[2308.11432] A Survey on Large Language Model based Autonomous Agents
A Survey on Large Language Model based Autonomous Agents
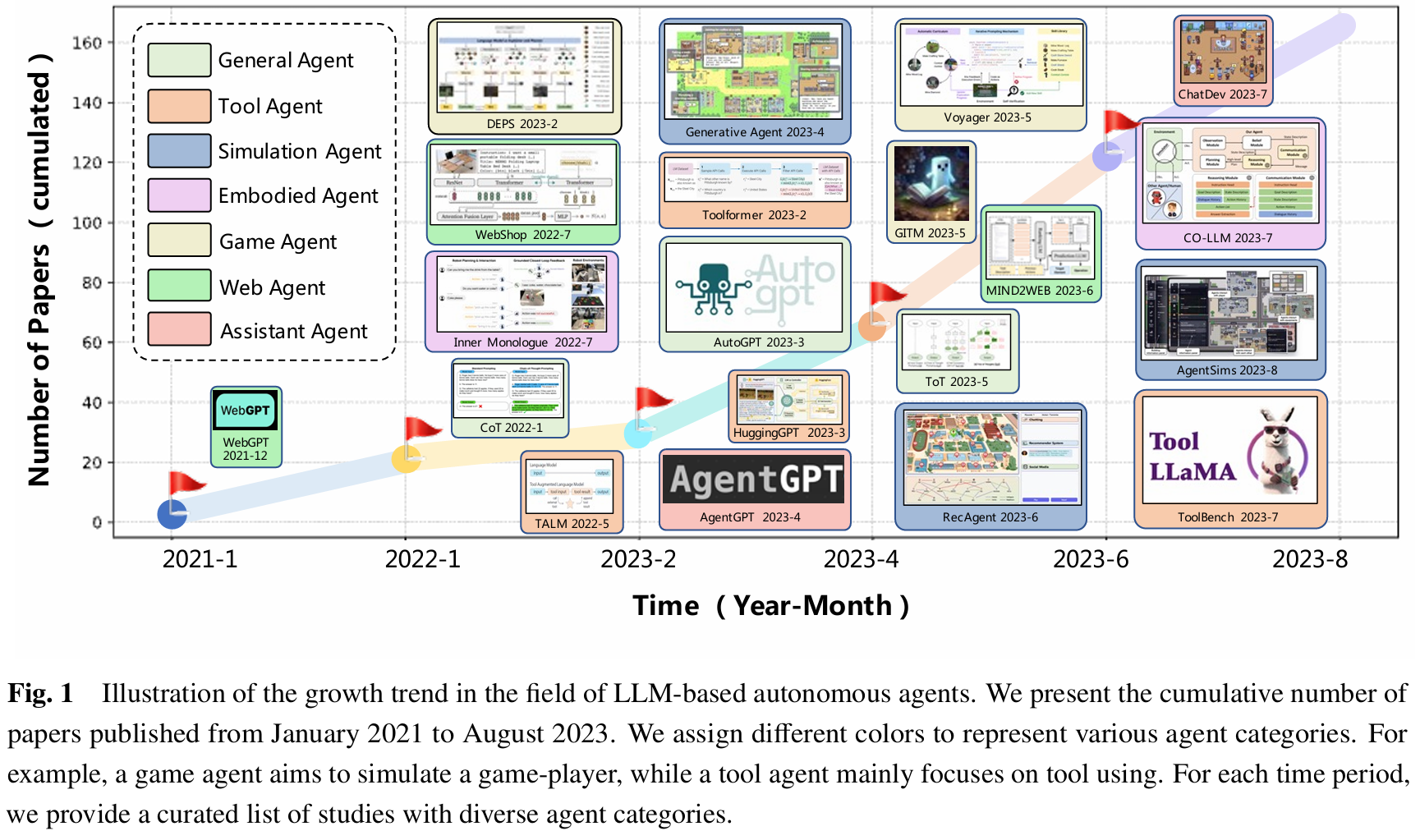
Autonomous agents have long been a prominent research focus in both academic and industry communities. Previous research in this field often focuses on training agents with limited knowledge within isolated environments, which diverges significantly from h
arxiv.org
1. Introduction
■ LLM이 발전하면서 인간과 유사한 의사 결정 능력을 얻기 위해 LLM을 central controllers로 사용하여 자율 에이전트를 구축하는 연구 분야가 성장하고 있다.
■ LLM-based agents의 장점은
- (1) 포괄적인 internal world knowledge를 보유하고 있어 특정 도메인 데이터로 별도 학습하지 않아도 합리적인 행동을 수행할 수 있다.
- (2) 자연어 인터페이스를 통해 사람과 상호작용할 수 있으므로 유연성과 설명 가능성이 높다.
■ 이러한 방향에 따라 수많은 연구들이 등장했으며, 특히 LLM에 "memory"와 "planning" 같은 인간의 능력을 부여하여 인간처럼 행동하고 다양한 tasks을 수행할 수 있는 에이전트를 만들고 있다.
■ 이 서베이에서는 LLM-based autonomous agents의 구성, 응용, 평가 세 가지 핵심 측면을 정리한다.
■ 그리고 에이전트 구성과 관련하여 (1) LLM을 더 잘 활용하기 위한 에이전트 아키텍처를 설계하는 방법 (2) 다양한 tasks를 수행하기 위해 에이전트의 역량을 향상시키는 방법에 초점을 둔다.
2. LLM-based Autonomous Agent Construction
■ LLM-based autonomous agent의 목표는 LLM의 인간과 유사한 능력을 활용하여 다양한 tasks을 효과적으로 수행하는 것이다.
■ 이 목표를 달성하기 위해 두 가지 중요한 측면이 있다.
- (1) LLM을 더 잘 활용하기 위해 "어떤 아키텍처를 설계해야 하는가"
- (2) 설계된 아키텍처가 주어졌을 때 "에이전트가 특정 작업을 완수하기 위한 역량을 어떻게 획득하게 할 것인가"
2.1 Agent Architecture Design
■ LLM은 question-answering (QA) 형태에서 광범위한 tasks을 잘 수행할 수 있는 잠재력을 보여주었다. 그러나 자율 에이전트는 단순한 QA와는 거리가 멀다.
■ 왜냐하면 에이전트는 단순히 답변만 생성하는 것이 아니라, 특정 역할을 수행해야 하고 마치 인간처럼 환경을 스스로 인식하고, 환경으로부터 배우고 스스로 진화해야 하기 때문이다.
■ 이 차이가 LLM과 LLM-based agent의 차이이다. 이 간극을 메우기 위해서는, LLM이 자신의 능력을 극대화할 수 있도록 돕는 합리적인 에이전트 아키텍처를 설계하는 것이다.
■ 이러한 방향으로 이전 연구들은 수많은 모듈들을 개발해 왔다. 이 섹션에서는 이러한 모듈들을 요약하는 통합 프레임워크를 제안한다. (Fig 2)

■ 저자들이 제시한 통합 프레임워크는 네 개의 모듈로 구성된다: profiling module, memory module, planning module, action module
- (1) 프로파일링 모듈의 목적은 에이전트의 역할을 정의하는 것이다.
- (2) 메모리와 플래닝 모듈은 에이전트를 동적인 환경 속에 배치하여, 과거의 행동을 회상하고 미래의 행동을 계획할 수 있게 한다.
- (3) 액션 모듈은 에이전트의 결정을 구체적인 output으로 변환하는 역할을 담당한다.
- 이러한 모듈들의 관계를 보면, 프로파일링 모듈은 메모리 및 플래닝 모듈에 영향을 미치며, 이 세 가지 모듈은 종합적으로 모여 액션 모듈에 영향을 준다. 즉, 액션은 프로파일링 + 메모리 + 플래닝의 결과로 나온다는 것이 저자들의 관점이다.
2.1.1 Profiling Module
■ 자율 에이전트는 일반적으로 coders, teachers, 도메인 전문가와 같은 특정 역할을 맡아 tasks을 수행한다.
■ 프로파일링 모듈은 이러한 에이전트의 역할의 프로필을 지정하는 것을 목표로 하며, 이는 보통 프롬프트 내에 작성되어 LLM의 행동 방식에 직접적인 영향을 미친다.
■ 저자들은 에이전트 프로필에 들어가는 정보를 크게 세 부류로 본다: 나이, 성별, 직업과 같은 기본 정보, 에이전트의 성격을 반영하는 심리 정보, 그리고 에이전트 간의 관계를 나타내는 사회적 정보
■ 어떤 프로필 정보를 넣을지는 주로 애플리케이션 시나리오에 따라 달라진다.
