[2404.14219] Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-min
arxiv.org
1. Introduction
■ LLM의 성능 향상은 scaling laws에 의존해 왔다. 그러나 cutting edge LLMs이 등장하면서, scaling laws에 대한 통념이 바뀌고 있다. GPT-4와 같은 LLM을 이용하면 데이터를 정제하거나 아예 고품질의 synthetic data를 생성할 수 있다.
■ 그리고 이러한 LLM-generated high-quality data를 small model에 사용하면, large model과 비교했을 때 경쟁력 있는 성능을 달성할 수 있다.
■ phi models에 대한 이전 연구들에서, MS는 공개적으로 사용가능한 web data의 LLM-based filtering과 LLM-created synthetic data를 함께 사용하면, 훨씬 더 큰 모델에서만 볼 수 있었던 성능을 더 작은 언어 모델에서도 가능하다는 것을 보여주었다.
■ 예를 들어 2.7B phi-2는, 이 방식으로 25배나 더 큰 모델드과 대등한 성능을 보였다.
■ 이번에는 phi-2에 사용된 데이터셋의 더 크고 개선된 버전에서 3.3T tokens으로 학습된 3.8B의 phi-3-mini를 제시한다.
■ 작은 크기 덕분에 phi-3-mini는 최신 핸드폰에서 로컬로 쉽게 추론할 수 있으며(Fig 2), Mixtral 8x7B나 GPT-3.5와 같은 모델과 동등한 quality를 보여준다.
2. Technical Specifications
phi-3-mini
■ phi-3-mini model은 transformer decoder architecture를 기반으로 하며, context length의 default는 4K이다. 기본 4K 외에 MS의 LongRope를 통해 context length를 128K까지 확장한, long context version인 phi-3-mini-128K도 제공한다.
■ phi-3-mini는 3072 hidden dimension, 32 heads, 32 layers을 사용하며, Llama 2와 유사한 블록 구조로 구축되었으며, 32604 크기의 vocabulary를 가진 동일한 tokenizer를 사용한다. bfloat16을 사용하여 총 3.3T tokens에 대해 학습시켰다.
■ 그리고 이 모델은 이미 chat-finetuned되었으며, chat template은 다음과 같다.

phi-3-small
■ 7B phi-3-small model은 multilingual tokenization을 위해 tiktoken tokenizer를 사용하며, vocabulary size는 100352이고 default context length 8192이다.
■ 4096 hidden size, 32 heads, 32 layers을 가지는 standard decoder architecture를 따르며, 4개의 queries이 1개의 key를 공유하는 GQA를 사용한다. 그리고 GeGLU activation을 사용한다.
■ MS & OpenAI의 Maximal Update Parametrization (muP)를 사용한다. 이는 작은 proxy model에서 하이퍼파라미터를 조정한 뒤 이를 더 큰 target mdoel에 그대로 사용하는 방법이다.
- target 7B model로 transfer했으며, muP를 적용했을 때 더 나은 성능과 학습 안정성을 보장하는 데 도움이 되었다고 한다.
- muP는 간단히 설명하면, 아주 작은 모델에서 튜닝하여 얻은 하이퍼파라미터 값을 더 큰 모델(예: GPT-3)에 적용하는 방법. 이를 통해 기존 GPT-3보다 더 높은 성능을 기록했다고 한다.
■ 또한, training 및 inference speed를 최적화하기 위해 blocksparse attention을 설계하여 사용했는데, 이로 인해 KV cache 메모리를 획기적으로 줄이면서도 long context를 처리할 수 있다.
■ Fig 1에서 볼 수 있듯이, context는 attention heads 사이에서 효율적으로 divided and conquered되므로, KV cache가 크게 감소한다.

■ blocksparse 설계로부터 실제 deployment 속도 향상을 위해, training과 inference 모두를 위한 kernels을 구현하여 사용한다.
■ training을 위해 Flash Attention에 기반한 triton kernel을 구축했으며, inference을 위해 prefilling phase를 위한 kernel을 구현하고 decoding phase를 위해 vLLM의 paged attention kernel을 확장하여 적용했다.
