3. LLM-based Autonomous Agent Evaluation
■ LLM 자체를 평가하는 것은 매우 까다로운 작업이다. LLM-based autonomous agent를 평가하는 것도 마찬가지이다.
■ 이 섹션에서는 널리 사용되는 두 가지 평가 방식, 주관적 방법과 객관적 방법에 대해 설명한다.
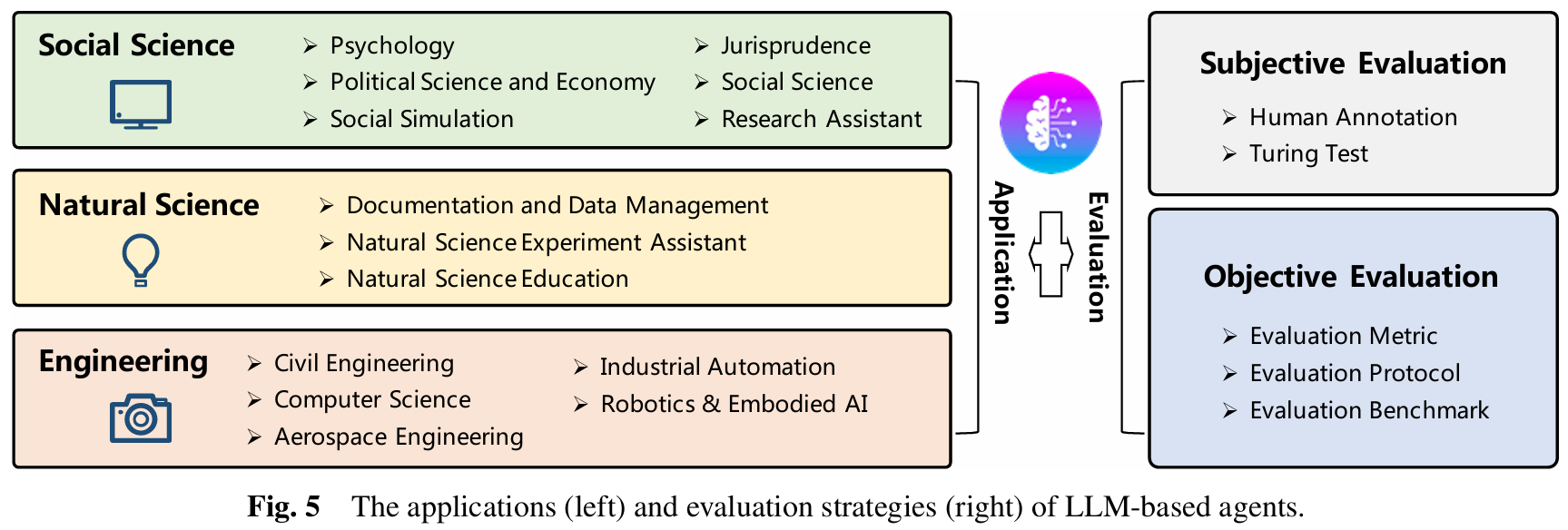
3.1 Subjective Evaluation
■ 모델의 성능은 항상 숫자로 측정할 수 있는 것이 아니다. 예를 들어 에이전트의 '지능'이나 '사용자 친화성'을 평가하는 경우 정답 라벨이나 단순 정확도로 평가하기 어렵다.
■ 이렇게 정량적인 지표를 설계하기 매우 어렵거나 평가용 데이터셋이 존재하지 않는 경우에는 subjective evaluation이 필요하다. 일반적으로 널리 사용되는 두 가지 방법은 다음과 같다.
Human Annotation
■ 이 방법은 human evaluators이 에이전트가 만든 결과에 직접 점수를 매기거나 순위를 매기는 방식이다.
■ Generative Agents에서는 수많은 annotators을 참여시켜 에이전트의 능력과 직결되는 5가지 영역에 대해 총 25개 질문을 던져 평가하게 했다.