- 예를 들어 고객 응대 에이전트라면 직업적 역할과 말투가 중요할 수 있고, 사람의 인지 과정을 연구하는 것을 목표로 하는 에이전트라면 심리 정보가 중추적인 역할을 하게 된다.
■ 위의 예시와 같이 시나리오에 따라 프로필에 어떤 종류의 정보가 필요한지 정했다면, 그 다음으로 중요한 문제는 "그 구체적인 프로필을 어떻게 만들 것인가"이다. 기존 연구들은 주로 다음과 같은 세 가지 프로필 생성 전략을 사용한다.
Handcrafting Method
■ 에이전트 프로필을 사람이 직접 수동으로 지정하는 방식이다. 프롬프트에 명시하여 전달해서 에이전트를 프로파일링한다.
■ 이러한 수작업 방식은 에이전트 프로필을 구체화하기 위해 많은 연구들에서 활용되었다.
- 예를 들어, Generative Agent는 에이전트를 이름, 목표, 다른 에이전트와의 관계와 같은 정보로 기술한다.
- 다양한 역할과 그에 상응하는 책임들을 미리 정의하고, 시스템 내 협업을 목표로 각 에이전트에게 뚜렷하게 구별되는 프로필을 수동으로 할당한 연구들도 있다.
■ 전반적으로 수작업 방식은 에이전트에게 상상할 수 있는 어떠한 프로필 정보도 부여할 수 있기 때문에 매우 유연하다. 그러나 다수의 대규모 에이전트를 다뤄야 할 때는 매우 많은 수작업이 요구된다.
■ 정리하면, 정밀하게 제어할 수 있다는 것이 장점이지만 확장성이 약하다는 단점이 있다.
LLM-generation Method
■ 에이전트 프로필을 LLM이 자동으로 생성하는 방식이다.
■ 이 방식은 먼저 에이전트 프로필이 어떤 구성과 속성을 가져야 하는지 "프로필 생성 규칙"을 지시하는 것으로 시작한다.
■ 그런 다음, 몇 개의 'seed 에이전트 프로필'을 작성해서 LLM에게 few-shot examples로 제공한다.
■ 마지막으로 LLM은 "생성 규칙"과 "examples"을 기반으로, 자신의 생성 능력을 활용하여 수많은 에이전트 프로필을 생성한다.
■ 즉, 위의 수작업 방식과 다르게, 규칙과 예시를 설계하고 대량의 프로필 생성은 LLM에게 맡기는 방식이기 때문에 확장성이 좋다.
- 예를 들어 RecAgent에서는 나이, 성별, 개인적 특성, 영화 취향과 같은 속성을 사람이 직접 작성하여 에이전트들에 대한 시드 프로필을 먼저 만든 다음, ChatGPT를 활용하여 이 시드 정보를 바탕으로 대량의 에이전트 프로필을 자동 생성한다.
■ 그러나 이 방식은 수작업 방식의 장점이었던, 사람의 정밀한 제어가 어렵다는 점이다. 이로 인해 의도한 특성과 어긋나는 일관성 없는 설정이나 편차가 발생할 수 있다.
■ 정리하면, 이 방식은 확장성이 뛰어나고 대량 생성이 쉽지만, 제어와 일관성에서는 handcrafting보다 약할 수 있다.
Dataset Alignment Method
■ real-world의 데이터셋으로부터 에이전트 프로필을 추출하는 방식이다.
■ 일반적으로 데이터셋에 있는 실제 인간에 대한 정보(통계, 설문 결과 등)를 먼저 자연어 프롬프트로 가공한 다음, 이를 활용하여 에이전트를 프로파일링한다.
■ 예를 들어, American National Election Studies (ANES) 참여자들의 인구통계학적 배경(인종/민족, 성별, 연령, 거주 주 등)을 그대로 가져와 GPT-3에 역할을 부여한 다음, GPT-3가 투표나 정치적 견해에 있어 실제 인간과 유사한 결과를 내는지 조사한 연구가 있다.
■ 이 방식은 실제 인구집단의 속성을 과장이나 편견 없이 정확하게 반영하므로, 실제 현실 세계의 시나리오를 반영한 에이전트의 행동을 만들 수 있다. 즉, 이 방식의 가장 큰 장점은 현실성이다.
■ 이전 연구의 대부분은 위의 프로필 생성 전략들을 각각 독립적으로 활용했지만, 저자들은 이 방법들을 결합하면 추가적인 이점을 얻을 수 있다고 주장한다.
■ 예를 들어 사회 발전을 예측하는 시뮬레이션을 하려면, 현재 사회를 정확히 반영하기 위해 일부 에이전트는 real-world dataset으로 프로파일링하고, 동시에 현실에는 아직 없지만 미래에 등장할 수 있는 직업이나 역할들(예: 화성 이주민)을 handcrafting으로 추가할 수 있으며, 이 예시 외에도 연구 목적에 따라 다른 전략들을 유연하게 조합할 수 있다고 설명한다.
■ 이러한 프로필 모듈은 전체 에이전트 설계의 가장 밑바닥이 되는 기초 역할을 하며, 이후 진행될 에이전트의 memorization, planning, 그리고 action procedures에 지대한 영향을 미치게 된다.
2.1.2 Memory Module
■ 메모리 모듈은 에이전트 아키텍처 설계에서 매우 중요한 역할을 한다. 환경으로부터 인식한 정보를 저장하고, 기록된 기억을 활용하여 미래의 행동을 원활하게 한다.
■ 다시 말해, 메모리 모듈은 에이전트가 경험을 축적하고, 스스로 진화하며, 보다 일관되고 합리적인 방식으로 행동하도록 만든다.
■ 이 섹션에서는 메모리 모듈의 structures, formats, operations에 대해 설명한다.
Memory Structures
■ LLM-based autonomous agents 중 일부는 인간의 기억 과정에 영감을 받아서 받아 설계되었다.
■ 인간 기억은 지각적인 입력을 등록하는 감각 기억(sensory memory)에서 시작하여, 정보를 일시적으로 유지하는 단기 기억(short-term memory)을 거쳐, 장기간에 걸쳐 정보를 유지하는 하는 장기 기억(long-term memory)으로 이어지는 프로세스를 따른다.
■ 논문에서는 메모리 구조를 크게 두 가지로 나눈다: unified memory와 hybrid memory
• Unified Memory
■ unified memory는 인간의 단기 기억만 흉내 내는 구조이다. 일반적으로 in-context learning을 통해 구현되고 memory 정보가 프롬프트에 작성된다.
■ 즉, 별도의 저장소를 두지 않고, agent가 당장 알아야 할 기억을 현재 프롬프트에 넣어서 행동하게 만드는 방식이다.
- 예를 들어, 대화형 에이전트인 RLP는 화자와 청자의 internal state를 유지하고, 각 대화 턴마다 internal state를 LLM prompt에 넣어서 사용해서 short-term memory을 수행한다.
- SayPlan은 planning 에이전트인데, scene graph와 environment feedback가 short-term memory 역할을 한다.
- CALYPSO는 scene description, monster information, previous summary로 short-term memory를 구성한다.
- DEPS는 마인크래프트 에이전트인데, 먼저 task plan을 만들고, 그 plan을 다시 LLM prompt로 써서 행동을 생성한다. 여기서는 plan 자체가 short-term memory로 사용된다.
■ 논문에 따르면 unified memory의 장점은
- (1) 설계와 구현이 쉽다: 별도의 저장소 없이 prompt engineering만으로도 memory 기능을 어느 정도 만들 수 있다.
- (2) 최근 정보를 반영하기 쉽다: agent가 방금 본 것, 방금 실패한 것, 현재 환경 상태 같은 것에 바로 반응하기 좋다.
- (3) 현재 맥락에 민감한 행동을 인지하는 에이전트의 능력을 향상시킬 수 있다.
■ 그러나 LLM의 제한된 context window는 포괄적인 기억을 통째로 프롬프트에 넣는 것을 제한한다. 그 결과 에이전트의 performance가 떨어질 수 있다.
■ 이러한 한계는 더 큰 context window를 갖고 확장된 context를 처리할 수 있는 LLM을 필요로 한다.
■ 결과적으로, 이 문제를 완화하기 위해 많은 연구들이 하이브리드 메모리 시스템으로 방향을 전환하고 있다.
• Hybrid Memory
■ hybrid memory는 short-term memory와 long-term memory를 둘 다 명시적으로 두는 구조이다.