■ 마지막으로, phi-3-small architecture에서는 long context retrieval 성능을 유지하면서 KV cache 절약을 최적화하기 위해 dense attention layers와 blocksparse attention layers를 번갈아 배치하였다. 이 모델에는 추가로 10%의 multilingual data가 사용되었다.
phi-3.5-MoE
■ phi-3.5-MoE는 model efficiency를 개선하기 위해 특정 inputs에 대해 modules의 일부만 선택적으로 activate하는 Mixture-of-Experts (MoE) architecture를 채택했다.
■ 이는 feedforward models로 MoE layer를 통합하며, 16개의 expert networks 중 상위 2개를 routing하는 방식을 사용한다.
■ 각 expert network는 별도의 GLU network이며, routing module은 각 토큰에 대해 16개의 expert networks 중 2개를 선택적으로 activate하여, 총 42B 파라미터 중 6.6B의 activated 파라미터를 가진 16x3.8B 모델이 되게 한다.
■ MoE model의 sparse router를 학습시키기 위해 SparseMixer approach를 활용한다.
■ 저자들은 다른 phi 시리즈 models과 비교를 위해, phi-3.5-MoE는 phi-3-medium 및 phi-3-mini와 동일한 32064 크기의 vocabulary를 가진 tokenizer를 사용하였다.
Highly capable language model running locally on a cell-phone
■ phi-3-mini에 4비트 양자화를 적용하여, 모델 크기가 약 1.8GB 메모리를 차지했다고 한다.
■ A16 Bionic 칩이 탑재된 iPhone 14에 이 phi-3-mini를 배포하여 완전한 오프라인 상태에서 자체적으로 실행하며 테스트했으며, 초당 12토큰 이상의 속도를 달성했다고 한다.
Training Methodology
■ phi-1 "Textbooks Are All You Need"에서 시작된 phi models에 대한 이전 연구들을 따른다.
■ phi models에 대한 연구들은 scaling-laws에서 벗어나기 위해, high-quality training data를 활용하여 SLM의 성능을 향상시켰다.
■ phi-3에서도 이러한 방법이 3.8B 모델로도 GPT-3.5나 Mixtral 45B와 같은 고성능 모델 수준에 도달할 수 있음을 보여준다.
■ 사용한 training data는 다양한 open internet sources에서 "educational level"에 따라 엄격하게 필터링된 public web data와 synthetic LLM-generated data로 구성된다.
■ pre-training은 두 개의 분리된 순차적인 단계들로 수행된다
- (1) 1단계는 주로 모델에게 general knowledge와 language understanding을 가르치는 것을 목표로 하는 web sources의 data를 사용하고,
- (2) 2단계는 더욱 엄격하게 필터링된 web data(1단계에서 사용한 subset)와 모델에게 logical reasoning 및 다양한 niche skills을 가르치는 synthetic data를 병합하여 사용한다.
Data Optimal Regime
■ Chinchilla의 "compute optimal"이나 Llama 2나 TinyLlama처럼 "over-train"에서 LM을 학습시키는 이전 연구들과 달리, 저자들은 주어진 scale에 대한 data의 quality에 중점을 두었다.
■ training data를 small model을 위한 "data optimal"에 가깝게 조정하려고 노력했다. 구체적으로, 공개적으로 사용 가능한 web data를 필터링하여 올바른 "knowledge"를 포함하고 "reasoning ability"를 잠재적으로 향상시킬 수 있는 web pages만을 남겨 사용한다.
■ 예를 들어, 특정 날짜의 프리미어 리그 경기 결과는 LLM에게 좋은 training data일 수 있지만, 미니 사이즈 모델의 경우 "reasoning"을 위한 model capacity를 더 남겨두기 위해 이런 정보를 제거하는 것이다.
■ 아래의 Fig 3은 이러한 저자들의 "data optimal" 전략과 Llama 2의 방식을 비교한 것이다.

