1. 허프 변환(hough transform)
■ 허프 변환은 영상/이미지에서 모양을 찾는 방법으로 이미지의 형태를 찾거나 깨진 영역을 복원하는 데 사용된다. 특히. 컴퓨터 비전에서 직선 검출은 주로 허프 변환 기법을 사용한다.
■ x, y 좌표 공간(2차원)에서 극좌표계 형식으로 직선의 방정식을 변환하는 이유는 y축과 평행한 수직선의 기울기는 무한대가 되어야 하는데, 직선의 방정식으로는 y축과 평행한 수직선을 표현할 수 없기 때문이다.
■ 극좌표계로 변환했을 때 로우는 원점에서 직선까지의 수직 거리, 세타는 원점에서 직선에 수직선을 내렸을 때 x 축과 이루는 각도이다.
참고) https://m.blog.naver.com/windowsub0406/220894462409
[Udacity] SelfDrivingCar- 2-3. 차선 인식(hough transform)
Python3.5 그리고 Opencv 3.1 기준 코드 작성 셋팅만 제대로 ...
blog.naver.com
[2023-04-11] 1. 허프변환 기반 차선인식
허프변환 기반 차선인식
shpark98.github.io
1.1 허프 변환 직선 검출
■ 이미지는 수많은 픽셀로 구성된다. 이 픽셀 중에서 엣지를 찾아낸 다음, 엣지 픽셀들 중 직선 관계를 갖는 픽셀들만 선택하는 것이 허프 변환 직선 검출의 핵심이다.
■ OpenCV에서는 허프 변환의 수학적 이론이 구현된 cv2.HoughLines(img, rho, theta, threshold, lines, srn=0, stn=0, min_theta, max_theta) 함수를 제공한다.
- img는 8비트, 1채널 바이너리 이미지, 캐니 엣지 선 적용
- rho는 로우 값의 범위(0~1 실수)로 거리 측정 해상도(더 정확히는 축적 배열에서 로우 값의 해상도)
- theta는 세타 값의 범위(0~18- 정수) (더 정확히는 축적 배열에서 세타 값의 해상도)
- threshold는 직선으로 판단할 임곗값. 즉, 만나는 점의 기준이다. 임곗값이 작으면 많은 선이 검출되지만 정확도가 떨어지고, 임곗값이 크면 검출되는 선의 개수가 감소하지만 정확도가 올라간다.
- srn은 멀티 스케일 허프 변환에서 로우 해상도를 나누는 값. 직선 검출에서는 사용하지 않으므로 0으로 지정
- stn은 멀티 스케일 허프 변환에서 세타 해상도를 나누는 값. 직선 검출에서는 사용하지 않으므로 0으로 지정
- min_theta와 max_theta는 검출할 직선의 최소, 최대 세타 값(=각도)
- rho와 theta 파라미터를 조정해 거리와 각도를 얼마나 세밀하게 게산할 것인지 정할 수 있다.
- 단, theta 구간을 촘촘하게 나누면 정밀한 직선 검출이 가능하지만 연산 시간이 늘어나고, 구간을 듬성하게 나누면 연산 속도는 빠르지만, 정확도가 낮아질 수 있다.
- 이는 rho와 theta 파라미터가 cv2.HoughLines() 함수 내부에서 사용할 축적 배열의 크기를 결정하는 역할을 하기 때문이다. 축적 배열에서 로우 간격은 1픽셀 단위, 세타는 1 라디안 단위로 처리한다.