■ short-term memory는 최근의 인식을 일시적으로 저장하는 반면, long-term memory는 시간이 지남에 따라 중요한 정보는 통합하여 보존한다.
- 예를 들어, hybrid memory 구조를 사용하는 Generative Agent의 경우 short-term memory에는 에이전트의 현재 상황에 대한 context information이 포함되어 있고, long-term memory에는 현재 일어나고 있는 이벤트와 연관지어 불러올 수 있는 에이전트의 과거 행동과 생각들이 저장된다.
- AgentSims에서는 프롬프트에 제공되는 정보를 short-term memory에 담는다. 그리고 long-term memory로는 vector database를 사용한다.
- 구체적으로, 에이전트의 기억들을 임베딩으로 인코딩하어 vector database에 저장하고, 에이전트가 이전 기억을 회상해야 할 경우 임베딩 유사도를 사용하여 관련 정보를 검색한다.
- SCM은 복잡한 문맥의 대화에서 추론을 하기 위해, short-term memory와 결합할 가장 관련성 높은 long-term knowledge만을 선택적으로 활성화한다.
- SimplyRetrieve는 user의 쿼리를 short-term memory로, private knowledge base를 long-term memory로 사용한다. 이 설계는 사용자의 개인정보를 보호할 수 있므며 모델의 정확도를 높인다.
■ 이러한 hybrid memory의 장점은 short-term memory와 long-term memory를 통합해서 사용할 수 있다는 점이다. 그래서 에이전트의 'long-range reasoning' 능력과 'accumulation of valuable experiences' 능력을 강력하게 향상시킬 수 있다.
■ 얼핏 생각하면 long-term memory만 있는 구조도 가능해 보일 수 있다. 그러나 저자들은 그런 유형이 기록된 경우가 없다고 말한다.
■ 그리고 그 이유를 추측하기를, 에이전트는 대체로 "연속적이고 동적인 환경 속에 있고, 연속된 행동들 사이의 상관이 높기 때문"이라고 설명한다.
■ 그래서 최근 상태를 반영하는 short-term memory를 무시하기 어렵다는 것이다. 즉, 에이전트는 과거의 큰 경험만 기억한다고 되는 것이 아니라, 방금 무슨 일이 일어났는지도 알아야 한다.
Memory Formats
■ 여기서는 memory를 저장하는 format에 대해 설명한다. 같은 memory라도 자연어, 임베딩 벡터, 데이터베이스나 리스트 구조로 저장할 수 있다. 다양한 memory formats은 저마다 고유한 강점을 지니고 있다.
• Natural Languages
■ 이 방식은 에이전트의 행동 및 관찰과 같은 memory 정보가 raw natural language로 저장한다.
■ 장점은 두 가지이다
- (1) memory 정보를 사람이 읽고 이해하기 쉽다.
- (2) 의미론적 정보가 풍부하다. 즉, 어떤 일이 발생했는지를 비교적 풍부하게 남길 수 있어서, 이후 에이전트가 행동할 때 더 종합적인 힌트를 줄 수 있다.
■ Reflexion에서는 경험적 피드백을 자연어로 sliding window에 저장했고, Voyager는 마인크래프트 게임 내의 skills을 표현하기 위해 자연어 설명으로 memory에 저장했다.
• Embeddings
■ 여기서는 memory 정보를 embedding vectors로 인코딩하여 저장한다. 이 방식의 장점은 검색 및 읽기 효율성이다.
• Databases
■ memory는 데이터베이스에 저장된다. 에이전트는 SQL문을 활용하여 memory 정보를 정밀하게 추가, 삭제 및 수정할 수 있다.
• Structured Lists
■ memory 정보를 리스트나 트리 같은 구조로 정리해 두는 방식이다. 장점은 정보를 간결하고 효율적으로 정리할 수 있다는 점이다.
■ 위의 네 가지는 대표적인 memory formats이다. programming code 같은 다른 형식도 활용될 수 있다.
■ 중요한 점은, 이런 format들이 서로 배타적이지 않다는 것이다. 즉 에이전트는 하나의 format만 쓰지 않고 여러 format들을 섞어 쓸 수 있다.
Memory Operations
■ 아래는 외부 환경과 상호작용하는 데 사용되는 memory operations에 대한 내용이다.
• Memory Reading
■ memory reading의 목적은 저장된 memory들 중에서 에이전트의 행동 향상에 도움이 되는 의미 있는 정보를 꺼내 오는 것이다. 예를 들어 유사한 목표를 달성하기 위해, 이전에 성공했던 행동을 다시 사용하는 경우가 있다.
■ memory 읽기의 핵심은 과거 행동들로부터 가치 있는 정보를 "어떻게" 추출해 낼 것인가에 있다.
■ 일반적으로 정보 추출을 위해 널리 사용되는 세 가지 기준이 있는데, 바로 recency, relevance, importance이다.
■ 더 최근이고, 더 관련성이 높으며, 더 중요한 memory일수록 추출될 가능성이 높다.
■ 식 (1)은 memory 정보 추출을 위한 방정식이다.
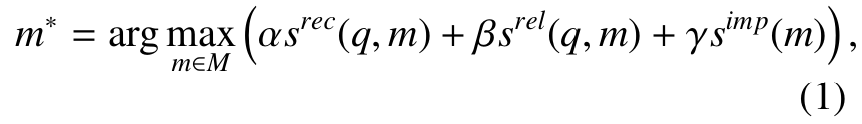
■ \( q \)는 쿼리이다. 에이전트가 처리해야 할 task이거나, 에이전트가 놓인 상황이다. \( M \)은 저장된 모든 memory의 집합이다.
■ \( s^{rec} ( \cdot ) \), \( s^{rel} ( \cdot ) \), \( s^{imp} ( \cdot ) \)는 memory \( m \)의 recency, relevance, importance를 측정하는 scoring functions이며, 점수가 높을수록 각각 더 최근의 기억, 더 관련 있는 기억, 더 중요한 기억임을 의미한다.
■ 식에서 볼 수 있듯이, \( s^{imp} \)는 memory 자체의 특성만을 반영하여 query \( q \)와는 무관하다.
■ 이러한 scoring functions은 다양한 방법으로 구현될 수 있다. 예를 들어 \( s^{rel} (q, m) \)은 query와 memory embeddings 간의 vector similarity를 사용하여 계산할 수 있다.
■ \( \alpha, \beta, \gamma \)는 세 점수를 얼마나 중시할지 정하는 가중치이다. 이 가중치들에 서로 다른 값을 할당함으로써 다양한 memory reading 전략들을 사용할 수 있다.
- 예를 들어 \( \alpha = \gamma = 0 \)으로 설정하면, 오직 \( s^{rel} \)만 고려하게 된다.
- \( \alpha = \beta = \gamma = 1.0 \)을 할당한다면, 이는 recency, relevance, importance 세 가지 지표를 모두 동등하게 반영한다.
• Memory Writing
■ memory writing의 목적은 에이전트가 환경에서 지각한 정보를 memory에 저장하는 것이다.
■ memory에 가치 있는 정보를 저장해 두어야 미래에 그것을 다시 꺼내 활용할 수 있고, 그 결과 에이전트가 더 효율적이고 합리적으로 행동할 수 있다.
■ memory writing 과정에는 두 가지 중요한 문제가 있다.
- (1) memory duplicated: 기존 memories과 유사한 정보가 새롭게 들어왔을 때, 이를 어떻게 저장할 것인가
- (2) memory overflow: 저장 공간이 가득 찼을 때 무엇을 지우고 무엇을 남길 것인가
(1) Memory Duplicated
■ 유사한 정보를 통합하기 위해, 새 기록과 이전 기록을 결합하는 다양한 방법들이 개발되었다.
- 예를 들어 GITM에서는 sub-goal과 관련된 성공적인 action sequences을 리스트에 쌓아 두다가(즉, 리스트 형태로 저장하다가), 리스트의 크기가 \( N = 5 \)에 도달하면, LLM을 사용하여 그 안의 모든 sequences을 압축하여 하나의 통합된 plan solution으로 응축시킨다.
- Augmented LLM은 중복된 내용들을 저장하는 대신, 단순히 중복된 횟수를 누적하는 방식으로 중복 정보를 집계하여 불필요한 것은 버려서 저장 공간의 낭비를 방지했다.
(2) Memory Overflow
■ memory가 가득 찼을 때, 새로운 정보를 저장하기 위해 기존 정보를 어떻게 삭제할지 결정해야 한다. 이 문제에 대해 여러 삭제 전략이 존재한다.
