■ 언어 모델을 더 크게 만드는 것(scaling up)이 사용자의 의도를 더 잘 따르도록 만들지는 않는다.
■ 예를 들어, LLM은 사실이 아니거나, 유해하거나, 또는 단순히 사용자에게 도움이 되지 않는 결과물을 생성할 수 있다. 다시 말해, 이 모델들은 사용자와 정렬(aligned)되어 있지 않다.
■ 논문에서는, 인간의 피드백을 통한 파인튜닝으로 광범위한 tasks에 걸쳐 언어 모델을 사용자 의도에 정렬시키는 InstructGPT를 보여준다.
■ 1.3B InstructGPT의 output은 100배 더 적은 파라미터를 가졌음에도 불구하고, 175B GPT-3 output보다 더 선호되었다.
■ InstructGPT 모델은 public NLP datasts에서 최소한의 성능 저하만 보이면서도, truthfulness 향상과 유해한 출력의 생성이 감소하는 모습을 보여준다.
■ 비록 InstructGPT가 여전히 간단한 실수를 저지르기는 하지만, 인간 피드백을 통해 파인튜닝이 언어 모델을 인간의 의도에 정렬시키는 유망한 방향임을 보여준다.
[2203.02155] Training language models to follow instructions with human feedback
Training language models to follow instructions with human feedback
Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not ali
arxiv.org
1. Introduction
■ LLM은 input으로 task에 대한 몇 개의 examples이 주어지면, 광범위한 NLP tasks을 수행하도록 "prompted"될 수 있다.
■ 그러나 이러한 모델들은 사실을 지어내거나, 편항되거나 유해한 텍스트를 생성하거나 혹은 사용자 지시를 따르지 않는 등 의도치 않은 행동을 자주 보인다.
■ 이러한 의도치 않은 행동을 피하는 것은, 특히 상업용으로 배포되고 사용되는 언어 모델에 있어 중요하다.
■ 저자들은 언어 모델이 사용자 의도에 따라 행동하도록 학습시킴으로써 언어 모델을 aligning하는데 진전을 이루었다.
■ 언어 모델을 alignment하기 위한 파인튜닝 접근 방식에 초점을 맞추었는데, 구체적으로 GPT-3가 광범위한 종류의 instructions을 따르도록 파인튜닝하기 위해 인간 피드백 기반 강화 학습 (RLHF)을 사용하였다. (Fig 2)
■ 인간의 선호도(preference)를 reward signal로 사용하여 모델을 파인튜닝한 것이다.

■ 파인튜닝을 위한 데이터셋을 수집하기 위해 screening test에서의 결과를 바탕으로 40명의 레이블러를 고용해서 데이터를 레이블링하였다.
■ OpenAI API를 통해서 수집된 prompt와 일부 레이블러가 작성한 prompt에 대해, 원하는 response를 인간이 작성한 demonstration datasets을 수집하였다. 이를 사용하여 supervised learning으로 베이스라인을 학습시켰다.
- 이렇게 수집된 demonstration datasets은 (prompt, response) 쌍 형태이다.
- 이 (prompt, response) 쌍으로 GPT-3를 지도 학습 방식으로 1차 파인튜닝하여, 다양한 prompt에 대한 모범 답안(레이블러가 작성한 response)을 답변하는 능력을 갖춘 베이스라인 모델을 만들었다.
■ 다음으로, 더 큰 API prompt set에 대한 모델의 답변들에 대해서 레이블러가 어떤 답변이 더 나은지 선호도 순위를 매겨 human-labeled comparison dataset을 구축하였다.
■ 그런 다음, 우리는 이 comparison dataset으로 reward model (RM)을 학습시켜 레이블러(사람)가 어떤 모델 output을 선호할지 예측하도록 하였다.
■ 마지막으로, 이 RM을 reward function으로 사용하고, PPO를 사용하여 이 reward을 최대화하는 방향으로 지도 학습 베이스라인을 파인튜닝하였다.
■ 이러한 절차를 통해 GPT-3의 행동을 "human values"라는 더 넓은 개념보다는 특정 집단(주로 우리 레이블러와 연구자들)의 선호도에 정렬시켰다. 그리고 이 결과 모델을 InstructGPT라고 명명하였다.
■ 저자들은 training data에 포함되지 않은 prompts로 구성된 test set에서, 레이블러들이 모델 output의 품질을 평가하게 함으로써 모델을 평가하였다. 또한, public NLP datasets에 대한 평가도 수행하였다.
■ 세 가지 모델 크기(1.3B, 6B, 175B)를 학습시켰으며, 모든 모델은 GPT-3 아키텍처를 사용한다.
■ InstructGPT를 통한 주요 발견들은 섹션 4 Results에서 확인할 수 있다.
2. Related work
Research on alignment and learning from human feedback.
■ 모델을 인간의 의도에 정렬시키기 위한 InstructGPT의 기반은 RLHF이다. 이는 원래 시뮬레이션 환경의 로봇이나 Atari game을 학습시키기 위해 개발되었지만, 최근에는 텍스트 요약을 위해 언어 모델을 파인튜닝하는 데 적용되었다.
■ 이 연구는 대화, 번역, 의미 분석, 이야기 생성, 리뷰 생성과 같은 영역에서 인간의 피드백을 보상으로 사용하는 유사한 연구의 영향을 받은 것이다.
■ InstructGPT는 광범위한 language tasks의 분포에 대해 언어 모델을 정렬하는 데 RLHF를 직접적으로 적용한 것으로 볼 수 있다.
■ 언어 모델이 정렬된다는 것이 무엇을 의미하는지에 대한 연구들이 있다.
