Improving language understanding with unsupervised learning | OpenAI
1. Introduction
■ 대부분의 딥러닝 방법론들은 대량의 레이블된 데이터(labeled data) 를 사용해 지도 학습을 수행한다. 즉, 레이블된 데이터가 부족하다면 해당 방법론들을 다양한 도메인에 적용하기 어렵다는 한계가 있다.
■ 어떤 도메인의 데이터가 레이블이 없는 데이터라면, 시간과 비용이 많이 소모되는 데이터 레이블링 작업을 통해 지도 학습을 위한 레이블 데이터를 만들어야 한다.
■ 그러므로 레이블이 없는 데이터(unlabeled data)로부터 언어적 정보(linguistic information)를 활용할 수 있는 모델은 시간과 비용이 많이 드는 데이터 레이블링 작업의 대안이 될 수 있다.
■ 또한, 레이블이 있는 데이터가 있는 경우에도 비지도 방식으로, 더 좋은 표현(representation)을 학습하는 것은 성능 향상을 가져올 수 있다.
- 다양한 NLP task들의 성능 향상을 위해 사전 학습된 단어 임베딩(pretrained word embedding)을 사용하는 것이 이에 대한 근거이다.
■ 단, 레이블이 없는 텍스트 데이터에서 단어 수준(word-level) 이상의 정보를 활용하는 데에는 다음과 같은 두 가지 어려움이 있다.
■ 첫 번째, 전이(transfer)에 유용한 텍스트 표현(text representation)을 학습하기 위해 어떤 최적화 목적 함수(optimization objectives)가 가장 효과적인지 명확하지 않다.
■ 두 번째, 학습된 표현을 target task로 전이시키는 가장 효과적인 방법이 정립되어 있지 않다.
■ 이 논문에서는 기존의 방법들(learning schemes, task-specific한 모델 아키텍처, auxiliary learning objectives 등)이 언어 처리를 위한 효과적인 준지도 학습(semi-supervised)의 접근법에 대한 개발을 어렵게 만들었다고 지적하며,
■ 비지도 사전 학습(unsupervised pre-training)과 지도 파인튜닝(supervised fine-tuning)의 조합을 사용하여 언어 이해 task를 위한 준지도 학습 접근법을 제시한다.
■ 이 접근법의 목표는 "서로 다른 도메인 & 레이블이 없는 말뭉치(corpus)"를 사용하여 최소한의 적응(adaptation)만으로 광범위한 범위의 task에 전이(transfer)될 수 있는 범용적인 표현(universal representation)을 학습하는 것이다.
- 사전 훈련에 사용될 레이블 없는 텍스트의 도메인과 파인 튜닝에 사용될 데이터의 도메인이 반드시 일치할 필요가 없다는 것이다. 이는 사전 훈련을 통해 학습된 보편적인 표현이 다양한 도메인에 걸쳐 전이될 수 있음을 의미한다.
■ 여기서 말하는 최소한의 적응이란, 먼저 레이블이 없는 데이터에 대해 언어 모델링(language modeling) 목적 함수를 사용하여 신경망 모델의 초기 파라미터를 학습한 다음, 이 파라미터들을 target task에 적용시키는 것이다.
■ 사용한 모델 아키텍처는 트랜스포머이다. 트랜스포머는 기계 번역, 문장 생성, 구문 분석 등 다양한 task에서 강력한 성능을 입증했다.
■ 특히, 순환 신경망 같은 대안들과 비교했을 때, 트랜스포머는 어텐션 메커니즘을 통해 텍스트 내 장기 의존성(long-term dependency)을 더 효과적으로 처리할 수 있다. 그 결과, 다양한 task에 걸쳐 강겅한 전이 성능을 보여준다.
■ 그리고 각 task의 입력 데이터를 하나의 형식으로 변환하여 모델에 넣어준다. 이렇게 하면 파인튜닝 시, 모델 아키텍처를 크게 변경하지 않고도 입력 데이터만 살짝 바꿔줌으로써 다양한 문제를 해결할 수 있다.
■ 이 논문에서는 네 가지의 언어 이해 작업(natural language inference, question answering, semantic similarity, text classification)에 대해 제안한 방법론(unsupervised pre-training and supervised fine-tuning)을 평가한다.
