■ 대규모 텍스트 코퍼스에서 pre-training한 후 특정 태스크에 대해 fine-tuning하는 방법은, 많은 NLP 태스크와 벤치마크에서 상당햔 향상을 보여주었다.
■ 이 방법은 일반적으로 모델 아키텍처 측면에서는 태스크에 구애받지 않지만(task-agnostic), 즉 모델 아키텍처가 범용적으로 사용될 수 있음에도 불구하고, 특정한 태스크에서 우수한 성능을 달성하기 위해서는 여전히 task-specific한 데이터셋이나 task-specific한 파인튜닝이 충분히 수행되어야 한다는 한계가 있다.
- task-agnostic이란 태스크와 독립적이다. 태스크와 무관하다.
■ 대조적으로, 인간은 단지 몇 개의 예제나 간단한 지시만으로 새로운 언어 태스크를 수행할 수 있다.
■ 저자들은 이 한계를 극복하기 위한 열쇠가 바로 규모(Scale)에 있다는 가정 하에, 175B 개의 파라미터를 가진 자기회귀 언어 모델인 GPT-3를 훈련시키고, few-shot 환경에서 그 성능을 테스트하였다.
[2005.14165] Language Models are Few-Shot Learners
Language Models are Few-Shot Learners
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fi
arxiv.org
1. Introduction
■ 앞서 언급한 것처럼, pre-training & fine-tuning 접근법의 주된 한계는, 모델 아키텍처는 태스크에 구애받지 않지만, 여전히 task-specific datasets과 task-specific fine-tuning이 필요하다는 것이다.
- 예를 들어, BERT나 GPT-2같은 모델은 하나의 범용 아키텍처(트랜스포머 encoder only, decoder only, 또는 encoder-decoder)를 가지고, 데이터만 바꾸어 파인튜닝하면 다양한 태스크를 해결할 수 있다.
- 원하는 태스크에 강력한 성능을 달성하기 위해서는, 일반적으로 해당 태스크에 특화된 수천에서 수십만 개의 예제로 구성된 데이터셋에 대한 파인튜닝이 필요하다. 또한, 파인튜닝이 충분히 수행되어야 한다.
■ 저자들은 이러한 한계를 제거하는 것이 다음과 같은 이유에서 바람직하다고 주장한다.
- (1) 모든 새로운 태스크마다 레이블이 지정된 examples을 가지고 있는 대규모 데이터셋이 필요하다는 점은 언어 모델의 적용 가능성(applicability)을 제한한다.
- 많은 태스크에 대해 대규모 지도 학습을 위한 데이터셋을 수집하는 것은 매우 어려우며, 특히 새로운 태스크마다 이 과정(대규모 지도 학습 데이터셋 수집, 예: 레이블링)을 반복하는 것은 더욱 어렵다.
- 그러므로 파인튜닝 과정 자체가 없다면, 파인튜닝을 위한 데이터셋 수집이 필요 없으므로 훨씬 더 다양한 태스크에 언어 모델을 쉽게 적용할 수 있다.
- (2) 모델 크기(파라미터 수)가 커지고 학습 데이터가 충분하지 않은 경우(학습 데이터의 분포가 좁은 경우)에는 가짜 상관관계(spurious correlations)가 발생할 확률이 증가한다.
- pre-training & fine-tuning 패러다임은 사전학습 과정에서 많은 정보를 흡수하기 위해 크고 넓게 설계되지만, 그 다음 매우 좁은 태스크 분포에서 파인튜닝된다.
- 즉, 거대한 사전학습된 모델을 좁고 특정한 데이터 분포(예: 특정 벤치마크의 데이터셋)에만 맞춰 훈련시킨다.
- 해당 벤치마크에서는 높은 점수를 받을 수 있지만, 다른 분포(out-of-distribution)의 데이터에 대해서는 일반화 성능이 떨어져서 형편없는 성능을 보일 수 있다.
- 논문에서는 특정 벤치마크에서 파인튜닝된 모델의 성능은, 인간 수준으로 보일지라도, 근본적인 태스크에 대한 실제 성능은 과장될 수 있다고 설명한다.
- spurious correlations의 예로, '아이스크림 판매량이 증가하는 시기에 익사 사고 발생률도 함께 증가한다'고 하자.
- 그러면 '아이스크림 판매가 익사 사고를 증가시키는 직접적인 원인이다'라는 결론을 내릴 수 있다.
- 그러나 아이스크림을 먹는 것과 익사는 전혀 상관이 없다. 즉, 둘 사이에는 직접적인 관계가 없는 것이다.
- 이 관계가 가짜인 이유는, 두 현상에 공통으로 영향을 미치는 숨겨진 요인, 즉 잠재 변수가 있기 때문이다.
- 예를 들어 잠재 변수에는 '더운 날씨'가 있을 수 있다.
- 날씨가 더워질수록 사람들이 아이스크림을 많이 사 먹고, (아이스크림 판매량 증가)
- 날씨가 더워질수록 사람들이 물놀이를 많이 간다. (익사 사고 발생 가능성 증가)
- '더운 날씨'라는 요인을 제외하고 보면, 아이스크림 판매량이 익사 사고 증가의 원인처럼 보일 수 있다. 하지만 실제로는 '더운 날씨'라는 공통된 원인 때문에 두 현상이 우연히 함께 증가한 것이다.
- 이것이 바로 spurious correlations이다. 통계학의 '상관관계는 인과관계를 의미하지 않는다'를 잘 보여주는 예시이다.
- (3) 인간은 언어 태스크를 배우기 위해 대규모의 지도 학습 데이터셋을 필요로 하지 않는다.
- 인간은 자연어로 구성된 간략한 문장이나, 아주 적은 수의 문장 몇 개만으로도 새로운 태스크에 대한 로직을 이해하고 해당 태스크를 풀어낼 수 있다.
■ GPT-3 논문에서 파인튜닝 없이 새로운 태스크 학습을 위해 사용하는 개념 중 하나는 메타 학습(meta-learning)이다.
■ 이는 인간이 대화 중에 덧셈 계산을 수행할 수 있는 것처럼, 여러 태스크와 특정 태스크를 위한 기술(덧셈, 번역, 오타 교정)들을 전환하며 활용하는 능력을 모방한 것이다. 아래의 Fig 1.1이 바로 meta-learning의 예를 시각화한 것이다.