img = cv2.imread('frame01.jpg')
img2 = img.copy()
imgray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 그레이 스케일
edges = cv2.Canny(gray,50,150,apertureSize=3) # 캐니 엣지로 먼저 경곗값 검출
## 허프 변환 직선 검출
lines = cv2.HoughLines(edges,1,np.pi/180,100)
for i in range(len(lines)): # 검출된 직선 순회
for rho, theta in lines[i]:
a, b = np.cos(theta), np.sin(theta)
x0, y0 = a*rho, b*rho # x, y 절편 좌표
## 직선 방정식을 그리기 위한 시작점과 끝점
x1, y1 = int(x0 + 1000*(-b)), int(y0+1000*(a))
x2, y2 = int(x0 - 1000*(-b)), int(y0 -1000*(a))
cv2.line(img, (x1, y1), (x2, y2), (0,0,255), 1) # 빨간 직선 그리기- 동일한 방법으로 threshold = 130으로 지정했을 때의 허프 변환 직선 검출을 수행해서 threshold = 100으로 지정했을 때의 결과와 비교하면 다음 그림과 같다.
plt.subplot(131),plt.imshow(img2[:,:,::-1]),plt.title('original'),plt.xticks([]); plt.yticks([])
plt.subplot(132),plt.imshow(img[:,:,::-1]),plt.title('threshold = 100'),plt.xticks([]); plt.yticks([])
plt.subplot(133),plt.imshow(img3[:,:,::-1]),plt.title('threshold = 130'),plt.xticks([]); plt.yticks([])
plt.show()
- 이 예에서 적합한 threshold 값은 100임을 확인할 수 있다.
- 이렇게 허프 변환은 적합한 파라미터 값을 찾기 위해 값을 바꿔가면서 적합한 값을 찾아야 한다.
1.2 확률적 허프 변환(probabilistic Hough transform) 직선 검출
■ OpenCV는 기본적인 허프 변환 직선 검출 방법 외에 확률적 허프 변환 함수 cv2.HoughLinesP(img, rho, theta, threshold, lines, minLineLength, maxLineGap)를 제공한다.
- minLineLength는 검출할 직선의 최소 길이
- maxLineGap는 직선으로 간주할 최대 간격
- 나머지 피라미터는 cv2.HoughLines()와 동일하다.
- 함수의 반환 값은 직선의 시작과 끝점의 좌표이므로, cv2.HoughLines() 함수를 이용했을 때처럼 직선을 이미지에 그리기 위해 별도의 변환이 필요하지 않다.
■ 기본적인 허프 변환 직선 검출 방법은 모든 점에 대해 선을 그어 가면서 직선을 찾기 때문에 연산량이 많다. 이를 개선한 방법이 확률적 허프 변환에 의한 직선 검출이다.
■ 이 방법은 모든 점을 고려하지 않고 무작위로 선정한 픽셀에 대해 허프 변환을 수행한다.
■ 무작위로 직선을 검출하기 때문에 cv2.HoughLines( ) 함수를 사용했을 때보다 검출되는 직선이 적다. 그러므로 캐니 엣지 검출을 먼저 적용할 때 엣지를 더 뚜렷하게, cv2.HoughLinesP 함수의 threshold 값은 낮게 지정해야 한다.
img = cv2.imread('hough_images.jpg')
edges = cv2.Canny(img,50,200,apertureSize = 3)
gray = cv2.cvtColor(edges,cv2.COLOR_GRAY2BGR)minLineLength, maxLineGap = 100, 0
## 확률적 허프 변환 직선 검출
lines = cv2.HoughLinesP(edges, 1, np.pi/360, 160, minLineLength, maxLineGap)
for i in range(len(lines)): # 검출된 직선 순회
for x1,y1,x2,y2 in lines[i]:
cv2.line(img,(x1,y1),(x2,y2),(0,0,255),3) # 빨간 직선 그리기cv2.imshow('img1',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 왼쪽은 minLineLength, maxLineGap = 100, 10, 오른쪽은 비교를 위해 minLineLength, maxLineGap = 100, 10으로 동일한 직선 검출을 수행한 결과이다.
- 우선 왼쪽의 경우 화단 부분의 윤곽선(엣지)이 복잡해서 해당 부분도 직선으로 검출되었다.
- 직선으로 간주할 엣지 픽셀의 최대 간격을 늘린 결과, 오른쪽 그림처럼 화단 부분의 복잡하고 매우 작은 엣지는 무시되었지만, 건물 부분의 엣지도 무시된 것을 볼 수 있다.
