3. Unigram Tokenizer
■ 유니그램 토큰화(unigram tokenization)은 BPE, WordPiece와 같은 하위 단어 토큰화(subword tokenization) 방법이다. 단, Unigram은 BPE 및 WordPiece와 다른 방향으로 작동한다.
- Unigram과 BPE/WordPiece의 주요 차이점은 다음과 같다.

3.1 Unigram 알고리즘 과정
■ BPE나 WordPiece가 크기가 작은 단어 집합(vocabulary)에서 시작하여 토큰을 추가하는 것과 달리, Unigram은 크기가 큰 단어 집합에서 시작하여 원하는 단어 집합 크기에 도달할 때까지 불필요한 토큰을 제거한다.
- Unigram에서 초기 단어 집합을 만드는 방법으로 사전 토큰화(pre-tokenization)된 단어에서 부분 문자열을 취하거나, 큰 규모의 단어 집합을 가진 초기 말뭉치에 BPE를 적용하는 방법이 있다.
■ Unigram에서 불필요한 토큰의 기준은 유니그램 토크나이저(unigram tokenizer)가 각각의 하위 단어(subword)들에 대해 계산한 손실(loss)값을 기준으로 한다.
■ 여기서 하위 단어(subword)의 손실(loss)이라는 것은, 단어 집합(vocabulary)에서 하위 단어(subword)가 제거되었을 경우, 말뭉치의 우도(likelihood)가 감소하는 정도를 말한다.
■ Unigram 알고리즘에서 손실 계산은, 학습의 각 단계에서 현재 단어 집합이 주어졌을 때 말뭉치에 대한 손실(loss)을 계산한 다음, 단어 집합 내 각 하위 단어에 대해, 해당 하위 단어가 제거될 경우 전체 손실이 얼마나 증가하는지 계산하고 가장 적게 증가하는 하위 단어를 찾는다.
■ 이렇게 찾은 하위 단어들은 말뭉치에 대한 전체 손실에 미치는 영향이 상대적으로 적기 때문에, 어떤 의미에서는 '덜 필요(less needed)'하다고 볼 수 있다. 즉, 제거 대상으로 가장 적합한 후보이다. 이러한 하위 단어들의 \( p \; \text{%} \) (\( p \)는 하이퍼파라미터, 일반적으로 10 또는 20으로 지정)를 제거한다.
■ 이렇게 계산한 하위 단어들의 손실의 정도를 정렬하여, 보통 손실값에 최악의 영향을 주는 10~20%의 토큰을 제거한다. 이를 사용자가 원하는 단어 집합의 크기에 도달할 때까지 반복한다.
■ 단, 모든 단어를 토큰화할 수 있도록 기본 문자(character)들을 제거하지 않는다는 점도 중요하다.
- 모든 단어를 토큰화할 수 있도록 기본 문자(character)들을 제거하지 않는다는 점도 중요하다.에서 기본 문자는 길이가 1인 하위 단어를 의미한다.
- 예를 들어, 기본 문자인 'i'가 'ill'의 토큰화에 사용된다고 했을 때, 길이가 1인 i라는 토큰을 제거하면 ill을 만들 수 없으므로 추가적인 손실이 발생할 수 있기 때문에 기본 문자들을 제거하지 않는다.
■ 정리하면, 이 알고리즘의 핵심은 말뭉치에 대한 손실을 계산하고, 단어 집합(vocabulary)에서 일부 불필요한 토큰을 제거할 때 손실이 어떻게 변하는지 확인하는 것이다.
■ 예를 들어, 말뭉치 데이터가 다음과 같이 구성되어 있다고 가정하자.
low low low low low lower lower
newest newest newest newest
newest newest widest widest widest■ 우선, 말뭉치 데이터에 사전 토큰화(pre-tokenization)를 통해 단어 단위로 모두 분절한다. 그리고 각 단어별로 다시 부분 문자(열)로 모두 분절시켜서 초기 단어 집합(vocabulary)를 구축한다. 이때 단어 집합의 value는 다음과 같이 빈도수이다.
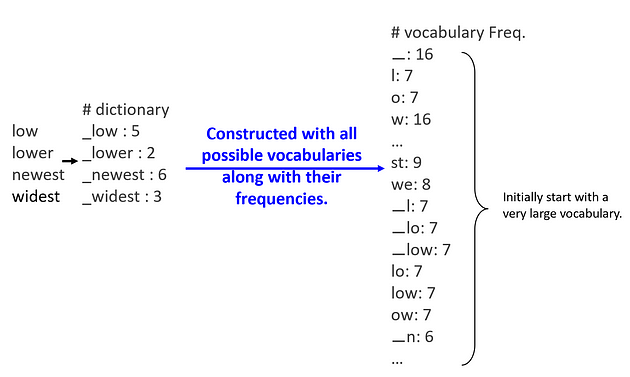
■ 위의 그림처럼 가능한 모든 조합을 단어 집합(vocabulary)에 등록하기 때문에, 초기 단어 집합의 크기는 메우 큰 상태에서 시작한다.
■ 이렇게 모든 토큰(하위 단어들=각 문자들의 모든 조합)들의 빈도수를 통해 특정 토큰의 확률을 계산할 수 있다.
■ 확률을 계산하는 방법은 말뭉치 내에서의 해당 토큰의 출현 빈도를 단어 집합에 조재하는 모든 토큰들의 출현 빈도의 합으로 나누는 것이다.

