1. '단순한' CBOW 모델의 문제점
■ 입력층에 타깃 단어의 주변 단어가 원핫 형태로 들어와서 입력 측의 가중치 Win과의 행렬 곱으로 은닉층을 계산한다. 그다음, 은닉층에서 출력 측의 가중치 Wout과의 행렬 곱으로 입력으로 들어왔던 각 단어의 점수를 계산한다.
■ 각 단어의 출현 확률을 계산하기 위해 출력층의 결과인 각 단어의 점수에 소프트맥스 함수를 적용하고, (범주형) 교차 엔트로피 오차를 적용하여 출현 확률과 정답 레이블을 비교해 손실을 계산한다.
■ 이 손실을 최소화했을 때의 가중치 Win이 단어의 분산 표현이다.

■ 이 예제에서는 어휘 수가 7개라서 단어를 원핫 벡터로 표현했을 때 벡터의 원소 수(차원)는 7개였다.
■ 만약, 대규모 말뭉치를 사용했을 때 어휘 수가 1만 개, 10만 개, 100만 개, ... 가 된다면, 단어를 원핫 벡터로 표현했을 때 벡터의 원소 수는 1만 개, 10만 개, 100만 개, ... 가 된다.
■ 이렇게 되면 ① 입력층의 원핫 표현과 Win의 행렬 곱, ② 은닉층과 Wout의 행렬 곱 계산 및 소프트맥스 함수 층의 계산에서 병목이 발생할 수밖에 없다.
■ ① 입력층의 원핫 표현과 Win의 행렬 곱 계산 속도 문제는 입력층의 원핫 표현에 따른 결과이다.
■ 단어를 원핫 벡터로 변환하기 때문에 어휘 수가 많으면 원핫 벡터의 크기가 커져 많은 메모리를 차지한다. 그리고 원핫 벡터와 Win의 행렬 곱을 계산해야 하기 때문에 은닉층의 뉴런 수가 많을수록 (순전파와 역전파 과정에서) 행렬 곱 계산 시, 상당한 컴퓨팅 리소스가 사용된다.
■ 예를 들어 어휘 수가 100만 개, 은닉층 뉴런 수가 3개라면 가중치 행렬 Win의 크기는 1000000 x 3, 은닉층 뉴런 수가 10개라면 1000000 x 10, 은닉층 뉴런 수가 100개라면 1000000 x 100, ....
■ 이렇게 어휘 수와 은닉층 뉴런의 수가 많을수록 Win의 크기가 커짐에 따라, 행렬 곱 계산 시 Win 크기에 따른 계산 자원이 사용된다.
■ 이 문제는 'Embedding 계층'을 도입해 해결할 수 있다.
■ ② 은닉층 이후의 계산 속도 문제는, 예를 들어 어휘 수가 100만 개이고 은닉층의 뉴런 수가 100개인 경우, 단어 100만 개에 대한 점수를 계산해야 하므로 Wout의 크기는 100 x 1000000이 된다. 또한, 소프트맥스 함수를 사용해 단어 100만 개의 점수를 확률로 변환해야 한다.
■ 예를 들어 Wout의 크기가 100 x 1000000, 각 단어의 점수가 s1,s2,…,s1000000이고 k 번째 원소(단어)가 타깃 단어일 때 Softmax 계산식은 yk=exp(sk)1000000∑i=1exp(si)이므로 exp 계산을 100만 번 수행해야 한다.
■ 즉, 순전파 & 역전파 과정에서의 행렬 곱 계산량과 소프트맥스 함수 층의 계산량이 병목 구간이 되어 계산 속도를 저하시킨다.
■ 이 문제는 '네거티브 샘플링'이라는 손실 함수를 도입해 해결할 수 있다. 소프트맥스 대신 네거티브 샘플링을 이용하면 어휘가 많아져도 낮은 수준의 계산량을 일정하게 유지할 수 있다.
2. word2vec 속도 개선 - ① Embedding 계층
■ 입력층의 원핫 벡터와 Win 행렬 곱의 계산 결과는, 결과적으로 어휘 수와 상관없이 단어 ID에 대응되는 Win의 행벡터 하나를 추출한 것과 같다.
