■ AutoGen은 개발자가 서로 대화할 수 있는 multiple agents을 통해 LLM applications을 구축할 수 있도록 하는 open-source framework이다.
■ AutoGen agents는 customizable하고 conversable하다. 그리고 LLM, human inputs, tools의 조합을 활용하는 다양한 모드에서 작동할 수 있다.
■ 또한, AutoGen을 사용하여 에이전트의 상호작용 방식도 개발자가 유연하게 정의할 수 있다.
■ 다양한 applications을 구축하기 위한 유연한 대화 패턴을 프로그래밍하는 데 자연어와 컴퓨터 코드를 모두 사용할 수 있다.
[2308.08155] AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
AutoGen is an open-source framework that allows developers to build LLM applications via multiple agents that can converse with each other to accomplish tasks. AutoGen agents are customizable, conversable, and can operate in various modes that employ combi
arxiv.org
1. Introduction
■ LLM은 많은 real-world tasks에서 reasoning, tool usage, 그리고 새로운 observations에 대한 적응까지 수행하는 강력한 에이전트를 개발하는 데 있어 중요한 구성 요소가 되고 있다.
■ task의 범위가 확장되고 복잡성이 증가함에 따라, 에이전트의 역량을 확장하기 위한 직관적인 접근법은 multiple agents을 사용하는 것이다.
■ 선행 연구들에 따르면 multiple agents은 divergent thinking, factuality 및 reasoning 능력 향상, 그리고 검증 기능까지 제공할 수 있다.
■ 이런 흐름 속에서 저자들의 목표는 "multi-agent approach에 기반하여, 광범위한 도메인과 복잡성을 포괄하는 LLM application 개발을 어떻게 더 쉽게 만들 수 있는가?"이다.
■ 이를 달성하기 위한 저자들의 접근은 "multi-agent conversations"을 사용하는 것이다.
■ 저자들은 이러한 방식이 가능하고 유용한 이유를 다음 세 가지로 설명한다.
- (1) chat-optimized LLMs (예: GPT-4)은 피드백을 통합하는 능력을 보여주었다.
- 이를 통해 LLM 에이전트들이 서로 간에 또는 인간과의 대화를 통해 협력(예: 서로 reasoning, observation, critique, validation을 주고받는 방식)할 수 있다.
- (2) single LLM은 (특히 적절한 프롬프트 및 추론 설정으로 구성될 때) 다양한 능력을 발휘할 수 있다.
- 그러므로, 서로 다르게 설정된 에이전트 간의 대화는 이 능력들을 모듈식의 보완적인 방식으로 결합할 수 있다.
- (3) LLM은 복잡한 task를 더 단순한 subtasks로 분할했을 때 더 잘 푸는 능력을 입증했다.
- multi-agent conversation은 바로 이런 분할과 통합을 자연스럽게 수행할 수 있다.
■ 그러나 단순히 에이전트 수를 늘리는 것만으로는 부족하다. 실제 applications에서는 LLM, humans, tools과 같이 서로 다른 능력을 가진 여러 구성요소가 함께 들어갈 수 있기 때문이다.
■ 그래서 저자들은 범용적인 추상화와 효과적인 구현체를 갖춘 multi-agent conversation framework가 필요하다고 말한다.
■ 그리고 이를 달성하기 위해 풀어야 할 두 가지 문제를 제시한다.
- (1) multi-agent 협업에서 유능하고, 재사용 가능하며, customizable할 수 있는 개별 에이전트를 어떻게 설계해야 하는가
- (2) 어떻게 하면 광범위한 에이전트 대화 패턴을 수용할 수 있는 unified interface를 만들 수 있는가
■ 애플리케이션은 서로 다른 복잡도를 가지기 때문에, 필요한 에이전트 집합도 달라지고, 대화 방식도 single-turn / multi-turn, 다양한 human involvement modes, static vs. dynamic conversation 등 서로 다른 대화 패턴을 요구할 수 있다.
■ 그리고 개발자 입장에서는 에이전트와 상호작용을 자연어로 제어하고 싶을 수도 있고, 코드로 프로그래밍하고 싶을 수도 있기 때문에 유연성이 필요하다.
■ 저자들은 AutoGen이 generalized multi-agent conversation framework라고 규정한다. AutoGen은 다음 두 가지 개념에 기반한다.

1. Customizable and conversable agents
■ AutoGen은 LLMs, human inputs, tools, 또는 이들의 조합을 활용할 수 있는 generic한 design을 사용한다.
