1. 리스트
■ 여러 개의 값을 저장하고 처리해야 하는 경우가 많다. 특히, 값들 사이에 순서가 있을 경우 리스트를 사용하는 것이 유용하다.
■ 리스트는 항목(item)들을 저장하는 일종의 컨테이너로, 항목들은 순서를 가진 채 저장되며 콤마(,)로 구분된다.
- 리스트 안에 저장된 데이터를 항목(item) 또는 요소(element)라고 한다.
■ 리스트는 항목이 추가되면 자동으로 크기가 늘어나고, 항목이 제거되면 자동으로 크기가 줄어든다. 또한, 리스트에는 어떠한 자료형도 항목(원소)으로 저장할 수 있으며, 모든 항목이 동일한 자료형일 필요도 없다.
1.1 리스트를 만드는 방법
■ 파이썬에서 리스트는 대괄호 []를 사용하여 만들 수 있다.
■ 예를 들어, 10일 동안의 기온을 저장한다고 했을 때, 10개의 변수를 각각 만드는 것은 비효율적이다. 이런 경우에는 다음과 같이 여러 값을 하나에 저장할 수 있는 데이터 구조인 리스트를 사용하는 것이 적합하다.
day_1 = 10
day_2 = 13
day_3 = 11
...,
...,
day_9 = 14
day_10 = 12
temps = [10, 13, 11, 14, 15, 16, 17, 10, 14, 12]■ 비어 있는 리스트는 아래와 같이 list()로 생성할 수 있다.
a = list()
a
```#결과#```
[]
````````````1.2 리스트의 인덱싱과 슬라이싱
1.2.1 리스트의 인덱싱
■ 리스트에서 하나의 항목에 접근하는 방법은 항목의 인덱스를 사용하는 것이다. 여기서 인덱스(index)란 리스트에서의 항목의 번호(위치)이다.
■ 리스트의 인덱스도 문자열처럼 0부터 시작하며, 마찬가지로 음의 인덱스가 존재한다. 예를 들어 다음과 같은 리스트 temps가 있다고 했을 때, temps[0]은 리스트 temps의 첫 번째 항목을, temps[-1]은 리스트 temps의 마지막 항목을 반환한다.
temps = [10, 13, 11, 14, 15, 16, 17, 10, 14, 12]
print(temps[0], temps[-1])
```#결과#```
10 12
````````````■ 리스트안에 저장되는 데이터는 어떠한 자료형도 가능하다고 하였다. 즉, 다음과 같이 리스트의 항목으로 리스트가 저장될 수 있다.
temps = [10, 13, 11, 14, ['11', '12', '13'], 15]■ 위의 예에서 항목 중 자료형이 리스트인 항목에 접근하려면 다음과 같이 temps[-2]를 통해 접근할 수 있다.
temps[-2]
```#결과#```
['11', '12', '13']
````````````■ 이때, 리스트 temps에 포함된 ['11', '12', '13'] 리스트에서 '11' 값을 다음과 같이 인덱싱을 사용해 접근할 수 있다.
temps[-2][0]
```#결과#```
'11'
````````````
temps[-2][-3]
```#결과#```
'11'
````````````■ ['11', '12', '13'] 리스트에서 첫 번째 항목인 '11'에 접근하기 위해 [0]을 붙여준 것이다. 이는 ['11', '12', '13']도 리스트이기 때문에 가능하다.
- 리스트 ['11', '12', '13']가 아닌 튜플 ('11', '12', '13')이어도 동일한 접근 방식을 사용할 수 있다.
1.2.2 리스트의 슬라이싱
■ 문자열과 마찬가지로 리스트에서도 다음과 같이 슬라이싱 기법을 적용할 수 있다.
temps[-3:]
```#결과#```
[14, ['11', '12', '13'], 15]
````````````
temps[:4]
```#결과#```
[14, ['11', '12', '13'], 15]
````````````■ 슬라이싱을 할 때, 단계(step)을 지정할 수도 있다.
리스트[start : end : step]
a = [1, 2, 3, 4, 5]
a[::2]
```#결과#```
[1, 3, 5]
````````````■ 위의 결과는 리스트 전 범위에 대해 step = 2를 적용한 결과이다. 인덱스를 2씩 증가하면서 항목들을 추출한다.