- 예를 들어 ChatDB에서는 사용자 명령에 따라 memory를 명시적으로 삭제한다.
- RET-LLM은 fixed-size buffer를 사용하고, FIFO 방식으로 가장 오래된 항목을 덮어쓴다.
• Memory Reflection
■ memory reflection은 인간이 자신의 인지적, 감정적, 행동적 과정을 관찰하고 평가하는 능력을 모방한 것이다.
■ 이를 에이전트에 적용할 때의 목표는, 에이전트가 더 추상적이고 복잡하며 고차원적인 정보를 독립적으로 요약하고 추론할 수 있게 만드는 것이다.
- 예를 들어 Generative Agent에서는 최근 memories을 기반으로 세 가지 핵심 질문을 먼저 생성한다.
- 그런 다음, 이 질문들을 사용해 memory를 쿼리하여 관련 정보를 얻는다.
- 획득한 정보를 바탕으로 에이전트는 자신의 고차원적 아이디어를 반영하는 다섯 개의 insight를 생성한다.
- 예를 들어, "클라우스 뮐러는 연구 논문을 쓰고 있다", "클라우스 뮐러는 연구를 진행하기 위해 사서와 대화하고 있다", "클라우스 뮐러는 아이샤 칸과 그의 연구에 대해 논의하고 있다"라는 1차원적인 low-level의 memories은 "클라우스 뮐러는 그의 연구에 전념하고 있다"라는 high-level insight로 요약될 수 있다.
■ 그리고 reflection 과정은 hierarchical하게 일어날 수 있다. 즉, 기존의 insights을 바탕으로 그 위에 새로운 insights을 생성할 수 있다는 것이다.
■ 다시 말해, low-level memories에서 high-level insights을 만들고, 다시 그 high-level insights로부터 더 상위의 insight를 만들 수 있다.
- 예를 들어 GITM에서는 sub-goals을 성공적으로 완수한 actions이 리스트에 저장된다.
- 이 리스트에 5개 이상의 항목이 쌓이면, 에이전트는 이를 공통적이면서 추상적인 패턴으로 요약한 다음, 원래의 항목들을 모두 그 요약본으로 교체해버린다.
- ExpeL에서는 두 가지 접근 방식이 도입되었다. 하나는 에이전트가 동일한 task 내에서 성공한 trajectories과 실패한 trajectories을 비교하는 방식이다. 다른 하나는 여러 성공적인 trajectories의 모음으로부터 학습하여 경험을 쌓는 것이다.
■ 전통적인 LLM과 에이전트 사이의 가장 큰 차이점은, 에이전트가 동적인 환경에서 학습하고 task를 완수할 수 있는 능력을 반드시 갖추어야 한다는 것이다.
■ memory module이 에이전트의 "과거" 행동을 관리하는 역할을 담당한다고 본다면, 에이전트가 "미래" 행동을 계획하도록 지원할 수 있는 또 다른 중요한 모듈을 갖추는 것이 필수적이 된다. 이 모듈을 planning module이라고 부른다. (섹션 2.1.3)
2.1.3 Planning Module
■ 복잡한 task에 직면했을 때, 인간은 이를 더 단순한 subtasks로 분해하고 각각을 개별적으로 해결하는 경향이 있다.
■ planning module은 이러한 인간의 능력을 에이전트에게 부여하는 것을 목표로 하며, 이를 통해 에이전트가 더 합리적이고, 강력하고, 신뢰할 수 있게 행동할 것으로 기대할 수 있다.
■ 기존 연구들은 크게 피드백 없이 계획하는 방식과 피드백을 받으며 계획을 수정하는 방식으로 나뉜다.
Planning without Feedback
■ 이 방법에서 에이전트는 액션을 취한 후 미래의 행동에 영향을 줄 수 있는 피드백을 외부로부터 받지 않는다. 아래는 몇 가지 대표적인 strategies이다.
• Single-path Reasoning
■ 이 전략에서 final task를 여러 개의 intermediate steps로 나눈다. 이 steps은 계단식 방식으로 연결되며, 각 step은 오직 '하나의' subsequent step으로만 이어진다.
■ 이 single-path의 대표 예가 CoT(Chain of Thought)이다. CoT는 복잡한 문제를 푸는 reasoning steps을 프롬프트에 예시로 넣어, LLM이 step-by-step 방식으로 계획하고 답하게 만든다.
■ 즉, 모델이 예시를 통해 intermediate steps를 따라하도록 만드는 것이다.
■ Zero-shot-CoT는 프롬프트에 예시 reasoning steps을 주지 않지만, "think step by step"과 같은 트리거 문장으로 LLM을 프롬프팅하여 reasoning processes을 스스로 생성하게 한다.
■ Re-Prompting은 plan을 생성하기 전에 각 step이 필수 전제 조건을 충족하는지 확인하는 과정이 있다.
■ 만약 어떤 step이 전제 조건을 충족하지 못하면, 오류 메시지를 통해 LLM이 다시 plan을 생성하도록 유도한다.
■ ReWOO에서는 plans을 외부의 관찰 결과와 분리하는 패러다임을 도입했다. 먼저 plans을 생성하고 observations을 독립적으로 얻은 다음, 이들을 결합하여 최종 결과를 도출한다.
■ HuggingGPT는 먼저 task를 여러 sub-goals로 분해한 다음, 각각을 해결한다.
■ 모든 reasoning steps을 한 번의 생성으로 출력하는 CoT나 Zero-shot-CoT와 달리, ReWOO와 HuggingGPT는 LLM을 여러 번 호출하여 결과를 산출한다.
■ SWIFTSAGE는 dual-process theory에서 영감을 받아, 복잡한 interactive tasks에서의 planning을 위해 학습된 패턴을 기반으로 quick responses을 제공하는 SWIFT 모듈과, LLM을 사용해 핵심적인 질문을 던지고 action sequence를 만드는 더 깊은 planning을 수행하는 SAGE 모듈을 결합한다.

• Multi-path Reasoning
■ 이 방식은 final plans을 생성하기 위한 reasoning steps이 tree와 같은 구조로 정리된다. 각 intermediate step은 여러 개의 subsequent steps을 가질 수 있다.
■ 사람도 매 추론 단계마다 여러 가지 선택지를 가질 수 있기 때문에, 이 접근법은 인간의 사고방식과 매우 유사하다.
■ 예를 들어, self-consistent CoT (CoT-SC)는 하나의 문제에 대해 여러 개의 reasoning path가 나올 수 있다고 보고, CoT를 사용하여 다양한 reasoning paths과 그에 상응하는 answers을 생성한다. 그런 다음, 가장 빈도수가 높게 나온 answer를 final output으로 선택한다.
■ Tree of Thoughts (ToT)는 tree-like reasoning structure를 사용하여 plans을 생성하도록 설계되었다. 이 접근법에서 트리의 각 노드는 'thought'을 나타내며, 이는 intermediate reasoning step에 해당된다.
■ 이러한 intermediate steps 중 무엇을 선택할지는 LLM의 평가를 기반으로 결정된다. final plan은 BFS 또는 DFS를 통해 생성된다. 모든 steps을 한번에 생성하는 CoT-SC와 비교할 때, ToT는 각 reasoning step마다 LLM에 생성을 요청해야 한다.
■ RecMind는 planning process 과정에서 버려진 과거의 정보까지 활용해 새로운 reasoning steps을 만드는 self-inspiring 메커니즘을 제안했다.
■ Graph of Thoughts (GoT)는 ToT의 트리 구조 추론을 그래프 구조로 확장한다.
■ Algorithm of Thoughts (AoT)는 프롬프트에 algorithmic examples을 통합하여 LLM의 추론 과정을 향상시키는 새로운 방법을 제시했다. 이 방법은 LLM 호출을 1~2회 정도로 줄인다는 점이 특징이다.
• External Planner
■ LLM이 zero-shot planning 능력을 보이기는 하지만, domain-specific problems에 대한 plans을 효과적으로 생성하는 것은 여전히 어려운 문제이다.
■ 이 문제를 해결하기 위해 이미 잘 개발된 외부의 planners을 사용하는 연구들이 등장하기 시작했다. 효율적인 탐색 알고리즘을 사용하여 정확하거나 최적화된 계획을 빠르게 찾아낼 수 있다.
■ 예를 들어 LLM+P는, 먼저 task descriptions을 Planning Domain Definition Languages (PDDL)로 변환한 다음, 외부의 플래너를 통해 이 PDDL을 처리한다. 마지막으로, 생성된 결과는 LLM에 의해 다시 자연어로 변환된다.