■ 이 덕분에 개발자는 built-in capabilities에서 필요한 일부를 선택하고 설정하는 것만으로도 서로 다른 역할(예: 코드 작성, 코드 실행, 인간 피드백 연결, 출력 검증 등을 수행하는 에이전트)을 가진 에이전트들을 쉽고 빠르게 생성할 수 있다.
■ 또한 agent의 backend는 더 복잡한 맞춤형 행동을 허용하도록 쉽게 확장될 수 있다.
■ multi-agent conversation에 적합하게 만들기 위해, 모든 에이전트는 conversable하도록 만들어졌다. 즉, 에이전트들은 메시지를 받고, 반응하며, 응답할 수 있다.
■ 적절하게 설정하면, 한 에이전트는 자율적으로 다른 에이전트와 여러 턴의 대화를 진행하거나, 특정 라운드에서 인간의 입력을 요청하여 인간의 개입과 자동화를 모두 지원할 수 있다.
■ 이러한 conversable agent 설계는 채팅을 통해 피드백을 수용하고 개선하는 LLM의 능력을 활용하며, LLM의 역량들을 모듈식으로 결합할 수 있게 한다. (섹션 2.1)
2. Conversation programming
■ AutoGen의 핵심은 복잡한 LLM 애플리케이션 workflows을 "multi-agent conversations라는 공통 형식으로 단순화하고 통일"할 수 있다는 것이다.
■ 그래서 AutoGen은 이러한 inter-agent conversations을 중심으로 하는 프로그래밍 패러다임을 채택하며, 저자들은 이 패러다임을 "conversation programming"이라고 부른다.
■ 이 패러다임은 두 가지 primary steps을 통해 복잡한 애플리케이션의 개발을 간소화한다.
- (1) 앞서 말한 대로, 특정 역할과 능력을 가진 대화 가능한 에이전트 집합을 정의하는 것
- (2) 대화 중심의 연산 및 제어를 통해 에이전트 간의 interaction behavior를 프로그래밍하는 것
■ 이 두 단계 모두 자연어와 프로그래밍 언어의 fusion을 통해 달성될 수 있으며, 이를 통해 광범위한 대화 패턴과 에이전트 행동을 가진 애플리케이션을 구축할 수 있다.
■ 정리하면, AutoGen의 핵심 설계 원칙은 multi-agent conversations을 통해 multi-agent workflows을 단순화하고 통합하는 것이다.
2. The AutoGen Framework
■ 이 섹션에서는 AutoGen의 두 가지 핵심 개념인 "conversable agents"와 "conversation programming"에 대해 설명한다.
2.1 Conversable Agents
■ AutoGen에서 "conversable agent"란 대화 가능한 다른 에이전트와 정보를 주고받기 위해 메시지를 전달할 수 있는 특정 역할을 가진 entity이다.
■ conversable agent는 주고 받은 메시지들을 기반으로 자체적인 internal context를 유지하며, LLMs, tools, 또는 human input 등을 통해 다양한 capabilities을 부여받을 수 있다.
■ 에이전트는 다음과 같은 프로그래밍된 행동 패턴에 따라 동작할 수 있다.
Agent capabilities powered by LLMs, humans, and tools
■ 에이전트의 역량은 메시지를 처리하고 응답하는 방식에 직접적인 영향을 미친다. 그래서 AutoGen은 에이전트에게 다양한 역량을 부여할 수 있는 유연성을 허용한다.
■ AutoGen은 에이전트를 위해 조합 가능한 여러 capabilities을 지원하며, 여기에는 다음과 같은 것들이 포함된다.
- (1) LLMs
- LLM-backed agents은 role playing, conversation history를 조건화하여 implicit state 추론, feedback, feedback에 대한 적응, 그리고 코딩과 같은 고급 능력 등 다양한 능력을 활용할 수 있다.
- 중요한 점은 이러한 능력들이 하나로 고정되어 있는 것이 아니라, prompting techniques을 통해 여러 방식으로 결합될 수 있어 agent의 숙련도와 자율성을 높일 수 있다는 것이다.
- 또한 AutoGen은 LLM inference layer를 통해 결과 캐싱, 에러 처리, 메시지 템플릿화 같은 LLM 추론 기능을 제공한다.
- (2) Humans
- 많은 LLM 애플리케이션에서 인간의 개입은 종종 요구되거나 필수적일 수 있다.
- 그래서 AutoGen은 인간이 agent conversation에 참여할 수 있도록 human-backed agent를 지원한다. 이 에이전트는 설정에 따라 특정 턴에서 human input을 요청할 수 있다.