■ 음의 인덱스를 이용하여 다음과 같이 리스트를 역순으로 만들 수도 있다.
a[::-1]
```#결과#```
[5, 4, 3, 2, 1]
````````````■ step = -1이므로 리스트의 끝에서부터 시작 위치까지 역순으로 항목들을 추출한다.
1.3 리스트 연산
1.3.1 +, *
■ 리스트 역시 문자열처럼 '+' 연산자를 사용해서 서로 다른 리스트를 연결할 수 있고, '*' 연산자를 사용해서 리스트를 반복할 수 있다.
a, b = [1, 2, 3], [4, 5, 6]
print(a + b)
print(a*3)
```#결과#```
[1, 2, 3, 4, 5, 6]
[1, 2, 3, 1, 2, 3, 1, 2, 3]
````````````1.3.2 len
■ 리스트의 길이(크기)를 구하기 위해서는 다음과 같이 len 함수를 사용하면 된다.
■ len 함수를 리스트에 사용할 경우, 리스트 내의 항목 개수를 반환한다.
len(a)
```#결과#```
3
````````````■ len 함수는 문자열, 리스트 외에도 튜플, 딕셔너리에도 사용할 수 있다.
1.3.3 del
■ del 함수는 다음과 같이 지정한 인덱스에 해당하는 항목을 삭제하는 함수이다. del 함수는 파이썬이 자체적으로 가지고 있는 삭제 함수이다.
del a[2]
a
```#결과#```
[1, 2]
````````````■ 슬라이싱 기법을 사용하여 여러 개의 항목을 한꺼번에 삭제할 수도 있다.
del b[1:]
b
```#결과#```
[4]
````````````1.3.4 max, min, sum
■ max(), min(), sum() 함수도 del 함수처럼 파이썬이 자체적으로 가지고 있는 내장 함수들이다.
■ max(), min()을 리스트에 사용하면 다음과 같이 리스트의 항목 중 가장 큰 값과 가장 작은 값을 반환할 수 있다.
a, b = [1, 2, 3], [4, 5, 6]
c = a + b
print(max(c), min(c), sum(c))
```#결과#```
6 1 21
````````````■ max(), min(), sum() 함수를 리스트에 사용할 때 주의할 점이 있다. 바로 리스트 내 항목들이 모두 동일한 타입이어야 한다는 것이다. 만약, 항목들의 타입이 서로 다르면 아래와 같은 에러가 발생한다.
temps = [10, 13, 11, 14, ['11', '12', '13'], 15]
max(temps)
```#결과#```
TypeError: '>' not supported between instances of 'list' and 'int'
````````````
sum(temps)
```#결과#```
TypeError: unsupported operand type(s) for +: 'int' and 'list'
````````````1.3.5 join
■ 아래와 같이 join 함수를 사용하여 특정 구분자로 리스트의 항목들을 연결할 수 있다.
line = ['to', 'be', 'or', 'not', 'to', 'be.']
print(''.join(line))
print(' '.join(line))
print(', '.join(line))
```#결과#```
tobeornottobe.
to be or not to be.
to, be, or, not, to, be.
````````````1.4 리스트 관련 함수(메서드)
■ 문자열과 마찬가지로 리스트 변수 이름 뒤에 점(.)을 붙여 리스트의 메서드를 사용할 수 있다.
1.4.1 append
■ append() 함수는 리스트의 맨 끝에 새로운 리스트의 항목을 추가하는 함수로, 추가할 새로운 항목은 어떠한 자료형이든 상관없이 추가할 수 있다.
c.append(10)
c
```#결과#```
[1, 2, 3, 4, 5, 6, 10, 'A']
````````````
c.append([1, '2'])
c
```#결과#```
[1, 2, 3, 4, 5, 6, 10, 'A', [1, '2']]
````````````1.4.2 insert
■ insert() 함수는 지정된 위치에 항목을 추가하기 위해 사용하는 함수이다. insert(a, b)와 같은 형태로 사용하는데, 이는 리스트의 'a 번째 위치 (앞)에' '값 b를 삽입한다'는 의미를 갖는다.
a = [1, 2, 3]
a.insert(1, 'Apple')
a
```#결과#```
[1, 'Apple', 2, 3]
````````````■ a.insert(1, 'Apple')은 a[1] 위치에 값 'Apple'을 삽입하라는 의미이다. 1번 인덱스에 삽입되는 새로운 항목 'Apple'을 위한 공간을 만들기 위해 1번 인덱스 이후의 모든 항목들이 한 위치 아래로 이동하게 된다.
