3. 통계학에서의 특이값 분해 응용
3.1 주성분 분석(PCA)
■ 다변량 자료분석 방법론 중 차원 축소는 여러 변수들에 담긴 복잡한 정보를 1차원이나 소수 몇 개의 차원으로 축소하여, 복잡한 다차원 구조를 단순화하고 보다 쉽게 이해할 수 있도록 만들기 위해 사용한다.
■ 이러한 차원 축소 기법의 대표적인 방법으로 주성분분석(Principal Component Analysis, PCA)이 있다.
- PCA를 통한 차원 축소의 결과로부터 얻어지는 주성분점수들은 군집분석, 회귀분석, 인자(factor)분석 등을 위한 입력자료로 이용되어, PCA는 어떤 일련의 분석 과정에서 하나의 중간단계 역할을 하기도 한다.
■ 주성분분석(PCA)은 서로 상관되어 있는(종속적인) n개의 변수들 간의 구조를 분석하기 위해서 n개의 변수들을 선형변환시켜 주성분(Principal Component, PC)이라고 부르는 서로 상관되어 있지 않은(독립적인) 새로운 인공(또는 가상)의 변수들을 유도하는 기법이다.
■ 원래 변수들의 변이를 결정하는 보다 낮은 차원의 서로 독립적인 요인을 성분(component)이라 한다.
■ 주성분분석에서는 원래 변수들(서로 상관되어 있는 변수들)이 가진 전체 변이(분산)에 대한 공헌도(설명력)를 순차적으로 최대화하도록 성분(component)들을 유도한다.
- 분산은 데이터들이 평균값을 중심으로 얼마나 퍼져 있는지를 나타내는 척도이다.
- PCA는 분산이 큰 방향이 데이터의 특성을 잘 반영한다는 아이디어를 기반으로, 모든 변수에 걸쳐 왼쪽 그림과 같이 퍼져 있는 데이터(관측값)들에 대해 오른쪽 그림과 같이 분산이 가장 큰 방향을 가리키는 주성분을 찾는다.

■ 차원 축소는 예를 들어, n개의 변수가 존재할 때, 이 변수들이 가지고 있는 정보는 n개의 축에 복잡하게 분포하여 나타난다.
■ 이렇게 나타나는 정보는 직관적으로 이해하기 어렵다. 그러므로 n개의 축을 1개의 축(1차원) 또는 소수 몇 개의 축(차원)으로 축소하여, 원래 n개의 변수들이 담고 있는 정보를 보다 쉽게 이해하려고 하는 것이 차원 축소의 아이디어이다.
■ 이는 예를 들어, 어떤 선형변환 T:U→V처럼 벡터공간 U의 모든 벡터 u를 선형변환을 적용하여 벡터공간 V의 모든 벡터 v에 대응시키게 만드는 것과 같다.
■ 이러한 선형변환을 바꿔 말하면, n차원 공간에 흩뜨려져 있는 점(data point)들을 새로운 축(주성분)에 사영(projection)시키는 것이며, 사영시켰을 때, 다음 그림과 같이 어떤 오차가 존재할 수 있다. 이때 손실되는 정보(분산)의 양이 적은 기저(축, 여기서의 기저는 주성분)를 찾는 것이 목표이다.
■ 투영(projection) 시, 손실되는 정보의 양이 가장 적게 되는 경우는 위의 그림처럼 축(주성분)에 직교투영(=정사영)시키는 것이다.
■ 그러므로 주성분분석은 n 차원 공간에 있는 흩뜨려져 있는 data point들을 직교최소제곱(orthogonal least square)의 개념에 따라 가장 잘 적합시키는 직선(또는 평면)을 찾기 위한 최적화 문제이다.
- 여기서 말하는, 가장 적합한 기저(축)을 찾았을 때 "직선"이라는 것은 위의 그림처럼 n차원 공간의 데이터들이 하나의 주성분(PC1) 위에 투영된 것을 의미한다.
- 가장 적합한 곳이 "평면"이라는 것은, 다음 그림처럼 최소 두 개의 주성분(PC1, PC2)로 구성된 평면에 데이터가 투영된 것을 의미한다.
■ 주성분분석을 이렇게 기존의 데이터들을 새로운 축(주성분)에 잘 적합시켜야 하는 문제로 본다면, 이는 기존의 데이터 포인트들을 새로운 축에 투영시켰을 때, 주성분이라는 축과 오차가 최소가 되게 만들어야 하는 문제로 볼 수 있다.
■ 즉, 주성분분석은 데이터를 근사할 때 평균제곱오차를 최소화하는 기저(주성분)를 찾는 문제로 볼 수 있다.
- 투영된 데이터 포인트를 실제값, 축(주성분) 위에 있는 값을 예측값이라고 생각했을 때, 모든 실제값과 예측값의 차이. 즉, 총 오차(total error)의 값은 '오차 = 실제값 - 예측값'으로 정의된 오차들을 모두 더하는 것으로 생각할 수 있다.
- 하지만, 단순히 '오차 = 실제값 - 예측값'으로 정의한다면, 오차값이 음수가 나오는 경우가 발생할 수 있다.
- 즉, '오차 = 실제값 - 예측값'으로 정의하면 오차를 모두 더하는 과정에서 오차값이 +(양수)가 되었다가 -(음수)가 되기를 반복하므로, 제대로 된 오차의 크기(실제값과 예측값의 차이)를 측정할 수 없다.
- 그러므로 오차를 단순히 모두 더하는 것이 아니라, 각 오차들을 제곱해 준 뒤에 전부 더해주는 방식으로 오차로서 음수가 나오는 것을 방지한다. 이를 수식으로 표현하면 다음과 같다.
n∑i=1(yi−ˆyi)2
-- 여기서 n은 데이터의 개수(샘플의 개수), yi는 실제(관측)값, ˆyi는 예측값(투영된 값)
■ n∑i=1(yi−ˆyi)2식에 데이터의 개수인 n으로 나누면 '오차의 제곱합에 대한 평균'을 구할 수 있다. 이를 평균제곱오차(Mean Squared Error, MSE)라고 한다. MSE의 식은 다음과 같다.
MSE=1nn∑i=1(yi−ˆyi)2
- 예를 들어 선형회귀 문제에서 MSE는 데이터 포인트들을 잘 설명할 수 있는. 즉, 오차가 최소가 되게 만드는 직선의 기울기와 편향을 찾기 위해 사용된다.
- 이 개념을 주성분분석에 대입하면 주성분분석의 문제는 투영된 데이터 포인트와 오차가 최소가 되는 축(주성분)을 찾는 문제로 볼 수 있다.
■ 평균제곱오차(MSE) 값이 최소화되려면 데이터에 이상치(outlier)가 존재해서는 안 된다.
■ 예를 들어 X1과 X2라는 변수를 주성분기저 1개에 투영시켰을 때, 다음과 같이 이상치가 존재한다고 가정하자. 이상치의 개수가 많아지면 많아질수록 평균제곱오차의 값은 점점 더 커질 것이다.
■ 즉, 주성분분석은 주성분분석은 데이터의 스케일(scale)에 민감하다. 그러므로 주성분분석을 수행하기 전에 데이터를 스케일링해야 한다.
cf) 그래서 주성분분석을 수행하기 앞서 이상치들을 제거하는 것이 일반적이다.