- 특히 기본 제공되는 default user proxy agent는 인간이 입력을 skip하거나, 입력 요청의 빈도와 조건 등 인간 참여의 수준과 패턴을 세밀하게 조절할 수 있다.
- (3) Tools
- tool-backed agents은 코드 실행이나 함수 실행을 통해 tools을 실행할 수 있다.
- 예를 들어 default user proxy agent는 LLM이 제안한 코드를 실행하거나 LLM이 제안한 function calls을 수행할 수 있다.
Agent customization and cooperation
■ 애플리케이션별 요구에 따라, 각 에이전트는 위에서 말한 basic backend 유형들을 혼합하여 복합적인 행동을 하도록 구성될 수 있다.
■ AutoGen은 built-in agents을 재사용하거나 확장하여 전문적인 역량과 역할을 가진 에이전트를 쉽게 생성할 수 있게 한다. Fig 2의 노란색 부분은 AutoGen의 built-in agents 구조이다.

■ ConversableAgent 클래스는 가장 상위의 추상화이며, 기본적으로 LLMs, humans, 그리고 tools을 사용할 수 있다.
■ AssistantAgent와 UserProxyAgent는 미리 설정된 두 개의 subclasses로, 각각 일반적인 사용 모드를 나타낸다. AssistantAgent는 AI assistant 역할, UserProxyAgent는 인간 입력을 받거나 코드/함수 실행을 수행하는 human proxy(실제 humans 및/또는 tools) 역할을 맡는다.
■ Fig 1의 오른쪽 예시는 LLM-backed assistant agent와 tool- 및 human-backed user proxy가 함께 하나의 task를 해결한다.
■ 이 예시에서 assistant agent는 LLM의 도움을 받아 솔루션을 생성하고, 그 솔루션을 user proxy agent에게 전달한다. 그런 다음, user proxy agent는 human inputs을 요청하거나 assistant의 코드를 실행하고, 그 결과를 피드백으로서 assistant에게 다시 전달한다.
■ AutoGen의 conversable agents은 서로 대화할 수 있는 custom agents을 지원하는 유용한 구성 요소이다. 단, 에이전트들이 단순히 메시지만 주고받는 것만으로는 유의미한 애플리케이션을 개발하기엔 부족하다.
■ 에이전트가 tasks을 의미 있게 수행하는 애플리케이션을 개발하려면 개발자가 이러한 multi-agent conversations을 구체적으로 지정하고 조정할 수 있어야 한다.
2.2 Conversation Programming
■ 이에 대한 해결책으로, AutoGen은 "conversation programming"이라는 패러다임을 활용한다. 이 패러다임은 두 가지 개념에 중심을 둔다.
■ 첫 번째는 "computation"으로, multi-agent conversation에서 에이전트가 응답을 만들기 위해 취하는 actions이다. 두 번째는 "control flow"로 computation들이 발생하는 어떤 순서(또는 조건)이다.
■ 이 두 요소를 프로그래밍하는 능력은 다양하고 유연한 multi-agent conversation patterns을 구현하는 데 도움을 준다.
■ AutoGen 안에서 computation은 onversation-centric이다. 에이전트는 자신이 관여한 대화와 관련된 행동을 취하며, 그 행동은 (종료 조건이 충족되지 않는 한) 후속 대화를 위한 메시지 전달로 이어진다.
■ computation과 유사하게, control flow는 conversation-driven이다. 대화에 참여하는 에이전트들이 어떤 에이전트에게 메시지를 보낼지에 대한 결정과 computation의 절차는 에이전트들 사이에서 오간 대화로 결정된다.
■ 이런 패러다임 덕분에 복잡한 워크플로우도 "에이전트가 행동하고, 메시지를 주고받는 과정"으로 보다 직관적으로 이해할 수 있다.
■ Fig 2의 하단은 각 에이전트들이 응답을 생성하기 위해 자신의 역할에 맞는 conversation-centric computations을 수행하는 과정을 보여준다. task는 대화를 통해 진행된다.
■ 가운데 부분은 conversation-based control flow를 보여준다. assistant가 메시지를 받으면, user proxy agent는 human input을 답장으로 보낸다. 만약 input이 없다면, assistant의 메시지에 포함된 코드를 실행한다.
1. Unified interfaces and auto-reply mechanisms for automated agent chat
■ AutoGen의 에이전트들은 모두 unified conversation interfaces를 가지는데, 여기에는 메시지를 송수신하기 위한 send/receive 함수와, 수신된 메시지를 바탕으로 행동을 취하고 응답을 생성하기 위한 generate_reply 함수가 포함된다.
