1. 확률변수(random variable)
■ 확률 변수는 '확률 실험의 각 결과인 표본공간의 각 원소를 실수 값으로 바꾸는 함수'이다.
즉, 표본공간 S에서 실수 공간 R으로의 함수이다.
■ 하나의 확률실험에 대해 여러 개의 확률변수를 정의할 수 있으며, 원소의 개수에 비례하는 확률분포를 갖는다.
■ 확률변수는 보통 알파벳 대문자 (X,Y,Z)로 표기한다.
■ 예를 들어 동전을 두 번 던져 앞면(H)와 뒷면(T)을 관측하는 실험에서의 표본공간 S = {(H, H), (H, T), (T, H), (T, T)}로 4개의 원소를 갖는다.
- 내가 관심 있는 경우가 뒷면이 나오는 횟수라면, 나올 수 있는 경우의 수는 0, 1, 2 중 하나가 된다.
- 즉, 확률변수 X를 뒷면이 나오는 횟수로 정의하면, 확률변수는 표본공간의 각 원소를 숫자로 바꾼다. 이를 그림으로 나타내면 다음과 같다.

- 확률 변수는 원소의 개수에 비례하는 확률 분포를 가지는데, 예를 들어 X=1(동전을 두 번 던졌을 대, 하나만 뒷면이 나오는 경우는 2번)에 해당하는 원소는 HT, TH로 2개 이므로 P(X=1)=24가 된다.
1.1 이산확률변수, 연속확률변수
■ 표본공간 S의 원소가 유한개 또는 셀 수 있는 무한개의 원소로 구성되어 있으면, 이산표본공간(discrete sample space)이라 하고, 표본공간 S가 실선 상의 임의의 구간으로 나타낼 수 있을 때(<=> 원소를 셀 수 없을 때) 연속표본공간(continuous sample space)라고 한다.
■ 예를 들어 주사위, 동전 던지기, 불량품 개수 등은 이산 표본공간, 일별 강수량, 제품의 치수 등은 연속 표본공간에 해당된다.
■ 이산표본공간, 연속표본공간의 정의와 유사하게 확률변수 X가 유한개 또는 셀 수 있는 무한개의 값을 가지면 이산확률변수(discrete random variable), 확률변수 X의 함수 값이 임의의 구간에서 어떠한 값도 가질 수 있을 때 연속확률변수(continuous random variable)라고 한다.
■ 즉 확률변수는 '셀 수 있는가?'를 기준으로 이산확률변수, 연속확률변수로 나뉘며 이산, 연속확률변수도 확률변수이므로 이산확률분포, 연속확률분포를 갖는다.
■ 예를 들어 이산확률변수가 불량품의 개수, 연속확률변수가 일별 주식 가격이라면 이들의 확률분포는 다음 그림과 같이 표현된다.
■ 주의할 점은 연속표본공간으로 얼마든지 이산확률변수를 정의할 수 있다는 점이다.
■ 예를 들어 제품 치수를 기준으로 양품(X = 10), 불량품(X = 1)으로 이산확률변수를 정의할 수 있다.
2. 확률분포
■ 확률분포는 '표본공간 S에서 정의된 확률변수 X의 함수 값들이 발생할 확률을 계산하는 것'을 말하며,
■ 이산확률변수가 생성하는 확률분포를 이산확률분포, 연속확률변수가 생성하는 확률분포를 연속확률분포로 나눈다. 이렇게 나누는 이유는 확률을 계산하는 방법이 다르기 때문이다.
■ 이산확률분포의 함수를 확률질량함수(probability mass function), 연속확률분포의 함수를 확률밀도함수(probability density function)라 하며, 두 함수를 통칭해서 확률분포함수(probability distribution function)라고 한다.
■ 이산확률분포(discrete probability distribution)는 '셀 수 있는(이산적인) 값을 갖는 확률변수의 확률분포'로서, 확률분포함수 f(x)는 P(X=x)를 의미하며 ( f(x)=P(X=x) ), 확률질량함수라고 한다.