■ 그 결과, 상식 추론이나 질의 응답과 같은 복잡한 이해 능력을 요구하는 task에서, 논문에서 제안한 task-agnostic model(특정 task에 맞춰 따로 설계된 것이 아닌 task에 관계없이 사용할 수 있도록 만든 pre-training 모델)이 discriminatively trained models(각 task에 맞춰 아키텍처가 설계되었고, 해당 task의 정답을 맞추는 데 학습된 모델)을 능가하였다고 한다.
참고) 제로샷(Zero-shot) 행동 분석: 파인튜닝을 전혀 하지 않은, 즉 사전 학습만 마친 모델이 처음 보는 과제를 얼마나 잘 푸는지를 테스트했습니다. 이를 통해 모델이 사전 학습 과정에서 이미 다양한 과제를 해결하는 데 필요한 잠재적인 능력을 스스로 학습했음을 보여주었습니다. 이는 "사전학습"의 효과를 증명하는 매우 중요한 근거가 됩니다.
-> 이거는 블로그 정리 x 차라리 뒤에 나오는 내용이니 뒤의 내용과 적절히 섞어 쓰던가
2. Related Work
2.1 Semi-supervised learning for NLP
■ NLP에서 준지도 학습은 시퀀스 레이블링이나 텍스트 분류와 같은 task에 적용되어 왔다.
■ 가장 초기의 접근법들은 레이블이 없는 데이터를 사용하여 단어 수준(word-level)이나 구문 수준(phrase-level)에서의 통계치(예: 단어 빈도수)를 계산하고, 이를 지도 학습 모델의 특징(feature)으로 사용하였다.
■ 이외에도 레이블이 없는 코퍼스에서 훈련된 단어 임베딩을 사용하여 다양한 task의 성능을 향상시킬 수 있다는 이점을 입증해왔다.
■ 하지만 이러한 접근법들은 단어 수준의 정보만을 전이하는 데 그친다.
■ GPT-1은 준지도 학습의 한 갈래로서, 단어 수준을 넘어선 더 높은 수준의 의미(semantics)를 담아내는 것을 목표로 한다.
2.2 Unsupervised pre-training
■ 비지도 사전 학습(Unsupervised pre-training)은 준지도 학습의 특별 케이스로, 지도 학습의 목적 함수 자체를 수정하기보다는 좋은 초기 시작점(사전 학습을 통해 찾은 모델의 좋은 가중치 '초깃값')을 찾는 것이 목표이다.
■ 초기 연구들은 이미지 분류나 회귀 task에서 이 기술의 사용을 탐구했으며, 후속 연구에서는 사전 학습이 정규화(regularization) 기법처럼 작용하여 좋은 가중치 초깃값을 통해 심층 신경망의 일반화 성능을 향상시킨다는 것을 보여주었다.
■ 이 방법이 이미지 분류, 음성 인식, 개체명, 기계 번역과 같은 다양한 task에서 심층 신경망 훈련을 돕는 데 사용되고 있다.
■ 논문의 연구와 가장 유사한 연구 갈래는 언어 모델링(language modeling) 목적 함수를 사용하여 신경망을 사전 학습한 다음, 지도 학습을 이용해 target task에 파인튜닝하는 것이다.
■ 텍스트 분류 성능을 향상시키기 위해 이 방법을 따르는 연구가 있다. 단, LSTM 모델을 사용하기 때문에 장기 의존성을 의식하여 예측 능력을 짧은 범위로 제한해서 언어적 정보의 일부만 포착한다.
■ 이와 대조적으로, 트랜스포머는 장거리 언어 구조(longer-range linguistic structure)를 포착할 수 있게 해준다.
■ ELMo같은 접근법은 학습된 모델에서 나온 은닉 표현(hidden representation)을 보조 특징(auxiliary features)으로 사용하고, 각 개별 target task마다 새로운 아키텍처를 설계하고 상당한 양의 새로운 파라미터를 추가해야 하지만,
■ GPT-1은 모델 자체를 가져와서 파인튜닝하기 때문에 전이 과정에서 모델 아키텍처에 최소한의 변경(예: output layer 추가)만 가하면 된다. 그러므로 추가되는 파라미터가 거의 없다.
2.2 Auxiliary training objectives
■ 비지도 학습에 보조 목적 함수를 사용하여 성능 향상을 이룬 다양한 선행 연구가 존재한다. target task의 목적 함수에 보조적인 언어 모델링 목적 함수를 추가하여 시퀀스 레이블링 task에서 성능 향상을 입증한 연구도 있다.