■ 평균제곱오차를 최소화하기 위한 스케일링 방법으로 평균 중심화는 관측값의 중심을 원점으로 모으기 때문에(=평균이 0을 갖도록 중심화하기 때문에) 특정 방향으로 편향되는 것을 방지할 수 있다.
- PCA를 수행하기 전에 평균 중심화를 적용한다. 그리고 필요에 따라 (기본) 표준화 또는 Z-score 표준화(표준정규분포) 등을 적용한다.
■ 평균 중심화는 변수의 관측값에서 그 평균을 빼주는 것이다. 즉, '평균 빼기'이다.
- 어떤 임의의 변수 X에 대응되는 n개의 관측값 x1,x2,⋯,xn이 주어질 때, 관측값의 평균 ¯x와 변수 X의 분산 Var(X)는 다음과 같다.
¯x=1nn∑i=1xi,Var(X)=1nn∑i=1(xi−¯x)2
- 평균 중심화는 변수(feature)의 n개의 샘플 x1,x2,⋯,xn에 대해 각각 ¯x를 빼주면 된다.
- 이때, 평균 중심화를 적용한 값들을 모아놓은 것을 편차 벡터 x=(x1−¯x,x2−¯x,⋯,xn−¯x)T라고 정의하면,
- 행렬의 곱이나 벡터의 내적을 이용하여 다음과 같이 변수 X의 분산을 나타낼 수 있다.
Var(X)=1nxTx=1n<x,x>
-- < a, b >는 벡터 a와 b의 내적
■ 주성분분석은 n개의 변수들을 선형변환시켜 주성분(Principal Component, PC)으로 유도하는 방법이라고 하였다.
■ 즉, n개의 여러 변수들이 X=(X1,X2,⋯,Xn), 주성분을 Z라고 할 때, Z=a1X1+a2X2+⋯+anXn으로 선형 결합을 통해 주성분 Z를 유도하는 것이다.
■ 여기서 가중치(가중계수)인 벡터 a=(a1,a2,⋯,an은 원래의 변수 X1,X2,⋯,Xn보다 더 유용한 정보를 보유할 수도 있고, 차원 축소는 물론 변수들 간의 관계를 단순화시키는 데 큰 역할을 한다.
■ 이때 사용되는 가중계수 a=a1,a2,⋯,an는 바로 고유벡터이다.
■ 주성분분석은 원래 공간에 있는 변수들이 가지고 있는 분산을 새로운 공간에서 소수의 가상 변수(주성분)로 최대한 근사 시키는 것이 목표이다.
■ 이는 데이터의 차원을 축소하면서도 원래 변수들이 가지고 있던 데이터 구조(분산)를 최대한 보존시킬(근사 시킬) 수 있는(또는 잘 설명하는) 주성분이라는 '축'을 찾는 방법이다.
■ 새로운 공간에서 원래 변수들이 가지고 있떤 분산을 표현하는 이 '축'의 방향은 고유벡터의 방향이며, 고윳값은 이 고유벡터의 크기를 조절하는 상숫값으로, '축'의 길이(크기)를 알려준다.
■ 즉, 분산이 퍼져 있는 방향을 알려주는 것은 고유벡터이다. 그리고 그 방향(고유벡터 방향)으로 분산이 얼마나 퍼져 있는지(크기) 알려주는 것이 고윳값이다. 그러므로 '고윳값의 합은 분산의 총량(원래 데이터의 총 분산)'이다.
■ 즉, 고유벡터와 원래 변수(벡터)의 선형 결합을 통해 분산이 퍼져 있는 방향으로 유도된 것이 주성분이라고 할 수 있다.
- 이때 사용되는 고유벡터를 PCA에서는 PC 로딩(Loading)이라고 부른다.
■ 고유벡터와 원래 변수(벡터)의 선형 결합을 통해 분산이 퍼져 있는 방향으로 유도된 것이 주성분이라면, 변수(feature)의 개수가 n개일 때, 제1 주성분을 Z1이라고 할 때, 제1 주성분은 다음과 같이 정의할 수 있다.
Z1=a11X1+⋯a1nXn
■ 여기서 PCA에서의 목표는 제1 주성분 Z1의 분산을 가능한 크게 만드는 것이다. 그래서 a211+⋯+a21n=1이라는 제약 조건이 붙는다.
■ Z1=a11X1+⋯a1nXn은 n개의 변수(feature)가 존재할 때, 조건 a211+⋯+a21n=1을 만족하면서 샘플들 간의 변동을 가능한 크게 만드는 원래 변수들 X1,⋯Xn의 선형 결합이라고 할 수 있다.
- 첫 번째 고유벡터를 a=(a211+⋯+a21n)라고 하면, 제약식 a211+⋯+a21n=1은 첫 번째 '고유벡터의 크기 = 1'이라는 제약으로 볼 수 있다.
■ a211+⋯+a21n=1이라는 제약 조건이 붙는 이유는, 고유벡터의 크기를 무시하기 위해서이다.
- 벡터는 '크기'와 '방향'이라는 두 가지 정보를 가지고 있다. 벡터의 크기를 1로 정규화(단위벡터화)하면, 벡터의 크기(길이)는 줄어들지만, 방향은 변하지 않는다.
- 고유벡터는 주성분의 '방향'을 나타낸다. 이 고유벡터의 크기를 1로 정규화하면, 고유벡터의 크기 정보는 제거되지만(정확히는 고유벡터 크기가 1이므로 큰 의미가 없다.), 중요한 '주성분의 방향'에 대한 정보는 변하지 않는다.
- 제약식 a211+⋯+a21n=1이 없으면, 상수 a1j 중 어떤 값을 계속 크게 할 때 주성분의 분산(이 예에서는 제1 주성분의 분산)은 계속 커지지만, 이것은 원래 변수 x1,⋯,xn의 영향 때문이 아니라 고유벡터의 크기 때문이다. 그러므로 고유벡터의 크기를 1로 제한하는 것이다.
- 제2 주성분, 제3 주성분, ⋯ 을 구할 때도 '고유벡터의 크기 = 1'이라는 제약 조건 하에 계산해야 한다.
- 또한, 주성분분석은 각 주성분들이 서로 상관관계가 없게끔 만들어야 한다. 즉, 주성분들이 서로 독립 관계를 가지게 만들어야 한다는 조건이 붙는다.
- 예를 들어 Z2를 만들 때, Z1과 Z2는 상관관계가 없다.(독립이다.)는 조건도 만족해야 하며,
- Z3은 Z1과 Z2 모두와 상관관계가 없다는 조건도 만족해야 한다.
- 추가 주성분들은 이와 같은 방식으로 계속 정의된다. 만약, 변수(feature)가 n개라면, 주성분도 n개이다.
■ 정리하면, a211+⋯+a21n=1이라는 제약 조건에 따라 고유벡터를 '단위'고유벡터로 제한함으로써, 주성분의 분산을 최대화하는 순수한 방향을 찾을 수 있다. 또는 주성분의 분산을 최대화하는 방향을 찾는 문제로 단순화되는 것으로 볼 수 있다.
■ 주성분분석을 위한 가중계수(고유벡터)는 일반적으로 변수들의 상관관계에 대한 정보를 가지고 있는 대칭행렬인 공분산행렬(또는 상관행렬)에 대한 고윳값 분해를 이용하여 구할 수 있다.
