1. 시퀀스 투 시퀀스(Sequence toSequence, seq2seq)
■ 시퀀스 투 시퀀스(Sequence toSequence, seq2seq)는 어떤 시계열 데이터를 다른 시계열 데이터로 변환하는 신경망 모델로, 모델의 아키텍처는 RNN(또는 LSTM이나 GRU)셀을 가지고 있는 인코더-디코더(Encoder-Decoder)로 구성되어 있다.
- seq2seq 모델은 대표적으로 번역기, STT(Speech to Text) 등에서 사용된다.
cf) 시계열 데이터(시간의 흐름에 따라 기록된 데이터)는 시퀀스 데이터의 대표적인 데이터이다.
- 텍스트는 작은 단위라고 할 수 있는 다양한 길이의 단어들이 순서대로 연결된 어떤 문장 혹은 문단으로 볼 수 있다.
- 이렇게 순서대로 정렬되어 연속적으로 나타나는 데이터를 시퀀스 데이터라고 한다.
- 텍스트, 오디오, 시계열 같은 데이터가 시퀀스 데이터라고 할 수 있다.
1.1 seq2seq 모델의 개요 - Encoder
■ 다음 그림은 '나는 학생이다.'라는 한글 문장을 입력 받아, 'I am a student'라는 영어 문장을 출력하는 seq2seq의 예이다

- 이렇게 seq2seq는 인코더와 디코더로 구성된 아키텍처이다.
■ 예를 들어, 문장을 단어 단위로 seq2seq의 인코더에 순차적으로 입력한다면, 이때의 인코더 내부 모습은 다음과 같다.

■ 위와 같이 seq2seq의 인코더는 매 시점 순서대로 단어를 입력으로 받는다.
- '나는 학생이다'라는 문장을 단어(토큰) 단위로 나눈 다음, 단어가 등장하는(연결되는) 순서대로 '나', '는', '학생', '이다'라는 단어를 Encoder에 입력한다.
■ 이렇게 입력받은 단어를 임베딩 벡터로 변환한 다음, 단어의 임베딩 벡터를 RNN(또는 LSTM이나 GRU)셀에 전달한다.
- 단어(토큰)은 Embedding 계층(layer)에 입력되면, 토큰은 밀집 벡터(dense vector)인 임베딩 벡터로 변환된다.
- RNN 계층(이 예에서는 LSTM 계층)은 이러한 임베딩 벡터를 입력으로 받는다.
■ RNN셀들이 모두 순차적으로 연결되어 있으며, 입력으로 받은 단어의 임베딩 벡터를 이용하여 계산한다. 그리고 마지막 시점의 RNN 셀은 \( h \)라는 최종 결과를 산출한다.
■ 산출된 Encoder의 결과인 \( h \)는 어떤 정보를 가지고 Decoder에 전달된다.
■ 이 예에서 각 시점의 임베딩 벡터를 입력받은 RNN 계층 4개가 계산한 결과를 순서대로 \( h_1, h_2, h_3, h_4 \)라고 하자.
■ \( h_1 \)은 첫 번째 입력인 '나'라는 단어(토큰)의 임베딩 벡터를 LSTM 계층에 입력하여 계산된 출력 값이다.
■ 그렇다면, \( h_1 \)은 '나'라는 단어의 정보를 가지고 있을 것이다.
■ 그리고 첫 번째 시점의 LSTM 계층의 결과인 \( h_1 \)은 다음 시점인 두 번째 시점의 LSTM 계층에 연결된다.
■ 이때, 두 번째 시점의 입력은 첫 번째 시점의 결과인 \( h_1 \)뿐만 아니라 두 번째 시점의 단어에 대한 임베딩 벡터를 입력으로 받는다.
■ 이렇게 두 개의 입력을 이용해 계산된 두 번째 시점의 LSTM 계층 결과 \( h_2 \)는 첫 번째 단어 '나'에 대한 정보가 담겨 있는 \( h_1 \)과 두 번째 단어 '는'에 대한 정보를 가지고 있을 것이다.
■ 세 번째 시점과 마지막 시점의 LSTM 계층도 이전 시점의 LSTM 계층의 결과와 현재 시점의 단어에 대한 임베딩 벡터를 입력으로 받는다.
■ 그렇다면, 각 시점의 결과를 다음과 같이 나타낼 수 있다.
- 첫 번째 시점의 LSTM 계층 결과는 '나'에 대한 정보
- 두 번째 시점의 LSTM 계층 결과는 '나' + '는'에 대한 정보
- 세 번째 시점의 LSTM 계층 결과는 '나' + '는' + '학생'에 대한 정보
- 마지막 시점의 LSTM 계층 결과는 '나'+ '는'+ '학생' + '이다'에 대한 정보를 갖게 된다.