Turing Test
■ 이 방법은 human evaluators에게, 주어진 결과가 인간이 만든 것인지, 아니면 에이전트가 만든 것인지를 구별하도록 한다.
■ human evaluators이 이 둘을 잘 구별하지 못한다면, 이는 해당 task에서 에이전트가 human-like의 성능을 달성할 수 있음을 증명하는 것이다.
■ LLM-based agents은 보통 인간을 위해 설계되므로, subjective evaluation은 인간의 기준을 온전히 반영하기 때문에 매우 중요한 역할을 한다.
■ 그러나 이런 평가는 높은 비용, 비효율성, 인구통계학적 편향과 같은 단점들이 있다. 이러한 문제들을 해결하기 위해, evaluator로 LLM을 사용하는 연구들이 증가하고 있다.
■ ChemCrow에서는 GPT를 사용하여 실험 결과를 평가하고, ChatEval은 여러 에이전트가 토론 형식으로 후보 결과를 평가한다.
3.2 Objective Evaluation
■ objective evaluation은 정량적 지표를 사용하여 모델의 능력을 평가하는 것을 의미한다.
■ subjective evaluation과 대조적으로 objective evaluation은 에이전트의 성능을 구체적이고 측정 가능한 지표를 통해 평가한다.
■ objective evaluation을 수행하기 위해서는 metrics, protocols 그리고 benchmarks가 필요하다.
Metrics
■ 에이전트의 성능을 객관적으로 평가하기 위해서는 적절한 지표를 설계하는 것이 매우 중요하며, 이는 평가의 정확성에 큰 영향을 미칠 수 있다.
■ 이상적인 평가 지표는 에이전트의 품질을 정밀하게 반영해야 하며, 실제 시나리오에서 인간이 에이전트를 사용할 때 느끼는 체감과도 align되어야 한다. 대표적인 평가 지표 세 가지는 다음과 같다.
(1) Task success metrics
■ 이 지표들은 에이전트가 task를 얼마나 잘 완료하고 목표를 달성했는지를 측정한다. success rate, reward/score, coverage, 그리고 accuracy/error rate가 여기에 포함된다.
(2) Human similarity metrics
■ coherent, fluent, dialogue similarities with human, human acceptance rate 등 인간의 특성과 관련된 다양한 측면을 비교함으로써, 에이전트의 행동이 실제 인간의 행동과 얼마나 밀접하게 닮아 있는지를 측정한다.
■ 유사성이 높을수록 인간 시뮬레이션 성능이 뛰어나다는 것을 시사한다.
(3) Efficiency metrics
■ 위의 두 가지는 에이전트의 'effectiveness'를 평가하는 데 사용되는 지표들이다.
■ 에이전트 개발과 관련된 비용 및 학습 효율성 등은 에이전트의 'efficiency' 평가에 사용된다.
Protocols
■ metrics 외에도 objective evaluation를 위한 또 다른 중요한 측면은 이러한 지표들을 "어떻게 활용할 것인가"이다. 널리 사용되는 평가 프로토콜들은 다음과 같다.
(1) Real-world simulation
■ real-world scenarios을 시뮬레이션함으로써, 에이전트의 실질적인 역량에 대한 평가를 수행한다.
■ 에이전트는 게임이나 대화형 시뮬레이터와 같은 환경 내에서 평가된다.
■ 에이전트는 task를 자율적으로 수행하며, 에이전트의 역량은 trajectories와 완료 결과를 바탕으로 task 성공률 및 human similarity와 같은 지표로 측정한다.
(2) Social evaluation
■ 시뮬레이션된 사회 내에서 에이전트 간의 상호 작용을 기반으로 '사회적 지능'을 평가한다.
■ 협업 task, 토론 등을 통해 coherence, theory of mind, social IQ와 같은 특성들을 분석하여 협력, 의사소통, 공감, 인간의 사회적 행동 모방 등과 같은 영역에서의 능력을 평가한다.
■ 에이전트를 복잡한 상호작용 설정에서 평가함으로써, 에이전트의 사회적 인지 능력을 확인할 수 있다.