- Fig 1.1을 보면 outer loop와 inner loop가 존재하는 것을 확인할 수 있다.
- SGD를 통해서 unsupervised pre-training을 진행하는 과정이 output loop이고, inner loop에서는 동일한 패턴을 가지는 데이터들이 각각의 시퀀스에 들어가는 것을 볼 수 있다. 논문에서는 이를 In-context learning이라고 표현하고 있다.
■ 저자들은 이 meta-learning을 통해 모델이 학습 과정에서 다양한 기술과 데이터의 패턴을 배우고, 추론 과정에서 학습한 능력들을 사용하여 원하는 태스크에 적용할 수 있도록 설계했다.
■ 그러나, 이 접근법은 기존의 파인튜닝 방식보다 훨씬 뒤떨어지는 성능을 보여서 추가적인 개선이 필요하다고 판단하였고, 개선 방법으로 모델의 스케일을 늘리는 방법을 선택하였다.
■ 이 선택에 대한 근거는, 트랜스포머 언어 모델의 용량(파라미터 수)이 계속 증가하고 있으며, 이러한 스케일 증가는 모델의 성능을 향상시킨다는 점이었다.
■ 그래서 저자들은 다음과 같은 가설을 세웠다.
- in-context learning을 통해 모델 파라미터 내에 많은 기술과 태스크를 흡수시킬 수 있고, 모델 용량(파라미터 수)을 늘리면 더 많은 기술과 패턴을 저장하고 처리할 수 있다.
- 그러므로, 기존 파인튜닝 방식보다 뒤떨어지는 in-context learning의 학습 능력 또한 스케일링의 법칙에 따라 향상될 수 있다.
■ 그리고 이 가설을 테스트하기 위해 GPT-3라고 부르는 175B 파라미터의 자기회귀 언어 모델을 훈련시키고, in-context learning 능력을 평가하였다.
■ 구체적으로 3가지 조건 하에서 GPT-3를 평가하였다.
- (1) zero-shot learning
- 어떤 태스크가 주어졌을 때, 그 태스크에 대한 example을 전혀 주지 않음
- (2) one-shot learning
- 단 하나의 example만 사용
- (3) few-shot learning
- context window에 들어갈 만큼의 example들(보통 10개에서 100개)을 사용