■ 이산확률분포는 ∑xf(x)=1 조건과 0≤f(x)≤1for all x 조건을 만족하는데, 각 조건이 의미하는 바는 모든 가능한 결과에 대한 확률의 합은 1이며, f(x)=P(X=x)의 확률은 0 이상 1 이하의 값을 가진다.
■ 확률질량함수는 각 값을 가질 확률을 계산한다.
■ 예를 들어 위의 예시, 동전을 두 번 던져 뒷면이 나오는 횟수의 경우, 경우의 수는 0, 1, 2이며, 각 경우의 수의 확률 중 P(X=1)=24 였다. \( P(X = 1) \)을 포함해 모든 경우의 확률질량함수는 다음 표와 같다.
| x | 0 | 1 | 2 |
| \( P(X = x) = P_x(x) | 1/4 | 2/4 | 1/4 |
- f(x)의 확률이 0이상 1이하이며, 모든 확률의 총합이 1이므로 이산확률분포의 조건을 만족한다.
- 이렇게 확률변수의 특정 값(x)에 대한 확률을 구할 수 있으며, 위의 표처럼 나타낸 표를 확률분포표라고 한다.
■ 연속확률분포(continuous probability distribution)는 셀 수 없는(연속적인) 값을 갖는 확률변수의 확률분포로서, 확률분포함수 f(x)는 확률 P(a<X<b)=∫baf(x)dx를 구하기 위한 확률밀도함수를 의미한다.
■ 즉, 연속확률분포는 연속확률변수 X가 연속적인 값을 갖는 경우로서, 모든 x에 대해 f(x)는 언제나 0 이상의 값을 가지며, f(x) 아래 면적의 합은 1이므로 ∫∞−∞f(x)dx=1, f(x)≥0이라는 조건을 만족한다.
■ 또한, 연속확률분포는 주어진 영역의 면적을 구하여 확률을 계산할 수 있다. P(a<X<b)=∫baf(x)dx
■ 만약 연속확률분포의 확률변수 X가 특정 값(x)과 같은 확률을 구한다면, ( P(X=x)=0 )이 된다.
왜냐하면, P(X=x)=P(x≤X≤x)=∫xxf(y)dy=0이 되기 때문이다.
3. 누적분포함수(cumulative distribution function)
■ 확률분포의 누적분포함수는 '이산형과 연속형 구분 없이 F(x)=P(X≤x)로 정의'된다.
즉, 누적분포함수 F(x)는 확률변수 X의 값이 x이하일 확률을 의미하며, 다음과 같은 특성을 갖는다.
1) 모든 x에 대해 0≤F(x)≤1이며
2) F(x)는 말 그대로 누적이므로x가 커질수록(<=> x=x1,x2,... ), x가 누적되어
X가 x이하일 확률이 증가하거나 최소한 같아지므로 단조 증가 함수라고 할 수 있다.
따라서, x1≤x2이면 항상 F(x1)≤F(x2)가 성립한다.
3) 그리고 F(∞)=P(X≤∞)=1, F(−∞)=P(X≤−∞)=0이 된다.
■ 예를 들어 동전을 두 번 던져 뒷면이 나오는 횟수에서 x = 0, 1 ,2였고, f(0)=14,f(1)=24,f(2)=14이므로 F(x)={0,x<014,0≤x<134,1≤x<21,x≥2가 된다.
■ 이산확률변수인 경우, F(x)=P(X≤x)=∑t≤xf(t),(−∞≤x≤∞)이다.
X가 x1,x2,...,xk,...의 값을 가지고, x1<x2<...<xk<...이면,
F(xn)=n∑k=1f(xk)이고 f(xn)=F(xn)−F(xn−1)이 성립한다.
■ 연속확률변수인 경우, F(x)=P(X≤x)=∫x−∞f(t)dt이며 f(x)=ddxF(x)=F′(x)이다.