■ 예를 들어 어휘 수가 100만 개이고 은닉층 뉴런이 100개일 때, 단어 ID가 3에 해당되는 원핫 벡터를 Win과 행렬 곱하면
■ 따라서 단어를 원핫 표현으로 변환하는 것과 단어의 원핫 표현을 Win과 행렬 곱 계산을 수행하는 대신, '단어 ID에 해당하는 가중치의 행벡터를 추출하는 계층'을 만들면 된다. 이 계층이 바로 'Embedding 계층'이다.
■ 가중치 Win의 각 행에는 단어의 임베딩(분산 표현)이 담겨 있다. 따라서 Embedding 계층의 역할은 단어의 임베딩을 저장하는 것이다.
2.1 Embedding 계층 구현
■ 파이썬에서 행렬의 행을 추출하는 방법은 다음과 같이 행렬이 있을 때 W[i]로 i 행을 추출한다.
cf) W[i,j]는 i 행의 j 원소를 반환한다.
W = np.arange(1000000*3).reshape(1000000, 3)
W
```#결과#```
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
...,
[2999991, 2999992, 2999993],
[2999994, 2999995, 2999996],
[2999997, 2999998, 2999999]])
````````````
W[2]
```#결과#```
array([6, 7, 8])
````````````
W[999999]
```#결과#```
array([2999997, 2999998, 2999999])
````````````■ 행렬에서 여러 개의 행을 한 번에 반환하고 싶으면, 반환하고자 하는 행들의 번호들을 다음과 같이 지정하면 된다.
idx = np.array([2, 999999])
W[idx]
```#결과#```
array([[ 6, 7, 8],
[2999997, 2999998, 2999999]])
````````````■ 따라서 Embedding 계층의 순전파는 단순히 행렬의 행에 접근하는 방식으로 구현할 수 있다.
class Embedding:
def __init__(self, W):
self.W = W
self.grads = np.zeros_like(W)
def forward(self, idx):
self.idx = idx
out = self.W[idx]
return out
Embedding(W).forward(2)
```#결과#```
array([6, 7, 8])
````````````■ 이렇게 Embedding 계층의 순전파는 가중치의 특정 행 뉴런만을 그대로 다음 층으로 흘려 보낸다.
■ 따라서 역전파도 앞 층에서 오는 기울기를 다음 앞 층으로 그대로 흘려보내주면 된다. 단, 앞 층으로부터 전해진 기울기를 가중치 기울기(dW)에 저장하되, 순전파 과정에서 흘려보낸 행(idx)에 저장해야 한다.
■ 역전파 과정을 가중치 기울기 행렬의 원소를 모두 0으로 만든 다음, 가중치 행렬의 행(idx)에 기울기(dout)을 넣는 구현 방식은
dW, = self.grads
dW[...] = 0
dW[self.idx] = doutidx의 원소가 중복될 경우 다음과 같이 먼저 쓰인 값을 덮어써버리는 문제가 발생한다.
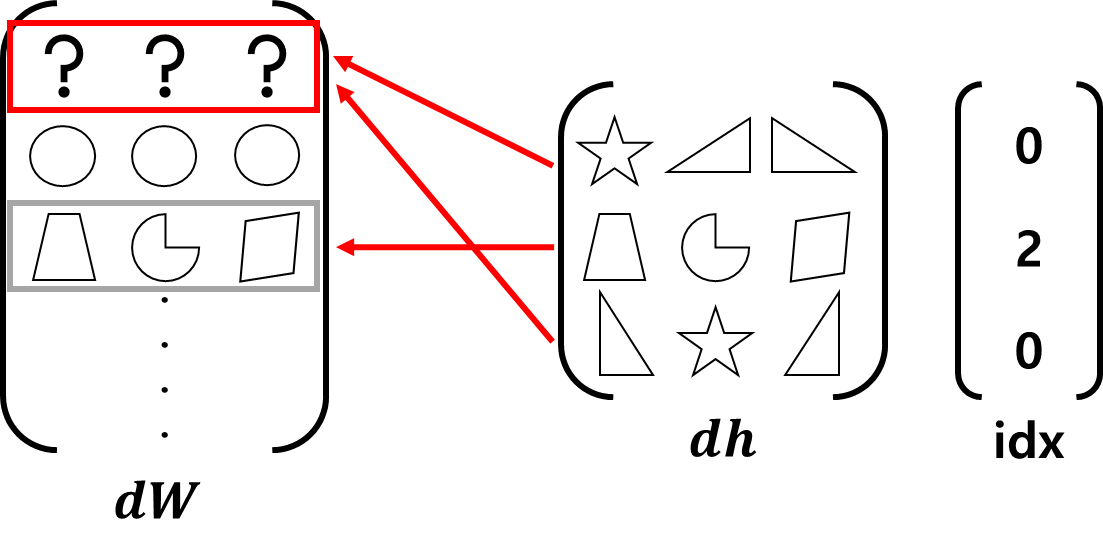
■ 위와 같은 역전파 과정에서 idx의 중복은 다음과 같이 순전파가 진행되었기 때문이다.