■ 이렇게 시점이 지나갈수록 입력 단어(토큰)에 대한 정보가 누적되면서, 마지막 시점의 LSTM 계층에서는 입력 텍스트의 맥락(문맥)을 하나로 압축하게 된다.(입력 문장의 모든 단어(토큰)들의 정보를 요약해서 담고 있는 상태가 된다.)
■ 그리고 마지막 시점의 LSTM 계층에서는 압축된 정보를 \( h \)라는 이름의 벡터로 Decoder에 전달한다.
■ \( h \)는 모든 단어 정보들을 압축해서 만든 하나의 컨텍스트 벡터(context vector)이며, 은닉 상태(hidden state) 벡터라고 부른다.
■ seq2seq의 인코더에서 발생하는 일을 정리하면,
- 입력 문장을 토큰화해서 얻은 단어(토큰) 각각은 Embedding 계층의 입력으로 들어가서 임베딩 벡터로 변환되고
- 변환된 임베딩 벡터들은 RNN(LSTM, GRU) 셀의 각 시점의 입력이 된다.
- 그리고 RNN 셀의 계산 결과인 각 시점의 은닉 상태 벡터들은 마지막 시점의 은닉 상태 벡터 \( h \)에 압축된다.
- 이 과정을 통해 입력 문장의 맥락이 마지막 시점의 은닉 상태 벡터 \( h \)에 압축된다.
- 그리고 마지막 시점의 은닉 상태 벡터 \( h \)는 Decoder에 전달된다.
- 즉, 모든 입력 단어들의 정보인 입력 문장의 맥락은 하나의 벡터로 압축되어 Decoder로 전달된다.
- 이 예에서는 은닉 상태 벡터 \( h \)에 입력 문장을 번역하는데 필요한 정보가 인코딩되는 것이다.
■ 이때, 은닉 상태 벡터 \( h \)는 입력 데이터(문장)의 길이와 관계없이 항상 동일한 길이를 갖는 고정 길이 벡터이다.
- 예를 들어, '나는 학생이다'라는 문장 다음에 '그래서 내일 학교에 9시까지 도착해야 한다'라는 더 긴 혹은 짧은 문장이
Encoder의 입력으로 돌아가도 모두 동일한 길이의 은닉 상태 벡터 \( h \)로 산출된다.
- 단, 두 문장(혹은 여러 문장)을 미니 배치로 처리할 경우, 패딩(padding)을 통해 두 문장의 길이를 동일하게 맞춰야 할 것이다.
1.2 seq2seq 모델의 개요 - Decoder

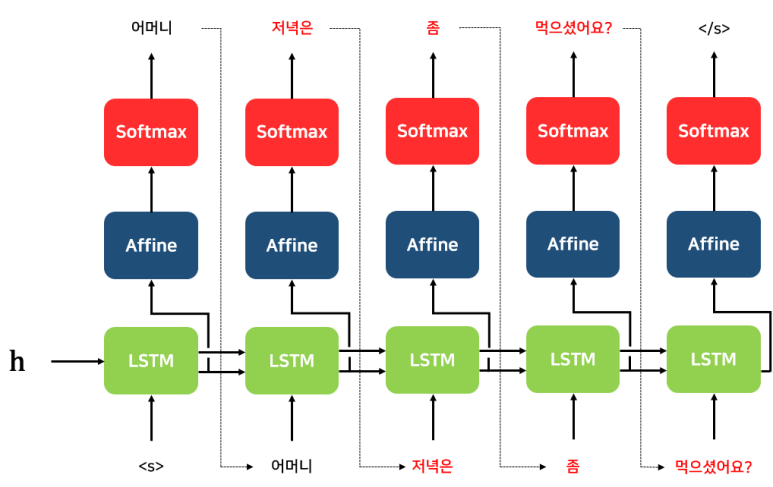
■ 위와 같이 Encoder의 마지막 시점에서 전달된 은닉 상태 벡터 \( h \)는 다음과 같이 디코더 RNN(LSTM, GRU)셀의 첫 번째 은닉 상태의 입력(첫 번째 RNN(LSTM, GRU) 계층의 입력)으로 사용된다.

■ 예시 Decoder의 과정을 보면, 일련의 과정을 거쳐 예시 task의 목적인 한글 단어를 영어 단어로 출력하는 것을 볼 수 있다.
■ 이렇게 seq2seq의 Decoder는 RNN을 이용한 RNNLM. 즉, LM(Language Model)이다. 다시 말해, Decoder에서는 언어 모델링(modeling)을 수행한다.
cf) 언어 모델링이란, 텍스트 데이터를 학습하는 가장 대표적인 방법으로, 모델이 입력받은 텍스트를 기반으로 다음 단어를 예측해 텍스트를 생성하는 방식을 말한다.