■ 예를 들어 다음과 같은 상황은
F(x+2)=F(x)+f(x)·2이며 \( P(x \leq X \leq) = F(x+2) - F(x) = f(x) · 2 \)이다.
- 단위 구간 길이당 확률값은 P(x≤X≤x+2)2이며, 2를 0으로 보내면
f(x)=lim2→0F(x+2)−F(x)h=F′(x)가 된다.
- 미분과 적분의 관계를 고려하면, 누적분포함수를 미분하면 확률밀도함수, 확률밀도함수를 적분하면 누적분포함수가 된다.
4. 결합확률분포(joint probability distribution)
■ 결합확률분포는 2개 이상의 확률변수에 대한 확률분포이다.
■ 2개 이상의 확률변수는 확률변수 간에 서로 영향을 주고 받을 수 있어 동시에 고려할 필요가 있다.
ex) 키와 몸무게, 기온과 강수량
■ 결합확률분포는 두 확률변수 X,Y가 이산확률변수일 경우, 동시에 각각 x,y값을 가질 확률이며, (확률변수 X=x이고 확률변수 Y=y일 경우의 확률) f(x,y)=PX,Y(x,y)=P(X=x,Y=y)로 나타낸다.
■ 이산확률변수들의 결합확률분포는 확률변수 X,Y가 이산적인 값 x,y를 갖는 경우이고, 모든 x,y에 대해 확률은 0 이상 1 이하의 값을 가진다. 0≤f(x,y)≤1, all x,y 그리고 확률의 총합은 1이므로 ∑x∑yf(x,y)=1을 만족한다.
■ 예를 들어

f(2,3)=PX,Y(2,3)=P(X=2,Y=3)은 X=2이고 Y=3인 경우의 확률이므로 2/20이 된다.
■ 주사위를 두 번 던졌을 때, 최댓값을 X, 최솟값을 Y라고 한다면, 확률변수 X와 Y의 결합확률분포는, 표본공간 S의 원소 개수는 62=36개 이며, X=x,Y=y인 원소의 개수를 n(x,y)={1,if x=y2,if x>y라 할 수 있다.
예를 들어 x=1일 때 x=y인 경우는 y=1로 한 가지이며, 주사위를 두 번 던지므로 X=2,Y=1인 경우는 주사위가 (1, 2) 또는 (2, 1)이 나오는 2가지이다. X=3,Y=1일 때도 주사위는 (3, 1), (1, 3), X=3,Y=2일 때도 마찬가지로 (3, 2), (2, 3) 2가지이다. X=4,5,6일 때도 마찬가지이다.
따라서 f(x,y)={136,if x=y236,if x>y, x,y=1,2,3,4,5,6이라 할 수 있다.
■ 연속형 확률변수 X,Y가 x,y라는 연속적인 값을 가질 때의 결합확률분포는, f(x,y)는 0 이상의 값을 가지므로 f(x,y)≥0이며, 확률의 총합은 1이므로 ∫∞−∞∫∞−∞f(x,y)dxdy=1이 된다.
■ 예를 들어 f(x,y)=2(ax+by)a+b,a,b>0,0<X<1,0<Y<1일 때
∫10∫102(ax+by)a+bdxdy=2a+b∫10∫10(ax+by)dxdy=2a+b∫10[12ax2+bxy]10dy=2a+b∫10(12a+by)dy=2a+b[12ay+12by2]10=2a+b⋅a+b2=1
이 되므로 f(x,y)는 a,b>0일 때, 0<x<1,0<y<1의 범위에서 확률변수 X, Y는 f(x,y)>0이며 ∫10∫10f(x,y)dxdy=1이므로 결합확률분포가 된다는 것을 알 수 있다. 따라서 a,b>0이라는 가정 하, 0<x<1,0<y<1의 범위에 속하는 P(0<X<12,0<Y<12)를 구할 수 있다. P(0<X<12,0<Y<12)도 ∫120∫120f(x,y)dxdy 이중적분을 계산하여 확률값을 구하면 된다.