■ 이와 유사하게, LLM-DP는 LLM을 활용하여 관찰 결과, 현재 세계의 상태, 그리고 달성할 목표를 PDDL로 변환한다. 그 후 이 변환된 데이터를 외부 플래너에 넘겨 final action sequence를 결정한다.
■ CO-LLM은 LLM이 high-level plans을 생성하는 데는 능숙하지만, low-level control에는 약하다고 보고, 이를 보완하기 위해 휴리스틱하게 설계된 external low-level planner를 사용한다.
Planning with Feedback
■ real-world의 많은 scenarios에서 에이전트는 복잡한 tasks을 해결하기 위해 장기적인 계획을 세워야 한다.
■ 이러한 tasks에 직면했을 때, 위의 planning without feedback은 다음과 같은 이유로 덜 효과적일 수 있다.
- (1) 다양하고 복잡한 전제 조건들을 모두 고려해야 하므로 처음부터 결함 없는 완벽한 계획을 단번에 생성하는 것은 매우 어렵다.
- (2) 예측하지 못한 상태 변환가 생겨 원래 계획이 아예 실행 불가능해질 수 있다.
■ 인간은 외부의 피드백을 기반으로 계획을 반복적으로 세우고 수정한다. 이러한 인간의 능력을 모방하기 위해, 에이전트가 액션을 취한 후 피드백을 받을 수 있는 다양한 planning modules이 등장했다.
■ 이때 피드백은 환경, 인간, 그리고 모델 자체로부터 얻을 수 있다.
• Environmental Feedback
■ 이 피드백은 objective world나 virtual environment로부터 얻어진다. 예를 들어 게임의 작업 완료 신호이거나 에이전트가 특정 액션을 취한 후 얻게 되는 관찰 결과일 수 있다.
■ 가장 대표적인 예가 ReAct이다. ReAct는 프롬프트를 'thought-act-observation'의 삼중 구조로 만든다.
- thought은 에이전트의 행동을 유도하기 위한, high-level reasoning과 planning
- act는 에이전트가 실제로 취한 행동. observation은 외부 피드백을 통해 획득한, 그 행동의 결과이다.
■ 그다음 이어지는 thought은 이전의 observations의 영향을 받으며, 그 결과 plan은 환경에 보다 적응적으로 조정된다.
■ Voyager는 environmental feedback을 더 세분화해서 사용한다. Voyager는 (1) 프로그램 실행의 중간 진행 상황 (2) 실행 오류 (3) 그리고 self-verification 결과를 포함한 세 가지 유형의 환경 피드백을 통합하여 plans을 세운다.
■ 이렇게 실행 과정에서 발생하는 신호들은 에이전트가 다음 액션을 위해 더 나은 계획을 세우는 데 도움을 줄 수 있다.
■ Voyager와 유사하게, Ghost 역시 reasoning 및 action 과정에 피드백을 넣는다. 이 피드백에는 환경의 상태뿐만 아니라, 실행된 각 액션의 성공 및 실패 정보가 포함된다.
■ SayPlan은 scene graph simulator에서 나오는 피드백으로 자신의 전략을 검증하고 수정한다. 이 simulator는 에이전트의 액션들에 뒤따르는 결과와 상태 변화를 파악하고, 실행 가능한 계획이 나올 때까지 전략을 반복 보정한다.
■ DEPS는 여기서 더 나아가, 단순 작업 완료 여부만 알려주는 것은 planning errors을 고치기에 부족한 경우가 많다고 보고, 에이전트에게 작업 실패에 대한 구체적인 이유까지 사용하여 계획을 보다 효과적으로 수정하게 한다.
■ LLM-Planner는 실행 중 object mismatch나 도달 불가능한 plan에 직면했을 때 LLM이 생성한 계획을 동적으로 업데이트하는 grounded re-planning 알고리즘을 도입한다.
■ Inner Monologue는 에이전트가 액션들을 취한 후 (1) task가 성공적으로 완료되었는지 여부 (2) passive scene descriptions (3) active scene descriptions이라는 세 가지 유형의 피드백을 사용한다.
■ environmental feedback에 대해 정리하면
- (1) 액션 결과를 next plan에 반영해야 한다.
- (2) 피드백은 단순 성공/실패 시그널을 넘어 상태 변화, 실행 에러, 실패 이유, scene descriptions 처럼 다양할수록 유용하다.
- (3) 이런 피드백 덕분에 에이전트의 planning은 일회성 추론이 아니라, 반복적 재조정 과정이 된다.
• Human Feedback
■ 환경으로부터 피드백을 얻는 것 외에도, 인간과 직접 상호작용하는 것 역시 에이전트의 planning 능력을 향상시키는 매우 직관적인 전략이다.
■ 이는 에이전트가 인간의 가치 및 선호도와 정렬되도록 유도할 수 있으며, hallucination 문제를 완화하는 데도 도움을 준다.
■ Inner Monologue에서 에이전트는 3D 환경에서 high-level natural language instructions을 수행하는 것을 목표로 한다.
■ 이 에이전트에게는 장면에 대한 설명과 관련해 인간에게 피드백을 요청할 수 있는 기능이 부여되어 있으며, 인간의 피드백을 프롬프트에 통합하여 보다 합리적인 planning과 reasoning을 가능하게 한다.
■ Inner Monologue에서 환경적 피드백과 인간의 피드백을 모두 수집해서 사용하는 것처럼, 에이전트의 planning 능력을 향상시키기 위해 다양한 유형의 피드백을 결합해서 사용할 수 있다.
• Model Feedback
■ 외부 신호은 environmental 및 human feedback과는 별개로, 에이전트 스스로 생성하는 내부 피드백을 활용한 연구들도 있다. 이러한 유형의 피드백은 대게 pre-trained models을 기반으로 생성된다.
■ 가장 기본적인 예가 self-refine이다. 이 메커니즘은 output, feedback, refinement라는 세 가지 요소로 이루어진다.
■ 에이전트가 output을 생성하면, LLM으로 해당 output에 대한 피드백을 제공하고 이를 개선하는 방법에 대한 guidance를 제공한다.
■ 피드백과 개선 과정을 통해 output이 향상된다. 이때, output-feedback-refinement 과정은 루프를 돌아 특정 조건에 도달할 때까지 반복된다.
■ SelfCheck은 에이전트가 다양한 단계에서 생성된 자신의 추론 단계들을 스스로 검사하고 평가한다. 그런 다음 결과들을 비교하여 모든 오류를 수정한다.
■ InterAct는 메인 LM이 잘못되거나 비효율적인 액션들을 피할 수 있도록, 서로 다른 언어 모델(ChatGPT 및 InstructGPT 등)을 checker 및 sorter와 같은 보조 역할로 사용한다.
■ Reflexion은 디테일한 verbal feedback을 통해 에이전트의 planning 능력을 향상시킨다.
■ 이 모델에서 에이전트는 먼저 memory를 바탕으로 액션을 생성하고, 그런 다음 evaluator가 에이전트의 trajectory를 입력으로 받아 피드백을 생성한다.
■ 피드백이 단순한 스칼라 값으로 주어졌던 과거의 강화학습 기반 연구들과 달리, 이 모델은 LLM을 활용하여 더 디테일한 verbal feedback을 사용한다는 점이 큰 특징이다.
■ 정리하면, 피드백이 없는 planning은 구현은 구현이 비교적 간단하다. 그러나 이는 적은 수의 추론 단계만을 요구하는 단순한 task에 적합하다.
■ 피드백을 포함하는 planning 전략은 피드백을 수집하고 처리하기 때문에 설계가 더 까다롭다. 대신 이 방식은 비교할 수 없을 만큼 훨씬 더 강력하며, long-range reasoning이 수반되는 복잡한 tasks을 해결할 수 있는 능력을 에이전트에게 부여한다.
2.1.4 Action Module
■ action module은 에이전트의 결정을 구체적인 결과로 변환하는 역할을 담당한다.
■ 이 모듈은 가장 아키텍처의 가장 하위 위치에 자리 잡고 있으며 환경과 직접 상호 작용한다. 또한, profile, memory, and planning 모듈의 영향을 종합적으로 받는다.
■ 이 섹션에서는 네 가지 관점에서 action module을 소개한다.