이 문제는 기울기 할당이 아닌 더하기를 하면 된다.
■ W[0] 하나가 h의 h[0], h[2]에 전달된 것이기 때문에 역전파 과정에서 h[0], h[2]에 대한 미분 값을 하나로 더해야 W[0]의 총 영향을 계산할 수 있다.
class Embedding:
def __init__(self, W):
self.W = W
self.grads = np.zeros_like(W)
def forward(self, idx):
self.idx = idx
out = self.W[idx]
return out
def backward(self, dout):
dW = self.grads
dW[...] = 0
np.add.at(dW, self.idx, dout) # dout값을 가중치 기울기 행렬 dW의 행(idx)에 더한다.
return Nonecf) 기울기를 더하는 이유는 순전파 수행 시, 동일한 값이 분기(복제)되는 상황에서 발생하는 다수의 경로로부터 역전파되는 기울기들을 하나로 합산하여 모든 경로를 정확히 반영하기 위함이다.
3. word2vec 속도 개선 - ② 네거티브 샘플링
3.1 다중 분류 → 이진 분류
■ 네거티브 샘플링 기법의 핵심 아이디어는 다중 분류에서 이진 분류(binary classification)로 근사하는 것이다.
■ 'You say goodbye and I say hello.'의 예에서 소프트맥스 함수를 사용해 주변 단어가 you와 goodbye일 때 타깃 단어가 무엇인가에 대한 답으로 단어들의 출현 확률을 반환하였다.
■ 이 다중 분류 문제를 이진 분류 문제로 생각한다면, 주변 단어가 you와 goodbye일 때 타깃 단어가 'say'일 확률을 구해서, 확률이 임곗값(threshold)를 넘기면 1(Yes), 그렇지 않으면 0(No)을 반환하면 된다.
■ 따라서 이진 분류를 수행할 경우 출력층에는 타깃 단어의 점수를 출력하는 뉴런 하나만 존재하면 된다.
■ 예를 들어 어휘 수가 100만 개, 은닉층 뉴런이 100개일 때 출력층 분류기가 이진 분류라면 다음과 같다.

■ Wout은 열 방향으로 단어의 분산표현이 저장되어 있으므로, CBOW 모델을 이진 분류기로 바꿀 경우 가중치 Wout 행렬에서 타깃 단어 ID에 대응되는 열벡터만 추출하여 추출한 열벡터와 은닉층 뉴런의 내적을 계산하면 된다.
- 여기서 Wout[:, 1]은 타깃 단어인 'say'에 해당하는 열벡터이다.
3.2 손실 계산
■ 신경망에서 이진 분류는 시그모이드 함수로 확률을 구하고 '(이진) 교차 엔트로피 오차'로 손실을 계산한다.
■ 시그모이드 함수의 출력을 '확률'로 해석할 수 있는 이유는 시그모이드 함수의 식이 y=11+exp(−x)으로 입력 값(x)는 0과 1 사이의 출력 값(y)로 변환된다.
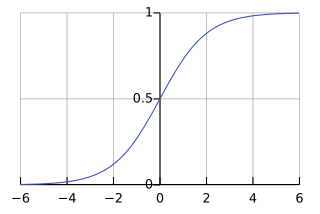
■ 시그모이드 함수 y=11+exp(−x)를 y라 했을 때, 시그모이드 함수의 미분 y′=y(1−y)이므로 시그모이드 계층의 순전파와 역전파 계산은 다음과 같다.