■ 또한 AutoGen은 conversation-driven control을 실현하기 위해 agent auto-reply mechanism을 채택했다: 에이전트가 다른 에이전트로부터 메시지를 받으면, 종료 조건이 만족되지 않는 한 자동으로 generate_reply를 호출하고 메시지를 보낸 에이전트에게 답장을 보낸다.
■ 이를 위해 AutoGen은 LLM inference, code나 function 실행, 또는 human input을 기반으로 하는 built-in reply functions을 제공한다. 또한 sender agent에게 답장하기 전에 다른 에이전트와 먼저 채팅을 하는 등, 에이전트의 행동 패턴을 customize하기 위해 custom reply functions을 등록할 수도 있다.
■ 이 메커니즘을 통해 reply functions이 등록되고 대화가 초기화되면 대화 흐름이 자연스럽게 유도되므로, 대화 흐름을 control하는 special module(별도의 control plane) 없이도 에이전트 대화가 자연스럽게 진행된다. 예를 들어 Fig 2의 회색 부분의 대화 상자에 나타난 것처럼 자동으로 진행된다.
2. Control by fusion of programming and natural language
■ AutoGen은 다양한 control flow management patterns에서 프로그래밍과 자연어 사용을 허용하도록 설계되었다.
- (1) Natural-language control via LLMs
- AutoGen에서는 LLM-backed agents에게 자연어로 프롬프팅하여 대화 흐름을 제어할 수 있다.
- 예를 들어, built-in AssistantAgent의 기본 system message는, 이전 결과에 오류가 있으면 코드를 고쳐 다시 생성하도록 자연어로 지시한다.
- 또한 LLM output을 특정 구조로 제한하도록 에이전트를 유도하여, tool-backed agents이 그 결과를 더 쉽게 사용하기 쉽게 만들 수 있다.
- 예를 들어, 모든 tasks가 완료되어 프로그램을 종료할 때 에이전트에게 "TERMINATE"로 응답하도록 지시하는 것이다. (Appendix C)
- (2) Programming-language control
- AutoGen에서 파이썬 코드는 종료 조건, human input mode, 그리고 최대 auto-reply 횟수와 같은 tool execution logic을 지정하는 데 사용될 수 있다.
- Fig 2에서 "Conversation-Driven Control Flow" 코드 블록처럼, 대화 흐름을 제어하기 위해 파이썬 코드로 프로그래밍된 auto-reply functions을 등록할 수 있다.
- (3) Control transition between natural and programming language
- AutoGen은 자연어와 프로그래밍 언어 간의 유연한 control transition을 지원한다.
- customized reply function 내에서 특정 control logic을 포함하는 LLM inference를 호출하여 code control에서 natural language control로 전환할 수 있으며, 또는 LLM이 제안한 function calls을 통해 natural language에서 code control로 전환할 수도 있다.
■ 이러한 conversation programming 패러다임에서 사용자는 다양한 패턴의 multi-agent conversations을 구현할 수 있다.
■ 미리 정의된 대화 흐름을 가진 static conversation 외에도, AutoGen은 여러 에이전트가 참여하는 dynamic conversation flow도 지원한다.
■ AutoGen은 이를 달성하기 위한 두 가지 일반적인 방법을 제공한다.
- (1) Customized generate_reply function: customized generate_reply function 내에서 한 에이전트는 현재 메시지와 컨텍스트의 내용에 따라 현재 대화를 보류한 채 다른 에이전트들과의 대화를 호출할 수 있다.
- (2) Function calls: LLM은 대화 상태에 따라 특정 함수를 호출할지 여부를 결정한다. 호출된 함수 내에서 다른 에이전트에게 메시지를 보냄으로써, LLM은 dynamic multi-agent conversation을 주도할 수 있다.
- 추가적으로, AutoGen은 built-in GroupChatManager를 제공하여 더 복잡한 dynamic group chat을 지원한다. 이 매니저는 다음에 누가 발언할지 동적으로 speaker를 선택하고, 그 응답을 다른 에이전트들에게 broadcast할 수 있다.