- 유해한 콘텐츠를 생성하거나 허점을 이용하는 것을 포함하여, 정렬 실패로 인해 발생하는 LM의 행동 문제들을 정리한 연구와
- 정렬을 시험하기 위해 'language assistants'라는 개념을 제안하고, 몇 가지 베이스라인을 제시한 연구가 있다.
Training language models to follow instructions.
■ InstructGPT는 언어 모델의 cross-task generalization에 대한 연구와도 관련이 있다.
■ 이 연구들에서는 광범위한 public NLP datasets에 적절한 instruction을 붙여 LM을 파인튜닝한 다음, 다른 NLP task set에서 성능을 평가한다.
■ 여러 연구에 걸친 일관된 발견은, instruction과 함께 다양한 NLP tasks에 대해 LM을 파인튜닝하는 것이, unseen tasks에 대한 zero-shot 및 few-shot setting 모두에서 다운스트림 성능을 향상시킨다는 것이다.
Evaluating the harms of language models.
■ 언어 모델의 행동을 조정하는 이유 중 하나는, 이 모델들이 real world에 배포되었을 때의 유해성을 완화하기 위해서이다.
■ 언어 모델이 학습한 datasets에는 이러한 위험들이 광범위하게 내재되어 있기 때문에, 편향된 출력을 생성하거나, 개인 정보를 유출하거나, 잘못된 정보를 생성하거나, 악의적으로 사용될 수 있다.
■ 이러한 위험들을 정량적으로 측정하기 위한 벤치마크 데이터셋들이 개발되고 있다. 그러나 LM 행동에 대한 이러한 선의의 개입이 오히려 오히려 부작용을 초래할 수 있다.
■ 예를 들어, 모델이 특정 소수 집단이 사용하는 비속어를 유해하다고 학습하여 필터링하면, 결과적으로 그 소수 집단의 언어 자체를 모델링하는 능력이 저하될 수 있다.
Modifying the behavior of language models to mitigate harms.
■ 언어 모델의 생성 방향을 바꾸는 방법은 여러 가지가 있다.
■ 우선, 크기는 작지만 가치 지향적인 datasets으로 LM을 파인튜닝하여 question-answering task에서 모델의 가치 준수 능력을 향상시킨 사례가 있다.
■ 또한, 언어 모델이 사람이 작성한 trigger phrase를 생성할 조건부 확률이 높은 문서를 제거해 pretraining 데이터셋을 필터링하고, 이렇게 정제된 데이터로 학습시켜 약간의 언어 모델링 성능 저하를 감수하는 대신 덜 유해한 텍스트를 생성하도록 한 접근도 제안되었다.
■ 한편, 챗봇의 safety를 향상시키기 위해 데이터 필터링, 생성 중 특정 단어나 n-gram 차단, 안전성 특화 제어 토큰, 인간 참여 데이터 수집 등 다양한 접근 방식을 사용한 시도가 있었다.
■ 이 밖에도, LM이 생성하는 편향을 완화하기 위해 단어 임베딩 정규화, 데이터 증강, 민감한 토큰의 분포를 더 균일하게 만드는 영공간 투영(null space projection), 대체 목적 함수, 인과 매개 분석 등을 활용하는 방법들이 제안되었다.
■ 나아가 두 번째 (보통 더 작은) 언어 모델을 사용하여 주 언어 모델의 생성을 조정하는 접근도 연구되었다.
■ 이러한 아이디어의 변형들이 언어 모델의 유해성을 줄이는 데 적용되어 왔다.
3. Methods and experimental details
3.1 High-level methodology
■ 학습을 위해 pre-trained LM과 모델이 aligned outputs을 생성하기 위한 다양한 prompts, 그리고 레이블러(사람)를 준비한 뒤, 다음의 3 steps를 진행한다. (Fig 2)
Step 1: Collect demonstration data, and train a supervised policy.
■ 먼저 레이블러들이 input prompts에 대해, 자신들이 원하는 행동의 demonstrations을 작성하여 dataset을 구축한다.
■ 그런 다음, 이 데이터에 대해 지도 학습을 사용하여 pretrained GPT-3 모델을 파인튜닝한다. (SFT)
Step 2: Collect comparison data, andtrain a reward model.
■ step 1에서 만든 모델에게 여러 다른 답변을 생성하게 하여 comparison dataset을 수집하며, 여기에 레이블러가 주어진 input에 대해 어떤 답변을 선호하는지 표시하게 한다.
■ 그런 다음, 인간이 선호하는 outputs을 예측하도록 reward model을 학습시킨다. (RM)
- 입력으로 들어온 prompt, response를 보고 reward 값(scalar)을 예측하는 RM을 학습시키는 것이다.
Step 3: Optimize a policy against the reward model using PPO.
■ reward model의 출력은 scalar reward이다. 여기에 PPO를 사용하여 reward를 최적화하도록 supervised policy를 파인튜닝한다. (RL with PPO)
- 이 강화 학습 과정을 거치면서, 모델은 점차 인간이 선호하는 방식으로 답변을 생성하는 법을 터득하게 된다.
- 이 최종 산출물이 바로 InstructGPT이다.
■ step 2와 step 3는 지속적으로 반복될 수 있다: best policy를 통해 더 나은 답변들이 생성되고, 이는 다시 RM을 학습시키는 데 사용되어 더 개선된 새로운 policy를 학습한다. 이러한 반복적인 개선 과정을 통해 모델을 지속적으로 발전시킬 수 있다.