■ y가 시그모이드 함수의 출력 값이고 t가 정답 레이블일 때, 이진 분류에 쓰이는 교차 엔트로피 오차는 다음과 같다. L=−(t⋅logey+(1−t)⋅loge(1−y)) 이진 분류에서 정답 레이블 t의 값은 0(No) 아니면 1(Yes)이므로 t=1이면 L=−logy, t=0이면 L=−log(1−y)가 출력된다.
- 즉, −t⋅logey 항은 t = 1인 경우, −(1−t)⋅loge(1−y) 항은 t = 0인 경우이다.
■ 이진 교차엔트로피 오차를 사용했을 때 시그모이드 계층의 역전파 ∂L∂y⋅∂y∂x=∂L∂y⋅y(1−y)는 ∂L∂y=−ty+1−t1−y=y−ty(1−y)이므로 ∂L∂x=∂L∂y⋅∂y∂x=y−ty(1−y)⋅y(1−y)=y−t가 된다.
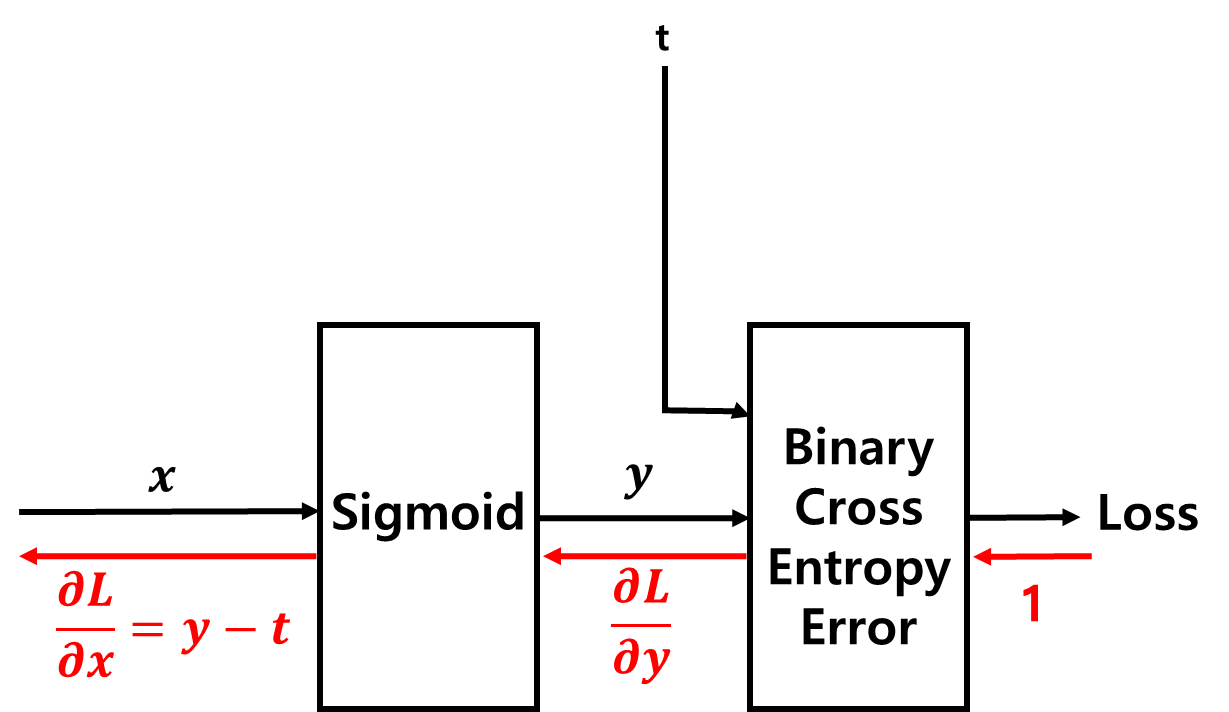
■ 시그모이드 계층의 역전파 값 y−t는 y가 시그모이드 함수의 결과인 확률이므로 y−t는 '예측 확률 - 실제 정답' 값이다.
■ 따라서 t=1일 때, y가 100%에 가까울수록 오차가 줄어들고, y가 0에 가까울수록 오차가 커진다.
3.3 다중 분류 → 이진 분류 구현
word2vec 속도 개선 - 다중 분류 → 이진 분류
3.4 네거티브 샘플링
■ 기존의 CBOW 모델의 구조에 지금까지의 과정을 반영하면 CBOW 모델의 구조는 다음과 같이 변경된다.