■ 이 논문에서도 보조 목적 함수를 사용하여 학습을 진행하였지만, 비지도 사전 훈련(unsupervised pre-training)만으로도 target task에 관련된 여러 언어적인 정보들을 학습했음을 보여준다.
3. Framework
■ 훈련 과정은 두 가지 단계로 진행된다.
■ 먼저, 방대한 양의 텍스트 코퍼스를 기반으로 언어 모델을 학습한 다음(Unsupervised pre-training), 레이블이 지정된 데이터를 사용하여 파인튜닝을 진행한다(Supervised fine-tuning).
3.1 Unsupervised pre-training
■ 레이블이 없는 토큰 코퍼스 U={u1,⋯,un}이 주어졌을 때, 표준적인 언어 모델링 목적 함수를 사용하여 우도(likelihood)를 최대화한다.

■ 여기서 k는 context window의 크기(size)이며, 조건부 확률 P는 파라미터 Θ를 가진 신경망을 사용하여 모델링된다. 이 파라미터들은 확률적 경사 하강법(stochastic gradient descent)을 사용하여 훈련된다.
- 위의 목적 함수는 이전 k개의 단어(또는 토큰)이 주어진 상황에서 다음 단어 ui가 나올 확률을 최대화하는 것
- 즉, 문맥(uik,⋯,ui−1)을 보고 가장 자연스러운 다음 단어(ui)를 예측하도록 모델 파라미터 Θ를 학습시킨다.
■ GPT-1 논문에서는 언어 모델을 위해 트랜스포머 디코더의 다층 구조(multi-layer Transformer decoder)를 사용한다.
- 트랜스포머 인코더는 문장 전체를 보고 양방향으로 정보를 처리한다.
- 반면, 디코더는 미래 시점의 정보를 볼 수 없도록 마스크드 셀프 어텐션을 사용하기 때문에, '생성'에 있어 디코더 구조가 더 적합하다.
■ 이 모델은 입력 토큰들(논문에서는 input context vector으로 표현)에 대해 멀티 헤드 셀프 어텐션 연산을 적용하고, 그다음 포지션 와이즈 피드포워드 계층을 거쳐 타겟 토큰에 대한 분포를 출력한다. 이 과정을 수식으로 나타내면 다음과 같다.
- 여기서 U는 토큰들의 컨텍스트 벡터
- We는 임베딩 행렬, Wp는 위치 임베딩 행렬(position embedding matrix)이다.
- 즉, 단어의 의미(정확히는 단어의 의미를 수치화한 벡터)와 단어의 위치 정보를 더해서 초기 입력(h0)으로 사용한다.
- 초기 입력이 첫 번재 트랜스포머 디코더 블록의 입력으로 들어가서 h1을 출력하고, 이 h1이 다시 트랜스포머 블록의 입력으로 들어가서 h2를 출력한다.
- 이 과정을 n개의 트랜스포머 블록(레이어)를 통과할 때까지. 즉, hn을 출력할 때까지 반복한다.
- 트랜스포머 모델의 최종 출력 표현인 hn은 선형 변환 행렬(WTe)을 거치며, 소프트맥스 함수를 통과해 확률 분포 P(u)를 계산한다.
3.2 Supervised fine-tuning
■ 위의 목적 함수로 모델을 훈련시킨 후, 파라미터들을 지도 학습 기반의 target task에 맞게 조정(adapt)한다.
■ 레이블이 있는 데이터셋 C를 가정하며, 각 데이터는 입력 토큰 시퀀스 x1,⋯,xm과 레이블 y로 구성된다.
■ 이 입력들은 사전 학습된 모델을 거치게 된다. 마지막 트랜스포머 블록에서 출력된 값이 hml이라고 했을 때,
■ hml 값은 y를 예측하기 위해 파라미터 Wy를 갖는 선형 출력 계층(linear output layer)의 입력으로 들어가며, 여기서 나온 출력값을 통해 최종적으로 y를 예측하게 된다.
- 이렇게 task에 output layer 하나만 추가하기 때문에, 모델 구조를 거의 바꿀 필요가 없다.
- 논문에 따르면, 파인튜닝 동안 추가되는 파라미터는 Wy와 3.3에 나오는 구분자 토큰(delimiter tokens)을 위한
임베딩뿐이라고 한다.