- PPO(proximal perference optimization)는 reward model을 통해 LLM을 학습할 때 발생하는 reward hacking 현상을 피하기 위한 강화 학습 방법으로,
- supervised fine-tuning(SFT) model(또는 reference model이라고도 불림)을 기준으로, 학습하는 모델이 너무 멀지 않은 가까운 범위에서 reward model의 높은 점수를 찾을 수 있도록 도와준다.
3.2 Dataset
■ 저자들이 사용한 prompt dataset은 주로 OpenAI API를 통해서 수집된 text prompt들로 구성된다.
■ 이 prompt들은 playground 인터페이스를 통해, 초기 버전의 InstructGPT 모델(수집한 demonstration data의 일부로 지도 학습을 통해 학습된 모델)에 실제 사용자들이 입력한 것들이다.
■ 사용자 ID당 prompt 수를 200개로 제한했으며, long common prefix를 가진 중복되는 prompt들을 제거하였다.
■ 그리고 사용자 ID를 기반으로, train, valid, test splits을 생성하여 valid 및 test set에는 train set에 있는 데이터가 포함되지 않도록 하였다.
■ 모델이 잠재적으로 민감한 정보(고객 세부 정보)를 학습하는 것을 피하기 위해, training split의 모든 prompts에서 개인 식별 정보(PII)를 필터링하였다.
■ 최초의 InstructGPT 모델을 학습시키기 위해, 레이블러들에게 다음과 같은 세 가지 종류의 prompt를 직접 작성하도록 요청하였다.
- (1) Plain: 레이블러들이 임의의 task에 대해 자유롭게 만든 다양한 종류의 prompt
- (2) Few-shot: 하나의 instruction과, 그 instruction에 대한 여러 개의 query/response pairs
- (3) User-based: 레이블러들에게 실제 OpenAI API 사용 신청서에 적힌 use-case들을 반영한 prompt를 작성하도록 요청
■ 이렇게 수집한 API prompts 및 레이블러가 작성한 prompts을 통해 fine-tuning procedure에 사용되는 세 가지 datasets을 생성하였다.
- (1) SFT 모델을 학습시키기 위해 사용하기 위해, 레이블러가 작성한 demonstrations이 포함된 SFT dataset
- (2) RM을 학습시키는 데 사용되는 모델 출력의 순위(레이블러가 매긴 순위)가 포함된 RM dataset
- (3) human labels 없이 RLHF fine-tuning의 입력으로 사용되는 PPO dataset
■ 데이터셋에 대한 details는 Table 6에서 확인할 수 있다.

- SFT dataset은 약 13k 개의 training prompts(API 및 레이블러가 작성한 prompts),
- RM dataset은 33k 개의 training prompts(API 및 레이블러가 작성한 prompts),
- PPO dataset은 31k 개의 training prompts(오직 API로부터)를 포함한다.
■ 아래의 Table 1은 레이블러들이 레이블링한 API prompt 중 RM dataset에서의 use-case 카테고리 분포를 나타낸 것이다. 대부분의 use-case는 생성에 대한 것임을 확인할 수 있다.
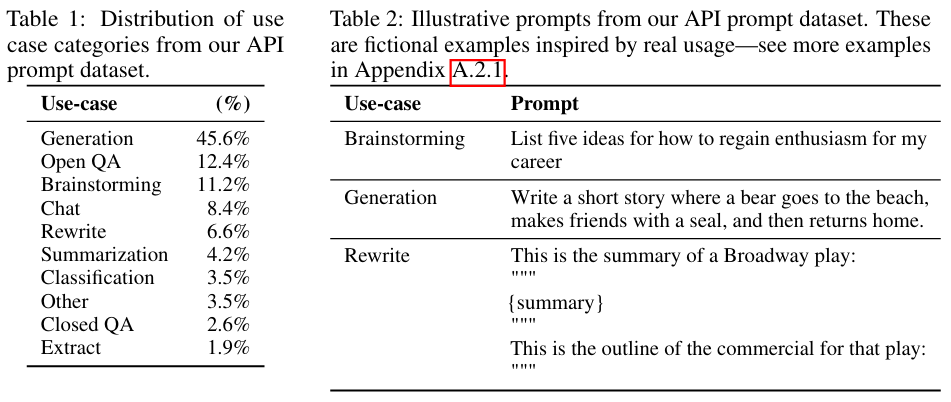
3.3 Tasks
■ training tasks의 source는 (1) 레이블러가 작성한 prompt dataset (2) 초기 InstructGPT로 수집한 prompt dataset
(Table 6)
■ 이 prompt들은 매우 다양하며, generation, question answering, dialog, summarization, extractions 등 다양한 natural language tasks을 포함하고 있다. (Table 1)
■ 각 자연어 prompt에 대해, task는 대부분 "현명한 개구리에 대한 이야기를 써줘"와 같은 자연어 instruction을 통해 직접적으로 명시되지만,
■ few-shot examples(예: 개구리 이야기 두 개를 주고 새로운 이야기를 생성하도록 프롬프팅)나 implicit continuation(예: 개구리에 대한 이야기의 시작 부분을 제공해서, 자연스럽게 뒷부분을 이어 쓰게 함)을 통해 간접적으로 명시될 수도 있다.
■ 저자들은 레이블러들에게 각 경우에 대해 prompt 작성자의 의도를 최대한 추론하고, task가 불분명한 input은 제외하도록 요청하였다. 또한, 암묵적인 의도까지 고려할 수 있도록 구체적인 지침을 제공하였다.
3.4 Human data collection
■ demonstration 및 comparison data를 생성하고, 주요 평가를 수행하기 위해 screening test를 통해 40명의 레이블러를 고용하였다.