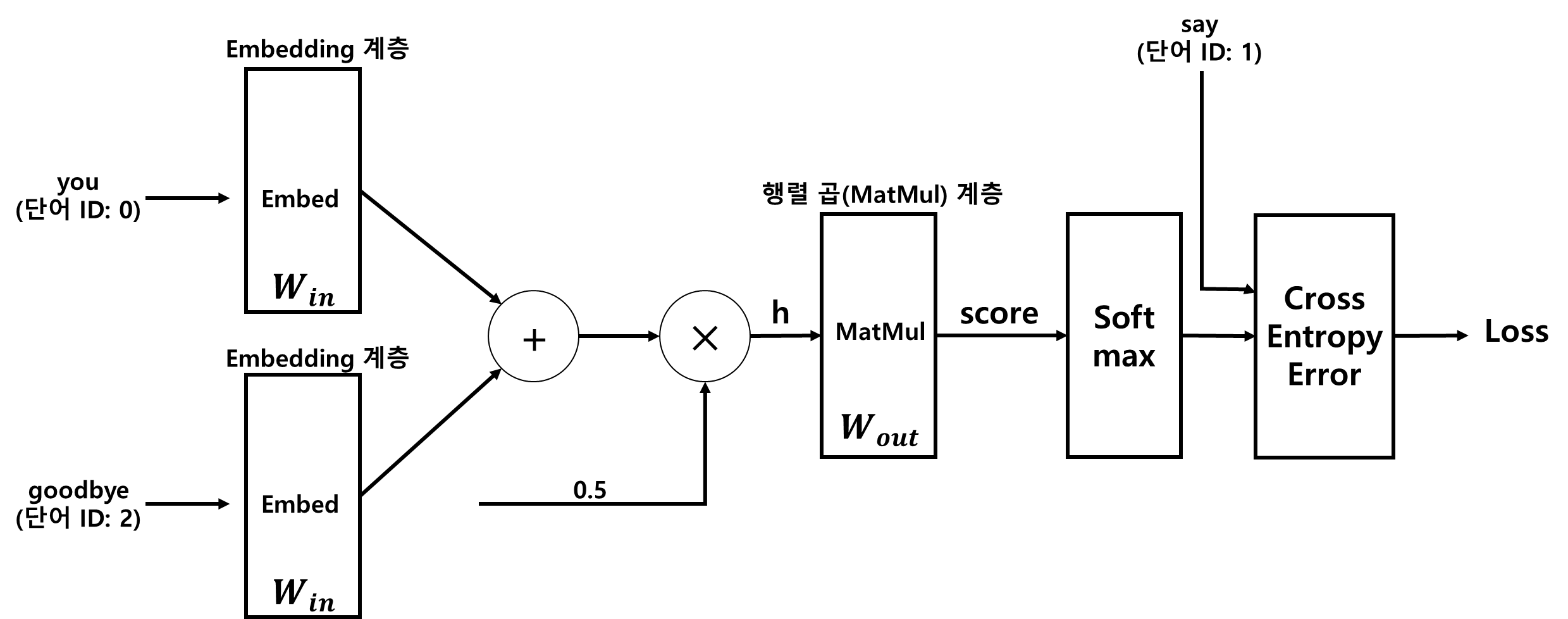

■ 여기서 은닉층 뉴런(h)와 타깃 단어의 임베딩 벡터의 내적하는 부분을 합쳐 Embedding Dot 계층으로 만들고 h → Embedding Dot 계층 → Sigmoid → Binary Cross Entropy Error계층 → Loss 부분만 보았을 때, 주변 단어가 'you'와 'goodbye'일 때 타깃이 'say'일 확률이 0.99라고 하자.