- 기존의 인덱스 1에 있는 항목인 2 앞에 'Apple'을 삽입한 것으로 볼 수 있다.
a.insert(0, 10)
a
```#결과#```
[10, 1, 'Apple', 2, 3]
````````````■ 0번 인덱스에 새로운 항목을 삽입하기 위해 0번 인덱스 이후의 모든 항목들이 한 위치 아래로 이동하는 것을 볼 수 있다.
■ 그리고 아래와 같이 음의 인덱스를 사용할 수도 있으며, 다양한 자료형을 삽입할 수 있다.
a.insert(-1, [1, 2, 3])
a
```#결과#```
[10, 1, 'Apple', 2, [1, 2, 3], 3]
````````````■ a의 -1번 인덱스 앞에 [1, 2, 3]이라는 항목을 삽입한 결과이다.
1.4.3 remove
■ 리스트에서 항목을 삭제하는 것도 가능하다. 특정 항목을 리스트에서 삭제하는 방법에는 remove와 pop 2가지가 있다.
■ remove(x)는 리스트에서 첫 번째로 등장하는 항목 x를 삭제하는 함수이다. 삭제된 값은 반환하지 않는다.
a
```#결과#```
[10, 1, 'Apple', 2, [1, 2, 3], 3, 1]
````````````
a.remove(1)
```#결과#```
[10, 'Apple', 2, [1, 2, 3], 3, 1]
````````````- a 라는 리스트에는 정수 1이 두 번 등장한다. 여기에 remove(1)을 적용하니 처음에 등장하는 정수 1만 제거하는 것과 삭제된 값은 반환하지 않는 것을 볼 수 있다.
1.4.4 pop
■ pop(x)는 리스트의 x번째 인덱스에 위치한 항목을 리턴하고 해당 항목은 삭제하는 함수이다.
a
```#결과#```
[10, 'Apple', 2, [1, 2, 3], 3, 1]
`````````````
a.pop(3)
```#결과#```
[1, 2, 3]
`````````````
a
```#결과#```
[10, 'Apple', 2, 3, 1]
`````````````1.4.5 clear
■ clear() 함수는 리스트를 다음과 같이 공백 리스트로 만들기 위해 사용한다.
c
```#결과#```
[1, 2, 3, 4, 5, 6, 10, 'A', [1, '2']]
````````````
c.clear()
c
```#결과#```
[]
````````````1.4.6 count
■ count(x)는 리스트 안에 특정 항목 x가 몇 개 존재하는지 그 개수를 반환하는 하뭇이다.
■ 아래의 예시에서 리스트 a 안에 정수 1이 두 번 포함되어 있음음 확인할 수 있다.
a
```#결과#```
[10, 1, 'Apple', 2, [1, 2, 3], 3, 1]
````````````
a.count(1)
```#결과#```
2
````````````1.4.7 sort
■ sort() 함수는 리스트의 항목을 오름차순으로 정렬해주는 함수이다.
■ sort() 함수는 제자리(in-place)에서 리스트를 정렬하기 때문에 sort()가 호출되면 대입문(할당문)을 사용하지 않아도 원본 리스트가 변경된다. 이는 리스트가 가변 객체이기 때문이다.
■ 아래와 같이 숫자 또는 문자를 오름차순으로 정렬할 수 있다.
a = [3, 2, 1, 4]
b = ['c','a','d','b']
a.sort()
a
```#결과#```
[1, 2, 3, 4]
````````````
b.sort()
b
```#결과#```
['a', 'b', 'c', 'd']
````````````■ 역순(내림차순)으로 정렬하려면 키워드 인수인 reverse를 다음과 같이 True로 설정하면 된다.
a.sort(reverse=True)
a
```#결과#```
[4, 3, 2, 1]
````````````
b.sort(reverse=True)
b
```#결과#```
['d', 'c', 'b', 'a']
````````````cf) sorted
■ sorted() 함수는 파이썬에 내장된 함수이다. 리스트에 사용하면, 크기순으로 정렬된 새로운 리스트를 반환한다. 이때, 원래의 리스트는 수정되지 않는다.