■ hml값이 Wy를 만나 소프트맥스 함수를 통해 출력된 값이 다음과 같이 확률 분포 P(y∣x1,⋯,xm)이라고 하자.
■ 위의 값은 다음과 같이 목적 함수를 최대화하는 방향으로 학습된다.
■ 이 L2(C)가 바로 파인 튜닝의 목적 함수(레이블된 데이터가 있는 지도 학습 task의 목적 함수)이다.
■ 저자들은 L2(C)에 보조 목적 함수(auxiliary objective)로 언어 모델링(language modeling) L1(C)을 추가한다. 그리고 보조 목적 함수L1(C)에 대한 가중치 λ를 두어 새로운 목적 함수 L3(C)를 만들고, 최종적으로 L3(C)를 최적화한다.
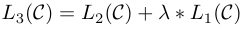
■ 이처럼 보조 목적 함수를 추가하는 이유는 크게 지도 학습 모델의 "일반화 성능 향상"과 "모델 학습의 수렴(convergence) 가속화"이다.
■ 방대한 텍스트 데이터로 사전 학습을 거친 모델도 특정 task를 위해 파인튜닝을 하는 과정에서 특정 패턴에만 의존하는 현상이 발생할 수 있다.
■ 특히, 지도 학습 데이터가 적을수록 이러한 현상은 더욱 쉽게 발생하며, 이는 모델이 unseen data에 대한 성능 저하로 이어진다. 이를 두고 일반화(generalization)성능이 좋지 않다고 표현한다.
- 예를 들어, task가 감성 분류라고 했을 때, '최고'라는 단어가 포함된 문장이 긍정 샘플에만 집중적으로 나타난다면, 모델은 다른 문맥은 무시하고 단순히 '최고 → 긍정'이라는 단순한 패턴만 학습할 수 있다.
- 이때, 언어 모델링(L1)을 보조 목적 함수로 추가하면, 모델은 감성 분류를 수행하는 동시에 주어진 문맥에서 다음 단어를 예측하는 언어 모델링 task도 함께 수행하게 된다.
- 이 과정에서 모델은 '최고'라는 단어뿐만 아니라 언어적인 측면(예: 단어 간의 관계, 문법 구조 등)을 학습하게 된다.
- 그 결과, 특정 키워드에만 의존하지 않고 더 유연하게 언어를 이해하게 되어, 처음 보는 데이터에 대해서도 더 나은 예측을 수행하는 일반화 성능 향상을 기대할 수 있다.
■ 학습 수렴 가속화도 이와 비슷한 논리이다. 예를 들어 하나의 손실 함수만 사용한다고 해보자. 보통 손실 함수를 사용해 만드는 손실 공간(loss landscape)은 다음 그림처럼 매우 복잡하다.

■ 손실 공간에는 local minimum과 saddle point가 포함되어 있기 때문에, global minimum을 찾아가는 과정에서 특정 지점에 갇히기 쉽다.
■ 보조 손실 함수를 추가한다면, 여기서 나오는 loss를 통해 업데이트하여 손실 공간을 더 평탄하게 만드는 효과가 있다.
- 예를 들어 메인 손실 함수의 경사가 좋지 않은 방향을 가리키더라도 보조 손실 함수가 제공하는 경사가 올바른 방향으로 이끌어 준다면,
- 복잡한 손실 공간을 더 쉽게 탈출할 수 있기 때문에 global minimu에 더 빠르고 안정적으로 도달할 수 있다. 이는 곧 모델의 수렴 속도를 높이는 결과로 이어진다.
3.3 Task-specific input transformations
■ 텍스트 분류와 같은 task는 linear output layer 하나만 추가하는 방식으로 파인튜닝이 가능하다.
■ 그러나 question answering이나 textual entailment같은 특정 task들은 문장 쌍, 또는 (문서, 질문, 답변)의 3중 구조와 같이 구조화된 입력을 가지는 task에서는 텍스트 분류처럼 파인튜닝을 할 수 없다.
■ 논문에서 제안한 사전 학습된 모델은 연속적인 텍스트 시퀀스로 훈련되었기 때문에, 구조화된 입력 형태를 가지는 task에 적용하기 위해서는 입력 형태를 수정해야 한다.
■ 입력 형태를 변환하기 위해 "travelsal-style"라는 방법을 사용하는데, 이는 구조화된 입력을 사전 학습된 모델이 처리할 수 있도록 정렬된 시퀀스로 변환하는 방법이라고 한다. 이 내용에 대한 시각적인 예시는 아래의 Figure 1.에서 볼 수 있다.