이렇게 하면 모든 확률의 합이 1이 된다.
■ 예를 들어, 'low'라는 단어 안에서 조합 가능한 부분 문자들에 대한 확률을 계산하면 다음과 같다고 하자.

■ 이렇게 확률이 각 토큰의 확률의 곱으로 계산되는 이유는 Unigram 모델은 각 토큰들의 출현 분포가 서로 독립적(i.i.d)이라는 가정을 하기 때문이다.(특정 토큰 X의 확률은 문맥에 상관없이 동일하다.)
■ 다시 말해, 모든 토큰의 출현 빈도가 독립적인 것으로 간주되기 때문에 \( P([l, o, w]) \)의 확률은 각 토큰의 확률의 곱으로 계산된다.
- Unigram 모델은 각 토큰들의 출현 분포가 서로 독립이라고 가정하기 때문에 다음과 같이 '전체 문장에서 각 단어가 몇 번씩 등장했는지에 대해 독립적으로' 확률을 계산한다.

■ 예시 결과를 보면, 확률 \( P([l, o, w]) \)가 확률 \( P([lo, w]) \), \( P([l, ow]) \)보다 값이 낮은 것을 볼 수 있다. 즉, ['l', 'o', 'w']보다 ['lo', 'w']나 ['l', 'ow']가 훨씬 더 자주 등장한다고 볼 수 있다.
- 이렇게 되는 이유는 \( P([l, o, w]) \) 은 3개의 하위 토큰으로, \( P([lo, w]) \), \( P([l, ow]) \)는 2개의 하위 토큰으로 구성되었을 때의 확률값이기 때문이다.
- 즉, 가장 적은 수의 하위 토큰들로 구성된 토큰화 결과는 비교적 높은 확률을 가진다. 모든 토큰들의 출현 빈도의 합(이 예에서는 344)을 각 하위 토큰에 대해 반복적으로 나누기 때문이다.
-- 이 예에서 \( P([l, o, w]) \)은 모든 토큰들의 출현 빈도의 합인 344를 3번 나눈다. 그러나 \( P([lo, w]) \)나 \( P([l, ow]) \)는 344를 2번 나눈다.
■ Unigram 모델에서 단어의 토큰화는 가장 높은 확률을 나타내는 분할 형태로 토큰화된다.
- 그러므로 이 예에서 단어 'low'는 ['lo', 'w']으로 토큰화된다.
■ 이렇게 계산된 확률값을 이용하여, 손실(loss)을 계산해서 학습 과정에서 단어 집합 내 불필요한 토큰들을 제거해 나간다.
여기서의 손실 값은 말뭉치의 '그럴듯함(Likelihood)'에 기반해서 계산된다.
- 우도(likelihood)는 다음과 같이 말뭉치에 있는 모든 단어의 확률의 합계이다.
- \( w_i \)는 \( i \)번째 단어로, \( P(w_i) \)는 단어 \( w_i \)의 확률이다.

■ 여기서 사용되는 아이디어는 [A, B, C] 조합으로 말뭉치 전체의 확률값을 계산했을 때와 [AB, C] 조합으로 말뭉치 전체의 확률값을 계산했을 때 [AB, C] 조합이 더 높은 그럴듯함을 가진다면, [A, B, C]라는 조합은 탈락시키겠다는 아이디어이다.
■ Unigram에서 사용되는 손실은 '음의 로그 우도(Negative Log-likelihood)'이다. 음의 로그 우도는 다음과 같이 우도를 로그 변환한 뒤, 음수를 취한 값이다.

즉, 말뭉치에 있는 모든 단어의 \( - \log (P(word)) \)의 합계이다.
■ Unigram에서 손실은 \( - \log (P(word)) \)와 단어의 해당 단어의 빈도수의 곱의 합으로 계산된다. 그리고 계산된 총 손실(전체 말뭉치에 대한 손실)을 기준으로, 제거했을 때 손실 증가량이 가장 작은 토큰부터 제거한다.
■ 특정 토큰을 제거했을 때, 손실의 증가량이 작다는 것은 해당 토큰을 제거해도 말뭉치 표현에 미치는 영향이 적다는 것으로 볼 수 있다. 그러므로 이러한 토큰들을 불필요한 토큰으로 간주할 수 있다.
■ 이러한 방식으로 불필요한 토큰들을 초기 단어 집합에서 제거하여 단어 집합의 크기를 줄여나간다.
3.2 Unigram 구현
■ 예를 들어 말뭉치가 다음과 같다고 하자.
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]3.2.1 사전 토큰화(pre-tokenization) 및 빈도수 계산
■ BPE, WordPiece와 마찬가지로 먼저 말뭉치에서 사전 토큰화(pre-tokenization)을 수행한 다음, 각 단어의 출현 빈도를 계산한다.
from transformers import AutoTokenizer
# load the BERT Tokenizer for pre-tokenization
tokenizer = AutoTokenizer.from_pretrained('xlnet-base-cased')- 이 예에서는 'xlnet-base-cased'를 모델로 사용하였다.