■ 자연어 프롬프트(태스크에 대한 설명)가 추가되고, examples의 수가 증가함에 따라 모델 성능이 향상되며, few-shot learning의 경우 모델 크기가 커질수록(1.3B 파라미터 \( \rightarrow \) 13B 파마리터 \( \rightarrow \) 175B 파라미터) 성능이 극적으로 향상되는 것을 Fig 1.2에서 볼 수 있다.
- 예를 들어덧셈 태스크가 있다고 했을 때,
- no prompt는 "1+2="만 주는 것을, natural language prompt는 "add integer: 1+2="로 태스크에 대한 설명이 붙은 것을 의미한다.
■ 모델 용량이 커지면 커질수록, no prompt 방법과 natural language prompt의 방법에 따른 성능의 차이가 거의 없어지는 것도 Fig 1.2에서 볼 수 있다.
■ 논문에 따르면, GPT-3는 제로샷과 원샷으로 특정한 데이터셋에서는 SOTA와 비슷하거나 더 뛰어난 성능을 보였으며,
■ 원샷과 퓨샷에서는 unscrambling words(뒤섞은 단어를 다시 되돌리기), performing arithmetic(산수 문제 풀기), using novel words in a sentence(문장에서 새로운 단어 사용하기) 등 빠른 적응이나 즉석에서 추론하는 능력을 평가하기 위해 고안된 태스크에서 좋은 성능을 보였고, 특히 퓨샷에서는 인간이 생성한 기사와 구별하기 어려운 synthetic한 뉴스 기사를 생성할 수 있었다고 한다.
■ 그러나 GPT-3의 규모에서도 퓨샷 성능이 어려움을 겪는 일부 태스크(ANLI과 같은 NLI 태스크, RACE나 QuAC와 같은 독해 데이터셋)가 존재한다고 밝혔다.

■ 저자들은 위의 Fig 1.3과 같이 제로, 원, 퓨샷 성능 간의 격차가 모델 용량에 따라 커지는 패턴을 발견하였으며, 이러한 결과는 용량이 더 큰 모델이 meta-learning 능력이 더 뛰어나다는 것을 보여준 것이라고 주장한다.
2. Approach
■ GPT-3는 아래의 Fig 2.1의 왼쪽 그림처럼 3개의 approach가 있다.