■ 위의 그림을 보면, 모든 입력 변환에는 무작위로 초기화된 시작 토큰 <s>과 종료 토큰 <e>가 포함되는 것을 볼 수 있다.
- <s>와 <e>는 문장의 시작과 끝을 알려주기 위해 사용하는 것이다.
■ Textual entailment task는 premise p와 hypothesis h 토큰 시퀀스를 연결하고, 그 사이에 구분자 토큰($)을 넣는다.
■ Similarity task의 경우, 비교되는 두 문장에는 정해진 순서가 없다.
■ 그래서 위의 Figure 1.처럼 가능한 두 가지 문장 순서(두 문장 사이에 구분자 토큰 포함)를 모두 포함하여 사전 학습된 모델이 처리할 수 있는 형태인 정렬된 시퀀스 형태로 변환해준다.
■ 그다음, 두 문장을 각각 독립적으로 처리하여 두 개의 시퀀스 표현을 각각 hml을 생성한다.
■ 이 두 개의 시퀀스 표현은 선형 출력 레이어(linear output layer)에 입력되기 전에 요소별(element-wise)로 더해진다.
■ Question Answering and Commonsense Reasoning task에서는 context document z, question q, 그리고 가능한 모든 답변들의 집합인 {ak}가 주어진다.
■ 여기서는 z와 q를 {ak}와 연결하고, 그 사이에 구분자 토큰을 추가하여 [z;q;$;ak] 형태를 만든다.
■ 이러한 형태를 갖는 각 시퀀스는 독립적으로 각각 처리한 다음, 가능한 답변들에 대한 분포를 생성하기 위해 소프트맥스 레이어에 통과시킨다.
- 문서와 질문을 주고 가능한 여러 답변 후보 중 정답을 고르기 위해, 각 답변 후보에 대한 점수(로짓)를 계산하고 소프트맥스로 확률화를 시키는 것이다.
4. Experiments
4.1 Setup
4.1.1 Unsupervised pre-training
■ 언어 모델을 훈련시키기 위해 BookCorpus 데이터셋을 사용한다. 이 데이터셋은 모험, 판타지, 로멘스 등 다양한 장르의 7,000 권이 넘는 도서들로 구성되어 있다.
■ BookCorpus는 길고 연속적인 문장을 가지고 있기 때문에 모델이 장거리 정보(long-range information)에 기반하여 학습하는 것을 가능하게 한다.
- ELMo에서 사용한 1B Word Benchmark의 경우 크기는 비슷하지만, 텍스트가 문장 단위로 뒤섞여 있어 BoockCorpus처럼 장거리 구조를 가질 수 없다.
4.1.2 Model specifications
■ 모델 구조는 트랜스포머 디코더 블록을 12개 쌓은 형태이며, 마스크드 셀프 어텐션(어텐션 헤드는 12개, 768 차원)을 사용하고, 3072 차원의 포지션-와이지 피드포워드 네트워크를 사용한다.
■ 사전 학습 과정에서 옵티마이저로 Adam을 사용하였으며, 학습률은 처음 2,000번의 업데이트 동안 0부터 2.5e-4까지 선형적으로 증가시켰고, 이후 코사인 스케줄을 사용하여 0으로 감소시켰다.
■ 512 토큰 길이의 연속적인 시퀀스를 무작위로 샘플링한 64개 미니 배치로 100 에폭동안 훈련을 진행한다.
- 즉, 한 번에 64 x 512개의 토큰을 처리한다.
■ 모델 전반에 걸쳐 층 정규화를 광범위하게 사용하기 때문에 N(0.02)로 가중치를 초기화하는 것만으로도 충분하다고 한다
■ 40,000개의 병합 규칙을 가진 BPE(Byte-Pair Encoding)을 사용하여 단어 집합(vocabulary)을 생성하였고, 정규화를 위해 잔차, 임베딩, 어텐션에 0.1 비율의 드롭아웃을 적용했으며, L2 regularization 0.01을 사용한다.
■ 활성화 함수로는 GELU(Gaussian Error Linear Unit)를 사용한다.
■ 트랜스포머 논문에서 제안된 sinusoidal 방식 대신 학습 가능한 위치 임베딩(learned position embeddings)을 사용한다.