a = [3, 2, 1, 4] # 원본 리스트
new_a = sorted(a) # 오름차순 정렬
new_a2 = sorted(a, reverse=True) # 내림차순 정렬
## 원본 리스트
a
```#결과#```
[3, 2, 1, 4]
````````````
## 오름차순 정렬
new_a
```#결과#```
[1, 2, 3, 4]
````````````
## 내림차순 정렬
new_a2
```#결과#```
[4, 3, 2, 1]
````````````1.4.8 reverse
■ reverse() 함수는 리스트를 역순으로 뒤집어 준다. 이는 역순으로 정렬하는 것이 아니라, 현재의 리스트를 그대로 거꾸로 뒤집는 것이다.
a
```#결과#```
[10, 'Apple', 2, 3, 1]
````````````
a.reverse()
a
```#결과#```
[1, 3, 2, 'Apple', 10]
````````````1.4.9 index
■ index() 함수는 리스트에서 특정한 항목의 위치(인덱스)를 반환하는 함수이다.
a.index('Apple')
```#결과#```
2
````````````
a.index([1, 2, 3])
```#결과#```
4
````````````■ 만약 값이 리스트에서 한 번 이상 등장한다면 (리스트 안에 특정 값이 중복해서 존재한다면), 가장 처음 등장하는 값에 대한 인덱스를 반환한다.
a.append(1)
a
```#결과#```
[10, 1, 'Apple', 2, [1, 2, 3], 3, 1] # 1이 두 번 등장
````````````
a.index(1)
```#결과#```
1
````````````cf) 아래와 같이 in 연산자를 사용하여 특정 항목이 리스트에 존재하는지 확인할 수도 있다.
for i in a:
print(i, end=' ')
```#결과#```
10 Apple 2 3 1
````````````
if 'Apple' in a:
print('A')
```#결과#```
A
````````````1.4.10 extend
■ extend(x)에서 x는 리스트만 올 수 있다. extend() 함수는 리스트의 끝 부분에 새로운 항목으로 리스트 항목을 삽입하는 함수이다.
new_a.extend(new_a2)
```#결과#```
[1, 2, 3, 4, 4, 3, 2, 1]
````````````■ extend() 함수 대신 아래와 같이 복합 대입 연산자를 사용해도 동일한 결과를 얻을 수 있다.
new_a += [10, 11, 12]
```#결과#```
[1, 2, 3, 4, 4, 3, 2, 1, 10, 11, 12]
````````````1.5 리스트 비교
■ 비교 연산자 ==, !=, >, <를 사용해서 2개의 리스트를 비교할 수 있다. 단, 리스트를 비교하려면 2개의 리스트가 동일한 자료형의 항목들을 가지고 있어야 한다.
■ 리스트를 비교할 때, 먼저 각 리스트의 첫 번째 항목들을 비교한다. 만약, 첫 번째 항목의 비교에서 False가 나오면 더 이상의 비교는 없고 False가 출력된다.
■ 첫 번째 항목의 비교에서 True가 나오면, 다음 항목인 두 번째 항목을 비교하게 된다. 마찬가지로 True이면 다음 항목인 세 번째 항목을 비교하고, False이면 False를 출력한다.
■ 이 과정은 중간에 False가 나오지 않는 한, 리스트의 모든 항목이 비교될 때까지 동일한 방식으로 반복된다.
■ 리스트 안의 모든 항목을 비교하여 모두 True가 나오면 전체 결과는 True가 된다.
■ 예를 들어서 다음과 같이 모든 항목이 동일한 list1과 list2를 == 연산자를 이용하여 비교한다면, 결과는 True가 되고
list1 = [1, 2, 3]
list2 = [1, 2, 3]
list3 = [4, 5, 6]
list1 == list2
```#결과#```
True
````````````
list1 != list3
```#결과#```
True
````````````■ 서로 다른 항목을 가지고 있는 list1과 list3을 != 연산자를 이용하여 비교한다면, 결과는 True가 된다. 반대로 list2와 list3을 == 연산자로 비교한다면 결과는 False가 된다.
list2 == list3
```#결과#```
False
````````````■ >, < 같은 연산자도 각 리스트의 첫 번째 원소부터 차례대로 비교한다.