■ GPT-3의 핵심은 inference에서 zero-shot이나 one-shot, few-shot의 examples에 대해서 Fig 2.1의 오른쪽 그림처럼 examples에 대한 그래디언트 업데이트를 하지 않는다는 것이다.
■ 먼저, 오른쪽에 있는 전통적인 파인튜닝 방법을 보면,
- 첫 번째 example이 주어졌을 때, 이 첫 번째 example에 대한 결과를 통해 그래디언트를 업데이트하고
- 그다음, 두 번째 example이 주어졌을 때에도 동일하게 example에 대한 결과를 통해 그래디언트를 업데이트한다.
■ 이렇게 전통적인 파인튜닝 방법은 examples들이 주어졌을 때 그래디언트를 업데이트하면서 파인튜닝을 진행한다.
■ 이제 Fig 2.1에서 GPT-3의 in-context learning에 대한 3가지 approach를 보면,
- (1) zero-shot
- zero-shot의 경우, prompt 안에 'Translate English to French:'라는 "task description"과 'cheese =>'라는 실제 번역해야 할 문제를 입력한다.
- zero-shot이므로, 모델은 '사전학습 과정에서 학습된 지식만으로' 이 프롬프트를 처리해야 한다.
- (2) one-shot
- one-shot은 말 그대로 모델에 하나의 example을 알려주는 것을 말한다. 이에 대한 예시를 Fig 2.1에서 확인할 수 있다.
- Fig 2.1을 보면 one-shot의 경우, prompt 안에 ① task description과 ② 처리해야 할 문제, 그리고 'sea otter => loutre de mer'이라는 영어-프랑스어 번역 ③ example 1개가 존재하는 것을 확인할 수 있다.
- (3) few-shot
- one-shot이 example 1개를 프롬프트 안에 넣는 것이라면, few-shot은 여러 개의 examples를 프롬프트 안에 넣는 것을 말한다.
■ 이렇게 GPT-3의 in-context learning은 Fig 2.1 오른쪽에 있는 전통적인 파인튜닝 방법과 다르게 example에 대한 그래디언트 업데이트가 전혀 없는 것을 볼 수 있다.
■ 즉, GPT-3는 오직 주어진 예시들의 패턴을 보고 다음에 올 단어를 예측한다. 이렇게 GPT-3의 핵심은 Fig 2.1의 오른쪽 그림처럼 '파인튜닝을 하지 않는다'는 것이다.
■ 논문에서 Fine-Tuning(FT)와 GPT-3의 3가지 in-context learning approach인 Few-Shot(FS), One-Shot(1S), Zero-Shot(0S)에 구체적으로 어떠한 차이가 있는지 확인할 수 있다.
Fine-Tuning (FT)
■ FT는 가장 일반적인 접근법이다. 원하는 태스크에 지도 학습 데이터셋으로 추가 훈련함으로써, 사전학습된 모델의 가중치를 업데이트(정확하게는 새로운 지도학습 데이터셋으로 그래디언트 업데이트를 이어서)하는 방식이다.
■ 일반적으로 수천에서 수십만 개의 레이블된 examples가 사용된다.
■ 이 방식의 장점은 많은 벤치마크에서의 강력한 성능이며, 단점은 ① 모든 태스크마다 새로운 대규모 데이터셋이 필요하다는 점, ② out-of-distribution(ood) 즉, 파인튜닝에 사용한 지도학습 데이터가 커버하지 못하는 데이터 분포(예: test set)에 대한 일반화가 어렵고, 그리고 ③ 훈련 데이터의 spurious features를 이용할 가능성, 즉 파인튜닝을 하기 위한 태스크 데이터셋에 과적합이 되는 문제 등이 존재한다.
cf) 저자들은 태스크에 구애받지 않는(task-agnostic) 성능에 초점을 맞추기 때문에 GPT-3를 파인튜닝하는 실험은 진행하지 않았다.
Few-Shot (FS)
■ 퓨삿(few-shot)은 추론(inference) 단계에서 모델에게 태스크에 대한 몇 가지 examples을 제공하지만, FT와 다르게 모델에게 준 examples에 대해 어떠한 가중치 업데이트(그래디언트 업데이트)도 수행하지 않는 설정을 의미한다.
■ 즉, few-shot의 장점은 FT처럼 매우 큰 양의 task-specific data가 필요하지 않다는 점이다. 그래서 파인튜닝 데이터셋으로부터 지나치게 좁은 분포를 학습할 가능성을 줄일 수 있다. 즉, FT처럼 좁은 데이터 분포에 모델을 과적합시킬 위험이 없다.
■ 단점은 성능이다. few-shot learning을 통한 모델의 성능은 (full) fine-tuning된 모델의 성능에 비해 뒤떨어진다. 그리고 제로샷(zero-shot)이 아닌 이상, 적은 양이라도 examples로 사용할 task의 데이터가 필요하다는 한계가 존재한다.
One-Shot (1S)
■ 원샷(one-shot)은 태스크에 대한 자연어 설명과 단 하나의 example만 허용된다는 점을 제외하면 few-shot과 동일하다.
Zero-Shot (0S)
■ 제로샷(zero-shot)은 어떠한 example없이, 모델에게 오직 태스크를 설명하는 자연어 지시만 주어진다는 점을 제외하면 one-shot과 동일하다.
■ Zero-shot은 example을 전혀 사용하지 않는다는 점에서 장점과 단점이 존재한다.
- example을 사용할 필요가 없으므로 다른 방법(one-shot, few-shot, fine-tuning)에 비해 가장 편리하다는 장점이 있다.
- 사전학습된 모델의 가중치에서 학습한 지식만을 바탕으로 답변을 생성하기 때문에 모델이 몇 개의 example에 과적합되는 것을 방지할 수 있다.
- 또한, example이 아예 없기 때문에 spurious correlations를 회피할 수 있다는 장점이 있다.
- 그러나 example이 아예 없기 때문에 높은 성능을 달성하기에는 까다로운 방법이다.
2.1 Model and Architectures