5. 주변확률분포(marginal probability distribution)
■ 이산확률변수 X,Y의 결합확률분포 f(x,y)로부터 주변확률분포는 다음과 같이 정의할 수 있다.fX(x)=∑yf(x,y),fY(y)=∑xf(x,y)
■ 예를 들어 x=1,2,3,4, y=1,2,3이면 fX(x)=f(x,1)+f(x,2)+f(x,3), fY(y)=f(1,y)+f(2,y)+f(3,y)+f(4,y)
■ 연속형일 경우, 주변확률분포는 다음과 같다. fX(x)=∫∞−∞f(x,y)dy,fY(y)=∫∞−∞f(x,y)dx
■ 예를 들어 확률변수 X,Y가 다음과 같을 때,
| Y=0 | Y=1 | Y=2 | |
| X=0 | 0.1 | 0 | 0.3 |
| X=1 | 0.2 | 0.15 | 0.25 |
- X에 대한 주변확률분포는 P(X=0)=P(X=0,Y=0)+P(X=0,Y=1)+P(X=0,Y=2)=0.1+0+0.3=0.4, P(X=1)=P(X=1,Y=0)+P(X=1,Y=1)+P(X=1,Y=2)=0.2+0.15+0.25=0.6
- Y에 대한 주변확률분포는 P(Y=0)=P(X=0,Y=0)+P(X=1,Y=0)=0.1+0.2=0.3, P(Y=1)=P(X=0,Y=1)+P(X=1,Y=1)=0+0.15=0.15, P(Y=2)=P(X=0,Y=2)+P(X=1,Y=2)=0.3+0.25=0.55
■ 연속일 경우, 2(ax+by)a+b,a,b>0,0<x<1,0<y<1에 대해 fX(x)=∫102(ax+by)a+bdy=2a+b∫10(ax+by)dy=2a+b(ax+∫10bydy)=2a+b(ax+b2)=2ax+ba+b,0<x<1
fY(y)=∫102(ax+by)a+bdx=2a+b∫10(ax+by)dx=2a+b(a2+by)=a+2bya+b,0<y<1
6. 조건부확률분포(conditional probability distribution)
■ 조건부확률분포는 PX|Y(x)=P(X=x|Y): Y라는 정보가 주어졌을 때, X=x일 확률이다.
■ 확률변수 X,Y의 결합확률분포가 f(x,y)(= PX,Y(x,y))이고,
주변확률분포가 각각 fX(x) (= PX(x)), fY(y) (= PY(y))일 때, Y의 값이 y로 주어지면, X의 조건부확률분포는 fX|Y(x|y)=PX|Y(x|y)=(P(X=x,Y=y)P(Y=y)=fX,Y(x,y)(=PX,Y(x,y))fY(y)(=PY(y)),fY(y)(=PY(y))>0이다. 반대로 X의 값이 x로 주어지면 fY|X(y|x)=fX|Y(x,y)fX(x),fX(x)>0이다.
■ 즉, 조건부확률분포는 분모가 주변확률밀도함수, 분자는 결합확률밀도함수로 구성된 형태이다.
■ 예를 들어
fX|Y(1|3)=PX|Y(1|3)=PX|Y(x=1,y=3)=P(X=1andY=3)P(Y=3)이며, 이는 Y=3일 때 X=1일 확률을 의미한다.
- 이때, Y=3이라는 조건이 주어졌으므로 표본공간은 Y=3일 때로 축소된 것.
분모 P(Y=3)은 P(X=1,Y=3)+P(X=2,Y=3)+P(X=3,Y=3)=320이다.
분자 P(X=1andY=3)=120이므로 fX|Y(1|3)=13이다.