(3) Multi-task evaluation
■ 여러 도메인의 다양한 tasks을 사용하여 에이전트의 'generalization 능력'을 평가할 수 있다.
(4) Software testing
■ 에이전트에게 테스트 케이스 생성, 버그 재현, 코드 디버깅, 개발자 및 외부 tools과의 상호작용 등 소프트웨어 테스트와 같은 tasks을 수행하게 함으로써 에이전트를 평가한다.
■ 그런 다음, 테스트 커버리지나 버그 탐지율과 같은 지표를 사용하여 에이전트의 effectiveness를 측정할 수 있다.
Benchmarks
■ metrics과 protocols이 주어졌을 때, 그에 맞는 적절한 벤치마크를 선택해야 한다.
■ 다양한 도메인과 시나리오에 걸쳐 LLM-based agents의 능력을 평가하기 위해 여러 벤치마크들이 도입되었다.
■ 많은 연구들에서 interactive 및 task-oriented simulations에서 에이전트의 능력을 평가하기 위해 ALFWorld, IGLU, 마인크래프트와 같은 환경을 채택한다.
- Tachikuma는 TRPG 게임 로그를 통해 다수의 캐릭터와 새로운 사물이 관련된 복잡한 상호작용을 추론하고 이해하는 LLM의 능력을 평가한다.
- AgentBench는 다양한 환경에 걸쳐 에이전트로서의 LLM을 평가하기 위한 포괄적인 프레임워크를 제공한다.
- SocKET는 유머와 비꼬기, 감정과 느낌, 신뢰성 등 5가지 카테고리를 포함하는 58개 tasks 전반에 걸쳐 LLM의 사회적 능력을 평가하는 벤치마크이다.
- AgentSims는 대화형 환경에서 에이전트의 planning, memory 그리고 action strategies을 유연하게 설계하고 다양한 에이전트 모듈의 효과를 측정한다.
- ToolBench는 LM의 tools 사용 능력을 평가하고 향상시키는 데 초점을 둔다.
- WebShop은 제품 검색 및 검색어 추출 역량 측면에서 LLM-based agent를 평가한다.
- Mobile-Env는 LLM-based agent의 multi-step interaction capabilities을 평가하도록 설계된 interactive platform 역할을 한다.
- WebArena는 여러 도메인의 웹사이트 환경을 제공한다. 에이전트를 end-to-end 방식으로 평가하고, 에이전트가 완료한 task의 정확도를 측정한다.
- GentBench는 복잡한 task를 완료하기 위해 tools을 활용할 때의 추론, safety 및 efficiency를 포함한 에이전트의 역량을 평가하도록 제작되었다.
- RocoBench는 다양한 시나리오에 걸쳐 multi-agent의 협업을 평가하는 6가지 tasks로 구성되어 있다.
- EmotionBench는 즉 특정 상황이 주어졌을 때, 모델의 기분이 어떻게 변하는지를 평가한다.
- PEB는 모의 해킹 시나리오에서 에이전트를 평가하는 데 맞춤화되어 있다.
- ClemBench는 플레이어로서의 LLM 능력을 평가하기 위해 5개의 Dialogue Games을 포함하고 있다.
- E2E는 챗봇의 정확도와 유용성을 테스트한다.
■ objective evaluation은 다양한 지표를 통해 LLM-based agents의 역량에 대한 정량적 분석을 한다.
■ 모든 유형의 에이전트 능력을 완벽하게 측정할 수는 없지만, objective evaluation는 subjective evaluation를 보완하는 역할을 할 수 있다.
■ objective evaluation과 subjective evaluation는 각각 장점과 단점을 가지고 있다. 그래서 에이전트를 포괄적으로 평가하기 위해선 이 두 가지 평가를 같이 사용하는 것이 바람직하다.
4. Challenges
■ LLM-based autonomous agent가 해결해야 할 한계들은 다음과 같다.