- 두 리스트 list1, list2를 비교할 때, list1[0]과 lits2[0]을 비교한다.
- 비교 연산자가 >라면 list1[0] > list2[0]가 True라면 두 번째 항목을 비교하고 False이면 False를 출력한다.
- < 연산자도 마찬가지이다.
list1 < list2
```#결과#```
False
````````````
list1 < list3
```#결과#```
True
````````````
list3 > list2
```#결과#```
True
````````````1.5 리스트 복사
■ 다음과 같이 리스트를 temps라는 변수에 할당한다고 하자.
temps = [10, 13, 11, 14, 15, 16]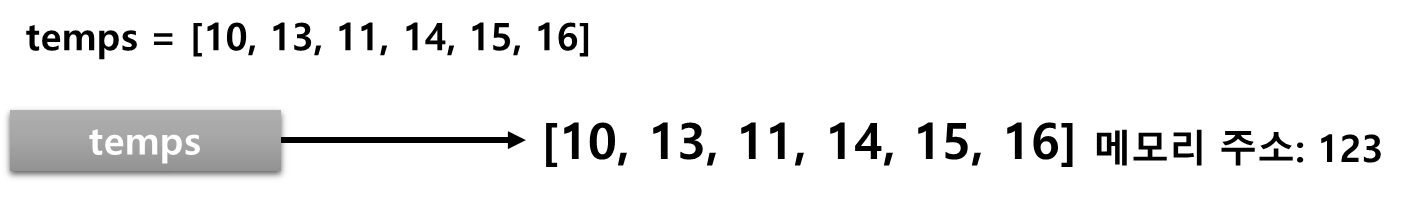
■ 리스트 변수 temps에 리스트가 저장되는 것이 아니다. 리스트는 다른 곳에 저장되고 리스트의 참조값(reference)만 변수 temps에 저장되는 것이다.
- 참조값은 메모리에서 리스트 객체의 위치라고 생각하면 된다.
■ temps 리스트를 복사하기 위해 아래와 같은 문장을 실행한다면,
values = temps■ 리스트는 복사되지 않는다. 위와 같은 문장은 단지, temps와 values가 모두 동일한 리스트를 가리키게 만드는 것이다.

■ values라는 변수명은 temps 리스트의 별칭이나 다름없다. 위와 같은 복사를 얕은 복사(shallow copy)라고 한다.
■ 이렇게 얕은 복사가 된 경우, values를 통하여 리스트 항목의 값을 변경하면 temps 리스트의 항목의 값도 변경된다.
print(temps);print()
values[2] = 100
print(values);print(values)
```#결과#```
[10, 13, 11, 14, 15, 16]
[10, 13, 100, 14, 15, 16]
[10, 13, 100, 14, 15, 16]
````````````■ 위와 같은 결과가 나오는 이유는 values와 temps가 같은 리스트를 참조(정확히는 같은 주소를 참조)하고 있기 때문이다. 즉, values의 특정 원소를 변경하는 것이 values가 가리키는 주소를 변경하지 않기 때문이다.
id(values) == id(temps)
```#결과#```
True
````````````■ 위의 얕은 복사와 달리, 리스트를 올바르게 복사하는 방법을 깊은 복사(deep copy)라고 한다.
■ 깊은 복사는 얕은 복사와 달리 똑같은 값을 가지는 완전히 독립된 새로운 객체를 생성한다.
■ 즉, 깊은 복사를 통해 만들어진 복사본은 원본과 동일한 값을 가지지만, 원본과 다른 메모리 주소를 참조하게 된다.

■ 깊은 복사를 하는 방법으로 list()를 사용하는 방법과 copy 모듈의 deepcopy 메서드를 사용하는 방법이 있다.
temps = [10, 13, 11, 14, 15, 16]
values = list(temps)
temps == values
```#결과#```
True
````````````
id(values) == id(temps)
```#결과#```
False
````````````
import copy
a = [1, 2, 3]
b = copy.deepcopy(a)
a == b
```#결과#```
True
````````````
id(a) == id(b)
```#결과#```
False
````````````cf) 공백 리스트를 생성하는 list() 함수는 다양한 용도로 사용할 수 있다. 예를 들어, range() 함수의 반환값을 모아서 리스트를 만들 때도 사용된다. 즉, 무언가를 리스트로 변환하고 싶으면 list() 함수를 사용하면 된다.
list(range(10))
```#결과#```
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
````````````1.6 리스트 컴프리헨션(list comprehensions)
■ 리스트 컴프리헨션(또는 리스트 함축)은 리스트의 항목을 생성하는 문장을 리스트 안에 넣는 방법으로 수학에서 집합을 정의하는 것과 유사하다.