1.3 허프 변환 원 검출
■ 허프 변환을 이용한 원 검출도 직선 검출처럼 직선의 방정식을 파라미터 공간으로 변환하는 허프 변환을 중심 좌표가 (a, b)이고 반지름이 r인 원의 방정식 \( (x-a)^2 + (y-b)^2 = r^2 \)에 적용하면 된다.
■ 하지만 원의 방정식은 세 개의 파라미터를 가지므로 허프 변환을 적용하면 3차원 파라미터 공간에서 축적 배열 계산을 수행해야 하기 때문에 많은 메모리와 연산 시간이 필요하다.
■ OpenCV에서는 위와 같은 일반적인 허프 변환 대신 허프 그래디언트 방법(Hough gradient method)을 사용하는 cv2.HoughCircles(img, method, dp, minDist, circles, param1, param2, minRadius, maxRadius) 함수를 제공한다.
■ cv2.HoughCircles( ) 함수는 캐니 엣지를 수행한 뒤, 소벨 필터를 적용해 엣지의 그래디언트를 누적하는 방법으로 원을 검출한다.
■ cv2.HoughCircles( ) 함수의 파라미터는 다음과 같다.
- img에는 입력 영상/이미지로 1채널 그레이스케일 영상/이미지를 지정한다.
- method는 검출 방식으로 현재 cv2.HOUGH_GRADIENT만 사용할 수 있다.
- dp는 입력 영상과 경사 누적의 해상도 반비례율로 1에 가까울수록 정확하게 원을 검출하며, 값이 커질수록 부정확해진다. 즉, dp 값은 값을 점차 키워가면서 적합한 값을 찾아야 한다.
- dp 값을 1로 지정할 경우 입력 영상/이미지와 같은 크기의 축적 배열을 사용한다. 2로 지정하면 입력 영상/이미지의 가로와 세로 크기를 2로 나눈 크기의 축적 배열을 사용한다.
- minDist는 인접한 원들 중심 간의 최소 거리이다. 두 원의 중심점 사이의 거리가 minDist보다 작으면 두 원 중 하나는 검출되지 않는다. 그리고 동심원을 검출할 때 이 값이 0이면 최소 거리가 0이므로 동심원 검출을 수행할 수 없다.
- param1은 캐니 엣지에 전달할 스레시홀드 최댓값이다.
- param2는 경사도 누적 경곗값으로 값이 작을수록 잘못된 원을 검출할 수 있다.
- minRadius, maxRadius는 검출할 원의 최소, 최대 반지름이다. 만약, 검출할 원의 대략적인 크기를 알고 있어 minRadius와 maxRadius 값을 적절하게 지정한다면 연산 속도를 향상시킬 수 있다.
img = cv2.imread('coins_spread.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (3,3), 0) # 가우시안 블러링으로 노이즈 제거
## 허프 변환 원 검출
circles = cv2.HoughCircles(blur, cv2.HOUGH_GRADIENT, dp = 1.5, minDist = 30, circles = None, param1 = 200)- cv2.HoughCircles( ) 함수 내에서 자체적으로 캐니 엣지를 사용하므로, 노이즈만 제거하고 별도로 엣지 검출은 수행하지 않는다.
if circles is not None:
circles = np.uint16(np.around(circles))
for i in circles[0,:]:
cv2.circle(img,(i[0], i[1]), i[2], (0, 255, 0), 2) # 원 둘레에 초록색 원 그리기
cv2.circle(img, (i[0], i[1]), 2, (0,0,255), 5) # 원 중심점에 빨강색 원 그리기
cv2.imshow('hough circle', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
2. 연속 영역 분할
2.1 거리 변환(Distatnce Transformation)
■ 이미지에서 객체 영역을 정확히 파악하려면 객체 영역의 뼈대(skeleton)를 찾는 것이 중요하다.