■ Fig 3의 x축은 모델의 크기이다. 오른쪽으로 갈수록 파라미터 수가 많은 모델이다. y축은 MMLU 벤치마크의 error rate이므로, 점수가 낮을수록 성능이 더 좋다는 뜻이다.
■ 보라색 선은 Llama 2 모델들의 성능 추세선이고, 빨간색 선은 data optimal 전략을 쓴 phi 모델들의 성능 추세선이다.
■ 빨간색 선이 보라색 선보다 기울기가 더 가파른 것을 볼 수 있다. 즉, error rate가 훨씬 급격하게 아래로 떨어진다. 이는 학습 효율이 Llama 2보다 월등히 높음을 보여주는 결과이다.
■ 또한 3.8B 크기의 phi 모델의 점수가 약 10배 더 큰 Llama 2 모델과 비슷한 y축 높이에 위치하는 것을 볼 수 있다.
■ 더 큰 크기의 모델에서 데이터를 테스트하기 위해, phi-3-mini와 동일한 토크나이저 및 아키텍처를 사용하고 동일한 데이터로 약간 더 많은 epochs 동안 학습된(단, phi-3-small과 동일하게 총 4.8T tokens으로) 14B 모델인 phi-3-medium을 학습시켰다.
■ phi-3-medium은 40 heads, 40 layers를 가지며 embedding dimension은 5120이다.
■ 저자들은 이 14B 모델에서 한계를 발견했는데, 일부 벤치마크에서 3.8B에서 7B로 확장했을 때 성능이 향상된 것보다 7B에서 14B로 향상된 폭이 훨씬 작았다고 한다.
■ 14B 정도면 3.8B나 7B보다 더 큰 model capacity를 가지므로, 더 많은 knowledge를 담을 수 있을 것으로 기대되지만, 그럼에도 불구하고 성능 향상이 제한적이었다는 점은 필요 이상의 데이터 필터링 때문일 수도 있다고 생각된다.
Post-training
■ phi-3의 post-training은 supervised finetuning (SFT)과 direct preference optimization (DPO)을 포함한 두 단계로 이루어진다.
■ SFT에서는 math, coding, reasoning, conversation, model identity, safety 등 다양한 도메인에 걸쳐 엄선된 high-quality data를 사용한다. SFT 데이터 구성은 초기에는 English-only examples을 사용하는 것으로 시작한다.
■ DPO data는 chat format data, reasoning, responsible AI (RAI) efforts을 포함하고 있다. 모델이 원치 않는 행동을 하지 않도록 교정하기 위해 DPO를 사용하며, outputs 중 바람직하지 않은 것을 "rejected" responses로 사용한다.
3. Academic benchmarks
■ 모델의 reasoning ability(common sense reasoning 및 logical reasoning)를 측정하는 standard open-source benchmarks에서 phi-3를 평가한다.
■ phi-2, Mistral-7b-v0.1, Mixtral-8x7b, Gemma 7B, Llama-3-instruct-8b, 그리고 GPT-3.5와 비교한다.
■ 그리고 관행을 따라, temperature 0에서 few-shot prompts을 사용하여 모델을 평가한다.

■ 3.8B의 phi-3-mini가 자신보다 약 2배 큰 7~8B급 모델들(Mistral, Gemma, Llama-3)을 대부분의 지표에서 압도하거 대등한 성능을 보인다. 전체 벤치마크 평균 점수에서도 phi-3-mini가 Mistral 7B, Gemma 7B, Llama-3-In 8B를 모두 앞선 것을 볼 수 있다.
■ 특히, phi-3가 다른 모델들과 큰 격차를 벌리는 분야는, GSM-8K와 MATH 그리고 HumanEval과 MBPP 결과에서 볼 수 있듯이 수학과 코딩 영역이다. GSM-8K에서는 GPT-3.5보다 더 높은 점수를 받은 것을 볼 수 있다.