[ 리스트 항목에 적용할 수식 for (변수 in 리스트) if (조건) ]
■ 예를 들어 다음과 같은 리스트 컴프리헨션은 range(10)에 속하는 모든 정수에 대하여 제곱을 계산하고, 그 결과를 리스트의 항목으로 사용하는 리스트를 생성한다.
[x*x for x in range(10)]
```#결과#```
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
````````````■ 리스트 컴프리헨션에는 if 문을 사용하여 조건을 추가할 수 있다. 예를 들어 range(10)에 속하는 모든 정수 중 짝수만을 제곱한 값을 항목으로 가지는 리스트를 생성하고 싶다면
[x*x for x in range(10) if x%2==0]
```#결과#```
[0, 4, 16, 36, 64]
````````````[x*x for x in range(10) if x%2==0 and x%3 ==0] # 필터 조건 2개
```#결과#```
[0, 36]
````````````■ 다음과 같이 if 문을 사용하여 조건 수식을 넣을 수도 있다.
[x*x if x%2==0 else 0 for x in range(10)]
```#결과#```
[0, 0, 4, 0, 16, 0, 36, 0, 64, 0]
````````````cf) [ 리스트 항목에 적용할 수식 for (변수 in 리스트) if (조건) ]에서 if (조건)은 일종의 필터 조건이며, 이 예에서 사용한 if 문은 조건 수식이다.
- [x*x for x in range(10) if x%2==0]는 0부터 9의 정수 중 짝수만 x*x를 적용하는 리스트 컴프리헨션이고
- [x*x if x%2==0 else 0 for x in range(10)]는 0부터 9의 정수 중 짝수에는 x*x를 적용하고, 홀수는 값을 0으로 변경하는 리스트 컴프리헨션이다.
- 즉, [x*x for x in range(10) if x%2==0]에는 if x%2==0이라는 일종의 필터 조건이 붙은 것이고
- [x*x if x%2==0 else 0 for x in range(10)]에는 x%2==0이면 x*x, 그렇지 않으면 0이라는 조건 수식이 붙은 것이다.
■ 리스트 컴프리헨션은 숫자에 대해서만 적용되는 것이 아니다. 어떤 자료형에 대해서도 리스트 컴프리헨션을 적용할 수 있다.
words = ['All', 'good', 'things']
c = [w[0] for w in words]
c
```#결과#```
['A', 'g', 't']
````````````■ 또한, 여러 개의 인수를 추가할 수도 있다. 아래의 예는 x와 y. 2개의 인수를 사용하는 리스트 컴프리헨션 예이다.
s = [x+y for x in ['a', 'b', 'c'] for y in ['x', 'y', 'z']]
s
```#결과#```
['ax', 'ay', 'az', 'bx', 'by', 'bz', 'cx', 'cy', 'cz']
````````````- 첫 번째 리스트의 'a'와 두 번째 리스트의 모든 요소가 더해져서 ['ax', 'ay', 'az']가 만들어지고
- 첫 번째 리스트의 'b'와 두 번째 리스트의 모든 요소가 더해져서 ['bx', 'by', 'bz'] 가 추가되고,
- 첫 번째 리스트의 'c'와 두 번째 리스트의 모든 요소가 더해져서 ['cx', 'cy', 'cz']가 추가된다.
■ 위의 예시는 아래의 중첩 for문과 동일하다.
s2 = []
for x in ['a', 'b', 'c']:
for y in ['x', 'y', 'z']:
s2.append(x+y)
s2
```#결과#```
['ax', 'ay', 'az', 'bx', 'by', 'bz', 'cx', 'cy', 'cz']
````````````■ 다음과 같은 활용도 가능하다.
list1 = [10, 20, 30, 40, 50]
list2 = [sum(list1[0:x+1]) for x in range(0, len(list1))]
list2
```#결과#```
[10, 30, 60, 100, 150]
````````````- 이 예는 i번째 항목이 원래 리스트의 0부터 i번째 항목까지의 합계인 리스트를 리스트 컴프리헨션으로 생성하는 예이다.