■ 연속확률변수인 경우, fX|Y(x|y)=fX,Y(x,y)fY(y)이면, P(a<X<b∣Y=y)=∫bafX∣Y(x∣y)dx=∫bafX,Y(x,y)fY(y)dx
■ 예를 들어 결합확률분포가 f(x,y)=2(ax+by)a+b,a,b>0,0<x<1,0<y<1이면, fY(y)=a+2bya+b이므로 fX∣Y(x∣y)=f(x,y)fY(y)=2(ax+by)a+2by,0<x<1,0<y<1이다.
만 , Y=12일 때, X가 12보다 작은 확률을 구한다면
P(X<12∣Y=12)=∫120f(X∣Y=12)dx=∫1202ax+ba+bdx=a+2b4a+4b가 된다.
7. 확률변수의 독립
■ 두 사건 A,B에 대해 P(A∩B)=P(A)⋅P(B)이면 A와 B는 독립이었다. 즉, 확률변수 X,Y가 서로의 확률분포에 영향을 미치지 않으면 X와 Y는 서로 독립이다.
■ 두 확률변수 X,Y의 결합확률분포를 fX,Y(x,y), X와 Y의 주변확률분포를 fX(x), fY(y)라 할 때, fX,Y(x,y)=fX(x)⋅fY(y), for all x,y를 만족하면 X와 Y는 독립이다.
■ 예를 들어 확률변수가 이산형이면
| X=0 | X=1 | ||
| Y=0 | 38 | 38 | fY(0)=34 |
| Y=1 | 18 | 18 | fY(1)=14 |
| fX(0)=12 | fX(1)=12 |
1) fX,Y(0,0)=fX(0)⋅fY(0)⟷38=12⋅34
2) fX,Y(0,1)=fX(0)⋅fY(1)⟷18=12⋅14
3) fX,Y(1,0)=fX(1)⋅fY(0)⟷38=12⋅34
4) fX,Y(1,1)=fX(1)⋅fY(1)⟷18=12⋅14
모든 x,y에 대해 fX,Y(x,y)=fX(x)⋅fY(y)를 만족하므로 확률변수 X,Y는 모든 가능한 x,y에 대하여 독립이라고 할 수 있다. 만약 1) ~ 4) 중 하나라도 성립하지 않으면 독립이 아니다.
■ 확률변수가 연속형인 경우, 예를 들어
fX,Y(x,y)=x+y,0<x<1,0<y<1이면, fX(x)=x+12,fY(y)=y+12이므로, x+y≠(x+12)(y+12)이라서 fX,Y(x,y)≠fX(x)⋅fY(y)이다. 따라서 독립이 아니다.
■ n차원으로 확장하면, 확률변수 X1,X2,...,Xn의 결합확률분포를 fx1,x2,...,xn(x1,x2,...,xn)이라 할 때, Xi의 주변확률분포는, 이산형이면 나머지 확률변수들의 영역을 더하거나, 연속형읜 경우 나머지 확률변수들의 영역을 적분하여 구할 수 있다. 만약, 확률변수 X1,X2,...,Xn이 서로 독립이면 fx1,x2,…,xn(x1,x2,…,xn)=fX1(x1)⋅fX2(x2)⋯fXn(xn)이 성립한다.
■ 예를 들어, X1,X2,X3의 결합확률분포 fX1,X2,X3(x1,x2,x3)=6e−x1−2x2−3x3(x1,x2,x3>0)이면,
1) X1의 주변확률분포는 나머지 확률변수 X2,X3의 영역에 대하여 적분하면 된다.
fX1(x1)=∫∞0∫∞06e−x1−2x2−3x3dx2dx3, 이때 x1은 상수로 볼 수 있으므로 ∫∞0∫∞06e−x1−2x2−3x3dx2dx3=e−x1∫∞0∫∞06e−2x2−3x3dx2dx3를 계산하면 된다.