■ 거리 변환은 그 뼈대를 검출하는 방법으로 외곽 경계로부터 가장 멀리 떨어진 객체 영역의 뼈대를 찾는다. 정확히는 바이너리 이미지를 이용해 픽셀 값이 0인 배경으로부터 가장 멀리 떨어진 전경(객체 영역)의 픽셀 값 255인 부분을 찾는다.
■ OpenCV에서는 거리 변환을 수행하는 cv2.distanceTransform(src, distanceType, maskSize) 함수를 제공한다.
- src는 입력 영상/이미지로 1채널 그레이스케일 영상/이미지를 지정한다.
- distanceType에는 거리를 계산할 방식을 지정한다.
| distance Type | 의미 |
| cv2.DIST_L1 | 맨해튼 거리(Manhattan distance) |
| cv2.DIST_L2 | 유클리드 거리(Euclidean distance) |
| cv2.DIST_L12 | L1+L2 형태로 결합된 거리 계산을 수행 |
| cv2.DIST_C | 체비쇼프 거리(Chebyshev distance) |
| cv2.DIST_FAIR | 공정 거리(Fair distance) |
| cv2.DIST_WELSCH | 웰치 거리(Welsch distance) |
| cv2.DIST_HUBER | 후버 거리(Huber distance) |
- maskSize는 거리 변환 커널(필터)의 크기이다.
img = cv2.imread('VthxV.png')
img.shape
```#결과#```
(486, 729, 3)
````````````
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 그레이스케일
_, th = cv2.threshold(gray, 40, 255, cv2.THRESH_BINARY) # 바이너리## 거리 변환
dst = cv2.distanceTransform(th, cv2.DIST_L1, 3)
## 거리 값을 0 ~ 255 범위로 정규화
dst = cv2.normalize(dst, None, alpha=0, beta=255, norm_type=cv2.NORM_MINMAX, dtype=cv2.CV_8U)
## 거리 값에서 완전한 뼈대(픽셀 값 255) 추출
skeleton = cv2.adaptiveThreshold(dst, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 7, -3)
- 첫 번째 이미지는 거리 변환을 하기 위해 입력으로 사용한 바이너리 이미지,
- 두 번째 이미지는 0~255 범위로 정규화한 거리 변환 결과 이미지이다. 외곽 경계로부터 멀어질수록 흰색이 짙어지는 것을 볼 수 있다.
- 마지막 이미지는 경계로부터 가장 멀리 떨어져 있는 뼈대의 픽셀(흰색, 255)을 추출한 것이다.
2.2 연결 요소 레이블링
■ 레이블링은 바이너리 이미지에서 연결된 요소를 분리하는 방법으로 다음 그림과 같이 바이너리 이미지 전체에서 픽셀 값이 0으로 끊어지지 않는 부분끼리 동일한 값을 부여해서 분리한다.

■ OpenCV에서는 cv2.connectedComponents(src, labels, connectivity=8, ltype=CV_32S) 함수를 이용해 레이블링을 수행할 수 있다.
- src는 바이너리 스케일의 영상/이미지
- connectivity는 연결성을 검사할 방향 개수로 8 또는 4를 지정할 수 있다.
- ltype은 결과 레이블의 dtype으로 CV_325 또는 CV_16S를 지정할 수 있다.
- 함수의 결과로 레이블 맵 행렬과 레이블 개수가 반환된다.
■ cv2.connectedComponents( ) 함수는 기본적인 레이블링 함수로 레이블 맵을 반환하지만, 객체 영역의 통계 정보(레이블링 수행 후, 각각의 객체 영역이 어느 위치에 있는지, 어느 정도 크기인지 등)가 제공되지 않는다.
■ cv2.connectedComponentsWithStats(src, labels, stats, centroids, connectivity, ltype) 함수를 이용하면 레이블 맵과 레이블링된 객체 영역의 통계 정보를 한꺼번에 얻을 수 있다.