from collections import defaultdict
word_freqs = defaultdict(int)
for text in corpus:
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
word_freqs[word] += 1
word_freqs
```#결과#```
defaultdict(int,
{'▁This': 3,
'▁is': 2,
'▁the': 1,
'▁Hugging': 1,
'▁Face': 1,
'▁Course.': 1,
'▁chapter': 1,
'▁about': 1,
'▁tokenization.': 1,
'▁section': 1,
'▁shows': 1,
'▁several': 1,
'▁tokenizer': 1,
'▁algorithms.': 1,
'▁Hopefully,': 1,
'▁you': 1,
'▁will': 1,
'▁be': 1,
'▁able': 1,
'▁to': 1,
'▁understand': 1,
'▁how': 1,
'▁they': 1,
'▁are': 1,
'▁trained': 1,
'▁and': 1,
'▁generate': 1,
'▁tokens.': 1})
````````````3.2.2 Unigram 모델 학습
3.2.2.1 초기 단어 집합(vocabulary) 생성
■ Unigram의 핵심은 말뭉치에 있는 단어로부터 모든 가능한 조합(길이가 1인 기본 문자(character)부터 단어 내의 부분 문자)과 해당 조합의 빈도수로 초기 단어 집합을 생성한 다음, 빈도수를 기반으로 계산되는 손실을 기준으로 단어집합 내 불필요한 토큰들을 제거하는 것이다.
■ 그러므로 다음과 같이 기본 문자(character)를 저장한 char_freqs와 말뭉치에 있는 단어 안에 존재할 수 있는 하위 단어의 조합(길이가 2인 부분 문자들부터 포함되어 있음)들을 저장한 subwords_freqs를 합쳐야 한다.
char_freqs = defaultdict(int)
subwords_freqs = defaultdict(int)
for word, freq in word_freqs.items():
for i in range(len(word)):
char_freqs[word[i]] += freq
# 적어도 길이가 2 이상인 subword들을 추가
for j in range(i + 2, len(word) + 1):
subwords_freqs[word[i:j]] += freq # 말뭉치에 있는 각 단어를 가능한 모든 조합으로 분절■ Unigram 토큰화의 가장 큰 특징 2가지가 있는데 그 중 하나가 바로 이렇게 '어느 정도 분절된 상태(위의 word_freqs)에서 시작'하여 '작은 단위(char_freqs, subwords_freqs 또는 sorted_subwords)로 자른 것을 사용'하는 것이다.
# Vocabulary for all Chartacter
print(f'Chartacter: {char_freqs.items()}')
print()
# Vocabulary for all possible cases
print(f'Subwords: {sorted_subwords[:10]}')
```#결과#```
Chartacter: dict_items([('▁', 31), ('T', 3), ('h', 9), ('i', 13), ('s', 13), ('t', 14), ('e', 21), ('H', 2), ('u', 6), ('g', 5), ('n', 11), ('F', 1), ('a', 12), ('c', 3), ('C', 1), ('o', 13), ('r', 9), ('.', 4), ('p', 2), ('b', 3), ('k', 3), ('z', 2), ('w', 3), ('v', 1), ('l', 7), ('m', 1), ('f', 1), ('y', 3), (',', 1), ('d', 4)])
Subwords: [('▁t', 7), ('is', 5), ('er', 5), ('▁a', 5), ('▁to', 4), ('to', 4), ('en', 4), ('▁T', 3), ('▁Th', 3), ('▁Thi', 3)]
````````````■ 이때, 초기 단어 집합의 크기를 사용자가 원하는 크기로 제한하고 싶다면, subwords_freqs에서 빈도수가 낮은 토큰들을 제외하고 합치면 된다.
- 빈도수가 낮다는 것은 말뭉치에서 거의 등장하지 않는다는 것이다. 말뭉치에서 해당 토큰이 중요하지 않을 가능성이 크다.
■ 이 예에서는 초기 단어 집합의 크기를 300으로 만들기 위해 다음과 같이 빈도수를 기준으로 내림차순 정렬한 sorted_subwords을 만들고
## key = lambda item: item[1], -> value를 기준으로 정렬. 여기서의 value는 빈도수
sorted_subwords = sorted(subwords_freqs.items(), key = lambda item: item[1], reverse = True)
len(sorted_subwords)
```#결과#```
564
````````````■ 기본 문자(char_freqs)와 빈도수를 기준으로 내림차순 정렬된 sorted_subwords 중에서 빈도수가 높은 하위 단어들을 선택하여 다음과 같이 초기 단어 집합을 생성한다.
token_freqs = list(char_freqs.items()) + sorted_subwords[ : 300 - len(char_freqs)]
token_freqs = {token: freq for token, freq in token_freqs}
len(token_freqs)
```#결과#```
300
````````````
## 확인
sorted_token_freqs = sorted(token_freqs.items(), key = lambda item: item[1], reverse = True)
sorted_token_freqs
```#결과#```
[('▁', 31),
('e', 21),
('t', 14),
('i', 13),
...,
('er', 5),
('▁a', 5),
('.', 4),
('d', 4),
('▁to', 4),
('to', 4),
...,
('sever', 1),
('severa', 1),
('several', 1)]
````````````3.2.2.2 손실 계산 및 단어 집합 최적화
■ 위의 초기 단어 집합을 보면, 어떤 문자(chartacter)는 하위 단어의 조합보다 많이 나타나기도 하고, (예를 들어 'e'와 'to')
반대로 어떤 문자는 하위 단어의 조합보다 훨씬 적게 나타나기도 하는 것을 볼 수 있다. (예를 들어 'er'과 'd')
■ 그러므로 어떤 기준을 통해 불필요한 단어(토큰)을 제거해야 하며, Unigram에서 그 기준은 손실(loss)값이다. 전체 말뭉치에 대한 손실의 증가가 가장 작은 토큰부터 제거한다.