- 단어의 위치 정보를 고정된 함수(sinusoidal)가 아닌, 학습을 통해 스스로 파악하게 한 것이다.
4.1.3 Fine-tuning details
■ 파인튜닝 과정에서도 사전 학습의 하이퍼파라미터 설정을 사용하지만, 경우에 따라 다른 설정값을 사용한다.
■ 분류기(classifier). 즉, linear output layer에는 0.1 비율의 드롭아웃을 추가한다.
■ 대부분의 task에서 학습률 6.25e-5와 배치 크기 32를 사용한다.
■ 모델이 매우 빠르게 파인튜닝되어, 대부분의 경우 3 에폭의 훈련만으로 충분하다.
■ 훈련 과정의 0.2% 동안 warmup을 적용하는 선형 학습률 감쇠 스케줄(linear learning rate decay schedule)을 사용한다.
■ auxiliary objective의 가중치인 λ는 0.5로 설정한다.
4.2 Supervised fine-tuning
■ NLI, QA, semantic similarity, text classification를 포함한 다양한 지도 학습 task에 대해 진행한다. 각각의 task에 대한 데이터셋은 아래의 Table 1.과 같다.

4.2.1 Natural Language Inference
■ recognizing textual entailment으로도 알려진 자연어 추론(NLI) task는 한 쌍의 문장을 읽고, 그들 사이의 '관계'가 귀결(entailment), 모순(contradiction), 중립(neutral) 중 어떤 것인지 판단한다.
■ 이 task가 어려운 이유는 단순히 단어만 봐서 풀 수 있는 문제가 아니고 문장 구조, 상식, 모호함 등의 복합적인 언어 이해 능력이 필요하기 때문이다.
■ image captions (SNLI), transcribed speech, popular fiction, government reports (MNLI), Wikipedia articles (QNLI), science exams (SciTail) or news articles (RTE) 등 다양한 도메인에서 추출한 데이터셋에서 모델에 대해 평가하였다.
■ 이에 대한 결과는 아래의 Table 2.와 같이 5개 데이터셋 중 RET를 제외한 4개에서 베이스라인 성능을 크게 넘어섰다.

4.2.2 Question answering and commonsense reasoning
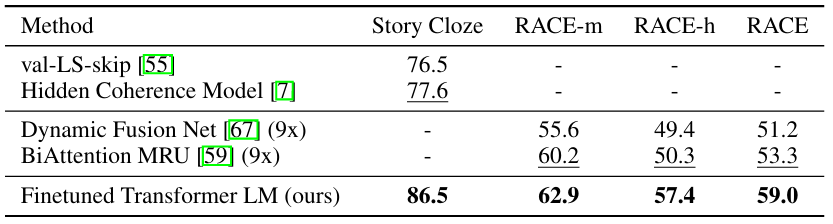
■ RACE 데이터셋을 사용했는데, 이 코퍼스는 CNN이나 SQuAD같은 데이터셋보다 더 많은 추론형 질문을 포함하고 있어, 장거리 문맥(long-range contexts)을 처리하도록 훈련된 모델을 평가하기에 적합하다.
■ 추가적으로 Story Cloze Test에서도 평가를 수행하는데, 이는 여러 문장으로 이루어진 이야기의 올바른 결말을 두 개의 보기 중에 선택하는 task이다.
■ 이에 대한 결과는 아래의 Table 3.과 같이 모든 Task에서 SOTA를 달성했다. 이는 모델이 장거리 문맥을 효과적으로 다룰 수 있는 능력이 있음을 보여주는 결과이다.
4.2.3 Semantic Similarity
■ 두 문장 간의 유사도를 구하는 Semantic Similarity는 두 문장이 의미적으로 동등한지 아닌지를 예측하는 task이다.
■ 이 task가 어려운 점은 같은 단어가 아니더라도 의미가 동일할 수 있고, 부정문을 이해해야 하며, 문장 구조에 따른 의미 변화를 이해해야 하기 때문이다.
■ Microsoft Paraphrase corpus (MRPC), the Quora Question Pairs (QQP), Semantic Textual Similarity benchmark (STS-B) 데이터셋을 사용하였으며, 이에 대한 결과는 아래의 Table 4.와 같이 3개의 task 중 2개에서 SOTA를 달성했다.