4.1 Role-playing Capability
■ 다양한 tasks을 해결하기 위해 specific roles(예: 프로그래머, 연구원 등)을 수행해야 한다는 점에서 autonomous agent는 전통적인 LLM과 다르다. 즉, 에이전트는 role-playing 능력이 매우 중요하다.
■ LLM은 영화 평론가와 같은 흔한 역할들은 잘 시뮬레이션할 수 있지만, 여전히 어려움을 겪는 역할들과 측면들이 존재한다.
■ LLM은 보통 web corpus를 기반으로 학습되므로, 웹에서 거의 다뤄지지 않는 드문 역할이나, 최근에 새롭게 등장한 역할은 제대로 시뮬레이션하지 못할 수 있다.
■ 그리고 기존 LLM은 인간의 심리학적 특성을 잘 모델링하지 못할 수 있다는 연구도 있다. 이는 대화 시나리오에서 self-awareness의 결여로 이어진다.
■ 이러한 문제들에 대한 해결책으로는 LLM을 파인튜닝하거나 에이전트의 프롬프트/아키텍처를 정교하게 설계하는 방법이 포함될 수 있다.
■ 예를 들어, 흔치 않은 역할이나 심리학적 특성에 대한 실제 인간의 데이터를 먼저 수집한 다음, 이를 활용하여 LLM을 파인튜닝하는 것이다.
■ 그러나 특정 역할로 파인튜닝된 모델이 기존의 흔한 역할들에 대해서도 여전히 좋은 성능을 발휘할지는 또 다른 문제이다.
■ 파인튜닝 외에도 tailored agent 프롬프트/아키텍처를 설계하여 LLM의 role-playing 능력을 향상시킬 수 있다.
■ 그러나 프롬프트와 아키텍처는 설계 공간이 너무 크기 때문에, 최적의 프롬프트와 아키텍처를 찾는 것은 쉽지 않다.
4.2 Generalized Human Alignment
■ 저자들은 LLM-based autonomous agent 분야, 특히 에이전트가 시뮬레이션에 활용되는 경우 human alignment가 더욱 중요하다고 주장한다.
■ 전통적인 LLM은 일반적으로 올바른 인간의 가치관과 정렬되도록 파인튜닝된다.
■ 그런데 에이전트를 사회 시뮬레이션에 쓰려면, 현실의 인간이 가진 다양한 성향, 심지어 바람직하지 않은 성향까지도 어느 정도 재현할 수 있어야 한다.
■ 왜냐하면 시뮬레이션의 중요한 목표는 현실의 문제를 발견하고 대응책을 찾는 것이기 때문이다.
■ 부정적인 측면이 전혀 없다는 것은 곧 해결할 문제도 없다는 것을 의미하기 때문에, 인간의 부정적인 측면을 시뮬레이션하는 것이 오히려 훨씬 더 중요할 수 있다.
■ 저자들은 'generalized human alignment'란 용도와 맥락에 따라, 선과 악을 포함한 다양한 인간의 가치관과 정렬되는 것이라고 설명한다.
■ 그러나 ChatGPT 및 GPT-4를 포함한 기존의 강력한 LLM들은 대부분 하나의 인간 가치(대체로 선)에만 정렬되어 있다.
■ 따라서 앞으로의 과제는 이러한 모델을 어떻게 realign하여, 상황에 따라 서로 다른 가치관을 표현할 수 있도록 만들 것인가에 있다고 저자들은 주장한다.
4.3 Prompt Robustness
■ 에이전트가 합리적으로 행동하도록 유도하기 위해, LLM에 memory 및 planning modules과 같은 보조 모듈을 사용하고 있다.
■ 그러나 이러한 모듈들을 포함하게 되면, 일관된 액션과 의사소통을 위해 훨씬 더 복잡한 프롬프트를 개발해야만 한다. 모든 모듈이 함께 작동하도록 만들어야 하기 때문이다.
■ 이전 연구들에서는 사소한 단어 변경만으로도 완전히 다른 결과를 낳을 수 있다는 점에서 프롬프트의 robustness가 부족하다고 지적해 왔다. 이 문제는 autonomous agent를 구축할 때 더욱 두드러진다.