■ GPT-3는 GPT-2와 동일한 아키텍처를 사용한다. 단 한 가지 예외는 거대한 175B 모델의 계산 효율성을 위해 sparse attention을 사용한다는 것이다.
■ 위의 Table 2.1을 보면, 저자들은 125M 모델부터 175B 모델까지, 8가지 다른 크기의 모델을 훈련시켰다. 여기서 175B 모델이 GPT-3이다.
■ \( n_{params} \)는 trainable parameters의 수, \( n_{layers} \)는 총 레이어 수, \( d_{model} \)은 모델 은닉 레이어의 유닛 수이며, 피드포워드의 \( d_{ff} = 4 * d_{model} \), 그리고 \( n_{heads} \)는 어텐션 헤드의 수이다. 모든 모델은 \( n_{\text{ctx}} = 2048 \) 토큰의 context window를 사용한다.
2.2 Training Dataset
■ GPT-3는 학습에 Common Crawl 데이터셋을 사용하였다. 저자들은 데이터셋 품질을 높이기 위해 필터링을 수행하였다.
■ 최종 데이터셋은 아래의 Table 2.2와 같은 데이터셋들로 혼합되었는데, 저자들은 고품질 데이터셋들에서 더 자주 샘플링하기 위해 가중치 샘플링을 사용한 것을 확인할 수 있다.. 즉, 모든 데이터셋을 동일한 비율로 샘플링하지 않았다.

■ Common Crawl과 Books2 데이터셋은 훈련 중에 한 번 미만으로 샘플링(0.44, 0.43)되지만, 다른 데이터셋들은 2~3번 샘플링(WebText2는 2.9, Books1은 1.9, Wikipedia는 3.4)되는 것을 확인할 수 있다.
■ 저자들은 이 전략이 고품질 데이터에 대해 약간의 과적합을 감수하는 대신, 본질적으로 더 높은 품질의 훈련 데이터를 얻는, 훈련 품질을 높이는 선택이라고 판단하였다.
2.3 Training Process
■ 저자들은 Scaling Laws For Neural Language Models라는 논문에서 발견한 법칙인 "일반적으로 큰 모델은 큰 배치 크기를 사용할 수 있지만, 작은 학습률이 필요하다." 는 분석에 기반하여, 학습 중에 그래디언트 노이즈 스케일(gradient noise scale)을 측정하여 배치 크기 선택하였다.
- Table 2.1에서 저자들이 사용한 파라미터 설정들을 확인할 수 있다.
■ GPT-3는 175B 파라미터 모델이기 때문에 일반적 GPU의 메모리에 절대 들어갈 수 없다. 그래서 저자들은 OOM(Out Of Memory)없이 모델을 훈련시키기 위해, 행렬 곱셈 내에서의 모델 병렬화와 네트워크의 레이어들에 걸친 모델 병렬화를 혼합하여 사용하였다.
- 즉, 두 종료의 병렬화를 혼합해서 사용한 것이다.
- 두 번째 병렬화는 서로 다른 GPU에 레이어들을 할당하는 것(예: 1-24번 레이어는 GPU0, 25-48번 레이어는 GPU1, ...)을 의미하고,
- 첫 번째 병렬화는 여러 개의 GPU가 레이어 내 거대한 행렬 곱셈 연산을 나누어 병렬로 계산하고, 각 GPU에서 계산한 결과를 다시 하나로 합치는 것을 의미한다.
■ Fig 2.2는 훈련 중 사용된 총 컴퓨팅을 나타낸 것이다.