3. Applications of AutoGen
■ AutoGen이 high-performance multi-agent applications 개발을 얼마나 단순화할 수 있는지 6가지 applications에서 확인한다. (Fig 3)
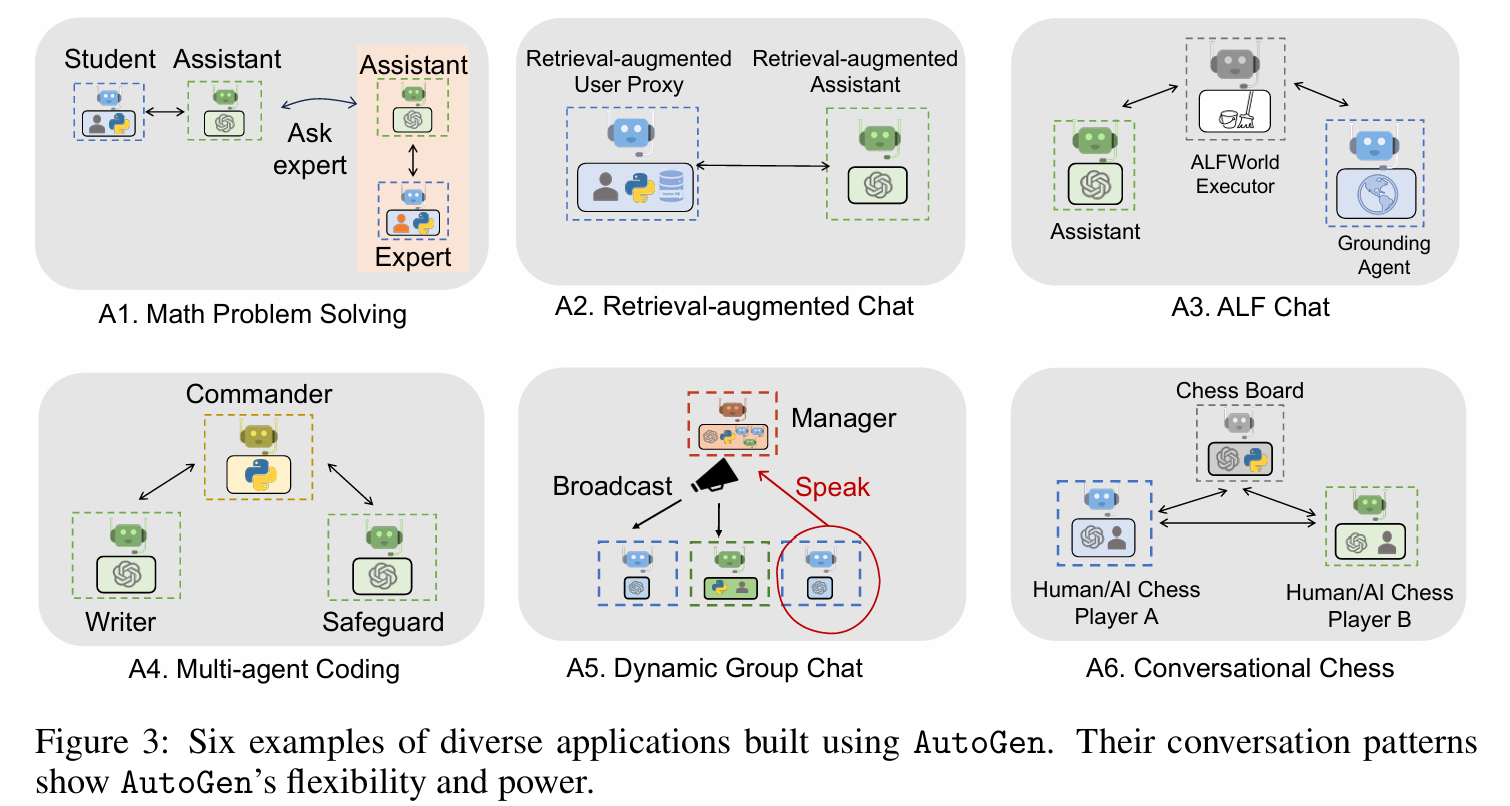
■ 이 applications은 real-world와의 관련성(A1, A2, A4, A5, A6), AutoGen에 의해 가능해진 문제 난이도 및 해결 능력(A1, A2, A3, A4), 그리고 innovative potential(A5, A6)을 기준으로 선택되었다.

A1: Math Problem Solving
■ 수학은 기초적인 학문 분야이다. 수학 문제 해결을 지원하기 위해 LLM을 활용할 수 있다는 가능성은 personalized AI tutoring, AI research assistance 등을 포함한 새로운 형태의 수많은 애플리케이션의 경로를 열어준다.
Scenario 1
■ 첫 번째 시나리오에서는 AutoGen의 built-in agent 두 개를 재사용하여 자율적인 수학 문제 풀이 시스템을 구축할 수 있을 보여준다.