■ 여기서의 손실은 위의 예시에서 본 것처럼, 단어의 확률과 음의 로그 우도를 이용하여 계산한다. 구체적인 방법은 다음과 같다.
■ 먼저, 여기서 사용하는 확률은 분자가 말뭉치라는 공간에 있는 \( i \) 번째 조합의 빈도수이며, 분모는 말뭉치에 있는 모든 조합의 빈도수 총합이다.
- 이렇게 확률을 계산하기 때문에 표본공간의 확률이 1이 되는 것이다.
■ \( i \) 번째 단어(토큰)의 확률을 \( p_i \)라고 하자. Unigram에서는 여기에 음의 로그를 씌운다. \( - \log p_i \)
음의 로그를 씌우는 이유는 작은 숫자를 곱하는 것보다 로그를 더하는 것이 수치적으로 더 안정적이기 때문이다.
■ 그다음, \( - \log p_i \)에 \( i \) 번째 토큰의 빈도수를 곱한다. \( i \) 번째 토큰의 빈도수를 \( f_i \)라고 하면, 식은 \( f_i \cdot - \log p_i \)이 된다.
■ 단, \( f_i \cdot - \log p_i \)는 \( i \) 번째 토큰에 대한 식이다. 토큰의 개수가 \( n \) 개라면 손실 함수는 다음과 같이 정의된다.

- 여기서 i는 각 토큰을 나타내는 인덱스
- n은 전체 토큰의 수
- f_i는 i 번째 토큰의 빈도수
- p_i는 i 번째 토큰의 확률
■ 위의 손실 함수에 대한 공식은 각 토큰의 빈도수와 해당 토큰의 음의 로그 확률을 곱한 값들의 총합을 계산한다. 이렇게 하면 전체 말뭉치에 대한 모델의 성능을 하나의 숫자로 나타낼 수 있다.
■ 이 손실 함수를 계산하여 불필요한 토큰을 제거하기 위해서 다음의 3가지 구성 요소를 구현해야 한다.
- (1) model
- model이라는 딕셔너리는 각 토큰에 대한 음의 로그 확률을 저장한다. key는 토큰, value는 해당 토큰의 음의 로그 확률이다.
- (2) encode_word( ) 함수
- 이 함수는 단어와 현재 모델(토큰)을 입력으로 받아서 단어를 인코딩하고 모델의 손실을 계산하는 함수이다.
- 여기서 동적 프로그래밍을 기반으로 하는 '비터비(Viterbi) 알고리즘'을 사용하여 현재 단어 집합에서 가장 최적의 토큰 분할을 찾아내서 전체 손실을 최소화하는 것이 목표이다. - 이 함수는 최적의 토큰화 결과와 그에 따른 손실을 반환한다.
- (3) compute_loss( ) 함수
- 이 함수는 현재 모델을 사용하여 말뭉치에 대한 총 손실을 계산한다.
- 말뭉치의 각 단어를 순회하면서 encode_word( ) 함수를 사용하여 단어를 인코딩하고, 그 손실들을 모두 더한다.
- 이 함수는 현재 모델(단어 집합)이 전체 말뭉치를 얼마나 잘 표현하는지를 나타내는 성능 지표로서 총 손실을 반환한다.
■ 먼저, 다음과 같이 빈도를 기반으로 초기 모델을 생성한다.
from math import log
total_sum = sum([freq for token, freq in token_freqs.items()])
## 초기 모델 생성. 빈도를 기반으로 함
model = {token: -log(freq / total_sum) for token, freq in token_freqs.items()}
len(model)
```#결과#```
300
````````````
# 초기 모델(단어 집합)의 각 토큰에 대한 손실(음의 로그 확률)값 확인
sorted_model = dict(sorted(model.items(), key = lambda item: item[1], reverse = True))
sorted_model
```#결과#```
{'F': 6.386879319362645,
'C': 6.386879319362645,
'v': 6.386879319362645,
'm': 6.386879319362645,
'f': 6.386879319362645,
...,
...,
'o': 3.821929961901108,
't': 3.7478219897473863,
'e': 3.342356881639222,
'▁': 2.952892114877499}
````````````■ 다음은 encode_word( ) 함수를 구현하는 단계이다. encode_word( ) 함수는 현재 단어 집합에서 가장 최적의 토큰 분할을 찾아내서 전체 손실을 최소화하는 역할을 수행하기 때문에 Unigram Tokenization의 핵심 요소이다.
■ 그러므로, 이 함수의 가장 중요한 부분은 Viterbi 알고리즘을 사용하여 단어를 토큰화하는 부분이다.
■ Viterbi 알고리즘은 관측된 사건들의 순서를 야기한 가장 가능성 높은 상태들의 순서인 비터비 경로(Viterbi path)를 찾는 알고리즘이다. 이것을 이용하여 encode_word( ) 함수에서 최적의 분할이 되는 Viterbi path를 찾는 것이다.
■ 주어진 단어에 대해 가능한 모든 분할들을 다음과 같이 그래프를 통해 나타낼 수 있다.

■ 만일 주어진 단어 내의 문자 a에서 b까지의 하위 단어(subword)가 단어 집합(vocabulary)에 존재한다면, 위의 그림처럼 이 그래프 내에서 a에서 출발하여 b까지 가는 그래프 내의 가지(branch)가 있다.