- (1) Action goal: 액션의 의도된 결과는 무엇인가
- (2) Action production: 액션은 어떻게 생성되는가
- (3) Action space: 에이전트가 취할 수 있는 액션의 종류는 무엇인가
- (4) Action impact: 액션이 초래하는 결과는 무엇인가
■ 저자들은 이 네 가지를 시간 흐름으로 나눈다: (1)과 (2)는 "before-action", (3)은 "in-action", (4)는 "after-action"
Action Goal
■ 에이전트는 다양한 objectives을 가지고 actions을 수행할 수 있다. 몇 가지 대표적인 예시는 다음과 같다: Task Completion, Communication, Environment Exploration
(1) Task Completion
■ Task Completion은 가장 전형적인 objective이다. 말 그대로 에이전트의 액션이 어떤 과제를 완료하기 위해 수행되는 경우이다. 예를 들어 마인크래프트에서 철 곡괭이를 제작하거나, 코드 작성에서 특정 함수를 완성하는 것이 있다.
■ 이 경우 액션들은 대게 명확하게 정의된 objectives을 가지고 있으며, 각각의 액션은 final task를 완료하는 데 기여한다.
(2) Communication
■ 다른 에이전트나 인간과의 정보 공유나 협업을 위해 사용된다.
■ 예를 들어, ChatDev의 에이전트들은 소프트웨어 개발 작업을 위해 에이전트들이 서로 의사소통한다.
■ Inner Monologue에서는 에이전트는 인간과 적극적으로 소통하고, human feedback에 따라 자신의 액션 전략을 조정한다.
(3) Environment Exploration
■ 에이전트는 익숙하지 않은 환경을 탐색하여 자신의 지각 범위를 넓히고, exploring과 exploiting 사이의 균형을 맞추는 것을 목표로 한다.
■ Voyager의 에이전트는 task completion 과정에서 아직 알지 못하는 skills을 탐색하고, 시행착오를 통한 환경 피드백을 기반으로 skill execution code를 계속 다듬는다.
Action Production
■ 모델의 input과 output이 1:1로 연결되는 일반적인 LLM과 달리, 에이전트는 다양한 strategies과 sources을 통해 actions을 취할 수 있다.
■ 일반적으로 사용되는 두 가지 action production strategies은 다음과 같다: (1) Action via Memory Recollection (2) Action via Plan Following
(1) Action via Memory Recollection
■ 이 전략에서 액션은 현재 task에 맞는 정보를 에이전트의 memory에서 추출함으로써 생성된다. 현재 task와 extracted memories이 결합되어 에이전트의 actions을 유도하는 프롬프트로 사용된다.
■ 예를 들어, Generative Agents에서 에이전트는 memory stream을 유지하고, 각각의 액션을 취하기 전에 memory stream으로부터 가장 최근의(recent), 관련성(relevant)이 높고 중요(important)한 정보를 검색하여 액션을 수행한다.
■ GITM에서는 low-level의 sub-goal을 달성하기 위해 에이전트가 memory를 쿼리하여 해당 task와 관련된 성공적인 경험이 있는지 확인한다. 만약 이전에 유사한 task를 성공적으로 완료한 적이 있다면, 에이전트는 이전에 성공했던 행동을 그대로 호출하여 현재 task를 처리한다.
■ ChatDev 및 MetaGPT와 같은 협업 에이전트 시스템에서는 여러 다른 에이전트들이 서로 의사소통할 수 있다. 이 과정에서 진행된 대화 기록은 에이전트의 memories에 저장된다. 에이전트가 내뱉는 각각의 발언은 바로 이 memory의 영향을 받아 생성된다.
■ 정리하면, Action via Memory Recollection은 과거의 경험을 기반으로 action을 생성한다. 그래서 비슷한 상황(경험했던 상황)에서 빠르고 일관된 행동을 만들기 쉽다는 장점이 있다. 특히 이전에 성공한 경험이 있을 때 강하다.
(2) Action via Plan Following
■ 이 전략에서 에이전트는 자신이 미리 생성해 둔 plans을 엄격하게 따라 actions을 취한다.
■ 예를 들어, DEPS에서는 주어진 task에 대해 에이전트가 가장 먼저 action plans을 세운다. plan failure를 알리는 신호가 없다면, 에이전트는 이 초기 plans을 엄격히 따른다.
■ GITM에서 에이전트는 task를 여러 sub-goals로 분해하여 high-level plans을 세운 다음, 이것들을 바탕으로 final task를 완료하기 위해 각 sub-goal을 순차적으로 해결해 나가는 actions을 취한다.
Action Space
■ action space는 에이전트가 수행할 수 있는 "가능한 actions의 집합"이다. 저자들은 이를 크게 두 부류로 나눈다: (1) external tools and (2) LLM의 internal knowledge
• External Tools
■ LLM은 포괄적이고 전문적인 knowledge가 필요한 도메인에서는 제대로 작동하지 않을 수 있다. 게다가 LLM은 스스로 해결하기 매우 힘든 hallucination 문제에 직면할 수도 있다.
■ 이러한 문제들을 완화하기 위해, 에이전트에게는 액션을 실행할 때 external tools을 호출할 수 있는 능력이 부여된다. 몇 가지 대표적인 tools은 다음과 같다.
(1) APIs
■ 외부 API를 활용하여 action space를 보완하고 확장할 수 있게 되었다.
■ HuggingGPT는 Hugging Face의 모델 생태계를 연결해 task를 처리한다.
■ WebGPT는 사용자 요청에 응답할 때, 외부 웹 페이지에서 관련 콘텐츠를 추출하기 위해 자동으로 검색 쿼리를 생성한다.
■ Gorilla는 API 호출을 위한 input arguments을 생성할 수 있도록 파인튜닝된 LLM을 도입하여, 외부 API를 사용할 때 발생하는 hallucination 문제를 효과적으로 완화한다.
■ Toolformer는 API demonstration을 학습 데이터로 사용한 self-supervised learning을 통해, 외부 tools을 언제, 어떻게 호출할지 학습한다.
■ API-Bank는 tool-augmented된 LLM을 체계적으로 평가하기 위한 다양한 API tools을 포함한 벤치마크와 데이터셋을 제공한다.
■ ToolLLaMA는 데이터 수집, 학습, 평가를 포괄하는 tool-use framework을 제안하며, 그 결과 파인튜닝된 모델이 광범위한 API에서 뛰어난 성능을 달성했다.
■ RestGPT는 RESTful API와 LLM을 연결하여, 프로그램이 현실 세계의 애플리케이션과 더 잘 호환되도록 만들었다.
■ 이러한 지능형 에이전트들은 외부 API를 전략적으로 도구화함으로써, action space를 확장하고 다양한 계산 능력을 통합하여 전통적인 LM의 근본적인 한계를 보완한다.
(2) Databases & Knowledge Bases
■ 외부의 database나 knowledge base를 통합하면, 에이전트는 특정 도메인에 대한 정보를 얻을 수 있어 보다 현실적인 actions을 생성할 수 있다.
■ ChatDB는 SQL 문을 사용하여 데이터베이스를 쿼리함으로써 에이전트가 논리적인 방식으로 행동할 수 있도록 한다.
■ MRKL과 OpenAGI는 knowledge bases 및 planners와 같은 다양한 expert systems을 통합하여 domain-specific information에 접근한다
(3) External Models
■ 가능한 actions의 범위를 확장하기 위해 외부의 모델을 활용한 연구들이 있다. API와 비교했을 때, 외부 모델은 일반적으로 훨씬 더 복잡한 task를 처리한다. 각각의 외부 모델은 여러 개의 API에 대응될 수 있다.
■ ViperGPT는 먼저 언어 모델 기반으로 구현된 Codex를 사용하여 text descriptions으로부터 파이썬 코드를 생성한다. 그리고 해당 코드를 직접 실행하여 주어진 task를 수행한다.
■ ChemCrow는 신약 개발, 유기 합성 등 화학과 관련된 tasks을 처리하도록 설계된 LLM 기반의 화학 에이전트이다. 이 에이전트는 전문가가 설계한 17개의 전용 모델을 활용한다.
■ MM-REACT는 비디오 요약을 위한 VideoBERT, 이미지 생성을 위한 X-decoder, 오디오 처리를 위한 SpeechBERT와 같은 다양한 외부 모델을 통합하여 multimodal 시나리오에서의 역량을 향상시킨다.
• Internal Knowledge
■ 외부 tools을 활용하는 것 외에도, 많은 에이전트들은 actions을 이끌기 위해 오직 LLM의 internal knowledge에만 전적으로 의존하기도 한다.