■ 저자들은 Scaling Laws For Neural Language Models라는 논문에서 "컴퓨팅 예산이 고정되어 있을 때, 모델이 데이터를 많이 학습하는 것보다 모델 크기를 키우는 것이 성능 향상에 효율적이다."라는 분석에 기반하여 적은 수의 토큰(데이터)로 모델을 훈련시켰다.
■ 결과적으로, GPT-3 3B가 RoBERTa-Large보다 거의 10배 더 크지만, 두 모델 모두 사전학습하는 데 사용된 총 계산량은 거의 동일했다고 한다.
2.4 Evaluation
■ 저자들은 태스크 유형별로 맞춤형 평가 방식을 통해 모델의 능력을 측정하였다.
■ 먼저, 여러 선택지 중 하나의 정답을 고르는 객관식 태스크에서 \( K \)개의 'context + correct completion' example를 제공하고, 그 뒤에 context만 있는 example 하나를 덧붙인 다음, 각 completion에 대한 언어 모델의 likelihood를 비교하여 확률이 가장 높은 선택지를 예측 결과로 선택하였다.
■ 대부분의 태스크에서는 선택지의 길이에 따른 유불리(문장이 길수록, 즉 토큰이 길수록 확률 곱이 작아지는 경향이 있음)를 없애기 위해 토큰 당 likelihood를 비교했지만, 일부 데이터셋(ARC, OpenBookQA, RACE)에서는 P(completion | context) / P(completion | answer_context)으로 보정을 해주었다.
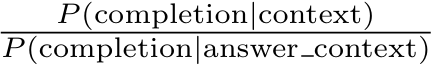
- 여기서 answer_context는 'Answer' 또는 'A: '와 같은 문자열로, completion이 정답이어야 함을 프롬프트한 것이라고 한다. - 이러한 보정을 추가한 이유는 다음과 같다.
- 예를 들어, 'The United States of America'나 '질문: What is the capital of Korea? 선택지1: Paris, 선택지2: Seoul'처럼, 언어적으로 더 자연스럽거나 흔한 표현이라서, 모델은 문맥과 무관하게 높은 (정답) 확률을 줄 수 있다.
- P(completion | context) / P(completion | answer_context)는 이런 영향을 제거하고자 사용한 것이다.
- 구체적으로, 분자는 context에서 해당 completion이 나올 확률이지만,
- 분모는 'Answer' 또는 'A: '같은 프롬프트만 주고, 동일한 completion이 나올 확률이므로 context 없이도 모델이 동일한 completion을 얼마나 선호하는지 측정할 수 있다.
- 그러므로, P(completion | context) / P(completion | answer_context)의 비율이 크면 문맥(context)때문에 선택된 것이고, 비율이 1에 가까우면 문맥(context)과 상관없이 선호되는 답(completion)일 가능성이 크다.
- 즉, context 없이도 기본적으로 얼마나 가능성이 높은 completion인지를 측정해서 그 영향을 제거하고자 한 것이다.
3. Results

■ 위의 Fig 3.1은 섹션 2에 기술된 8개 모델의 훈련 곡선(training curves)이다. 저자들은 여기에 10만 개만큼 적은 파라미터를 가진 6개의 소형 모델들을 추가적으로 포함시켰다.
- x축은 compute, y축은 valid loss이며, 오른쪽의 그라데이션은 모델 크기를 나타낸다. 밝은 색일수록 크기가 큰 모델이다.
■ Scaling Laws For Neural Language Models에서 관찰된 바와 같이, 크기가 큰 모델이든 작은 모델이든 compute가 증가할수록 언어 모델링 성능이 향상(valid loss가 감소)하는 것을 볼 수 있다.
- 이 valid loss는 cross-entropy loss이다.
- 모델 크기에 상관없이 compute에 따라 valid loss가 거의 직선 형태로 줄어드는 데, x축이 로그 스케일을 따르기 때문에 이 그래프의 실질적인 관계는 멱법칙(power-law)을 따르고 있다. 즉 valid loss가 power law 형태로 줄어들고 있음을 알 수 있다.
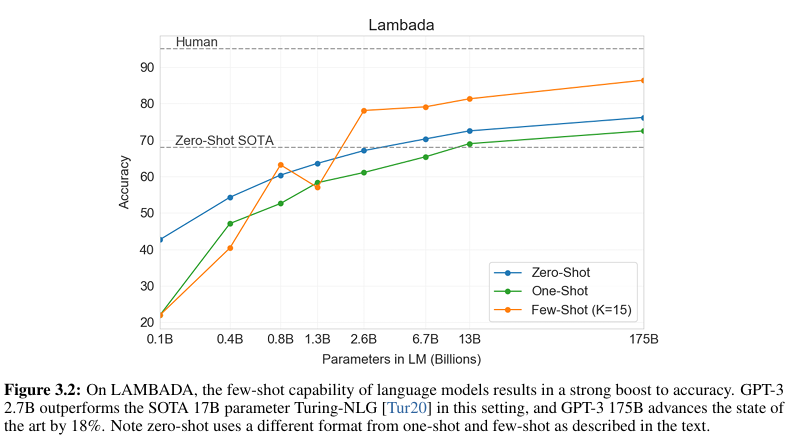
■ 위의 Fig 3.2의 x축은 모델 크기(파라미터 개수), y축은 LAMBADA 데이터셋에서의 정확도를 나타낸 것이다.
■ 이 실험에서 zero-shot과 one-shot은 위에서 언급한 것처럼 설정하였다. 단, few-shot의 경우 아래 예시 그림처럼 'fill in the blank' format을 examples로 사용하였다.
- Fig 3.2의 범례에서 few-shot의 경우 아래와 같은 형식의 example 15개를 사용했다는 것을 볼 수 있다.