- 공분산행렬은 "대칭행렬이고 양의 준정부호이며, 주대각선에는 각 변수의 분산을, 대각선 이외의 원소는 가능한 모든 변수 쌍의 공분산을 나타내는" 행렬이다.
참고) https://hyeon-jae.tistory.com/193
확률변수의 기댓값과 분산, 공분산, 상관계수
1. 확률변수의 기댓값1.1 기댓값의 개념■ 확률변수의 기댓값은 '확률변수의 결과 값을 그 확률변수의 확률뷴포를 가중치로 평균한 값'으로 이산형 확률변수 X의 기댓값은 \(\mu_X = E(X) = \su
hyeon-jae.tistory.com
■ 그리고 대칭행렬에 대해서 특이값 분해(SVD)는 고윳값 분해와 같은 개념이다. 즉, 공분산행렬의 고윳값 분해 또는 공분산행렬의 특이값 분해를 사용하여 주성분분석을 수행할 수 있다.
3.2 상관 행렬, 공분산 행렬, 주성분분석
■ 예를 들어, 다음과 같은 고객만족 데이터가 있을 때, 주성분분석을 이용하여 변수들 간의 관련성을 분석한다고 하자.

- 총 변수의 수는 8개이고 그 중 2개는 범주형 변수, 나머지는 수치형 변수이다.
- 수치형 변수 중 'ID'라는 변수는 단순히 고객을 분류하기 위한 변수이기 때문에 제외하고 주성분분석을 수행한다.
■ 먼저 (피어슨) 상관관계는 다음과 같다.
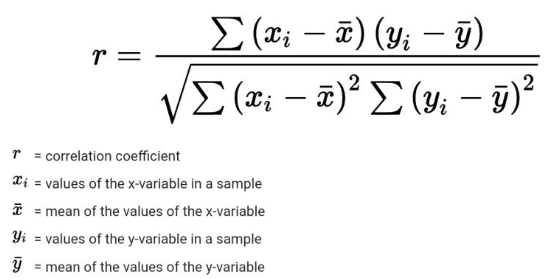
■ 식을 보면, 분자와 분모에 각 변수의 관측값에 대해 평균 중심화를 적용하는 것을 볼 수 있다. 이 정규화를 통해 상관계수의 범위는 -1 ~ +1이 된다.
■ 이때, 분자는 공분산이고, 두 변수의 공분산을 각각의 표준 편차의 곱으로 나누는 형태임을 알 수 있다. 이렇게 상관계수는 공분산을 각 확률변수의 표준편차로 나눔으로써 '측정 단위가 상쇄된다.' 즉, 상관계수는 측정 단위의 영향을 받지 않는다.
■ 상관계수를 구하는 방법은 위의 (피어슨) 상관계수의 식을 통해 계산할 수도 있으며, 다음과 같은 코사인 유사도를 이용하여 계산할 수도 있다.

■ 코사인 유사도에 대한 식과 피어슨 상관계수에 대한 식을 보면, 유일한 차이점은 코사인 유사도에는 평균 중심화를 적용하는 과정이 없다는 것이다. 즉, 피어슨 상관계수는 평균 중심화된 코사인 유사도로 볼 수 있다.
- 데이터에 평균 중심화를 적용한 후, 코사인 유사도를 계산한 결과는 피어슨 상관계수와 동일하다.
■ 예를 들어, 예시 데이터의 각 수치형 변수에 대해 표준화를 적용하여 평균 0 & 표준편차 1인 변수로 만들면 다음과 같다.

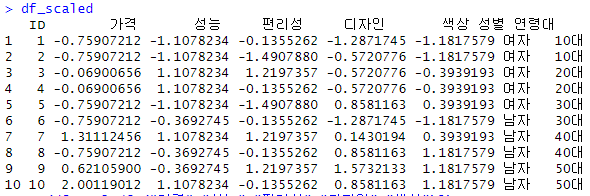
■ 위의 df_scaled는 평균 중심화가 적용된 상태이다. 이때, 수치형 변수에 5개(가격, 성능, 편리성, 디자인, 색상)에 대한 편차 벡터(평균 중심화된 관측값들)를 t1,t2,⋯,t5라고 하자.

■ 이제 두 편차 벡터 ti와 tj에 코사인 유사도를 적용하여 상관계수를 얻을 수 있다.
■ 이때, 두 편차 벡터에 대해 코사인 유사도를 적용했으므로, 계산된 결과는 코사인 유사도가 아니라 상관관계이다.
■ 앞서, 명시한 바와 같이 상관관계의 범위는 -1에서 +1이다. 그리고 값이 -1에 가까우면 음의 상관관계가 높다고 할 수 있으며, +1에 가까우면 양의 상관관계가 높다고 할 수 있다. 그리고 값이 0이면 상관관계가 없다고 할 수 있다.
- 이때, 계산되는 코사인 유사도는 편차 벡터에 대한 코사인 유사도이다. 그러므로 코사인 값이 결과로 나온다.
- 즉, 코사인 값이 -1에 가까우면 음의 상관관계, +1에 가까우면 양의 상관관계, 코사인 값이 0이면 두 편차 벡터는 상관관계가 없는 것이다.
- 그리고 벡터의 관점에서 두 편차 벡터의 상관관계(코사인 값)가 +1에 가까우면(양의 상관관계이면), 두 편차 벡터의 관계는 평행에 가깝다는 의미이다. 그러므로 값이 정확히 +1이면, 두 편차 벡터의 관계는 정확히 같은 방향으로 평행한 상태라고 할 수 있다.
- 반대로 두 편차 벡터의 상관관계가 -1에 가까울수록(음의 상관관계), 두 편차 벡터의 관계는 서로 점점 반대 방향을 가지는 상태이다. 그러므로 값이 정확히 -1이면, 두 편차 벡터의 관계는 정확히 서로 반대 방향으로 평행한 상태라고 할 수 있다.
- 그리고 두 편차 벡터의 상관관계가 정확히 0으로 상관관계가 없는 경우, 분자인 두 편차 벡터의 내적이 0이 되는 것이며, 어떤 두 벡터의 내적이 0이라는 것은 두 벡터가 서로 직교하는 것이므로, 두 벡터는 수직 관계를 이루고 있다고 할 수 있다.
■ 이렇게 두 편차 벡터 ti와 tj 사이의 코사인 값 cosθij를 계산하는 식은 cosθij=<ti,tj>‖ti‖‖tj‖이다.
■ 이 식을 이용하여 편차 벡터 t1과 t2의 코사인값(상관관계)를 계산하면 다음과 같다.

■ 나머지 편차 벡터들에 대해서도 동일한 방법으로 상관관계를 계산할 수 있다.
■ 이번에는 피어슨 상관관계에 대한 식을 이용하여 각 변수 사이의 상관관계를 구해보면 다음과 같이 동일한 값임을 확인할 수 있다.

- 위 결과를 해석하면
- 가격은 성능과 가장 큰 상관을 가지며 디자인과는 비교적 상관관계가 작음을 알 수 있다.
- 그리고 가격은 편리성과 색상에 양의 상관관계를 가지는 것을 볼 수 있다.
- 성능의 경우 편리성과 양의 상관관계를 가지며, 디자인과의 상관관계는 0에 가까운 값을 가진다.