■ 여기서는 에이전트가 보다 합리적이고 효과적으로 행동하도록 뒷받침하는 LLM의 몇 가지 핵심 능력을 소개한다.
(1) Planning Capability
■ 기존 연구들은 LLM이 복잡한 문제를 더 단순한 문제로 분해하는 planner로 사용될 수 있음을 보여주었다. LLM의 이러한 능력은 프롬프트에 examples을 포함시키지 않더라도 이끌어낼 수 있다.
■ DEPS는 이러한 LLM의 planning 능력을 기반으로, sub-goal 분해를 통해 복잡한 task를 해결할 수 있는 마인크래프트 에이전트를 개발했다.
■ GITM 및 Voyager와 같은 에이전트들 역시 다양한 task를 수행하기 위해 LLM의 planning 능력에 크게 의존한다.
(2) Conversation Capability
■ LLM은 일반적으로 매우 high-quality의 conversations을 생성할 수 있다. 이 능력 덕분에 에이전트는 더 사람처럼 행동할 수 있다. 많은 에이전트들은 LLM의 강력한 대화 능력을 기반으로 action을 취한다.
■ ChatDev에서는 서로 다른 에이전트들이 소프트웨어 개발 과정에 대해 토론하고 자신들의 actions을 성찰한다.
■ RLP에서 에이전트는 자신의 발언에 대한 청자의 잠재적인 피드백을 예측하여 청자와 소통할 수 있다.
(3) Common Sense Understanding Capability
■ LLM의 중요한 능력 중 하나는 인간의 common sense를 잘 이해할 수 있다는 것이다. 이 능력을 기반으로 많은 에이전트들은 인간의 일상생활을 시뮬레이션하고 human-like 같은 결정을 내릴 수 있다.
■ Generative Agent는 자신의 현재 상태와 주변 환경을 이해하고 기본적인 관찰을 바탕으로 high-level의 ideas을 요약할 수 있다.
■ LLM의 common sense understanding 능력이 없다면 이러한 행동들을 신뢰할 수 있는 수준으로 시뮬레이션할 수 없다.
Action Impact
■ action impact는 에이전트가 취한 actions의 consequences을 의미한다.
■ 다양한 impacts이 있지만, 여기서는 몇 가지 핵심적인 것들만 설명한다: (1) Changing Environments (2) Altering Internal States (3) Triggering New Actions
(1) Changing Environments
■ action이 외부 환경의 상태를 직접적으로 바꿀 수 있다.
■ 예를 들어 에이전트가 이동하면 → 위치가 바뀌고, 아이템을 수집하면 → 그 자원은 환경에서 사라지고, 건물을 지으면 → 환경에 새로운 구조물이 생긴다.
(2) Altering Internal States
■ 에이전트가 취한 actions은 memories을 업데이트하거나, 새로운 plans을 수립하거나, 새로운 knowledge를 습득하는 등 에이전트 '자기 자신'을 변화시키기도 한다.
(3) Triggering New Actions
■ task completion processes에서 하나의 action은 종종 그 뒤를 잇는 subsequent actions으로 이어지기도 한다.
■ 예를 들어, Voyager에서 에이전트가 필요한 자원을 모두 모으고 나면, 그것은 즉시 건물을 건설하는 새로운 action을 trigger하게 된다.
2.2 Agent Capability Acquisition
■ 2.1의 아키텍처는 에이전트의 "하드웨어"에 해당한다.
■ 효과적인 task 수행을 위해서는 하드웨어만으로는 충분하지 않다. task별 필수 역량, skills, 경험이 부족할 수 있기 때문이다. 이러한 요소들은 에이전트의 "소프트웨어" 리소스로 볼 수 있다.
■ 에이전트에게 이러한 리소스를 갖추게 하기 위해 다양한 전략이 고안되었다. 서베이에서는 이러한 전략들을 "LLM에 대한 파인튜닝이 필요한지 여부"에 따라 두 가지 클래스로 분류한다
Capability Acquisition with Fine-tuning
■ 에이전트의 task completion 역량을 향상시키는 직접적인 방법은 "task-specific datasets"으로 모델을 파인튜닝하는 것이다.
■ 이러한 데이터셋은 human annotations, LLM이 생성한 콘텐츠, 또는 real-world의 applications으로부터 구축될 수 있다.
• Fine-tuning with Human Annotated Datasets
■ 에이전트를 파인튜닝하기 위해, human annotated datasets을 활용하는 것은 다양한 애플리케이션 시나리오에 적용할 수 있는 접근법이다.
■ CoH는 LLM을 인간의 가치관 및 선호도와 align시키는 것을 목표로 한다. human feedback을 자연어 형태로 변환한 다음, LLM을 이러한 자연어 데이터셋에 파인튜닝시킨다.
■ RET-LLM에서는 자연어로 구조화된 memory 정보로 더 잘 변환하기 위해, 각 샘플이 "triplet-natural language" 쌍으로 구성된 human constructed dataset을 기반으로 LLM을 파인튜닝한다.
■ WebShop에서는 아마존에서 1.18 million의 real-world products을 수집하고, 인간 쇼핑 시나리오가 포함된 시뮬레이션 전자상거래 웹사이트에 이를 올려놓는다.
■ 이 웹사이트를 기반으로 13명의 작업자가 실제 인간의 행동 데이터셋을 수집한다. 마지막으로 이 데이터셋을 바탕으로 heuristic rules, imitation learning, reinforcement learning에 기반한 세 가지 방법을 학습시킨다.
■ 이 논문에서 제안된 데이터셋은 웹 쇼핑 분야에서 에이전트의 역량을 향상시킬 수 있는 잠재력을 가지고 있다.
■ EduChat은 open-domain question answering, essay assessment, Socratic teaching, emotional support와 같은 LLM의 교육적 기능을 향상시키는 것을 목표로 한다.
■ 다양한 교육적 시나리오와 tasks들을 포괄하는 human annotated datasets으로 LLM을 파인튜닝한다.
• Fine-tuning with LLM Generated Datasets
■ human-annotated datasets은 사람이 필요하며, 이는 특히 대규모의 작업을 다룰 때 막대한 비용이 들 수 있다.
■ 그래서 human-annotated의 대안으로 LLM-generated data를 사용하는 연구들이 등장하기 시작했다.
■ 이 방법으로 생성된 데이터셋은 인간이 annotation을 단 것만큼 완벽하지 않을 수 있지만, 비용이 훨씬 저렴하고 기하급수적으로 더 많은 샘플을 생성하는 데 사용되고 있다.
■ ToolBench에서는 오픈 소스 LLM의 tool 사용 능력을 향상시키기 위해 RapidAPI Hub에서 49개 카테고리에 걸쳐 16,464개의 API를 수집했다.
■ 그리고 single-tool과 multi-tool 시나리오를 모두 포함하는 다양한 instructions을 생성하도록 ChatGPT에게 이 API들을 프롬프트로 제공했다.
■ 이렇게 얻은 데이터셋을 기반으로 LLaMA를 파인튜닝하여, 결과적으로 tool 사용 측면에서 상당한 성능 향상을 얻었다.
■ 에이전트에게 사회적 역량을 부여하기 위한 연구가 있다. 여기서는 저자들이 하나의 샌드박스 환경을 만들고, 여러 에이전트를 그 안에 배치해 서로 상호작용하게 한다.
■ 어떤 social question이 주어지면, 중앙 에이전트가 먼저 초기 응답을 만들고, 그 응답을 주변 에이전트들에게 공유해 피드백을 받는다.
■ 중앙 에이전트는 피드백과 그 피드백에 대한 디테일한 설명을 바탕으로, 초기 응답이 사회적 규범에 더 맞도록 수정한다.
■ 이 과정 전반에 걸쳐 저자들은 대량의 agent social interaction data를 수집하며, 이 데이터는 이후 LLM을 파인튜닝하는 데 활용된다.
• Fine-tuning with Real-world Datasets
■ human/LLM annotations을 기반으로 데이터셋을 구축하는 것 외에도, real-world의 데이터셋을 사용하여 에이전트를 파인튜닝하는 것 역시 일반적인 방법이다.
■ MIND2WEB에서는 웹 도메인에서 에이전트의 역량을 향상시키기 위해 대량의 실제 데이터셋을 수집한다.
■ 구체적으로 31개 도메인에 걸친 137개의 실제 웹사이트에서 2,000개가 넘는 open-ended tasks을 수집한 다음, 이 데이터셋을 사용하여 영화 검색 및 티켓 예매와 같은 웹 관련 task에 대한 LLM의 성능을 향상시키기 위해 파인튜닝을 진행한다.