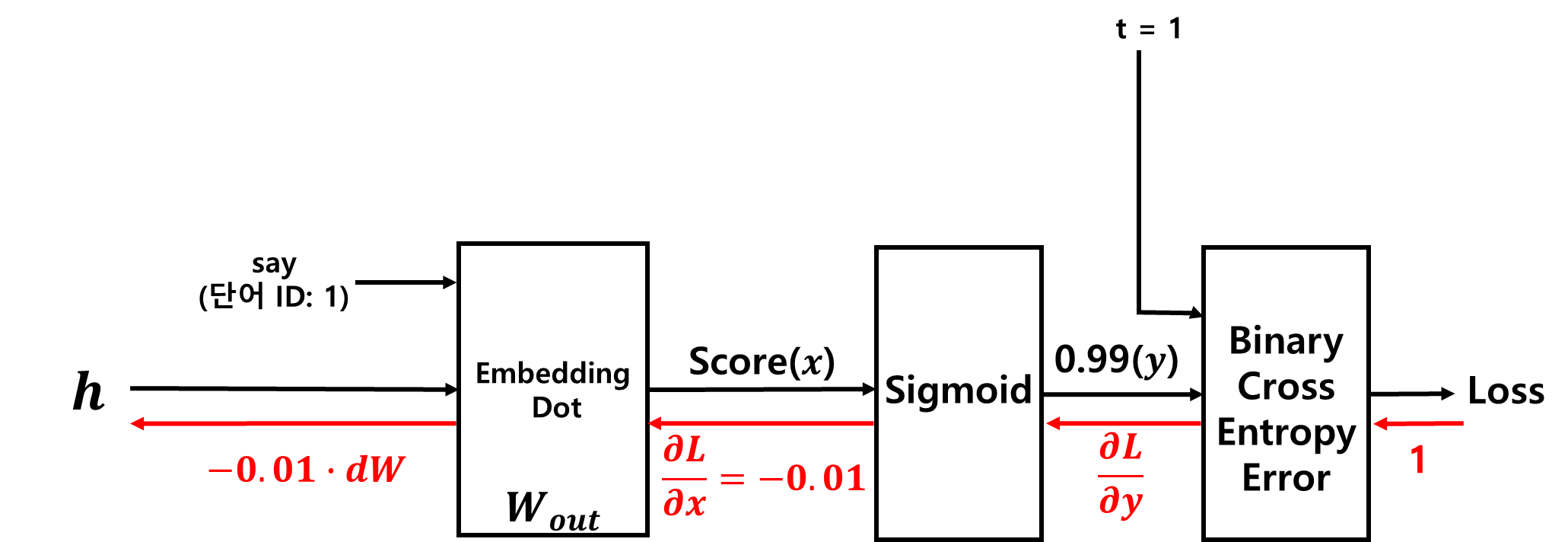
■ 이렇게 시그모이드의 출력값(y)이 0.99로 나오면 역전파 시 오차는 -0.01로 매우 작은 값이 된다. 이러한 결과가 나오는 이유는 현재의 신경망 구조가 '정답 단어 say에 대해서만 학습'했기 때문이다.
■ 따라서 현재 모델은 오답 단어에 대해서도 학습이 필요하다. 정답에 대한 Sigmoid 계층의 출력 결과는 1에 가깝게, 오답에 대한 Sigmoid 계층의 출력 결과는 0에 가깝게 반환하도록 모델 구조를 만들어야 역전파를 통해 완전한 모델 학습을 수행할 수 있기 때문이다.
■ 즉, 이진 분류기이므로 정답과 오답 각각에 대해 바르게 이진 분류할 수 있어야 한다.
■ 또한, 타깃 단어가 들어왔을 때 Sigmoid 계층의 출력 결과를 1에 가깝게, 오답인 단어가 들어왔을 때 Sigmoid 계층의 출력 결과를 0에 가깝게 만들어주는 가중치도 필요하다.
■ 만약, 모든 오답을 사용해 이진 분류 모델을 학습시킨다면 어휘 수가 늘어날 경우, 계산량을 감당할 수 없다. 그러므로 근사적인 방법으로 오답의 예를 몇 개 선택(샘플링)한다. 이 방법이 바로 '네거티브 샘플링'이다.
■ 네거티브 샘플링 기법은 '정답을 타깃으로 한 경우의 손실'과 '선택한 오답들에 대한 손실'을 구한 후, 각각의 손실을 모두 더한 값을 최종 손실로 사용한다.
■ 예를 들어 정답 단어 'say'외에 오답 단어 'and'와 'hello'를 사용했을 때 네거티브 샘플링 과정은 다음과 같다.
( Sigmoid 계층과 Binary Cross Entropy Error 계층을 합쳐 Sigmoid with Loss 계층으로 나타냄.)