■ training과 evaluation 과정에서 저자들이 세운 alignment 기준들 사이에 딜레마가 발생할 수 있는 상황이 있다.
■ 예를 들어, 사용자가 잠재적으로 유해한 응답(예: 폭탄 제조법)을 요청하는 경우이다. helpfulness를 우선하면 정보를 제공해야 하지만, Harmlessness를 고려하면 응답을 거절해야 한다.
■ 이 문제에 대해, 저자들은 training에서는 사용자에 대한 helpfulness를 최우선으로 삼았다. 즉, 일단 사용자의 지시를 최대한 따르도록 한 것이다.
- 논문에 따르면, 유해한 요청을 거절하는 방법을 가르치는 것은 매우 어려운 설계 과정을 필요로 하기 때문에, training 과정에서는 helpfulness 우선시했다고 한다.
■ 그러나 final evaluations에서는 저자들이 중요하다고 생각한 truthfulness와 harmlessness를 우선시하도록, 평가하는 레이블러들에게 요청하였다.
■ 모델이 레이블러들의 선호도에 얼마나 잘 일반화되는지 확인하기 위해, training data 구축에 참여하지 않은 레이블러들을 고용하였다.
3.5 Models
Supervised fine-tuning (SFT).
■ 지도 학습을 사용하여 demonstration data에 pretrained GPT-3를 파인튜닝하였다.
■ 16 에폭 동안 학습했으며, cosine learning rate decay와 residual dropout으로 0.2를 사용하였다.
■ valid set에서의 RM score를 기반으로 최종 SFT 모델을 선택하였다.
■ 이전 연구와 유사하게, SFT 모델이 1 에폭 후에 valid loss에 과적합되는 현상을 발견하였다.
■ 그러나 이러한 과적합에도 불구하고, 더 많은 에폭 동안 학습하는 것이 RM score와 인간 선호도 평가 모두에 도움이 된다는 것을 발견하였다.
Reward modeling (RM).
■ 마지막 unembedding layer가 제거된 SFT 모델에서 prompt와 response를 입력으로 받아 scalar reward를 출력하는 모델을 학습시켰다.
■ 175B 크기의 RM(앞 단계에서 얻은 SFT 모델) 학습은 불안정하여 value function으로 사용하기 적합하지 않았다. 저자들이 사용한 것은 6B RM이다.
- 강화 학습 자체가 하이퍼파라미터에 민감하고 학습에 불안정하다.
■ 각 prompt에 대해 \( K = 4 \sim 9 \)개의 response가 생성되면, 생성된 결과물들에 대해 레이블러가 선호도 순위를 매긴다.
■ 그런 다음, 레이블러가 선호하는 답변을 예측하는 RM을 학습시킨다. RM은 입력으로 prompt, response를 받아 scalar reward를 출력한다.
■ 이를 위해, 매겨진 순위를 바탕으로 각 prompt에 대해 \( \binom{K}{2} \)개의 비교 쌍을 생성하여, 비교군을 모두 활용해 학습시켰다.
■ 예를 들어, 하나의 prompt를 입력으로 받은 RM이 A, B, C, D라는 4개(\( K=4 \))의 response를 생성했다고 하자.
■ 레이블러는 이 4개의 response에 대한 선호도 순위를 매긴다. 레이블러가 매긴 순위가 'B > C > D > A'라고 하자.
■ 이 순위를 바탕으로 \( \binom{4}{2} \)개의 비교 조합('B > C', 'B > D', 'B > A', 'C > D', 'C > A', 'D > A')을 만들어서 모델 업데이트에 사용한다. 이렇게 \( \binom{K}{2} \)개의 비교 쌍을 한 번에 얻을 수 있어, 데이터 수집 효율이 크게 향상된다.
■ 모든 prompt에 대해 이렇게 \( \binom{4}{2} \)개의 비교 조합을 생성하면, ('B > C', 'B > D', 'B > A', 'C > D', 'C > A', 'D > A')와 같은 다수의 비슷한 비교 조합들이 만들어져서 비교 쌍 간에 높은 상관관계가 형성되기 때문에, 단순히 비교 쌍을 하나의 dataset으로 섞어 사용하면(즉, 비교 쌍들을 독립적인 데이터처럼 취급하여 모델을 훈련시키면), 과적합이 빠르게 발생하는 문제가 생긴다.
■ 그래서 저자들은 각 prompt로 나온 모든 \( \binom{K}{2} \)개의 비교 쌍들을 하나의 batch로 사용하여 모델을 학습시켰다. 모델이 각 prompt 내에서의 순위만 학습하기 때문에 과적합을 방지할 수 있다. 또한, 비교 쌍들을 하나의 batch로 처리하기 때문에 훨씬 더 계산 효율적이다.
■ reward model의 loss function은 다음과 같다. 이 loss function은 선호되는 response의 점수가 선호되지 않는 response의 scalar reward보다 항상 높도록, reward model의 파라미터 \( \theta \)를 학습시키는 것을 목표로 한다.

- \( \dfrac{1}{\binom{K}{2}} \)는 \( K \)개의 response에서 생성 가능한 모든 비교 쌍들의 평균을 구하기 위한 정규화 상수이다.
- \( (x, y_w, y_l) \sim D \)는 \( x, y_w, y_l \)이 데이터 분포 \( D \)에서 샘플링되는 것을 의미한다. 이는 input \( x \)를 받아 output으로 \( y_w, y_l \)가 출력되는 상황을 의미한다.
- 여기서 \( D \)는 human comparison dataset, \( x \)는 prompt, \( y_w \)와 \( y_w \)는 각각 winner response, loser response, 즉 선호되는 응답과 선호되지 않는(선호도가 더 낮은) 응답을 의미한다.