- 즉, 성능과 디자인은 상관관계가 없는 것으로 볼 수 있다. 또한 성능과 색상도 성능과 디자인의 상관관계만큼은 아니지만, 아주 약한 상관을 가지는 것을 볼 수 있다. 또한 편리성도 디자인과 색상에 대해 아주 약한 상관을 가지는 것을 볼 수 있다.
- 반면, 디자인과 색상은 아주 강한 상관을 가지는 것을 볼 수 있다.
- 이 결과를 통해 어떤 제품의 '외향적 요인'인 디자인과 색상이라는 변수는 강한 상관을 가지며,
- 가격, 성능, 편리성이라는 변수는 '내향적 요인'이라고 생각할 수 있다.
■ 평균 중심화의 결과인 편차 벡터는, 편차벡터를 단위벡터로 만들어도 두 벡터 사이의 코사인 값은 변하지 않는다.
■ 각 편차벡터의 단위벡터를 ui=vi‖vi‖,(1≤i≤5라 하고, 10개의 샘플을 가지는 5개의 수치형 변수를 나타내는 10×5 비정방 행렬을 U라고 할 때, U=(u1,u2,u3,u4,u5라고 하자.
■ UTU라는 대칭행렬을 C라고 할때, 이 C 행렬은 위에서 본 각 변수들의 상관관계를 나타내는 상관행렬이다.
■ 대칭행렬 C=UTU는 다음과 같이 계산되기 때문에, 5개 벡터의 상관관계를 나타내는 행렬이 된다.
uTjui=<ui,uj>=<ti,tj>‖ti‖‖tj‖=cosθij
■ n개의 변수 X1,X2,⋯,Xn 각각에 대해 자료값이 m개씩 주어질 때, 각 변수별로 자료값에서 평균을 뺀 편차로 이루어진 벡터를 xi라 하고, 각 편차 벡터 xi를 크기로 나눈 단위벡터를 ui라 하자.
■ 이때, 비정방 m×n 행렬 U=(u1⋯un)에 대해 상관행렬 C는 C=UTU로 대칭행렬이 된다.
■ 상관행렬과 관계가 있는 또 다른 행렬로 공분산행렬이 있다.
■ 변수 X에 대한 자료값이 x1,x2,⋯,xn으로 주어지고, 변수 Y에 대한 자료값이 y1,y2,⋯,yn으로 주어질 때, 각 변수에 대한 편차 벡터를 각각 x,y라고 하자. 그러면, x=(x1−¯x,x2−¯x,⋯,xn−¯x)T,y=(y1−¯y,y2−¯y,⋯,yn−¯y)T
■ 이때, 두 편차 벡터 x와 y의 내적을 n으로 나눈 값을 두 변수 X,Y에 대한 공분산이라 하고, Cov(X,Y)로 나타낸다. 즉, Cov(X,Y)=1nyTx=1n<x,y>
■ R 상에서 n개의 변수 X1,X2,⋯,Xn에 대해 각각 m개씩의 샘플(자료값)이 주어질 때, 각 변수 Xi에 대한 m×1 크기의 편차 벡터를 xi라고 하자.
■ 이때, m×n행렬 V=(x1,x2,⋯,xn)에 대해, 행렬 S를 S=1mVTV라고 정의하면, Sij=Cov(Xj,Xi)인데, 실수 상에서 정의된 벡터공간의 내적에 대해서는 교환법칙이 성립하므로 Sij=Cov(Xj,Xi)=Cov(Xi,Xj)=Sji가 성립한다.
- m은 샘플(sample)의 개수, n은 변수(feature)의 개수
cf) 실수 상에서 정의된 벡터공간의 내적에 대해서는 교환법칙이 성립하므로 Cov(X,Y)=Cov(Y,X)가 성립한다.
■ 즉, 대칭행렬 S는 각 변수 사이의 공분산을 나타내는 행렬이 되므로 공분산행렬이라고 부른다.
■ 특히, 행렬 S의 i,i 위치에 있는. 즉, 대각 원소(성분)는 변수(feature) Xi의 분산이 되므로 행렬 S를 분산-공분산행렬이라고 부르기도 한다.
Sii=Cov(Xi,Xi)=1nxTixi=Var(Xi)
■ 예를 들어, 변수(feature)의 개수가 n개, 샘플(sample)의 개수가 m개이고, 평균 중심화를 적용해 편차가 기록된 m×n 행렬을 A라고 하자.
■ 즉, 행렬 A의 각 행은 특정 샘플의 n가지 변수에 대한 편차를 나타내고, 행렬 A의 각 열은 각 변수의 편차 벡터를 나타낸다.
■ A의 i 번째 열벡터를 ai라고 하자.
■ m×n행렬 A에 대해 행렬 A의 계수(rank)가 rank(A)<n이라면, 이는 행렬 A의 열벡터들은 종속 관계임을 의미한다.
■ 행렬 A의 열벡터는 어떤 변수에 대한 m개의 관측값과 이 관측값들의 (표본)평균의 편차에 대한 값이다.
■ 이러한 열벡터들이 종속 관계라는 것은 n가지 변수 중에서 어떤 하나의 변수를 나머지 변수들로 설명할 수 있다.
■ 이 예에서의 열은 편차 벡터라는 점에서 어떤 하나의 변수는 나머지 변수들로부터 그 변수에 대한 편차 벡터를 설명할 수 있다는 뜻이 된다.
■ 예를 들어 a2=2a1−a3이라면, m개의 샘플(sample) 각각에 대해 첫 번째 변수와 세 번째 변수의 편차를 아는 것만으로 두 번째 변수를 설명할 수 있다는 의미이다.
■ 즉, 요인 분석 관점에서 보면 두 번째 변수는 불필요한 변수라고 할 수 있다.
■ 이런 관점에서 생각하면, 변수별로 만들어진 편차 벡터 ai(1≤i≤n) 중 선형(일차) 독립 관계를 갖는 편차 벡터들만 있으면, 요인 분석 관점에서 충분하다는 의미이고, 이를 수학적으로 표현하면 ai(1≤i≤n) 중 선형 독립인 열벡터들은 열공간 C(A)의 기저가 된다는 것과 같은 의미이다.
- 보통 벡터 ai들은 서로 상관관계가 있는 벡터들이 되기 쉽다.
■ 주성분분석을 수학적으로 표현하면, 행렬 A의 계수(rank)가 r이라고 할 때, 행렬 A의 r차원 열공간 C(A)에 대해 직교기저(서로 종속 관계가 아닌 편차벡터들. 즉, 서로 상관관계가 없는 편차벡터들) y1,y2,⋯,yr를 구하되,
각 벡터 yi를 가상의 요인에 대한 편차벡터로 이해할 때, Var(y1)≥Var(y2)≥⋯≥Var(yr)가 성립하도록 벡터를 잡는 것을 의미한다.
■ 이때, 가장 큰 분산을 갖는 편차벡터 y1가 첫 번째 주성분(벡터)이 되는 것이다.
- yi(1≤i≤r)를 i번째 주성분(벡터)
■ 이렇게 주성분(벡터)들은 서로 상관관계가 없는(=선형 독립인) 벡터들로 구성된다.
■ 예를 들어, m×1 크기를 갖는 첫 번째 주성분 벡터 y1을 구하는 방법은 A의 열공간과 상공간(=선형변환에서의 치역)은 일치하므로 y1=Av1을 만족하는 n×1크기의 벡터 vi가 존재한다.는 것을 이용한다.