■ 이때, 이 하위 단어의 확률(여기서는 점수(손실 값))을 해당 가지에 지정할 수 있다.
■ Viterbi 알고리즘은 최고 점수를 얻을 얻을 비터비 경로(Viterbi path)를 찾기 위해
- 먼저, 다음 그림처럼 단어 내의 각 위치(문자, character)를 순회하며, 각 위치에서 끝나는 하위 단어(subword)들을 고려하여, 다시 말해, 모든 가능한 부분 문자열을 고려하여 최고 점수를 나타내는 분할(segmentation)을 결정한다.
-- 계산된 점수는 그래프 내의 가지에 지정된 손실 값이다.
cf) Viterbi 알고리즘은 다음 그림처럼 현재 상태로 전이할 확률이 가장 큰 직전 상태를 모든 시점, 모든 상태에 대해 계산해서 점수를 계산하여 경로를 업데이트한다.
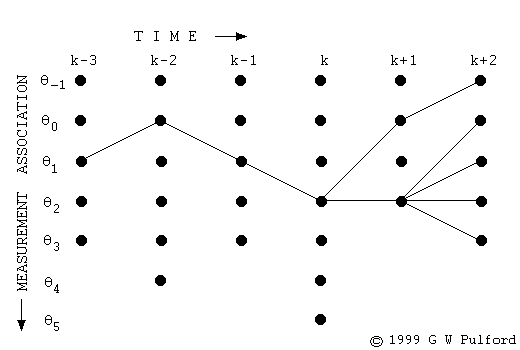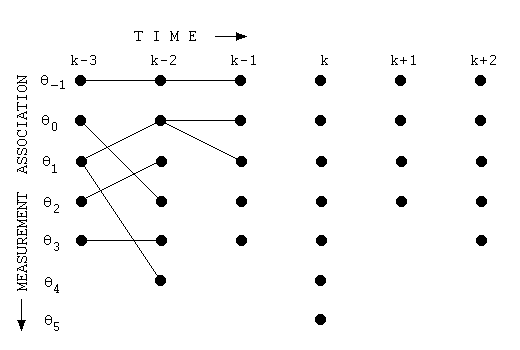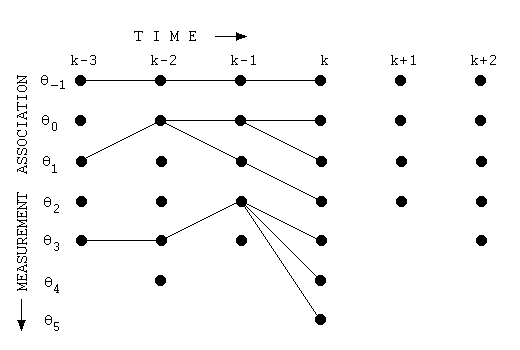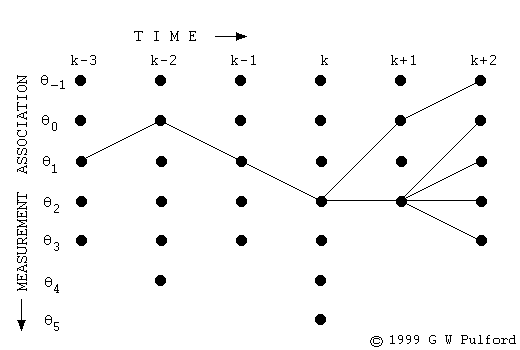
- 이렇게 모델(model)에 존재하는 토큰(부분 문자열)에 대해 손실을 계산하는데, 더 나은 분할 경로가 있다면, 분할 경로를 업데이트한다.
- 최종적으로 마지막 위치(단어의 끝에 위치한 문)에서부터 역추적하여 최적의 토큰화를 재구성한다. 그래프로 따지면, 다음 그림처럼 최종 경로를 펼치는 것이다.
- 유효한 토큰화가 없으면 <unk> 토큰을 반환한다.
def encode_word(word, model):
best_segmentations = [{"start": 0, "score": 1}] + [
{"start": None, "score": None} for _ in range(len(word))
]
for start_idx in range(len(word)):
# This should be properly filled by the previous steps of the loop
best_score_at_start = best_segmentations[start_idx]["score"]
for end_idx in range(start_idx + 1, len(word) + 1):
token = word[start_idx:end_idx]
if token in model and best_score_at_start is not None:
score = model[token] + best_score_at_start
# If we have found a better segmentation ending at end_idx, we update
if (
best_segmentations[end_idx]["score"] is None
or best_segmentations[end_idx]["score"] > score
):
best_segmentations[end_idx] = {"start": start_idx, "score": score}
segmentation = best_segmentations[-1]
if segmentation["score"] is None:
# We did not find a tokenization of the word -> unknown
return ["<unk>"], None
score = segmentation["score"] # 여기서의 점수(score)는 계산된 손실(loss) 값
start = segmentation["start"]
end = len(word)
tokens = []
while start != 0:
tokens.insert(0, word[start:end])
next_start = best_segmentations[start]["start"]
end = start
start = next_start
tokens.insert(0, word[start:end])
return tokens, score■ encode_word 함수는 위와 같이 '토큰화할 단어인 word'와 '하위 단어(subword)와 그에 대응하는 loss(확률로 계산된 손실 값)을 입력으로 받으며, 출력으로 최적의 subword 분할 결과인 tokens와 최적의 분할에 대한 총 손실 값인 loss를 반환한다.