Capability Acquisition without Fine-tuning
■ model capability를 얻는 것에 대한 패러다임 전환은 Fig 4와 같다.

■ 전통적인 머신러닝의 시대에는 주로 데이터셋으로부터 학습함으로써 모델의 역량을 획득했으며, 이때 knowledge는 모델의 파라미터 내부에 인코딩되었다.
■ 그러나 LLM의 시대에는, 모델의 파라미터를 학습/파인튜닝하는 것은 물론이고, 정교한 프롬프트를 설계하는 것으로도 모델의 역량을 획득할 수 있다.
■ 프롬프트 엔지니어링에서는 모델의 역량을 향상시키거나 기존 LLM 안에 잠재된 능력을 끌어내기 위해 프롬프트에 가치 있는 정보를 자세하게 작성해야 한다.
■ 에이전트의 시대에 접어들면서, 모델의 역량은 세 가지 전략으로 획득할 수 있다: (1) 모델 파인튜닝 (2) 프롬프트 엔지니어링 (3) 적절한 에이전트 evolution mechanisms을 설계하는 것 (서베이에서는 이를 mechanism engineering이라고 부른다)
■ mechanism engineering은 specialized modules을 개발하고, 새로운 working rules을 도입하며, 에이전트의 능력을 끌어올리기 위한 strategies을 모두 포괄하는 광범위한 개념이다.
• Prompting Engineering
■ LLM의 language comprehension capabilities 덕분에 사람들은 자연어를 사용하여 LLM과 직접 상호작용할 수 있다.
■ 이 점을 이용한 전략은, 에이전트가 갖추었으면 하는 능력을 자연어로 설명한 프롬프트를 제공하여, 에이전트가 그에 맞는 방식으로 행동하도록 유도하는 것이다.
■ CoT에서는 에이전트에게 reasoning 능력을 부여하기 위해, 프롬프트 내에 intermediate reasoning steps을 few-shot examples로 사용한다. 비슷한 테크닉들이 CoT-SC, ToT에서도 사용된다.
■ RLP에서는 대화 중 에이전트 자신의 정신 상태와 청자의 정신 상태 모두에 대한 beliefs을 프롬프트로 제공함으로써, 대화에서 에이전트의 self-awareness을 향상시키는 것을 목표로 한다. 이를 통해 더 매력적이고 상황에 잘 맞는 에이전트의 발언을 이끌어낸다.
■ Retroformer는 에이전트가 과거의 실패에 대한 reflections을 생성할 수 있게 해주는 retrospective model을 제시한다. 이 내용은 에이전트의 미래 행동을 가이드하기 위해 LLM의 프롬프트에 통합된다.
• Mechanism Engineering
■ 모델 파인튜닝이나 프롬프트 엔지니어링과 달리, 메커니즘 엔지니어링은 에이전트의 역량을 향상시키는 매우 독특한 전략이다. 대표적인 방법들은 다음과 같다.
(1) Trial-and-error
■ 이 방법에서 에이전트는 먼저 액션을 수행하고, 그 직후에 사전 정의된 critic가 호출되어 해당 액션을 판단한다.
■ 액션이 만족스럽지 않다고 판단되면, 에이전트는 critic의 피드백을 통합하여 다시 react한다.
■ RAH에서 에이전트는 추천 시스템의 assistant 역할을 한다.
■ 에이전트의 중요한 역할 중 하나는 인간의 행동을 시뮬레이션하고 사용자를 대신해 responses을 생성하는 것이다.
■ 이 목표를 달성하기 위해 에이전트는 먼저 predicted response를 생성한 다음 이를 실제 human feedback과 비교한다.
■ predicted response과 real human feedback을 비교한 결과 서로 다를 경우, critic은 실패 정보를 생성하며 이는 에이전트의 next action에 통합된다.
■ DEPS에서 에이전트는 먼저 주어진 task를 완수하기 위한 plan을 설계한다. plan 실행 과정에서 action이 실패할 경우, explainer가 실패 원인을 설명하는 정보를 생성한다. 이 정보는 plan을 다시 설계하기 위해 에이전트에 통합된다.
■ PREFER는 에이전트의 성능이 떨어질 때, LLM이 자세한 피드백을 만들어 반복적인 개선 및 성능 향상을 돕는다.
(2) Crowd-sourcing
■ 에이전트의 능력을 향상시키기 위해 wisdom of crowds을 활용하는 토론 메커니즘을 설계한 연구(Multiagent Debate)가 있다.
■ 우선, 서로 다른 에이전트들이 주어진 질문에 대해 개별적인 답변을 생성한다. 만약 생성된 답변들이 일치하지 않는다면, 에이전트들은 다른 에이전트들의 솔루션을 참고해 업데이트된 답변을 출력한다.
■ 이 반복적인 과정은 최종적인 합의 도출에 도달할 때까지 계속된다. 이 방법에서 각 에이전트의 역량은 다른 에이전트들의 의견을 이해하고 수용함으로써 크게 향상된다.
(3) Experience Accumulation
■ 이름 그대로 경험 축적을 통해 능력을 키우는 방식이다.
■ GITM에서 에이전트는 처음에는 task 해결 방법을 모르는 상태이다. 에이전트는 계속해서 환경을 탐색하며, task를 성공적으로 완수하고 나면, 성공에 사용된 액션들을 에이전트의 memory에 저장한다.
■ 성공 정보를 memory에 저장했기 때문에, 훗날 에이전트가 이와 유사한 task를 만나면 관련 memory들을 추출해서 사용할 수 있다.
■ Voyager는 특정 스킬에 대한 실행 가능한 코드들이 환경과의 상호작용을 통해 정제되고 저장되는 'skill library'를 도입하여, 시간이 지남에 따라 경험이 축적된 에이전트가 효율적으로 task를 실행할 수 있게 한다.
■ AppAgent에서는 에이전트를 마치 human user처럼 앱과 상호작용하도록 만들기 위해, 자율적인 탐색과 human demonstrations에 대한 관찰로 knowledge base를 만들고 모두 학습시킨다.
■ MemPrompt는 문제 해결과 관련하여 사용자에게 자연어로된 피드백을 제공하도록 요청하고, 사용자의 자연어 피드백을 memory에 저장했다가 비슷한 문제에 직면했을 때 관련된 memory를 검색한다.
(4) Self-driven Evolution
■ 이 방법은 self-directed learning과 feedback mechanisms을 통해 에이전트가 스스로 발전할 수 있도록 한다.
■ LMA3는 에이전트가 스스로 목표를 설정할 수 있게 하며, 환경을 탐색하고 reward function으로부터 피드백을 받음으로써 능력을 점진적으로 향상시킨다.
■ 이 메커니즘을 따르면 에이전트는 자신만의 선호도에 따라 knowledge를 습득하고 능력을 키울 수 있다.
■ SALLM-MS는 GPT-4와 같은 advanced LLMs을 multi-agent system에 통합하여, 에이전트들이 환경에 적응하고 복잡한 tasks을 수행하며 높은 의사소통 능력을 선보이게 함으로써, 환경과의 상호 작용 속에서 자기 주도적으로 진화한다.
■ CLMTWA에서는 LLM을 teacher로, teacher보다 weaker LM이 student가 되어 자연어 설명을 통해 reasoning skill을 개선한다.
■ agent capability를 얻기 위해 언급된 전략들을 비교해 보면,
- (1) 파인튜닝 방식은 방대한 양의 task-specific knowledge를 흡수할 있는 모델 파라미터를 조정함으로써 에이전트의 역량을 향상시키지만, 이는 내부 가중치에 접근이 가능한 오직 오픈 소스 LLM에만 적합하다.
- (2) 파인튜닝이 없는 방식은 주로 정교한 프롬프팅 전략이나 메커니즘 엔지니어링을 기반으로 에이전트의 역량을 향상시킨다. 이 방법들은 (1)과 달리 오픈 소스 및 클로즈드 LLM 모두에 범용적으로 사용할 수 있다.
- 그러나 LLM의 context window size의 제한 때문에, 하나의 프롬프트에 너무 많은 정보를 넣을 수 없다는 단점이 있다.
- 게다가 주어진 문제에 대한 최적의 프롬프트와 메커니즘을 찾기가 쉽지 않기 때문에, 최적의 솔루션을 찾아내는 것이 결코 쉽지 않다.
'Agent' 카테고리의 다른 글
| A Survey on Large Language Model based Autonomous Agents (2) (0) | 2026.04.09 |
|---|