■ 왜냐하면 에이전트는 하나의 프롬프트가 아니라 모든 모듈을 엮어놓은 프롬프트 체계를 쓰기 때문에, 하나의 모듈에 들어가는 프롬프트가 다른 모듈의 프롬프트 결과에 잠재적인 영향을 미칠 수 있다.
■ 게다가 LLM마다 프롬프트를 사용했을 때의 성능이 다를 수 있다.
■ 그러므로 다양한 LLM에 공통적으로 적용할 수 있는, 통일되고 견고한 프롬프트 프레임워크를 만드는 것이 중요하다.
■ 저자들은 잠재적인 해결책으로 두 가지를 제시한다: (1) 시행착오를 통해 핵심 프롬프트 요소를 사람이 직접 설계하거나 (2) GPT를 사용하여 프롬프트를 자동 생성해서 최적의 프롬프트를 찾는 것이다.
4.4 Hallucination
■ hallucination은 LLM이 가지는 근본적인 문제로, 모델이 높은 확신을 가지고 거짓 정보를 진실인 것처럼 생성하는 것을 말한다. 이 문제는 autonomous agent에서도 심각한 문제이다.
■ 예를 들어, 코드 생성 중 지나치게 단순한 명령을 받았을 때 에이전트가 환각적인 출력을 보일 수 있음을 관찰한 연구가 있다. 부정확하거나 오해를 일으키는 코드, 보안 위험, 그리고 윤리적 문제를 초래할 수 있음을 보여주었다.
■ 이 문제를 완화하기 위해, 인간-에이전트 상호작용의 반복적인 과정에 human correction feedback을 넣어주는 것이 실현 가능한 접근법으로 제시되고 있다.
4.5 Knowledge Boundary
■ LLM-based autonomous agent의 주된 목표 중 하나는 real-world의 다양한 인간 행동을 시뮬레이션하는 데 있다.
■ LLM은 다양한 소스들로부터 데이터를 수집하여 학습되었기 때문에 보통 인간보다 방대한 knowledge를 가지고 있다. 그러나 이런 LLM의 강력한 힘이 항상 유리한 것만은 아니다.
■ 이상적인 시뮬레이션이라면 일반적인 인간의 지식수준을 정확하게 따라할 수 있어야 한다.
■ 이러한 맥락에서 LLM은 일반인이 알 수 있는 수준을 아득히 초과하는 corpus에서 학습되었기 때문에 인간보다 지나치게 뛰어난 능력을 보일 수 있다.
■ 즉, human simulation에서는 인간이 아는 만큼만 알고 행동하는 것이 중요한 경우가 있는데, LLM의 방대한 knowledge이 오히려 이를 방해한다는 것이다.
■ 예를 들어, 사람은 영화를 보기 전에 내용 전체를 모른다. 그러나 LLM은 이미 그 영화 정보를 알고 있을 수 있고, 자신의 방대한 배경지식을 바탕으로 결정을 내릴 수 있기 때문에 현실 사용자와 다르게 판단할 수 있다.
■ 그래서 저자들은 사용자는 모르지만 LLM은 이미 알고 있는 knowledge의 활용을 어떻게 억제할 것인가도 중요한 문제라고 언급한다.
4.6 Efficiency
■ autoregressive architecture의 LLM들은 단어를 한 번에 하나씩 순차적으로 예측하기 때문에 일반적으로 inference speed가 느리다.
■ 그러나 에이전트는 memory에서 정보를 추출하거나, 액션을 취하기 전에 plan을 세우는 등 단 하나의 액션을 취하기 위해서도 백그라운드에서 LLM에 여러 번 생성을 요청해야 할 수 있다.
■ 결과적으로 에이전트의 전체적인 효율성은 LLM의 근본적인 inference speed에 큰 영향을 받는다.
'Agent' 카테고리의 다른 글
| A Survey on Large Language Model based Autonomous Agents (1) (0) | 2026.04.07 |
|---|