■ GPT-3.5와 비교해 볼 때, cell phone에서 로컬로 구동할 수 있는 small model이 서버급 모델에 근접했다는 것을 알 수 있다. GSM-8K와 MBPP에서는 오히려 더 뛰어나거나 대등하며, MMLU에서도 큰 차이가 나지 않는다.
■ phi-3-mini보다 사이즈를 키운 14B phi-3-medium의 경우, 전체 벤치마크 평균 점수에서 가장 뛰어난 성능을 달성했다.
4. Multilingual and Long Context
■ phi-3 models의 multilingual와 long-context capabilities을 향상시키기 위해, mid-training 중에 더 많은 multilingual 및 long-text data를 학습한 phi-3.5-mini 및 phi-3.5-MoE를 개발하였다.
■ 구체적으로, 4K-context tasks의 성능을 저하시키지 않으면서 context length limit를 4K에서 128K로 확장하기 위해 LongRope 방법과 mixed context window 방식을 채택하였다.
■ Fig 4는 MMLU multilingual tasks에서 phi-3-mini, phi-3.5-mini, 그리고 phi-3.5-MoE의 성능을 비교한 결과이다.

■ phi-3.5-mini는 아랍어, 중국어, 러시아어, 우크라이너어, 베트남어와 같은 언어에서 phi-3-mini에 비해 상당한 개선을 보이며, 평균 MMLU-multilingual scores의 경우 phi-3.5-MoE는 더 큰 model capacity 덕분에 69.9라는 점수를 달성하여 phi-3.5-mini를 능가한다.
■ 다음으로, RULER와 RepoQA라는 두 가지 long-context understanding tasks에 대해 phi-3.5-mini와 phi-3.5-MoE를 평가한다.
■ Table 1, 2에서 볼 수 있듯이, phi-3.5-MoE와 phi-3.5-mini 모두 RepoQA task에서 Llama-3.1-8B, Mixtral-8x7B, Mixtral-8x22B와 같은 더 큰 크기의 open-source models을 능가하며, RULER에서는 Llama-3.1-8B와 대등한 성능을 보인다.
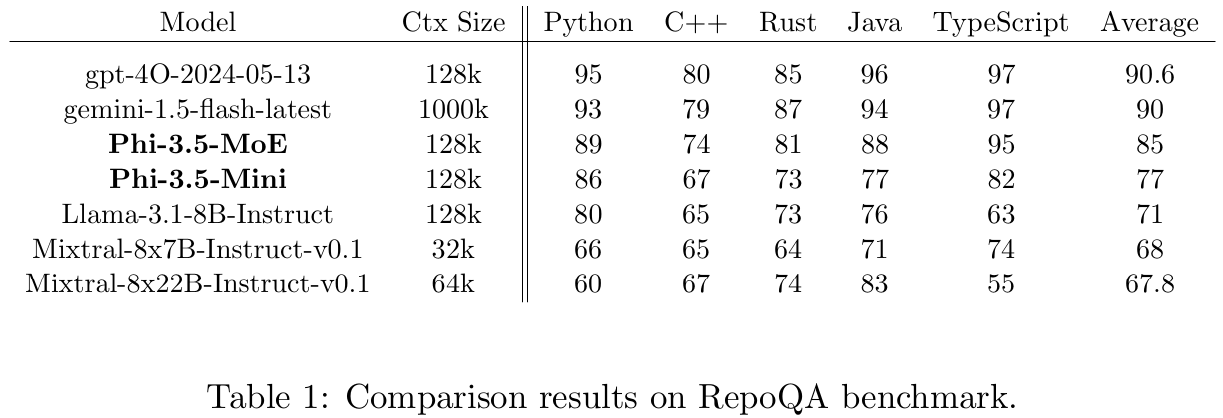

■ 그러나 RULER에서 128K context window를 테스트할 때 상당한 성능 저하를 볼 수 있다. 저자들은 이 성능 저하가 mid-training 과정에서 high-quality의 long-context data가 부족했기 때문이라고 추측한다.
■ Table 3은 phi-3.5-mini 및 phi-3.5-MoE를 GPT-4o-mini, Gemini-1.5 Flash와 같은 SOTA pretrained language models 및 Llama-3.1-8B, Mistral과 같은 open-source models과 비교한 결과이다.