e−x1∫∞0∫∞06e−2x2−3x3dx2dx3=3e−x1∫∞0∫∞02e−2x2−3x3dx2dx3=e−x1∫∞03e−3x3dx3=e−x1,(x1>0)
2) X2,X3의 주변확률분포도 동일한 방식으로 계산하면
fX2(x2)=2⋅e−2x2(x2>0), fX3(x3)=3⋅e−3x3(x3>0) 따라서 fX1,X2,X3(x1,x2,x3)=fX1(x1)⋅fX2(x2)⋅fX3(x3)⟷6⋅e−x1−2x2−3x3=e−x1⋅2e−2x2⋅3e−3x3이 성립하므로 X1,X2,X3은 독립이라고 할 수 있다.
8. 확률변수의 변환
■ 기존에 정의된 확률변수를 이용해 새로운 확률변수를 정의해야 할 때가 있다. 이를 확률변수의 변환이라고 한다.
■ 예를 들어 동전을 10번 던져서 나오는 뒷면의 개수를 확률변수 X라고 할 때, 뒷면 개수의 제곱만큼 1000만큼의 수익이 발생한다면, 수익이라는 새로운 확률변수 Y=1000X2이 된다.
■ 위의 예시와 같이 새로운 확률변수 Y를 기존에 정의된 확률변수 X의 함수 형태인 Y=u(X)로 정의한다. 따라서 Y를 구하기 위해 확률변수 X의 확률분포로부터 새로운 확률변수 Y=u(X)의 확률분포를 구해야 하며, 여러 방법 중 누적분포함수법과 변수변환법이 있다.
8.1 누적분포함수법
■ 연속형 확률변수인 경우만 사용하는 누적분포함수법은 기존에 정의된 확률변수의 확률분포로부터 새로운 확률변수의 누적분포함수를 계산한 후, 이를 미분해 확률밀도함수를 구하는 방법이다.
■ 기존 확률변수 X의 확률밀도함수를 f(x), 새로운 확률변수 Y=u(X)라 하면,
1) Y의 누적분포함수 FY(y)=P(Y≤y)를 계산한다.
FY(y)=P(Y≤y)=P(u(X)≤y)=∫u(X)≤yf(x)dx
2) \( F_{Y}(y)\)를 미분하여 확률변수 Y의 확률밀도함수 fY(y)를 계산하고, 범위를 확인한다. fY(y)=ddyFY(y)
■ 예를 들어 확률변수 X의 확률밀도함수 fx(x)=2x,0≤x≤1일 때, Y=3X−1의 확률분포는
1) FY(y)=P(Y≤y)=P(3X−1≤y)=P(X≤y+13, 이때 P(Y≤y)와 P(X≤y+13의 면적이 같으므로 P(X≤y+13)=∫y+13−∞f(x)dx=∫y+1302xdx=[x2]y+130=(y+13)2
2) fY(y)=ddyFY(y)=ddy(y+13)2=29(y+1)
3) 범위는 0≤X≤1→−1≤3X−1≤2⇔−1≤Y≤2가 된다.
따라서 Y의 확률밀도함수 fY(y)={29(y+1),−1≤Y≤20,otherwise이다.
8.2 변수변환법
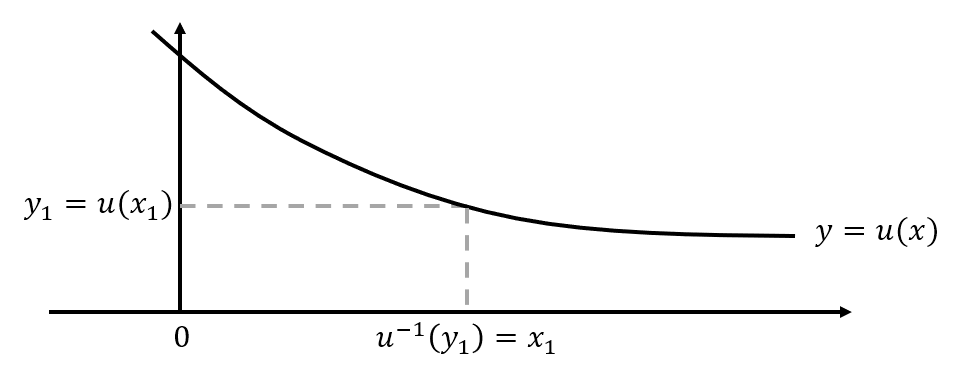
■ 변수변환법은 확률변수 X와 새로운 확률변수 Y=u(X)가 일대일 관계일 경우, 즉 함수 Y=u(X)의 역함수 X=u−1(Y)가 존재할 때 사용할 수 있다.
