) (0) | 2024.08.10 |