■ Fig 3.2를 보면, 논문에서 주장하는 것처럼 모델의 스케일이 커질수록(모델 크기가 커질수록), 성능이 점점 향상되는 것을 확인할 수 있다.

■ QA 태스크인 TriviaQA에서도 Fig 3.2와 비슷한 경향(모델의 스케일이 커질수록 성능이 향상된다.)을 확인할 수 있다.

■ machine translation에서도 비슷한 경향을 확인할 수 있다. 구체적으로, 어떠한 언어 번역 유형(예: 프랑스어-영어, 영어-독일어 등)에서도 x가 커질수록 y가 증가하는 것을 확인할 수 있다.
■ 저자들은 few-shot을 사용하여 GPT-3가 생성한 뉴스 기사의 품질을 측정하기 위해, 어떤 기사가 실제 기사이고 GPT-3가 생성한 기사인지를 사람이 판별하도록 하였다. 이에 대한 결과는 아래의 Table 3.11에서 확인할 수 있다.

■ 의도적으로 엉터리로 만든 기사가 모델에 의해 생성되었음을 구별하는 평균 인간 정확도(human mean accuracy)는 약 86%였으며 (Control (deliberately bad model), GPT-3 모델의 크기가 커질수록 정확도가 꾸준히 감소하여 GPT-3 175B의 경우 정확도가 52%인 것을 확인할 수 있다. 정확도가 52%라는 것은 거의 무작위로 정답을 고른 수준이다.
- 논문에 따르면, 참가자들이 더 큰 모델이 쓴 글일수록, 더 오랜 시간 고민하고 읽었음에도 불구하고 정답률은 오히려 떨어졌다고 한다.
- 모델의 스케일이 커질수록 텍스트 생성 능력이 향상된다는 것을 증명한 실험 결과이다.
■ 논문의 Fig 3.5부터 Fig 3.11까지 각 태스크 유형별로 모델의 스케일을 키웠을 때, 모델 성능을 측정한 실험 결과로 GPT-3는 전반적으로 SOTA와 비견될 수 있는 성능을 기록하였다.
■ 단, 자연어 추론(NLI) 태스크(Fig 3.9)에서는 가장 큰 모델인 175B에 이르러서야 비로소 SOTA 모델 성능의 절반 정도 따라잡는 성능을 보이기 시작한다.
■ 그리고 Fig 3.10은 산수 문제에 대한 성능 결과로, 13B 모델까지는 매우 저조한 성능을 보이다가, 175B 모델에서 성능이 급등하는 것을 확인할 수 있다.
■ 이러한 결과는 산수같은 문제는 모델이 충분히 커져서 그 원리를 내재적으로 학습할 수 있는 용량(capacity)을 갖추기 전까지는 능력이 발현되지 않는 것으로 해석할 수 있다.

■ Fig 4.1은 GPT-3가 과적합된 모델인지, 일반화 성능이 잘 갖춰진 모델인지 확인하기 위해 train loss와 valid loss를 시각화한 그림이다.
■ Fig 4.1을 보면 점선과 실선 사이 갭이 존재하는 것을 확인할 수 있다. 그리고 모델 크기가 커져도 두 곡선 사이의 갭은 거의 벌어지지 않으며, 어느 정도 괜찮은 모델이라고 수긍할 수 있는 정도이다.
■ 이 결과에 대해 저자들은, Fig 4.1의 train loss와 valid loss의 갭은 과적합보다는 train set과 valid set의 난이도 차이에서 비롯된 것이라고 주장한다. 즉, train set보다 valid set에 더 어려운 문제가 있었기 때문에 위와 같은 결과가 나타난 것이라고 주장한 것이다.
참고) https://www.youtube.com/watch?v=xNdp3_Zrr8Q&t=1010s