4.2.4 Classification
■ 한 문장이 문법적으로 옳은지에 대한 전문가의 판단과 모델의 언어적 편향(linguistic bias)을 테스트하는 CoLA와 이진 분류 task인 SST-2에 대해 모델을 평가한다.
■ 논문에서 제안한 접근법은 12개의 데이터셋 중 9개에서 SOTA를 달성했으며, 앙상블 모델들을 능가한 경우도 있다.
■ 또한, 작은 데이터셋인 STS-B부터 가장 큰 데이터셋인 SNLI에 이르기까지, 다양한 크기의 데이터셋 전반에 걸쳐 잘 작동한다는 것을 확인할 수 있다.
5. Analysis
5.1 Impact of number of layers transferred
■ 저자들은 비지도 사전 학습에서 파인튜닝 시 전이되는 레이어의 수를 변화시켰을 때의 영향을 관찰하였다.
■ 이는 사전 학습된 모델의 모든 층이 모두 성능 향상에 유용한지, 아니면 특정 층만 유용한지를 확인하기 위해서이다.
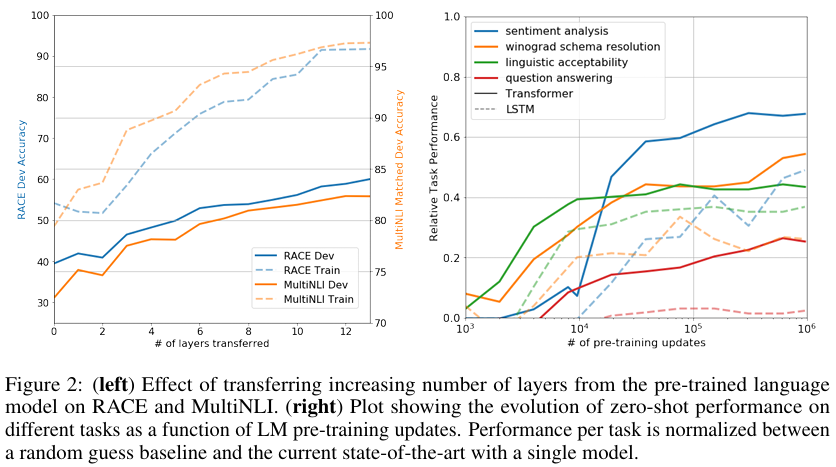
■ 위의 왼쪽 그림은 전이된 레이어의 수에 따른 MultiNLI와 RACE에서의 성능을 나타낸다.
■ 임베딩만 전이(0개 층을 전이)해도 성능이 향상되며, 전이하는 트랜스포머 레이어가 증가할수록 정확도가 향상하는 것을 볼 수 있다. 이는 사전 학습된 모델의 각 레이어가 target task를 해결하는데 유용하다는 것을 의미한다.
■ 즉, 낮은 층에서는 저수준의 정보(단어, 구문 구조 등)를 학습할 가능성이 높고, 높은 층으로 갈수록 고수준의 복잡한 정보(문맥, 의미 변화 등)를 학습할 가능성이 높다.
5.2 Zero-shot Behaviors
■ 논문에서는 왜 트랜스포머를 이용한 언어 모델 사전 학습이 효과적인지 그 이유를 찾고자, 다음과 같은 가설을 세웠다.
■ 가설은 기저의 생성 모델(generative model)이 자신의 언어 모델링 능력을 향상시키기 위해 많은 task들을 수행하는 법을 학습하며, 트랜스포머의 어텐션 메커니즘의 구조가 LSTM 구조보다 전이에 적합하다는 것이다.
■ 가설을 검증하기 위해, 파인튜닝을 전혀 하지 않은 사전 학습 모델(unsupervised pre-trained model)만으로 각 task에 맞춰 간단한 휴리스틱을 사용하여 정답을 예측하게 해서 제로샷(zero-shot) 성능을 측정하였다.
■ 즉 GPT 모델이 파인튜닝 없이, 즉 사전 학습만으로도 task를 해결하는 능력을 이미 가지고 있다." 라는 가설을 확인하려고 한 것이다.
■ 각 데이터셋에 사용한 휴리스틱한 방법은 다음과 같다.