■ 저자들은 MATH 데이터셋에서 평가하고, 비교 대상으로 Multi-Agent Debate, LangChain ReAct, vanilla GPT-4, 그리고 ChatGPT + Code Interpreter, ChatGPT + Plugin (Wolfram Alpha)을 사용한다.
■ 평가는 무작위로 선택한 120개의 level-5 문제와 MATH의 전체 test set에서 수행된다. Fig 4a에서 AutoGen의 built-in agents이 별도의 구성 없이도 상용 제품을 포함한 기존 대안들과 비교했을 때, 더 나은 성능을 산출함을 볼 수 있다.
Scenario 2
■ 두 번째 시나리오에서는 human-in-the-loop problem-solving을 다룬다.
■ 첫 번째 시나리오의 시스템에서 UserProxyAgent의 human_input_mode="ALWAYS"로 설정하기만 하면 AutoGen에 human feedback을 포함하는 수학 문제 풀이 시스템으로 바꿀 수 있다.
■ 이 설정을 통해 사람 없이는 해결할 수 없는 어려운 문제들을 해결할 수 있다.
Scenario 3
■ 세 번째 시나리오는 여기서 더 나아가, 문제 풀이 과정 중의 대화에 여러 human users이 참여할 수 있는 형태이다.
■ 세 가지 시나리오의 case studies와 평가에 대한 details은 Appendix D
A2: Retrieval-Augmented Code Generation and Question Answering
■ retrieval augmentation은 외부의 documents을 통합함으로써 LLM의 본질적인 한계를 완화하는 실용적이고 효과적인 접근법이다.
■ 저자들은 AutoGen을 사용하여 Retrieval-augmented Chat이라는 이름의 RAG 시스템을 구축했다.
■ 이 시스템은 두 개의 에이전트로 구성된다: Retrieval-augmented User Proxy 에이전트와 Retrieval-augmented Assistant 에이전트이며, 두 에이전트 모두 AutoGen의 built-in agent를 확장한 것이다.
■ 특히 Retrieval-augmented User Proxy에는 context retriever로서 SentenceTransformers가 탑재된 vector database Chroma가 포함되어 있다. (Appendix D)
■ Retrieval-augmented Chat을 question-answering 및 code-generation scenarios에서 평가한다.
Scenario 1
■ Natural Questions dataset을 기반으로 natural question answering에 대한 평가를 수행한다. 결과는 Fig 4b와 같다.
■ 이 평가에서는 기존 평가 관행을 따라, Retrieval-augmented Chat을 DPR(Dense Passage Retrieval)과 비교한다.
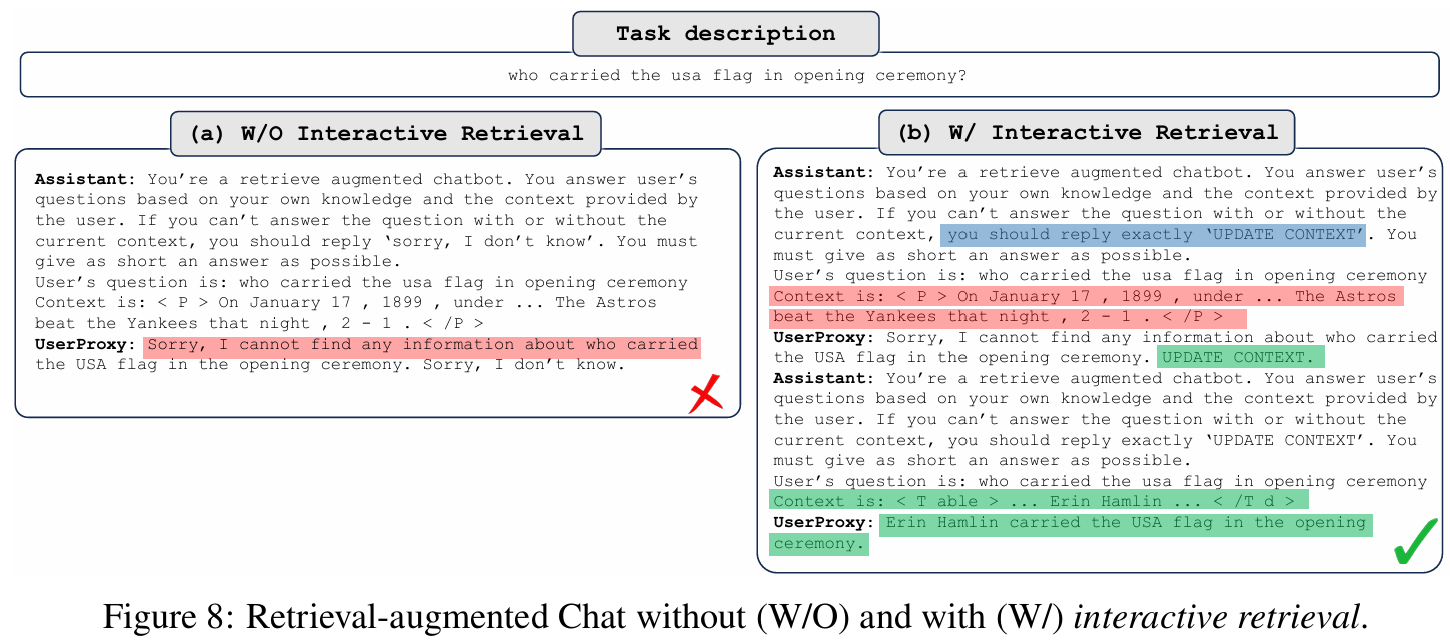
■ conversational design과 natural-language control을 활용하여 AutoGen은 이 애플리케이션에 interactive retrieval 기능을 도입했다.