■확률변수가 이산형인 경우와 연속형인 경우, 모두 사용할 수 있다. 단, 적용 방식에 차이가 있다.
■ 이산형확률변수인 경우, 다음의 식을 이용하여 새로운 확률변수 Y의 확률분포함수를 구한다.
fY(y)=P(Y=y)=P(X=u−1(y))=fX(u−1(y))
■ 이산형확률변수 X에 대해 Y=u(X)에 일대일 변환을 하면 P(X=x)=P(Y=u(X))이므로, X의 확률이 Y의 확률과 같아진다. X의 확률을 Y가 이어 받는 것이라 생각하면 된다.
■ 예를 들어 확률변수 X의 확률분포함수 fX(x)=13(23)x3−2, x=1,2,3,...일 때, 새로운 확률변수가 Y=X2이라면 X의 값이 모두 양수이며, Y=X2이라 단사 함수이다. 따라서 서로 다른 양수인 X의 각 값에 대해 유일한 Y값이 대응되므로 확률변수 X와 Y는 일대일 대응이다. 그리고 y=x2이므로 x=√y. 따라서 확률변수 Y의 확률분포는 fY(√y)=13(23)y⋅√y−2,y=1,4,9,...
■ 연속형확률변수인 경우 X와 Y=u(X)가 일대일 관계일 때, u가 증가함수인지 감소함수인지 구별하여 접근해야 한다.
1) u가 증가함수
- 증가함수는 x1<x2이면 u(x1)<u(x2)이며, u가 증가함수이면 u−1도 증가함수이다. y1<y2⇒U−1(y1)<U−1(y2)
- 예를 들어 y=u(x)가 증가 함수라고 가정하면 x1<x2이면 y1=u(x1)<u(x2)=y2가 성립하고 역함수가 x=u−1(y)일 때, 정의역과 치역이 바뀌고 y1<y2이면 u−1(y1)=x1<u−1(y2)=x2 즉, y1<y2일 때, u−1(y1)<u−1(y2)이 성립한다.
- u(x)≤y1인 x들의 집합과 x≤u−1(y1)인 x들의 집합이 동일하게 된다.

- 따라서 u가 증가함수인 경우,
FY(y)=P(Y≤y)=P(u(X)≤y)=P(u−1(u(X))≤u−1(y))=P(X≤u−1(y))=FX(u−1(y))이므로 Y의 누적분포함수는 FY(y)=FX(u−1(y))이다.
따라서 fY(y)=ddyFY(y)=ddyFX(u−1(y))=fX(u−1(y))×ddy(u−1(y)) (* y에 대한 미분이므로 속미분을 곱해줘야 한다.)
- 만약 −1≤X≤1 범위에서 Y=X2이었다면, Y=X2이 −1≤X≤1의 구간에서 일대일 대응이 아니기 때문에 변수변환법을 적용할 수 없다.

'확률' 카테고리의 다른 글
| 연속형 확률분포 (1) (0) | 2025.02.14 |
|---|---|
| 적률생성함수 (3) | 2025.02.14 |
| 이산형 확률분포 (0) | 2025.02.14 |
| 확률변수의 기댓값과 분산, 공분산, 상관계수 (0) | 2025.02.05 |
| 확률 (0) | 2024.08.28 |