- \( r_{\theta} (x, y) \)는 \( \theta \)를 파라미터로 하는 reward model이 prompt \( x \)와 response \( y \)에 대해 출력하는 scalar reward 값이다.
- \( r_{\theta} (x, y_w) - r_{\theta} (x, y_l) \)은 선호도가 더 높은 response와 선호도가 더 낮은 response의 reward 값(scalar) 차이이다. 식(1)은 두 reward 값의 차이가 클수록 loss가 감소하는 구조이다.
- \( \sigma \)는 시그모이드 함수로, reward 값의 차이를 0과 1사이의 확률 값으로 변환한다. \( r_{\theta} (x, y_w) > r_{\theta} (x, y_l) \)일수록, 즉 reward 값의 차이가 더 큰 양수일수록 \( \sigma \)의 출력은 1에 가까워진다.
- 그러므로, \( \sigma \left( r_\theta (x, y_w) - r_\theta (x, y_l) \right) \) 값은 \( y_w \)가 \( y_l \)보다 선호될 확률을 의미한다고 해석할 수 있다.
- \( \sigma ( \cdots ) \) 앞에 \( - \log \)가 붙어 있기 때문에, \( \sigma \left( r_\theta (x, y_w) - r_\theta (x, y_l) \right) \) 값이 1에 가까울수록, 즉 \( r_{\theta} (x, y_w) \)와 \( r_{\theta} (x, y_l) \)의 차이가 클수록 loss가 감소한다.
- 기댓값이 있으므로, 식 (1)의 loss function은 \( D \)에 있는 모든 비교 쌍에 대해 \( -\log( \sigma( \cdots ) ) \) 값을 계산하여 그 평균을 구하는 것을 목표로 한다.
- 그리고 이 loss가 최소화되도록 RM의 파라미터 \( \theta \)를 학습시킨다. 결과적으로, RM은 레이블러(사람)가 더 선호한 response \( y_w \)에는 더 높은 reward 값을, 덜 선호되는 답변 \( y_l \)에는 더 낮은 reward 값을 부여하도록 학습된다.
■ 마지막으로, RM을 다음 단계인 강화 학습(RL)에 사용하기 전에 레이블러가 작성한 demonstrations이 평균 0의 점수를 달성하도록 bias를 사용하여 reward model을 정규화하였다.
- RM이 학습하는 것은 두 response의 상대적인 차이이다.
- 예를 들어 \( r(x, y_w) = 10, r(x, y_l) = 8 \)이라면, 점수 차이는 2이다. 그리고 \( r(x, y_w) = -1, r(x, y_l) = -3 \)이나 \( r(x, y_w) = 100, r(x, y_l) = 98 \)로 예측한 경우에도 점수 차이는 2이다.
- 식 (1)의 loss function의 관점에서 보면, 세 가지 상황의 loss 값은 모두 동일하다. 식 (1)은 오직 점수 차이에만 관심이 있기 때문이다.
- 이렇게 일정하지 않은 점수를 RL에 그대로 사용하면 학습이 불안정해질 수 있다. 그러므로 일관성이 있는 RM을 만들어야 한다.
- RM이 생성하는 모든 점수에 일정한 값(여기서는 bias)을 더하거나 빼는 것으로 변경되지는 않는다.
- 이러한 정규화 과정을 통해 학습의 변동성을 줄여 학습 안정성을 높일 수 있다. 모든 보상 점수들이 평균 0 점이라는 기준을 중심으로 분포하게 되어, 강화 학습이 훨씬 더 안정적으로 진행된다.
Reinforcement learning (RL).
■ 저자들은 학습된 RM을 value function으로 사용하여 PPO를 통해 policy 최적화하고자 하였다.
■ RL을 위해 PPO 모델과 PPO-ptx 모델을 정의하고, PPO-ptx 모델을 위한 objective function에 대해 설명한다.
■ 논문에서는 다음과 같은 objective를 사용하는 모델을 PPO 모델이라고 정의하였다. reward model의 over-optimization을 완화하기 위해 각 토큰에서 SFT 모델로부터의 토큰당 KL penalty term을 추가하였다.

- \( r_{\theta} (x, y) \)는 전 단계에서 학습된 reward model이다. 파라미터가 \( \theta \)이므로, 위의 objective function에서는 학습되지 않는다.
- \( \beta \log \left( \pi_\phi^{\text{RL}}(y \mid x) / \pi^{\text{SFT}}(y \mid x) \right) \)는 업데이트되는 policy(\( \pi_{\phi}^{\text{RL}} \))가 SFT(\( \pi^{\text{SFT}} \))와 너무 멀어지지 않게 파라미터 변동폭에 제한을 두는 penalty term이다.
- \( \pi_{\phi}^{\text{RL}} \)는 학습된(또는 업데이트되는) RL policy 모델, \( \pi^{\text{SFT}} \)는 SFT 모델, \( \beta \)는 KL reward coefficient로 penalty 강도를 조절하는 하이퍼파라미터이다.
- 만약에 이 penalty term이 없다면, 허점을 파고들어 단순히 reward를 높게 받는 데에만 집중하는 reward hacking과 같은 현상이 발생할 수 있다.
- KL penalty term을 통해 SFT 모델(reference model)을 기준으로, SFT 모델과의 거리가 지나치게 멀어지지 않도록 제한하면서도, reward가 높은(RM 점수를 높이는) 방향으로 안정적으로 학습할 수 있다.