■ 검색된 컨텍스트에 정보가 포함되어 있지 않으면 종료하는 대신, LLM-based assistant는 "Sorry, I cannot find any information about... UPDATE CONTEXT."라고 답하며, 추가적인 검색 시도를 호출하여 더 많은 정보를 찾아오게 된다.
■ 관련 정보를 찾을 수 없는 경우 assistant agent에게 "UPDATE CONTEXT." 대신 "I don't know"라고 말하도록 프롬프팅한 뒤 성능을 비교한 결과는 Fig 4b에서 볼 수 있다. interactive retrieval 메커니즘이 성능 향상에 기여함을 볼 수 있다.
Scenario 2
■ 더 나아가 Retrieval-augmented Chat이 GPT-4의 training data에 포함되지 않은 코드베이스를 바탕으로도 코드 생성(즉, 외부 지식이 필요한 code task)을 도울 수 있음을 보여준다. (Appendix D)
A3: Decision Making in Text World Environments
■ AutoGen이 interactive 또는 online decision making을 수반하는 applications을 개발하는 데 어떻게 사용될 수 있는지 확인한다.
■ TextWorld를 기반으로 한 가정 환경에서 language-based interactive decision-making tasks을 다양하게 모아놓은 ALFWorld 벤치마크를 사용하여 실험을 수행한다.
■ 저자들은 AutoGen을 이용해 ALFWorld 문제를 해결하는 two-agent system을 구축했다. 이 시스템은 (1) task를 수행하기 위해 계획을 제안하는 LLM-backed assistant agent와 (2) ALFWorld 환경에서 행동을 실행하는 executor agent로 구성된다.
■ 이 시스템은 ReAct prompting을 통합하고 있으며, 그 결과 기본적으로 ReAct와 유사한 수준의 성능을 낼 수 있다.
■ ReAct와 AutoGen-based two-agent system 모두에서 겪는 문제점은, 이들이 가끔 물리적 세계에 대한 기본적인 상식을 활용하지 못한다는 것이다. 이러한 한계는 반복적인 에러로 인해 시스템이 루프에 갇히게 만들 수 있다.
■ 이 지점에서 저자들은 AutoGen의 모듈식 설계가 강점이 된다고 주장한다: AutoGen에서는 기존 에이전트 시스템 구조에 새로운 에이전트를 쉽게 추가할 수 있다.
■ 그래서 저자들은 "물건을 조사하려면 먼저 그 물건을 찾아서 집어야 한다. 물건을 사용하려면 그 물건이 있는 곳으로 먼저 가야 한다"와 같은 상식을 제공하는 grounding agent를 도입했다. 이를 통해 시스템이 에러 루프에 빠지지 않는 능력을 크게 향상시킬 수 있다.
■ ALFWorld의 134개 unseen tasks에서 2-agent system과 grounding agent가 추가된 2-agent system을 GPT-3.5-turbo 및 ReAct와 비교했으며, Fig 4c에서 grounding agent를 도입했을 때 추가적인 성능 향상이 나타났음을 확인할 수 있다.
A4: Multi-Agent Coding
■ AutoGen을 사용하여 optimization solutions을 해석하고 사용자 질문에 답하기 위한 코드를 작성하는 데 탁월한 시스템인 OptiGuide를 기반으로 multi-agent coding system을 구축했다. (Fig 3)
■ 여기서 핵심은 Commander, Writer, Safeguard라는 세 agent의 협력이다. workflow는 다음과 같다.