- 또는, 위에서 주성분벡터 yi는 행렬 A의 r차원 열공간 C(A)에 대해 직교기저여야 한다고 하였으므로
- 행렬 A가 m×n행렬이고 행렬 A의 열공간에 존재하는 직교기저인 주성분벡터 yi의 크기는 m×1이라면, 선형대수에서 Ax=b 문제를 생각했을 때,
- A와 yi를 연결하는 n×1 벡터가 존재하는 것을 추론할 수 있다.
- 이 n×1 벡터를 vi라고 했을 때, Avi=yi가 성립한다고 할 수 있다.
cf) A와 벡터 vi의 곱 Avi는 벡터 vi와 행렬 A의 열들의 선형 결합으로 나타낼 수 있다.
- 열공간은 열들의 모든 선형 결합으로 생성된다. 그리고 가능한 모든 결합은 벡터 Avi이다.
- 즉, 열공간 C(A)에는 선형 독립 관계를 가지는 행렬 A의 열들뿐만 아니라, 벡터 vi와 선형 독립인 A의 열들과의 선형 결합 결과인 벡터 Avi도 A의 열공간에 존재한다는 것을 의미한다.
■ 첫 번째 주성분벡터(가장 큰 분산을 갖는 편차 벡터) y1의 분산 Var(y1)은 Var(y1)=1myT1y1이며, Av1=y1이므로, y1의 분산은 Var(y1)=1myT1y1=1mvT1ATAv1으로 나타낼 수 있다.
■ 또한 공분산행렬 S가 S=1mATA가 된다는 것을 이용하면
Var(y1)=1myT1y1=1mvT1ATAv1=vT(ATAm)v1=vT1Sv1으로 나타낼 수 있다.
■ 이때, y1의 분산이 최대가 되도록 한다는 의미는 ‖v1‖=1인 벡터 v1에 대해 Var(y1)=1myT1y1=1mvT1Sv1가 최대가 되게 한다는 의미가 된다.
■ 이는 벡터 v1이 공분산행렬 S=ATA의 가장 큰 고윳값 λ1에 대응되는 고유벡터가 될 때 Var(y1)이 가장 최대화된다는 것을 의미한다.
■ 이 분산 최대화 문제는 다음과 같이 제약 조건 ‖v1‖=1이라는 1개의 등식 제약(equality constraint) 하에 최적화 문제로 생각할 수도 있다. 이에 대한 목적 함수를 나타내면 다음과 같이 나타낼 수 있다.
maxvT1Sv1subject to ‖v1‖=1
■ 제약 조건이 없는 경우 최대 또는 최소를 판별하는 최적화 문제는 다음과 같이 폐구간으로 정의된 연속함수에서 미분을 통해 극대 또는 극소가 될 수 있는 임계점을 찾은 다음, 찾은 임계점과 양끝 점을 연속 함수에 넣었을 때, 함수의 값이 가장 큰 것이 연속 함수 f의 최댓값이었고, 가장 작은 것이 f의 최솟값이었다.
참고) https://hyeon-jae.tistory.com/237
Positive definite matrices and minima
1. 양정치 행렬 또는 양의 정부호 행렬(Positive definite matrices)■ 양정치행렬(양의 정부호 행렬)은 대칭행렬에서만 적용된다. ■ 2×2 대칭행렬 A=[abbc]라
hyeon-jae.tistory.com
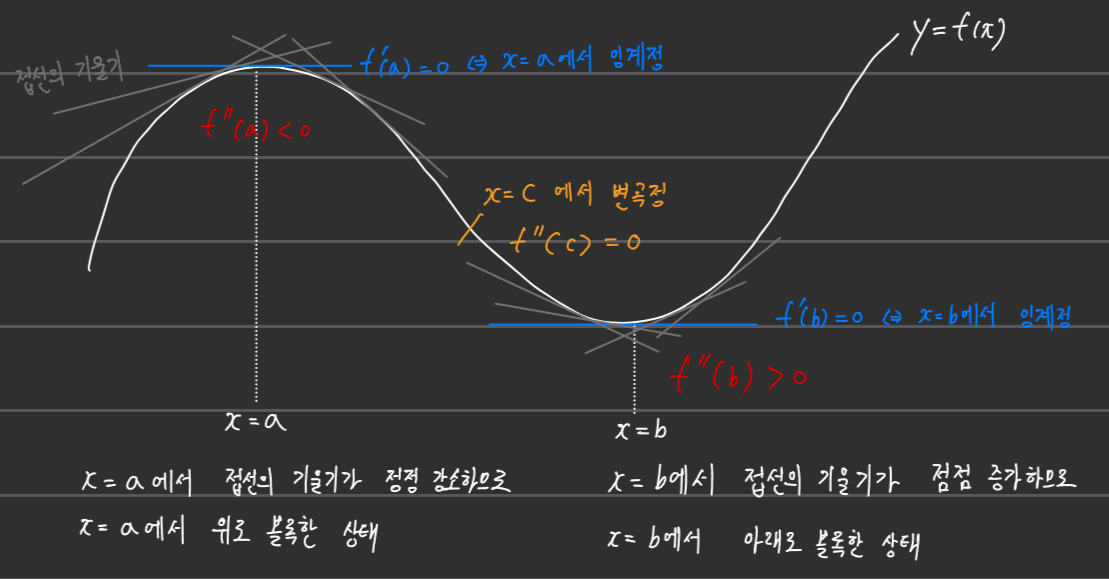
■ 하지만, 지금 문제와 같이 제약 조건으로 등식 조건이 있으면 극대(local maximum) 또는 극소(local minimum)이 되기 위한 필요조건은 더 이상 f′=0이 아닐 수 있다.
- 예를 들어 연속 함수 f(x)와 제약 조건 h(x)=0이라는 등식 조건이 다음과 같이 나타난다고 하면,

- 빨간선인 h(x)=0을 만족하는 x 중에서 극대 또는 극소가 될 수 있는 임계점은 더 이상 f′=0이 되는 지점이 아닐 수 있는 것을 볼 수 있다.
- 위의 그림처럼 제약 조건이 붙는 경우 극대 또는 극소(혹은 최대 또는 최소)는 제약 조건과 함수 f가 접했을 때 발생할 수 있다.
■ 이렇게 제약 조건을 만족하면서 함수 f의 최댓값과 최솟값을 구하는 방법으로 '라그랑주 승수법'이 있다.
■ 라그랑주 승수법 중 제약 조건이 g(x1,x2,⋯xn)=k로 1개일 경우 함수 f(x1,x2,⋯,xn)의 최댓값과 최솟값을 구하는 방법은
-- k는 상수
- (1) ∇g=λ∇f, g(x1,x2,⋯xn)=k를 만족하는 x1,x2,⋯,xn과 λ를 구한다. (단, λ는 0이 아닌 실수)
- (2) 그리고 (1)에서 구한 모든 점(x1,x2,⋯,xn)에서 f(x1,x2,⋯,xn)을 계산한다. 이 값들 중 가장 큰 값이 f의 최댓값이고, 가장 작은 값이 f의 최솟값이다.
- 즉, ∇g가 ∇f의 상수배일 때, ∇g=λf일 때, 최대 및 최소가 발생한다고 볼 수 있다.