- CoLA (문법성 판단)
-- 주어진 문장에 대해 각 토큰이 나타날 로그 확률을 계산
-- 이 확률들의 평균을 구하여, 그 문장에 대한 점수를 매김
-- 임곗값보다 높으면 문법적, 낮으면 비문법적이라 판단
- SST-2 (감성 분석)
-- 문장 끝에 'very'라는 단어를 붙이고 다음에 올 단어를 예측
-- 단, 예측 가능한 단어를 'positive'와 'negative' 두 개로 설정
-- 모델이 어느 단어의 확률을 더 높게 예측하는지 확인
- RACE (4지선다)
-- 모델이 가장 높은 평균 토큰 로그 확률을 부여하는 보기를 정답으로 선택.
- Winograd Schema (대명사 판별)
-- 문장 내의 대명사를 가능한 지시 대상으로 각각 교체(예: it을 the cat으로 교체)
-- 교체 후 모델이 더 높은 평균 토크 로그 확률을 부여하는 쪽을 정답으로 예측
■ 제로샷 성능의 결과는 아래의 오른쪽 그림과 같다. 실선은 트랜스포머, 점선은 LSTM으로 수행한 결과이다.
■ 결과를 보면, 사전 학습이 진행될수록(학습 업데이트 수가 늘어날수록) 제로샷 성능이 꾸준히 향상되는 것을 확인할 수 있다.
■ 이는 모델이 사전 학습 과정에서 이미 다양한 task를 푸는 능력을 내재화하고 있음을 의미한다.
■ 또한, 트랜스포머에 비해 LSTM이 제로샷 성능에서 더 큰 변동성을 보이는데, 이는 트랜스포머 아키텍처의 귀납적 편향 (inductive bias)이 전이에 더 적합하다는 것을 보여준다.
참고) [TIL] Inductive Bias 란? Transformer는 Inductive Bias이 부족하다라는 의미는 무엇일까? | by daewoo kim | Medium
5.3 Ablation studies
■ 세 가지 abalation study를 수행한다.
■ 첫 번째는 파인튜닝 동안 보조 목적 함수(LM 목적 함수)의 유무에 따른 성능이다.
■ Table 5.를 보면, 보조 목적 함수를 제거했을 때, 데이터가 많은 데이터셋인 NLI, QQP에서 성능이 하락한 것을 확인할 수 있다. 보조 목적 함수를 추가하는 것은 큰 데이터셋에는 효과적이지만, 작은 데이터셋은 그렇지 않다는 경향이 나타난다.
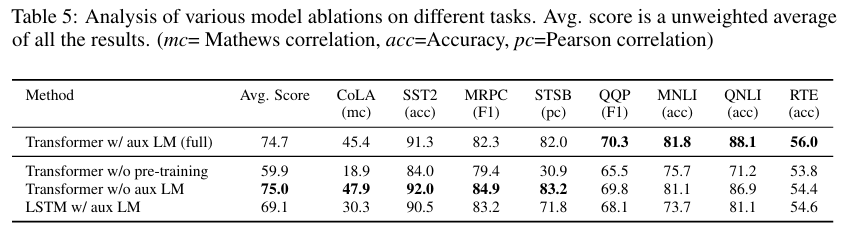
■ 두 번째는 트랜스포머의 효과를 분석하기 위해, 트랜스포머 대신 LSTM으로 교체하여 성능을 비교하였다. 그 결과, 성능이 하락하는 것을 확인할 수 있다.
- LSTM은 오직 MRPC 데이터셋에서만 트랜스포머를 능가한다.
■ 마지막으로 사전 학습의 효과를 분석하기 위해, 사전 학습 없이 target task에 바로 학습을 수행하였다. 그 결과, 모든 task에서 성능이 떨어진 것을 확인할 수 있다.
■ 즉, abalation study를 통해 큰 데이터셋에는 보조 목적 함수를 추가하는 것이 성능을 안정시킬 수 있으며, 트랜스포머 디코더 구조가 핵심적인 역할을 하며, 사전 학습은 필수라는 것을 알 수 있다.
'자연어처리' 카테고리의 다른 글
| GPT-2(Language Models are Unsupervised Multitask Learners) (2) (0) | 2025.06.12 |
|---|---|
| GPT-2(Language Models are Unsupervised Multitask Learners) (1) (0) | 2025.05.29 |
| RoBERTa: A Robustly Optimized BERT Pretraining Approach (1) (0) | 2025.05.26 |
| BERT(Bidirectional Encoder Representations from Transformers) (3) (0) | 2025.05.18 |
| BERT(Bidirectional Encoder Representations from Transformers) (2) (0) | 2025.05.17 |