■ best_segmentations라는 변수에 단어의 각 부분 문자열에 대한 분할 결과를 저장한다.
- 초기에는 {"start": 0, "loss": 0}]와 {"start": None, "loss": None}로 구성되며, {"start": 0, "loss": 0} 원소는 한 개, {"start": None, "loss": None}는 range(len(word))만큼의 개수를 가진다.
- start는 가장 점수가 높은 분할에서의 마지막 토큰의 시작 인덱스이며, loss는 해당 분할의 점수(손실 값)
- 첫 번째 요소인 {"start": 0, "loss": 0}가 초깃값이며, 나머지 {"start": None, "loss": None}는 아직 값이 없는 상태로 초기화된다.
■ for start_idx in range(len(word))로 시작되는 루프가 Viterbi 알고리즘을 통한 최적 경로를 탐색하는 부분이다.
- 외부 루프(for start_idx)에서는 start_idx를 기준으로 단어를 탐색한다. 그리고 start_idx에서 끝나는 경로의 손실 값을 best_loss_at_start라는 변수에 저장한다.
- 내부 루프(for end_idx)에서는 시작 인덱스(start_idx) 다음 인덱스에서 시작하는 모든 가능한 하위 단어(subword). 즉, 하위 문자열을 탐색한다.
- token에는 start_idx부터 end_idx까지의 subword가 저장된다.
■ 이렇게 외부 루프는 각 시작 위치(start_idx)로 이동하고 내부 루프는 해당 시작 위치에서 시작하는 모든 하위 문자열을 검토한다.
■ 첫 번째 if 문에서는, 위의 이중 루프를 통해 token이라는 변수에 저장된 하위 단어(subword)가 모델에 존재하고(token in model), 현재 시작 위치까지의 손실 값(best_loss_at_start = best_segmentations[start_idx]["loss"])이 존재해야 한다.(best_loss_at_start is not None)
- 첫 번째 if 문이 True라면, 현재 하위 단어(subword)의 손실 값(model[token])과 이전 위치까지의 누적 손실 값(best_loss_at_start)을 더해 새로운 손실 값을 계산한다.
■ 두 번째 if 문에서는 end_idx에서 끝나는 경로 중 더 낮은 손실 값을 발견하면, 해당 위치의 정보를 경로에 업데이트한다.
■ segmentation = best_segmentation[-1]부터 while문까지는 최적 경로를 역추적하는 부분이다.
■ 마지막 위치에서 최적 경로를 가져온다. (segmentation = best_segmentation[-1]).
■ 만약, 마지막 위치까지 도달하는 유효한 경로가 없다면(=유효한 토큰화가 없다면) <unk> 토큰과 함께 None을 반환다. (if segmentation["loss"] is None: return ["<unk>"], None)
■ segmentation = best_segmentation[-1]이므로, 남은 코드들은 단어의 끝(마지막 위치)에서부터 역추적하여 토큰 리스트를 생성하는 역할을 수행한다.
- 단어의 끝(마지막 위치)부터 시작하여 단어의 시작 위치에 도달할 때까지 특정 시작 위치에서 다음 위치로 이동하면서 토큰을 추출한다.
- 이때, 추출된 토큰은 리스트 앞쪽에 삽입(insert[0, word[start:end])되어 원래 순서를 유지한다.
■ 반환되는 토큰화 결과인 tokens는 Viterbi 알고리즘을 사용해 찾은 가장 낮은 손실 값을 가지는 최적 분할을 탐색한 결과이다.
■ 예를 들어, "unhug"라는 단어를 넣었을 때, 해당 단어의 각 위치(Character i)에 대해 최고 점수로 끝나는 하위 단어가 다음과 같다고 하자.
Character 0 (u): "u" (score 0.171429)
Character 1 (n): "un" (score 0.076191)
Character 2 (h): "un" "h" (score 0.005442)
Character 3 (u): "un" "hu" (score 0.005442)
Character 4 (g): "un" "hug" (score 0.005442)- 처음부터 마지막 문자('g')까지 진행한 결과, ["un" "h"], ["un" "hu"], ["un" "hug"]가 가장 높은 점수인 0.005442를 기록했다.
- 이때, [-1]로 역추적을 하기 때문에 ["un", "hug"]가 뽑힌다. 즉, 단어 "unhug"는 ["un" "hug"]로 토큰화된다.
■ 이제 encode_word 함수를 이용하는 compute_loss( ) 함수를 구현하여 말뭉치에서 모델의 손실을 쉽게 계산할 수 있다.
# 현재 모델을 사용하여 전체 말뭉치의 총 손실을 계산
def compute_loss(model):
loss = 0
for word, freq in word_freqs.items():
_, word_loss = encode_word(word, model)
loss += freq * word_loss
return loss■ 말뭉치에 대한 모델의 손실을 계산하는 과정은 다음과 같다.
- 손실값을 저장할 변수를 0으로 초기화한다.
- 말뭉치의 각 단어에 대해 encode_word 함수로 최적의 토큰화와 손실을 찾는다. 여기서 찾은 손실에 단어의 빈도를 곱하고 총 손실에 더한다.
- 누적된 총 손실을 반환한다.
■ 이 과정을 통해 현재 모델이 전체 말뭉치를 얼마나 잘 표현하는지 수치화할 수 있다. 이 예에서는 다음과 같이 413.1037 정도가 계산되었다.
compute_loss(model)
```#결과#```
413.10377642940875
````````````■ compute_loss(model)의 반환 값인 413.10377이라는 수치의 의미는 현재 모델(model)의 전체 말뭉치에 대한 손실 값이다.