■ ∇g가 ∇f의 상수배 ⇔ ∇g=λf라는 것은 ∇g와 ∇f가 평행하다는 것이다.
■ 이때 f와 g를 통해 다음과 같은 라그랑즈 함수를 정의할 수 있다.
L(x1,x2,⋯,xn,λ)=f(x1,x2,⋯,xn)−λ(g(x1,x2⋯,xn)−k)
- 제약 조건이 한 개가 아니라 여러 개인 경우는 다음과 같이 일반화할 수 있다.
L(x1,x2,⋯,xn,λ1,λ2,⋯,λn)=f(x1,x2,⋯,xn)−n∑i=1λi(gi(x1,x2,⋯,xn))
■ 위의 예시에서 제약 조건이 붙으면 최대 및 최소가 될 수 있는 임계점인 극대 및 극소점이 f′=0이 아닌 제약 조건 g와 함수 f가 접하는 지점에서 발생한다고 하였다.
■ 즉, 최대 및 최소를 찾기 위해서는 두 함수 f와 g가 접하는 점을 찾아야 하며, 이 점은 L(x1,x2,⋯,xn,λ)=f(x1,x2,⋯,xn)−λ(g(x1,x2⋯,xn)−k)의 미분 = 0 ⇔ ∇L(x1,x2,⋯,xn,λ)=0이 되는 지점에서 찾을 수 있다.
■ 즉, 제약 조건이 등식 조건으로 1개일 때, 라그랑주 함수 L을 각 변수들 x1,x2,⋯,xn,λ로 편미분한 결과가 0이 되는 n+1개의 수식들을 연립하여 제약식을 풀게되면 최적화된 해를 구할 수 있다.
■ 다시 주성분분석으로 돌아와서 maxvT1Sv1subject to ‖v1‖=1에 라그랑주 승수법을 적용하면 라그랑주 함수는 다음과 같이 나타낼 수 있다.
L=vT1Sv1−λ(vT1v1−1)
- 목적 함수를 보면 최대화하고자 하는 것이 바로 공분산행렬의 이차형식임을 알 수 있다.
■ 이제 이 예의 최대, 최소는 이 라그랑주 함수에 대해 변수인 벡터 v1을 편미분한 결과가 0이 되는 지점에서 발생한다.
■ 벡터 v1에 대한 도함수를 0으로 설정하면 ∂L∂v1=2Sv1−2λv1=0⇒Sv1=λv1이 된다.
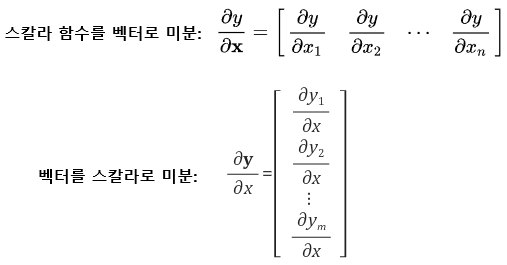
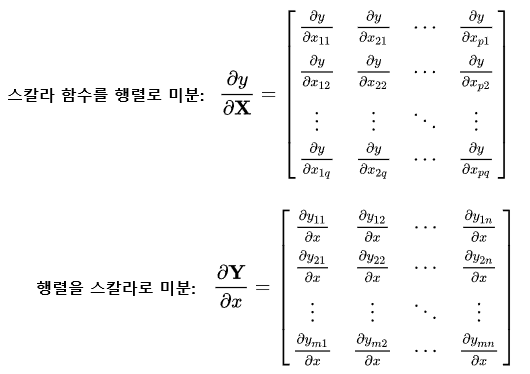

- L=vT1Sv1−λ(vT1v1−1)에서 먼저, (vT1v1−1)에 대한 미분은
- xTx=[x1⋯xn][x1⋮xn]=x1x1+x2x2+⋯+xnxn=x21+⋯+x2n= 스칼라 값
- xTx는 스칼라 값이다. 그러므로 스칼라를 벡터로 미분하는 첫 번째 식을 이용해야 한다.
- 위의 첫 번째 식의 결과는 행벡터, 두 번째 식의 결과는 열벡터로 되어 있는데, 이는 피미분 변수를 중심으로 행과 열을 결정할지 아니면 미분 변수를 중심으로 행과 열을 결정할지의 차이이다. 즉, 첫 번째 식의 결과를 열벡터, 두 번째 식의 결과를 행벡터로 나타내도 된다.
- 위의 미분식들은 모두 분자중심 표현법(numerator layout)으로 나타낸 것이다. - 예를 들어 결과가 행벡터로 나타나는 첫 번째 식을 분모중심 표현법(denominator layout)으로 나타내면, 결과는 열벡터가 된다. 둘 중 하나의 표현법으로 일관되게 사용하기만 하면 된다. - 즉, 분자중심 표현법과 분모중심 표현법은 서로 전치 관계에 있다. 분자중심 표현법으로 나온 결과에 전치를 적용한 결과는 분모중심 표현법의 결과라는 얘기이다.
참고) Matrix calculus - Wikipedia
Matrix calculus - Wikipedia
From Wikipedia, the free encyclopedia Specialized notation for multivariable calculus In mathematics, matrix calculus is a specialized notation for doing multivariable calculus, especially over spaces of matrices. It collects the various partial derivative
en.wikipedia.org
- 분모중심 표현법을 사용하여 두 번째 항에 대해 미분을 하면 다음과 같다.
-- 계산 과정을 보기 쉽게 v1을 x로 두고 계산
∂xTv∂x=[∂xTx∂x1⋮∂xTx∂xn]=[∂(x1x1+⋯+xnxn)∂x1⋮∂(x1x1+⋯+xnxn)∂xn]=[∂∂x1(x21+⋯+x2n)⋮∂∂xn(x21+⋯+x2n)]
- 여기서 ∂∂x1(x21+⋯+x2n)은 x21+⋯+x2n를 x1에 대해서만 미분하고 ∂∂xn(x21+⋯+x2n)은 x21+⋯+x2n를 xn에 대해서만 미분하면 된다. 그러면 그 결과는 다음과 같다.
=[2x12x22x3⋮2xn]=2x
- 첫 번째 항 L=vT1Sv1에 대한 미분은 다음과 같다.
-- 계산 과정을 보기 쉽게 vT1Sv1을 xTAx로 두고 계산
- xTAx에서 벡터 Ax를 w=Ax로 두자. 그러면 xTw에 대해 다음과 같이 미분을 하면 된다.
- ∂xTw∂x는 x와 w에 대한 식이므로, ∂xTw∂x=xT∂w∂x+wT∂x∂x가 된다.
-- 두 번째 항은 xTw=<x,w>=스칼라 값이므로 xTw=wTx임을 이용한 것이다.
- ∂xTw∂x=xT∂w∂x+wT∂x∂x=xTA+wT=xTA+xTAT=xT(A+AT)
- 이때 A는 공분산행렬. 즉, 대칭행렬이므로 결과는 xT(A+AT)=2xTA가 된다.
- 그러므로 라그랑주 함수 L의 미분 결과는 2Ax−2λx가 된다.
■ 지금 최적화 문제는 최대에 대한 문제이다. 즉, Sv1=λv1조건을 만족하는 v1이 선택되면, 목표함수 vT1Sv1이 최대가 될 수 있다는 것을 알 수 있다.