■ phi-3.5-mini는 Mistral-Nemo-12B 및 Llama-3.1-8B와 같은 훨씬 더 큰 모델과 견줄 만한 성능을 보인다.
■ phi-3.5-MoE는 open-source models을 크게 능가하고 Gemini-1.5 Flash와 필적하는 성능을 보이며, 다양한 language benchmarks 전반에 걸쳐 GPT-4o-mini 평균 성능의 90% 이상을 따라잡았다.
5. Safety
■ phi-3-mini는 MS의 AI principles에 따라 개발되었다. 전반적인 접근법은 post-training에서의 safety alignment, red-teaming, 그리고 수십 개의 RAI harm categories에 대한 automated testing 및 evaluations이다.
■ safety post-training에서 RAI harm categories을 다루기 위해 이전 연구들에서 공개한 helpfulness 및 harmlessness preference datasets을 수정하여 사용했으며, 자체 생성한 datasets을 사용하였다.
■ phi-3 개발팀과 독립된 MS 내 레드 팀이 post-training 과정 동안 phi-3-mini를 반복적으로 공격하고 취약점을 찾아냈으며, 레드 팀의 피드백을 바탕으로 찾아낸 약점을 보완하기 위해 맞춤형 데이터를 추가하는 식으로 post-training dataset을 정제했다고 한다.
■ Fig 5에서 볼 수 있듯이, 이러한 과정을 통해 harmful response의 비율을 상당히 감소시켰다.
■ phi-3-small, phi-3-medium, phi-3.5-MoE의 safety alignment도 동일한 red-teaming 과정을 거치고, 동일한 datasets을 활용하며, 약간 더 많은 수의 샘플을 추가해 수행되었다.

■ Table 4는 MS가 만든 RAI benchmarks에서 phi-3 models의 결과를 phi-2, Mistral-7b-v0.1, Gemma 7b, Llama-3-instruct-8b와 비교한 결과이다.
■ GPT-4를 활용하여 5가지 다른 범주에서 가상의 multi-turn 대화를 시뮬레이션하고 model responses을 평가하였다. 0 (fully grounded)에서 4 (not grounded) 사이의 ungroundedness는 response의 정보가 주어진 prompt에 기반하는지를 측정한 점수이다.
- 0점은 주어진 context(즉, prompt)에 완벽하게 기반한 것, 4점은 prompt에 전혀 기반하지 않은, 근거가 전혀 없는 결과
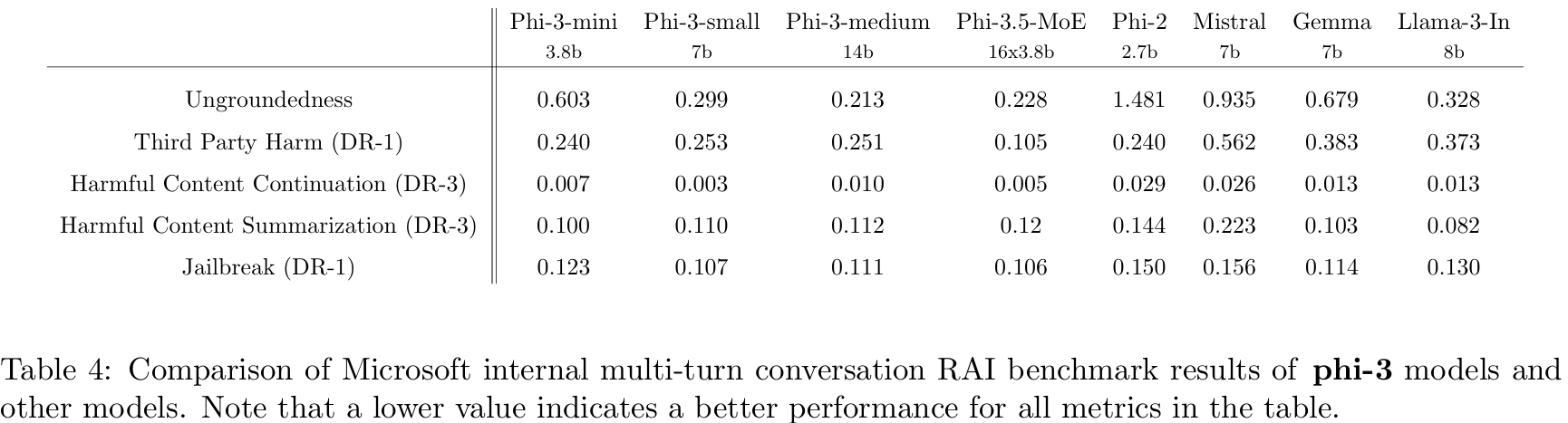
■ 다른 범주에서는 harmfulness severity를 측정하기 위해 responses이 0 (noharm)에서 7 (extremeharm)까지의 점수를 사용했으며, defect rates (DR-\( x \))은 severity score가 \( x \) 이상인 샘플의 비율로 계산되었다.