- 즉, 언어 모델링은 '텍스트를 생성하는 모델을 학습시키는 방법'이다.
- 이렇게 다음 단어를 예측하는 방식으로 훈련한 모델을 언어 모델(Language Model, LM)이라고 한다.
- 언어 모델링은 위의 Decoder처럼 텍스트를 생성하는 모델을 학습시키는 방법으로도 사용되지만, 대량의 데이터로부터 언어의 특성을 학습하는 사전 학습(pre-training)으로 많이 사용된다.
■ 그리고 seq2seq 'Decoder의 첫 번째 시점 RNN 계층'은 'Encoder에서 전달받은 은닉 상태 벡터 \( h \)'와 'Decoder의 첫 번째 시점의 토큰'을 입력으로 받아서 첫 번째 시점에 나올 단어를 예측하고, 계산된 결과를 다음 시점의 RNN 계층으로 전달한다.
■ 이 예시에서 Decoder의 첫 번째 LSTM 계층은 문장 시작을 의미하는 심볼인 <sos> 토큰의 임베딩 벡터와 Encoder에서 전달한 은닉 상태 벡터 \( h \)를 입력으로 받아 계산한다.
- <sos>와 <eos>는 구분 기호로 사용하는 토큰이다. Decoder의 문장 생성의 시작, 종료를 알리는 구분자로 사용된다.
■ 그리고 계산된 결과(Decoder의 첫 번째 시점의 은닉 상태 벡터)를 현재 시점의 Affine 계층과 다음 시점의 LSTM 계층으로 전달한다.
■ 현재 시점의 Affine 계층은 Decoder의 첫 번째 시점 은닉 상태 벡터를 입력으로 받고, 계산된 결과를 Softmax 계층에
전달한다. 그러면, Softmax 계층에서는 입력된 점수(score)를 기반으로 '다음에 등장할 단어를 확률적으로 예측'한다.
- Decoder는 이렇게 입력(예를 들어 <sos> 토큰)을 받아 다음으로 등장할 단어(예를 들어 'i')를 예측하기 때문에
언어 모델이라고 할 수 있다.
- 출력 결과로 나올 수 있는 단어들은 다양한 단어들이 있을 것이다. 그러므로 선택될 수 있는 모든 단어들로부터 하나의 단어를 선택해야 하므로 소프트맥스 함수를 사용한다.
■ Decoder의 두 번째, 세 번째, ... 시점의 LSTM 계층에서는 이전 시점에서 전달받은 은닉 상태 벡터 \( h_{t-1} \)와 함께 이전 시점에서 예측된 결과를 현재 시점의 입력으로 사용해서 다음에 올 단어를 예측한다.
■ 이 과정을 문장의 문장의 끝을 의미하는 <eos>가 다음에 등장할 단어로 예측할 때까지 반복한다.
- 이 예에서 Decoder의 첫 번째 시점의 결과로 얻은 단어 'I'를 두 번째 시점의 입력으로 사용해서 'I' 다음에 올 단어인 'am'을 예측한다.
- 두 번째 시점의 예측 결과인 단어 'am'은 다시 세 번째 시점의 입력으로 들어가는 것을 볼 수 있다.
- 이러한 과정은 마지막 시점에서 문장 생성의 끝을 의미하는 <eos>가 예측될 때까지 반복하는 것을 볼 수 있다.
■ 사실, 이 과정은 seq2seq의 테스트 과정에서 진행되는 과정에 대한 얘기이다.
■ seq2seq는 훈련 과정과 테스트 과정의 작동 방식이 조금 다르다. 테스트 과정에서는 위와 같이 설명한 단계로 진행되며, 학습 과정에서는 교사 강요(teacher forcing)가 진행된다.
1.2.1 Teacher Forcing
■ teacher forcing은 seq2seq(Encoder-Decoder)을 기반으로 한 모델들에서 실제 정답인 target word(ground-truth)를 Decoder의 다음 입력으로 사용하여 RNN이 실제 정답 시퀀스에 가깝게 유지되도록 강제하는 기법이다.
■ teacher forcing을 적용하지 않은 seq2seq 모델은 테스트 과정에서 이전 시점인 \( t - 1 \) 시점에서 예측한 결과(단어)를 현재 시점 \( t \) 시점의 입력으로 사용한다.
■ 이때, 이전 시점의 예측 결과가 정확하다면 문제가 되지 않지만, 잘못된 예측 결과일 경우, 문장의 맥락을 담고 있는 은닉 상태는 잘못된 예측값이 희석되어 업데이트되므로 Decoder는 \( t \) 시점에서 잘못된 단어를 예측할 것이다.