- 함수의 결과로 레이블 맵 행렬과 레이블 개수뿐만 아니라 [x 좌표, y 좌표, 폭, 높이, 너비]에 대한 정보가 담긴 N(레이블 개수) x 5 행렬과 각 레이블의 중심점 좌표를 추가로 반환한다.
img = cv2.imread('chessboard.jpg')
img2 = np.zeros_like(img) # 결과 이미지
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 그레이스케일
_, th = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY) # 바이너리
## 바이너리 이미지에 레이블링
retval, labels, stats, centroids = cv2.connectedComponentsWithStats(th)
print(retval)
```#결과#```
34
````````````- 총 34개의 레이블링이 적용된 것을 확인할 수 있다.
## 레이블이 같은 영역에 랜덤한 색상 적용
for i in range(retval): ## 레이블 갯수 만큼 반복
img2[labels==i] = [int(j) for j in np.random.randint(0,255, 3)]
# 0부터 255 사이 3개의 값 랜덤으로 뽑음 # 이 3개의 값이 순서대로 B, G, R에 해당된다.
# 이 B,G,R을 img2[labels==i]에 넣는다.
plt.subplot(121),plt.imshow(img[:,:,::-1]),plt.title('origin'),plt.xticks([]); plt.yticks([])
plt.subplot(122),plt.imshow(img2[:,:,::-1]),plt.title('labeled'),plt.xticks([]); plt.yticks([])
plt.show()
- 연결된 부분(같은 레이블을 가지는 영역)끼리는 동일한 색상이 칠해진 것을 볼 수 있다.
2.3 워터셰드(Watershed)
참고) https://opencv-python.readthedocs.io/en/latest/doc/27.imageWaterShed/imageWaterShed.html
■ 워터셰드 알고리즘의 개념은 다음과 같다.
- 이미지를 그레이스케일로 변환하면 각 픽셀의 값은 0~255 사이의 값을 갖게 된다. 이 값으로 픽셀 값의 높고 낮음을 구분할 수 있다.
- 이것을 지형의 높낮이로 가정하면, 높은 픽셀 값은 봉우리(peak), 낮은 부분을 골짜기(valley)라고 표현할 수 있다.
- 이곳에 물을 붓는다고 하면 골짜기 영역 중 같은 높이의 연속된 영역에는 물웅덩이가 형성되고, 높낮이가 다르므로 물웅덩이를 경계로 만들면 물이 서로 섞이지 않을 것이다.
- 이런 경계선을 이미지의 구분 지점으로 설정하여 다음 그림처럼 이미지를 분할하는 것이 워터셰드 알고리즘의 개념이다.

■ OpenCV에서는 워터셰드 함수 cv2.watershed(img, markers)를 제공한다.
- img는 입력 이미지
- markers는 마커로 입력 이미지와 크기가 같은 1차원 배열이다.
- markers의 값은 경계를 찾고자 하는 픽셀 영역은 -1을 갖게 하고, 나머지 연속된 영역에서는 동일한 정숫값을 갖게 한다.
- 워터셰드 함수를 적용했을 때 생기는 -1인 영역이 경곗값이 된다.
img = cv2.imread('watershed.jpg')
img2 = img.copy()
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) # 그레이 스케일
ret, thresh = cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU) # 바이너리
#Morphology의 opening, closing을 통해서 노이즈나 Hole제거
kernel = np.ones((3,3),np.uint8)
opening = cv2.morphologyEx(thresh,cv2.MORPH_OPEN,kernel,iterations=2)- marker를 통해 전경(객체)과 배경, 그리고 객체가 아닌 아무것도 확신하지 못하는 지역에 레이블을 붙여야 한다.
- 먼저 전경과 배경을 구분해야 한다.
- dilate를 이용해서 서로 연결되지 않은 부분을 확실한 배경으로 간주한다.
- 거리 변환을 적용하면 뼈대(Skeleton) 이미지를 얻을 수 있다. 이 뼈대 이미지에 스레시홀딩을 적용해서 확실한 전경을 찾는다.
sure_bg = cv2.dilate(opening,kernel,iterations=3) # dilate
dist_transform = cv2.distanceTransform(opening,cv2.DIST_L2,5) # 거리 변환
ret, sure_fg = cv2.threshold(dist_transform,0.5*dist_transform.max(),255,0) # 스레시홀딩
sure_fg = np.uint8(sure_fg)- 전경과 배경을 구분했다면, 이제 확실하지 않은 영역을 파악해야 한다. 이 영역은 배경에서 전경을 뺀 영역이다.