- 예를 들어, DR-3은 severity score가 3점 이상인 답변이 전체의 몇 %인가를 계산한 결과이다. 그러므로, severity 3점 이상의 유해한 답변이 나올 확률로 해석할 수 있다.
6. Weakness
■ LLM의 capabilities 측면에서, phi-3-mini는 훨씬 더 큰 모델들과 비슷한 수준의 language understanding 및 reasoning ability를 달성했지만, 특정 tasks에서는 여전히 그 크기로 인해 근본적인 한계를 가진다.
■ small model이므로 너무 많은 단순한 "factual knowledge"를 저장할 capacity가 부족하다. 이러한 이유로 TriviaQA에서 낮은 성능을 달성했다.
■ 그러나 저자들은 이러한 약점이 검색 엔진을 통한 증강으로 해결될 수 있다고 주장한다.
■ Fig 6은 phi-3-mini와 함께 HuggingFace의 Chat-UI를 사용한 예시이다. left는 검색 기능 없이 대화했을 때, right는 검색 기능을 키고 대화했을 때의 결과이다. 검색 기능을 활용했을 때 질문을 정확히 파악하고, 적절한 일정을 제안하는 것을 볼 수 있다.

■ 즉, small model은 capacity가 부족하지만 anguage understanding 및 reasoning ability가 충분하기 때문에, 검색 엔진을 통해 정보만 제공해주면, large model 못지않게 정확하고 구체적인 답변을 제공할 수 있음을 보여주는 결과이다.
■ model capacity와 관련된 phi-3-mini의 또 다른 약점은 model capacity의 한계로, 학습이 대부분 English 위주로 제한되어, language가 거의 English에만 최적화되어 있다는 점이다.
■ 저자들은 mini보다 더 큰 phi-3-small에 더 많은 multilingual data를 학습시킴으로써 이 문제를 완화했다.
■ RAI efforts에도 불구하고, 대부분의 LLM과 마찬가지로 phi-3 역시 factual inaccuracies(or hallucinations), biases의 재생산 또는 증폭, 부적절한 콘텐츠 생성 및 safety issues과 관련된 tasks에서 완전히 자유롭지는 않다.
■ 이러한 문제를 최소화하기 위해 training data를 신중하게 선별하고, 두 단계의 post-training, 그리고 red-teaming의 피드백을 활용하여 모든 차원에서 위험도가 상당히 완화되었지만, 완벽히 없어진 것은 아니다.
'자연어처리 > LM' 카테고리의 다른 글
| RecurrentGemma: Moving Past Transformers for Efficient Open Language Models (0) | 2025.12.29 |
|---|---|
| Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models (0) | 2025.12.29 |
| Gemma: Open Models Based on Gemini Research and Technology (0) | 2025.12.25 |
| TinyLlama: An Open-Source Small Language Model (0) | 2025.12.24 |
| Qwen 1: Qwen Technical Report (0) | 2025.12.20 |