■ 아래와 같은 objective function을 사용하는 모델을 PPO-ptx 모델이라고 정의하였다. 새로운 term이 추가된 것을 볼 수 있는데, 이는 public NLP tasks에서의 성능 저하를 해결하기 위해 추가한 term이다. InstructGPT는 PPO-ptx 모델을 지칭한다.

- \( D_{\text{pretrain}} \)은 pretraining distribution
- \( \gamma \)는 pretraining loss coefficient로 pretraining gradients의 강도를 제어하기 위해 사용된다.
- \( \gamma = 0 \)이면, PPO 모델이 된다.
■ 성능 저하의 원인은 pretraining data와 NLP task의 data의 distribution이 많이 다르기 때문에 발생한 것으로 보인다.
■ 그래서 저자들은 식 (2)의 마지막 항을 추가함으로써, PPO gradients에 pretraining gradients를 혼합하는 시도를 하였다.
■ 서로 다른 data distribution의 갭을 메우기 위해, RL 학습(PPO 업데이트)을 진행하면서 pretraining에 사용한 데이터를 조금씩 섞어 pretraining gradients을 PPO 업데이트 시에 반영을 하기 위한 것으로 보인다.
Baselines.
■ 저자들은 위와 같은 단계를 거쳐 얻은 PPO 모델들의 성능을 SFT 모델 및 GPT-3와 비교하였다.
■ 또한, GPT-3가 'instruction-following' 모드로 프롬프트되도록 few-shot prefix를 사용했을 때의 GPT-3(GPT-3-prompted)와도 비교하였다. prefix는 사용자가 지정한 instruction 앞에 덧붙여진다.
■ 추가적으로, InstructGPT를 FLAN 및 T0 데이터셋에서 175B GPT-3를 fine-tuning한 것과 비교하였다.
- 두 데이터셋은 모두 각 task에 대한 자연어 instructions과 결합된 다양한 NLP task들로 구성되어 있다.
■ 각각 약 1M 개의 examples로 파인튜닝하고, valid set에서 가장 높은 보상 점수를 얻는 체크포인트를 선택하였다.
3.6 Evaluation
■ 모델이 얼마나 "aligned"되었는지를 평가하기 위해, alignment를 모델이 유용하고(helpful), 정직하며(honest), 무해하면(harmless) 정렬된 것으로 정의하였다.
■ helpful하기 위해서는, 모델은 instructions 따라야 할 뿐만 아니라, few-shot prompt나 "Q: {question} \nA: "와 같은 해석 가능한 패턴으로부터 사용자의 의도를 추론할 수 있어야 한다.
■ 그러나 주어진 prompt의 의도가 불분명하거나 모호할 수 있기 때문에, 모델의 평가를 레이블러들의 판단에 의존하였다.
■ 하지만, 레이블러들이 prompt를 생성한 사용자가 아니기 때문에, 사용자가 실제로 의도한 것과 레이블러가 prompt만 읽고 의도했다고 생각한 것 사이에는 차이가 있을 수 있다.
■ 생성 모델에서 honesty를 측정하는 방법은 불분명하다. 모델의 출력을 올바른 출력에 대한 모델의 "믿음"과 비교해야 하는데, 모델은 블랙박스이기 때문에, 사람이 그 믿음을 추론할 수 없다. 그래서 저자들은 honesty 대신 truthfulness를 측정하였다.
■ 모델이 세상에 대한 진술이 사실인지 여부를 두 가지 지표를 사용하여 측정하였다.
- (1) closed domain tasks(한정된 주제 또는 정보 내에서만 답해야 하는 과제)에서 모델의 hallucinations을 평가
- (2) TruthfulQA dataset을 사용
■ honesty처럼, 언어 모델의 유해성(harms)을 측정하는 것 또한 쉽지 않다.
■ 대부분의 경우, 언어 모델로 인한 유해성은 그 출력이 real world에서 어떻게 사용되는지에 달려 있기 때문이다.
■ 예를 들어, 유해한 출력을 생성하는 모델로 챗봇을 사용하면 해로울 수 있지만, 더 정확한 유해성 탐지 모델을 훈련시키기 위한 데이터 증강에 사용된다면 유용하게 사용될 수 있다.
■ 저자들은 레이블러에게 모델의 output이 잠재적으로 유해한지를 평가하게 하였다. 그러나 논문에 따르면, output이 궁극적으로 어떻게 사용될지에 대한 너무 많은 추축을 요구했기 때문에 이를 중단했다고 한다.
■ 그래서 harmlessness 대신, 구체적으로 관찰 가능한 모델의 행동들을 측정하였다.
- 모델이 고객을 지원하는 도우미의 입장에서 부적절한 행동을 하는지, 보호가 필요한 계층을 비하하는지, 또는 성적이거나 폭력적인 콘텐츠를 포함하는지를 평가하였다.
■ 또한, RealToxicityPrompts나 CrowS-Pairs와 같이 편향과 toxicity을 측정하기 위한 데이터셋에서 InstructGPT를 벤치마크하였다.
■ InstructGPT의 성능을 정량적으로 평가하기 위한 방법은 다음과 같은 두 개의 측면으로 나눌 수 있다.
Evaluations on API distribution.
■ 주요 지표는 훈련 분포와 동일한 source에서 가져온 prompt set에 대한 인간 선호도 평가이다.
■ 평가를 위해 API의 prompt를 사용할 때, training에 포함시키지 않은 prompt들만 사용한다.
■ 그러나 training prompt가 InstructGPT 모델과 함께 사용되도록 설계되었다는 점을 감안할 때, 이것이 GPT-3 베이스라인에 불리하게 작용할 가능성이 있다. 그래서 저자들은 GPT-3 API를 통해 수집된 prompt에 대해서도 평가를 수행하였다.