2. 2차원 리스트
2.1 2차원 리스트 만들기
■ 파이썬에서는 리스트를 2차원(=행렬)으로 만들 수 있다.
s = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
]
s
```#결과#```
[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
````````````■ 위의 예시에서 리스트 [1, 2, 3, 4]가 1행, 리스트 [5, 6, 7, 8]이 2행, 리스트 [9, 10, 11, 12]가 3행을 나타낸다.


■ 위의 2차원 리스트 s는 초깃값이 미리 결정된 상태이다. 즉, 정적으로 2차원 리스트를 생성한 것이다.
■ 동적으로 2차원 리스트를 생성하는 많은 방법 중 아래와 같이 행과 열의 값만 미리 지정한 다음, for 문을 이용하여 생성하는 방법이 있다.
rows, cols = 3, 4
s = []
for row in range(rows):
s += [[0]*cols]
s
```#결과#```
[[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]
````````````- cols = 4이므로 [0]*cols = [0, 0, 0, 0]이다. 이 결과를 리스트로 한 겹 더 감싸면 [ [0]*cols] = [[0, 0, 0, 0]]이 된다.
- rows = 3이므로 '공백' 리스트 s에 s += [[0, 0, 0, 0]]을 3번 수행하게 되므로 s = [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]
- 따라서 3 x 4 크기의 2차원 리스트가 완성된다.
■ 다음과 같이 리스트 컴프리헨션을 사용해도 된다.
s = [ [0]*cols for row in range(rows) ]
s
```#결과#```
[[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]
````````````
2.2 2차원 리스트 항목 접근
■ 2차원 리스트의 항목에 접근하려면 2개의 인덱스 번호를 지정해야 한다. 2.1에서 본 것처럼 첫 번째 인덱스 번호는 행 번호이고, 두 번째 인덱스 번호는 열 번호가 된다.
■ 인덱스 번호가 0부터 시작하므로 행 번호와 열 번호도 0부터 시작한다고 하자. 그렇다면 아래의 2차원 리스트 s에서 항목 6은 1행 1열에 있는 항목 s[1][1]이 된다.
s = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
]
s[1][1]
```#결과#```
6
````````````
rows = len(s)
cols = len(s[0]) # i번째 행(1차원 리스트)의 길이 = i번째 행에 들어 있는 열의 개수 = 열의 길이
# 모든 행의 길이가 같기 때문ㅇ
print(rows, cols)
```#결과#```
3 4
````````````
for i in range(rows):
for j in range(cols):
print(s[i][j], end = ' ')
print()
```#결과#```
1 2 3 4
5 6 7 8
9 10 11 12
````````````■ 이러한 접근 방식을 이용하여 다음과 같이 특정 행 또는 열 혹은 모든 행, 모든 열의 합계를 계산할 수도 있다.
i = 0
total = 0
## 0번째 행의 모든 원소의 합
for j in range(cols):
total += s[i][j]
print(total)
```#결과#```
10
````````````
total = 0
## 0번째와 1번째 행의 모든 원소의 합
for i in range(rows-1):
for j in range(cols):
total += s[i][j]
print(total)
```#결과#```
36
````````````
j = 1
total = 0
## 1번째 열의 모든 원소의 합
for i in range(rows):
total += s[i][j]
print(total)
```#결과#```
18
````````````
total = 0
## 1번째와 2번째 열의 모든 원소의 합
for i in range(rows):
for j in range(cols):
if j==2: break
total += s[i][j+1]
print(total)
```#결과#```
39
````````````'파이썬' 카테고리의 다른 글
| 제어문(control statement) (2) - 반복문 for, while (0) | 2024.09.02 |
|---|---|
| 제어문(control statement) (1) - 조건문 if (0) | 2024.08.28 |
| 자료형(Data Type) (4) - 세트(집합), 딕셔너리 (0) | 2024.08.24 |
| 자료형(Data Type) (3) - 튜플, 불(bool) (0) | 2024.08.23 |
| 자료형(Data Type) (1) - 숫자, 문자열 (2) | 2024.08.21 |