■ 위의 그림처럼 정답 단어에 대해서는 t=1, 오답 단어에 대해서는 t=0을 입력하여 정답 단어와 적은 수의 오답 단어에 대해 모델이 학습할 수 있도록 한다.
■ 그리고 각 단어의 손실을 모두 더해 최종 손실을 산출한다.
3.5 네거티브 샘플링의 샘플링 기법
■ 모델 학습에 사용할 오답 단어 샘플링은 말뭉치의 단어 빈도를 기준으로, 말뭉치에서 자주 등장하는 단어는 많이 추출하고 빈도수가 적은 단어는 적게 추출한다.
■ 말뭉치에서 단어별 출현 횟수에 대한 확률분포를 구한 다음, 이 확률분포에 따라 샘플링을 수행하면 된다. 이때, 샘플링할 개수는 데이터 셋의 크기에 따라 다르며, 일반적으로 학습 데이터 셋이 작으면 5~20개, 크면 2~5개를 선택한다.
■ 확률분포대로 샘플링하기 때문에 고빈도 단어가 선택될 가능성은 높고, 저빈도 단어가 선택될 가능성은 낮다.
■ 만약, 저빈도 단어'만' 선택된 상태에서 모델이 학습된다면 좋은 결과를 얻을 수 없다. 실제 문장에서 저빈도 단어의 출현은 희소하기 때문이다.
■ 따라서 이런 경우에는 저빈도 단어 대신, 흔히 출현되는 단어로 학습하는 것이 더 좋은 결과를 얻을 수 있다.
■ 파이썬에서 np.random.choice( ) 메서드를 사용해서 확률분포에 따른 샘플링을 수행할 수 있다.
## 확률분포에 따라 샘플링
words = ['you', 'say', 'goodbye', 'and', 'i', 'hello', '.']
p = [0.1, 0.07, 0.06, 0.5, 0.04, 0.2, 0.03] # 단어 순서대로 각 단어의 확률분포가 p와 같다고 했을 때
print(np.random.choice(words, p = p, size = 3, replace = True)) # 3개만 무작위 샘플링(중복 허용 o)
print(np.random.choice(words, p = p, size = 3, replace = False)) # 3개만 무작위 샘플링(중복 허용 x)
```#결과#```
['you' 'and' 'hello']
['goodbye' 'and' 'hello']
````````````■ word2vec의 네거티브 샘플링에서는 출현 확률이 낮은 단어도 어느 정도 확률을 높여 샘플링하기 위해 확률분포에 0.75를 제곱한다.
[1310.4546] Distributed Representations of Words and Phrases and their Compositionality
Distributed Representations of Words and Phrases and their Compositionality
The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships. In this paper we present several extens
arxiv.org
P′(wi)=P(wi)0.75n∑jP(wj)0.75 - 분자는 기존 확률분포의 각 원소에 0.75를 제곱한 값이다.
- 수정한 '확률'분포를 구하는 것이므로 총합은 1이 되어야 한다.
- 따라서 일종의 스케일로 분모에 수정한 확률분포의 총합을 사용한다.
- 0.75에 특별한 의미는 없다. 다른 값으로 제곱해도 된다. 단, 0에 가까울수록 모든 확률이 비슷해질 것이다.
p = [0.1, 0.07, 0.06, 0.5, 0.04, 0.2, 0.03]
new_p = np.power(p, 0.75)
new_p = new_p / np.sum(new_p)
print(new_p)
```#결과#```
[0.11931971 0.09131365 0.08134402 0.3989695 0.06001464 0.20067103
0.04836744]
````````````- 수정 전 확률이 0.03이던 원소가 수정 후 0.0483...으로 확률이 높아졌다.
3.6 네거티브 샘플링 구현과 개선된 word2vec 구현
word2vec 속도 개선 - 네거티브 샘플링 구현, 개선된 word2vec 구현
'딥러닝' 카테고리의 다른 글
| 순환 신경망(RNN) (1) (0) | 2025.01.06 |
|---|---|
| 합성곱 신경망(CNN) (2) (0) | 2024.12.06 |
| 단어의 의미를 파악하는 방법 (4) (0) | 2024.11.22 |
| 단어의 의미를 파악하는 방법 (2) (0) | 2024.11.21 |
| 단어의 의미를 파악하는 방법 (1) (0) | 2024.11.20 |