■ 이로 인해 전체적으로 잘못된 시퀀스를 예측하게 되며, 이전 시점의 예측 결과를 고려하여 예측하는 Decoder의 장점이 오히려 단점으로 작용하는 상황이 된다.
■ 이러한 단점을 해결하기 위해 나온 기법이 teacher forcing이다. teacher forcing은 훈련 과정에서 RNN에 실제 정답(ground-truth)을 다시 공급한다.
■ 예를 들어, 훈련 과정에서 Encoder가 보낸 은닉 상태 벡터 \( h \)와 함께 실제 정답인 <sos> I am a student를 입력으로 받았을 때, I am a student <eos>가 나와야 된다고 Decoder에게 정답을 알려주면서 훈련한다.
■ teacher forcing은 여러 파트로 구성된 시험을 치르는 학생에 비유하여 설명할 수 있다.
■ 여기서 각 파트의 답은 이전 파트의 답에 의존한다고 했을 때, (수학 문제처럼 최종 답을 얻기 위해 각 파트에서 어떤 값을 구해야 하는 문제)
■ 교사는 모든 파트의 답을 한꺼번에 채점해서 점수를 알려주지 않고, 각 개별 파트에 대한 점수를 기록한 후 학생에게 다음 파트에서 사용할 정답을 알려준다.
■ 예를 들어, A B C D E 라는 연속된 단어들로 이루어진 문장을 생성할 때, 모델이 A 다음에 올 B 단어를 제대로 예측하지 못했을 때, 다음 입력으로 A B를 강제로 주어 C를 예측하도록 학습시키는 것이다.

- 위의 그림은 teacher forcing을 사용하지 않은 경우와 사용한 경우의 차이에 대한 예시이다.
- teacher forcing을 사용하지 않은 경우 왼쪽 그림과 같이 이전 단계에서 잘못된 예측 결과가 발생하면, 이후 단계에서도 연쇄적으로 잘못된 예측을 도출할 수 있다.
- 하지만, 오른쪽 그림처럼 teacher forcing을 사용하면, 잘못된 예측 결과를 도출했을 때, 이전 단계의 잘못된 예측값 대신 실제 정답(ground truth)을 다음 단계의 입력으로 사용하게 된다.
1.3 seq2seq 모델의 개요 - Encoder - Decoder
■ 예시에서 사용한 Encoder와 Decoder가 연결된 구조. 즉, seq2seq의 전체 구조는 다음과 같다.

■ 위의 구조를 보면, \( h \)가 Encoder와 Decoder를 연결하는 것을 볼 수 있다.
■ 순전파 과정에서는 Encoder에서 출력된 \( h \)가 Decoder에 전달되고, 역전파 과정에서는 기울기가 Decoder로부터 \( h \)를 통해 Encoder로 전달된다.
■ 위의 예시는 단어 단위로 분할해서 입력 데이터로 사용한 예시이다. 문장을 반드시 '단어' 단위로 분할해야 하는 것은 아니다. '문자' 단위로 분할해서 입력으로 사용해도 된다.
■ 이 예시에서는 Encoder의 최종 은닉 상태 벡터 \( h \)를 Decoder의 초기 은닉 상태로만 사용했지만, \( h \)를 Decoder의 모든 시점마다 하나의 입력으로 사용할 수 있게 Decoder를 만들 수 있다. 이러한 Decoder를 Peeky Decoder라고 한다.
참고) 시퀀스 투 시퀀스(Sequence toSequence, seq2seq)
시퀀스 투 시퀀스(Sequence toSequence, seq2seq)
1. seq2seq■ seq2seq는 한 시계열 데이터를 다른 시계열 데이터로 변환하는 신경망 모델로 '인코더-디코더(Encoder-Decoder)' 모델이라는 신경망 모델의 일종이다.■ Encoder-Decoder 모델은 입력 데이터를 인
hyeon-jae.tistory.com
참고) A ten-minute introduction to sequence-to-sequence learning in Keras
A ten-minute introduction to sequence-to-sequence learning in Keras
Fri 29 September 2017 By Francois Chollet In Tutorials. Note: this post is from 2017. See this tutorial for an up-to-date version of the code used here. I see this question a lot -- how to implement RNN sequence-to-sequence learning in Keras? Here is a sho
blog.keras.io
'자연어처리' 카테고리의 다른 글
| RNN (2) (0) | 2025.03.26 |
|---|---|
| RNN (1) (1) | 2025.03.23 |
| Subword Tokenizer - (3) Unigram Tokenization (0) | 2025.03.17 |
| Subword Tokenizer - (2) WordPiece Tokenization (0) | 2025.03.16 |
| Subword Tokenizer - (1) Byte Pair Encoding(BPE) Tokenization (0) | 2025.03.15 |