- 이 prompt들은 일반적으로 "instruction following" 스타일이 아니지만, GPT-3를 위해 설계된 prompt이다.
- 즉, InstructGPT를 위해 설계된 prompt들만 아니라, 기존 GPT-3에 최적화된 prompt들에서도 뛰어난 성능을 보이는지 공정하게 평가하려 한 것이다.
■ 두 경우(InstructGPT용 프롬프트, GPT-3용 프롬프트) 모두, 각 모델에 대해 모델의 출력이 baseline policy보다 얼마나 자주 선호되는지를 계산하였다.
■ 175B SFT 모델을 베이스라인으로 선택했는데, 논문에 따르면 그 성능이 전체 그룹의 중간 정도에 가깝기 때문에 선택했다고 한다.
■ 추가적으로, 레이블러에게 각 response의 전반적인 품질을 1-7점의 리커트 척도로 평가하도록 하였고, 각 모델 출력에 대한 다양한 metadata를 수집하였다. (Table 3)

Evaluations on public NLP datasets.
■ 두 가지 유형의 public dataset에서 모델을 평가하였다:
- (1) truthfulness, toxicity, bias와 같은 언어 모델의 safety의 한 측면을 포착하는 dataset
- (2) QA, reading comprehension, summarization과 같은 전통적인 NLP tasks에서의 zero-shot 성능을 평가하는 dataset
■ 또한, RealToxicityPrompts dataset에서 toxicity에 대한 인간 평가도 수행하였다.
4. Results
4.1 Results on the API distribution
Labelers significantly prefer InstructGPT outputs over outputs from GPT-3.
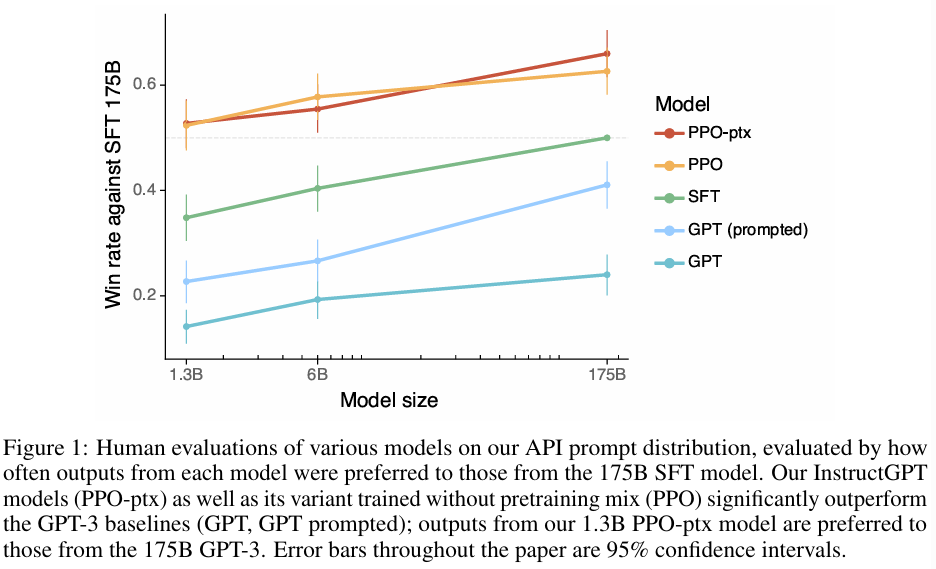
■ test prompt set에서 레이블러들은 InstructGPT의 outputs을 훨씬 더 선호한다는 결과를 Fig 1에서 볼 수 있다.
■ GPT-3의 outputs은 최악의 성능을 보이며, 잘 만들어진 few-shot prompt를 사용(GPT-3(prompted))하고, 지도 학습을 사용하여 demonstrations로 학습하고(SFT), 마지막으로 PPO를 사용하여 comparison data로 학습함으로써 단계적인 개선을 얻을 수 있다는 것을 확인할 수 있다.
■ 또한, GPT-3 API로 수집한 prompt(GPT-3에 최적화된 prompt, Fig 3의 GPT distribution)에서 평가했을 때, InstructGPT의 outputs을 선호한다는 결과가 크게 변하지 않았다는 것을 확인할 수 있다.

- heldout workers는 training data 생성에 참여하지 않은 레이블러들을 의미한다.
■ Fig 4에서, 다양한 항목에 대해서도 레이블러들이 InstructGPT outputs을 더 호의적으로 평가했음을 확인할 수 있다.
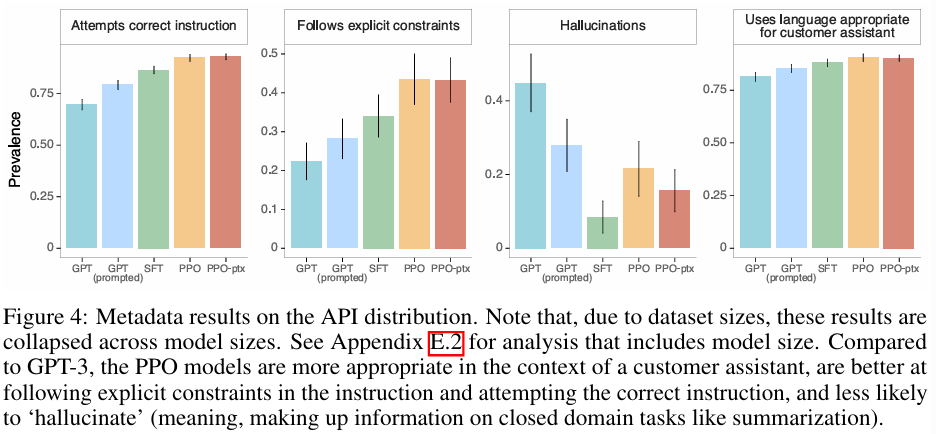
■ 구체적으로, GPT-3와 비교했을 때, InstructGPT outputs은 더 적절하고 지시에 정의된 명시적인 제약 조건(예: "답변을 2문단 이하로 작성하세요.")을 더 자주 따르며, 사용자의 지시를 무시하거나 완전히 잘못 이해하는 경우가 더 적고, closed-domaintasks에서 사실을 지어내는(hallucinate) 경우다 더 적다.