## Background에서 Foregrand를 제외한 영역을 Unknow영역으로 파악
unknown = cv2.subtract(sure_bg, sure_fg)- 전경, 배경, 그리고 unknown 영역을 찾았으면, 이제 전경에 레이블링 작업을 한다.
- 레이블링으로 각 영역에 라벨을 붙이게 되고, 이것이 바로 marker가 된다.
## 전경에 레이블링작업
ret, markers = cv2.connectedComponents(sure_fg)
markers = markers + 1
markers[unknown == 255] = 0- 이제 cv2.watershed( ) 함수를 적용하면 객체의 경계는 -1 값을 갖게 된다.
## watershed를 적용
markers = cv2.watershed(img,markers)
img[markers == -1] = [0,255,0] # 마커에 -1로 표시된 경계를 초록색으로 표시plt.subplot(231),plt.imshow(thresh, cmap = 'gray'),plt.title('binary'),plt.axis('off')
plt.subplot(232),plt.imshow(sure_bg, cmap = 'gray'),plt.title('sure_bg'),plt.axis('off')
plt.subplot(233),plt.imshow(dist_transform, cmap = 'gray'),plt.title('dist_transform'),plt.axis('off')
plt.subplot(234),plt.imshow(sure_fg, cmap = 'gray'),plt.title('sure_fg'),plt.axis('off')
plt.subplot(235),plt.imshow(unknown, cmap = 'gray'),plt.title('unknown'),plt.axis('off')
plt.subplot(236),plt.imshow(markers),plt.title('markers'),plt.axis('off')
plt.show()
cv2.imshow('original', img2)
cv2.imshow('result', img)
cv2.waitKey()
cv2.destroyAllWindows()
2.4 그랩컷(Graph Cut)
참고) https://deep-learning-study.tistory.com/240
■ 그랩컷은 픽셀을 그래프의 정점(vertex)으로 간주하고 픽셀들을 전경 영역과 배경 영역으로 분할하는 최적의 컷(cut)을 찾는 방법이다.
■ 전경과 배경을 분리하기 위해(최적 컷을 찾기 위해) 색상 분포를 추정해서 동일한 레이블을 가진 정점(픽셀)끼리 분리한다.
■ OpenCV에서는 그랩컷 함수 cv2.grabCut(img, mask, rect, bgdModel, fgdModel, iterCount, mode)를 제공한다.
- img는 입력 이미지
- mask는 입력 이미지와 크기가 같은 1채널 배열로 배경과 전경을 구분하는 값을 저장한다.
- mask는 4개의 값으로 구성된다.
| mask | 의미 |
| cv2.GC_BGD(0) | 확실한 배경 |
| cv2.GC_FGD(1) | 확실한 전경 |
| cv2.GC_PR_BGD(2) | 아마도 배경 |
| cv2.GC_PR_FGD(3) | 아마도 전경 |
- rect는 ROI 영역으로 전경이 있을 것으로 추측되는 영역의 사각형 좌표(x1, y1, x2, y2)이다.
- bgdModel는 임시 배경 모델 행렬, fgdModel는 임시 전경 모델 행렬
- iterCount는 그랩컷을 수행할 반복 횟수
- mode는 동작 방법으로 cv2.GC_INIT_WITH_RECT을 지정하면 rect에 지정한 좌표를 기준으로 그랩컷을 수행하고, cv2.GC_INIT_WITH_MASK를 지정하면 mask에 지정한 값을 기준으로 그랩컷을 수행한다.
- 함수의 결과로 mask, bgdModel, fgdModel이 반환된다.
■ cv2.grabCut( )의 mode에 cv2.GC_INIT_WITH_RECT을 지정하면 세 번째 파라미터 rect에 지정한 사각형 좌표로 전경과 배경을 분리한다.