- 여기서 현재 모델은, 현재 모델 = 현재 토큰(부분 문자열)들이 저장된 단어 집합
■ compute_loss(model)로 반환되는 값은
- 각 토큰의 음의 로그 확률에 해당 토큰의 빈도수를 곱한 합으로 계산된 값으로
- 낮은 손실 값은 현재 모델이 말뭉치를 잘 표현함을 의미한다.
- 이 값이 단어 집합의 크기를 조정하는 기준점으로 사용된다.
- 단어 집합을 최적화하면서(단어 집합의 크기를 작게 만들면서), 이 손실 값의 변화를 모니터링하여 모델(model)의 성능을 평가할 수 있다.
■ compute_loss(model)로 반환되는 값은 단어 집합의 크기를 조정하는 기준점으로 사용된다고 하였다. 왜냐하면, 이 총 손실 값을 '커지게' 만드는 토큰은 단어 집합에 계속 유지시켜야 하기 때문이다.
■ 하지만, 총 손실 값을 비슷하게 유지하거나 작아지게 하는 토큰은 단어 집합에서 삭제해도 좋다. 이것이 Unigram의 가장 큰 특징 중 하나이다.
■ '토큰을 제거했을 때, 총 손실 값을 크게 증가시키는' 토큰은, 해당 토큰을 제거했을 때 모델(model)의 성능이 크게 저하될 수 있기 때문에 말뭉치를 효과적으로 표현하는데 중요한 역할을 하는 것으로 볼 수 있다.
■ 반면, '토큰을 제거했을 때, 총 손실 값을 '비슷하게 유지하거나 작게 만드는' 토큰은 제거해도 모델의 전반적인 성능에 미치는 영향이 작으므로, 단어 집합에서 제거할 후보가 된다.
■ 정리하면, 단어 집합을 최적화하는 방법은 각 토큰을 제거했을 때 손실 변화를 계산해서 '손실 증가가 가장 작은 토큰부터 순차적으로 제거'하는 것이다. 이 과정을 사용자가 원하는 단어 집합 크기에 도달할 때까지 반복하여 진행한다.
■ 이 최적화 방법을 통해 Unigram의 모델(model)은 불필요한 토큰을 제거하여 효율적인 단어 집합으로 말뭉치를 효과적으로 표현할 수 있는 것이다. 이러한 최적화 과정은 다음과 같이 compute_scores( ) 함수를 통해 계산할 수 있다.
import copy
def compute_scores(model):
scores = {}
model_loss = compute_loss(model)
for token, score in model.items():
# We always keep tokens of length 1
if len(token) == 1:
continue
model_without_token = copy.deepcopy(model)
_ = model_without_token.pop(token)
scores[token] = compute_loss(model_without_token) - model_loss
return scores■ 이 함수에서 반환되는 scores는 어떤 손실 값을 기록한 딕셔너리로, key는 현재 단어 집합의 토큰이며 value는 해당 토큰을 제거할 경우 발생할 총 손실의 변화이다.
■ compute_scores( ) 함수를 통해 얻은 scores를 이용하여 다음과 같이 어떤 토큰을 제거해도 되는지 확인할 수 있다.
## 여기서의 점수는 해당 토큰을 제거했을 때, 손실 값의 변화량
# 점수가 가장 높은 단어 5개
for i in range(5):
print(sorted_scores[i])
```#결과#```
('▁This', 8.858676344632443)
('ll', 6.376412403623874)
('s.', 6.2575655626822595)
('▁the', 5.905784229754943)
('and', 4.915591745409358)
````````````
# 점수가 가장 낮은 단어 5개
for i in range(1, 6):
print(sorted_scores[-i])
```#결과#```
('several', 0.0)
('severa', 0.0)
('sever', 0.0)
('seve', 0.0)
('sev', 0.0)
````````````■ 위 결과를 보면, 어떤 토큰이 손실 값에 큰 영향을 미치는지 확인할 수 있다.
- 예를 들어 '▁This','ll', 's.', '▁the', 'and' 같은 토큰들은 삭제하면 손실이 크게 증가하기 때문에, 해당 토큰들은 단어 집합에 유지시켜야 할 것이다.
- 반면, 'several', 'severa', 'sever', 'seve', 'sev' 같은 토큰들은 제거해도 손실 변화가 0이기 때문에 삭제 대상이 된다.
■ 예를 들어서, "ll"과 "his"를 제거했을 때 손실 변화량을 보면 다음과 같은데
print(scores["ll"])
print(scores["his"])
```#결과#```
6.376412403623874
0.0
````````````- "ll"은 "Hopefully"의 토큰화에 사용되는 토큰으로, "ll"을 제거한다면, 토큰 "l"을 두 번 사용해야 하므로 추가적인 손실이 발생할 것이다.
- 그러나 "his"는 현재 말뭉치의 단어 "This" 에서만 사용되는 토큰이므로 추가적인 손실이 0이다.
■ 이제 마지막 단계는 특수 토큰을 단어 집합(vocabulary)에 추가한 다음, 사용자가 원하는 크기에 도달할 때까지 단어 집합에서 토큰을 반복적으로 제거하는 것이다.