■ 이러한 결과는 InstructGPT 모델이 GPT-3보다 더 신뢰할 수 있고 제어하기 쉽다는 것을 시사한다.
Our models generalize to the preferences of "held-out" labelers that did not produce any training data.
■ held-out 레이블러(training data 생성에 참여하지 않은 레이블러)들도 training 레이블러들과 유사한 선호도를 가진다. GPT-3 베이스라인보다 InstructGPT 모델의 outputs을 더 선호한다. (Fig 3)
4.2 Results on public NLP datasets
InstructGPT models show improvements in truthfulness over GPT-3.

■ Fig 6은 TruthfulQA dataset에 대한 human evaluatoin 결과로, PPO 모델들은 GPT-3에 비해 truthful하고 informative한 outputs을 생성함을 볼 수 있다.
■ 또한, Fig 4에서 보여줬듯이, closed-domain task에서도 정보를 지어내는(즉, hallucinate) 비율이 GPT-3의 절반 정도이다.
InstructGPT shows small improvements in toxicity over GPT-3, but not bias.

■ RealToxicityPrompts dataset에서 두 가지 방식으로 모델을 평가하였다.
- (1) 이 데이터셋의 표준 평가 절차인 Perspective API를 통해 모델 샘플을 실행하여 자동으로 toxicity를 평가
- (2) 이 샘플들을 레이블러들이 평가 (human evaluation)
■ Fig 7에서 safe하고 respectful한 output을 생성하라는 지시("respectful prompt")를 받았을 때, InstructGPT 모델이 GPT-3보다 덜 유해한 outputs을 생성한 것을 확인할 수 있다.
■ bias를 평가하기 위해, 수정된 버전의 Winogender 및 CrowS-Pairs dataset에서 InstructGPT를 평가한 결과, GPT-3에 비해 크게 개선되지 않았다. (Appendix E)
We can minimize performance regressions on public NLP datasets by modifying our RLHF fine-tuning procedure.

■ Fig. 29에서 볼 수 있듯이, PPO fine-tuning에 pretraining update를 추가한 PPO-ptx는 모든 dataset에서 성능 저하를 완화하며, 일부 task에서는 GPT-3의 성능을 능가하는 모습을 보인다.
4.3 Qualitative results
InstructGPT models show promising generalization to instructions outside of the RLHF fine tuning distribution.

■ Fig 8의 예시처럼, InstructGPT는 finetuning 과정에서 거의 본 적 없는 instructions(코드 요약이나, 코드에 대한 질의 응답, 영어가 아닌 다른 언어로 응답)에 대해서도 어느 정도 적절한 response를 생성한다.
■ 저자들은 이러한 결과에 대해 InstructGPT가 “following instructions” 능력을 일정 부분 일반화할 수 있다. 즉, InstructGPT가 특정 언어나 task 유형에 종속되지 않고, instruction의 구조를 이해하여 처음 접하는 task에도 적용할 수 있는 능력을 갖추었다고 주장한다.
InstructGPT still makes simple mistakes.

■ 다른 language tasks에서 좋은 성능을 보였음에도 불구하고, InstructGPT는 여전히 간단한 실수들을 저지른다.
■ 논문에서는 몇 가지 예로,
- (1) 거짓된 전제를 가진 지시가 주어지면, 모델이 그 전제가 사실이라고 가정하는 경우
- (2) 회피적인 답변을 하는 경우; 문맥상 명확한 답이 있음에도 불구하고, 때때로 질문에 대한 정답이 하나가 아니라 여러 개의 답변을 제공
- (3) "프랑스를 배경으로 1930년대에 만들어진 영화 10개를 나열해 줘"와 같이 지시에 여러 명시적인 제약 조건이 포함되거나, "지정된 문장 수로 요약을 작성해 줘"와 같이 제약 조건이 언어 모델에게 어려울 수 있을 때 모델의 성능이 저하
■ 저자들은 (1)의 경우, training set에 거짓된 전제를 가정하는 prompt가 거의 없기 때문에 발생한 문제이며, (2)는 모델이 겸손하게 말하는 답변에 더 높은 점수를 받도록 학습된 결과, 명백한 정답이 있는 질문에도 확신에 찬 답변을 주저하게 된 것으로 보인다고 주장한다.
■ 그리고 이러한 (1), (2)의 문제는 adversarial data들을 수집하여 학습하면 크게 개선될 수 있을 것이라 주장한다.
'자연어처리 > LM' 카테고리의 다른 글
| OPT: Open Pre-trained Transformer Language Models (0) | 2025.11.10 |
|---|---|
| Chinchilla: Training Compute-Optimal Large Language Models (0) | 2025.10.30 |
| FLAN: Finetuned Language Models Are Zero-Shot Learners (0) | 2025.10.27 |
| LaMDA: Language Models for Dialog Applications (0) | 2025.10.13 |
| GPT-3: Language Models are Few-Shot Learners (1) | 2025.07.23 |