- 사용자는 "공급업체 1에서 로스터리 2로의 배송을 금지하면 어떻게 되나요?"와 같은 질문을 Commander agent에게 보낸다.
- Commander는 이 질문에 답하기 위해 Writer 그리고 Safeguard와 조율한다.
- Writer의 역할은 코드를 작성하여 Commander에게 전송하는 것이고, Commander는 코드를 받은 후 Safeguard를 통해 코드의 안전성을 검사한다.
- Safeguard가 문제가 없다고 판단하면, Commander는 외부 도구들(예: 파이썬)을 사용하여 코드를 실행하고, Writer에게 실행 결과를 해석해 달라고 요청한다. 예를 들어, Writer는 "공급업체 1에서 로스터리 2로의 배송을 금지하면 총비용이 10.5% 증가할 것이다"라는 식의 해석을 제공할 수 있다.
- Commander는 그 결론을 사용자에게 전달한다.
- 특정 단계에서 예외가 발생할 경우(예: Safeguard에 의해 security red flag가 제기됨), Commander는 디버깅 정보와 함께 문제를 다시 Writer에게 보낸다.
- 이 과정은 사용자의 질문에 대한 답을 찾거나 time-out이 발생할 때까지 여러 번 반복될 수 있다.
■ AutoGen을 사용했을 때 OptiGuide의 core workflow code는 430줄 이상에서 100줄 수준으로 줄어들어 상당한 생산성 향상을 이끌어냈다.
■ ChatGPT+Code Interpreter를 비교했을 때, AutoGen-based OptiGuide는 사용자의 시간을 약 3배 절약하고 사용자 상호작용을 평균 3~5배 감소시켰다. (Appendix D)
■ 추가로, multi-agent abstraction가 필수인지 확인하기 위해 ablation 실험도 수행한다. 구체적으로, single agent가 code-writing과 safeguard processes를 모두 수행하는 single-agent를 구축했다.
■ 이 single-agent와 multi-agent 방식을, 동일한 수의 safe task와 unsafe task가 포함되도록 구성된 100개의 coding task dataset에서 평가한다.
■ unsafe code를 식별하는 성능에서 multi-agent 설계는 GPT-4 기준 F1을 8%, GPT-3.5-turbo 기준 35% 향상시킨다. (Fig 4d)
A5: Dynamic Group Chat
■ AutoGen은 동일한 context를 공유하고 dynamic한 방식으로 다른 에이전트들과 대화하는 dynamic group chat communication pattern을 지원한다.
■ dynamic group chat은 진행 중인 대화에 따라 에이전트 간 상호작용의 흐름을 유도한다. 이런 구조는 엄격한 communication order가 없이 협업하는 상황에 적합하다.
■ AutoGen에서 GroupChatManager 클래스는 에이전트 간 대화의 conductor 역할을 하며 다음 세 가지 단계를 반복한다: 발화할 speaker를 동적으로 선택, 선택한 speaker로부터 응답 수집, 메시지를 다른 에이전트들에게 broadcast (Fig 3-A5)
■ 저자들은 speaker 선택을 위해 role-play 스타일의 prompt를 사용한다. 그 이유는 role-play prompt를 사용했을 때, 문제 해결 과정과 speaker selection에서 conversation context와 role alignment 모두를 더 효과적으로 이끄는 경우가 많다는 것을 관찰했다고 한다. 결과적으로 이는 더 높은 success rate와 더 적은 LLM calls로 이어진다. (Appendix D)
A6: Conversational Chess
■ AutoGen을 사용하여 natural language interface game인 Conversational Chess를 개발했다.
■ 이 게임은 플레이어 역할을 하는 built-in agents, 정보를 제공하고 standard rules을 따라 수를 검증하는 third-party board agent가 포함된다.
■ 게임 도중 board agent는 플레이어가 제안한 각 move가 적절한지 검사한다. 만약 그 수가 규칙에 맞지 않으면, board agent는 오류를 반환하고, 플레이어 agent는 그 피드백을 바탕으로 올바른 수를 다시 제안해야 한다. 이 과정 덕분에 유효한 수만 플레이되며, 게임이 일관되게 진행된다.
■ 저자들은 이 grounding의 중요성을 확인하기 위해 ablation study를 수행했다: board agent를 제거하고, 대신 플레이어들에게 "you should make sure both you and the opponent are making legal moves"라는 프롬프트만 제공한다.
■ 그 결과, 규칙을 어기는 수가 발생하여 게임이 중단되는 문제가 나타났다고 한다.