■ 불필요한 토큰을 제거하는 과정은 다음과 같다.
percent_to_remove = 0.1 # 10 % 제거
while len(model) > 100: # 단어 집합의 크기가 100에 도달할 때까지 반복
scores = compute_scores(model)
sorted_scores = sorted(scores.items(), key=lambda x: x[1]) # 오름차순 정렬
for i in range(int(len(model) * percent_to_remove)): # 점수가 가장 낮은 percent_to_remove % 개의 토큰 제거
_ = token_freqs.pop(sorted_scores[i][0])
total_sum = sum([freq for token, freq in token_freqs.items()])
model = {token: -log(freq / total_sum) for token, freq in token_freqs.items()}- 목표로 한 단어 집합의 크기가 될 때까지 다음 과정을 반복한다.
- 각 반복에서 현재 모델(model)의 각 토큰에 대한 손실을 계산한다.
- 그리고 손실이 가장 적은 순서대로 토큰을 제거하기 위해 손실 변화량인 scores 딕셔너라의 value를 기준으로 오름차순 정렬한다.
- 그리고 현재 단어 집합의 크기의 precent_to_remove(이 예에서는 10%)에 해당하는, 가장 손실이 적은 토큰들을 제거한다.
-- 만약, 단어 집합의 크기(토큰의 개수)가 100이라면, 첫 번째 반복에서는 100개 중 10개를 제거하여 90개가 남게 되고, 두 번째 반복에서 90개 중 9개를 제거하여 81개가 남게 되고, 세 번째 반복에서는 81개 중 8개를 제거한다. 이 과정을 목표로 한 단어 집합의 크기가 될 때까지 반복한다.
- 그다음, 남은 토큰들의 빈도를 다시 계산해서, 새로운 빈도를 바탕으로 모델을 업데이트한다.
- 이러한 과정을 통해 매 반복마다 단어 집합의 크기가 점진적으로 줄어들며, 각 단계에서 새로운 상황을 반영(예를 들어, 첫 번째 반복에서 100개 중 scores 값이 가장 작은 토큰 10개를 제거해서 90개가 남고, 두 번째 반복에서 90개 중 9개를 제거해서 81개가 남고, 세 번째 반복에서 81개 중 8를 제거....)하여 말뭉치를 효과적으로 표현할 수 있는 최적의 토큰을 유지한다.
sorted_model = list(sorted(model.items(), key = lambda item: item[1], reverse = True))
## 점수가 가장 높은 단어 5개
for i in range(5):
print(sorted_model[i])
```#결과#```
('F', 5.752572638825633)
('C', 5.752572638825633)
('v', 5.752572638825633)
('m', 5.752572638825633)
('f', 5.752572638825633)
````````````
# 점수가 가장 낮은 단어 5개
for i in range(1, 6):
print(sorted_model[-i])
```#결과#```
('▁', 2.318585434340487)
('e', 2.70805020110221)
('t', 3.1135153092103742)
('o', 3.1876232813640963)
('s', 3.1876232813640963)
````````````3.3 Unigram Tokenizer 사용
■ 이제 3.2 과정을 통해 학습된 Unigram 모델을 사용하여 입력 텍스트를 토큰화할 수 있다. 입력 텍스트를 토큰화하려면 사전 토큰화(pre-tokenization)를 적용한 다음, encode_word( ) 함수를 사용하면 된다.
def tokenize(text, model):
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
pre_tokenized_text = [word for word, offset in words_with_offsets]
encoded_words = [encode_word(word, model)[0] for word in pre_tokenized_text]
return sum(encoded_words, [])
tokenize("This is the Hugging Face course !", model)
```#결과#```
['▁This',
'▁is',
'▁the',
'▁Hugging',
'▁Face',
'▁',
'c',
'ou',
'r',
's',
'e',
'<unk>']
````````````- model에 없는 토큰인 '!'는 <unk> 토큰으로 처리된 것을 볼 수 있다.
참고 - 대표적인 언어모델과 사용된 토큰화 방법
■ 다음은 각 토큰화 알고리즘을 사용하는 대표적인 언어 모델과 각 모델의 어휘 수를 정리한 테이블이다.

■ 위의 표를 보면, 사전 토큰화 작업없이 토큰화를 수행하여 언어에 종속되지 않는 SentencePiece 토큰화 방법과 Byte-Level BPE 토큰화 방법이 많이 사용된 것을 볼 수 있다.
■ Byte-Level BPE는 문자(character)들에 대하여 바이트(byte) 단위의 병합으로 처리함으로써 희귀 단어나 신조어 그리고 다국어 환경에서 효율적으로 작동하는 것으로 알려져 있다. 즉, 복잡합 언어 패턴을 잘 파악하는 것이다.
■ 그리고 표를 보면, 라마-3의 경우 단어 집합의 크기가 128,000으로 다양한 토큰을 사용하고 있다. 이는 정교한 언어 표현과 다양한 언어 지원을 위한 것으로 볼 수 있다.
'자연어처리' 카테고리의 다른 글
| RNN (1) (1) | 2025.03.23 |
|---|---|
| 시퀀스투시퀀스(Sequence‑to‑Sequence, seq2seq) (1) (0) | 2025.03.19 |
| Subword Tokenizer - (2) WordPiece Tokenization (0) | 2025.03.16 |
| Subword Tokenizer - (1) Byte Pair Encoding(BPE) Tokenization (0) | 2025.03.15 |
| 엘모(Embeddings from Language Model, ELMo) (0) | 2025.03.08 |