- 분리된 결과는 두 번째 파라미터인 mask에 할당. 이 mask가 함수의 결과로 반환된다.
- mask에 할당받은 값이 0이면 확실한 배경, 1이면 확실한 전경, 2와 3이면 아마도 배경, 전경일 가능성이 있다는 의미이다.
- 이렇게 1차적으로 전경과 배경을 분리한 뒤, mode에 cv2.GC_INIT_WITH_MASK를 지정해서 다시 cv2.grabCut( )를 적용하면, 더 정확한 mask를 얻을 수 있다. 이때 bgdModel, fgdModel은 cv2.grabCut( ) 함수 내부에서 사용할 임시 배경과 전경이다.
- bgdModel, fgdModel을 통해 재귀적으로 전경과 배경을 계속 분리해서 mask를 업데이트한다. 단, bgdModel, fgdModel은 이전 연산을 반영하기 때문에 같은 영상/이미지 처리 시에는 그 내용을 변경하면 안 된다.
img = cv2.imread('img3.jpg')
x,y,w,h = cv2.selectROI('img', img, False)
if w and h:
roi = img[y:y+h, x:x+w]
cv2.imshow('cropped', roi)
cv2.moveWindow('cropped', 0, 0)
print(x,y,w,h)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
```#결과#```
67 97 179 67
````````````rect = [67, 97, 179, 67] # 전경으로 사용할 영역
mask = np.zeros(img.shape[:2], dtype=np.uint8) # (검정색으로 채워진) 마스크 생성
## 그랩컷 적용
cv2.grabCut(img, mask, tuple(rect), None, None, 1, mode = cv2.GC_INIT_WITH_RECT)img2 = img.copy()
## 마스크로 확실한 배경과 아마도 배경으로 표시된 영역을 0(검은색)으로 채우기
img2[(mask==cv2.GC_BGD) | (mask==cv2.GC_PR_BGD)] = 0
cv2.imshow('grabcut', img2)
cv2.waitKey()
cv2.destroyAllWindows()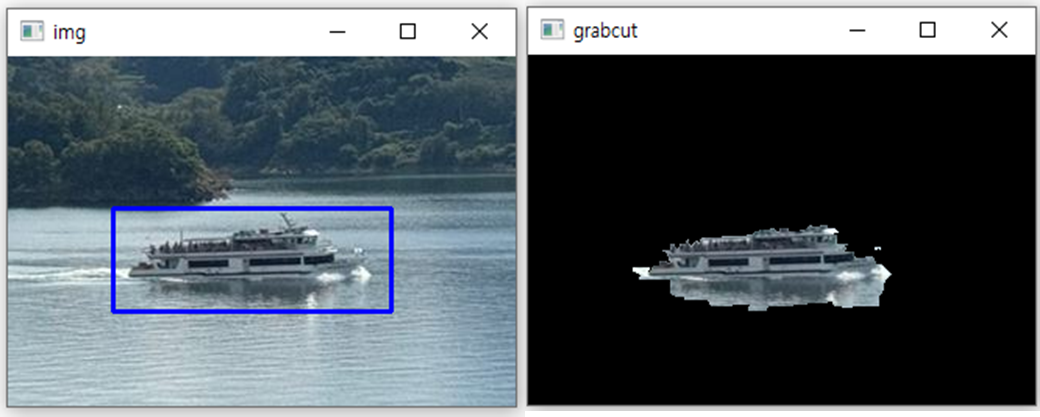
'OpenCV' 카테고리의 다른 글
| 매칭(Matching) (2) (2) | 2024.12.24 |
|---|---|
| 매칭(Matching) (1) (0) | 2024.12.23 |
| 분할(segmentation) (1) (0) | 2024.12.22 |
| 모폴로지(Morphology) 연산, 이미지 피라미드(Image Pyramid) (0) | 2024.12.21 |
| 필터와 블러링 (0) | 2024.12.18 |