■ 근데 Sv1=λv1라는 조건을 보면 이는 고윳값 방정식의 형태임을 알 수 있다.
■ 여기서 S는 대칭행렬인 공분산행렬이므로 고유벡터 v1은 공분산 행렬의 고유벡터이며 λ는 고유벡터 v1에 대응되는 공분산행렬의 실수 고윳값 λ1임을 알 수 있다.
■ 정리하면, 첫 번째 주성분(벡터) y1의 분산이 최대가 되는 경우를 찾기 위해
- (1) 목적 함수 maxvT1Sv1subject to ‖v1‖=1를 계산해야 하며,
- (2) 이 목적 함수를 풀기 위해 라그랑주 승수법을 이용했으며, 이때의 라그랑주 함수는 L=vT1Sv1−λ(vT1v1−1)
- (3) 제약 조건으로 등식 조건 1개인 라그랑주 함수의 최대/최소는 라그랑주 함수를 미분했을 때 0이 되는 지점이므로, 라그랑주 함수 L을 미분했으며,
- 그 결과로 ∂L∂v1=2Sv1−2λv1=0⇒Sv1=λv1를 얻었다.
- (4) 목적 함수가 maxvT1Sv1subject to ‖v1‖=1이므로
- ‖v1‖=1라는 등식 제약 하에, Sv1=λv1라는 조건을 만족하는 v1가 선택되면 목적 함수가 최대가 될 수 있다는 것을 알 수 있다.
■ 고윳값 방정식 Sv1=λv1에서 행렬 S의 고유벡터 v1에 대응되는 고윳값 λ를 λ1이라고 하자.
■ 이때, Sv1=λ1v1라는 조건의 양변 좌측에 vT1을 곱하면, 좌변이 목적 함수인 vT1Sv1=vT1λ1v1식이 성립한다.
■ 이때 λ1는 음이 아닌 실수이다.
- 공분산행렬 S를 S=1mATA로 정의하였다.
- 여기서 m×n 행렬 A는 임의의 실수 행렬이다.
- 그리고 임의의 실수 행렬 A에 대해 대칭행렬 ATA는 최소한, 항상 양의 준정부호 행렬이다.
- xT(ATA)x=(Ax)T(Ax)=‖Ax‖2이며, 제곱은 항상 0보다 크거나 같기 때문이다.
- ATA가 양의 준정부호 행렬이므로 대칭행렬 ATA의 모든 고윳값은 음이 아닌 실수이다.
- 공분산행렬 S는 ATA라는 양의 준정부호 행렬에 단지 1m이라는 값을 곱한 행렬이다. ( m은 샘플의 개수. 즉 어떤 숫자)
- 그러므로 위의 상황에서 λ1는 음이 아닌 실수라고 할 수 있다.
■ λ1가 음이 아닌 실수이므로 vT1Sv1=vT1λ1v1=λ1vT1v1식이 성립하며 v1v1은 자기 자신에 대한 내적이므로 결과는 어떤 임의의 스칼라이다.
■ 그러므로 Sv1=λ1v1라는 조건을 만족하는 v1가 선택되면 목적 함수가 최대가 될 수 있는 것이다.
- 음이 아닌 실수 λ1와 v1가 선택되어야 목적 함수가 최대가 되는 것이 아니라,
- v1 하나만 잘 선택했을 때, 목적 함수가 최대가 되는 이유는 고유벡터 v1에 대응되는 것이 λ1이기 때문이다.
- 다시 말해, v1을 선택하면 따라오는 것이 λ1이기 때문이다.
- 그리고 위에서 목적 함수를 보면 최대화하고자 하는 것이 바로 공분산행렬의 이차형식이라고 하였다. 그러므로 주성분을 찾는 것은 공분산행렬의 이차형식을 최대화하는 벡터 v1을 찾는 것과 동일하다고 할 수 있다.
■ 그리고 Sv1=λ1v1라는 조건은 라그랑주 승수법에 의해 나온 결과이다.
■ 위에서 y1의 분산이 최대가 되도록 한다는 의미는 ‖v‖=1인 벡터 v1에 대해 Var(y1)=vT1Sv1가 최대가 된다고 하였따.
■ 이 라그랑주 승수법에 의해 나온 결과를 Var(y1)에 대입하면, Var(y1)=vT1Sv1=vT1λ1v1=λ1vT1v1=λ1‖v‖=λ1이 된다.
■ Var(y1)=λ1이므로, 벡터 v1가 ‖v1라는 조건 하에 첫 번째 주성분벡터 y1의 분산이 최대가 되기 위해서는 λ1의 값이 최대여야 한다는 의미이며, λ1은 공분산행렬 S의 고윳값이다.
■ 이를 통해 알 수 있는 것은 PCA의 해법은 공분산행렬에 대한 고윳값 분해라는 것을 알 수 있다.
- (1) 주성분(벡터)의 분산은 고윳값이며,
- (2) 특히, 첫 번째 주성분(벡터)의 분산은 공분산행렬 S의 고윳값 중 가장 큰 고윳값이라는 사실이다.
- (3) S의 가장 큰 고윳값은 대칭행렬인 S를 대각화했을 때 나오는 고윳값 대각행렬의 가장 왼쪽 위의 대각 원소에 위치하고 있다.
- (4) 그러므로 첫 번째 주성분벡터가 갖는 분산(고윳값)은 다른 주성분벡터가 갖는 분산(고윳값) 중 최대가 된다는 사실을 알 수 있다.
■ 그리고 대칭행렬 S를 대각화했을 때, S=QΛQT라고 하자. Λ가 바로 고윳값 대각행렬이다. 이때, 행려 Q의 첫 번째 열벡터가 바로 v1이다.
■ 그러므로 첫 번째 주성분(벡터) Var(y1)=vT1Sv1이 최대가 되는 경우는 벡터 v1이 행렬 S의 가장 큰 고윳값 λ1에 대응되는 고유벡터가 될 때이다.
■ 그리고 Var(y1)=1myT1y1=vT1Sv1=1mvT1ATAv1에서 특이값 분해를 생각하면, ATA의 고유벡터는 A의 오른쪽 특이벡터에 대응된다.
■ 그러므로 벡터 v1은 특이값 σ1=√λ1에 대응되는 오른쪽 특이벡터가 되고, σ1에 대응되는 왼쪽 특이벡터를 u1이라 할 때, y1=Av1=σ1u1이 성립한다.
■ 두 번째 주성분벡터 y2는 두 번째로 큰 분산을 가져야 한다.
■ 주성분을 수학적으로 표현하면 rank(A)=r차원 열공간 C(A)에 대한 직교기저라고 할 수 있다.
■ 즉, 두 번째 주성분(벡터) y2는 첫 번째 주성분(벡터) y1과 서로 직교한다.
■ 그러므로 첫 번째 주성분벡터와 두 번째 주성분벡터는 서로 독립이라고 할 수 있다.
■ 주성분의 방향은 고유벡터의 방향이며, 주성분이 가리키는 방향인 분산이 퍼져 있는 방향을 알려주는 것이 고유벡터의 방향이라는 점에서
■ 첫 번째 주성분벡터와 두 번째 주성분벡터는 독립이므로 두 주성분벡터는 서로 다른 분산을 가리킨다고 볼 수 있다.
■ 위의 과정에서 첫 번째 주성분은 분산을 최대화하는 축(= 공분산행렬의 고유벡터 v1가 가리키는 방향과 동일한 축)을 선택하였다.
■ 두 번째 주성분은 첫 번째 주성분과 직교하는 제약 조건 하에서 남은 분산 중 가장 큰 값을 갖는 축을 선택한다.
■ 이 과정은 고윳값의 크기 순으로 주성분을 선택하는 것과 동일하며, 결과적으로 첫 번째 주성분이 설명하지 못한
잔여 분산을 최대화하는 것이다.
■ 만약 주성분벡터들의 직교성을 포기한다면, 두 번째 주성분이 첫 번째 주성분과 가리키는 방향이 같을 수 있다. 즉, 첫 번째 주성분과 두 번째 주성분이 겹치는 정보(분산)를 포함할 수 있어 차원 축소의 효율성이 떨어진다.
■ 직교성을 유지함으로써 각 주성분이 독립적인 정보를 최대한 보존할 수 있는 것이다.
■ PCA는 이러한 아이디어를 사용하기 때문에 데이터의 주요 변동성을 최소한의 성분(component)으로 설명할 수 있다.
■ 핵심은 분산이 큰 순서대로 주성분을 선택하는 것이다. 이를 통해 적은 수의 성분(component)으로도 원본 데이터의 분산을 효율적으로 보존할 수 있다.
■ 정리하면 두 번째 주성분이 두 번째로 큰 분산을 갖는 것은 공분산행렬의 고윳값 분해와 직교성 제약에 기인한다. 이를 통해 정보 중복을 배제하면서 데이터의 변동성을 순차적으로 최대화하여 효율적인 차원 축소를 가능하게 한다.
■ 두 번째 주성분벡터 y2는 두 번째로 큰 분산을 가져야 하므로, y2=Av2에서 벡터 v2는 v1과 수직이면서 크기가 1인 벡터일 때, y2=1myT2y2=1mvT2ATAv2가 최대가 되는 벡터 v2를 구하면 된다.
■ 따라서 v2는 ATA의 두 번째 고윳값 λ2에 대응되는 고유벡터가 된다.
■ 결국 v2는 A의 특이값 중 두 번째로 큰 특이값 σ2=√λ2에 대응되는 오른쪽 특이벡터가 되고, σ2에 대응되는 왼쪽 특이벡터 u2에 대해 y2=Av2=σ2u2가 된다.
- 첫 번째 주성분은 특이값 중 특이값이 가장 큰 σ1으로 정의되는 것을 볼 수 있다.
- 즉, 두 번째 주성분은 두 번째로 큰 분산을 가져야 하므로 특이값 중 특이값이 두 번째로 큰 σ2로 정의된다.
■ 동일한 방법으로 i번째 주성분벡터 yi는 A의 i번째 특이값 σi에 대응되는 오른쪽 특이벡터 vi에 대해 yi=Avi가 되고, σi에 대응되는 왼쪽 특이벡터 ui에 대해 yi=Avi=σiui가 성립한다.
■ 이때, yi=σiui이고 yj=σjuj에 대해 <yi,yj>는 σi,σj는 어떤 실수이므로, <yi,yj>=σiσj<ui,uj>=σiσj×0=0이 성립한다.
- 정규직교기저는 직교기저인데 크기가 1인 직교기저이므로 서로 다른 직교기저와는 수직 관계를 갖는다.(직교한다.)
- 수직 관계를 갖는다는 것은 두 직교기저의 사잇각이 90도라는 의미므로 두 직교기저의 내적값은 0이된다. (cos90도 = 0 \)
- 그리고 정규직교기저는 단위벡터이므로 자기 자신과의 내적은 1이된다.
- 특이값 분해에서 왼쪽 특이벡터와 오른쪽 특이벡터는 각각 정규직교집합이 된다.
- 그러므로 위에서 서로 다른 왼쪽 특이벡터의 내적은 0이 되는 것이다.
■ 서로 다른 주성분벡터의 내적값이 0이라는 것은 서로 다른 주성분벡터들은 서로 직교한다는 것이며, 이는 서로 다른 주성분벡터들은 서로 독립 관계를 가진다는 것이다. 그러므로, 주성분벡터 yi(1≤i≤r) 사이에는 서로 상관관계가 없음을 알 수 있다.
■ yi의 분산은 대칭행렬 A^TA의 고윳값이 λ1≥λ2≥⋯,≥λr>0일 때, Var(yi)=1myTiyi=1mσ2iuTiui=λim이므로 Var(yi)는 Var(yi)=λim=√σim라고 할 수 있다.
-여기서 r은 r=rank(A)이며 σi는 i번째 특이값, λi는 i번째 고윳값이다.
- λi는 대칭행렬 A^T A의 고윳값 λ1≥λ2≥⋯≥λr>0을 의미한다.
- 마찬가지로 σi는 특이값 σ1≥σ−2≥⋯≥σr>0을 의미한다.
- 또한, 위의 식에서 정규직교기저의 uTiui는 자기 자신의 내적. 즉, 자기 자신의 크기이다. 정규직교기저는 단위벡터이므로 크기는 1이다. 그러므로 Var(yi)=λim=σ2im가 된다.
■ 이를 통해 주성분 yi의 분산의 크기를 결정짓는 모수(parameter)는 샘플(sample)의 개수 m과 λi 또는 σi라는 것을 알 수 있다.
■ 여기서 가상의 요인에 대한 편차 벡터인 주성분벡터를 구체화하는 방법은 n가지 종류의 변수 X1,X2,⋯,Xn에 가중치를 주어 생각하는 것이다.
■ 즉, 가중결합을 생각하는 것이다. 예를 들어 y1은 행렬 A의 가장 큰 특이값에 대응되는 오른쪽 특이벡터 v1에 대해 y1=Av1이므로 v1=(v11,v21,⋯vn1)T라 할 때, A의 열벡터 ai에 대해 y1=v11a1+⋯+vn1an이라는 선형 결합으로 생각할 수 있다.
■ 이렇게 PCA는 분산이라는 통계적 개념과 선형대수학의 선형 결합이라는 개념을 통합한 것이다.
■ 그리고 행렬 A에 대한 특이값 분해 A=UΣVT=r∑i=1uiσivTi=u1σ1vT1+u2σ2vT2+⋯+urσrvTr=y1vTi+y2vT2+⋯+yrvTr로 나타낼 수 있다.
- yi=Avi=σiui
■ 여기서 Singular value decomposition (1) cf)에 있는 주어진 행렬을 계수가 작은 행렬로 근사시키는 최적의 방법을 사용하면 A와 동일한 m×n 크기를 갖는 계수(rank) 1 행렬 중에서 A가 담고 있는 편차를 가장 잘 근사시키는 행렬은 y1vT1이라고 할 수 있다.
- 이때 y1은 주성분벡터이고 v1은 n개의 변수를 이용하여 y1을 표현하는 가중치를 담고 있는 벡터이다.
'선형대수' 카테고리의 다른 글
| 상관행렬, 공분산행렬을 이용한 주성분분석 (0) | 2025.03.24 |
|---|---|
| Linear transformations and their matrices (0) | 2025.03.21 |
| Singular value decomposition (2) - 특이값 분해 응용 (1) (0) | 2025.03.12 |
| Singular value decomposition (1) (0) | 2025.03.10 |
| Similar matrices and Jordan form (0) | 2025.03.07 |



